
Jeder KI-Web-Scraper sieht in seiner Produktdemo beeindruckend aus. Dann setzen Sie ihn auf eine echte Website mit Cloudflare-Schutz an – und er liefert eine Challenge-Seite zurück, während er selbstbewusst behauptet, 47 Produktlisten gefunden zu haben.
Ich habe in den letzten Monaten bei Thunderbit mehrere Scraping-Tools für unser Team bewertet. Die Lücke zwischen Demo-Performance und Zuverlässigkeit im produktiven Einsatz ist durchgehend die größte Frustrationsquelle, die ich in Communities sehe. Ein Reddit-Nutzer hat es perfekt auf den Punkt gebracht: Mit allein in der Kategorie Web Scraping, plus Dutzenden weiteren Chrome-Erweiterungen, API-Anbietern und Actor-Marktplätzen, ist die Qual der Wahl real. Also habe ich 12 davon getestet.
Dieser Artikel bewertet 12 KI-Web-Scraper-Tools nach produktionsrelevanten Kriterien: Anti-Bot-Behandlung, Skalierbarkeit, Qualität strukturierter Ausgaben, Kosteneffizienz, Unterstützung dynamischer Websites und Flexibilität für Entwickler. Keine Feature-Checklisten. Keine Marketing-Screenshots. Nur das, was wirklich funktioniert, wenn die Demo vorbei ist.
Warum die meisten KI-Web-Scraper nach der Demo scheitern
Das Muster ist vorhersehbar. Die Marketingseite eines Tools zeigt, wie es saubere Spalten aus einer einfachen Produktlisten-Seite extrahiert. Sie installieren es, testen es auf einer geschützten E-Commerce-Seite – und bekommen eines davon:
- Eine
200 OK-Antwort mit einer Cloudflare-Challenge-Seite statt echter Daten - Saubere Ergebnisse für die ersten 5 Seiten, danach stille Fehler oder erfundene Zeilen
- Heute perfekte Extraktion, nächste Woche kaputte Selektoren nach einem kleinen Layout-Update
Das sind keine Ausnahmen. Das ist der Normalfall.
Wie ein Praktiker : „Der Scraper liefert einen 200er mit einer Cloudflare-Challenge-Seite, dein Agent versucht, das zu interpretieren, halluziniert – und du hast keine Ahnung warum.“
Das Kernproblem ist architektonisch. Die meisten Demos zeigen die Parsing-Schicht auf sauberen öffentlichen Seiten, während die eigentliche Arbeit in der Fetch-Schicht scheitert. Produktionsseiten bringen Bot-Schutz, dynamisches Rendering, verschachtelte Detailseiten, unendliches Scrollen, Login-Zustände, Locale-Unterschiede und wechselnde Layouts mit.
Ein Tool kann in einer Produktdemo großartig aussehen und trotzdem innerhalb des ersten ernsthaften Kunden-Workflows zusammenbrechen.
Deshalb bewertet dieser Artikel jedes Tool anhand seiner Produktionsreife statt anhand einer Feature-Checkliste. Die sechs Kriterien, die ich verwendet habe:
| Kriterium | Warum es wichtig ist |
|---|---|
| Anti-Bot-/CAPTCHA-Behandlung | Geschützte Websites scheitern, bevor die Extraktionsqualität überhaupt zählt |
| Skalierbarkeit über die Demo hinaus | Batch-Jobs und parallele Läufe offenbaren operative Grenzen |
| Qualität strukturierter Ausgaben | Nutzer brauchen sauberes JSON/CSV, nicht rohes HTML mit manueller Nachbearbeitung |
| Token-/Kosteneffizienz | KI-Extraktion kann teurer werden als das Scraping selbst |
| Unterstützung dynamischer/JS-lastiger Seiten | Moderne Seiten brauchen gerenderte DOMs, nicht statisches HTML |
| No-Code vs. API-Flexibilität | Vertriebsteams und Data Engineers haben unterschiedliche Anforderungen |
Wenn Sie einen schnellen Überblick darüber möchten, wie sich Web Scraping in den letzten zwei Jahren verändert hat, ist dieser Browserless-Talk ein guter Einstieg, bevor Sie die Tools einzeln vergleichen.
Wo KI in einer Scraping-Pipeline wirklich hilft – und wo nicht
Ein hartnäckiger Mythos in diesem Markt ist, dass „KI-Web-Scraper“ bedeutet, KI erledige alles von Anfang bis Ende. Der Konsens in der Community ist erstaunlich klar: . Ein Nutzer brachte es drastisch auf den Punkt: „Sie nutzen KI, um einen Screenshot einer Webseite zu lesen. Sie nutzen KI nicht, um den Scraper selbst zu programmieren.“
Die Scraping-Pipeline besteht aus drei klaren Schichten, und der Nutzen von KI unterscheidet sich dort stark:
Crawling und Fetching: Die Infrastrukturschicht
Hier passieren die Requests: Proxies, Headless-Browser, Sitzungsverwaltung, CAPTCHA-Lösung, Wiederholungsversuche. KI bringt hier fast keinen Nutzen. Sie brauchen weiterhin Proxy-Pools, Browser-Fingerprinting und Unblocking-Infrastruktur. Genau hier scheitern die meisten Tools in der Produktion zuerst.
Parsing und Extraktion: Hier glänzt KI
Sobald Sie sauberen Seiteninhalt haben, ist KI hervorragend darin, unstrukturiertes HTML in strukturierte Felder umzuwandeln. Schema-basierte Extraktion, adaptive Felderkennung und das Abfangen von Layout-Abweichungen ohne fragile XPath-Selektoren sind die Stärken von KI im Scraping.
Nachbearbeitung: Labeln, Übersetzen, Kategorisieren
Nach der Extraktion schafft KI Mehrwert, indem sie Produkte kategorisiert, Texte übersetzt, Telefonnummern normalisiert oder Beschreibungen zusammenfasst. Das passt gut – aber nur, wenn die extrahierten Daten bereits korrekt sind.
So ordnen sich die 12 Tools über diese Schichten hinweg ein:
| Tool | Crawling/Fetching | Parsing/Extraktion | Nachbearbeitung | Beste Beschreibung |
|---|---|---|---|---|
| Thunderbit | Stark | Stark | Stark | No-Code-KI-Scraper mit vollständigem Stack |
| Octoparse | Stark | Mittel | Niedrig | Regelbasierter visueller Scraper mit Cloud-Infrastruktur |
| Browse AI | Mittel | Mittel | Mittel | Cloud-Roboterplattform mit Fokus auf Monitoring |
| Firecrawl | Mittel | Stark | Niedrig-Mittel | Entwickler-API für Extraktion |
| Apify | Stark | Mittel-Stark | Mittel | Actor-Marktplatz und Orchestrierung |
| Gumloop | Mittel | Mittel | Stark | Workflow-Automatisierung mit Scraper-Knoten |
| Bright Data | Sehr stark | Mittel | Niedrig-Mittel | Infrastruktur-Stack für Unternehmen |
| Bardeen | Mittel | Mittel | Stark | Browser-Automatisierung für GTM-Workflows |
| Diffbot | Niedrig-Mittel | Sehr stark | Mittel | Vortrainierte Extraktion plus Knowledge Graph |
| ScrapingBee | Stark | Niedrig-Mittel | Niedrig | Fetching- und Unblocking-API |
| Instant Data Scraper | Niedrig | Mittel (einfache Seiten) | Niedrig | Heuristischer Quick-Scraper im Browser |
| ParseHub | Mittel | Mittel | Niedrig | Visueller Desktop-Scraper für komplexe Interaktionen |
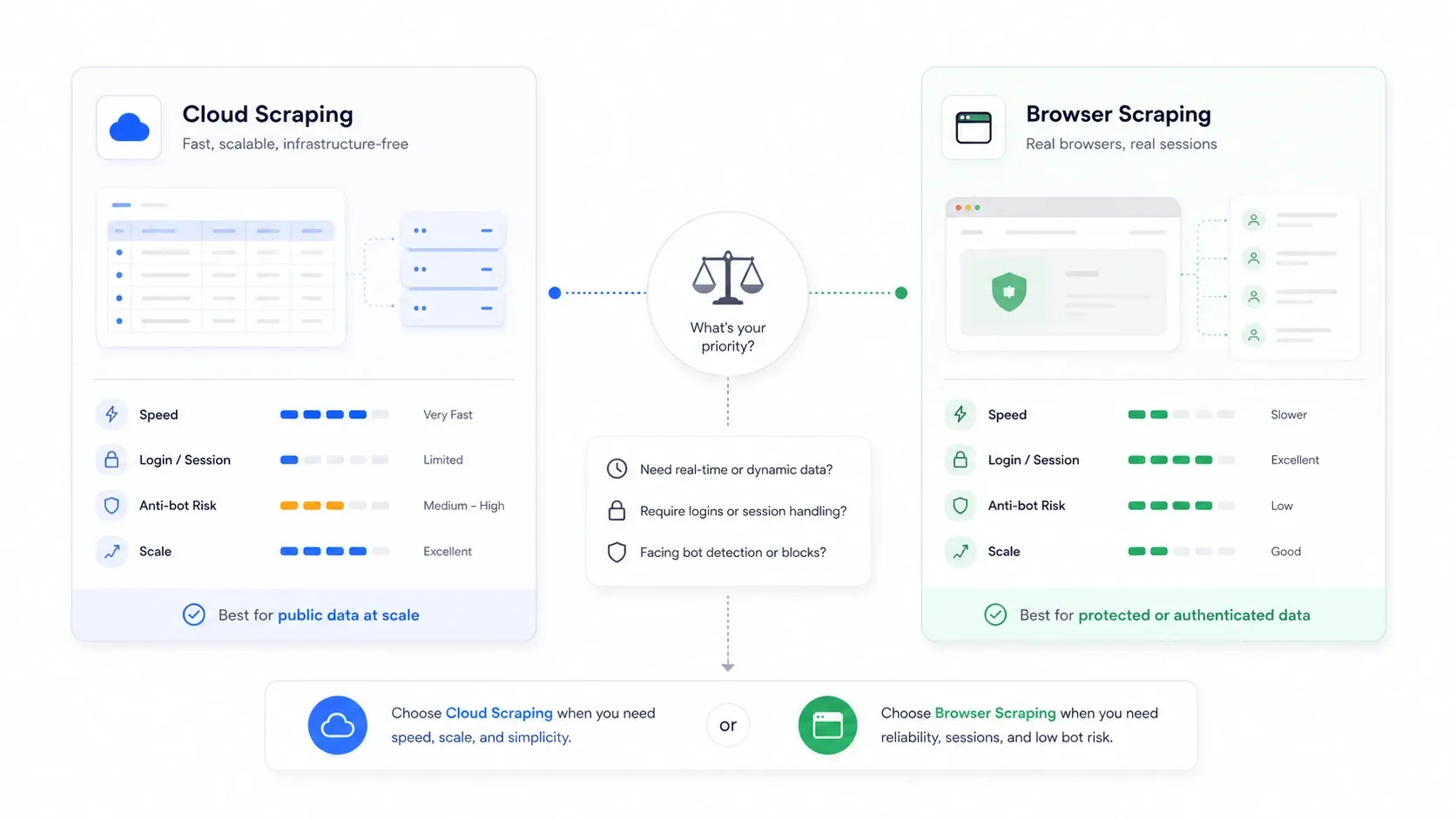
Cloud Scraping vs. Browser Scraping: Die Entscheidung, die niemand erklärt
Das ist die architektonische Entscheidung, die die meisten Übersichtsartikel komplett ignorieren – und sie ist oft wichtiger als die Wahl des konkreten Tools.
Cloud Scraping bedeutet, dass entfernte Server die Seiten in Ihrem Auftrag abrufen. Browser Scraping bedeutet, dass die Extraktion in Ihrer eigenen Browser-Sitzung stattfindet, mit Ihren Cookies, Ihrer IP und Ihrem authentifizierten Zustand.
| Szenario | Besserer Modus | Warum |
|---|---|---|
| Öffentliche E-Commerce- und Listing-Seiten in großer Menge | Cloud | Schnellere Parallelisierung und kein Engpass durch den lokalen Rechner |
| Seiten, die Login oder Authentifizierung erfordern | Browser | Nutzt Ihre echten Sitzungs-Cookies wieder |
| Seiten, die Rechenzentrums-IPs bestrafen | Browser | Wirkt wie normaler Nutzerverkehr |
| Große wiederkehrende Monitoring-Jobs | Cloud | Einfachere Planung und Kontinuität |
| Einmalige, fragile Jobs mit hohem Anti-Bot-Risiko | Browser | Leichter zu prüfen, was die Website tatsächlich gerendert hat |
Auch wirtschaftlich ist das wichtig. Der Apify-Bericht „State of Web Scraping 2026“ zeigt, dass und höhere Infrastrukturkosten meldeten. Anti-Bot ist nicht nur ein technisches Problem. Es ist ein Budgetproblem.
Die meisten Tools bieten nur einen Modus an. Hier ist die Aufschlüsselung:
| Tool | Cloud | Browser | Beides |
|---|---|---|---|
| Thunderbit | ✅ | ✅ | ✅ |
| Octoparse | ✅ | ✅ (lokal) | ✅ |
| Browse AI | ✅ | Nur Einrichtung | — |
| Firecrawl | ✅ | API für interaktive Nutzung | — |
| Apify | ✅ | ✅ (über Actors) | ✅ |
| Gumloop | ✅ | ✅ (Web Agent) | ✅ |
| Bright Data | ✅ | ✅ | ✅ |
| Bardeen | Begrenzt (öffentliche Seiten) | ✅ | Teilweise |
| Diffbot | ✅ | — | — |
| ScrapingBee | ✅ | — | — |
| Instant Data Scraper | — | ✅ | — |
| ParseHub | ✅ (kostenpflichtig) | ✅ (Desktop) | ✅ |
Die 12 KI-Web-Scraper im Überblick
Hier ist der Gesamtvergleich aller 12 Tools:
| Tool | Am besten für | Kostenloser Tarif | Cloud/Browser | API-Zugriff | Geplantes Scraping | Anti-Bot-Behandlung |
|---|---|---|---|---|---|---|
| Thunderbit | Nicht-technische Teams | ✅ (6 Seiten) | Beides | ✅ | ✅ | Stark |
| Octoparse | Template-lastiges Scraping | ✅ (eingeschränkt) | Beides | ✅ | ✅ | Mittel-Stark |
| Browse AI | Veränderungen überwachen | ✅ (eingeschränkt) | Primär Cloud | ✅ | ✅ | Mittel |
| Firecrawl | Entwickler-Pipelines für Extraktion | ✅ (1.000 Credits/Monat) | Cloud plus Browser-API | ✅ | Nein | Mittel |
| Apify | Entwicklerteams plus Marktplatz | ✅ (5 $ Gratisguthaben) | Beides | ✅ | ✅ | Stark mit Add-ons |
| Gumloop | Workflow-Automatisierung | ✅ (5.000 Credits/Monat) | Beides | ✅ | ✅ | Mittel |
| Bright Data | Datenzugriff auf Enterprise-Niveau | Testphase / Credits | Beides | ✅ | Extern | Sehr stark |
| Bardeen | Browser-Automatisierung für Sales und Ops | ✅ (100 Credits) | Browser-first | Eingeschränkt | ✅ | Mittel-Niedrig |
| Diffbot | Strukturierte Extraktions-APIs | ✅ (10.000 Credits) | Cloud | ✅ | Nein | Niedrig beim Fetching / hoch bei Extraktion |
| ScrapingBee | Entwickler-Fetching und Unblocking | ✅ (1.000 Credits) | Cloud | ✅ | Nein | Stark |
| Instant Data Scraper | Kostenlose Einmal-Scrapes | ✅ (komplett kostenlos) | Nur Browser | Nein | Nein | Niedrig |
| ParseHub | Komplexe visuelle Workflows | ✅ (5 Projekte) | Desktop plus Cloud | ✅ | ✅ (kostenpflichtig) | Mittel |
1. Thunderbit
ist der KI-Web-Scraper, den wir speziell für nicht-technische Teams entwickelt haben, die Produktionsdaten ohne Code und ohne Infrastrukturverwaltung benötigen. Der Kernablauf sind tatsächlich nur zwei Klicks: AI Suggest Fields liest die Seite und schlägt Spalten vor, dann führt Scrape die Extraktion im Cloud- oder Browser-Modus aus.
Was Thunderbit von anderen No-Code-Scrapern unterscheidet, ist die Architektur. Thunderbit trennt Crawling-Themen wie Cloud-Infrastruktur, Proxy-Rotation, Anti-Bot-Behandlung und JavaScript-Rendering von der KI-Extraktion, die HTML liest und strukturierte Spalten ausgibt. Das entspricht dem Expertenmuster „zuerst der Scraper, dann das LLM“, ist aber als Chrome-Erweiterungs-Workflow verpackt, den Vertriebs- und Operations-Teams tatsächlich nutzen können.
Wichtigste Stärken
- Cloud- und Browser-Scraping in einer Oberfläche. Wechseln Sie je nach Zielseite zwischen den Modi, ob die Seite öffentlich ist oder Ihre authentifizierte Sitzung benötigt. Der Cloud-Modus verarbeitet bis zu 50 Seiten parallel.
- KI liest die Seitenstruktur jedes Mal neu. Keine Pflege von XPath-Selektoren. Wenn eine Website ihr Layout ändert, passt sich Thunderbit beim nächsten Lauf automatisch an.
- Subpage-Scraping. Die KI besucht verlinkte Detailseiten und reichert die Haupttabelle ohne manuelle Konfiguration an.
- Field AI Prompts. Individuelles Labeln, Übersetzen und Kategorisieren direkt während der Extraktion statt als separater Nachbearbeitungsschritt.
- Kostenlose Exporte nach Google Sheets, Excel, Airtable und Notion.
- Sofortige Scraper-Vorlagen für beliebte Websites wie Amazon, Zillow und LinkedIn.
- Planung in natürlicher Sprache. Sagen Sie einfach „jeden Montag um 9 Uhr scrapen“ und daraus wird ein wiederkehrender Zeitplan.
- Offene API mit Distill- und Extract-Endpunkten, Batch-Verarbeitung von bis zu 100 URLs und veröffentlichter Parallelität von 2 im Free-Tarif bis 50 in Pro 1.
Wo Thunderbit sich noch verbessern könnte
- Der Free-Tarif ist absichtlich klein.
- Für die No-Code-Erfahrung steht die Chrome-Erweiterung im Zentrum. Entwickler, die API-only-Workflows möchten, müssen die Open API separat nutzen.
- Nicht das richtige Tool, wenn Sie primär rohe Proxy-Infrastruktur ohne Extraktion benötigen.
Preise
Kostenloser Tarif verfügbar. No-Code-Pläne starten bei 9 $/Monat bei jährlicher Abrechnung oder 15 $/Monat bei monatlicher Abrechnung für Starter. Die API-Preise sind separat: kostenlos einmalig 600 Einheiten, danach 16 $/Monat jährlich für Starter API und 40 $/Monat jährlich für Pro 1 API. Siehe und .
Am besten für: Vertriebs-, E-Commerce- und Operations-Teams, die strukturierte Webdaten ohne Unterstützung durch Ingenieure brauchen.
2. Octoparse
ist ein visueller Workflow-Builder für Web Scraping mit einer großen Bibliothek vorgefertigter Vorlagen. Das Tool gibt es lange genug, um eine ausgereifte Cloud-Infrastruktur zu haben, und es verarbeitet Paginierung auf strukturierten, vorhersehbaren Websites gut.
Wichtigste Stärken
- Umfangreiche vorgefertigte Scraping-Vorlagen für beliebte Websites
- Cloud-Extraktion mit geplanten Läufen
- IP-Rotation und CAPTCHA-Lösung als kostenpflichtige Add-ons
- API-Zugriff in höheren Tarifen
Wo Octoparse sich noch verbessern könnte
- Die KI-Funktionen sind schwächer als bei LLM-nativen Tools. Feldvorschläge stützen sich stärker auf Vorlagen als auf adaptive Analyse.
- Komplexe oder ungewöhnliche Layouts erfordern im visuellen Editor viel manuelle Feinjustierung.
- Die Lernkurve wird steiler, sobald bedingte Logik oder Anti-Blocking-Workarounds nötig werden.
Preise
Ein dauerhaft kostenloser Plan ist verfügbar. Die offizielle Hilfe-Center-Preisübersicht nennt derzeit Standard ab 75 $/Monat bei jährlicher Abrechnung und Professional ab 208 $/Monat bei jährlicher Abrechnung, während einige lokalisierte Seiten und Upgrade-Pfade höhere monatliche Gegenwerte zeigen. Wichtig ist: Die Preisstruktur von Octoparse kombiniert inzwischen Abos mit kostenpflichtigen Add-ons wie Residential Proxies und CAPTCHA-Lösung.
Am besten für: Analysten und Operations-Teams, die strukturierte, vorlagenfreundliche Websites in mittlerem Umfang scrapen.
3. Browse AI
ist eine cloudbasierte No-Code-Plattform, die in erster Linie für das Monitoring von Website-Änderungen über die Zeit entwickelt wurde – etwa Wettbewerberpreise, Lagerbestände und Inhaltsaktualisierungen. Scraping ist Teil des Produkts, aber der eigentliche Unterschied liegt im wiederkehrenden Monitoring- und Alarmsystem.
Wichtigste Stärken
- Integrierte Änderungs-Erkennung und Benachrichtigungen
- No-Code-Roboter-Recorder mit Point-and-Click-Einrichtung
- Vorgefertigte Roboter für beliebte Websites
- Premium-Proxy-Support in höheren Tarifen
Wo Browse AI sich noch verbessern könnte
- Credit-basierte Preise werden schnell teuer, wenn man Detailseiten in großem Umfang überwacht
- Für groß angelegte Einmal-Extraktionen ist es weniger überzeugend als API-first-Tools
- Mittlere Anti-Bot-Behandlung; manche Websites benötigen trotzdem Premium-Proxies oder Workarounds
Preise
Kostenloses Konto verfügbar. Bezahlte Tarife starten bei etwa 19 $/Monat bei jährlicher Abrechnung für Starter, darüber liegen höhere Credit- und Monitoring-Stufen.
Am besten für: Teams, die laufend Wettbewerberpreise, Inhaltsänderungen oder Lagerbestände überwachen müssen, statt einmalig große Datenmengen zu extrahieren.
4. Firecrawl
ist eine entwicklerorientierte API, die Webseiten in sauberes Markdown oder strukturiertes JSON umwandelt. Sie sitzt vor allem in der Extraktionsschicht und ist hervorragend für Teams geeignet, die RAG-Pipelines bauen oder Webinhalte in LLMs einspeisen.
Wichtigste Stärken
- Sehr gute Markdown-Ausgabequalität für nachgelagerte LLM-Workflows
- Saubere API mit Scrape-, Crawl-, Map-, Search-, Extract- und Browser-Aktionen
- Unterstützung für Batch-Verarbeitung
- Parallelität von 2 im Free-Tarif bis 100 im Growth-Tarif
Wo Firecrawl sich noch verbessern könnte
- Keine No-Code-Oberfläche; Entwicklerkenntnisse sind erforderlich
- Eingebaute Proxy- und Anti-Bot-Hilfe existiert, aber Firecrawl ist nicht als dedizierter Unblocking-Anbieter positioniert
- Kein eigener Scheduler für wiederkehrende Jobs
- Für Nicht-Entwickler, die einfach eine Datentabelle wollen, nicht kosteneffizient
Preise
Der kostenlose Plan umfasst 1.000 Credits pro Monat. Bezahlte Pläne starten bei 16 $/Monat jährlich für Hobby und skalieren mit mehr Credits, Parallelität und Browser-Nutzung. Browsersitzungen werden separat in Credits abgerechnet.
Am besten für: Entwickler, die LLM-Pipelines, RAG-Systeme oder benutzerdefinierte Extraktions-Workflows bauen und sauberes Markdown oder JSON aus Webseiten benötigen.
5. Apify
ist eine Plattform mit einem Marktplatz vorgefertigter Scraping-Actors sowie Werkzeugen zum Erstellen eigener. Man kann es als Orchestrierungsschicht verstehen: Sie wählen oder bauen spezialisierte Scraper für bestimmte Websites und planen und verwalten sie dann über eine einheitliche API.
Wichtigste Stärken
- Riesiger Actor-Marktplatz mit Community-Scrapern für Hunderte von Websites
- Starke API und SDK für Entwickler
- Integrierte Proxy-Verwaltung und Planung
- Lässt sich mit vielen nachgelagerten Tools verbinden
Wo Apify sich noch verbessern könnte
- „No-Code“ ist nur teilweise zutreffend, sobald man den Marktplatz verlässt und eigene Logik benötigt
- Die Zuverlässigkeit der Actors hängt von der Pflege durch die Community ab
- Die Kosten können steigen, weil Rechenleistung, Actor-Kosten und Proxies zusammenkommen
Preise
Der Free-Tarif enthält 5 $ monatliches Plattformguthaben. Bezahlte Pläne starten bei 39 $/Monat für Starter, darüber folgen auf Skalierung ausgelegte Tarife.
Am besten für: Entwicklerteams, die wiederverwendbare, planbare Scraping-Workflows mit einem großen Ökosystem vorgefertigter Lösungen möchten.
6. Gumloop
ist eine No-Code-Workflow-Automatisierungsplattform mit einem Web-Scraping-Knoten. Der eigentliche Wert liegt nicht im Scraping allein, sondern darin, Extraktion mit LLMs, Google Sheets, CRMs und anderen Tools auf einer visuellen Arbeitsfläche zu verbinden.
Wichtigste Stärken
- Visueller Drag-and-Drop-Workflow-Builder
- Verbindet Scraping mit LLMs und nachgelagerten Business-Tools in einem Ablauf
- Der kostenlose Plan wird derzeit mit 5.000 Credits/Monat beworben
- Zeitbasierte Planung für wiederkehrende Workflows
- Basis-Scraping und interaktiver Web Agent decken sowohl einfache als auch komplexere Abläufe ab
Wo Gumloop sich noch verbessern könnte
- Die Scraping-Engine ist weniger robust als dedizierte KI-Web-Scraper-Tools
- Begrenzte Tiefe bei Anti-Bot- und Proxy-Funktionen im Vergleich zu Spezialanbietern
- Parallelität und Trigger-Limits sind in Free-Plänen enger
- Nicht ideal für groß angelegtes Scraping mit hohem Volumen als Hauptanwendungsfall
Preise
Kostenloser Plan verfügbar. Gumloop hat seine frühere Solo- und Team-Struktur Ende 2025 in einen Pro-Plan überführt, und die öffentliche Kommunikation seitdem konzentriert sich stärker auf großzügigere Gratis-Credits plus konsolidierte Bezahlstufen statt auf Scraper-first-Preise.
Am besten für: Teams, die Scraping als einen Schritt in einem größeren automatisierten Workflow wollen: scrapen, analysieren und in Business-Tools übertragen.
Wenn Sie sehen möchten, wie sich ein KI-nativer Extraktions-Workflow in der Praxis anfühlt, bevor Sie den Rest der Liste lesen, ist diese Thunderbit-Anleitung die relevanteste Produktdemo für nicht-technische Teams.
7. Bright Data
ist der Infrastruktur-Stack auf Enterprise-Niveau in dieser Liste. Wenn Ihr Problem lautet: „Ich komme bei diesem Website-Bot-Schutz einfach nicht durch“, ist Bright Data wahrscheinlich die Antwort – allerdings mit entsprechender Enterprise-Komplexität und Preisgestaltung.
Wichtigste Stärken
- Branchenführendes Proxy-Netzwerk über Residential-, Rechenzentrums- und Mobile-IPs
- Web Unlocker zum Umgehen von Anti-Bot-Schutz und CAPTCHAs
- Scraping Browser mit integriertem Unblocking
- Vorgefertigte Datensätze käuflich verfügbar
- Vollständige programmatische Kontrolle per API und SDK
Wo Bright Data sich noch verbessern könnte
- Nicht für nicht-technische Nutzer konzipiert
- Die Preise spiegeln die Enterprise-Positionierung wider
- KI-Extraktion ist nicht der Hauptgrund, die Plattform zu kaufen
Preise
Die Browser API startet bei 8 $/GB Pay-as-you-go, mit niedrigeren GB-Preisen bei größeren monatlichen Commitments. Andere Bright-Data-Produkte wie Unlocker, Scraper APIs, Datensätze und Proxy-Pools nutzen unterschiedliche Preislogiken.
Am besten für: Enterprise-Datenteams, die stark geschützte Websites in großem Umfang scrapen müssen und das technische Personal haben, um die Infrastruktur zu verwalten.
8. Bardeen
ist ein Browser-Automatisierungstool für Klicks, Formularausfüllungen und Scraping, dem eine KI-gestützte Datenextraktion überlagert ist. Am besten versteht man es als GTM-Workflow-Tool, das zufällig auch scrapen kann – nicht als Scraping-Tool, das auch GTM macht.
Wichtigste Stärken
- Intuitive Playbook-ähnliche Automatisierung, bei der Scraping nur ein Schritt ist
- Offizielle Scraper, die vom Bardeen-Team für beliebte Websites gepflegt werden
- Starke Integrationen mit CRM, Google Sheets, Slack und anderen Business-Tools
- Gut für Lead-Scraping, Enrichment und CRM-Export-Workflows
Wo Bardeen sich noch verbessern könnte
- Browser-first-Architektur begrenzt unbeaufsichtigtes Scraping mit hohem Volumen
- Cloud Scraping funktioniert nur auf öffentlichen Seiten, nicht auf geschützten
- Die Anti-Bot-Behandlung entspricht im Wesentlichen dem, was Ihre Browser-Sitzung ohnehin bietet
- KI-Extraktion kann bei komplexen oder unüblichen Seitenlayouts Probleme haben
Preise
Der kostenlose Plan enthält 100 monatliche Credits. In der öffentlichen Support-Dokumentation wird noch der alte 15 $/Monat-Pro-Preis für bestehende Nutzer erwähnt, während die aktuelle kommerzielle Verpackung von Bardeen eher auf Enterprise und Workflows als auf klassische Low-End-Scraper-Preise ausgerichtet ist.
Am besten für: Sales- und Ops-Teams, die Scraping als Teil eines größeren Browser-Automatisierungs-Workflows brauchen.
9. Diffbot
nutzt Computer Vision und NLP, um Webseiten wie ein Mensch zu lesen, und gibt strukturierte Daten für Artikel, Produkte, Diskussionen und Organisationen aus. Es ist eine der hochwertigsten Extraktions-APIs auf dem Markt, wenn Ihre Seiten zu den vortrainierten Modellen passen.
Wichtigste Stärken
- Vortrainierte Extraktionsmodelle für Artikel, Produkte, Diskussionen und mehr
- Knowledge Graph mit Milliarden von Entitäten für Data Enrichment
- Sehr hohe Qualität strukturierter Ausgaben bei unterstützten Seitentypen
- Klare Entwickler-API mit veröffentlichten Rate Limits
Wo Diffbot sich noch verbessern könnte
- Keine No-Code-Oberfläche
- Kein eingebautes Crawling, keine Proxy-Verwaltung und keine Anti-Bot-Behandlung
- Für kleine Teams teuer
- Bei unüblichen Seitentypen weniger flexibel als schema-basierte Prompt-Extraktoren
Preise
Der kostenlose Plan enthält 10.000 Credits. Startup kostet 299 $/Monat für 250.000 Credits, und Plus kostet 899 $/Monat für 1.000.000 Credits.
Am besten für: Entwicklerteams, die hochgenaue strukturierte Extraktion aus Standard-Seitentypen brauchen und das Fetching separat handhaben können.
10. ScrapingBee
ist eine Web-Scraping-API, die sich auf die Fetching- und Unblocking-Schicht konzentriert. Sie schicken eine URL, das Tool übernimmt Proxies, Rendering mit Headless-Browser und Anti-Bot-Abwehr, und es gibt HTML oder optional extrahierte Daten zurück.
Wichtigste Stärken
- Integrierte Proxy-Rotation und Anti-Bot-Behandlung
- Unterstützung für JavaScript-Rendering
- Einfache REST-API
- Google-Search-Scraping-Endpunkt
- Veröffentlichte Parallelität je nach Plan
Wo ScrapingBee sich noch verbessern könnte
- KI-Extraktionsfunktionen sind begrenzt
- Keine No-Code-Oberfläche
- Kein integriertes Scheduling oder Monitoring
- Eine
200-Antwort mit einer Blockier-Seite kann trotzdem als erfolgreicher Request zählen
Preise
Der kostenlose Plan enthält 1.000 API-Credits. Bezahlte Pläne starten bei 49 $/Monat und skalieren mit höherer Parallelität und Request-Volumen.
Am besten für: Entwickler, die vor allem zuverlässiges Seiten-Fetching trotz Anti-Bot-Schutz brauchen und die Extraktion mit eigenem Code oder einem separaten Tool erledigen.
11. Instant Data Scraper
ist eine kostenlose Chrome-Erweiterung mit über 1.000.000 Nutzern, die automatisch Datenmuster auf einer Seite erkennt und den Export nach CSV oder Excel ermöglicht. Es gibt keine KI-Feldvorschläge im LLM-Sinn. Stattdessen wird heuristische Mustererkennung verwendet.
Wichtigste Stärken
- Komplett kostenlos, kein Konto erforderlich
- Erkennung von Daten mit einem Klick auf vielen Listen- und Tabellen-Seiten
- Verarbeitet auf einigen Websites Paginierung
- Extrem niedrige Einstiegshürde
- Wird weiterhin gepflegt, mit Chrome-Web-Store-Updates im Jahr 2026
Wo Instant Data Scraper sich noch verbessern könnte
- Keine KI-gestützten Feldvorschläge oder Datenlabeling
- Kein Cloud Scraping, kein Scheduling, keine API
- Schwierigkeiten mit komplexen Layouts, dynamischen Inhalten und JS-lastigen Seiten
- Keine Anti-Bot-Behandlung über das hinaus, was Ihr Browser ohnehin laden kann
- Export nur nach CSV und Excel
Preise
Kostenlos. Für immer.
Am besten für: Alle, die einen schnellen, einmaligen Scrape einer einfachen Listing-Seite brauchen und weder ein Konto anlegen noch etwas bezahlen möchten.
12. ParseHub
ist eine Desktop-Anwendung mit visueller Point-and-Click-Oberfläche zum Erstellen von Scraping-Projekten. Sie kann komplexe verschachtelte Daten, per AJAX geladene Inhalte, unendliches Scrollen und Dropdown-Interaktionen verarbeiten, die einfachere Erweiterungen oft verpassen.
Wichtigste Stärken
- Visuelle Selektor-Oberfläche zum Definieren von Extraktionsregeln
- Verarbeitet verschachtelte Daten, Dropdowns, unendliches Scrollen und AJAX-Inhalte
- Kostenloser Tarif mit bis zu 5 Projekten
- Export nach JSON, CSV und Excel
- Cloud-Scheduling und IP-Rotation in Bezahlplänen
Wo ParseHub sich noch verbessern könnte
- Nur Desktop-Workflow, keine bequeme Browser-Erweiterung
- Langsamere Ausführung als cloud-native Tools
- Projekte brechen, wenn sich Website-Layouts ändern, weil es keine KI-Neuleseschicht gibt
- Begrenzte KI-Funktionen und eher ein klassisches visuelles Scraper-Gefühl
Preise
Kostenloser Plan mit 5 Projekten und 200 Seiten pro Lauf verfügbar. Bezahlte Pläne starten bei 189 $/Monat mit Scheduling, IP-Rotation und höheren Limits.
Am besten für: Nicht-technische Nutzer, die komplexe interaktive Websites scrapen müssen und bereit sind, Zeit in die visuelle Workflow-Einrichtung zu investieren.
So starten Sie in 5 Schritten mit einem KI-Web-Scraper
Jedes Tool auf dieser Liste hat einen anderen Onboarding-Ablauf. Ich verwende Thunderbit als konkretes Beispiel, weil es die Suchintention „Ich brauche einfach, dass das auf einer echten Seite funktioniert“ am besten trifft.
Schritt 1: Installieren und zur Seite navigieren
Installieren Sie die und öffnen Sie die Seite, die Sie scrapen möchten: eine Produktliste, ein Verzeichnis oder ein Immobilienportal.
Schritt 2: Lassen Sie KI Ihre Datenfelder vorschlagen
Klicken Sie auf AI Suggest Fields. Die KI liest die aktuelle Seite und schlägt Spaltennamen sowie Datentypen vor. Auf einer Produktseite könnte sie Produktname, Preis, Bewertung, Bild-URL und Beschreibung vorschlagen.
Schritt 3: Felder mit KI-Prompts anpassen
Passen Sie die Spalten an, wenn die Standardwerte nicht ganz passen. Fügen Sie Field AI Prompts für benutzerdefinierte Transformationen hinzu, etwa „Beschreibung ins Spanische übersetzen“, „als Elektronik, Haushalt oder Mode kategorisieren“ oder „nur den numerischen Preis extrahieren“.
Schritt 4: Cloud- oder Browser-Modus wählen und scrapen
Wählen Sie Cloud Scraping für öffentliche Seiten oder Browser Scraping für authentifizierte oder stark geschützte Ziele. Klicken Sie dann auf Scrape.
Schritt 5: Exportieren Sie Ihre Daten überallhin
Exportieren Sie die Ergebnisse nach Google Sheets, Excel, Airtable oder Notion. Exporte sind kostenlos.
Was passiert, wenn sich das Seitenlayout ändert?
Das ist der entscheidende Produktionsvorteil KI-nativer Extraktoren gegenüber regelbasierten Tools. Traditionelle Scraper wie ParseHub und ältere Octoparse-Workflows verlassen sich auf XPath-Selektoren oder CSS-Pfade. Wenn eine Website ihre HTML-Struktur aktualisiert, brechen diese Selektoren und Sie müssen manuell neu konfigurieren.
KI-gestützte Extraktoren wie Thunderbit lesen die Seitenstruktur jedes Mal neu. Das bedeutet keine XPath-Pflege und keine fragilen Selektoren. Die KI passt sich beim nächsten Lauf automatisch an Layout-Änderungen an.
Geplantes Scraping und API-Zugriff: Die Power-User-Funktionen, über die niemand spricht
Einmalige Scrapes reichen für Recherche. Produktionsfälle wie Preisüberwachung, Aktualisierung von Lead-Listen und Bestandsverfolgung brauchen wiederkehrende Extraktion und programmatischen Zugriff. Diese Funktionen trennen Spielzeuge von echten Tools.
Unterstützung für Scheduling
| Tool | Natives Scheduling | Hinweise |
|---|---|---|
| Thunderbit | ✅ | Einrichtung in natürlicher Sprache |
| Octoparse | ✅ | Geplante Cloud-Läufe |
| Browse AI | ✅ | Kernfunktion des Produkts |
| Firecrawl | ❌ | Externen Cron verwenden |
| Apify | ✅ | Vollständige Cron-Ausdrücke |
| Gumloop | ✅ | Zeitbasierte Workflow-Trigger |
| Bright Data | Extern | Meist über Kundensysteme orchestriert |
| Bardeen | ✅ | Playbook-Scheduling |
| Diffbot | ❌ | API-first, externe Orchestrierung |
| ScrapingBee | ❌ | Nur API |
| Instant Data Scraper | ❌ | Manuelles Browser-Tool |
| ParseHub | ✅ (kostenpflichtig) | Premium-Funktion |
Vergleich der Entwickler-APIs
| Tool | Parallelität oder Rate-Hinweis | Preismodell |
|---|---|---|
| Thunderbit | 2 → 50 parallel | Credit-basiert |
| Firecrawl | 2 → 100 parallel | Credit-basiert |
| Apify | Abhängig vom Plan | Compute Units |
| Gumloop | Planbegrenzte Workflow-Parallelität | Credit-basiert |
| Diffbot | 5 Aufrufe/Min. → 25 Aufrufe/Sek. | Credit-basiert |
| ScrapingBee | 10 → 200 parallel | API-Credit-basiert |
| Bright Data | Die Browser API wirbt mit unbegrenzten parallelen Requests | GB-basiert |
Wenn Ihr Anwendungsfall technischer ist und Sie entscheiden wollen, wie viel Infrastruktur Sie selbst betreiben möchten, ist dieses Firecrawl-Video eine nützliche, umsetzungsorientierte Ergänzung zu den Produktvergleichen oben.
So wählen Sie den richtigen KI-Web-Scraper
Nach dem Test aller 12 Tools würde ich so entscheiden:
- Nicht-technisches Team, das schnell Daten braucht: Starten Sie mit Thunderbit. Der Zwei-Klick-Workflow, kostenlose Exporte und der Wechsel zwischen Browser und Cloud decken die meisten Business-Scraping-Anforderungen ohne Engineering-Unterstützung ab.
- Laufendes Monitoring und Alarme nötig: Browse AI ist genau dafür gemacht. Es ist nicht der stärkste Einmal-Extraktor, aber die Änderungs-Erkennung ist eine Kernfunktion.
- Entwickler, der eine LLM-Pipeline baut: Firecrawl für Markdown- oder JSON-Extraktion, oder Diffbot für vortrainierte strukturierte Extraktion. Kombinieren Sie eines davon mit ScrapingBee oder Bright Data, wenn Sie auf der Fetch-Schicht ernsthafte Anti-Bot-Behandlung brauchen.
- Sie wollen einen Marktplatz vorgefertigter Scraper: Apify hat das größte Actor-Ökosystem. Seien Sie nur darauf vorbereitet, Wartungsaufwand zu haben, wenn Actors ausfallen.
- Enterprise-Scale, stark geschützte Ziele: Bright Data. Nichts anderes erreicht die Proxy-Infrastruktur auf diesem Niveau, aber Budget und technisches Personal müssen entsprechend vorhanden sein.
- Scraping als Teil einer größeren Automatisierung: Gumloop oder Bardeen – je nachdem, ob Sie Workflows oder browserbasierte GTM-Aufgaben automatisieren.
- Sie brauchen nur schnell einen kostenlosen Scrape: Instant Data Scraper. Kein Setup, keine Kosten, keine Komplexität – aber auch kein Scheduling, keine KI und keine Cloud.
- Komplexe interaktive Websites mit Dropdowns und AJAX: ParseHub verarbeitet diese immer noch besser als die meisten Erweiterungen, auch wenn der Wartungsaufwand real ist.
Fazit
Der Markt für KI-Web-Scraper ist 2026 voll mit Tools, die in Demos beeindruckend wirken und in der Produktion enttäuschen. Die Lücke zwischen „funktioniert auf einem Marketing-Screenshot“ und „funktioniert auf einer geschützten E-Commerce-Seite um 3 Uhr morgens nach Zeitplan“ ist genau der Punkt, an dem die meisten Käufer Zeit und Geld verlieren.
Die wichtigste Erkenntnis aus der Bewertung aller 12 Tools ist einfach: Die Fetch-Schicht bleibt der schwierige Teil. KI ist stark bei Extraktion und Nachbearbeitung, ersetzt aber keine Proxy-Infrastruktur, keine Anti-Bot-Behandlung und kein Sitzungsmanagement. Die besten Tools lösen entweder beide Schichten, wie Thunderbit und Bright Data, oder sagen ehrlich, welche Schicht sie abdecken, wie Firecrawl für Extraktion und ScrapingBee für Fetching.
Wenn Sie sehen möchten, wie ein produktionsreifer KI-Web-Scraper ohne Code aussieht, . Der kostenlose Tarif reicht aus, um den gesamten Workflow auf echten Seiten zu testen. Wenn Ihre Anforderungen eher entwicklerorientiert sind, kombinieren Sie eine Extraktions-API mit einem spezialisierten Fetching-Dienst und ersparen Sie sich die Frustration, von einem einzigen Tool alles zu erwarten.
FAQs
Warum scheitern die meisten KI-Web-Scraper auf echten Websites, obwohl sie in Demos gut funktionieren?
Demos zeigen typischerweise Extraktion auf sauberen, ungeschützten Seiten. Echte Websites bringen Cloudflare-Schutz, dynamisches JavaScript-Rendering, Paginierung, Login-Anforderungen und häufig wechselnde Layouts mit. Die meisten Tools beherrschen die Parsing- und Extraktionsschicht gut, aber es fehlt ihnen eine robuste Infrastruktur für die Fetch-Schicht.
Was ist der Unterschied zwischen Cloud Scraping und Browser Scraping, und wann sollte ich was nutzen?
Cloud Scraping nutzt entfernte Server zum Abrufen der Seiten. Das ist schneller, parallelisierbarer und skalierbarer. Browser Scraping läuft in Ihrer eigenen Browser-Sitzung und ist besser für authentifizierte Seiten oder Seiten mit aggressiver Bot-Erkennung. Thunderbit ist eines der wenigen Tools, das beide Modi in derselben Oberfläche anbietet.
Kann ich einen KI-Web-Scraper für wiederkehrende Aufgaben wie Preisüberwachung verwenden?
Ja, aber nur, wenn das Tool geplantes Scraping unterstützt. Thunderbit, Octoparse, Browse AI, Apify, Gumloop, Bardeen und ParseHub in kostenpflichtigen Plänen bieten Scheduling an.
Welcher KI-Web-Scraper ist am besten, wenn ich keine Programmierkenntnisse habe?
Thunderbit bietet für nicht-technische Nutzer den schnellsten Weg zu brauchbaren Daten. Instant Data Scraper ist komplett kostenlos, aber auf einfache Seiten beschränkt. Browse AI und Octoparse bieten visuelle Oberflächen mit mehr Einrichtung. ParseHub ist leistungsstark für komplexe interaktive Websites, hat aber eine steilere Lernkurve.
Wie viel kostet KI-Web-Scraping auf Produktionsniveau wirklich?
Die Spanne ist groß. Instant Data Scraper ist kostenlos. Thunderbit, Firecrawl und Browse AI bieten kostenlose Einstiege mit günstigen Bezahlplänen. Mittelklasse-Tools wie Octoparse, ParseHub und ScrapingBee liegen etwa zwischen 49 und 189 $ pro Monat. Enterprise-Lösungen wie Bright Data und Diffbot starten deutlich höher.