

網頁爬蟲現在已經是現代企業團隊的必備工具了——不管你是做銷售、營運還是行銷,只要能夠快速從網路上抓到資料,專案成功的機會就大大提升。隨著數據驅動決策成為主流,大家對工具的要求也越來越高,不只要快,還要夠穩、夠能擴充。這時候,Rust 這個現代程式語言在網頁爬蟲領域默默崛起,特別適合追求速度和安全性的團隊。
這可不是隨便說說——Rust 已經連續好幾年在 Stack Overflow 開發者調查 被選為「最受歡迎程式語言」,而且在後端和數據工程領域的應用也越來越多。但對商業用戶來說,「用 Rust 做網頁爬蟲」到底有什麼特別?又跟像 Thunderbit 這種專為非技術團隊設計的無程式碼解決方案有什麼差別?接下來我們用最簡單的方式說明——就算你沒寫過程式也能看懂。
什麼是 Rust 網頁爬蟲?基礎概念說明
簡單來說,網頁爬蟲就是自動幫你從網站上抓資料。你可以把它想像成一個數位小幫手,幫你逛遍上百上千個網頁,把你要的資訊(像是商品價格、聯絡方式、評論等等)整理好帶回來。對需要即時數據的企業來說,這真的超省時省力,不管是開發潛在客戶、做市場調查還是監控價格都很實用。
Rust 是一種以高效能、記憶體安全和穩定性著稱的系統程式語言。跟傳統語言比起來,Rust 能在程式跑之前就抓出很多錯誤,減少 bug 和效能問題。用 Rust 寫網頁爬蟲,代表你可以打造超快又不容易當機、記憶體不會亂噴的工具——這對大規模抓資料來說特別重要。
不只開發者受益,Rust 的優勢也能讓商業用戶直接感受到。更快、更安全的爬蟲,代表你能拿到更新鮮的數據、減少錯誤,讓團隊有更可靠的洞察。
為什麼選 Rust 來做網頁爬蟲?商業用戶的關鍵優勢
那為什麼越來越多團隊考慮用 Rust 來做網頁爬蟲?尤其 Python 和 JavaScript 已經紅很久了。這裡幫你整理 Rust 幾個超有感的優勢:
- 效能超強: Rust 會直接編譯成機器碼,速度遠遠贏過 Python 或 JavaScript 這種直譯語言。當你要大規模抓資料(像是幾百萬頁面)時,這種速度優勢直接變成商業價值。
- 記憶體安全: Rust 有獨特的記憶體管理(沒有垃圾回收、嚴格所有權規則),大大降低程式當掉或出錯的機率。你的爬蟲任務不容易半路失敗,省時又省心。
- 超穩定: Rust 編譯器會嚴格檢查型別和錯誤處理,很多問題在程式跑之前就能發現,讓爬蟲流程更穩定、可預期。
- 並行處理: Rust 讓你更容易寫出同時處理多任務的程式(下一段會細講),對需要同時抓很多頁面的情境特別有感。
那跟 Python 或 JavaScript 比呢?雖然這些語言上手快,但遇到大規模應用時,效能和穩定性常常卡關。Rust 的技術優勢,讓你能更快、更大量地收集資料,減少麻煩,讓企業在競爭中搶得先機。
Rust 的非同步優勢:高效大規模網頁爬蟲
Rust 最厲害的地方就在於:非同步程式設計(async programming)。簡單說,非同步讓你的爬蟲可以同時對很多網站發送請求,不用等一個結束才開始下一個。當你要快速收集大量資料時,這就是關鍵。
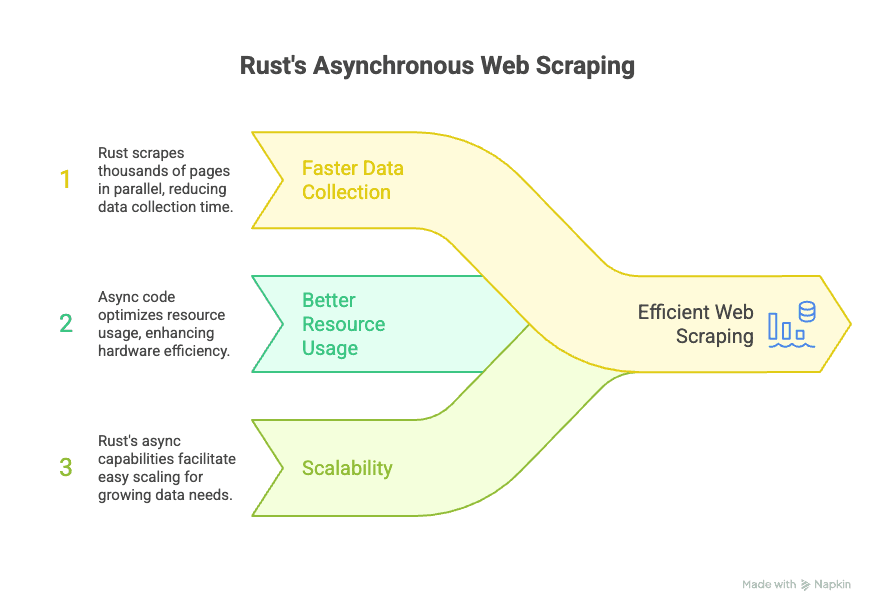
Rust 的非同步生態系由 Tokio 和 async-std 這些函式庫支撐,讓你的爬蟲可以同時處理上千個請求,主程式不會卡住。對商業用戶來說,這代表:
- 資料收集更快: 可以同時抓成千上萬個頁面,建資料集的時間大幅縮短。
- 資源運用更有效率: 非同步程式更省硬體資源,用更少設備就能做更多事。
- 高度擴展性: 隨著資料需求成長,Rust 的非同步能力讓你輕鬆擴充,不用重寫流程。
實際應用上,這讓你的團隊能即時回應市場變化、監控競爭對手或快速產生潛在客戶名單,不用再等好幾小時甚至幾天才能拿到資料。
Rust 網頁爬蟲怎麼運作?流程簡介
想知道 Rust 網頁爬蟲的基本流程嗎?這裡用最簡單的步驟說明:
- 設定目標: 先決定你要抓哪些資料、從哪些網站擷取。
- 抓取網頁: 用 Reqwest 這類函式庫發送 HTTP 請求,把網頁內容抓下來。
- 解析內容: 用 Scraper 或 Select 這些工具,從 HTML 裡擷取你要的資訊(像商品名稱、價格、Email 等)。
- 處理分頁/子頁面: 寫邏輯自動瀏覽多頁內容或點連結進入子頁面(下一段會細講)。
- 匯出資料: 把抓到的資料存成結構化格式(像 CSV、Excel 或直接寫進資料庫),方便團隊後續使用。
每個函式庫各有分工:Reqwest 負責「抓取」,Scraper/Select 負責「解析」,資料匯出則可以用 Rust 內建功能或第三方套件搞定。
應對複雜網站:Rust 處理分頁與子頁面的方式
很多商業爬蟲任務不只是單頁抓資料,還可能需要:
- 從多頁商品目錄抓所有產品
- 收集分散在多個子頁面的評論
- 從多層目錄中取得聯絡資訊
Rust 在這方面表現很強。它的型別系統和錯誤處理機制,讓你更容易寫出能:
- 自動偵測並點「下一頁」或分頁連結
- 拜訪子頁面(像商品詳情、作者簡介)並把資料合併到主資料集
- 優雅處理異常狀況(像頁面遺失、連結失效),避免爬蟲中斷
舉例來說,一個 Rust 爬蟲可以從主商品列表頁開始,依序點分頁連結,再進每個商品的詳情頁,完整收集價格、描述和評論。最後,你就能拿到一份即時、完整的資料集,方便後續分析。
Thunderbit vs. Rust 程式碼:商業團隊的無程式碼優勢
說到現實問題:不是每個人都有時間或技術力從零寫一個 Rust 爬蟲。這時候,Thunderbit 就超好用。
Thunderbit 是一款人工智慧驅動的無程式碼網頁爬蟲,專為商業用戶設計。你只要:
- 開啟 Thunderbit Chrome 擴充功能
- 前往你想抓資料的網站
- 點「AI 建議欄位」,讓 Thunderbit 的 AI 自動推薦可擷取的資料
- 按「開始爬取」,就能直接把結果匯出到 Excel、Google Sheets、Airtable 或 Notion
完全不用模板、不用寫程式、也不用維護。Thunderbit 甚至能自動處理分頁和子頁面擷取——就像自訂的 Rust 爬蟲,但你只要點幾下滑鼠。
什麼時候該選 Thunderbit?如何挑選合適工具
那到底什麼情境該用哪種工具?這裡有一份快速對照表:
| 情境 | Thunderbit | Rust |
|---|---|---|
| 快速產生銷售名單 | ✅ 最簡單、最快速 | 可行,但太複雜 |
| 電商競品價格監控 | ✅ 無程式碼、可排程 | ✅ 適合自訂整合 |
| 複雜自訂流程爬取 | 有機會,但有限制 | ✅ 完全掌控、高度自訂 |
| 大型資料管道整合 | 有 API 可串接 | ✅ 深度整合最佳選擇 |
| 非技術用戶(銷售、營運、行銷) | ✅ 專為你設計 | ❌ 需程式能力 |
| 快速原型或臨時任務 | ✅ 兩步完成 | 可行,但啟動較慢 |
簡單說:Thunderbit 適合想要快速、穩定抓資料、又不想碰技術細節的商業用戶。Rust 則適合需要高度自訂、複雜邏輯或大規模爬取的技術團隊。
實戰案例:Rust 網頁爬蟲應用情境
舉個實際例子。假設你是市場研究分析師,要收集某大型電商網站上所有筆記型電腦的資料。這網站有分頁(多頁商品),每個商品還有詳情頁,裡面有規格和評論。
用 Rust,你會這樣做:
- 用 Reqwest 抓主商品列表頁
- 用 Scraper 解析 HTML,抓每個商品連結
- 偵測並點「下一頁」連結,抓所有分頁
- 進每個商品詳情頁,抓規格和評論
- 妥善處理錯誤(像頁面遺失),必要時重試
- 最後把資料匯出成 CSV 或上傳到分析平台
這樣你就能拿到一份完整、即時的市場資料,幫助訂價、庫存和行銷決策。
Rust 網頁爬蟲的挑戰與注意事項
當然,就算 Rust 很強,網頁爬蟲還是有一些常見挑戰,這裡幫你整理重點(還有 Rust 怎麼幫得上忙):
- 網站結構變動: 網站版型一改,爬蟲就可能失效。Rust 的嚴格型別檢查能提早發現問題,但還是要定期維護程式。
- 反爬蟲機制: 很多網站會用驗證碼或流量限制。Rust 的高效能有助於降低被偵測風險,但有時還是要加延遲或代理伺服器。
- 資料格式不一: 網頁資料常常很亂,Rust 強大的解析工具能幫你處理各種不規則 HTML。
- 維護成本: 自訂爬蟲需要持續維護。對商業用戶來說,這代表要和技術團隊密切合作,或考慮用 Thunderbit 這種無程式碼工具來處理日常任務。
2025 年資料擷取是什麼?如何操作? Get Started Free
小提醒: 不管你用 Rust 還是 Thunderbit,抓資料時都要遵守網站服務條款和相關隱私法規。
結論:用 Rust(及更多工具)釋放網頁爬蟲的商業價值
在這個數據驅動的時代,網頁爬蟲已經是企業不可或缺的能力。Rust 以超強效能、安全性和穩定性,成為需要自訂、大規模爬取解決方案團隊的首選,尤其在速度和穩定性不能妥協時更顯重要。但對多數商業用戶來說,技術門檻還是有點高。
這時,Thunderbit 就是最佳解方:它讓每個人都能輕鬆用上網頁爬蟲,AI 驅動、無程式碼介面,連複雜的分頁和子頁面擷取都能自動搞定。不管你是銷售開發名單、電商價格監控,還是市場情報分析,Thunderbit 都能讓你快速拿到所需資料。
重點整理:
- Rust 適合需要高度自訂、大規模爬取的技術團隊。
- Thunderbit 讓非技術用戶也能輕鬆用上網頁爬蟲。
- 根據需求選工具:要深度自訂選 Rust,追求效率和簡單選 Thunderbit。
使用 AI 從任何網站抓取資料 Get Started Free
想體驗網頁爬蟲的便利嗎?馬上下載 Thunderbit,感受資料擷取的輕鬆和高效。如果你準備好打造專屬解決方案,也可以深入探索 Rust 的高效能爬蟲生態系。
體驗人工智慧網頁爬蟲 Get Started Free
常見問答
1. 什麼是 Rust 網頁爬蟲?跟其他語言有什麼不同?
Rust 網頁爬蟲就是用 Rust 程式語言自動化網站資料擷取。跟 Python 或 JavaScript 比,Rust 速度快、記憶體安全又穩定,特別適合大規模或高要求的爬蟲任務。
2. Rust 適合非技術商業用戶嗎?
Rust 功能很強,但需要寫程式。對非技術用戶來說,像 Thunderbit 這種無程式碼、AI 驅動的工具,讓資料擷取變得人人都能上手。
3. Rust 怎麼處理分頁或子頁面等複雜爬蟲任務?
Rust 的型別系統和非同步函式庫,讓你能輕鬆寫出自動瀏覽分頁、跟子頁面連結並處理錯誤的程式,確保資料集完整又可靠。
4. 什麼時候該用 Thunderbit,而不是自訂 Rust 爬蟲?
當你需要快速、簡單的資料擷取,不想寫程式時,Thunderbit 是最佳選擇,特別適合銷售、行銷和營運團隊。要高度自訂、大規模或深度整合,則建議選 Rust。
5. Rust 網頁爬蟲的主要挑戰有哪些?該怎麼應對?
常見挑戰有網站結構變動、反爬蟲機制和持續維護。Rust 的安全機制能提早發現錯誤,但網站變動時還是要更新程式。對日常商業爬蟲,無程式碼工具如 Thunderbit 能大幅減少維護負擔。
延伸閱讀:




