Thunderbit 的 FlexJobs 爬蟲 透過 AI,能把 FlexJobs 頁面快速整理成乾淨、可用的結構化資料集。你可以抓取遠端職缺清單與職涯建議文章,並使用 子頁面爬取,為每一列補上完整職缺內容或文章全文。最後可在幾分鐘內透過 匯出到 Excel、Google Sheets、Airtable 或 Notion。
🤖 什麼是 FlexJobs 爬蟲
AI 驅動的 FlexJobs 爬蟲 是一款 ,可從 擷取資料並整理成表格,讓你下載或同步到常用工具。操作方式很直覺:打開你要的頁面(例如職缺目錄或部落格),點選 AI Suggest Columns,再按 Scrape 即可。
它特別適合真實工作情境:你往往不只需要列表頁上看得到的資訊。透過 子頁面爬取,Thunderbit 能逐一開啟每個職缺或文章頁,將更多欄位(例如完整描述、條件要求、分類、作者等)回填到同一份資料集中。
🧲 你可以用 FlexJobs 抓取哪些資料
FlexJobs 常被用來尋找 遠端工作、混合辦公職位 與 彈性工時機會,同時也提供豐富的職涯資源。使用 Thunderbit,你可以同時抓取職缺列表與內容頁,應用在研究、名單開發、招募營運與內容分析等情境。
🧑💻 抓取 FlexJobs 遠端職缺列表
你可以從 的職缺目錄抓取資料,建立包含職位、公司與職缺屬性的結構化資料庫。接著再爬取每個職缺的子頁面,補齊完整職務描述、條件要求與投遞資訊。
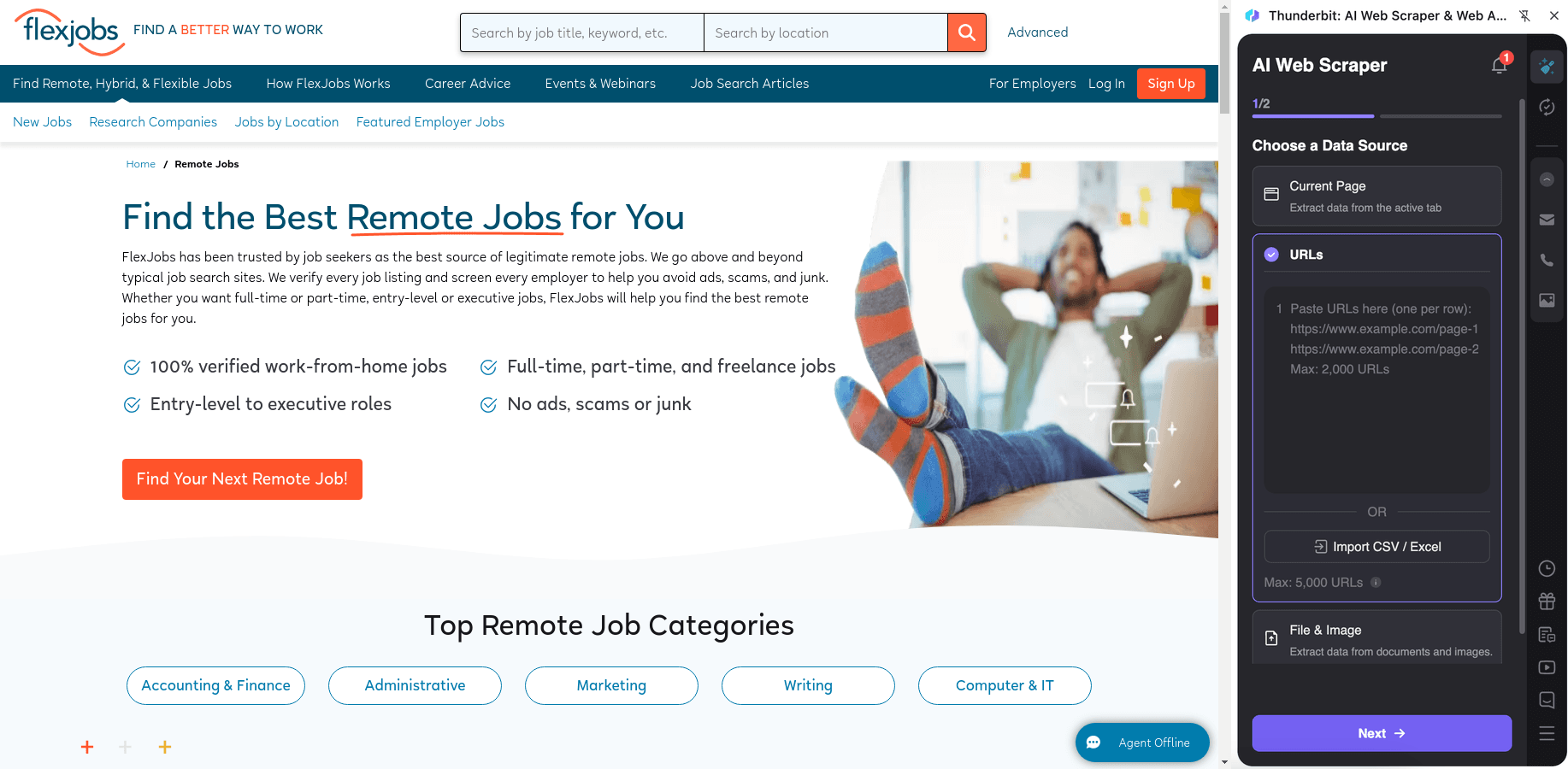
操作步驟:
- 下載 並註冊帳號。
- 前往目標頁面,例如:。
- 點選 AI Suggest Columns,自動產生建議欄位名稱與資料類型。
- 點選 Scrape 開始抓取,完成後匯出到 Excel、Google Sheets、Airtable 或 Notion。
欄位名稱
| 欄位 | 說明 |
|---|---|
| 🧾 職缺名稱 | 結果列表頁上顯示的職位標題。 |
| 🏢 公司 | 雇主或招募公司名稱(若有提供)。 |
| 📍 地點/遠端類型 | 地點資訊,例如遠端、僅限美國、州別限制或城市/州。 |
| 🕒 工作型態 | 全職、兼職、自由接案、合約、短期等。 |
| 🧩 類別/職涯層級 | 列表中顯示的職缺分類與/或資歷層級。 |
| 🗓️ 刊登日期 | 職缺發布或最後更新日期(若有顯示)。 |
| 🔗 職缺 URL | 連到職缺詳情頁的連結,用於子頁面爬取。 |
| 📝 簡短摘要 | 列表頁上的摘要/預覽文字。 |
| 🧠 技能/關鍵字 | 列表中顯示的技能或標籤(若有)。 |
| 📄 完整職務描述(子頁面) | 從職缺詳情頁擷取的完整職務內容。 |
| ✅ 條件要求(子頁面) | 從職缺詳情頁擷取的資格/條件。 |
| 📬 如何應徵(子頁面) | 可取得的投遞說明或申請連結資訊。 |
📚 抓取 FlexJobs 職涯建議文章
你可以抓取 的文章列表,蒐集文章中繼資料,用於內容研究、SEO 分析或建立內部知識庫。再透過子頁面爬取,擷取文章全文、段落標題與作者資訊。
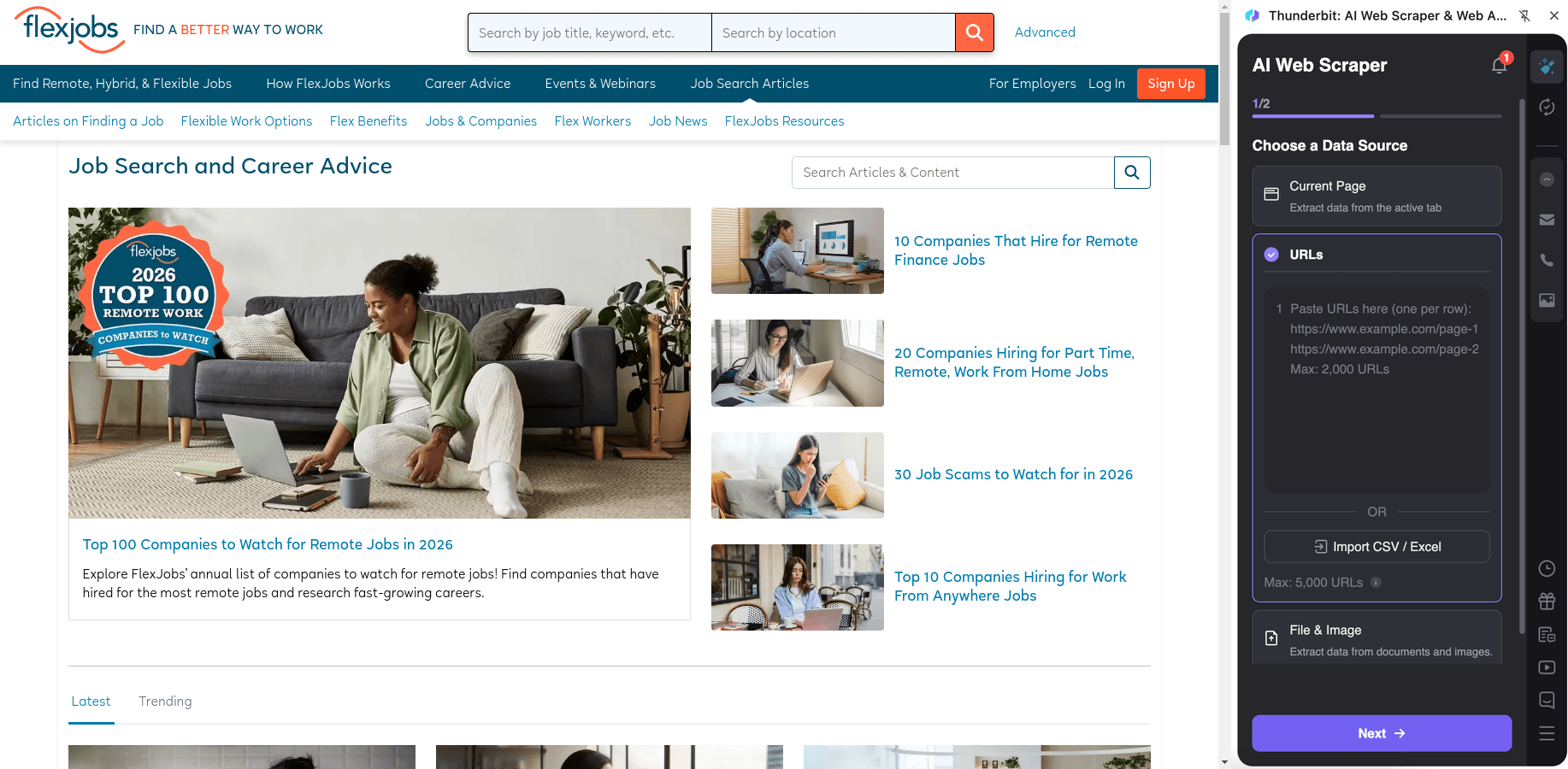
操作步驟:
- 下載 並註冊帳號。
- 前往目標頁面,例如:。
- 點選 AI Suggest Columns,自動產生建議欄位名稱與資料類型。
- 點選 Scrape 擷取資料,完成後匯出到 Excel、Google Sheets、Airtable 或 Notion。
欄位名稱
| 欄位 | 說明 |
|---|---|
| 📰 文章標題 | 部落格文章的標題。 |
| 🔗 文章 URL | 文章頁連結,用於子頁面爬取。 |
| ✍️ 作者 | 頁面上顯示的作者名稱(若有)。 |
| 🗓️ 發布日期 | 文章發布日期。 |
| 🏷️ 分類/標籤 | 部落格分類或標籤(列表或子頁面若有顯示)。 |
| 🧷 摘要 | 文章列表頁上的簡短預覽文字。 |
| 🖼️ 精選圖片 URL | 文章主圖連結(若有)。 |
| 🧾 文章全文(子頁面) | 從文章頁擷取的完整內容。 |
| 🔠 段落標題(子頁面) | 擷取 H2/H3 標題,用於大綱與分析。 |
| ⏱️ 閱讀時間(選填) | 若頁面提供,則擷取預估閱讀時間。 |
🎯 為什麼要使用 FlexJobs 爬蟲工具
抓取 FlexJobs 的資料,能支援多種需要結構化資料的團隊與流程。
- 招募與人才營運:依分類、地點限制與工作型態建立可搜尋的遠端職缺管道,追蹤趨勢並與團隊共享一致的資料集。
- 業務與合作夥伴開發:找出正在招募遠端職位的公司,並依產業、招募速度與職位類型強化名單。
- 職涯教練與內容創作者:蒐集就業市場訊號,將職涯建議文章整理成內容資料庫,用於電子報、課程或教練方案。
- 行銷與 SEO 團隊:分析 FlexJobs 部落格主題、發文節奏與內容結構,協助規劃自家內容策略。
- 電商營運與分析(沒錯,也適用):若你經營職缺平台、人力媒合市場或 HR 產品,可用抓取到的職缺資料做競品研究與分類體系(taxonomy)建置。
Thunderbit 專為追求速度與穩定性的商務使用者打造,不需要維護脆弱的爬蟲腳本。當頁面版型變動時,AI 會重新理解頁面並自動調整。
🧩 如何使用 FlexJobs Chrome 擴充功能
- 安裝 Thunderbit Chrome 擴充功能:到 下載並建立帳號。
- 前往 FlexJobs 頁面:職缺用 ,文章用 。
- 啟用 AI 驅動爬取:點選 AI Suggest Columns 產生欄位,必要時可調整欄位名稱與資料類型(文字、日期、URL、圖片等)。
- 抓取列表並用子頁面補強:先對列表頁按 Scrape,再用 Scrape Subpages 把完整職缺細節或文章全文補進同一張表。
如果你剛開始接觸資料抓取,以下資源會很有幫助:
- 更多教學請見
💳 FlexJobs 爬蟲的收費方式
Thunderbit 採用簡單的點數(credit)制度:
- 1 點 = 結果表格中的 1 列輸出(例如一筆職缺或一篇文章)。
- 匯出資料免費:可匯出到 Excel、Google Sheets、Airtable 或 Notion,或下載 CSV/JSON。
你可以先從 Free 方案開始,每月可抓取 6 個頁面。若啟用免費試用,還能 免費抓取 10 個頁面,很適合在升級前先測試職缺分頁與子頁面補強流程。
付費方案會依你的工作量擴充:
- Starter 適合輕量抓取與一次性專案。
- Pro 等級更適合持續性的招募營運、職缺市場監測與內容追蹤。
- 年繳方案 通常最划算,因為相較月繳有折扣。
你可以在 查看各方案細節。
❓ 常見問題
-
什麼是 AI Powered FlexJobs Scraper?
AI Powered FlexJobs Scraper 是 Thunderbit 的一套工作流程,可將 FlexJobs 的職缺與部落格文章擷取成結構化的列與欄。它透過 AI 理解頁面版型,因此能快速抓取並得到乾淨欄位,例如標題、公司、地點與 URL。
你也可以用子頁面爬取補齊完整職務描述或文章全文。 -
Thunderbit 是什麼?
是一款 AI 網頁爬蟲 Chrome 擴充功能,可將網站、PDF 與圖片中的資料整理成結構化表格。它面向名單開發、招募、電商營運與市場研究等商務情境打造。
一般流程是點 AI Suggest Columns 再點 Scrape,需要時 Thunderbit 也能處理分頁與子頁面。 -
抓取 FlexJobs 需要會寫程式嗎?
不需要。Thunderbit 針對非技術流程設計,你不必使用 Python、選擇器或自建爬蟲基礎設施。
只要會開頁面並點幾個按鈕,就能建立資料集。 -
Thunderbit 可以抓取每個職缺頁的完整細節嗎?
可以。先抓取列表頁後,你可使用 子頁面爬取 逐一開啟職缺 URL,擷取更深入的欄位,例如完整描述、條件要求與投遞說明。
當列表頁只顯示簡短摘要時,這個功能特別實用。 -
Thunderbit 如何處理 FlexJobs 的分頁與無限捲動?
Thunderbit 支援「點下一頁」的分頁模式與無限捲動(infinite scroll)兩種情境,可在一次執行中抓取多頁資料,適合蒐集大量職缺。
若你選用 Cloud Scraping,Thunderbit 可在雲端快速批次處理(常見可一次到 50 頁,實際仍視網站行為而定)。 -
可以匯出成哪些格式?
你可以把資料匯出到 Excel、Google Sheets、Airtable 或 Notion,也能下載 CSV 或 JSON。
匯出本身免費,你可以把預算用在抓取量,而不是檔案存取。 -
FlexJobs 的 Cloud Scraping 與 Browser Scraping 有什麼差別?
Browser Scraping 會在你的 Chrome 工作階段中執行,若網站需要登入或依帳號顯示個人化內容會更合適。Cloud Scraping 則在 Thunderbit 的雲端基礎設施上執行,通常抓取公開頁面更快。
若你要抓取依賴帳號狀態的頁面,通常建議選 Browser Scraping。 -
我可以抓取多少列?「500 max rows」代表什麼?
「max rows」(例如 500)是單次執行的實務建議值,會依頁面結構與你的設定而不同。實際可抓取量取決於分頁深度、點數,以及是否啟用子頁面補強。
由於 1 點等於 1 列輸出,你可以用預計蒐集的職缺或文章數量來估算成本。 -
抓取 FlexJobs 資料可以嗎?
請務必遵守 FlexJobs 的使用條款、尊重隱私,並符合適用的法律與規範。Thunderbit 提供的是資料擷取與結構化工具,但你需要對使用方式負責。
若不確定,建議先小量測試,並確認用途符合你的合規要求。
📘 了解更多
- 取得擴充功能:
- 產品介紹:
- 方案與價格:
- 抓取入門:
- 匯出到試算表:
- 用 AI 更聰明地抓取:
- 教學影片: