

Für das halbe Internet ist Amazon gleichzeitig Kaufhaus, Supermarkt und Elektronikmarkt. Wer im Vertrieb, im E-Commerce oder im Operations-Bereich arbeitet, weiß: Was auf Amazon geschieht, bleibt nicht auf Amazon – es schlägt auf Ihre Preise durch, auf die Lagerplanung und mitunter auf den nächsten Produktlaunch. Der Knackpunkt: Produktdetails, Preise, Bewertungen und Rezensionen stecken hinter einer Oberfläche, die für Käufer gebaut wurde, nicht für datenhungrige Teams. Wie also kommen Sie an die Daten, ohne am Wochenende alles wie 1999 per Copy & Paste zusammenzuklicken?
Hier kommt Web-Scraping ins Spiel. Ich zeige Ihnen zwei Wege zu Amazon-Produktdaten: den klassischen „Ärmel hochkrempeln und in Python programmieren"-Ansatz und den modernen Weg, bei dem ein No-Code-Web-Scraper wie Thunderbit die Schwerstarbeit übernimmt. Ich führe Sie durch echten Python-Code – samt aller Stolperfallen – und zeige danach, wie Thunderbit dieselben Daten in wenigen Klicks liefert, ganz ohne Code. Ob Entwickler, Business Analyst oder jemand, der die manuelle Dateneingabe satthat: Hier sind Sie richtig.
Warum Amazon-Produktdaten extrahieren? (amazon scraper python, web scraping with python)
Amazon ist nicht nur der größte Onlinehändler der Welt, sondern zugleich der größte offene Marktplatz für Competitive Intelligence. Mit über 600 Millionen gelisteten Produkten und knapp 2 Millionen aktiven Verkäufern wird die Plattform zur Goldgrube für alle, die:

- Preise überwachen (und die eigenen Preise in Echtzeit nachziehen)
- Wettbewerber analysieren (neue Produkteinführungen, Bewertungen und Rezensionen verfolgen)
- Leads generieren (Verkäufer, Lieferanten oder potenzielle Partner aufspüren)
- Nachfrage prognostizieren (Lagerbestände und Verkaufsrang im Blick behalten)
- Markttrends erkennen (Rezensionen und Suchergebnisse auswerten)
Das ist keine graue Theorie – Unternehmen verbuchen echte Erträge. Ein Elektronikhändler steigerte mit gescrapten Amazon-Preisdaten seine Gewinnmargen um 15 %, eine andere Marke verzeichnete nach automatisiertem Wettbewerber-Preismonitoring einen Umsatzanstieg von 4 % bei 30 % weniger Analystenzeit.
Die folgende Tabelle fasst typische Anwendungsfälle und den jeweils zu erwartenden Nutzen zusammen:
| Anwendungsfall | Wer nutzt ihn | Typischer ROI / Nutzen |
|---|---|---|
| Preisüberwachung | E-Commerce, Operations | 15 %+ höhere Gewinnmarge, 4 % mehr Umsatz, 30 % weniger Analystenzeit |
| Wettbewerbsanalyse | Vertrieb, Produkt, Operations | Schnellere Preisanpassungen, bessere Wettbewerbsfähigkeit |
| Marktforschung (Rezensionen) | Produkt, Marketing | Schnellere Produktiteration, bessere Anzeigentexte, SEO-Erkenntnisse |
| Lead-Generierung | Vertrieb | 3.000+ Leads/Monat, 8+ Stunden pro Mitarbeiter und Woche eingespart |
| Bestands- und Nachfrageprognose | Operations, Supply Chain | 20 % weniger Überbestand, weniger Lagerengpässe |
| Trend-Erkennung | Marketing, Führungsebene | Frühe Erkennung gefragter Produkte und Kategorien |
Entscheidend ist dieser Befund: Über 90 % der Organisationen berichten inzwischen von messbarem Nutzen durch Datenanalyse. Wer Amazon nicht scrapt, verschenkt also Erkenntnisse – und Geld.
Überblick: Amazon Scraper Python vs. No-Code-Web-Scraper-Tools
Um Amazon-Daten aus dem Browser in Ihre Tabellen oder Dashboards zu holen, gibt es zwei Hauptwege:
-
Amazon Scraper Python (web scraping with python):
Sie schreiben ein eigenes Skript mit Python-Bibliotheken wie Requests und BeautifulSoup. Das verschafft volle Kontrolle, verlangt aber Programmierkenntnisse, den Umgang mit Anti-Bot-Maßnahmen und laufende Pflege, sobald Amazon seine Website umbaut.
-
No-Code-Web-Scraper-Tools (wie Thunderbit):
Sie greifen zu einem Tool, das per Zeigen, Klicken und Extrahieren erfasst – ohne Code. Moderne Vertreter wie Thunderbit setzen KI ein, um die passenden Daten zu erkennen, Unterseiten und Pagination abzuarbeiten und direkt nach Excel oder Google Sheets zu exportieren.
So stellen sich beide Ansätze im Vergleich dar:
| Kriterium | Python-Scraper | No-Code (Thunderbit) |
|---|---|---|
| Einrichtungszeit | Hoch (installieren, programmieren, debuggen) | Gering (Erweiterung installieren) |
| Erforderliche Kenntnisse | Programmieren erforderlich | Keine (zeigen & klicken) |
| Flexibilität | Unbegrenzt | Hoch für gängige Anwendungsfälle |
| Wartung | Sie beheben den Code | Das Tool aktualisiert sich selbst |
| Anti-Bot-Behandlung | Sie kümmern sich um Proxys und Header | Integriert, für Sie übernommen |
| Skalierbarkeit | Manuell (Threads, Proxys) | Cloud-Scraping, parallelisiert |
| Datenexport | Individuell (CSV, Excel, DB) | Mit einem Klick nach Excel, Sheets |
| Kosten | Kostenlos (Ihre Zeit + Proxys) | Freemium, bezahlt wird bei größerem Umfang |
In den nächsten Abschnitten gehe ich beide Wege durch – zuerst den Bau eines Amazon-Scrapers mit Python (inklusive echtem Code), danach dieselbe Aufgabe mit Thunderbits KI-Web-Scraper.
Einstieg in Amazon Scraper Python: Voraussetzungen & Setup
Bevor es an den Code geht, richten wir Ihre Umgebung ein.
Sie benötigen:
- Python 3.x (Download über python.org)
- Einen Code-Editor (ich nehme gern VS Code, aber jedes Werkzeug taugt)
- Die folgenden Bibliotheken:
requests(für HTTP-Anfragen)beautifulsoup4(fürs HTML-Parsing)lxml(schneller HTML-Parser)pandas(für Datentabellen/Export)re(reguläre Ausdrücke, bereits eingebaut)
Bibliotheken installieren:
pip install requests beautifulsoup4 lxml pandas
Projekt-Setup:
- Legen Sie einen neuen Ordner für Ihr Projekt an.
- Öffnen Sie Ihren Editor und erstellen Sie eine neue Python-Datei (z. B.
amazon_scraper.py). - Los geht's!
Schritt für Schritt: Web-Scraping mit Python für Amazon-Produktdaten
Sehen wir uns an, wie sich eine einzelne Amazon-Produktseite scrapen lässt. (Keine Sorge: Wie Sie mehrere Produkte und Seiten erfassen, folgt gleich.)
1. Anfragen senden und HTML abrufen
Zunächst holen wir das HTML einer Produktseite. (Ersetzen Sie die URL durch ein beliebiges Amazon-Produkt.)
import requests
url = "<https://www.amazon.com/dp/B0ExampleASIN>"
response = requests.get(url)
html_content = response.text
print(response.status_code)
Achtung: Diese schlichte Anfrage blockiert Amazon mit hoher Wahrscheinlichkeit. Statt der Produktseite bekommen Sie womöglich einen 503-Fehler oder ein CAPTCHA zu sehen. Der Grund: Amazon erkennt, dass kein echter Browser anfragt.
Amazons Anti-Bot-Maßnahmen umgehen
Bots sind Amazon ein Dorn im Auge. Damit Sie nicht blockiert werden, sollten Sie:
- Einen User-Agent-Header setzen (also vorgeben, Chrome oder Firefox zu sein)
- User-Agents rotieren (nicht jedes Mal denselben verwenden)
- Anfragen drosseln (zufällige Verzögerungen einstreuen)
- Proxys einsetzen (fürs Scraping in größerem Umfang)
So setzen Sie Header:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)... Safari/537.36",
"Accept-Language": "en-US,en;q=0.9",
}
response = requests.get(url, headers=headers)
Sie möchten es etwas ausgefeilter? Halten Sie eine Liste von User-Agents bereit und rotieren Sie sie pro Anfrage. Bei größeren Projekten empfiehlt sich ein Proxy-Dienst (Auswahl gibt es reichlich); für kleinere Scraping-Aufgaben genügen Header und Verzögerungen meist.
Wichtige Produktfelder extrahieren
Liegt das HTML vor, parsen Sie es mit BeautifulSoup.
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_content, "lxml")
Nun ziehen wir die wichtigsten Daten heraus:
Produkttitel
title_elem = soup.find(id="productTitle")
product_title = title_elem.get_text(strip=True) if title_elem else None
Preis
Amazon-Preise können an mehreren Stellen stehen. Probieren Sie diese Varianten:
price = None
price_elem = soup.find(id="priceblock_ourprice") or soup.find(id="priceblock_dealprice")
if price_elem:
price = price_elem.get_text(strip=True)
else:
price_whole = soup.find("span", {"class": "a-price-whole"})
price_frac = soup.find("span", {"class": "a-price-fraction"})
if price_whole and price_frac:
price = price_whole.text + price_frac.text
Bewertung und Anzahl der Rezensionen
rating_elem = soup.find("span", {"class": "a-icon-alt"})
rating = rating_elem.get_text(strip=True) if rating_elem else None
review_count_elem = soup.find(id="acrCustomerReviewText")
reviews_text = review_count_elem.get_text(strip=True) if review_count_elem else ""
reviews_count = reviews_text.split()[0] # z. B. "1,554 ratings"
Hauptbild-URL
Hochauflösende Bilder versteckt Amazon mitunter als JSON im HTML. Hier ein schneller Regex-Weg:
import re
match = re.search(r'"hiRes":"(https://.*?.jpg)"', html_content)
main_image_url = match.group(1) if match else None
Alternativ greifen Sie direkt das Hauptbild-Tag ab:
img_tag = soup.find("img", {"id": "landingImage"})
img_url = img_tag['src'] if img_tag else None
Produktdetails
Spezifikationen wie Marke, Gewicht und Maße finden sich meist in einer Tabelle:
details = {}
rows = soup.select("#productDetails_techSpec_section_1 tr")
for row in rows:
header = row.find("th").get_text(strip=True)
value = row.find("td").get_text(strip=True)
details[header] = value
Oder, falls Amazon das „detailBullets"-Format nutzt:
bullets = soup.select("#detailBullets_feature_div li")
for li in bullets:
txt = li.get_text(" ", strip=True)
if ":" in txt:
key, val = txt.split(":", 1)
details[key.strip()] = val.strip()
Geben Sie Ihre Ergebnisse aus:
print("Titel:", product_title)
print("Preis:", price)
print("Bewertung:", rating, "basierend auf", reviews_count, "Rezensionen")
print("Hauptbild-URL:", main_image_url)
print("Details:", details)
Mehrere Produkte scrapen und Pagination verarbeiten
Ein einzelnes Produkt ist schön und gut, doch meist brauchen Sie eine ganze Liste. So erfassen Sie Suchergebnisse über mehrere Seiten hinweg.
Produktlinks von einer Suchseite holen
search_url = "<https://www.amazon.com/s?k=bluetooth+headphones>"
res = requests.get(search_url, headers=headers)
soup = BeautifulSoup(res.text, "lxml")
product_links = []
for a in soup.select("h2 a.a-link-normal"):
href = a['href']
full_url = "<https://www.amazon.com>" + href
product_links.append(full_url)
Pagination handhaben
Amazons Such-URLs arbeiten mit &page=2, &page=3 und so weiter.
for page in range(1, 6): # erste 5 Seiten scrapen
search_url = f"<https://www.amazon.com/s?k=bluetooth+headphones&page={page}>"
res = requests.get(search_url, headers=headers)
if res.status_code != 200:
break
soup = BeautifulSoup(res.text, "lxml")
# ... Produktlinks wie oben extrahieren ...
Über Produktseiten iterieren und nach CSV exportieren
Sammeln Sie Ihre Produktdaten in einer Liste von Dictionaries und übergeben Sie sie anschließend an pandas:
import pandas as pd
df = pd.DataFrame(product_data_list) # Liste von Dicts
df.to_csv("amazon_products.csv", index=False)
Oder nach Excel:
df.to_excel("amazon_products.xlsx", index=False)
Best Practices für Amazon-Scraper-Python-Projekte
Machen wir uns nichts vor: Amazon baut seine Website permanent um und geht gezielt gegen Scraper vor. Damit Ihr Projekt stabil bleibt:
- Header und User-Agents rotieren (etwa mit einer Bibliothek wie
fake-useragent) - Proxys fürs Scraping in großem Umfang einsetzen
- Anfragen drosseln (zufälliges
time.sleep()zwischen den Anfragen) - Fehler sauber abfangen (bei 503 erneut versuchen, bei Blockierung das Tempo drosseln)
- Flexible Parsing-Logik schreiben (pro Feld mehrere Selektoren prüfen)
- Auf HTML-Änderungen achten (liefert Ihr Skript plötzlich überall
None, prüfen Sie die Seite) - robots.txt respektieren (Amazon untersagt das Scraping vieler Bereiche – gehen Sie verantwortungsvoll vor)
- Daten gleich beim Erfassen bereinigen (Währungszeichen, Kommas und Leerzeichen entfernen)
- Mit der Community in Kontakt bleiben (Foren, Stack Overflow, Reddits r/webscraping)
Checkliste für die Pflege Ihres Scrapers:
- User-Agents und Header rotieren
- Proxys bei großem Umfang verwenden
- Zufällige Verzögerungen einbauen
- Den Code modular aufbauen, damit Updates leichter fallen
- Auf Sperren oder CAPTCHAs achten
- Daten regelmäßig exportieren
- Selektoren und Logik dokumentieren
Mehr Tiefe bietet mein Leitfaden zum Web-Scraping mit Python.
Die No-Code-Alternative: Amazon mit Thunderbit AI Web Scraper scrapen
Amazon-Produktdaten mit KI scrapen Get Started Free
Sie kennen jetzt den Python-Weg. Doch was, wenn Sie gar nicht programmieren wollen – oder die Daten lieber in zwei Klicks holen? Genau dafür gibt es Thunderbit.
Thunderbit ist eine KI-Web-Scraper-Chrome-Erweiterung, mit der Sie Amazon-Daten – und Daten praktisch jeder Website – ganz ohne Code extrahieren. Warum mir das Tool so gefällt:
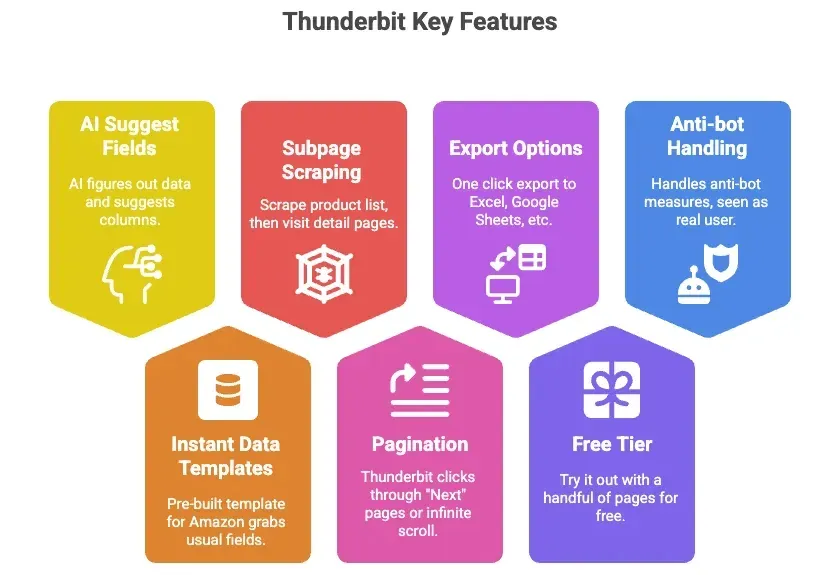
- KI-Feldvorschläge: Ein Klick auf eine Schaltfläche genügt, und Thunderbits KI erkennt die vorhandenen Daten und schlägt passende Spalten vor (etwa Titel, Preis, Bewertung).
- Sofortige Datenvorlagen: Für Amazon liegt eine fertige Vorlage bereit, die alle gängigen Felder erfasst – ohne jegliches Setup.
- Unterseiten-Scraping: Scrapen Sie eine Produktliste, und Thunderbit besucht anschließend jede Detailseite, um automatisch weitere Informationen zu ziehen.
- Pagination: Thunderbit klickt für Sie durch „Weiter"-Seiten oder verarbeitet Infinite Scroll.
- Export nach Excel, Google Sheets, Airtable, Notion: Ein Klick, und Ihre Daten sind einsatzbereit.
- Kostenlose Stufe: Testen Sie das Tool mit einigen Seiten gratis.
- Anti-Bot-Handling inklusive: Da das Tool in Ihrem Browser (oder in der Cloud) läuft, hält Amazon es für einen echten Nutzer.
Schritt für Schritt: Mit Thunderbit Amazon-Produktdaten scrapen
So unkompliziert läuft es:
-
Thunderbit installieren:
Laden Sie die Thunderbit Chrome Extension herunter und melden Sie sich an.
-
Amazon öffnen:
Rufen Sie die Amazon-Seite auf, die Sie scrapen möchten (Suchergebnisse, Produktdetailseite, was auch immer).
-
„KI-Felder vorschlagen" klicken oder eine Vorlage nutzen:
Thunderbit schlägt Spalten zum Extrahieren vor (oder Sie wählen die Amazon-Produktvorlage).
-
Spalten prüfen:
Passen Sie die Spalten bei Bedarf an (Felder ergänzen/entfernen, umbenennen usw.).
-
„Scrapen" klicken:
Thunderbit holt die Daten von der Seite und zeigt sie in einer Tabelle an.
-
Unterseiten & Pagination verarbeiten:
Haben Sie eine Liste gescrapt, klicken Sie auf „Unterseiten scrapen", um jede Detailseite zu besuchen und mehr Informationen zu erfassen. Auch durch „Weiter"-Seiten klickt Thunderbit automatisch.
-
Daten exportieren:
Klicken Sie auf „Nach Excel exportieren" oder „Nach Google Sheets exportieren". Fertig.
-
(Optional) Scraping planen:
Sie brauchen die Daten täglich? Dann übernimmt der Thunderbit-Planer den Vorgang für Sie automatisch.
Das war's. Kein Code, kein Debugging, keine Proxys, kein Stress. Eine visuelle Anleitung gibt es auf dem Thunderbit-YouTube-Kanal oder auf der Vorlagenseite für den Amazon Product Scraper.
Amazon-Product-Scraper-Vorlage testen
Amazon Scraper Python vs. No-Code-Web-Scraper: Direktvergleich
Fassen wir alles zusammen:
| Kriterium | Python-Scraper | Thunderbit (No-Code) |
|---|---|---|
| Einrichtungszeit | Hoch (installieren, programmieren, debuggen) | Gering (Erweiterung installieren) |
| Erforderliche Kenntnisse | Programmieren erforderlich | Keine (zeigen & klicken) |
| Flexibilität | Unbegrenzt | Hoch für gängige Anwendungsfälle |
| Wartung | Sie beheben den Code | Das Tool aktualisiert sich selbst |
| Anti-Bot-Behandlung | Sie kümmern sich um Proxys und Header | Integriert, für Sie übernommen |
| Skalierbarkeit | Manuell (Threads, Proxys) | Cloud-Scraping, parallelisiert |
| Datenexport | Individuell (CSV, Excel, DB) | Mit einem Klick nach Excel, Sheets |
| Kosten | Kostenlos (Ihre Zeit + Proxys) | Freemium, bezahlt wird bei größerem Umfang |
| Am besten geeignet für | Entwickler, individuelle Anforderungen | Geschäftsanwender, schnelle Ergebnisse |
Tüfteln Sie als Entwickler gern und brauchen etwas sehr Individuelles, ist Python Ihr Verbündeter. Zählen für Sie Tempo, Einfachheit und null Code, führt der Weg zu Thunderbit.
Wann Sie Python, No-Code oder einen KI-Web-Scraper für Amazon-Daten wählen sollten
Greifen Sie zu Python, wenn:
- Sie individuelle Logik brauchen oder das Scraping in Backend-Systeme einbinden möchten
- Sie in sehr großem Umfang scrapen (Zehntausende Produkte)
- Sie verstehen möchten, wie Scraping technisch funktioniert
Greifen Sie zu Thunderbit (No-Code, KI-Web-Scraper), wenn:
- Sie schnell Daten brauchen, ohne zu programmieren
- Sie als Business-User, Analyst oder Marketer arbeiten
- Sie Ihrem Team ermöglichen wollen, sich selbst mit Daten zu versorgen
- Sie sich den Aufwand für Proxys, Anti-Bot-Maßnahmen und Wartung sparen möchten
Kombinieren Sie beides, wenn:
- Sie mit Thunderbit zügig einen Prototyp bauen und dann für den Produktivbetrieb eine maßgeschneiderte Python-Lösung entwickeln
- Sie Thunderbit zur Datenerfassung und Python zur Bereinigung/Analyse einsetzen möchten
Für die meisten Geschäftsanwender deckt Thunderbit 90 % der Amazon-Scraping-Anforderungen in einem Bruchteil der Zeit ab. Die übrigen 10 % – sehr individuelle, groß angelegte oder tief integrierte Vorhaben – bleiben die Domäne von Python.
Fazit und wichtigste Erkenntnisse
So scrapen Sie Amazon-Produkte und -Bewertungen 2025 mit KI Get Started Free
Wer Amazon-Produktdaten scrapt, verschafft jedem Vertriebs-, E-Commerce- oder Operations-Team eine Superkraft. Ob Preise verfolgen, Wettbewerber analysieren oder das Team vor endlosem Copy-Paste bewahren – für jeden Fall gibt es einen Weg.
- Python-Scraping verschafft Ihnen volle Kontrolle, bringt jedoch eine Lernkurve und laufende Wartung mit sich.
- No-Code-Web-Scraper wie Thunderbit öffnen die Amazon-Datenextraktion für alle – kein Code, kein Stress, nur Ergebnisse.
- Der beste Ansatz? Das Tool, das zu Ihren Fähigkeiten, Ihrem Zeitplan und Ihren Geschäftszielen passt.
Wenn Sie neugierig sind, testen Sie Thunderbit – der Einstieg ist kostenlos, und Sie werden staunen, wie schnell die Daten vorliegen. Und als Entwickler scheuen Sie sich nicht, beides zu verbinden: Manchmal führt der kürzeste Weg darüber, der KI die langweiligen Teile zu überlassen.
Thunderbit Chrome-Erweiterung holen
FAQs
1. Warum sollte ein Unternehmen Amazon-Produktdaten scrapen?
Mit dem Scraping von Amazon können Unternehmen Preise überwachen, Wettbewerber analysieren, Rezensionen für die Produktrecherche sammeln, die Nachfrage prognostizieren und Sales-Leads gewinnen. Bei über 600 Millionen Produkten und knapp 2 Millionen Verkäufern ist Amazon eine ergiebige Quelle für Competitive Intelligence.
2. Was sind die Hauptunterschiede zwischen Python und No-Code-Tools wie Thunderbit für das Scrapen von Amazon?
Python-Scraper bieten maximale Flexibilität, verlangen aber Programmierkenntnisse, Einrichtungszeit und laufende Wartung. Thunderbit als No-Code-KI-Web-Scraper lässt Nutzer Amazon-Daten sofort per Chrome-Erweiterung extrahieren – ohne Code, mit integriertem Anti-Bot-Handling und Export nach Excel oder Sheets.
3. Ist es legal, Daten von Amazon zu scrapen?
Die Nutzungsbedingungen von Amazon untersagen Scraping grundsätzlich, und Amazon setzt aktiv Anti-Bot-Maßnahmen ein. Dennoch scrapen viele Unternehmen weiterhin öffentlich zugängliche Daten und achten dabei auf ein verantwortungsvolles Vorgehen – etwa indem sie Rate Limits einhalten und übermäßige Anfragen vermeiden.
4. Welche Daten kann ich mit Web-Scraping-Tools von Amazon extrahieren?
Zu den typischen Feldern zählen Produkttitel, Preise, Bewertungen, Anzahl der Rezensionen, Bilder, Produktspezifikationen, Verfügbarkeit und mitunter sogar Verkäuferinformationen. Thunderbit beherrscht zusätzlich Unterseiten-Scraping und Pagination, um Daten über mehrere Listings und Seiten hinweg zu sammeln.
5. Wann sollte ich Python-Scraping gegenüber einem Tool wie Thunderbit wählen – oder umgekehrt?
Nehmen Sie Python, wenn Sie volle Kontrolle, individuelle Logik oder die Anbindung an Backend-Systeme benötigen. Nehmen Sie Thunderbit, wenn Sie schnelle Ergebnisse ohne Code wollen, mühelos skalieren müssen oder als Business-Anwender eine wartungsarme Lösung suchen.
Sie möchten tiefer einsteigen? Dann werfen Sie einen Blick auf diese Ressourcen:
- Thunderbit Blog
- Was ist Data Scraping und wie macht man es 2025
- So scrapen Sie Amazon-Produkte und -Bewertungen 2025 mit KI
- Leitfaden zum Web-Scraping mit Python
Viel Erfolg beim Scrapen – und mögen Ihre Tabellen stets auf dem neuesten Stand bleiben.
Thunderbit AI Web Scraper für Amazon testen Get Started Free




