
大家都在談資料驅動決策,但往往忽略了資料蒐集其實既耗時又繁瑣。只要你曾經手動整理資料,就知道那有多累。我看過不少公司因為資料蒐集效率太差,遲遲無法把資料驅動策略真正落地。如果你也遇到同樣的問題,這篇文章會提供你一些全新的解法。
💡 這篇文章會帶你認識資料爬取,以及它如何隨著技術演進而不斷升級。我們會看看傳統做法的限制、AI 驅動資料爬取的優勢,並提供一些可直接應用在實務上的技巧。
什麼是資料爬取?
資料爬取,或稱為 網頁爬蟲,指的是透過工具從網頁中擷取結構化資訊(通常整理成表格)。這是一種能快速收集大量資料的高效率方式。舉例來說,你可以從 Google 地圖 擷取公開資料來開發潛在客戶,抓取 Amazon 上的電商 SKU 進行轉售或市場分析,或是從 Yelp 蒐集社群評論來了解顧客回饋。
資料爬取的技術轉變
過去,資料蒐集幾乎像是只有技術人員才能處理的工作(或者得花大量時間手動複製貼上)。但到了 2025 年,AI 開始接手這些工作。資料爬取不再只是程式設計師或單純自動化的專屬領域。
傳統方法正在失效
現代網站也帶來了更多挑戰:動態內容載入(像是 React/Vue 架構)、多模態資料的興起(文字、影片、圖片),以及非標準化資料結構(同一頁面有多種模板)。近期研究指出,傳統 網頁爬取方法 主要有三大問題:
-
維護成本像無底洞
傳統網頁爬蟲需要持續手動維護(每個網站大約每月要花 3–5 小時)。當網站更新或前端框架變動時,60% 的 XPath 選擇器都可能失效。AI 工具憑藉語言模型與程式理解能力,能自動適應 90% 的結構變化,將維護成本降低 60–80%。對於採用 React/Vue 建置的現代網站,AI 工具即使在 class 名稱變動時,也能透過語意理解維持資料爬取穩定。 -
可擷取的資料維度有限
傳統方法通常只能抓到結構化資料,卻會錯過很多有價值的資訊,例如:- 圖片中的資料
- 文章中的文字內容
- 沒有 HTML 標籤的非結構化資料
-
資料品質問題
傳統方法在處理動態內容時容易出錯,導致資料不完整或不正確:- 對於分頁資料(像電商商品列表),傳統爬蟲只能擷取首屏內容的 30–50%。
- 無限滾動頁面(像社群動態)會遺失超過 60% 的關鍵資料。
- 非結構化資料比對錯誤率高(清單資料對不齊)。
這就是像 Thunderbit 這類 AI 驅動工具派上用場的地方。下面我會進一步說明它們的優勢。
AI 資料爬取的崛起
使用 AI 從任何網站抓取資料 Get Started Free
到了 2025 年,AI,尤其是大型語言模型(LLM),已經展現出非常強大的能力。這些模型能理解並生成自然語言、處理複雜的資料分析任務,並提供更有效率的解決方案。現在許多資料爬取工具都開始運用 LLM,突破傳統方法的限制。經過近幾個月實測 13 款 資料爬取工具 後,我推薦 Thunderbit AI Web Scraper。
Thunderbit 之所以脫穎而出,原因如下:
-
革命性的互動方式:
使用者只要輸入簡單的自然語言指令,系統就能自動建立爬取方案,與傳統工具相比,設定時間可減少 87%。 -
在地化爬取的顯著優勢:
作為瀏覽器擴充功能,Thunderbit 提供:- 即時資料爬取
- 動態頁面與無限滾動頁面的爬取
- 需要登入才能查看的頁面爬取
-
強大的多模態資料處理能力:
Thunderbit 可以處理多種資料型態,例如:- 擷取文章中的文字資料
- 從 PDF 擷取財務資料表
- 辨識多張圖片中的資料並整理成表格
- 擷取影片字幕並自動摘要
有了 Thunderbit,你就能輕鬆應對各種資料蒐集情境。接下來一起看看如何使用 Thunderbit。
如何使用 AI 進行資料爬取
照著以下四個步驟,就能開始使用 Thunderbit 強大的 AI 網頁爬蟲功能:
-
安裝瀏覽器擴充功能
前往 Thunderbit 官網,從 Chrome Web Store 下載 Thunderbit 擴充功能。安裝完成後,將它釘選到瀏覽器工具列。 -
註冊並取得免費額度
在擴充功能內註冊,即可獲得試用額度。這些額度可讓你體驗 AI 網頁爬取、表單自動填寫與智慧摘要等核心功能。建議先在 playground 中免費試用,看看工具的實際效果,再使用額度開始正式操作。 -
啟動智慧爬取
從 Thunderbit 側邊欄開啟範本。使用自然語言描述你想要的資料內容與類型,設定特定擷取格式,或調整其他細節,然後按下爬取按鈕開始資料爬取。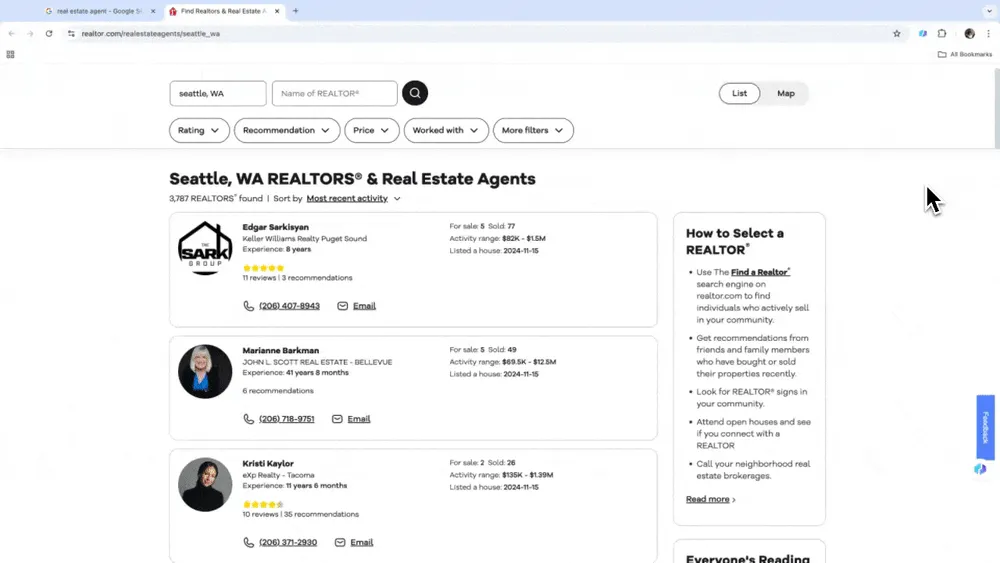
進階爬取功能(Pro 方案)
訂閱 Thunderbit 的 Pro 方案(或開始免費試用)後,你將解鎖以下功能:
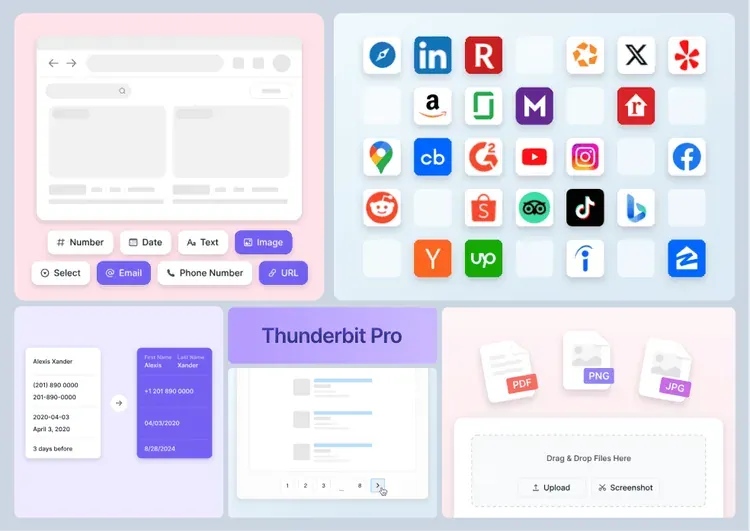
-
多模態資料處理
可處理像是 PDF 檔案解析(財報/產品手冊)、圖片資料擷取(價格標籤/規格表)與影片字幕爬取等複雜情境。系統會自動將非結構化資料標準化。 -
深層子頁面爬取
可選擇抓取頁面上的所有子連結(例如 商品詳情頁/使用者評論頁),智慧辨識相關資料,並自動合併到主資料表中。非常適合電商商品目錄、房地產列表等場景。 -
內建範本庫
可立即使用超過 30 個平台的最佳化 爬蟲範本,像是 TikTok、Amazon 與 Zillow,並可自動適應頁面結構變化。新使用者平均可節省 83% 的設定時間。 -
批次爬取任務
可同時執行多個爬取任務,並支援匯入 URL 清單進行批次抓取。 -
智慧分頁處理
能自動辨識並抓取分頁內容(包含「載入更多」按鈕與頁面導覽),也支援無限滾動頁面。經測試,可完整爬取超過 200 頁的電商商品列表。
Thunderbit 實戰指南
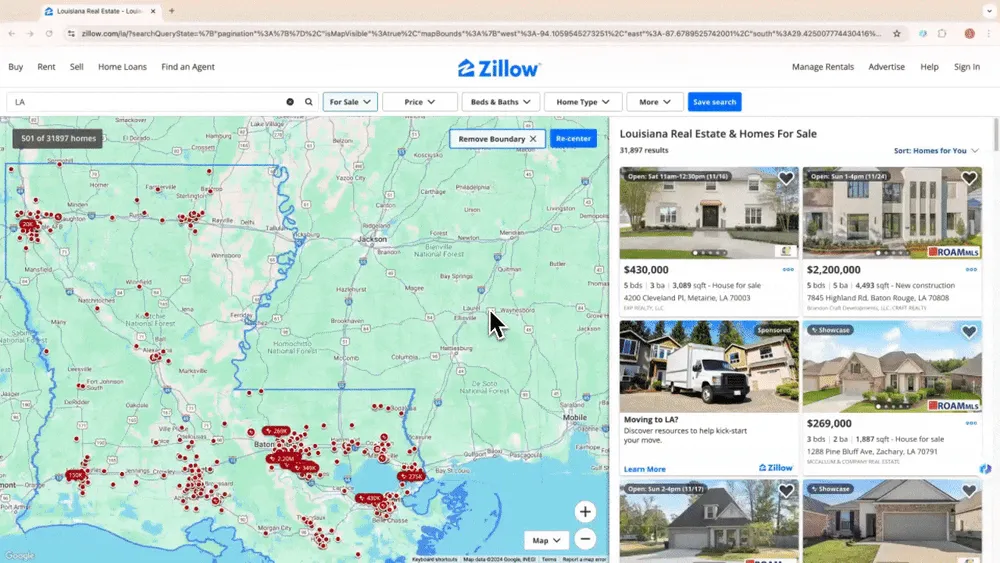
情境 1:房地產資料蒐集
如果你是想從 Zillow 蒐集房屋資料的房仲,或是尋找投資機會的投資人,一款可靠的網頁爬蟲會是你的得力助手。Thunderbit 的 AI 網頁爬蟲可幫助你輕鬆擷取 Zillow 上的重要房產資訊,讓你掌握最新資訊、維持競爭力。你也可以參考如何使用 Thunderbit 抓取 Zillow 的教學影片。
情境 2:人才與客戶開發
如果你是正在尋找人才的 HR,或是想開發新客戶的業務人員,一款可靠的網頁爬蟲可以成為強大的助手。Thunderbit 讓你能從公開網站、名錄與個人頁面中擷取有用的聯絡資訊與公司資料,幫助你簡化人才搜尋與潛在客戶管理。使用後你會發現,耗時的人工搜尋與複製貼上已經成為過去式。若想直接上手,可先從 Website Contact Scraper 開始。
情境 3:市場分析與客群定位
如果你是蒐集在地資料做市場分析的企業主,或是尋找本地商家名單的業務人員,一款可靠的網頁爬蟲可以徹底改變你的工作方式。Thunderbit 能讓你輕鬆從 Google 地圖 擷取關鍵資料,協助你做出更有根據的決策並優化外聯策略。
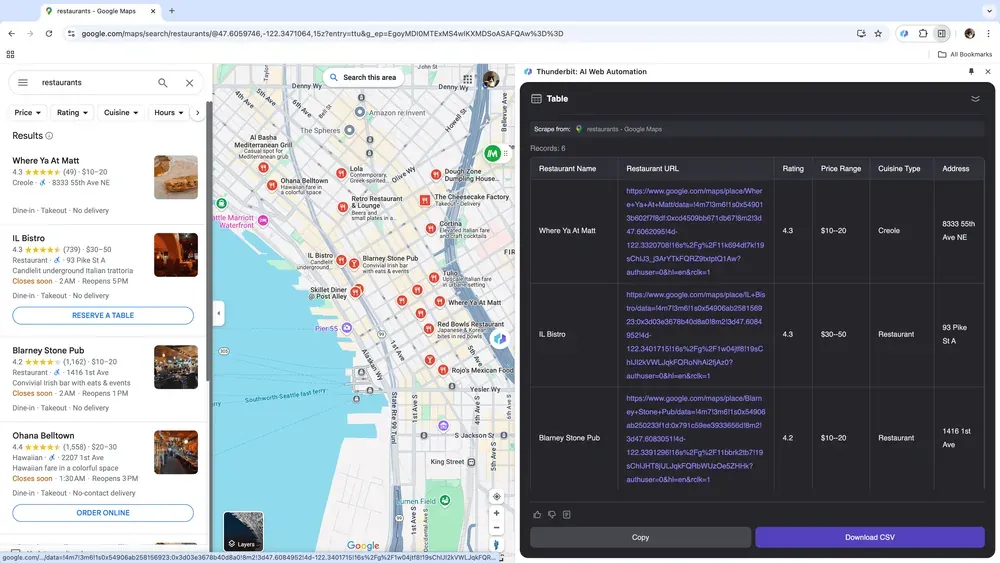
情境 4:電商資料分析
如果你是想了解競爭對手的線上賣家,或是追蹤市場趨勢的創業者,Thunderbit 就是你的理想工具!它能輕鬆蒐集來自 Amazon 的各種商品資料,包括詳細描述、價格以及 使用者評論。
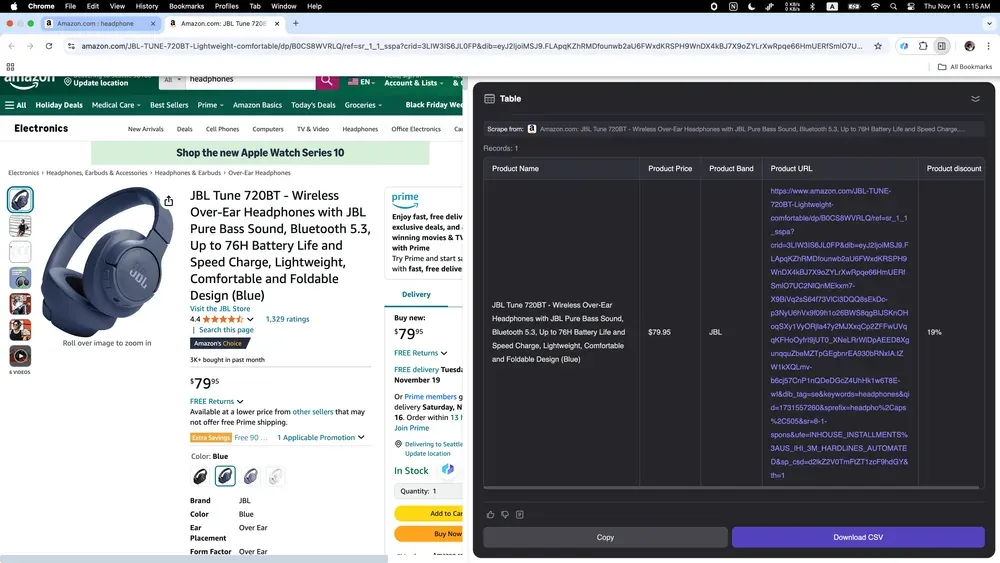
Thunderbit AI 網頁爬蟲重新定義了商務使用者蒐集資料的方式,讓整體流程變得更快、更簡單,也更有效率。無論你是在房地產市場找房源、在人才市場尋找潛在客戶,還是在電商市場分析趨勢,AI 網頁爬蟲都能幫你省下大量時間與麻煩。擁抱 AI 在網頁爬取上的力量,你會明顯感受到生產力的提升。準備好了嗎?現在就試試 Thunderbit,踏出更智慧網頁爬取的第一步。
獨家資料清理技巧
對傳統爬蟲來說,真正的挑戰往往不是資料爬取,而是爬完之後的資料清理。Thunderbit 可在資料爬取過程中直接利用 LLM 進行清理,透過以下創新功能將資料清理工作量降低 83%:
技巧 1:智慧欄位對齊
當處理多來源、異質資料時(例如同時整理電商商品頁、Zillow 房源與公司名錄),Thunderbit 的 AI 會自動建立語意對應關係:
- 自動辨識不同資料來源之間的欄位對應(例如「price」↔「售價」↔「Price」)
- 智慧合併相似欄位(例如「area」與「square feet」)
- 跨平台資料標準化(例如將商品頁的「availability」與 Zillow 的「property status」統一為標籤資料)
技巧 2:情境感知補全
透過大型語言模型的上下文理解能力,Thunderbit 可達到業界領先的 99% 資料填補率:
- 地址補全:根據郵遞區號自動補上城市/州資訊(例如輸入 10001 → New York City, NY)
- 職涯路徑推測:根據 LinkedIn 的學歷背景推測可能的工作經歷
技巧 3:資料最佳化
- 多語翻譯(支援 12 種語言的即時翻譯,包括英文、中文與日文)
- 智慧摘要(將 500 字的產品描述濃縮成三個關鍵賣點)
- 單位統一(自動轉換 square feet ↔ square meters、Fahrenheit ↔ Celsius)
- 格式標準化(日期統一為 YYYY-MM-DD,貨幣統一為 USD)
技巧 4:品質驗證
- 智慧錯誤修正:自動修正格式錯誤(例如電話號碼 +01 138-1234-5678 → +113812345678)
- 邏輯驗證:確保「建造年份」早於「最後翻修時間」
技巧 5:AI 標註
透過自然語言處理自動產生智慧標籤:
- 情緒分析標籤(自動將顧客評論標示為正面/負面/中性)
- 商業價值標籤(自動標示「高潛力客戶」/「待追蹤房源」)
- 產業分類標籤(自動為 LinkedIn 個人檔案加上「tech|finance|healthcare」標籤)
資料爬取的缺點
雖然資料爬取帶來極大的價值,但也不能忽視企業在實作時可能遇到的障礙。法律合規永遠是第一道門檻——像 GDPR 與 CCPA 這類法規,對資料蒐集作法有嚴格要求,必須仔細遵守隱私法規。網站也常部署像 Cloudflare 這類更複雜的防護機制,透過 IP 限制來偵測並阻擋爬取行為。
AI 時代下資料爬取的未來
AI 的演進正在把網頁爬取轉變成更直覺的企業級解決方案。想像一下,你只要輸入一個網域(例如 zillow.com)和你的需求(例如「抓取紐約市所有房源」),AI 就能自動規劃出所有相關資料點——從房屋細節到價格趨勢——完全不需要手動設定。這些智慧系統還能將爬取到的資料無縫整合進商業流程,例如自動把 LinkedIn 潛在客戶資訊送進 CRM,或將電商數據推送到分析儀表板。進階的模式辨識能力也將帶來預測型爬取功能,主動監控庫存變化或新興市場趨勢。更重要的是,AI 會動態處理合規需求,即時調整爬取參數以符合不斷演變的法規,同時保留透明的稽核紀錄。
AI 驅動的典範轉移,不只讓關鍵商業情報更容易取得,也從根本上重新定義了組織與網頁資料的互動方式。隨著這些技術日益成熟,越早導入像 Thunderbit 這類 AI 驅動爬取方案的企業,將在資料驅動決策上取得明顯的競爭優勢。
常見問題
-
Thunderbit 是什麼?
Thunderbit 是一款基於大型語言模型(LLM)的智慧瀏覽器擴充功能,專為現代資料蒐集需求而設計。它不僅提供 AI 網頁爬蟲 功能,也整合了多模態資料處理,可完整擷取動態網頁、PDF 檔案、圖片與影片中的資料。作為在地化的瀏覽器解決方案,它也能處理需要互動或動態載入的公開頁面,並自動適應現代前端框架的變化。 -
Thunderbit 的 AI 網頁爬蟲如何運作?
Thunderbit 的 AI 網頁爬蟲會利用 AI 從網站中擷取結構化資料。使用者只要點擊「AI Suggest Columns」,讓 AI 建議目前網站的爬取方式,再按下「Scrape」即可收集資料。只需兩次點擊,就能處理任何網站、PDF 或圖片中的資料。 -
清單爬取和子頁面爬取有什麼差別?
清單爬取針對分頁情境進行最佳化(例如電商商品列表),可自動辨識分頁邏輯並爬取數千筆資料。子頁面爬取則採用樹狀結構蒐集模式(例如 Zillow 房源列表 → 詳情頁 → 戶型圖),透過語意關聯自動建立主表與子表之間的關係。 -
不會寫程式的人也能使用 Thunderbit 嗎?
Thunderbit 採用自然語言互動設計:使用者只要描述需求,例如「姓名、email、電話」,系統就會自動產生爬取方案。我們的測試資料顯示,85% 的使用者能在 10 分鐘內完成第一次資料蒐集,完全不需要任何網頁程式設計知識。 -
Thunderbit 可以處理哪些類型的資料?
Thunderbit 支援智慧辨識多種資料型態:- 結構化資料:表格、清單(例如 Amazon 商品規格)
- 非結構化資料:評論文字、PDF 檔案(可自動辨識)
- 多模態資料:圖片中的價格標籤、影片字幕擷取
- 動態資料:無限滾動內容、延遲載入圖片
- 關聯資料:跨頁面關係映射(例如商品頁 → 評論 → 規格變體)
延伸閱讀:
試用 AI 網頁爬蟲 Get Started Free




