

如果您曾經試著從網站或舊式軟體中擷取資料,卻覺得自己像在玩數位打地鼠,那您絕對不是唯一一個。在今天這個資料驅動的世界裡,銷售、行銷、營運等團隊都渴望取得洞察——但許多有價值的資訊都被藏在複雜介面、老舊系統,或根本不太合作的網站後面。雖然大家都聽過網頁爬蟲工具,但其實還有另一種技術,數十年來一直默默支撐著資料擷取:螢幕爬取。它有點老派、有點常被誤解,而且因為新一代 AI 工具的出現,如今比以往更有關聯性。
讓我們深入了解螢幕爬取到底是什麼、它和您可能熟悉的網頁爬取有什麼不同,以及為什麼它已經成為企業追逐難以取得資料時的秘密武器。我也會示範像 Thunderbit 這類現代工具,如何讓螢幕爬取不再只屬於開發者或 IT 專業人士,而是人人都能上手。相信我,如果您曾經想在幾秒內複製貼上一大堆資料(但又不是真的複製貼上),這篇文章您一定會想看下去。
螢幕爬取是什麼?與網頁爬取有何不同?
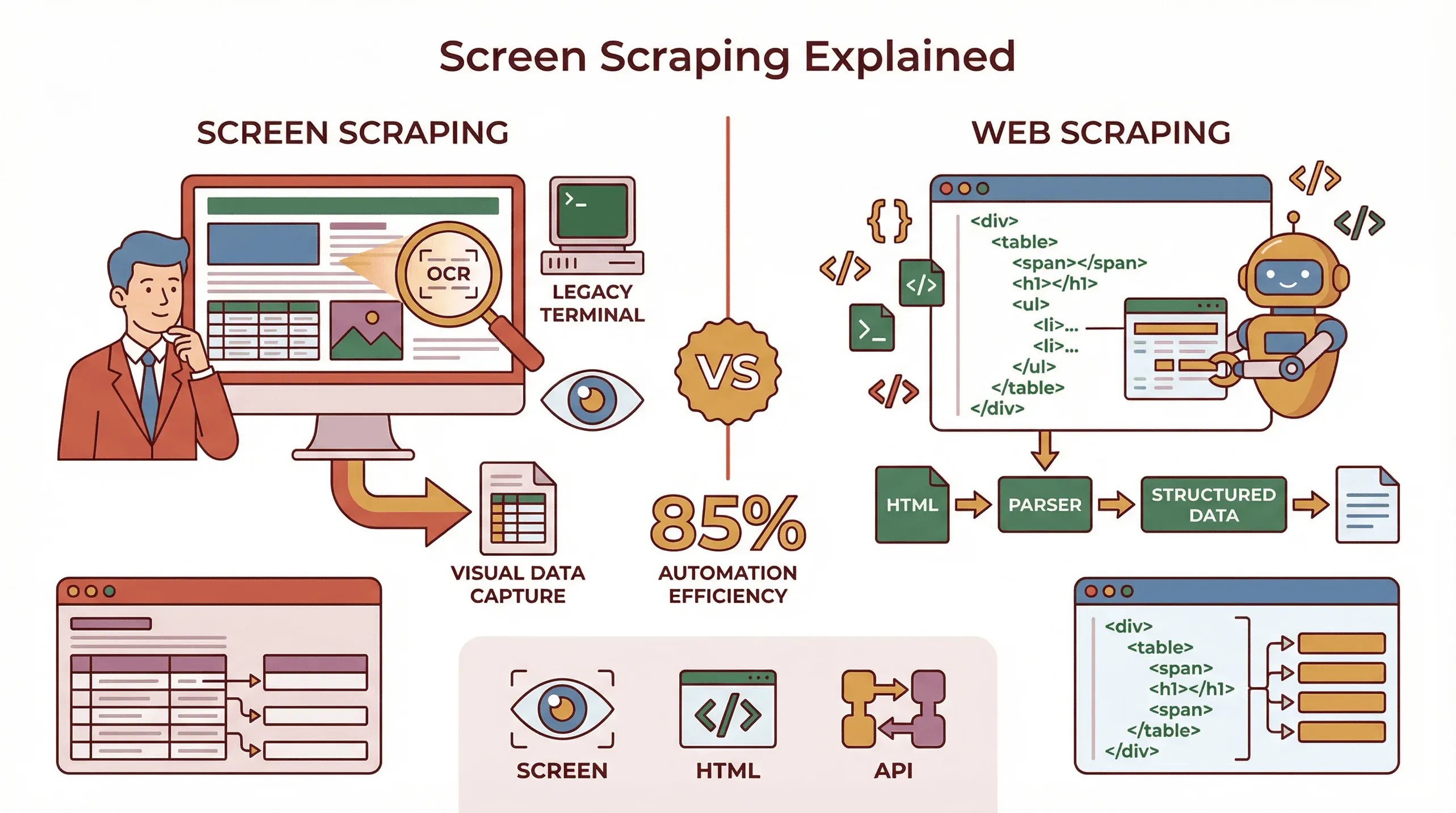 螢幕爬取可以說是數位版的「看著電腦螢幕、讀取資訊,再把它輸入到別處」——只不過這一切都是自動化的。它是從螢幕上實際顯示的內容擷取資料的過程,不論那是網站、桌面應用程式,甚至是終端機視窗。不同於傳統的網頁爬取直接深入網頁背後的 HTML 程式碼,螢幕爬取擷取的是顯示輸出——也就是人眼看得到的內容,而不只是程式碼裡的東西 (ScrapeHero)。
螢幕爬取可以說是數位版的「看著電腦螢幕、讀取資訊,再把它輸入到別處」——只不過這一切都是自動化的。它是從螢幕上實際顯示的內容擷取資料的過程,不論那是網站、桌面應用程式,甚至是終端機視窗。不同於傳統的網頁爬取直接深入網頁背後的 HTML 程式碼,螢幕爬取擷取的是顯示輸出——也就是人眼看得到的內容,而不只是程式碼裡的東西 (ScrapeHero)。
螢幕爬取的起源可以追溯到老舊系統的年代——像是舊式大型主機、綠底終端機,或從未聽過 API 的銀行系統。那時候如果您想把資料拿出來,就得模擬使用者:登入、操作選單,然後「讀取」螢幕上出現的內容。今天,螢幕爬取仍然用在這些老系統上,但它也成為現代網頁資料擷取的重要備援方案,尤其是在網站視覺上很複雜,或刻意阻擋傳統爬蟲時特別有用 (TechTarget)。
主要差異:
- 螢幕爬取:自動化處理使用者看得到的內容——擷取螢幕、應用程式或網頁上顯示的文字、圖片或表格。也可以使用 OCR(光學字元辨識)從圖片或 PDF 中擷取文字。
- 網頁爬取:處理網頁的 HTML 結構,透過標籤、class 與 ID 來抓取結構化資料。
- API 擷取:使用應用程式或網站提供的官方結構化資料來源(如果有的話)。
如果您曾經在網站上選取一個表格,然後貼到 Excel 裡,恭喜您——您其實做過手動螢幕爬取。現代的螢幕爬蟲只是把這個流程自動化並放大而已。
螢幕爬取在網頁資料擷取中的角色
什麼是資料爬取,以及如何在 2026 年完成 Get Started Free
那麼,螢幕爬取在現代網頁資料擷取中究竟扮演什麼角色?簡單來說:當其他工具搞不定時,它就是您會拿出的瑞士刀。
什麼時候需要螢幕爬取?
- 老舊或封閉系統:許多產業(金融、保險、醫療保健)仍仰賴早於 API 或匯出功能問世的軟體。螢幕爬取常常是進行資料遷移或分析的唯一方式 (UiPath)。
- 動態或視覺上複雜的網站:有些現代網站會用 JavaScript 載入內容、把資料藏在使用者互動後面,甚至把關鍵資訊渲染成圖片來阻擋爬蟲。螢幕爬取可以「看到」真正顯示出來的內容,而不只是程式碼裡的東西 (ScrapeHero)。
- 繞過 API 限制:當 API 受限、昂貴,或者根本不存在時,螢幕爬取可以補上缺口——直接從儀表板或報表抓取即時資料。
- 即時市場情報:銷售與行銷團隊常常需要的是現在就能用的資料,而不是等 IT 協商幾週後才拿得到。螢幕爬取讓他們能在看到資料的當下就把它抓下來 (Kanhasoft)。
螢幕爬取不一定是第一選擇——它可能比網頁爬取更脆弱、速度也更慢——但它通常是最靈活的,尤其是當您需要像使用者一樣「看到」資料時。
螢幕爬取、API 與網頁爬取:關鍵差異
我們用並排比較來拆解:
| 方法 | 運作方式 | 最適合 | 優點 | 缺點 |
|---|---|---|---|---|
| 螢幕爬取 | 讀取 UI 的可見輸出(螢幕、應用程式、網頁) | 老舊系統、動態 UI、圖片 | 能擷取使用者看得到的任何內容;當 API 或 HTML 解析失敗時仍可運作 | 對 UI 變動敏感;可能需要 OCR;速度較慢 |
| 網頁爬取 | 解析網頁的 HTML/DOM 結構 | 結構化網站、大量資料 | 快、精準、可處理大量內容 | HTML 一變就容易失效;難以應付動態內容 |
| API 擷取 | 使用官方資料端點(JSON、XML) | 有支援的應用程式/網站、即時資料流 | 最可靠、結構化、合法、快速 | 涵蓋範圍有限;可能需要驗證或付費 |
範例:
- API:從商店後端抓取商品價格(如果允許)。
- 網頁爬取:在 HTML 程式碼中找出價格。
- 螢幕爬取:讀取頁面上實際顯示的價格——即使它在圖片裡,或被彈出視窗遮住也一樣。
若想深入了解,請看 這份完整指南。
網頁爬取工具如何讓螢幕爬取更簡單
不久前,螢幕爬取還得寫腳本、和瀏覽器自動化工具纏鬥,或自己打造 RPA 機器人。那現在呢?現代的網頁爬取工具——尤其是由 AI 驅動的工具——讓螢幕爬取幾乎變得像叫外送一樣簡單。
現代工具的關鍵功能:
- 點選式介面:只要點一下您要的資料,工具就會自動判斷怎麼擷取。不用寫程式、不用選擇器、也不用頭痛 (ParseHub)。
- 自然語言指令:直接描述您想要什麼(例如「取得所有商品名稱與價格」),AI 就會幫您設定爬蟲 (ScrapeOps)。
- 自動資料結構化:工具會輸出乾淨的表格,可直接用於 Excel、Google Sheets,或您常用的 BI 儀表板。
- 自動導覽:處理分頁、點「下一頁」、捲動,甚至登入——就像真人使用者一樣。
這些進步意味著任何人——銷售營運、行銷人員,甚至還在用 Internet Explorer 的表親——都能在沒有技術背景的情況下,開始從複雜畫面中擷取資料。
Thunderbit:用 AI 驅動的螢幕爬取處理複雜網頁資料擷取
來聊聊 Thunderbit,因為這正是螢幕爬取開始變得超有趣的地方(沒錯,我有一點偏愛——我們就是為這些挑戰而打造它的)。
Thunderbit 是一款 AI 網頁爬蟲 Chrome 擴充功能,專為想從任何網站取得資料的商務使用者設計,只要點幾下就能完成。以下是它如何把螢幕爬取帶進現代時代:
- AI 建議欄位:Thunderbit 像人一樣閱讀頁面,然後建議最適合擷取的欄位——不必再到處找選擇器,也不用猜哪個最重要 (Thunderbit Docs)。
- 2 步驟爬取:點「AI 建議欄位」,檢查欄位後,再按下「爬取」。剩下的交給 Thunderbit,包括處理棘手版面或動態內容。
- 子頁面爬取:如果需要更多細節,Thunderbit 可以自動前往每個子頁面(例如單一商品頁或個人檔案頁),抓取額外資訊並附加到您的表格中 (Thunderbit Docs)。
- 預建範本:針對熱門網站(Amazon、Zillow、LinkedIn、Shopify 等),Thunderbit 提供一鍵範本,無需設定。
- 處理分頁與無限捲動:Thunderbit 可在雲端一次爬取 50 頁,讓大規模擷取快速又有效率。
- 免費資料匯出:可直接將結果匯出到 Excel、Google Sheets、Airtable 或 Notion——沒有額外費用,也沒有綁定風險 (Thunderbit)。
Thunderbit 真正與眾不同的地方在於它的 AI。它不只是抓取螢幕上的內容——它還能理解上下文、適應變化,甚至即時重新格式化、摘要或翻譯資料。
使用 Thunderbit 進行螢幕爬取的主要優勢
 這就是為什麼 Thunderbit 是我做螢幕爬取時的首選(也是為什麼那麼多銷售、行銷和營運團隊都已經改用它):
這就是為什麼 Thunderbit 是我做螢幕爬取時的首選(也是為什麼那麼多銷售、行銷和營運團隊都已經改用它):
- 超級容易上手:不用寫程式、不用範本、沒有學習門檻。只要您會用瀏覽器,就會用 Thunderbit (Product Hunt)。
- AI 驅動的準確度:即使網站版面改了,Thunderbit 的 AI 仍能辨識欄位——維護更少,壞掉的爬蟲也更少。
- 能處理複雜情況:子頁面爬取、動態內容、圖片、PDF——Thunderbit 都能擷取,即使網站視覺上很雜亂或一直變動也沒問題。
- 無縫整合:一鍵匯出到 Excel、Google Sheets、Airtable 或 Notion。還能排程爬取,讓資料隨時保持最新。
- 成本效益高:小型任務有免費方案,付費方案也能隨需求擴充。匯出與進階功能不另收費 (Thunderbit 定價)。
- 一體化解決方案:需要擷取電子郵件、電話號碼或圖片?Thunderbit 也有對應的專用提取器。
對於過去得花好幾個小時複製貼上的團隊來說,Thunderbit 就像生產力加速器。有位使用者跟我說,他們用 10 分鐘就做出一份 500 筆的潛在客戶名單——這在以前可是得花上半天的事。
常見應用場景:今天螢幕爬取在哪些地方創造價值
| 產業/職能 | 應用案例 |
|---|---|
| 電商/零售 | 競爭對手價格監控、從市場平台爬取商品清單、追蹤庫存 |
| 銷售/名單開發 | 從目錄、LinkedIn、房地產刊登頁或活動參加者頁面擷取聯絡資訊 |
| 行銷 | 監控品牌提及、爬取評論或社群貼文進行情緒分析 |
| 金融 | 彙整即時股價、爬取競爭對手貸款利率、從舊入口網站提取資料 |
| 保險 | 爬取競爭對手報價頁、從老舊理賠系統擷取資料 |
| 醫療保健 | 從舊系統遷移病歷資料、爬取臨床試驗登錄資料 |
| 房地產 | 彙整物件刊登、爬取開放看屋或建照紀錄 |
| 旅遊/飯店業 | 追蹤競爭對手房價、爬取評論、監控訂房網站 |
| 政府/法律 | 爬取法院紀錄、法規文件或公開監督名單 |
只要資料看得到、卻不容易取得,螢幕爬取就是那張「脫身卡」。
螢幕爬取的演進與未來趨勢
螢幕爬取正在快速演進,而且不再只是靠蠻力而已。未來會往這些方向前進:
- AI 驅動的適應能力:現代螢幕爬蟲會用




