IDCrawl 爬蟲
深受頂尖公司的專業人士信任











保持可用的 IDCrawl 資料
使用 IDCrawl 搭配 Thunderbit,更快、更乾淨、也更大規模地擷取資料。
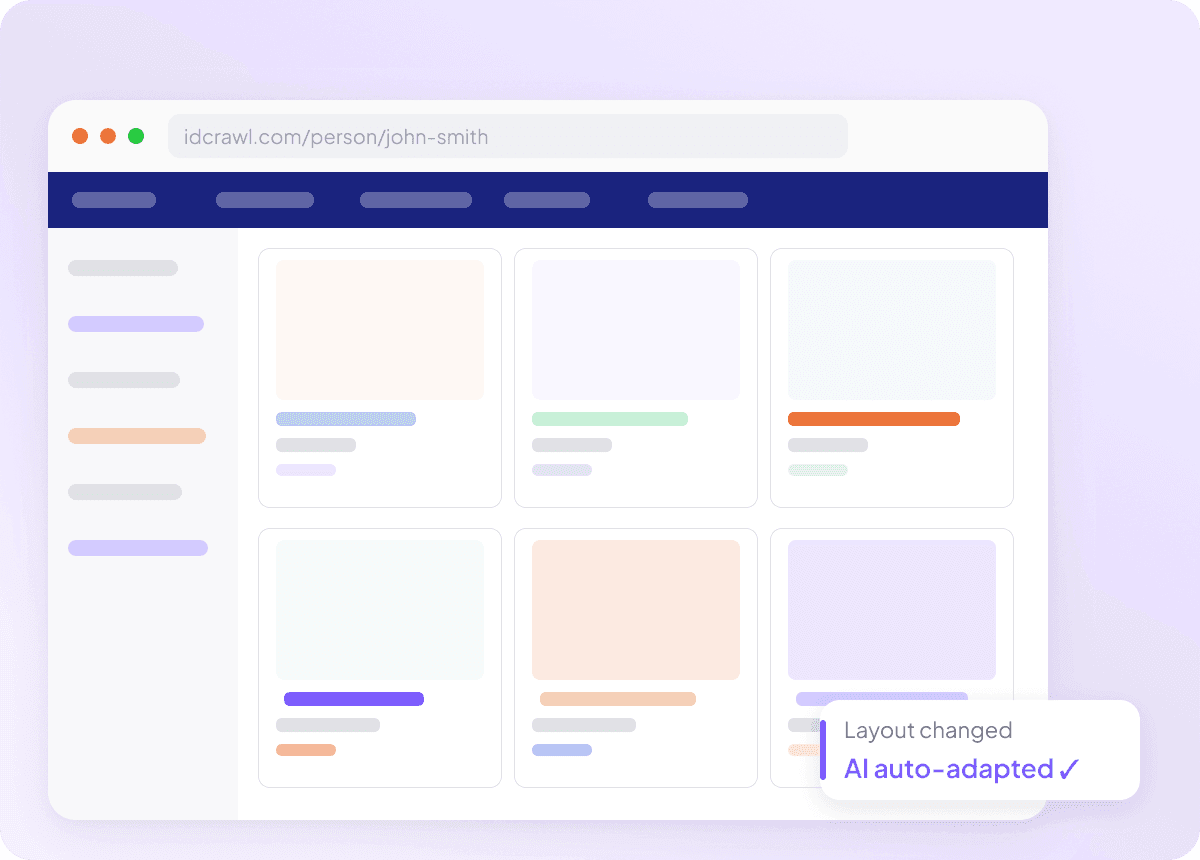
IDCrawl 版面一變也能自動適應
如果每次網站更新後爬蟲就失效,那就毫無用處,尤其當您想從 IDCrawl 擷取完整姓名、職稱、公司名稱、電子郵件地址、電話號碼與 LinkedIn 個人檔案時更是如此。Thunderbit 是依照頁面語意來讀取,而不是依賴固定選擇器,因此當版面調整時也能自動適應。您就能少花時間修爬蟲,把更多時間用在取得真正需要的資料。
從一開始就有乾淨資料
原始資料只是實際工作的起點,而 IDCrawl 的結果在可用之前,通常都需要整理。Thunderbit 會在擷取過程中直接結構化與格式化資料,因此匯出的內容本來就是乾淨可用的。這代表更少的排序、更少的重工,也能更順利交給團隊接手。
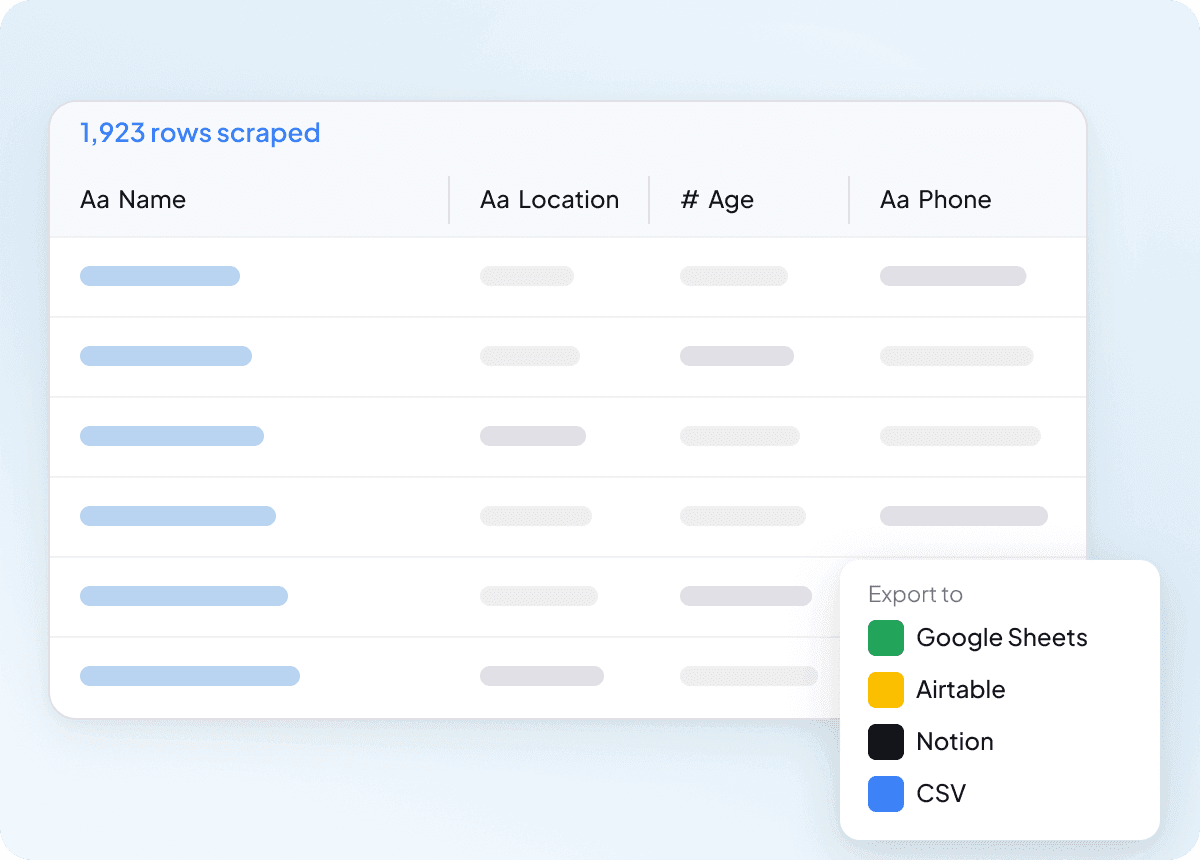
一次大量抓取 IDCrawl
當您需要一長串聯絡人名單時,一次只抓一個 IDCrawl 頁面並不具擴充性。Thunderbit 可以一次大量抓取數百個頁面,讓您直接提供一串 URL,並批次擷取其中的完整姓名、職稱、公司名稱、電子郵件地址、電話號碼與 LinkedIn 個人檔案。這是把大量清單轉成可用資料的更簡單方式。

Thunderbit 和傳統的 IDCrawl 爬蟲 有什麼不同?
一種更簡單的 IDCrawl 資料擷取方式,無需反覆修正。
傳統爬蟲
舊式作法Thunderbit AI
更聰明的作法不只聽我們怎麼說
看看使用者對 Thunderbit 的評價。






常見問題
相關 使用情境
探索 Thunderbit 網頁爬蟲的更多使用情境。
On the Beach 網頁爬蟲
Thunderbit 的 On the Beach 爬蟲能讓你快速擷取 On the Beach 上的度假與飯店清單、價格、評分等資訊。透過 AI 智慧欄位建議,輕鬆收集並整理旅遊數據,方便分析、比價或規劃行程。非常適合旅遊業者、數據分析師與度假規劃者使用。
了解更多 ->
Trustpilot 爬蟲
將 Trustpilot 頁面轉換成乾淨的試算表,整理出評論、評分與評論者名稱。我們幫您逐頁讀取,無需寫程式,也不用複製貼上。
了解更多 ->
Herold 爬蟲
Thunderbit Herold 爬蟲讓你只需兩下就能從 Herold 的企業與個人搜尋結果中擷取資料。透過 AI 智慧欄位建議,快速收集公司名稱、地址、電話、電子郵件等資訊,無論是開發潛在客戶、資料研究還是行銷推廣都非常適合。特別適合銷售團隊、行銷人員與研究人員取得結構化的 Herold 資料。
了解更多 ->
Tieba 爬蟲
Thunderbit Tieba 爬蟲讓你輕鬆擷取百度貼吧的數據,包括熱門話題與論壇分類。透過 AI 智慧欄位建議,快速收集話題名稱、網址、貼文數量及用戶活躍度,無論是用於市場研究、行銷分析或內容創作都非常適合。特別適合分析 Tieba 上的社群趨勢與討論熱點。
了解更多 ->
UpCity 爬蟲
Thunderbit UpCity 爬蟲可協助你從 UpCity 的廣告代理商列表與服務評論中擷取資料。透過 AI 智能欄位建議,快速收集代理商名稱、地點、評分、聯絡方式及詳細評論內容,方便分析與研究。非常適合行銷人員、研究者及企業主取得結構化的 UpCity 資料。
了解更多 ->
United Airlines 爬蟲
只要點選幾下,就能擷取 United Airlines 航班資料,例如航班編號、抵達時間與出發機場;其餘工作交給 Thunderbit AI 搞定。
了解更多 ->準備好讓資料擷取火力全開了嗎?
加入 100,000+ 已在使用 Thunderbit 自動化網頁爬取流程的專業人士行列。
免費試用可為 8 個網頁提供無限額度。