

Selten war die Nachfrage nach sauber gelabelten Trainingsdaten im Machine Learning so groß wie heute. In Gesprächen mit Teams, die neue KI-Modelle aufbauen — sei es für Umsatzprognosen, Produktempfehlungen oder die Auswertung von Kundenstimmungen — kommen immer dieselben Schwachstellen zur Sprache: Daten von Hand zu labeln ist langsam, teuer und auf Dauer ziemlich ermüdend. Ich habe Projekte erlebt, die wochen- oder monatelang feststeckten, einzig weil zu wenige gelabelte Beispiele für ein brauchbares Modelltraining vorhanden waren. Und sobald die Labels uneinheitlich ausfallen, wird es richtig unangenehm: Dann sind die Vorhersagen des Modells etwa so zuverlässig wie eine Wettervorhersage drei Wochen im Voraus.
Die gute Nachricht: Automatisiertes Data Labeling per Machine Learning ist hier ein echter Wendepunkt. Wenn die KI die mühsame Arbeit übernimmt, beschleunigen Unternehmen nicht nur den Labeling-Prozess, sondern gewinnen zugleich an Genauigkeit und Konsistenz — und genau daran entscheidet sich oft, ob ein ML-Projekt gelingt oder scheitert. In diesem Leitfaden erkläre ich, wie automatisiertes Data Labeling abläuft, warum es für belastbare Modelle so zentral ist und wie Sie mit Tools wie Thunderbit Ihren eigenen automatisierten Labeling-Workflow einrichten — ohne eine Zeile Code.
Was ist automatisiertes Data Labeling mit Machine Learning?
Schauen wir uns das genauer an. Automatisiertes Data Labeling mit Machine Learning heißt, dass Algorithmen und KI-Tools Ihren Rohdaten die passenden Labels zuweisen — etwa „Spam“ oder „kein Spam“, „Katze“ oder „Hund“, „positiv“ oder „negativ“ — ohne dass jemand jedes einzelne Beispiel von Hand anklicken muss. Der Unterschied ist ungefähr so wie zwischen dem manuellen Verschlagworten Tausender Urlaubsfotos und einer Bildersuche, die per Gesichtserkennung automatisch nach Person, Ort oder sogar Stimmung sortiert.
Klassisches manuelles Labeling ist genau das, wonach es klingt: Menschen sichten die Daten Stück für Stück und vergeben das jeweils passende Label. Das ist oft präzise, aber langsam, teuer und schwer zu skalieren. Beim automatisierten Labeling kommen dagegen Machine-Learning-Modelle zum Einsatz — trainiert mit einem kleineren, von Hand gelabelten Datensatz — die dann die Labels für den restlichen Datensatz vorhersagen. Das Resultat: schnelleres, einheitlicheres und deutlich besser skalierbares Labeling (GeeksforGeeks).
Für die Praxis im Unternehmen bedeutet das: bessere Modelle, schneller fertig und mit deutlich weniger stupider Handarbeit. Und wer datenbasiert arbeitet, verschafft sich damit einen handfesten Wettbewerbsvorteil.
Data Labeling mit Thunderbit automatisieren Nutzen Sie Thunderbits KI-gestützten Web-Scraper, um Ihren Data-Labeling-Workflow zu automatisieren — ganz ohne Programmierung. Get Started Free
Warum automatisiertes Data Labeling der Schlüssel zu hochwertigen Machine-Learning-Modellen ist
Entscheidend ist: Die Qualität Ihrer gelabelten Daten wirkt sich unmittelbar darauf aus, wie gut Ihre Machine-Learning-Modelle arbeiten. Stecken schlechte Daten rein, kommen auch schlechte Ergebnisse heraus. Sind Ihre Labels uneinheitlich oder falsch, lernt das Modell die falschen Muster — und die Vorhersagen werden entsprechend schwach (DataCamp).
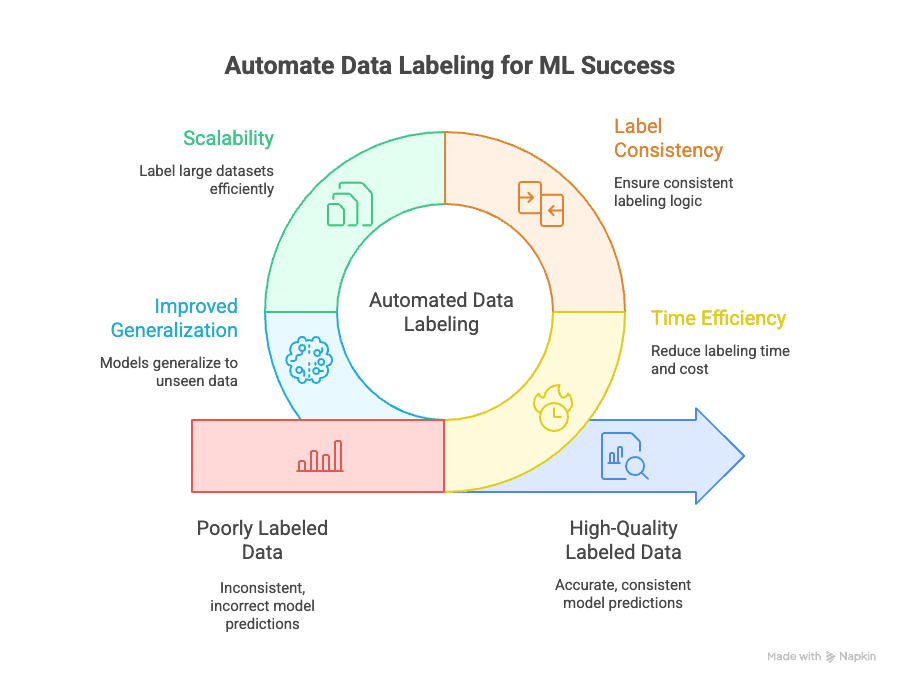
Automatisiertes Data Labeling löst gleich mehrere zentrale Herausforderungen:
- Zeitersparnis: Manuelles Labeling kann 70 % der gesamten Zeit und Kosten eines ML-Projekts verschlingen. Automatisierung drückt diesen Aufwand auf einen Bruchteil und macht schnellere Iterationen und Deployments möglich.
- Label-Konsistenz: Maschinen ermüden nicht und lassen sich nicht ablenken. Automatisiertes Labeling stellt sicher, dass jeder Datenpunkt nach derselben Logik gelabelt wird, und reduziert so menschliche Fehler und Verzerrungen (GeeksforGeeks).
- Skalierbarkeit: 10.000, 100.000 oder gar eine Million Datenpunkte zu labeln? Mit Automatisierung machbar — ohne dafür ein ganzes Heer von Annotatoren einzustellen (Keylabs).
- Bessere Generalisierung: Einheitliche, hochwertige Labels helfen Modellen, auch auf neue, unbekannte Daten zuverlässig zu reagieren — und genau darum geht es im Machine Learning (Kili Technology).
Und der Effekt fürs Geschäft ist messbar: Keylabs berichtet, dass hybride Workflows aus KI-gestütztem Labeling und menschlicher Kontrolle die Labeling-Genauigkeit um bis zu 80 % verbessern können — verglichen mit rein manuellen Pipelines. Das schlägt sich direkt in schnelleren Modelliterationen und verlässlicheren Vorhersagen weiter unten in der Verarbeitungskette nieder.
Manuelles vs. automatisiertes Data Labeling im Vergleich
Stellen wir beides direkt gegenüber:
| Faktor | Manuelles Labeling | Automatisiertes Labeling mit ML |
|---|---|---|
| Geschwindigkeit | Langsam (Wochen/Monate bei großen Datensätzen) | Schnell (Minuten/Stunden bei großen Datensätzen) |
| Genauigkeit | Hoch, aber anfällig für menschliche Fehler/Inkonsistenzen | Hoch, mit konsistenter Logik und weniger Fehlern |
| Skalierbarkeit | Durch personelle Ressourcen begrenzt | Skaliert problemlos auf Millionen von Datenpunkten |
| Kosten | Teuer (arbeitsintensiv) | Niedrigere langfristige Kosten (Keylabs) |
| Am besten geeignet für | Kleine, komplexe oder mehrdeutige Datensätze | Große, repetitive oder klar definierte Datensätze |
Manuelles Labeling hat weiterhin seine Berechtigung — etwa bei Sonderfällen oder mehrdeutigen Daten — doch für die meisten geschäftlichen Anwendungen ist die Automatisierung der richtige Weg.
Die grundlegenden Schritte des automatisierten Data Labeling mit Machine Learning
Wie läuft automatisiertes Data Labeling konkret ab? Hier der durchgängige Workflow, den ich empfehle — und selbst nutze:
- Datenerfassung und Vorverarbeitung
- Feature-Extraktion und Aufbereitung
- Automatisches Labeling mit Machine Learning
- Qualitätssicherung und menschliche Prüfung
Gehen wir die einzelnen Schritte durch.
Schritt 1: Datenerfassung und Vorverarbeitung
Bevor Sie irgendetwas labeln, müssen Sie Ihre Daten zusammentragen und bereinigen. Das kann heißen: Produktlisten von Websites scrapen, Kundenbewertungen exportieren oder Bilder aus internen Datenbanken zusammenziehen. Worauf es hier ankommt, ist die Qualität — schlechte Daten ergeben schlechte Labels, und schlechte Labels ergeben schlechte Modelle (Snorkel AI).
Bewährte Vorgehensweisen:
- Duplikate und irrelevante Einträge entfernen
- Formate vereinheitlichen (Datumsangaben, Währungen usw.)
- Fehlende oder unvollständige Daten gezielt behandeln
Schritt 2: Feature-Extraktion und Aufbereitung
Im nächsten Schritt legen Sie fest, welche Merkmale für Ihre Labeling-Aufgabe relevant sind. Beim Labeln von Produktlisten könnten das Attribute wie Preis, Marke, Kategorie und Beschreibung sein. In Vertrieb oder Marketing ginge es vielleicht darum, Firmennamen, Kontaktdaten oder Stimmungen aus E-Mails herauszuziehen.
Beispiel aus der Praxis: Mit Thunderbit lassen sich strukturierte Daten von Webseiten scrapen — etwa Produktspezifikationen, Bewertungen oder Kontaktdaten — ohne eine einzige Zeile Code.
Schritt 3: Automatisches Labeling mit Machine Learning
An diesem Punkt kommt der eigentliche Kern. Sie setzen Machine-Learning-Modelle ein — trainiert auf einem kleineren, von Hand gelabelten Datensatz — um die Labels für den Rest Ihrer Daten vorherzusagen. Zu den gängigen Verfahren zählen:
- Überwachte Modelle: Trainieren Sie einen Klassifikator mit gelabelten Beispielen und nutzen Sie ihn anschließend, um neue Daten zu labeln.
- Regelbasiertes Labeling: Setzen Sie vordefinierte Regeln ein (z. B. „wenn Preis > 1.000 $, dann als ‚Premium‘ labeln“) für einfache Fälle.
- Active Learning: Das Modell fordert bei unsicheren Fällen menschliches Eingreifen an und wird mit der Zeit besser (GeeksforGeeks).
- Transfer Learning: Verwenden Sie vortrainierte Modelle, um das Labeling in neuen Bereichen zu beschleunigen (GeeksforGeeks).
Das Resultat: einheitliche, hochwertige Labels — und das im großen Maßstab.
Schritt 4: Qualitätssicherung und menschliche Prüfung
Selbst die besten Modelle brauchen ab und zu einen Realitätscheck. Regelmäßige menschliche Reviews helfen dabei, Sonderfälle, mehrdeutige Daten oder ein Abdriften des Modells zu erkennen. Sinnvolle QA-Schritte sind:
- Gelabelte Daten stichprobenartig für eine manuelle Prüfung herausziehen
- Automatische Labels mit einem „Goldstandard“-Datensatz abgleichen
- Übereinstimmungsmetriken zwischen Annotatoren nutzen, um die Konsistenz zu messen (Kili Technology)
So nutzen Sie Thunderbit für automatisiertes Data Labeling mit Machine Learning
Jetzt zur praktischen Umsetzung. Thunderbit ist ein KI-gestützter Web-Scraper und ein Data-Labeling-Tool für Anwender im Geschäftsalltag — ohne Programmierung. So automatisieren Sie damit Ihren Data-Labeling-Workflow:
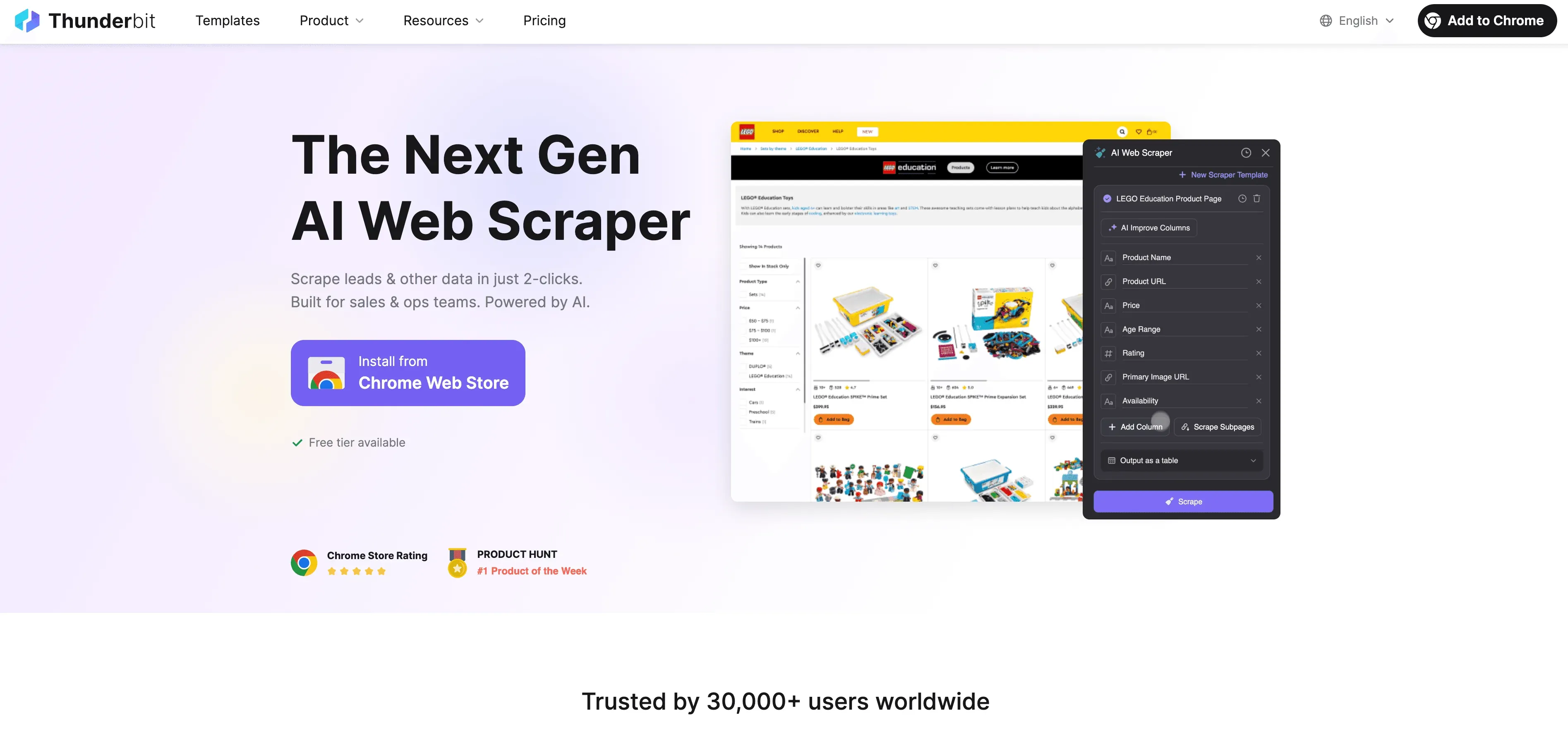
Schritt-für-Schritt-Anleitung
- Website-Daten scrapen: Verwenden Sie die Thunderbit Chrome-Erweiterung, um strukturierte Daten von jeder Website zu sammeln. Öffnen Sie einfach die Erweiterung, wählen Sie Ihre Datenquelle aus, und lassen Sie Thunderbits KI die passendsten Felder zur Extraktion vorschlagen.
- Label-Anweisungen definieren: Nutzen Sie Thunderbits Prompts in natürlicher Sprache, um der KI mitzuteilen, wie Ihre Daten gelabelt werden sollen. Zum Beispiel: „Alle Produkte über 500 $ als ‚Premium‘ labeln“ oder „Bewertungen mit positiver Stimmung markieren“.
- Automatisches Labeling anwenden: Mit Thunderbits Field-AI-Prompt-Funktion passen Sie an und verfeinern, wie die Labels vergeben werden — ideal für mehrfeldrige oder komplexe Labeling-Aufgaben.
- Gelabelte Daten exportieren: Sind Ihre Daten gelabelt, exportieren Sie sie direkt nach Excel, Google Sheets, Airtable oder Notion — bereit für Modelltraining oder Analyse.
Das Beste daran? Thunderbit ist auf nicht-technische Anwender in Vertrieb, Marketing, Operations und weiteren Bereichen zugeschnitten. Sie schreiben keine einzige Zeile Code und müssen sich nicht mit komplizierten Templates abmühen.
Thunderbit für automatisiertes Data Labeling testen
Thunderbits Prompts in natürlicher Sprache und Field-AI-Funktionen
Eine meiner liebsten Funktionen ist die Möglichkeit, die Label-Logik in schlichtem Deutsch zu beschreiben. Sie möchten Leads nach Region einordnen, Produkte nach Kategorie verschlagworten oder E-Mails mit dringlichem Wortlaut markieren? Beschreiben Sie einfach, was Sie brauchen — den Rest erledigt Thunderbits KI.
Beispiel-Prompts:
- „Alle Kontakte mit einer .edu-E-Mail dem Segment ‚Bildung‘ zuordnen.“
- „Wenn die Bewertung ‚schneller Versand‘ erwähnt, als ‚Positive Versand-Erfahrung‘ taggen.“
- „Produkte nach Marke und Preisspanne gruppieren.“
Thunderbits Field-AI-Prompt erlaubt noch feinere Abstimmung — Sie steuern die Label-Logik für jede Spalte einzeln, kombinieren Regeln oder übersetzen Labels sogar in mehrere Sprachen.
Subpage-Scraping und Multi-Field-Labeling
Verschachtelte Datenstrukturen? Kein Hindernis. Mit Thunderbits Subpage-Scraping ziehen Sie Daten aus untergeordneten Seiten — etwa Produktdetails oder Autoren-Profile — extrahieren und labeln sie und führen alles in einer einzigen strukturierten Tabelle zusammen. So labeln Sie mehrere Felder in einem Durchgang — und sparen noch mehr Zeit.
Praxisbeispiel: Produktlisten von einer E-Commerce-Website scrapen, dann jeden Produktlink aufrufen, um Spezifikationen, Bewertungen und Verkäuferinformationen zu extrahieren und zu labeln — alles in einem einzigen Durchlauf.
Mehrere Data-Labeling-Tools für höhere Genauigkeit und Effizienz kombinieren
Thunderbit deckt bereits viel ab, doch für bestimmte Datentypen brauchen Sie mitunter spezialisierte Tools — etwa für Bildannotation oder Videolabeling. Hier kommen Plattformen wie Label Studio oder Supervisely ins Spiel.
Profi-Tipp: Setzen Sie Thunderbit für die Web-Datenextraktion und das erste Labeling ein und exportieren Sie Ihre Daten anschließend in Label Studio oder Supervisely für fortgeschrittene Annotationen — etwa Bounding Boxes bei Bildern oder Tags Bild für Bild bei Videos. Dieser Multi-Tool-Ansatz spielt die Stärken jeder Plattform aus und steigert sowohl Genauigkeit als auch Effizienz (GeeksforGeeks).
Wann Sie spezialisierte Tools zusätzlich zu Thunderbit einsetzen sollten
- Bildannotation: Für Aufgaben wie Objekterkennung oder Segmentierung greifen Sie zu Supervisely oder Label Studio.
- Videolabeling: Spezialisierte Video-Tools übernehmen Annotation und Tracking Bild für Bild.
- Komplexe Multi-Label-Aufgaben: Kombinieren Sie Thunderbits strukturierte Datenextraktion mit fortgeschrittenen Annotationstools für die besten Ergebnisse.
Bewährte Vorgehensweise: Starten Sie mit Thunderbit für schnelles, skalierbares Labeling strukturierter und semistrukturierter Daten und ziehen Sie bei Bedarf spezialisierte Tools für tiefergehende Annotationen hinzu.
Wie Sie Daten aus PDFs mit KI scrapen Erfahren Sie, wie Sie mit Thunderbits KI-gestützten Tools Daten aus PDFs extrahieren und labeln. Get Started Free
Best Practices für automatisiertes Data Labeling mit Machine Learning
Sie wollen das Maximum aus Ihrem automatisierten Labeling-Workflow herausholen? Hier meine wichtigsten Empfehlungen:
- Klare Label-Richtlinien festlegen: Mehrdeutige Labels führen zu uneinheitlichen Daten — definieren Sie genau, was jedes Label bedeutet.
- Mit einem hochwertigen Seed-Set starten: Labeln Sie von Hand eine kleine, repräsentative Stichprobe, um Ihr erstes Modell zu trainieren.
- Iterieren und nachschärfen: Nutzen Sie Active Learning, um Ihr Modell schrittweise zu verbessern, und konzentrieren Sie die menschliche Prüfung auf die kniffligsten Fälle.
- Regelmäßig validieren: Sehen Sie in festen Abständen eine Zufallsstichprobe gelabelter Daten durch, um Fehler oder ein Abdriften zu erkennen.
- Integrieren und automatisieren: Setzen Sie Tools wie Thunderbit ein, um Datenerfassung, Labeling und Export in einem einzigen Workflow zu verbinden.
Häufige Herausforderungen und wie Sie sie meistern
Ganz ohne Hürden geht automatisiertes Data Labeling nicht. So nehmen Sie die häufigsten in Angriff:
- Mehrdeutige Daten: Arbeiten Sie mit klaren, detaillierten Label-Definitionen und liefern Sie Beispiele für Sonderfälle.
- Abdriften des Modells: Trainieren Sie Ihr Labeling-Modell regelmäßig mit neuen, von Hand geprüften Daten nach.
- Sonderfälle: Richten Sie einen Prozess für die menschliche Prüfung unsicherer oder neuartiger Datenpunkte ein.
- Integrationsprobleme: Wählen Sie Tools wie Thunderbit, die einen reibungslosen Export in Ihre bevorzugten Plattformen ermöglichen.
Fazit und wichtigste Erkenntnisse
Automatisiertes Data Labeling mit Machine Learning ist die stille Zutat hinter den wirksamsten KI-Modellen unserer Zeit. Es spart Zeit, senkt Kosten und liefert vor allem die einheitlichen, hochwertigen Labels, die Ihre Modelle für Spitzenleistungen brauchen. Kombinieren Sie Tools wie Thunderbit mit spezialisierten Annotation-Plattformen, bauen Sie sich einen Labeling-Workflow, der schnell, präzise und skalierbar ist — unabhängig von Ihrem technischen Hintergrund.
Sie möchten den Unterschied selbst erleben? Laden Sie Thunderbit herunter, testen Sie automatisiertes Labeling in Ihrem nächsten Projekt und sehen Sie, wie Ihre Machine-Learning-Modelle klüger und schneller werden. Und wenn Sie Lust auf weitere Tipps und bewährte Vorgehensweisen haben, schauen Sie im Thunderbit-Blog vorbei — dort warten ausführliche Analysen und Tutorials.
Data Labeling mit Thunderbit automatisieren
FAQs
1. Was ist automatisiertes Data Labeling mit Machine Learning?
Dabei labeln KI- und ML-Modelle die Daten automatisch, statt dass Menschen das von Hand erledigen. Dieser Ansatz beschleunigt das Labeling, sorgt für mehr Konsistenz und skaliert auf große Datensätze.
2. Warum ist die Qualität des Labelings für Machine Learning wichtig?
Ein Modell lernt nur die Muster, die in seinen Labels stecken. Uneinheitliche oder falsche Labels bringen ihm also das Falsche bei. Branchenbeiträge von Labeling-Anbietern wie Keylabs zeigen, dass hybride Workflows aus KI und Mensch die Labeling-Genauigkeit gegenüber rein manuellen Verfahren um bis zu 80 % steigern können — und dieser Zugewinn schlägt sich direkt in der Modellleistung nieder.
3. Wie hilft Thunderbit beim automatisierten Data Labeling?
Mit Thunderbit scrapen und labeln Sie Webdaten per KI — mit Prompts in natürlicher Sprache und anpassbarer Feldlogik, ganz ohne Programmierung. Es eignet sich bestens für Anwender in Vertrieb, Marketing und Operations.
4. Kann ich Thunderbit mit anderen Labeling-Tools kombinieren?
Auf jeden Fall. Nutzen Sie Thunderbit für die strukturierte Datenextraktion und das erste Labeling und exportieren Sie anschließend in Tools wie Label Studio oder Supervisely für fortgeschrittene Bild- oder Videoannotation.
5. Was sind die Best Practices für automatisiertes Data Labeling?
Legen Sie klare Label-Richtlinien fest, starten Sie mit einem hochwertigen Seed-Set, iterieren Sie mit Active Learning, validieren Sie regelmäßig und nutzen Sie integrierte Tools, um Ihren Workflow zu vereinfachen.
Bereit, Ihr Data Labeling zu automatisieren und Ihre Machine-Learning-Projekte auf das nächste Level zu heben? Probieren Sie Thunderbit aus und überzeugen Sie sich selbst, wie viel Zeit — und Frust — Sie sich sparen.
Mehr erfahren:
- Wie Sie Daten aus PDFs mit KI scrapen
- Was ist Data Scraping und wie macht man es 2025?
- Was ist List Crawling und wie macht man es mit KI?
- Wie Sie jede Website mit KI scrapen
KI-Web-Scraper für automatisiertes Data Labeling testen Get Started Free




