
Die Nachfrage nach erstklassig gelabelten Daten für Machine Learning ist aktuell so hoch wie nie. Immer wenn ich mit Teams spreche, die an neuen KI-Modellen tüfteln – egal ob für Umsatzprognosen, Produktempfehlungen oder die Analyse von Kundenfeedback – stoße ich auf die gleichen Probleme: Manuelles Data Labeling ist langsam, kostet viel Geld und ist ehrlich gesagt einfach nervig. Ich habe schon Projekte gesehen, die wochen- oder monatelang auf Eis lagen, nur weil es nicht genug gelabelte Beispiele fürs Modelltraining gab. Und wenn die Labels dann auch noch uneinheitlich sind? Dann sind die Vorhersagen des Modells ungefähr so verlässlich wie meine Versuche, rückwärts einzuparken.
Die gute Nachricht: Automatisiertes Data Labeling mit Machine Learning krempelt alles um. Wenn KI die Hauptarbeit übernimmt, läuft der Labeling-Prozess nicht nur viel schneller, sondern auch genauer und konsistenter – und genau das braucht man für erfolgreiche ML-Projekte. In diesem Guide zeige ich dir, wie automatisiertes Data Labeling funktioniert, warum es für starke Modelle so wichtig ist und wie du mit Tools wie ganz ohne Programmierkenntnisse deinen eigenen automatisierten Labeling-Workflow aufsetzen kannst.
Was steckt hinter automatisiertem Data Labeling mit Machine Learning?
Kurz gesagt: Automatisiertes Data Labeling mit Machine Learning heißt, dass Algorithmen und KI-Tools Rohdaten automatisch mit Labels versehen (zum Beispiel „Spam“ oder „Nicht Spam“, „Katze“ oder „Hund“, „Positiv“ oder „Negativ“), ohne dass du jedes einzelne Beispiel selbst anklicken musst. Stell dir vor, du müsstest nicht mehr tausende Urlaubsfotos von Hand taggen – eine Gesichtserkennung sortiert sie einfach automatisch nach Person, Ort oder sogar Stimmung.
Beim klassischen, manuellen Labeling schauen sich Menschen jeden Datensatz einzeln an und vergeben das passende Label. Das kann zwar sehr genau sein, ist aber langsam, teuer und kaum skalierbar. Automatisiertes Labeling nutzt dagegen ML-Modelle, die auf einer kleineren, manuell gelabelten Datenmenge trainiert wurden, um den Rest der Daten zu labeln. Das Ergebnis: Schneller, konsistenter und viel besser skalierbar ().
Für Unternehmen bedeutet das: Bessere Modelle, weniger Handarbeit und ein echter Vorsprung im datengetriebenen Wettbewerb.
Warum automatisiertes Data Labeling für starke Machine-Learning-Modelle so wichtig ist
Klar ist: Die Qualität deiner gelabelten Daten entscheidet maßgeblich darüber, wie gut deine Machine-Learning-Modelle am Ende performen. Wie man so schön sagt: „Garbage in, garbage out.“ Sind die Labels fehlerhaft oder uneinheitlich, lernt das Modell die falschen Muster – und die Vorhersagen werden unzuverlässig ().
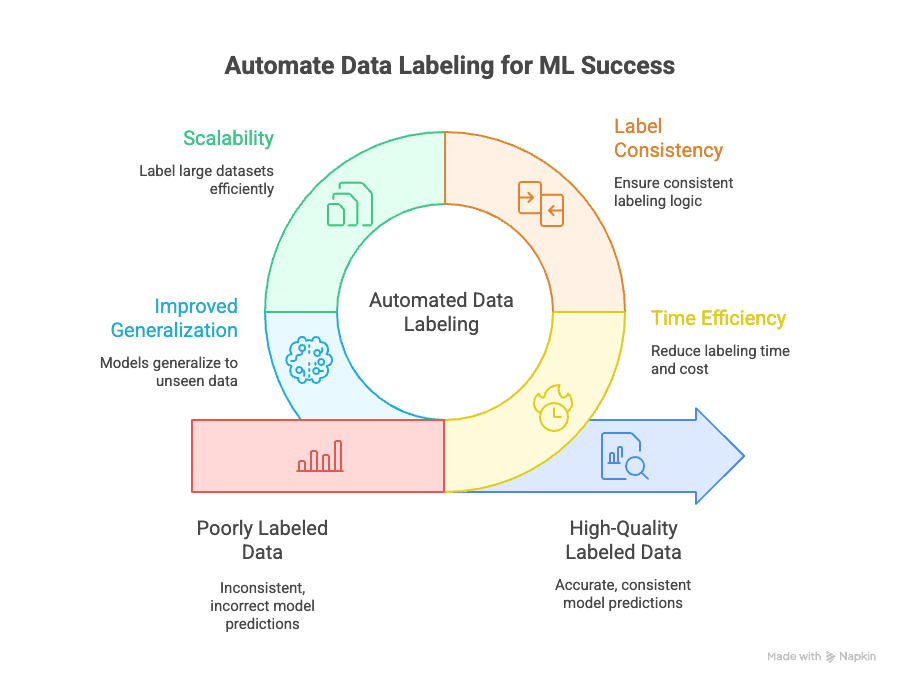
Automatisiertes Data Labeling löst gleich mehrere große Probleme:
- Zeitersparnis: Manuelles Labeln kann bis zu eines ML-Projekts verschlingen. Automatisierung spart hier massiv Zeit und ermöglicht schnellere Iterationen.
- Konsistenz: Maschinen werden nicht müde oder unaufmerksam. Automatisiertes Labeling sorgt dafür, dass jeder Datensatz nach denselben Regeln gelabelt wird – menschliche Fehler und Bias werden minimiert ().
- Skalierbarkeit: Egal ob 10.000, 100.000 oder eine Million Datenpunkte – mit Automatisierung ist das easy, ohne ein riesiges Team an Labelern zu brauchen ().
- Bessere Generalisierung: Einheitliche, hochwertige Labels helfen deinem Modell, auch auf neue, unbekannte Daten besser zu reagieren – das ist das Ziel von Machine Learning ().
Der Business-Impact ist riesig: Schlechte Labels können die Modellgenauigkeit um bis zu senken, während automatisiertes, hochwertiges Labeling die Entwicklung und den Einsatz von Modellen deutlich beschleunigt.
Manuelles vs. automatisiertes Data Labeling im Vergleich
Hier der direkte Vergleich:
| Faktor | Manuelles Labeling | Automatisiertes Labeling mit ML |
|---|---|---|
| Geschwindigkeit | Langsam (Wochen/Monate bei großen Datenmengen) | Schnell (Minuten/Stunden bei großen Datenmengen) |
| Genauigkeit | Hoch, aber anfällig für menschliche Fehler/Inkonsistenz | Hoch, mit konsistenter Logik und weniger Fehlern |
| Skalierbarkeit | Begrenzung durch verfügbare Arbeitskraft | Skaliert problemlos auf Millionen von Datenpunkten |
| Kosten | Teuer (arbeitsintensiv) | Geringere langfristige Kosten (Keylabs) |
| Am besten geeignet für | Kleine, komplexe oder mehrdeutige Datensätze | Große, repetitive oder klar strukturierte Datensätze |
Manuelles Labeling hat weiterhin seine Daseinsberechtigung – vor allem bei Sonderfällen oder unklaren Daten. Für die meisten Business-Anwendungen ist Automatisierung aber der deutlich effizientere Weg.
Die Grundschritte beim automatisierten Data Labeling mit Machine Learning
Wie läuft automatisiertes Data Labeling konkret ab? Hier mein bewährter Workflow:
- Datensammlung und Vorverarbeitung
- Feature-Extraktion und -Vorbereitung
- Automatisiertes Labeling mit Machine Learning
- Qualitätssicherung und menschliche Kontrolle
Schauen wir uns die einzelnen Schritte genauer an.
Schritt 1: Datensammlung und Vorverarbeitung
Bevor du Daten labeln kannst, musst du sie erstmal einsammeln und aufbereiten. Das kann heißen, Produktlisten von Webseiten zu holen, Kundenbewertungen zu exportieren oder Bilder aus internen Datenbanken zu sammeln. Wichtig ist die Datenqualität: Schlechte Rohdaten führen zu schlechten Labels – und damit zu schlechten Modellen ().
Best Practices:
- Doppelte und irrelevante Einträge rauswerfen
- Formate vereinheitlichen (z. B. Datumsangaben, Währungen)
- Fehlende oder unvollständige Daten bereinigen
Schritt 2: Feature-Extraktion und -Vorbereitung
Jetzt werden die relevanten Merkmale für die Labeling-Aufgabe identifiziert. Beim Labeln von Produktlisten könnten das z. B. Preis, Marke, Kategorie und Beschreibung sein. Im Vertrieb oder Marketing sind es vielleicht Firmennamen, Kontaktdaten oder Stimmungen aus E-Mails.
Praxisbeispiel: Mit kannst du strukturierte Daten von Webseiten extrahieren – wie Produktspezifikationen, Bewertungen oder Kontaktdaten – ganz ohne Programmieraufwand.
Schritt 3: Automatisiertes Labeling mit Machine Learning
Jetzt kommt die eigentliche Automatisierung ins Spiel. Du nutzt ML-Modelle (trainiert auf einer kleineren, manuell gelabelten Datenbasis), um die restlichen Daten zu labeln. Typische Methoden sind:
- Überwachtes Lernen: Ein Klassifikator wird auf gelabelten Beispielen trainiert und labelt dann neue Daten.
- Regelbasierte Ansätze: Vordefinierte Regeln (z. B. „Wenn Preis > 1000 €, dann Label ‚Premium‘“) für einfache Fälle.
- Active Learning: Das Modell bittet bei unsicheren Fällen um menschliches Feedback und verbessert sich so kontinuierlich ().
- Transfer Learning: Vorgefertigte Modelle werden genutzt, um das Labeling in neuen Bereichen zu beschleunigen ().
Das Ergebnis: Konsistente, hochwertige Labels – und das in großem Maßstab.
Schritt 4: Qualitätssicherung und menschliche Kontrolle
Auch die besten Modelle brauchen eine Qualitätskontrolle. Regelmäßige menschliche Überprüfung hilft, Sonderfälle, mehrdeutige Daten oder Modellabweichungen zu erkennen. Praktische QA-Maßnahmen sind:
- Zufällige Stichproben zur manuellen Kontrolle
- Vergleich automatisierter Labels mit einer „Goldstandard“-Menge
- Konsistenzmessung mit Inter-Annotator-Agreement-Metriken ()
So setzt du Thunderbit für automatisiertes Data Labeling mit Machine Learning ein
Jetzt wird’s praktisch. ist ein KI-basierter Web-Scraper und Data-Labeling-Tool, das speziell für Business-Anwender entwickelt wurde – ganz ohne Programmierkenntnisse. So kannst du deinen Data-Labeling-Workflow automatisieren:
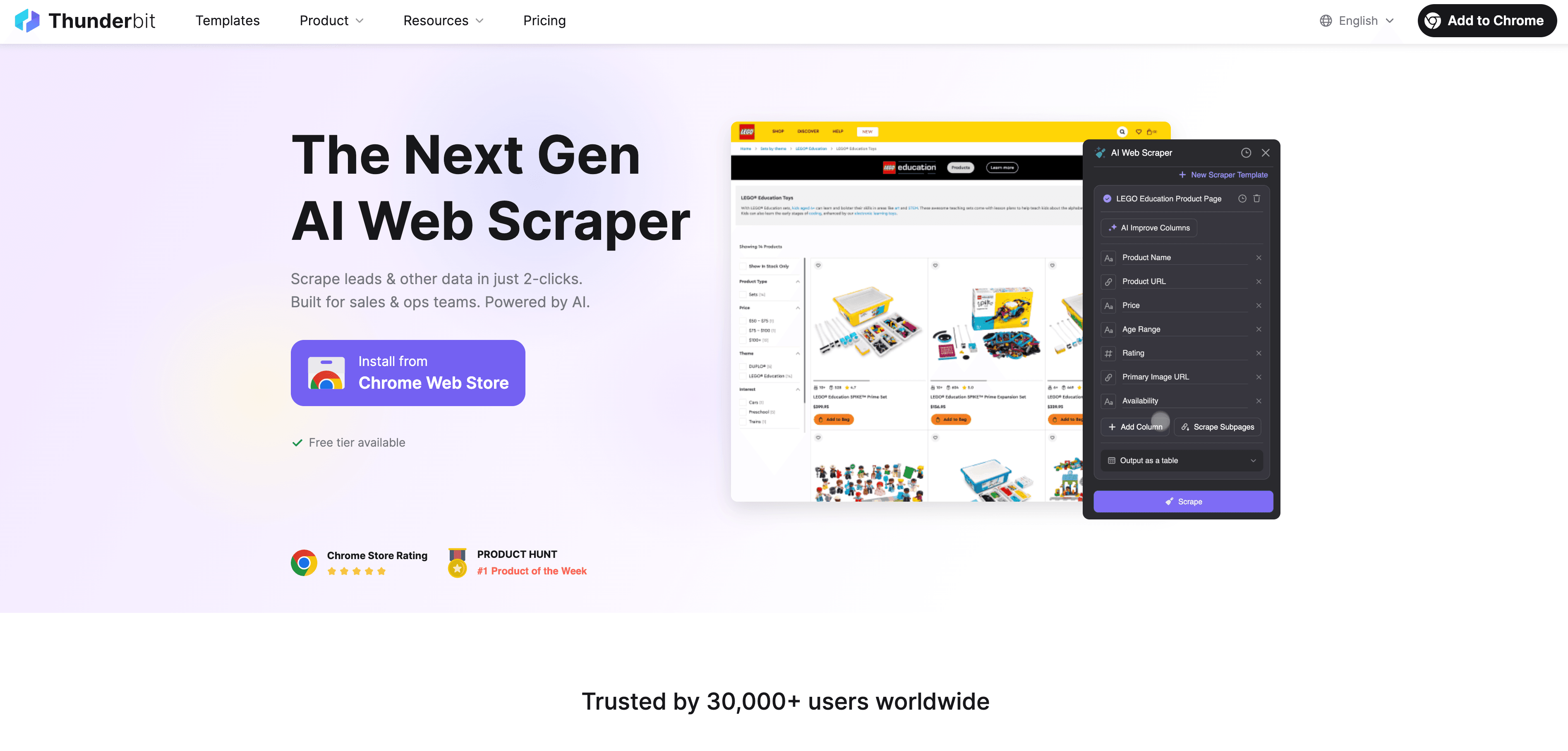
Schritt-für-Schritt-Anleitung
- Webdaten extrahieren: Mit der strukturierte Daten von jeder Website sammeln. Einfach die Erweiterung öffnen, Datenquelle auswählen und Thunderbits KI schlägt die besten Felder zum Extrahieren vor.
- Label-Anweisungen definieren: Mit natürlichen Sprachbefehlen beschreibst du der KI, wie die Daten gelabelt werden sollen. Zum Beispiel: „Alle Produkte über 500 € als ‚Premium‘ labeln“ oder „Bewertungen mit positiver Stimmung taggen“.
- Automatisiertes Labeling anwenden: Mit dem Field AI Prompt von Thunderbit kannst du die Label-Logik individuell anpassen – ideal für komplexe oder mehrstufige Labeling-Aufgaben.
- Gelabelte Daten exportieren: Nach dem Labeling kannst du die Daten direkt nach Excel, Google Sheets, Airtable oder Notion exportieren – bereit für das Modelltraining oder die Analyse.
Das Beste: Thunderbit ist für Nicht-Techniker in Vertrieb, Marketing, Operations und vielen anderen Bereichen gemacht. Du brauchst keine einzige Zeile Code zu schreiben oder dich mit komplizierten Vorlagen herumzuschlagen.
Thunderbits Natural Language Prompts und Field AI Features
Ein echtes Highlight ist die Möglichkeit, Label-Logik einfach in Alltagssprache zu definieren. Du möchtest Leads nach Region kategorisieren, Produkte nach Kategorie taggen oder E-Mails mit dringender Sprache markieren? Beschreibe einfach, was du brauchst – Thunderbits KI übernimmt den Rest.
Beispiel-Prompts:
- „Alle Kontakte mit einer ‚.edu‘-E-Mail als ‚Education‘-Segment labeln.“
- „Wenn die Bewertung ‚schneller Versand‘ erwähnt, als ‚Positive Versand-Erfahrung‘ taggen.“
- „Produkte nach Marke und Preisspanne gruppieren.“
Mit dem Field AI Prompt von Thunderbit kannst du die Label-Logik für jede Spalte individuell anpassen, Regeln kombinieren oder Labels sogar in verschiedene Sprachen übersetzen lassen.
Subpage Scraping und Multi-Field Labeling
Komplexe Datenstrukturen? Kein Problem. Mit Thunderbits Subpage-Scraping-Funktion kannst du Daten aus verschachtelten Seiten (z. B. Produktdetails oder Autorenprofile) extrahieren und labeln – alles in einer strukturierten Tabelle. Mehrere Felder lassen sich gleichzeitig labeln – das spart noch mehr Zeit.
Praxisbeispiel: Produktlisten aus einem Onlineshop extrahieren, dann zu jedem Produkt die Detailseite aufrufen und Spezifikationen, Bewertungen und Verkäuferinfos labeln – alles in einem Workflow.
Mehr Genauigkeit und Effizienz durch die Kombination mehrerer Data-Labeling-Tools
Thunderbit deckt viele Anwendungsfälle ab, aber manchmal braucht man für spezielle Datentypen (z. B. Bild- oder Videoannotation) spezialisierte Tools wie oder .
Tipp aus der Praxis: Nutze Thunderbit für die Webdaten-Extraktion und das initiale Labeling. Exportiere die Daten dann zu Label Studio oder Supervisely für fortgeschrittene Annotationen (z. B. Bounding Boxes auf Bildern oder Frame-für-Frame-Labels in Videos). So nutzt du die Stärken jeder Plattform und steigerst Genauigkeit und Effizienz ().
Wann du spezialisierte Tools zusätzlich zu Thunderbit einsetzen solltest
- Bildannotation: Für Aufgaben wie Objekterkennung oder Segmentierung eignen sich Supervisely oder Label Studio.
- Video-Labeling: Spezielle Videotools ermöglichen Frame-für-Frame-Annotation und Tracking.
- Komplexe Multi-Label-Aufgaben: Kombiniere Thunderbits strukturierte Datenerfassung mit fortgeschrittenen Annotationstools für optimale Ergebnisse.
Best Practice: Starte mit Thunderbit für schnelles, skalierbares Labeling von strukturierten und halbstrukturierten Daten. Für tiefergehende Annotationen ziehe spezialisierte Tools hinzu.
Best Practices für automatisiertes Data Labeling mit Machine Learning
So holst du das Maximum aus deinem automatisierten Labeling-Workflow heraus:
- Klare Label-Guidelines definieren: Unklare Labels führen zu Inkonsistenzen – beschreibe genau, was jedes Label bedeutet.
- Mit einer hochwertigen Seed-Menge starten: Label eine kleine, repräsentative Stichprobe manuell, um das Anfangsmodell zu trainieren.
- Iterativ verbessern: Nutze Active Learning, um das Modell kontinuierlich zu optimieren und konzentriere die menschliche Kontrolle auf schwierige Fälle.
- Regelmäßig validieren: Überprüfe in regelmäßigen Abständen zufällig gelabelte Daten, um Fehler oder Drift zu erkennen.
- Integrieren und automatisieren: Verbinde mit Tools wie Thunderbit die Datensammlung, das Labeling und den Export in einem Workflow.
Typische Herausforderungen und wie du sie meisterst
Automatisiertes Data Labeling bringt auch Herausforderungen mit sich. So gehst du damit um:
- Mehrdeutige Daten: Definiere Labels klar und gib Beispiele für Sonderfälle.
- Modelldrift: Trainiere dein Labeling-Modell regelmäßig mit neuen, manuell geprüften Daten nach.
- Edge Cases: Richte einen Prozess für die menschliche Überprüfung von unklaren oder neuen Datenpunkten ein.
- Integrationsprobleme: Wähle Tools (wie Thunderbit), die einen einfachen Export zu deinen bevorzugten Plattformen ermöglichen.
Fazit & wichtigste Erkenntnisse
Automatisiertes Data Labeling mit Machine Learning ist das Geheimnis hinter den erfolgreichsten KI-Modellen. Es spart Zeit, senkt Kosten und – am wichtigsten – liefert die konsistenten, hochwertigen Labels, die deine Modelle für Top-Performance brauchen. Mit Tools wie und spezialisierten Annotation-Plattformen baust du einen Workflow, der schnell, präzise und skalierbar ist – unabhängig von deinem technischen Hintergrund.
Bereit, den Unterschied selbst zu erleben? , probiere automatisiertes Labeling im nächsten Projekt aus und sieh zu, wie deine Machine-Learning-Modelle schneller und smarter werden. Noch mehr Tipps und Praxisbeispiele findest du im .
FAQs
1. Was ist automatisiertes Data Labeling mit Machine Learning?
Dabei übernehmen KI- und ML-Modelle das automatische Labeln von Daten – statt alles von Hand zu machen. Das beschleunigt den Prozess, sorgt für mehr Konsistenz und ist auch bei großen Datenmengen problemlos skalierbar.
2. Warum ist die Label-Qualität für Machine Learning so wichtig?
Hochwertige, konsistente Labels sind die Basis für präzise Modelle. Schlechte Labels können die Modellgenauigkeit um bis zu 80 % senken und zu unzuverlässigen Ergebnissen führen.
3. Wie unterstützt Thunderbit beim automatisierten Data Labeling?
Mit Thunderbit kannst du Webdaten per KI extrahieren und labeln – mit natürlichen Sprachbefehlen und individuell anpassbarer Feldlogik, ganz ohne Programmieren. Ideal für Business-Anwender in Vertrieb, Marketing und Operations.
4. Kann ich Thunderbit mit anderen Labeling-Tools kombinieren?
Klar! Nutze Thunderbit für die strukturierte Datenerfassung und das initiale Labeling. Für fortgeschrittene Bild- oder Videoannotation exportiere die Daten zu Tools wie Label Studio oder Supervisely.
5. Was sind Best Practices für automatisiertes Data Labeling?
Definiere klare Label-Guidelines, starte mit einer hochwertigen Seed-Menge, optimiere iterativ mit Active Learning, validiere regelmäßig und nutze integrierte Tools für einen reibungslosen Workflow.
Bereit, dein Data Labeling zu automatisieren und deine Machine-Learning-Projekte zu beschleunigen? Probiere Thunderbit aus und spare Zeit – und Nerven.
Mehr erfahren: