Zusammenfassung für Führungskräfte
Wir haben die robots.txt-Datei jeder Domain aus der Tranco-Top-10.000-Liste der weltweit meistbesuchten Websites abgerufen. Danach haben wir jede Datei mit einem RFC-9309-konformen Parser ausgewertet, die jeweiligen KI-Bot-Richtlinien der Site klassifiziert und gezählt, wie viele der weltweit meistbesuchten Seiten ChatGPT, Claude, Perplexity, Gemini, Common Crawl, Bytespider, Apple Intelligence und andere Crawler, die große Sprachmodelle trainieren und bedienen, im Jahr 2026 tatsächlich blockieren.
Die Kernergebnisse auf Basis von 7.248 Sites, deren robots.txt wir sauber lesen konnten:
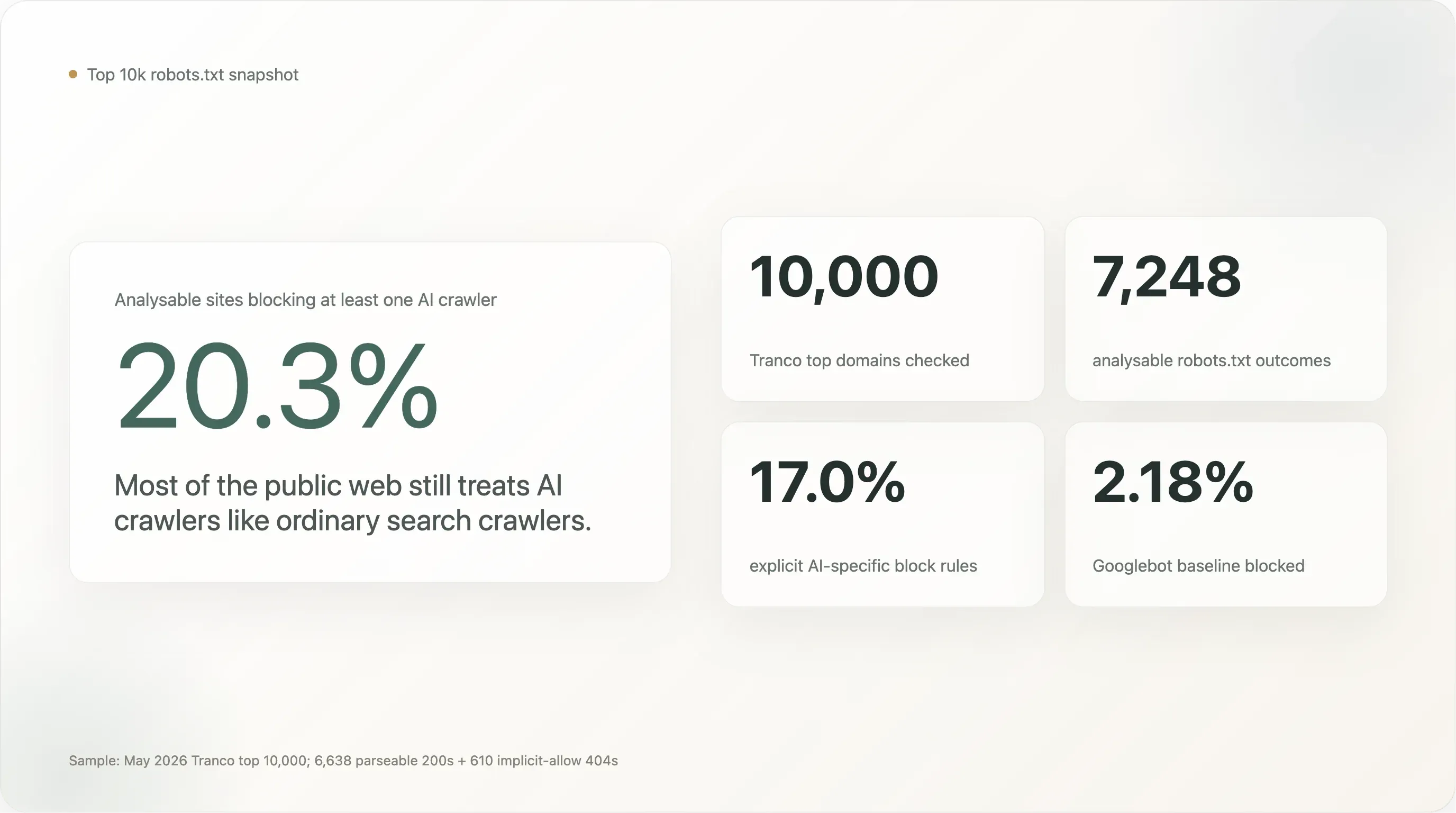
20,3 % der weltweiten Top-10.000-Sites blockieren mindestens einen KI-Crawler. 17,0 % haben absichtlich eine explizite, KI-spezifische Regel formuliert. Die übrigen 80 % lassen KI-Crawler so willkommen wie Googlebot.
Sechs Erkenntnisse, die das Bild verändern:
- Nachrichtenorganisationen liegen bei 47 % Blockierung — der höchste Wert aller Sektoren. Deutsche News-Sites führen mit 88 %, französische mit 80 %, russische mit 0 %. Ausschlaggebend ist vor allem das Rechtsregime, nicht Technologie oder Branchenökonomie.
CCBot(Common Crawl) ist mit 16,3 % der am häufigsten blockierte Bot — vorGPTBot(15,8 %) undBytespider(14,9 %). Verlage zielen auf den Trainingskorpus, nicht auf die Modellmarke. Die am weitesten verbreitete selektive Regel lautet „CCBotblockieren,Googleboterlauben“ (14,1 % der Sites).- Frankreich führt alle Länder mit 50,6 % KI-Blocking auf
.fr-Sites an; der EU-Cluster liegt 16 Punkte über dem globalen Ausgangswert. 275robots.txt-Dateien verweisen ausdrücklich auf die EU-Richtlinie 2019/790. Artikel 4 ist das einzige Rechtsregime, das die Zahlen sichtbar bewegt. - 17,8 % haben ihre eigenen KI-Regeln geschrieben; 4,5 % laufen mit Cloudflares Anbieter-Vorlage; 75,7 % sagen nichts. Große Sites schreiben selbst; der Long Tail nutzt den Schalter. The Atlantic und
cloudflare.comselbst stehen auf der von Cloudflare verwalteten Liste. - 108 Sites erlauben
GPTBotausdrücklich — WordPress.org, Kaspersky, Norton, Avast, Sophos, The Verge, The Atlantic, NBA.com, The Sun, Branch.io. Sicherheits- und Dev-Tools sind überproportional vertreten. - Die KI-Politik wird an der Spitze der Kurve nicht aggressiver. Top 100, 101–1000, 1001–5000, 5001–10000 liegen alle zwischen 19 % und 23 %. Die Gesamtquote ist eine Eigenschaft des öffentlichen Webs im Jahr 2026, kein Signal dafür, wie groß eine einzelne Site ist.
Die Frage ist also nicht mehr, ob das Web „zurückschlägt“. Entscheidend ist, welche Branchen, welche Länder, welche Rechtsregime und welche KI-Anbieter Ziel aktiver Richtlinien sind — und welche nicht.
I. Hintergrund: Wie robots.txt zu einem KI-Politikartefakt wurde
Drei Kräfte haben die Bedeutung von robots.txt seit dem Start von OpenAIs GPTBot im August 2023 neu geprägt.
KI-Anbieter wurden zahlreicher. Googles Google-Extended, Anthropics ClaudeBot, ByteDances Bytespider, Apples Applebot-Extended, Amazons Amazonbot, Metas Meta-ExternalAgent kamen hinzu. Der bereits existierende CCBot von Common Crawl wurde zum Bot mit der höchsten Hebelwirkung, weil sein Archiv die meisten Open-Weight-Modelle speist. Auch Bots ohne Anbieterbezug tauchten auf: AI2Bot, cohere-ai, PerplexityBot, YouBot, DuckAssistBot, Diffbot, Omgili. Eine umfassende Blockliste für 2026 umfasst rund 25 Namen.
Artikel 4 der EU-Urheberrechtsrichtlinie 2019/790 schuf eine gesetzliche Ausnahme für Text- und Data-Mining, die nicht greift, wenn Rechteinhaber ihre Rechte in einer „maschinenlesbaren“ Form ausdrücklich vorbehalten. 2024–2025 einigten sich EU-Verlage und ihre Anwälte weitgehend auf robots.txt als kanonischen Weg, diesen Vorbehalt zu erklären. Unser Datensatz zeigt 275 Sites mit explizitem Verweis auf Richtlinie 2019/790 und 87 mit Erwähnung von „TDM“ — konzentriert auf europäische News-Sites, wo das meist als 4–8-zeiliger rechtlicher Vorspann steht.
Cloudflare hat den Schalter produktisiert. 2024–2025 führte Cloudflare ein Dashboard für „AI Audit“, einen Schalter „Block AI Bots“ und eine verwaltete robots.txt-Vorlage mit der Formulierung Content-Signal: search=yes,ai-train=no sowie Boilerplate zu EU 2019/790 ein. Bis Mai 2026 läuft diese Vorlage auf 4,5 % der auslesbaren Top-10k. Cloudflare diskutiert öffentlich, den Schalter für neue Konten standardmäßig zu aktivieren — das würde die globale Blockrate um 5–8 Punkte verschieben, ohne dass ein einzelner Publisher bewusst entscheidet.
robots.txt ist 2026 nicht mehr die unscheinbare Konfigurationsdatei von 2022. Sie ist ein Mechanismus zum Vorbehalt von Urheberrechten mit EU-rechtlicher Rückendeckung, ein vom Anbieter geprägtes Politikartefakt im Long Tail und die Frontlinie einer langsamen Verhandlung zwischen den Betreibern von Websites und den Betreibern von Modellen.
II. Methodik
Wir haben versucht, das Ganze so langweilig und reproduzierbar wie möglich zu machen. Die komplette Pipeline (Python-Skripte, geparste CSVs, Roharchiv der robots.txt, Diagramme) wird mit diesem Bericht veröffentlicht.
Stichprobe
Wir sind von der Tranco-Liste vom Mai 2026 ausgegangen, heruntergeladen als top-1m.csv.zip, und haben die ersten 10.000 Zeilen verwendet. Tranco aggregiert vier Upstream-Rankings (Cisco Umbrella, Majestic, Farsight und Cloudflare Radar), filtert Stabilität über ein 30-Tage-Fenster und entfernt offensichtliches Crawler-/CDN-Rauschen. Die Liste ist das, was einer kanonischen „globalen Web-Traffic-Top-10k“ am nächsten kommt, und sie ist der Standard-Sample für akademische Webforschung (seit dem Start durch KU Leuven 2018 in mehr als 600 begutachteten Arbeiten verwendet).
Die Liste enthält eine Mischung aus (a) primären Websites, die Menschen besuchen, (b) Infrastruktur-/API-/DNS-/CDN-Apex-Domains ohne /, und (c) Domains, die intern von großen Plattformen genutzt werden (z. B. gvt1.com, apple-dns.net, googleusercontent.com). Statt diese vorzufiltern, haben wir alle beibehalten und sie in der Analyse als Kategorie infrastructure markiert. Sie fallen von selbst heraus, wenn wir auf „Sites beschränken, die eine auswertbare robots.txt zurückgegeben haben“.
Abruf
Für jede der 10.000 Domains haben wir einen asynchronen GET /robots.txt über HTTPS ausgeführt, mit Fallback auf HTTP, Weiterleitungen über bis zu vier Hops, einem Gesamt-Timeout von 12 Sekunden, einer Body-Obergrenze von 500 KB und einem echten Browser-User-Agent-String mit Accept-Language: en-US. Die Parallelität wurde auf 80 Anfragen gleichzeitig begrenzt. Der Lauf erfolgte von einer einzelnen Residential IP in San Francisco.
Das Abruf-Ergebnis:
| Status | Anzahl | Interpretation |
|---|---|---|
200 OK | 6.638 | robots.txt-Inhalt zurückgegeben und auswertbar. |
404 Not Found | 610 | Keine robots.txt vorhanden. RFC 9309 definiert das als implizites „alles erlauben“. |
403 Forbidden | 563 | Ursprungsserver weist robots.txt-Anfragen aktiv zurück. Aus der Analyse ausgeschlossen. |
429 Too Many Requests | 7 | Kaum CDN-basiertes Throttling in dieser Ranking-Stufe. |
fetch_failed (TLS-/DNS-/TCP-Fehler) | 2.065 | Meist CDN-Apex-Domains (akamai.net, cloudfront.net, fastly.net, gtld-servers.net, apple-dns.net), die unter / keinen Webserver betreiben. Nicht „blockiert“ — sie haben schlicht keine robots.txt auszuliefern. |
| Sonstige 4xx/5xx | 117 | Gemischt — Serverfehler, Geofencing, fehlerhafte Antworten. |
Damit haben wir 7.248 Sites in der analysierbaren Stichprobe (6.638 200 + 610 404). Die 2.065 fetch_failed sind echte Domains, aber CDN-/DNS-Apex-Punkte, keine Websites im eigentlichen Sinn; sie als „KI-Richtlinie“ zu behandeln, wäre unsinnig. Sie bleiben als separate Zugänglichkeitsstatistik im Datensatz.
Parsing
Jeder 200-Body wurde mit protego geparst, einer Python-Implementierung von RFC 9309, die produktiv in Scrapy verwendet wird. Für jedes (Site-, Bot-)Paar haben wir drei Dinge berechnet:
can_fetch_root— ob der Bot/abrufen darf, mit der Semantik des Standards für Regelgruppen, der Priorität der längsten Übereinstimmung und der Überschreibung vonUser-agent: *durch einen spezifischen Bot-Block, wenn beide existieren.has_specific_rule— ob die Datei eineUser-agent:-Zeile enthält, die genau diesen Bot nennt (ohne Beachtung der Groß-/Kleinschreibung).disallow_count— wie vieleDisallow:-Anweisungen im passenden Block stehen; das dient dazu, vollständige Sperren der gesamten Site von Pfad-Einschränkungen zu unterscheiden.
Die Kombination ist wichtig, weil eine reine „Blockrate“ zwei völlig verschiedene Phänomene verschleiert: Marken, die absichtlich User-agent: GPTBot \n Disallow: / geschrieben haben, weil sie bewusst Gegenwehr leisten wollten, und Marken, deren generischer Block User-agent: * \n Disallow: / (vor Jahren für Staging oder Wartungszwecke eingerichtet) zufällig nun auch jeden KI-Bot verbietet, der beim Erstellen der Vorlage noch gar nicht existierte. In diesem Bericht umfasst die Kennzahl „any AI block“ beide Varianten; „explicit AI block“ ist die bewusste Teilmenge.
Bots im Scope
Wir haben 25 Bots verfolgt, gruppiert in drei Kategorien:
- KI-Trainings-Crawler (16):
GPTBot,ClaudeBot,anthropic-ai,CCBot,Google-Extended,Meta-ExternalAgent,Bytespider,Applebot-Extended,Diffbot,Amazonbot,ImagesiftBot,FacebookBot,cohere-ai,AI2Bot,Omgili,Omgilibot. - KI-Inferenz-/Live-Retrieval-Bots (7):
PerplexityBot,Perplexity-User,ChatGPT-User,OAI-SearchBot,ClaudeBot(der sowohl Training als auch Inferenz bedient),YouBot,DuckAssistBot. - Such-Baseline (6):
Googlebot,Bingbot,DuckDuckBot,Slurp(Yahoo),Baiduspider,YandexBot.
Einige Bots bewegen sich zwischen Training und Inferenz. ClaudeBot ist der prominenteste Fall — Anthropic hat den älteren anthropic-ai-UA 2024 abgekündigt und verwendet ClaudeBot nun sowohl für Training als auch für Live-Retrieval. Daher lässt sich eine Regel Disallow: ClaudeBot nicht mehr sauber als „Training blockieren, Sichtbarkeit erhalten“ lesen. Wir haben die Zuordnung so belassen und die Konsequenz später hervorgehoben.
Branchenklassifizierung
Wir haben jede Domain mit einem mehrstufigen Verfahren in eine von 16 Branchenkategorien eingeordnet (news, social, streaming, ecommerce, search, finance, infrastructure, saas, academia, dev, gov, adult, gambling, travel, telecom, unknown):
- Bekannte-Domain-Wörterbuch — eine manuell kuratierte Zuordnung von rund 500 stark frequentierten Domains zu Branchen.
- TLD-/Suffix-Muster —
.gov→gov,.eduund.ac.*→academia, erkannte CDN-Suffixe →infrastructure. - Schlüsselwörter im Domainnamen — news, post, shop, bank, porn, casino usw. als Fallback-Signale.
- Homepage-Crawl — für Sites, die auf den ersten drei Ebenen nicht klassifiziert werden konnten und bei denen
robots.txtmit200zurückkam, haben wir die Homepage-HTML abgerufen,<title>,<meta name="description">,<meta property="og:type">extrahiert und eine Schlüsselwort-Bewertung gegen kategorietypische Signale im Stil von Sprachmodellen durchgeführt.
So erhielten wir 3.407 Sites (34 %) mit belastbaren Branchen-Tags; 6.593 blieben unknown. Der unknown-Block wird dominiert von nicht-englischen Regionalportalen, Marken-Websites in .com, die in keine einzelne Kategorie passen, und traditionellen Medien kleiner Sprachmärkte, für die wir keine Wörterbucheinträge hatten. Wo dieser Bericht pro Branche Prozentwerte nennt, ist der Nenner die klassifizierte Stichprobe dieser Branche, nicht die vollen 10.000.
III. Ergebnisse
Ergebnis 1 — Eine von fünf Sites mit hohem Traffic blockiert mindestens einen KI-Bot
Über die 7.248 analysierbaren Sites hinweg blockieren 1.472 (20,31 %) mindestens einen KI-Bot. 1.230 (16,97 %) haben eine absichtliche, KI-spezifische Regel. Die Googlebot-Baseline liegt bei 2,18 % (158 Sites — die meisten davon blockieren entweder als Wartungsstandard alles oder sind in drei Fällen Suchmaschinen, die Konkurrenten blockieren).
Die Schlagzeilenquote von 20 % ist 9× die Googlebot-Baseline. Das ist ein echtes Signal — Websites mit hohem Traffic blockieren einen KI-Crawler deutlich wahrscheinlicher als einen Suchcrawler — aber auch eine merklich kleinere Zahl als die Narrative über „KI-Blocking erreicht universelle Akzeptanz“, die seit 2024 in der Presse kursieren. Selbst unter den 10.000 meistbesuchten Seiten des Webs schweigt die Mehrheit von fünf zu sechs zur KI.
Die Aufteilung zwischen „any AI block“ (20,3 %) und „explicit AI block“ (17,0 %) ist absolut gesehen klein, aber konzeptionell wichtig. Die Differenz von 3,3 Punkten entspricht dem Anteil der Sites, die KI-Bots nur deshalb blockieren, weil ihre bestehende Regel User-agent: * \n Disallow: / alles einfängt, was vorbeikommt — einschließlich Bots, die beim Schreiben der Regel noch gar nicht existierten. Die bewusst formulierten 17,0 % sind die sauberere Lesart darauf, „wie viele der größten Websites der Welt eine explizite KI-Entscheidung getroffen haben“.
Im Vergleich zur Vorliteratur:
| Quelle | Datum | Stichprobe | Blockrate |
|---|---|---|---|
| Originality.ai | März 2025 | 1.000 beliebteste Nachrichten (englisch) | 35,7 % blockieren GPTBot |
| Palewire | Aug. 2024 | 1.500 Nachrichtenorganisationen | 36,0 % irgendein KI-Crawler |
| Reuters Institute | Frühjahr 2025 | 50 führende Nachrichtenmarken, 10 Länder | 78 % irgendein KI-Crawler |
| WIRED / NYT | Ende 2023 | Top 50 US-News | 26 % blockieren GPTBot |
| Dieser Bericht (Thunderbit) | Mai 2026 | Tranco Top 10.000 (alle Sektoren) | 20,3 % / 17,0 % explizit |
Unsere expliziten 17,0 % liegen unter allen News-only-Studien, weil zwei Drittel unserer Stichprobe nicht aus Nachrichten besteht. Beschränkt auf die 650 News-Sites kommen wir auf 47 % — innerhalb desselben Bereichs wie die früheren Studien, wenn man die Stichprobenzusammensetzung berücksichtigt. Das strukturelle Bild bleibt konsistent: Der News-Sektor blockiert KI mit der 3- bis 4-fachen Rate des übrigen Webs.
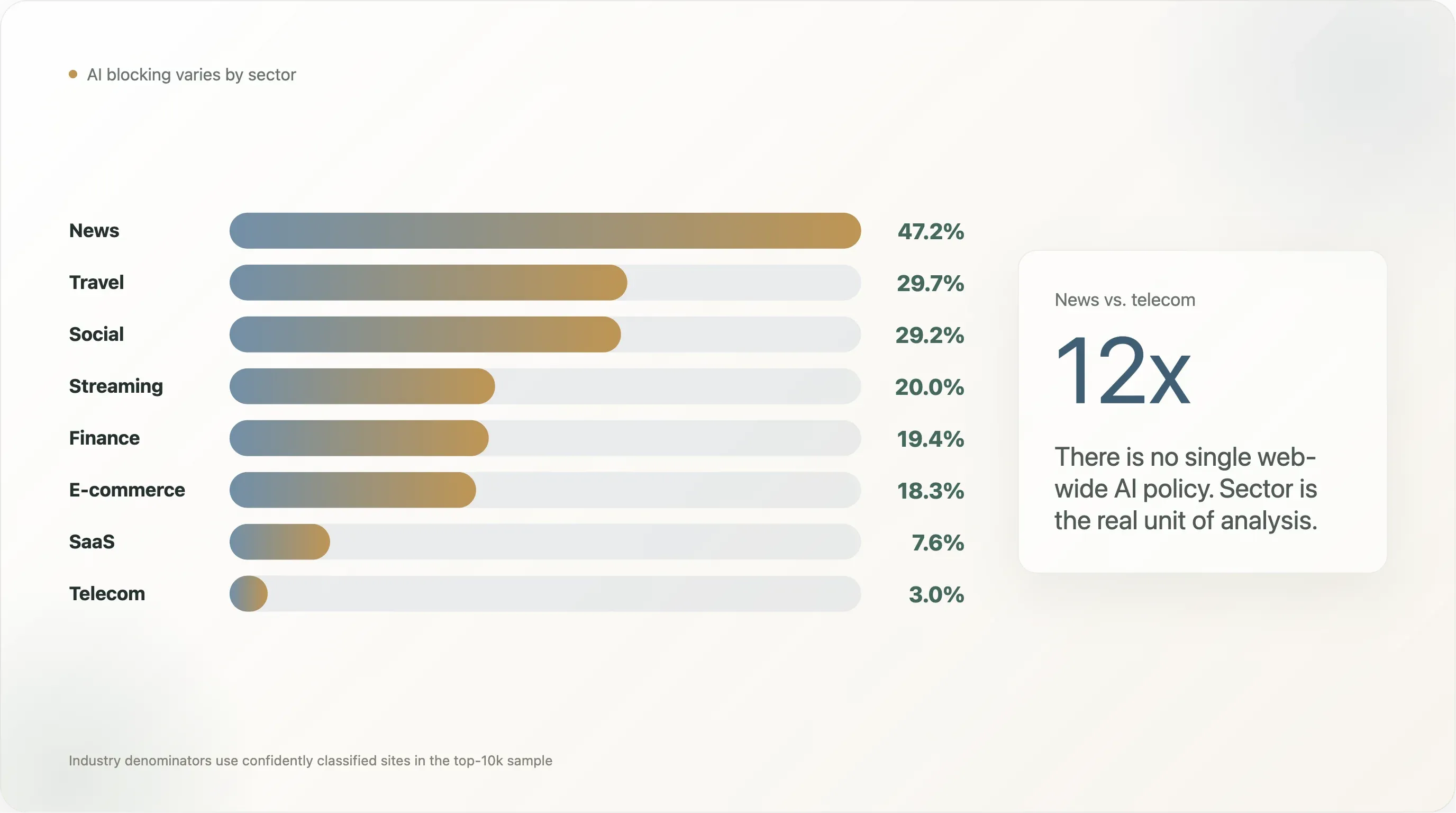
Ergebnis 2 — Tiefenanalyse nach Branche: 12-fache Spannweite von News bis Telecom
Die am häufigsten zitierte Erkenntnis aus zwei Jahren „AI scraping“-Berichterstattung war die Zahl „80 % der News-Seiten blockieren GPTBot“ aus den Untersuchungen von Originality.ai und Palewire. Unser Ausschnitt ergibt eine kleinere, aber weiterhin markante Zahl: 47,2 % der News-Sites in den Top 10.000 blockieren mindestens einen KI-Bot, 45,2 % formulieren eine explizite KI-Regel.
Aber „News gegen den Rest“ ist zu grob. Die vollständige Aufschlüsselung (Branchen mit n ≥ 10 in der Stichprobe) erzählt eine deutlich reichere Geschichte:
| Branche | n | Any AI block | Explizit | Googlebot blockiert | DIY-Regeln | Cloudflare Managed | Silent |
|---|---|---|---|---|---|---|---|
| News | 650 | 47,2 % | 45,2 % | 1,5 % | 46,9 % | 1,5 % | 48,5 % |
| Travel | 64 | 29,7 % | 29,7 % | 0,0 % | 35,9 % | 3,1 % | 54,7 % |
| Social | 65 | 29,2 % | 23,1 % | 4,6 % | 23,1 % | 6,2 % | 66,2 % |
| Streaming | 440 | 20,0 % | 17,7 % | 0,7 % | 16,8 % | 3,6 % | 75,5 % |
| Finance | 129 | 19,4 % | 12,4 % | 0,8 % | 14,7 % | 2,3 % | 75,2 % |
| E-commerce | 224 | 18,3 % | 17,4 % | 0,4 % | 24,1 % | 1,3 % | 66,1 % |
| Adult | 254 | 17,3 % | 14,6 % | 0,4 % | 10,2 % | 7,9 % | 79,5 % |
| Search | 12 | 16,7 % | 0,0 % | 0,0 % | 0,0 % | 0,0 % | 100,0 % |
| Academia | 268 | 14,6 % | 13,8 % | 0,4 % | 13,4 % | 3,4 % | 77,2 % |
| Gambling | 100 | 14,0 % | 13,0 % | 0,0 % | 18,0 % | 4,0 % | 77,0 % |
| Dev tools | 129 | 10,1 % | 7,8 % | 0,0 % | 8,5 % | 5,4 % | 77,5 % |
| SaaS | 369 | 7,6 % | 6,2 % | 0,3 % | 9,5 % | 0,8 % | 87,5 % |
| Government | 172 | 5,2 % | 3,5 % | 0,0 % | 4,1 % | 0,6 % | 83,1 % |
| Infrastructure | 47 | 4,3 % | 0,0 % | 0,0 % | 4,3 % | 2,1 % | 72,3 % |
| Telecom | 33 | 3,0 % | 3,0 % | 0,0 % | 12,1 % | 0,0 % | 78,8 % |
Die 12-fache Spannweite zwischen News und Telecom zeigt, warum „die KI-Politik des Webs“ die falsche Analyseeinheit ist. Es gibt nicht eine Zahl; es gibt sektorale Zahlen, die sich um eine Größenordnung unterscheiden. Im Folgenden gehen wir die vier markantesten Ergebnisse durch.
News: 47 % Blockierung, 47 % DIY. News ist der Sektor, der das Playbook geschrieben hat. Cloudflare Managed kommt in News nur auf 1,5 % — diese Verlage lagern die Regel nicht aus. Der Text ist ungewöhnlich reich: Die NYT beginnt mit einem 14-zeiligen juristischen Vorspann, der auf „Art. 4 der EU-Richtlinie“ verweist; die BBC mit „Please use our site like a human, not a robot... TL;DR: Browse, read, watch, enjoy — like a human.“; The Sun mit „The Sun does not permit the unlicensed use of our content for large language models.“ Das ist robots.txt als Richtlinienerklärung, nicht als Konfiguration.
Travel bei 30 % — die Überraschung. Booking, Expedia, TripAdvisor, Kayak und die großen Fluggesellschaften blockieren mit etwa zwei Dritteln der News-Rate. Das selektive Muster ist konsistent: Der durchschnittliche Travel-Blocker verweigert 5–7 Trainings-UAs, lässt Inferenz-UAs (PerplexityBot, ChatGPT-User, OAI-SearchBot) jedoch unangetastet. Aggregierte Preis- und Bewertungsdaten sind der Burggraben; Zitate zurück auf die Site sind der Mehrwert. Das ist das klarste „Training raus, Inferenz rein“-Muster in einer einzelnen Branche.
Adult bei 17 % — ebenfalls überraschend. Frühere kleinere Stichproben zeigten 0 %. Die Gesamtdaten zeigen, dass 1 von 6 Adult-Sites mindestens einen KI-Bot verbietet, mit der höchsten Cloudflare-Managed-Rate aller Sektoren (7,9 %). Mehr als die Hälfte der KI-Blockierungen bei Adult-Sites stammt vom Cloudflare-Schalter, nicht von einer Verlegerentscheidung. Das Training für Bildgenerierung ist die implizite Bedrohung — Modelle der StableDiffusion-Klasse lernen visuellen Stil schneller, als Textmodelle Schreibstil lernen.
SaaS bei 7,6 % ist kontraintuitiv. Software-Anbieter sind in der KI-Politik-Debatte am lautesten, aber ihre robots.txt ist weit offen. Die richtige Lesart: SaaS-Marketingteams haben AI Search korrekt als Distributionskanal erkannt. Die Anbieter, die sich tatsächlich Gedanken gemacht haben, schalten ein statt aus — die explizite-Allow-GPTBot-Liste (Ergebnis 12) wird von Sicherheits- und Dev-Tools-SaaS dominiert.
Government 5,2 %, Telecom 3,0 %, Infrastructure 4,3 %, Dev 10,1 %. Pflichten zur öffentlichen Aktenführung machen Disallow: / für .gov rechtlich heikel. Telecom-Marketingseiten wollen Auffindbarkeit. CDN-Apex-Domains haben nichts zu schützen. Dev-Tools schalten ausdrücklich ein (ihr Inhalt gewinnt an Wert, wenn LLMs darauf verweisen).
Die Schlussfolgerung: Es gibt keine einzelne „das Web blockiert KI / blockiert KI nicht“-Zahl, die nicht mehr verschleiert als erklärt. Eine sektorbezogene Berichterstattung ist die einzige ehrliche Art, die Daten zu diskutieren.
Ergebnis 3 — Pro KI-Anbieter: Wer wird am stärksten blockiert?
Ein weiterer naheliegender Schnitt ist nicht nach Bot, sondern nach KI-Unternehmen. Mehrere Anbieter betreiben mehrere Bots (OpenAI drei: GPTBot, ChatGPT-User, OAI-SearchBot; Anthropic zwei: ClaudeBot, anthropic-ai; Meta zwei: Meta-ExternalAgent, FacebookBot). Auf Anbieterebene zusammenzufassen kommt der Frage am nächsten, „was denkt das öffentliche Web über jedes KI-Unternehmen?“
| KI-Anbieter | Aggregierte Bots | Sites blockieren ≥ 1 Bot | % der analysierbaren Sites |
|---|---|---|---|
| Common Crawl | CCBot | 1.178 | 16,25 % |
| OpenAI | GPTBot, ChatGPT-User, OAI-SearchBot | 1.172 | 16,17 % |
| Anthropic | ClaudeBot, anthropic-ai | 1.111 | 15,33 % |
| ByteDance | Bytespider | 1.082 | 14,93 % |
| Meta | Meta-ExternalAgent, FacebookBot | 989 | 13,65 % |
Google-Extended | 970 | 13,38 % | |
| Amazon | Amazonbot | 877 | 12,10 % |
| Apple | Applebot-Extended | 859 | 11,85 % |
| Webz.io (Omgili) | Omgili, Omgilibot | 731 | 10,09 % |
| Cohere | cohere-ai | 717 | 9,89 % |
| Perplexity | PerplexityBot, Perplexity-User | 715 | 9,86 % |
| Diffbot | Diffbot | 684 | 9,44 % |
| You.com | YouBot | 563 | 7,77 % |
| AI2 (Allen AI) | AI2Bot | 487 | 6,72 % |
| DuckDuckGo | DuckAssistBot | 482 | 6,65 % |
Common Crawl ist die am stärksten angezielte einzelne Entität, obwohl es ein gemeinnütziges Webarchiv ist und kein LLM-Betreiber. Der Grund ist die Hebelwirkung: CCBot speist fast jedes Open-Weight-Modell und einen großen Teil der geschlossenen Modelle. CCBot zuerst zu blockieren ist die Regel mit der höchsten Abdeckung, die ein Publisher schreiben kann.
OpenAI, Anthropic, ByteDance liegen bei 14–16 %. OpenAIs Vorsprung ist zum Teil ein Zählartefakt (drei OpenAI-Bots statt eines Bots bei ByteDance). Bytespiders 14,9 % sind der „Bytespider-Verhaltenseffekt“ — dokumentiert ist, dass der Bot robots.txt seit 2024 ignoriert, und Publisher blockieren ihn als öffentliches Signal, nicht weil sie sich wegen TikTok Sorgen machen.
Meta, Google, Amazon, Apple bei 12–14 % bilden die zweite Stufe — eher defensiv als als Positionsstatement geschrieben. Kleinere Anbieter (Webz.io, Cohere, Perplexity, Diffbot, You.com, AI2, DuckDuckGo) bei 6–10 % werden meist durch die 3,8-%-Catch-all-Untergrenze nach oben gezogen; explizite Regeln für sie liegen eher im Bereich von 1–4 %.
xAI (Grok), Mistral und die meisten europäischen/chinesischen Modelllabore fehlen in der Tabelle — sie haben keine dokumentierten Trainings-Crawler-UAs veröffentlicht. Das derzeitige robots.txt-Ökosystem ist ein Dialog zwischen US-/chinesischen Anbietern, die UAs ausgeliefert haben, und US-/EU-Publishern, die Regeln geschrieben haben; Anbieter ohne ausgelieferte UAs bleiben für die Verhandlung unsichtbar.
Ergebnis 4 — CCBot ist der neue Blitzableiter, nicht GPTBot
Die Reihenfolge der Bots in der Top-10k sieht so aus:
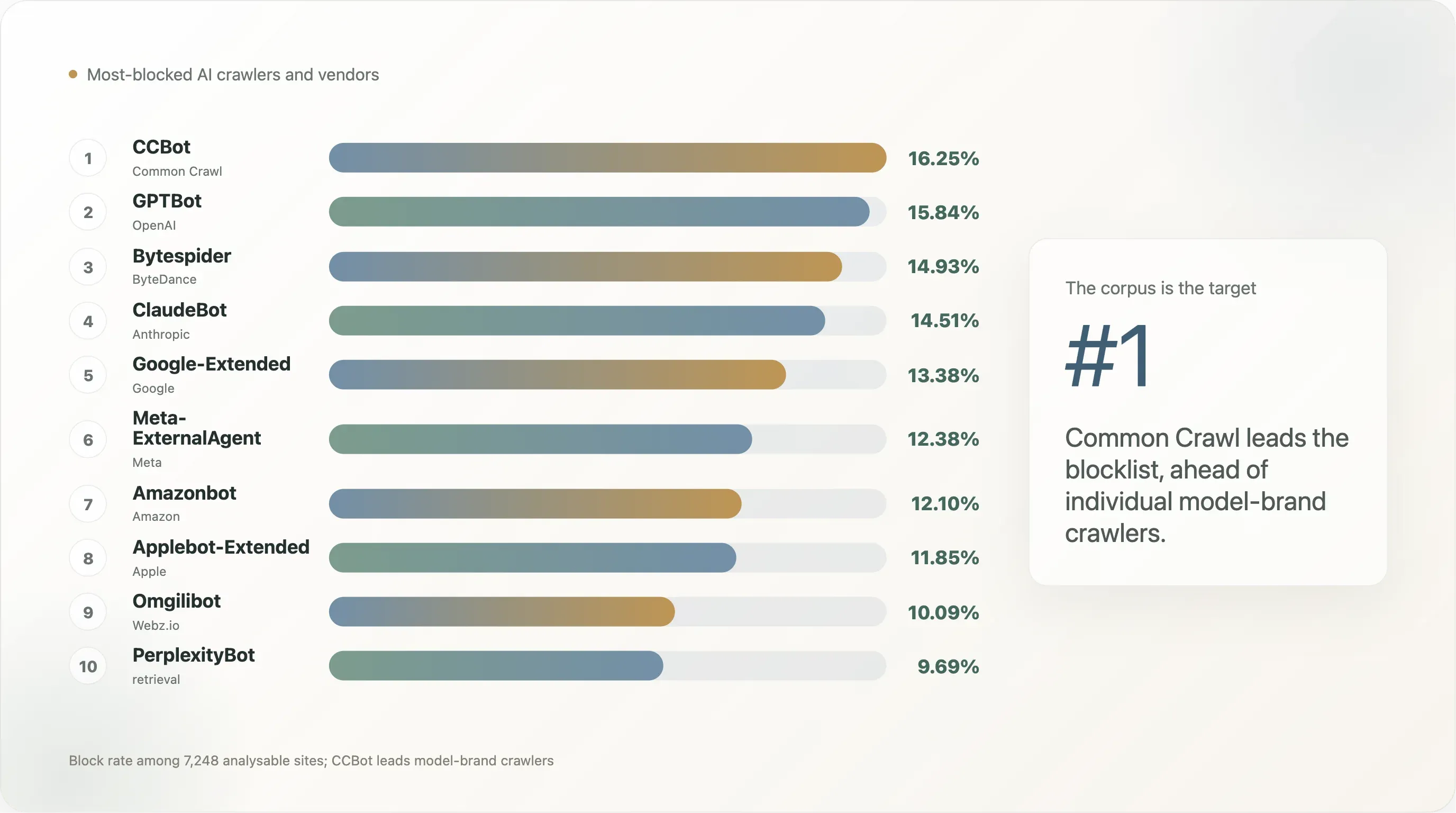
| Rang | Bot | Blockrate | Rate für explizite Regel |
|---|---|---|---|
| 1 | CCBot (Common Crawl) | 16,25 % | 12,90 % |
| 2 | GPTBot (OpenAI) | 15,84 % | 12,72 % |
| 3 | Bytespider (ByteDance) | 14,93 % | 11,35 % |
| 4 | ClaudeBot (Anthropic) | 14,51 % | 11,13 % |
| 5 | Google-Extended | 13,38 % | 10,18 % |
| 6 | Meta-ExternalAgent | 12,38 % | 8,95 % |
| 7 | Amazonbot | 12,10 % | 8,66 % |
| 8 | Applebot-Extended | 11,85 % | 8,72 % |
| 9 | Omgilibot | 10,09 % | 5,31 % |
| 10 | anthropic-ai (veraltet) | 9,99 % | 6,55 % |
| 11 | cohere-ai | 9,89 % | 6,42 % |
| 12 | PerplexityBot | 9,69 % | 6,40 % |
| 13 | Diffbot | 9,44 % | 5,95 % |
| 14 | ChatGPT-User (Inferenz) | 8,90 % | 5,73 % |
| 15 | YouBot (Inferenz) | 7,77 % | 4,29 % |
| 16 | OAI-SearchBot (Inferenz) | 6,83 % | 3,66 % |
| Basis | Googlebot | 2,18 % | — |
| Basis | Bingbot | 2,27 % | — |
Die Aussage dieser Tabelle ist: Der Bot, den das öffentliche Web zuerst blockiert, ist nicht die Modellmarke — sondern der Korpus. Common Crawls 250-Milliarden-Seiten-Archiv war der größte einzelne Trainingsinput für GPT-3, GPT-4, Llama 1 / 2 / 3, Falcon, Mistral, BLOOM und die meisten seit 2020 veröffentlichten Open-Weight-Modelle. Eine Site, die „nicht im nächsten Frontier-Modell enthalten sein“ möchte, optimiert am besten, indem sie zuerst CCBot verbietet — wenn man nicht in Common Crawl ist, ist man praktisch kostenlos aus der Open-Source-Trainingspipeline draußen. GPTBot und ClaudeBot stehen an zweiter und dritter Stelle, weil sie die sichtbare Frontend-Schicht zweier spezifischer kommerzieller Produkte sind; der UA auf Korpusebene ist das strukturelle Ziel.
Auch die niedriger platzierten KI-Bots in der Tabelle sind aufschlussreich. Omgilibot bei 10 % ist ungewöhnlich hoch für einen Bot, den viele Leser nicht kennen dürften — er wird von Webz.io betrieben, einem Content-Data-Broker, der Webarchive an LLM-Betreiber verkauft, und eine beträchtliche Zahl von Nachrichtenorganisationen nennt ihn inzwischen explizit in ihren Dateien. AI2Bot bei 6,7 % (und eine entsprechende Ai2Bot-Dolma-Regel auf Squarespace-Sites) deutet darauf hin, dass auch die akademische LLM-Community markiert wird — von Publishern, die nicht unbedingt zwischen „nicht-kommerziellem Forschungs-Crawler“ und „kommerziellem Crawler“ unterscheiden.
Der Inferenz-Cluster — ChatGPT-User, OAI-SearchBot, YouBot, Perplexity-User — liegt 4–8 Prozentpunkte unter dem Trainings-Cluster. Diese Lücke beantwortet eine langjährige Policy-Frage: Ja, Top-Sites unterscheiden zwischen einem Bot, der Daten für zukünftiges Modelltraining sammelt, und einem Bot, der gerade live Informationen abruft, um die Frage eines Nutzers zu beantworten. Sie machen den Unterschied nicht immer explizit (die Catch-all-Regeln tun das nicht), aber ein relevanter Anteil schreibt Regeln, die speziell auf die Trainingsseite zielen.
Ergebnis 5 — 14 % blockieren CCBot, lassen aber Googlebot willkommen: das Muster „Korpus blockieren, Suche behalten“
Die selektive Regel mit der höchsten Verbreitung in den Top-10k:
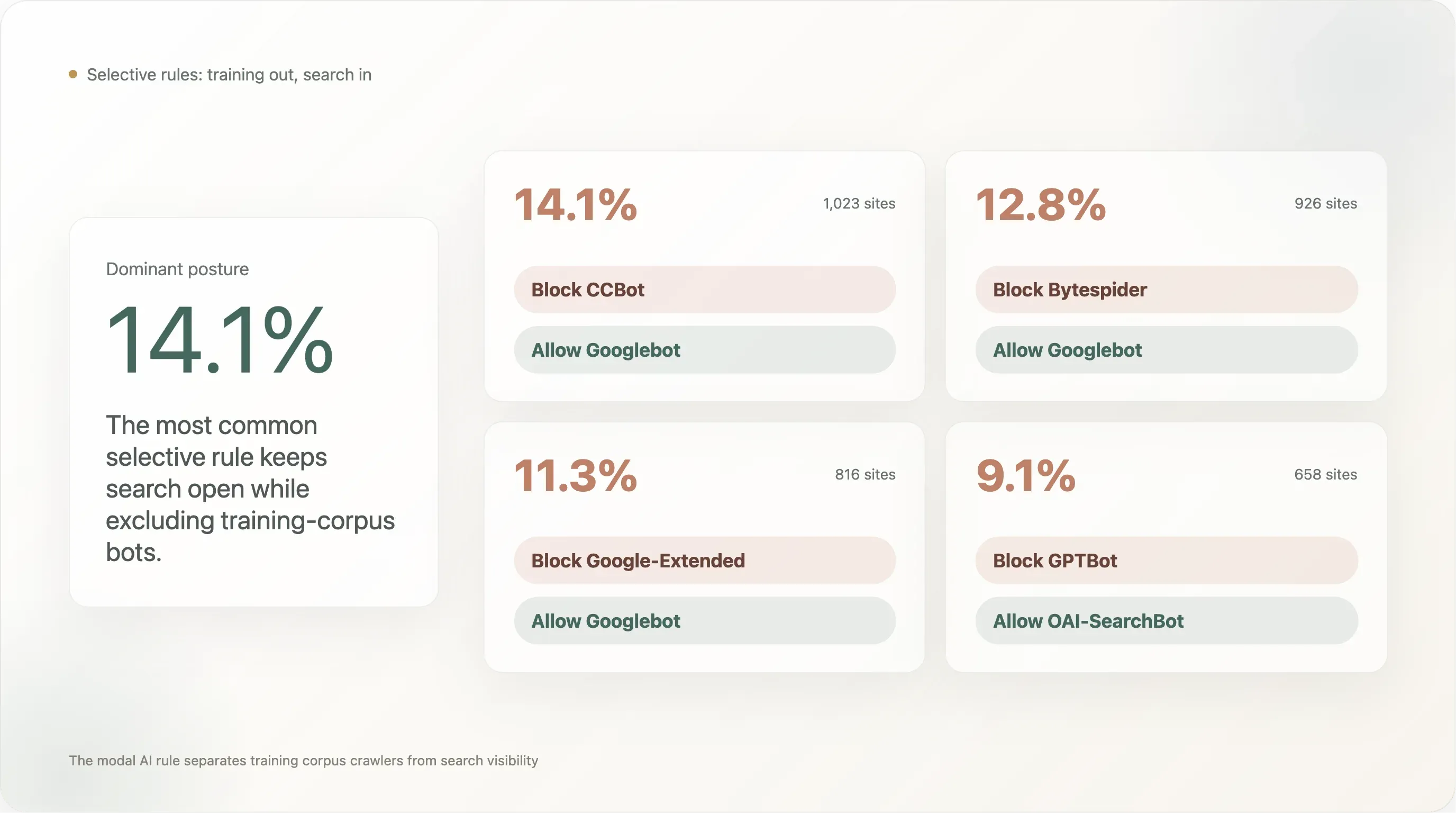
This paragraph contains content that cannot be parsed and has been skipped.
Das am weitesten verbreitete Muster (14,1 %) lautet „Common Crawl blockieren, Google-Sichtbarkeit behalten“. Der Zweitplatzierte (12,8 %) ist „Bytespider blockieren, Google-Sichtbarkeit behalten“ — also den reputationskritischen Crawler von ByteDance sperren, während die legitime Such-Baseline unberührt bleibt. Drittens (11,3 %) steht „Googles eigene KI-Trainings-UA blockieren, während Googles Such-UA erhalten bleibt“; genau dafür hat Google Google-Extended geschaffen: Der Publisher optiert aus Bard-/Gemini-Training aus, ohne das Such-Ranking zu verlieren.
Diese drei Zahlen zusammen beschreiben die dominante Haltung im Top-10k-Web: Trainingskorpus-Bots verbieten, Such- und Inferenz-Bots unberührt lassen. Das Minderheitsmuster „Training verbieten, aber die spezifische Live-Retrieval-UA dieses LLM erlauben“ — GPTBot ✗ / ChatGPT-User ✓ bei 7,2 % — existiert, ist aber kleiner als die Korpusschnitte.
Die Zeile anthropic-ai / ClaudeBot bei 0,81 % spiegelt Anthropics UA-Abkündigung von 2024 wider: ClaudeBot dient nun sowohl Training als auch Inferenz, wodurch die klare Formulierung „Training blockieren, Zitation erlauben“, die die alte anthropic-ai-UA zuließ, wegfällt. Das ist die am wenigsten diskutierte UA-Designentscheidung von 2024–2025 — sie hat eine ganze Kategorie von Richtlinienausdrücken aus robots.txt entfernt.
Ergebnis 6 — News im Detail: nach Land und Sprache
Wenn wir die News-Kategorie nach Länder-Code-TLD aufschlüsseln — wohlgemerkt bedeutet das .de für deutsche News, .fr für französische News usw., nicht die Sprache des Angebots — ist die Varianz innerhalb von News größer als die zwischen News und dem Rest:
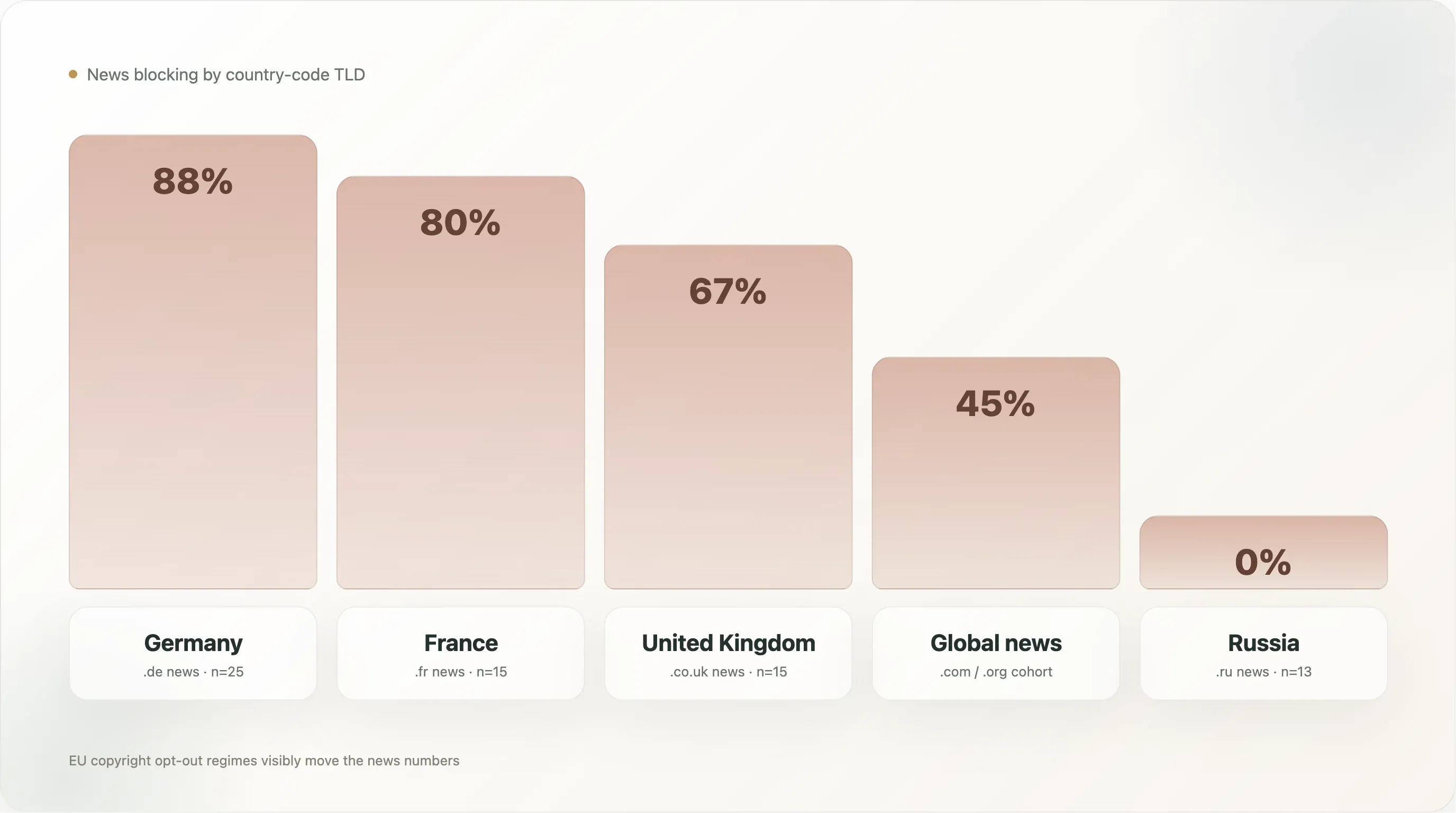
| Land (nur News) | n | Any AI block | Explizit |
|---|---|---|---|
🇩🇪 Deutschland (.de) | 25 | 88,0 % | 88,0 % |
🇫🇷 Frankreich (.fr) | 15 | 80,0 % | 80,0 % |
🇬🇧 Vereinigtes Königreich (.co.uk) | 15 | 66,7 % | 53,3 % |
🇪🇸 Spanien (.es) | 5 | 60,0 % | 60,0 % |
🇮🇹 Italien (.it) | 13 | 53,8 % | 53,8 % |
Globale News (.com/.org/etc.) | 500 | 45,0 % | 42,8 % |
🇵🇱 Polen (.pl) | 7 | 42,9 % | 42,9 % |
🇯🇵 Japan (.jp) | 12 | 25,0 % | 25,0 % |
🇷🇺 Russland (.ru) | 13 | 0,0 % | 0,0 % |
🇬🇷 Griechenland (.gr) | 6 | 0,0 % | 0,0 % |
Deutsche News sind mit 88 % das stärkste Blocking-Segment im gesamten Datensatz, und zwar zu 88 % explizit — es gibt praktisch keine deutsche News-Site in den Top 10k, die KI-Trainings-Crawler bis in ihr Archiv lässt. Der Kreis wird angeführt von Spiegel, Bild, Welt, Zeit, FAZ, Süddeutsche, Heise, Golem, Stern, Focus — der gesamten deutschen Mainstream-Presse plus Tech-Publishern, die unabhängig Regeln geschrieben haben. Dahinter steht eine dichte politische Infrastruktur: VG Media, die deutsche Verwertungsgesellschaft der Verlage, gehört zu den klagestärksten Gruppen in der EU-KI-Urheberrechtslitigation, und Artikel 4 der EU-Richtlinie ist im deutschen Recht als §44b UrhG mit expliziter maschinenlesbarer Opt-out-Sprache umgesetzt. Als die KI-Anbieter auftauchten, waren deutsche Verlage von allen nationalen Gruppen am besten darauf vorbereitet, diese Rechtslage in robots.txt-Regeln zu übersetzen.
Französische News mit 80 % liegen knapp dahinter. Das französische Rechtsumfeld ist ähnlich (Richtlinie 2019/790 in französisches Recht umgesetzt), und das Verhalten des Kreises ist ähnlich — lemonde.fr, lefigaro.fr, liberation.fr, lequipe.fr, 20minutes.fr, ouest-france.fr blockieren allesamt; die Datei von Le Monde verweist zusätzlich auf das französische droit du producteur de base de données (Artikel L 342-1 des Code de la propriété intellectuelle) als parallele nationale Rechtsgrundlage. Frankreich hat außerdem den Sonderfall eines Urteils des Pariser Handelsgerichts von 2024, das Opt-outs per robots.txt als ausreichenden Hinweis im Sinne von Artikel 4 anerkennt; das liefert eine unmittelbare Rechtsprechungsgrundlage, die kein anderes Land bisher in dieser Form vorweisen kann.
Das Vereinigte Königreich liegt mit 67 % niedriger, weil mehrere große britische Publisher (thesun.co.uk, dailymail.co.uk, mirror.co.uk) statt KI-spezifischer Regeln generelle User-agent: *-Blockaden verwenden, was den expliziten Wert auf 53 % senkt. Der Gesamteffekt ist derselbe — diese Sites erlauben kein KI-Crawling —, aber die Politik wird als „keine Bots außer dieser spezifischen Suchmaschinen-Allowlist“ ausgedrückt und nicht als benannte KI-Bot-Verbote. Auch die rechtliche Grundlage ist schwächer: Nach dem Brexit hat das Vereinigte Königreich die Logik von Artikel 4 übernommen, aber die entsprechende nationale Rechtsprechung ist dünner.
Russische News bei 0 % sind die überraschendste Zeile. Dreizehn russischsprachige News-Domains in der Stichprobe (dzen.ru, rbc.ru, ria.ru, kommersant.ru, tass.ru, lenta.ru, gazeta.ru, interfax.ru, kp.ru, tass.com usw.) — keine davon blockiert einen KI-Crawler. Die naheliegende Erklärung: Das Training russischsprachiger LLMs wird von Yandexs eigenen GPT-ähnlichen Modellen dominiert (die Yandex-interne Crawler verwenden, nicht Common Crawl), das russische Urheberrecht hat kein Pendant zu Artikel 4 übernommen, und große russische Publisher sehen westliche LLMs als kein zentrales Problem (US-Exportkontrollen begrenzen OpenAI-/Anthropic-Dienste in Russland bereits) und Yandex als heimischen Stakeholder statt als Gegner. Die politische Haltung ist also grundlegend anders.
Japanische News bei 25 % bilden ein drittes Muster. Japan hat in seinem Urheberrecht explizite Ausnahmen für Text- und Data-Mining (Artikel 30-4 des japanischen Urheberrechts, 2018 geändert), die großzügiger als Artikel 4 der EU-Richtlinie sind — sie erlauben TDM für Zwecke ohne „Genuss-/Nutzungsabsicht“, einschließlich KI-Training, ohne Zustimmung der Rechteinhaber. Japanische Verlage haben weniger rechtlichen Spielraum für Opt-outs, und die entsprechenden robots.txt-Werte sind niedriger. Die 25 %, die blockieren, sind meist die größten und internationalsten Verlage (asahi.com, nikkei.com), die sich eher global als rein national positionieren.
Die länderübergreifenden News-Daten sind der klarste Beleg in diesem Bericht dafür, dass das Rechtsregime, nicht Technologie oder Branchenökonomie, der Haupttreiber des KI-Blockings ist. EU-News-Kreise liegen zwischen 54 % und 88 %; Nicht-EU-News-Kreise (Russland, Japan, der globale .com-Kreis) reichen von 0 % bis 45 %. Der Höchstwert von 88 % findet sich in dem Land mit der am weitesten ausgebauten Artikel-4-Umsetzung; der Tiefstwert von 0 % in dem Land ohne praktisch jede KI-Politikgesetzgebung.
Ergebnis 7 — EU vs. Rest: eine Lücke von 16 Punkten
Wenn man den Länderaspekt eine Ebene höher zieht, ist der EU-vs.-Rest-Schnitt deutlich:
| Region | n | Any AI block | Explizit |
|---|---|---|---|
EU-ccTLDs (.fr, .de, .es, .it, .nl, .pl, .se, .dk, .fi, .be, .at, .cz, .hu, .ro, .gr, .pt, .ie, .sk, .bg) | 617 | 35,2 % | 33,9 % |
Nicht-EU-National-ccTLDs (.uk, .jp, .kr, .cn, .ru, .br, .in, .au, .mx, .ca, .tr, .ar, .cl, .co, .pe) | 897 | 17,2 % | 13,6 % |
Global (.com, .net, .org, etc.) | 5.734 | 19,2 % | 15,7 % |
EU-ccTLD-Sites blockieren KI mit der doppelten Rate des nicht-EU-Nationalkreises und fast doppelt so häufig wie die globale .com-Baseline. Der Unterschied ist über die EU-Mitgliedstaaten hinweg konsistent (kein einzelnes Land treibt den Durchschnitt) und über Branchen hinweg ebenfalls konsistent (.de News bei 88 %, .de SaaS bei etwa 12 %, .de E-Commerce bei etwa 25 % — alles höher als die globalen Gegenstücke).
Wir fanden 275 robots.txt-Dateien in den Top-10k, die in ihren Kommentaren ausdrücklich auf Richtlinie 2019/790 verweisen — etwa 3,8 % der auswertbaren Stichprobe. Der Kreis wird von EU-Publishern dominiert, reicht aber über sie hinaus: Mehrere US-News-Marken (insbesondere die NYT, die direkt auf „Art. 4 of the EU Directive“ verweist), einige UK-Sites und eine Handvoll größerer europäischer E-Commerce-Angebote übernehmen die juristische Sprache. 87 Dateien erwähnen „TDM“ oder „text and data mining“ explizit beim Namen. 460 Dateien enthalten eine Form von Urheberrechtsvorbehalt („expressly opts out“, „all rights reserved“, „no commercial use“, „no machine learning“), auch wenn sie kein bestimmtes Gesetz nennen.
Zwei weitere feinere Beobachtungen aus diesem Ausschnitt:
Der EU-Effekt betrifft nicht nur News. Wenn wir News konstant halten, blockieren EU-Non-News-Sites KI immer noch häufiger als Nicht-EU-Non-News-Sites (etwa 28 % gegenüber 14 %). Ein kleiner, aber realer Anteil von EU-SaaS, E-Commerce und Academia hat den Artikel-4-Rahmen für die eigene Branche übernommen.
Die EU-geprägte Sprache wird de facto auch außerhalb der EU zur Vorlage. Die von Cloudflare verwaltete robots.txt-Vorlage — weltweit verwendet — zitiert in ihrem Boilerplate ausdrücklich „ARTICLE 4 OF THE EUROPEAN UNION DIRECTIVE 2019/790“. Eine US-Site, die Cloudflares Einstellung „Block AI Bots“ aktiviert, erklärt damit, ohne es zwingend zu wissen, einen gesetzlichen Rechtevorbehalt nach EU-Recht. Das ist eines der interessantesten Drift-Artefakte, die wir gefunden haben: Ein europäisches Rechtskonzept wird über die Produktoberfläche eines US-Infrastrukturproviders globalisiert.
Ergebnis 8 — Vorlagen und ihre Herkunft
Die Verteilung der Vorlagen bei den 6.638 Sites, die eine auswertbare robots.txt zurückgegeben haben:
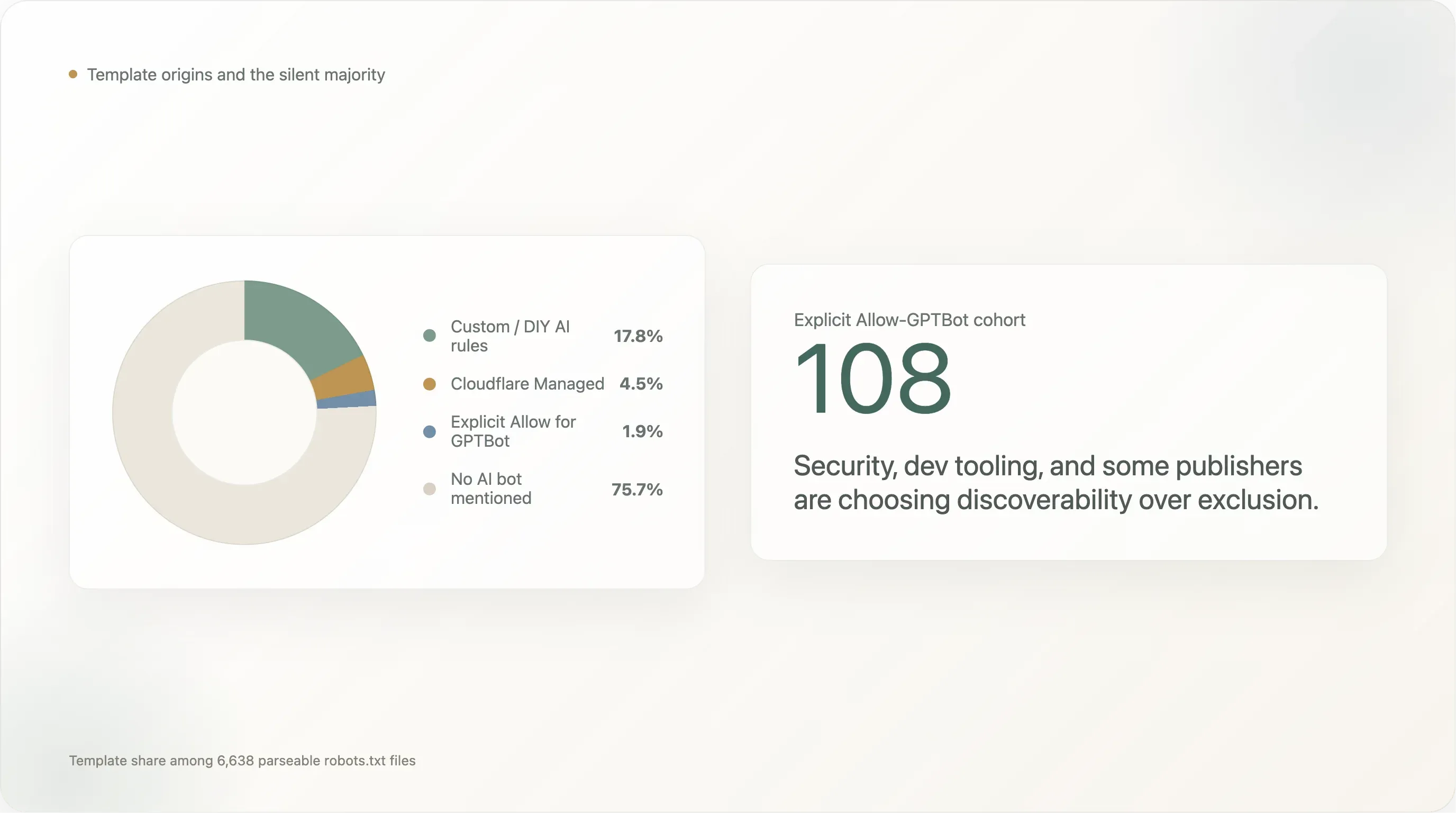
| Vorlage | Sites | Anteil |
|---|---|---|
| Kein KI-Bot erwähnt (Standard-Templates von Shopify, Yoast, manuell ohne KI-Betrachtung geschrieben) | 5.024 | 75,7 % |
| Eigene / DIY-KI-Regeln | 1.183 | 17,8 % |
Cloudflare Managed (Content-Signal: search=yes,ai-train=no) | 302 | 4,5 % |
Explizites Allow: / für GPTBot | 124 | 1,9 % |
| Squarespace-Standard (28 AI-UAs im pfadbeschränkten Block) | 5 | 0,1 % |
DIY-Regeln dominieren mit 17,8 %. Der Kreis der selbst verfassten Blockaden wird angeführt von allen Social-Media-Plattformen (facebook.com, twitter.com, linkedin.com, whatsapp.com, tiktok.com, snapchat.com, pinterest.com, x.com, chatgpt.com selbst), den größten E-Commerce-Destinationen (amazon.com, amazonvideo.com), den großen News-Marken (nytimes.com, cnn.com, bbc.com, theguardian.com, forbes.com, reuters.com, bbc.co.uk, t-online.de, weather.com), wichtigen Streaming-/Media-Angeboten (netflix.com, vimeo.com, soundcloud.com, imdb.com) und einem langen Schwanz an Professional-Services-Seiten (canva.com, medium.com).
Cloudflare Managed liegt bei 4,5 % — deutlich höher als die Verbreitung derselben Vorlage an der Spitze der Kurve und niedriger als ihre Verbreitung im Long Tail außerhalb unseres Ausschnitts. Die Vorlage wird am häufigsten im Segment Rang 1001–10000 genutzt (4–5 %) und ist an der Spitze der Kurve praktisch abwesend (Top 100: 1 Site nutzt sie; Top 101–1000: 5 Sites). Die großen globalen Properties schreiben ihre eigenen Regeln; der Long Tail nutzt den Schalter.
Einige konkrete Cloudflare-Managed-Sites sind bemerkenswert. cloudflare.com selbst läuft mit der Vorlage, was konsistent ist (Cloudflare dogfooded sein eigenes Produkt auf der eigenen Domain). theatlantic.com läuft mit der Vorlage — die einzige große US-News-Marke, bei der wir keine kundenspezifische Regel gefunden haben. spankbang.com läuft mit der Vorlage — die höchstrangige Adult-Site, die eine von Cloudflare eingefügte KI-Blockade übernommen hat. linktr.ee läuft mit der Vorlage und blockiert so das KI-Training über die gesamte von Linktree gehostete Creator Economy mit einer einzigen Anbieterentscheidung. launchpad.net, nexusmods.com, vinted.fr, cookielaw.org, rustdesk.com und eine lange Liste kleinerer Medienangebote vervollständigen den sichtbaren Cloudflare-Managed-Kreis.
Das Cloudflare-Muster ist der konkretste Beleg dafür, dass ein großer Teil der „KI-Politik des Webs“ von Infrastrukturbetreibern entschieden wird. Der absolute Anteil ist klein (4,5 %), aber strukturell wichtig: Die Vorlage ist der Standard, den Cloudflare ausliefert, und die default-on-Tendenz für die nächsten 12 Monate zeigt nach oben. Wenn Cloudflare den Schalter für neue Konten standardmäßig aktiviert, verschiebt sich die globale Blockrate spürbar, ohne dass ein einzelner Publisher eine Entscheidung trifft.
Der Squarespace-Standard (5 Sites in den Top-10k, aber ein deutlich größerer Kreis außerhalb unserer Stichprobe) ist ein anderes Muster: Squarespace liefert eine robots.txt aus, die 28 KI-Bots in einem einzigen Block nennt, diese Bots übernehmen aber die Pfadbeschränkungen von User-agent: * statt einer umfassenden Site-Sperre zu erhalten. KI-Crawler können /, die Startseite, die Produktseiten und den Blog abrufen. Sie können nur nicht /config oder /account abrufen. Wir hatten das bereits als Quelle falsch positiver „KI-Block“-Lesarten bei Drittanbieter-Scans von Squarespace-Sites markiert; hier gilt dieselbe Einschränkung.
Ergebnis 9 — Die KI-Politik ist über die Rangverteilung hinweg recht homogen
Die übliche Intuition bei so einer Studie ist, dass die meistbesuchten Sites die aggressivste KI-Politik hätten — sie haben am meisten durch Trainingsverdrängung zu verlieren, die größte rechtliche Kapazität und die stärkste öffentliche Aufmerksamkeit. Die Daten stützen diese Intuition nicht.
| Rangbereich | n | Any AI block | Explizit | Cloudflare Managed |
|---|---|---|---|---|
| Top 100 | 67 | 22,4 % | 17,9 % | 1 Site |
| Top 101–1.000 | 598 | 22,9 % | 19,2 % | 5 Sites |
| Top 1.001–5.000 | 2.810 | 19,0 % | 15,3 % | 99 Sites |
| Top 5.001–10.000 | 3.773 | 20,8 % | 17,8 % | 197 Sites |
Die vier Gruppen liegen zwischen 19 % und 23 %. Die Top 100 ist nicht aggressiver als der Long Tail von Rang 5001 bis 10.000. Die Schlagzeilenquote scheint also eine Eigenschaft des öffentlichen Webs im Jahr 2026 zu sein — kein Signal dafür, wie groß oder sichtbar eine einzelne Site ist.
Zwei Faktoren tragen dazu bei. Erstens wird die Spitze der Kurve von Infrastruktur-/SaaS-/Such-/Portal-Domains (Microsoft, Apple, Google usw.) dominiert, die für sich genommen niedrige KI-Blocking-Raten haben. Zweitens enthält der Long Tail einen hohen Anteil regionaler News-Publisher und Sites aus EU-Rechtsräumen, die — wie Ergebnis 6 und 7 gezeigt haben — KI deutlich häufiger blockieren als der globale Durchschnitt. Die beiden Effekte heben sich weitgehend auf, und netto ergibt sich eine homogene Gesamtzahl.
Die Cloudflare-Managed-Spalte verschiebt sich allerdings über die Kurve hinweg. In der Top-1000 gibt es 6 Cloudflare-verwaltete Sites (1,0 %); in Top 1001–10000 sind es 296 (5,7 %). Die großen Sites schreiben selbst; der Long Tail nutzt den Anbieter-Schalter. Das ist das einzige relevante rangabhängige Signal im Datensatz, und es deutet darauf hin, dass mit dem Weg von der Spitze des Webs hin zum Long Tail der Anteil der KI-Politik, der vom Anbieter statt vom Publisher gesetzt wird, stetig steigt. Wir erwarten, dass dieser Gradient über die Top 10k hinaus in die Top 100k und weiter anhält.
Ergebnis 10 — Fünf Anatomien: Wie robots.txt aussieht, wenn sie tatsächlich Politik ist
Zahlen beschreiben die Form des Datensatzes; der eigentliche Charakter der „KI-Politik im öffentlichen Web“ wird am besten sichtbar, wenn man konkrete Dateien liest. Hier sind fünf, die sich besonders lohnen.
Anatomie 1 — The New York Times (nytimes.com)
Die ersten 14 Zeilen von nytimes.com/robots.txt:
1# New York Times content is made available for your personal, non-commercial
2# use subject to our Terms of Service here:
3# https://help.nytimes.com/hc/en-us/articles/115014893428-Terms-of-Service.
4# Use of any device, tool, or process designed to data mine or scrape the content
5# using automated means is prohibited without prior written permission from
6# The New York Times Company. Prohibited uses include but are not limited to:
7# (1) text and data mining activities under Art. 4 of the EU Directive on Copyright in
8# the Digital Single Market;
9# (2) the development of any software, machine learning, artificial intelligence (AI),
10# and/or large language models (LLMs);
11# (3) creating or providing archived or cached data sets containing our content to others; and/or
12# (4) any commercial purposes.
13# Contact https://nytlicensing.com/contact/ for assistance.Das ist robots.txt als juristisches Beweisstück. Die Datei ist so strukturiert, dass sie als Beweis im laufenden Rechtsstreit NYT v. OpenAI zulässig sein dürfte. Die Verweise auf „Art. 4 of the EU Directive“ — durch einen US-Publisher — illustrieren die Beobachtung aus Ergebnis 7, dass EU-rechtliche Rahmen in den globalen Diskurs einsickern. Das ausdrückliche Verbot, „archived or cached data sets“ zu erstellen oder bereitzustellen, zielt direkt auf Common Crawl. Die Datei ist über 60 Zeilen lang und enthält benannte User-agent-Blöcke für GPTBot, OAI-SearchBot, ChatGPT-User, anthropic-ai, ClaudeBot, CCBot, Google-Extended, Applebot-Extended, Bytespider, Diffbot, Meta-ExternalAgent, Amazonbot, Omgili, Omgilibot und weitere; jeder benannte Bot erhält ein eigenes Disallow: /.
Anatomie 2 — Der Spiegel (spiegel.de) — KI-Freigabe auf Abschnittsebene
Der Spiegel hat die mit Abstand betrieblich ausgefeilteste robots.txt, die wir im gesamten Datensatz gefunden haben. Der relevante Block:
1# TLP-6507: Testweise Freischaltung der OpenAI-Suchcrawler fuer ausgewaehlte Bereiche
2User-agent: OAI-SearchBot
3Allow: /ausland/
4Allow: /partnerschaft/
5Allow: /gesundheit/
6Allow: /familie/
7Allow: /reise/
8Allow: /psychologie/
9Allow: /stil/
10Disallow: /
11User-agent: ChatGPT-User
12Allow: /ausland/
13Allow: /partnerschaft/
14Allow: /gesundheit/
15Allow: /familie/
16Allow: /reise/
17Allow: /psychologie/
18Allow: /stil/
19Disallow: /Der Kommentar bedeutet sinngemäß „Testweise Freischaltung der OpenAI-Suchcrawler für ausgewählte Bereiche“. Spiegel hat sieben konkrete Inhaltskategorien whitelisted — Ausland, Partnerschaft, Gesundheit, Familie, Reise, Psychologie und Stil — für OpenAIs Inferenz-UAs, während alles andere blockiert wird. Politik, deutsche Inlandsthemen und investigativer Journalismus sind ausdrücklich ausgenommen. Common Crawl, Bytespider, Cohere, Webzio-Extended und die übrigen Trainings-UAs erhalten weiter unten in der Datei ein vollständiges Disallow: /.
Das ist robots.txt als redaktionelle Richtlinie auf Abschnittsebene. Die implizite Theorie lautet, dass Lifestyle-Inhalte ein geringeres Risiko der Trainingsverdrängung und einen höheren Inferenz-Zitationsnutzen haben, sodass Spiegel KI den Zugriff auf diese Bereiche erlaubt; politische und investigative Inhalte sind der Burggraben, also wird KI ausgeschlossen. Wir haben dieses Muster sonst nirgends gesehen. Es impliziert ein Maß an interner Abstimmung zwischen Redaktion, Recht und Infrastruktur, das die meisten Redaktionen noch nicht erreicht haben. Wir erwarten, dass sich diese granulare Richtlinienform 2026–2027 verbreitet — Spiegels Datei ist im Grunde ein Frühindikator.
Anatomie 3 — BBC (bbc.com) — die Form der Richtlinienerklärung
Die BBC-robots.txt beginnt mit:
1# version: ec59bd036e5138eb4831a9ed44447b1ff310e235
2# The BBC's Terms of Use: https://www.bbc.co.uk/terms
3# - Explain the rules for using our services
4# - Tell you what you can do with our content
5#
6# In short: Please use our site like a human, not a robot.
7# That means:
8# - No scraping, crawling, or systematic extraction of content
9# - No use of BBC content for training or fine-tuning AI models, including LLMs
10# - No retrieval-augmented generation (RAG), AI-powered search, agentic AI or
11# grounding using BBC content
12# - No creating datasets from BBC content
13# - No text and data mining (TDM) under Article 4 of the EU Directive on Copyright
14# - No using BBC content to create summaries for your own use
15# - No business use without permission
16# - The BBC reserves all rights in its content and expressly opts out of any
17# statutory exceptions in any jurisdiction for text and data mining,
18# as permitted by law
19#
20# TL;DR: Browse, read, watch, enjoy - like a human.Die BBC versieht ihre robots.txt mit einer Versionsangabe (# version: ec59bd... ist ein Git-Commit-Hash), verbietet die acht konkreten Arten von KI-Nutzung, die die BBC-Juristen im Blick haben, und endet mit einer einzeiligen Zusammenfassung im Tonfall, auf dem die BBC-Marke aufbaut. Die Formulierung „expressly opts out of any statutory exceptions in any jurisdiction“ ist ein bewusster globaler Vorbehalt — die Aussage ist: Wir vertrauen keinem einzelnen Rechtsregime, uns den gewünschten Schutz zu geben, also erklären wir den Opt-out überall zugleich. Das ist die am stärksten redigierte robots.txt im Datensatz, und sie liest sich eher wie eine Pressemitteilung als wie eine Konfigurationsdatei.
Anatomie 4 — WordPress.org — das ausdrückliche Willkommen
Vergleichen wir das mit wordpress.org:
1User-agent: GPTBot
2Allow: /
3User-agent: ClaudeBot
4Allow: /
5User-agent: anthropic-ai
6Allow: /
7User-agent: Google-Extended
8Allow: /
9User-agent: Applebot-Extended
10Allow: /
11User-agent: PerplexityBot
12Allow: /
13User-agent: Bytespider
14Allow: /
15User-agent: CCBot
16Allow: /
17User-agent: Copilot
18Allow: /WordPress.org optiert ausdrücklich in neun KI-Trainings-Crawler ein, darunter die drei (Bytespider, CCBot, anthropic-ai), die anderswo am häufigsten blockiert werden. Die implizite Theorie lautet, dass die WordPress-Dokumentation und das Plugin-Ökosystem ein öffentliches Gut sind, dessen Wert steigt, wenn KI-Assistenten Fragen dazu beantworten können. Jedes Mal, wenn jemand Claude fragt „Wie konfiguriere ich Permalinks in WordPress?“ und Claude auf wordpress.org/documentation/ trainiert wurde, dient das der WordPress-Mission. Die Foundation scheint entschieden zu haben, dass die Präsenz in jedem Trainingskorpus strategisch positiv ist, und hat dafür die Ausdruckslogik der Datei genutzt.
Anatomie 5 — The Verge (theverge.com) — das gesponserte Hybridmodell
Noch ein Muster, das sich zu zeigen lohnt. The Verge strukturiert seine KI-Regeln als Disallow: / \ Allow: /sp/:
1User-agent: GPTBot
2Allow: /
3User-agent: Applebot
4Allow: /
5User-agent: Google-Extended
6Disallow: /
7Allow: /sp/
8User-agent: anthropic-ai
9Disallow: /
10Allow: /sp/
11User-agent: Bytespider
12Disallow: /
13Allow: /sp/
14User-agent: CCBot
15Disallow: /
16Allow: /sp/
17User-agent: ChatGPT-User
18Disallow: /
19Allow: /sp/
20User-agent: ClaudeBot
21Disallow: /
22Allow: /sp/Der Pfad /sp/ ist der Bereich für gesponserte bzw. Partner-Inhalte von The Verge. Redaktionelle Inhalte werden vom KI-Training ausgeschlossen; gesponserte Inhalte sind erlaubt. Die ökonomische Logik ist klar: Sponsoren bezahlen dafür, dass ihre Inhalte auffindbar sind, auch über KI; das redaktionelle Flaggschiff ist der Burggraben. GPTBot ist vollständig offen (vermutlich aufgrund einer direkten OpenAI-Beziehung), Applebot ist als Such-Baseline vollständig offen, und der Rest erhält die Hybridbehandlung. Das ist die einzige „gestufte KI-Zugangs“-Struktur dieser Art, die wir gefunden haben.
Diese fünf Dateien beschreiben das derzeitige Spektrum der robots.txt-KI-Politik. Die meisten Dateien in den Top 10k sehen nach keiner dieser Varianten aus — sie sind entweder still oder verwenden eine Anbieter-Vorlage. Die Dateien, die einer dieser Varianten ähneln, wurden von Menschen geschrieben, die entschieden haben, dass sich das genaue Lesen lohnt.
Ein Hinweis zur Größe: Der Median der robots.txt-Bodies in unserer Stichprobe liegt bei 858 Bytes — zu klein, um eine sinnvolle KI-Politik auszudrücken. Die Regeln liegen im rechten Rand: 1.005 Sites (15,3 %) haben eine Datei größer als 5 KB, 273 größer als 20 KB, und das Maximum lag bei 248 KB. 460 Dateien enthalten Urheberrechtsvorbehalt; 275 nennen EU 2019/790 namentlich. Eine robots.txt ist 2026 zunehmend ein versioniertes, juristisch geprüftes Dokument und keine reine Konfigurationszeile mehr.
Ergebnis 11 — 108 Sites heißen GPTBot ausdrücklich willkommen
Ein kleiner, aber sichtbarer Kreis schreibt eine Regel User-agent: GPTBot \n Allow: / — das Gegenstück zum häufiger diskutierten „Disallow GPTBot“. Die Gesamtzahl in unserer Stichprobe beträgt 108 Sites mit einem ausdrücklichen Allow für GPTBot auf dem Root-Pfad. Die ersten 25 nach Tranco-Rang:
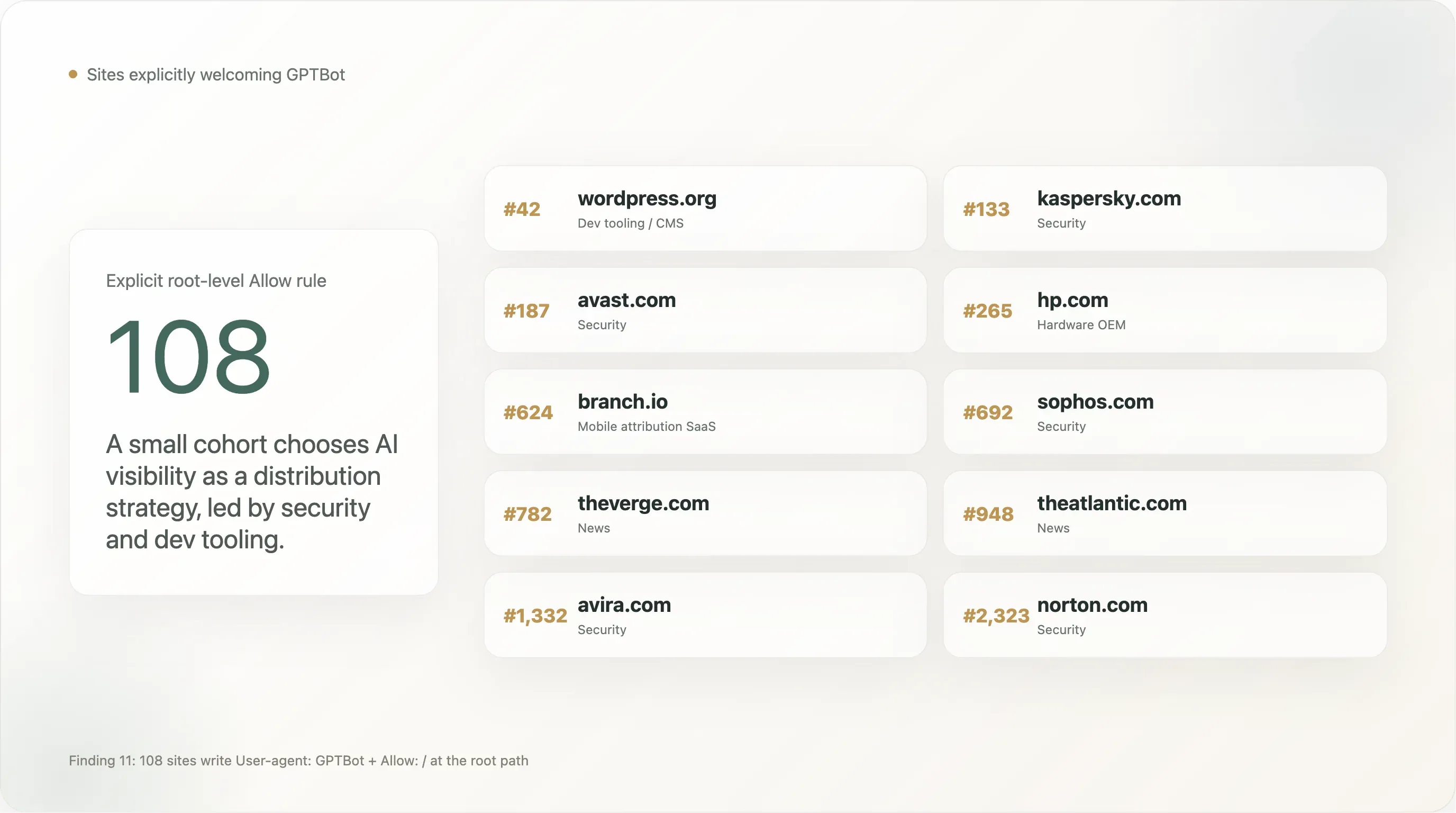
| Rang | Domain | Sektor |
|---|---|---|
| 42 | wordpress.org | Dev-Tools / CMS |
| 133 | kaspersky.com | Sicherheit |
| 187 | avast.com | Sicherheit |
| 265 | hp.com | Hardware-OEM |
| 624 | branch.io | Mobile-Attribution-SaaS |
| 692 | sophos.com | Sicherheit |
| 782 | theverge.com | News |
| 905 | rambler.ru | Russisches Portal |
| 945 | kleinanzeigen.de | Deutscher Marktplatz |
| 948 | theatlantic.com | News |
| 1.092 | lge.com | LG Electronics |
| 1.300 | justdial.com | Lokale Suche in Indien |
| 1.332 | avira.com | Sicherheit |
| 1.412 | youm7.com | Ägyptische News |
| 1.530 | goodreturns.in | Finanzen in Indien |
| 1.621 | publi24.ro | Rumänische Kleinanzeigen |
| 1.807 | geocomply.com | Compliance-SaaS |
| 1.908 | nba.com | Sport |
| 1.956 | oneindia.com | Indische News |
| 1.974 | mindbox.ru | Russisches SaaS |
| 2.009 | thesun.co.uk | News |
| 2.126 | vox.com | News |
| 2.140 | mgid.com | Native Advertising |
| 2.314 | ninjarmm.com | IT-Management-SaaS |
| 2.323 | norton.com | Sicherheit |
Einige Muster:
Sicherheitsunternehmen sind auffällig überrepräsentiert. Kaspersky, Avast, Sophos, Avira, Norton, NinjaRMM erlauben GPTBot ausdrücklich. Das ist ein bewusster Distributionshebel: Wenn ein Nutzer ChatGPT fragt „Was ist der beste Virenschutz für meinen Windows-Rechner?“, beeinflusst die Präsenz der Marke im Trainingskorpus direkt die Empfehlung. Sicherheit ist eine der wenigen B2C-Kategorien, in denen AI Search bereits SEO als primären Akquisitionskanal verdrängt, und diese Marken sind zuerst vorgegangen. Wir erwarten, dass der Rest des Sicherheitssektors innerhalb von 12 Monaten folgen wird.
Einige große News-Marken stehen auf dieser Liste, nicht auf der Blockliste. The Verge, The Atlantic, Vox, The Sun, NBA.com. Das ist kein Widerspruch — diese Publisher scheinen entschieden zu haben, dass Zitierbarkeit in ChatGPT-Suche wertvoller ist als Schutz vor Training, und haben die explizite Allow-Regel geschrieben, um sich gegen künftige Überblockierungen durch CDN oder CMS abzusichern. Vergleichen Sie das mit der Haltung von NYT / Reuters / BBC / Forbes / Guardian mit explizitem Disallow. Beide Positionen sind vertretbar; die News-Branche ist nicht monolithisch.
Die Präsenz von The Sun ist bemerkenswert, weil dieselbe Site an anderer Stelle in ihrer Datei einen pauschalen User-agent: *-Verbot-Block verwendet. Am besten liest man die Politik von The Sun als „KI-Training ist verboten, KI-Suche ist erlaubt, und wir haben GPTBot ausdrücklich als Ausnahme von der pauschalen Sperre whitelisted, damit ChatGPT Fragen unter Berufung auf The Sun beantworten kann.“ Das ist die rechtlich ausgereifteste der GPTBot-Allow-Regeln — ein Opt-out plus ein opt-in für einen einzelnen Anbieter.
Die Präsenz von WordPress.org ist der wohl folgenreichste einzelne Eintrag auf der Liste. Ein nicht triviale Teil des globalen Open-Source-CMS-Ökosystems verweist für Dokumentation auf WordPress.org oder hostet Plugins von dort. Indem die WordPress Foundation GPTBot in wordpress.org/robots.txt ausdrücklich erlaubt, hat sie de facto erklärt, dass das WordPress-Dokumentationsökosystem für Training offen ist — mit Folgen dafür, wie gut Claude, Gemini und ChatGPT „Wie mache ich ...?“-Fragen zu WordPress beantworten können.
Die übrigen 83 Sites in der vollständigen Allow-GPTBot-Liste sind ein langer Schwanz aus regionalen News-Seiten, kleineren Sicherheitsanbietern, Kleinanzeigenplattformen in nicht-englischen Märkten und B2B-SaaS. Soweit wir sehen, gibt es keine sektorweite „Allow-GPTBot“-Koordination — die Regel wird Site für Site übernommen, von Betreibern, die entschieden haben, dass Präsenz im Korpus die strategische Position ist.
Ergebnis 12 — llms.txt ist in dieser Größenordnung kaum mehr als ein Gerücht
llms.txt, das vorgeschlagene alternative Dateiformat für LLM-freundliche Inhaltserkennung (seit Ende 2024 von Mintlify, Anthropic, Vercel und einigen Dev-Tool-Anbietern propagiert), hat in unserer Stichprobe praktisch keine sichtbare Verbreitung.
Von den 6.638 Sites mit auswertbarer robots.txt erwähnen 83 (1,15 %) llms.txt — typischerweise als Zeile Sitemap: https://example.com/llms.txt. Das ist zwei Größenordnungen weniger als derselbe Wert in Commerce-Stichproben mit starkem Dev-Tool-Fokus, wo Vercel- und Mintlify-Defaults die Verbreitung aufblasen.
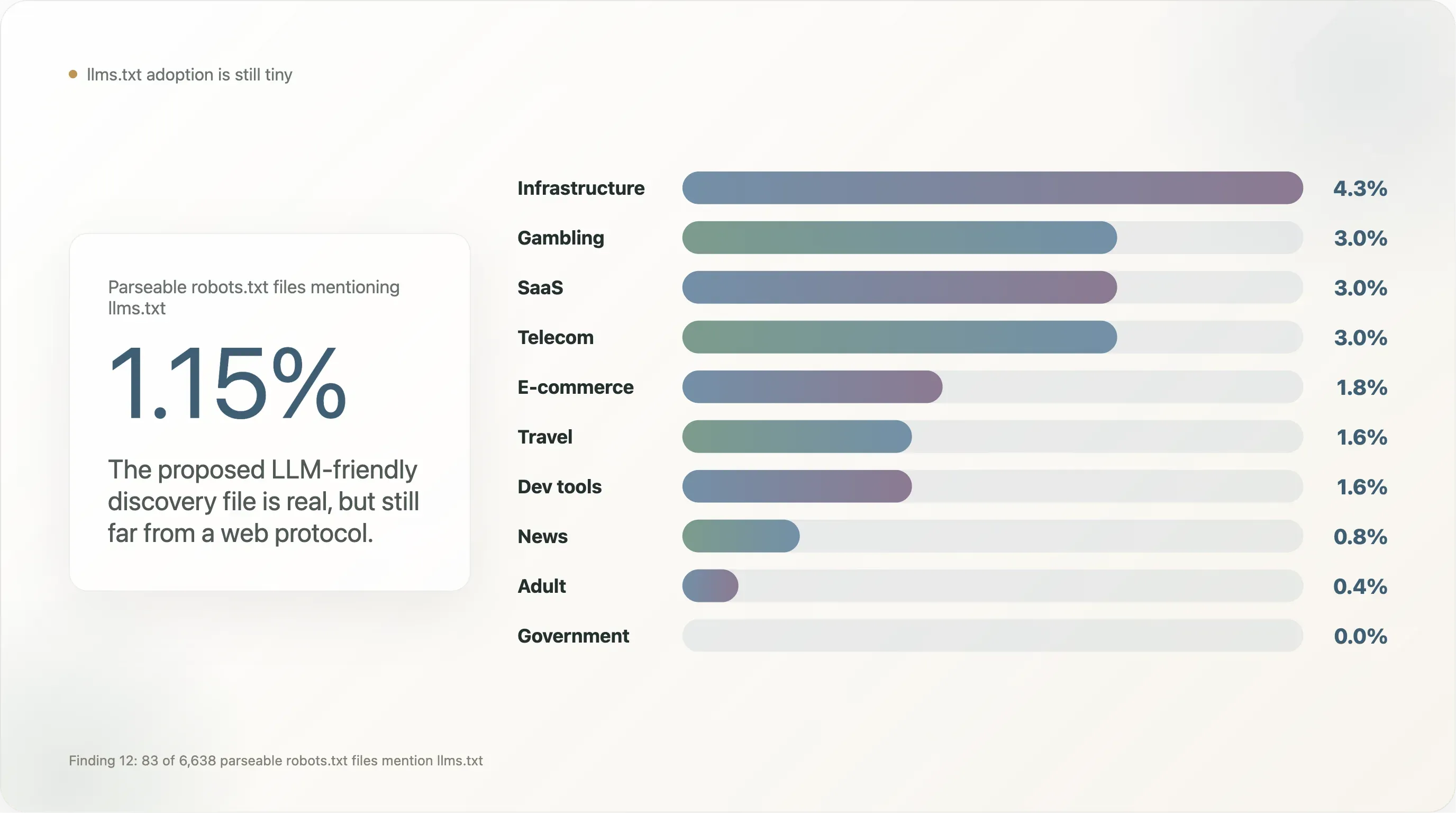
Die Aufschlüsselung nach Branchen:
| Branche | n | % mit Erwähnung von llms.txt |
|---|---|---|
| Infrastructure | 47 | 4,3 % |
| Gambling | 100 | 3,0 % |
| SaaS | 369 | 3,0 % |
| Telecom | 33 | 3,0 % |
| E-commerce | 224 | 1,8 % |
| Travel | 64 | 1,6 % |
| Dev tools | 129 | 1,6 % |
| News | 650 | 0,8 % |
| Adult | 254 | 0,4 % |
| Government | 172 | 0,0 % |
| Academia | 268 | 0,0 % |
| Search | 12 | 0,0 % |
llms.txt konzentriert sich auf SaaS mit Nähe zu Dev-Tools, Gambling (das neue robots.txt-Vokabeln schneller übernimmt als andere regulierte Branchen, weil dort Compliance-Teams gewohnt sind, zusätzliche Metadaten einzuschichten) und B2B-E-Commerce. Auffällig abwesend ist es in News und Government — den beiden Segmenten, die sich am stärksten mit KI-Politik befassen und deren Adoption nötig wäre, damit der Standard vom „Anbieterexperiment“ zum „Webprotokoll“ aufsteigt. Bis dahin ist llms.txt real, aber klein, und ein Folge-Audit Ende 2026 wäre ein sinnvoller Re-Test.
Das strukturelle Problem von llms.txt ist, dass es von keinem IETF-Prozess standardisiert wird und die großen KI-Anbieter sich nicht verpflichtet haben, es zu respektieren. Eine robots.txt-Regel steht auf 30 Jahren Crawler-Infrastruktur; eine llms.txt-Regel auf gar keiner. Solange nicht mindestens ein großer Anbieter (OpenAI, Anthropic, Google, Cloudflare) formale Unterstützung erklärt, ist die Datei im Wesentlichen ein Marketingartefakt des Mintlify-/Vercel-Ökosystems. Wir erwarten nicht, dass sich das 2026 ändert.
Ergebnis 13 — Zugänglichkeit: robots.txt bleibt für zwei Drittel des Top-Webs lesbar
Eine Nebenbeobachtung, die eigentlich kein Ergebnis sein sollte: 66 % der Top-10.000-Sites gaben robots.txt auf eine einzelne Forschungs-IP in auswertbarer Form zurück, und nur 7 von 10.000 (0,07 %) antworteten mit 429 Too Many Requests. Das ist gute Nachricht für robots.txt als öffentliches Protokoll.
Zum Vergleich: Dieselbe Pipeline auf einer 1.008-Domain-Commercial-Stichprobe aus dem Mid-Market, zwei Monate zuvor, erhielt von 52 % der aufgelösten Domains ein 429 — Shopify- und Cloudflare-CDNs drosselten aggressiv jeden Nicht-Major-Search-Engine-UA. Das Top-Traffic-Web ist deutlich freundlicher: Top-Sites haben eher entweder (a) weniger aggressive Bot-Management-Stufen oder (b) explizite Allowlists für bekannte Forschungs-Crawler, oder beides.
Die 21-%-Rate fetch_failed im Top-10k wird von CDN-Apex-Domains (akamai.net, cloudfront.net, fastly.net, apple-dns.net, gtld-servers.net) dominiert, die unter / keinen Webserver betreiben. Sie blockieren uns nicht; sie haben nichts auszuliefern. Ohne diese Fälle liegt die echte „versucht zu lesen, konnte aber nicht“-Fehlerrate im niedrigen einstelligen Bereich.
Das bedeutet, dass künftige Versionen dieses Berichts — Quartals-Snapshots, Year-over-Year-Vergleiche — billig und reproduzierbar auf einer einzigen Maschine laufen können. Der Audit-Fenster bleibt an der Spitze der Kurve offen. Der asymmetrische Fall ist der Long Tail und das Commerce-Segment, wo CDN-Throttling robots.txt faktisch bereits privatisiert hat. Wir erwarten, dass sich diese Divergenz vergrößert: Top-Sites bleiben lesbar, weil Suchmaschinen Lesbarkeit verlangen; Long-Tail-Commerce wird weniger lesbar, weil Cloudflares Bot-Fight-Stufen aggressiver werden. Die öffentliche Auditierbarkeit von robots.txt spaltet sich entlang derselben Linie, die „das sichtbare Web“ vom „operativ geschützten Web“ trennt.
IV. Was das alles bedeutet
Vier Thesen, in der Reihenfolge, in der die Daten sie am stärksten stützen.
1. Das Internet hat eine branchenbezogene, keine globale KI-Politik. Die 12-fache Spannweite zwischen News und Telecom dominiert jede Aggregatzahl. Wer „X % des Webs blockieren KI“ ohne sektorale Aufschlüsselung berichtet, überbewertet SaaS/Government/Dev und unterschätzt News/Travel/Social. Nur die Aufschlüsselung nach Sektor ist ehrlich.
2. Artikel 4 der EU-Urheberrechtsrichtlinie ist das einzige Rechtsregime, das die Zahlen sichtbar bewegt. EU-ccTLD-Sites blockieren mit 35 % gegenüber der globalen Baseline von 19 %. Die US-Litigation (NYT v. OpenAI, der Bericht des Copyright Office vom Januar 2025) hat den US-News-Kreis verschoben, aber nicht das breitere US-Web. Der EU-Rahmen sickert zudem global durch die Cloudflare-Vorlage ein, die Richtlinie 2019/790 unabhängig von der Jurisdiktion des Kunden im Boilerplate zitiert.
3. Zwei parallele „KI-Politiken“ werden ausgedrückt, und sie stimmen nicht überein. Die bewusste, manuell geschriebene Politik (17,8 %, vor allem News/Social/Travel/E-Commerce) und die übernommene, Cloudflare-verwaltete Politik (4,5 %) überschneiden sich inhaltlich, unterscheiden sich aber in ihrer Legitimität. In einer Welt, in der KI-Betreiber nach einer rechtlichen Absicherung suchen, um robots.txt zu ignorieren, ist die Verteidigung „wir haben es geschrieben und geprüft“ strukturell stärker als „ich habe es einfach eingeschaltet“. Der Anreiz in der Litigation ist, Politik aus der zweiten in die erste Kategorie zu verschieben.
4. Blockiert wird der Korpus, nicht das Modell. CCBot bei 16,3 % — höher als jeder bot mit Modellmarke — ist die klarste Aussage dazu. OpenAI zu verbieten reicht Publishern nicht, um dem Training zu entkommen; CCBot zu verbieten schon. 14,1 % des Top-10k-Webs blockieren CCBot, lassen Googlebot aber willkommen. Das Muster „Training blockieren, Suche behalten“ ist die typische KI-Regel im Jahr 2026.
Für Sites, die ihre eigene Haltung prüfen: Die Median-Haltung ist Schweigen — 80 % der Top 10k sagen nichts über KI. Die 17 % mit Regeln konzentrieren sich auf Disallow, aber ein kleiner, wachsender Kreis (die Liste mit explizitem Allow für GPTBot mit 1,5 %, angeführt von Sicherheitsanbietern) entscheidet sich öffentlich für das Gegenteil. Es gibt keinen Branchenkonsens und in den nächsten zwölf Monaten wird es auch keinen geben.
Für KI-Betreiber: Die Behauptung, robots.txt sei ein Legacy-Protokoll mit mehrdeutiger Semantik, wird immer schwerer aufrechtzuerhalten, wenn 17 % der größten Websites der Welt explizite, absichtliche Regeln mit Bot-Namen von Hand schreiben und 3,8 % der Dateien eine konkrete EU-Norm mit Abschnittsangabe zitieren. Ob man diese Regeln respektiert, ist eine Geschäftsentscheidung; dass sie existieren, ist inzwischen eine empirische Tatsache.
V. Ausblick: Was wir bis Ende 2026 erwarten
Drei Entwicklungen sind im Datensatz sichtbar:
Cloudflare Managed wird seinen Anteil mehr als verdoppeln und plausibel 10 %+ der auswertbaren Top-10k erreichen. Cloudflare diskutiert öffentlich, Block AI Bots für neue Konten standardmäßig zu aktivieren. Wenn der Schalter default-on ausgeliefert wird, steigt die globale Blockrate um 5–8 Prozentpunkte, ohne dass ein Publisher eine Entscheidung trifft. Wir werden das daran erkennen, dass der Anteil von Cloudflare Managed im Rangbereich 5001–10000 über den aktuellen 5,7 % liegt.
Abschnittsbezogene KI-Politiken (Spiegel-Stil) werden sich unter den großen Nachrichten-Flaggschiffen verbreiten. Die ökonomische Logik — KI darf niedrigrangige Inhalte zitieren, der Burggraben-Inhalt bleibt geschützt — ist überzeugend genug, dass wir bis Ende 2026 mindestens 10 weitere große Redaktionen mit solchen Regeln erwarten. Beobachten Sie zuerst die deutsche und französische Mittelklassepresse; der rechtliche Rahmen belohnt dort Experimente.
Der Kreis mit explizitem Allow für GPTBot wird wachsen, angeführt von B2B-SaaS und Dev-Tools. Wenn AI Search für Softwareanbieter zu einem messbaren Akquisitionskanal wird (wie es für Sicherheit bereits der Fall ist), wird der marginale CMO User-agent: GPTBot \n Allow: / schreiben, um sich gegen versehentliche Überblockierung zu immunisieren. Wir erwarten, dass sich die 108er-Liste bis Jahresende ungefähr verdoppelt.
Was wir nicht erwarten: eine spürbare Veränderung des Silent-Majority-Anteils. Die 80 % des Webs, die über KI nichts sagen, umfassen Sektoren (Government, Telecom, Infrastruktur, B2B-SaaS) ohne wirtschaftlichen Anlass für eine Regel und ohne rechtlichen Druck dazu. Eine universelle KI-Politik kommt nicht.
VI. Einschränkungen
- Ein-Snapshot-Bias. Die Abrufe erfolgten in einem 36-Stunden-Fenster Anfang Mai 2026. Auf der Top-100 ändert sich die Datei täglich; auf die Schlagzeilenzahlen sind pro Quartal 1–2 Prozentpunkte Drift zu erwarten.
- Lücken in der Branchenklassifikation. 6.593 von 10.000 Sites blieben nach dem Vier-Ebenen-Klassifikator
unknown. Pro-Branchen-Prozente sind robust, wenn n groß ist (News: 650, Streaming: 440, SaaS: 369, Academia: 268, Adult: 254, E-Commerce: 224, Government: 172, Finance: 129, Dev: 129) und deutlich noisiger unter n=30. Der Länder-News-Schnitt ist ähnlich begrenzt — DE/FR/UK haben n≥15, Korea/Schweden/Tschechien basieren auf n=20–25. robots.txtist freiwillig. EinDisallowist eine Bitte, keine Barriere.Bytespider,PerplexityBotund andere sind dokumentiert worden, Regeln zu ignorieren. Wir haben Richtlinienerklärungen gemessen, nicht deren Durchsetzung.- Einzelne US-basierte IP. Wir konnten 21 % der aufgelösten Domains nicht lesen. Die meisten sind CDN-Apex-Punkte ohne Webserver; ein kleiner Teil sind Sites, deren CDN uns vor dem Origin bereits blockiert hat. Das verzerrt die Stichprobe leicht in Richtung älterer Infrastruktur und gegen geofencete Sites nach Herkunftsland.
- Tranco-Semantik. Tranco filtert auf Stabilität; es ist kein echtes Ranking des Nutzerverhaltens. Die Aggregatzahlen sind robust gegenüber der Wahl der Liste; die genauen Rangpositionen nicht.
- Keine Traffic-Daten. Wir haben
robots.txt-Politik gemessen, nicht den tatsächlichen Durchsatz von KI-Bots. Politik und Traffic stimmen nicht immer überein.
VII. So reproduzieren Sie das
Alles, was zur Erstellung dieses Berichts verwendet wurde, liegt im Deliverable-Ordner.
- tranco_top10k.csv — Eingabeliste
- out/sites.csv — Domain × Rang × Branche × Sprache × robots.txt-Status (10.000 Zeilen)
- out/fetch_meta.csv — Abruf-Ergebnis pro Domain (Status, Schema, Bytes, Fehler)
- out/bot_status.csv — Domain × Bot-Raster (250.000 Zeilen: blockiert, Regel vorhanden, Fetch-Status)
- out/site_meta.csv — ein analytischer Datensatz pro Site (Vorlage, Summary-Flags)
- out/analysis.json — jede im Bericht zitierte Kennzahl
- 01_fetch_robots.py, 02_classify.py, 03_parse_and_analyze.py — vollständige Python-Pipeline
Methodische Korrekturen, Datenprobleme und Folgeanalysen sind willkommen unter support@thunderbit.com. Dieser Bericht wird unabhängig von jeder kommerziellen Position veröffentlicht, die Thunderbit innehat; wir bauen einen KI-gestützten Web-Scraper und haben ein strukturelles Interesse daran, dass robots.txt auf dem öffentlichen Web ein bedeutender, maschinenlesbarer Vertrag bleibt. Die Daten in diesem Bericht stehen für sich. — Das Thunderbit-Forschungsteam, Mai 2026.