

網路上充滿了有價值的資料——無論您從事業務開發、電商,還是市場研究,網頁爬蟲都是開發潛在客戶、監控價格與進行競品分析的秘密武器。但問題來了:隨著越來越多企業投入爬蟲,網站也比以往更加積極反制。這個變化確實存在:一份2024 年 ppc.land 分析指出,前 1,000 大網站中已有超過三分之一只針對 OpenAI 的爬蟲進行封鎖——而更廣泛的IP 封鎖、CAPTCHA 與瀏覽器指紋辨識工具包,如今已從例外變成常態。
如果您曾看著 Python 腳本順順地跑了 20 分鐘,卻突然撞上一片 403 錯誤牆,您一定懂那種挫折感有多真實。
我在 SaaS 與自動化領域待了多年,親眼看過爬蟲專案如何在轉眼間從「哇,這也太簡單了」變成「為什麼到處都被擋?」。所以,讓我們務實一點:我會帶您了解如何用 Python 進行不被封鎖的網頁爬蟲,分享最有效的技巧與程式碼片段,並告訴您什麼時候該考慮像Thunderbit這樣的 AI 替代方案。不管您是 Python 老手,還是只是勉強在爬資料(雙關語請笑一下),看完後都能帶走一套可靠、不中斷的資料擷取工具箱。
什麼是用 Python 進行不被封鎖的網頁爬蟲?
從本質上說,不被封鎖的網頁爬蟲,就是以不會觸發網站反機器人防護機制的方式擷取資料。放到 Python 的脈絡裡,這不只是寫一個 requests.get() 迴圈而已——而是要盡量像真實使用者、融入網站行為,並且比偵測系統快一步。
為什麼選 Python?Python 是最受歡迎的網頁爬蟲語言——因為語法簡單、生態系龐大(像是 requests、BeautifulSoup、Scrapy、Selenium),而且從快速腳本到分散式爬蟲都很有彈性。但人氣高也有代價:許多反機器人系統如今都已調整到能辨識 Python 爬取模式。
所以,如果您想要穩定地爬資料,就得超越基本功。這代表您必須了解網站如何偵測機器人,以及如何在不越過倫理與法律界線的前提下,想辦法比它們更聰明。
為什麼避免封鎖對 Python 網頁爬蟲專案很重要
被封鎖不只是技術小插曲——它可能直接拖垮整個業務流程。拆開來看:
| 使用情境 | 被封鎖的影響 |
|---|---|
| 潛在客戶開發 | 名單不完整或資料過時,錯失銷售機會 |
| 價格監控 | 漏掉競爭對手調價,導致定價決策失準 |
| 內容彙整 | 新聞、評論或研究資料出現缺口 |
| 市場情報 | 競品或產業追蹤出現盲點 |
| 房地產列表 | 房源資料不準或過時,錯失機會 |
當爬蟲被封鎖時,您損失的不只是資料,還有資源、合規風險,甚至可能因為資訊不完整而做出錯誤的商業判斷。在一個79% 的企業都依賴網頁爬蟲進行潛在客戶開發的世界裡,可靠性就是一切。
網站如何偵測並封鎖 Python 網頁爬蟲
網站在辨識機器人這件事上,已經變得非常聰明。以下是您最常遇到的反爬防禦機制(Medium、Bright Data):
- IP 位址黑名單: 如果同一個 IP 發出太多請求,就會被封鎖。
- User-Agent 與標頭檢查: 缺少或過於通用的請求標頭(例如 Python 預設的
python-requests/2.25.1)會很顯眼。 - 速率限制: 短時間內請求過多,會觸發限流或封禁。
- CAPTCHA: 要您「證明自己是人類」的測驗,機器人通常很難解(至少沒那麼容易)。
- 行為分析: 網站會觀察是否出現機械化模式,例如每隔固定時間就點同一個按鈕。
- 誘餌陷阱: 只有機器人才會碰到的隱藏連結或欄位。
- 瀏覽器指紋辨識: 收集您的瀏覽器與裝置細節,用來找出自動化工具。
- Cookie 與工作階段追蹤: 無法正確處理 Cookie 或 session 的機器人,很容易被標記。
把它想成機場安檢:如果您看起來、行為上、移動方式都跟其他人一樣,就能順利通關;如果您穿著風衣、戴著墨鏡出現,就準備好接受更多盤問吧。
不被封鎖的 Python 網頁爬蟲必備技巧
接下來進入重點:實際用 Python 爬資料時,怎麼避開封鎖。以下是每個爬蟲都該熟悉的核心策略:

輪換代理伺服器與 IP 位址
為什麼重要: 如果所有請求都來自同一個 IP,您很容易成為 IP 封鎖的目標。輪換代理伺服器可以把請求分散到多個 IP 上,讓對方更難封鎖您。
Python 實作方式:
import requests
proxies = [
"<http://proxy1.example.com:8000>",
"<http://proxy2.example.com:8000>",
# ...更多代理
]
for i, url in enumerate(urls):
proxy = {"http": proxies[i % len(proxies)]}
response = requests.get(url, proxies=proxy)
# 處理回應
您也可以使用付費代理服務(例如住宅代理或輪換代理)來提高穩定性(ScrapingBee)。
設定 User-Agent 與自訂標頭
為什麼重要: Python 預設標頭會直接暴露「我是機器人」。透過設定 user-agent 和其他標頭,模擬真實瀏覽器。
範例程式碼:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive"
}
response = requests.get(url, headers=headers)
輪換 user-agent 會更隱蔽(ZenRows)。
隨機化請求時間與模式
為什麼重要: 機器人速度快又可預測;人類則慢而且不固定。加入延遲並打亂瀏覽路徑,會更像真人。
Python 小技巧:
import time, random
for url in urls:
response = requests.get(url)
time.sleep(random.uniform(2, 7)) # 等待 2~7 秒
如果您使用 Selenium,也可以隨機化點擊路徑與捲動模式。
管理 Cookie 與 Session
為什麼重要: 很多網站需要 Cookie 或 session token 才能存取內容。不處理這些的機器人,很容易被封鎖。
Python 管理方式:
import requests
session = requests.Session()
response = session.get(url)
# session 會自動處理 cookies
如果流程更複雜,可以使用 Selenium 擷取並重用 Cookie。
用無頭瀏覽器模擬人類行為
為什麼重要: 有些網站會把 JavaScript、滑鼠移動或捲動當成真人訊號。像 Selenium 或 Playwright 這類無頭瀏覽器,就能模擬這些動作。
Selenium 範例:
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
import random, time
driver = webdriver.Chrome()
driver.get(url)
actions = ActionChains(driver)
actions.move_by_offset(random.randint(0, 100), random.randint(0, 100)).perform()
time.sleep(random.uniform(2, 5))
這有助於繞過行為分析與動態內容(ScrapingBee)。
進階策略:在 Python 中繞過 CAPTCHA 與誘餌陷阱
CAPTCHA 的設計目的就是要把機器人擋下來。雖然某些 Python 函式庫可以解簡單 CAPTCHA,但多數嚴肅的爬蟲都會依賴第三方服務(例如 2Captcha 或 Anti-Captcha)來付費代解(Medium)。
整合範例:
# 使用 2Captcha API 的偽代碼
import requests
captcha_id = requests.post("<https://2captcha.com/in.php>", data={...}).text
# 等待解答後,再隨請求送出
誘餌陷阱 是只有機器人會互動到的隱藏欄位或連結。請避免點擊或提交在真實瀏覽器中看不到的內容(ZenRows)。
用 Python 函式庫設計更穩健的請求標頭
除了 user-agent 之外,您還可以輪換與隨機化其他標頭(例如 Referer、Accept、Origin 等),讓自己更像真人。
搭配 Scrapy:
class MySpider(scrapy.Spider):
custom_settings = {
'DEFAULT_REQUEST_HEADERS': {
'User-Agent': '...',
'Accept-Language': 'en-US,en;q=0.9',
# 更多標頭
}
}
搭配 Selenium: 可使用瀏覽器設定檔或擴充功能來設定標頭,或透過 JavaScript 注入。
請記得保持標頭清單更新——您可以透過瀏覽器 DevTools 複製真實瀏覽器請求來找靈感。
當傳統 Python 爬蟲已不夠用:反機器人技術的崛起
現實就是這樣:爬蟲越來越普及,反機器人技術也同步升級。大型網站現在不只封鎖明顯的機器人,連進階無頭瀏覽器與輪換代理也在打擊範圍內。AI 偵測、動態請求門檻與瀏覽器指紋辨識,讓即使是進階 Python 腳本也越來越難不被發現(Medium)。
有時候,不管您的程式碼多聰明,還是會撞牆。那時候,就該考慮不同的做法了。
Thunderbit:替代 Python 爬蟲的 AI 網頁爬蟲
當 Python 遇到極限時,Thunderbit 就會以免寫程式、AI 驅動的網頁爬蟲角色登場,而且是專為商務使用者設計,不只是開發者。您不必再跟代理伺服器、標頭與 CAPTCHA 糾纏不清,Thunderbit 的 AI 代理會讀取網站、建議最適合擷取的欄位,並從子頁面導覽到資料匯出一手包辦。
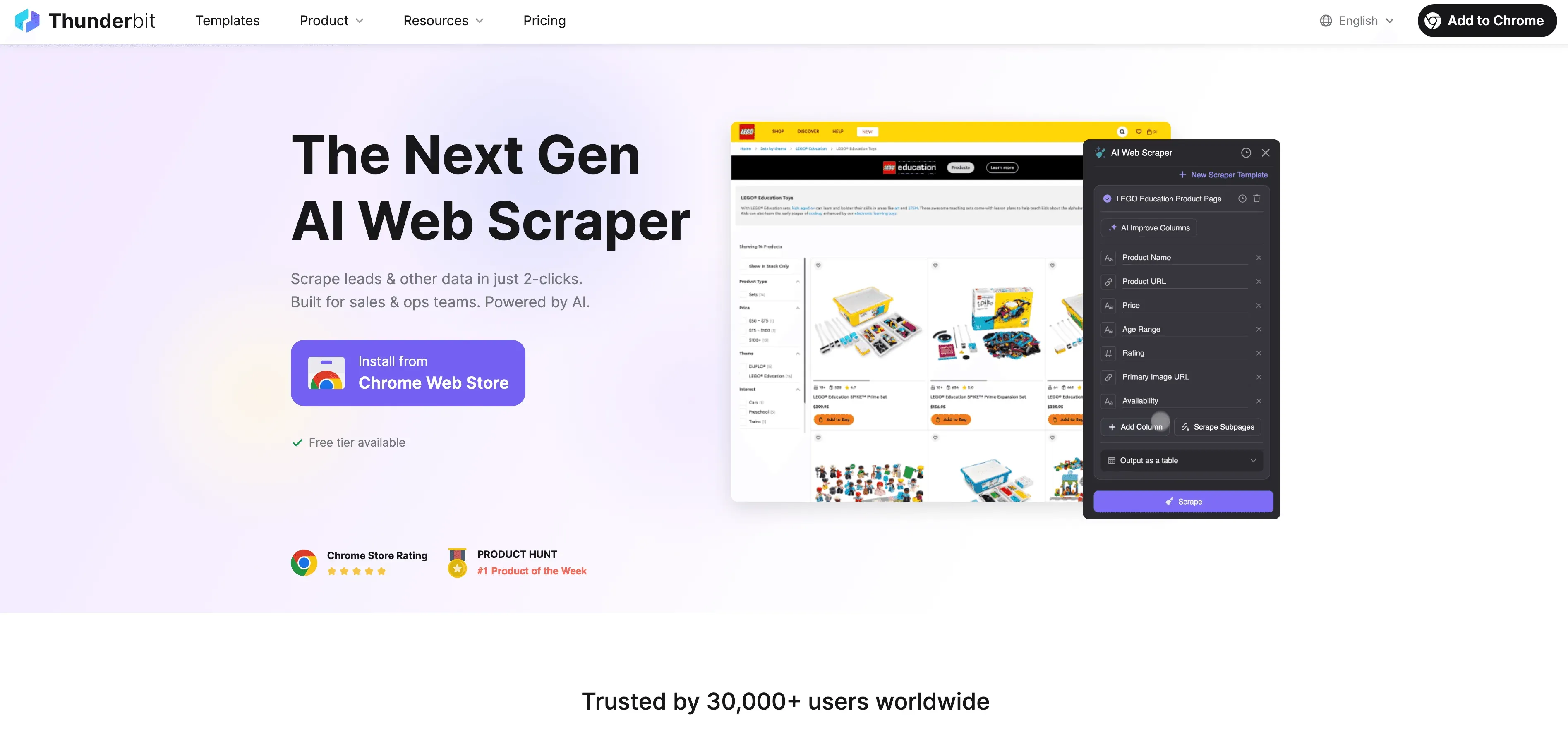
Thunderbit 有什麼不同?
- AI 欄位建議: 點一下「AI 建議欄位」,Thunderbit 會掃描頁面、推薦欄位,甚至自動生成擷取指令。
- 子頁面爬取: Thunderbit 可以逐一造訪每個子頁面(如產品詳情或 LinkedIn 個人檔案),自動補充您的表格。
- 雲端或瀏覽器爬取: 選擇最快的方式——公開網站用雲端,登入保護頁面用瀏覽器。
- 排程爬取: 設定好就能自動執行——Thunderbit 可依排程抓取,讓資料永遠保持最新。
- 即時範本: 對於熱門網站(Amazon、Zillow、Shopify 等),Thunderbit 提供一鍵範本,無需設定。
- 免費資料匯出: 可匯出到 Excel、Google Sheets、Airtable 或 Notion,無額外費用。
Thunderbit 已獲得全球超過10 萬名使用者信賴,而且您完全不需要寫任何程式碼。
使用 AI 從任何網站擷取資料 Get Started Free
Thunderbit 如何幫助使用者避開封鎖並自動化資料擷取
Thunderbit 的 AI 不只是模仿人類行為——它會即時適應每個網站,降低被封鎖的風險。方式如下:
- AI 適應版面變化: 當網站更新設計時,您不必每週重調 selector,因此重工更少。
- 子頁面與分頁處理: Thunderbit 會像真人逐頁點選一樣,自動跟隨連結與分頁列表。
- 雲端批次爬取: 讓工作在 Thunderbit 的雲端執行,而不是您的筆電上,且批次大小依方案設定(請參考定價頁以取得目前限制)。
- 更少維護程式碼: 網站一改版時,不用您半夜盯著壞掉的 selector;AI 會重新讀取頁面。
若想深入了解,請參考如何使用 AI 抓取任何網站。
Python 爬蟲 vs. Thunderbit:您該選哪個?
我們直接並排比較:
| 功能 | Python 爬蟲 | Thunderbit |
|---|---|---|
| 設定時間 | 中~高(腳本、代理等) | 低(2 次點擊,剩下交給 AI) |
| 技術門檻 | 需要寫程式 | 不需要寫程式 |
| 可靠性 | 變動大(容易壞) | 高(AI 會適應變化) |
| 被封鎖風險 | 中~高 | 低(AI 會模仿使用者並自我調整) |
| 擴展性 | 需要自訂程式碼/雲端設定 | 內建雲端/批次爬取 |
| 維護成本 | 頻繁(網站改版、封鎖) | 極低(AI 自動調整) |
| 匯出選項 | 手動(CSV、資料庫) | 可直接匯出到 Sheets、Notion、Airtable、CSV |
| 成本 | 免費(但很耗時) | 有免費方案,大規模使用則為付費方案 |
什麼時候用 Python:
- 您需要完全控制、自訂邏輯,或要和其他 Python 工作流程整合。
- 您爬取的網站反機器人防禦較少。
什麼時候用 Thunderbit:
- 您想要速度、穩定性,且不想做任何設定。
- 您要爬的是複雜或經常變動的網站。
- 您不想處理代理、CAPTCHA 或程式碼。
逐步指南:設定不被封鎖的 Python 網頁爬蟲
我們來走一個實際範例:從示範網站抓取產品資料,同時套用防封鎖最佳實踐。
1. 安裝必要函式庫
pip install requests beautifulsoup4 fake-useragent
2. 準備您的腳本
import requests
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
import time, random
ua = UserAgent()
urls = ["<https://example.com/product/1>", "<https://example.com/product/2>"] # 請換成您的網址
for url in urls:
headers = {
"User-Agent": ua.random,
"Accept-Language": "en-US,en;q=0.9"
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, "html.parser")
# 在這裡擷取資料
print(soup.title.text)
else:
print(f"{url} 被封鎖或發生錯誤:{response.status_code}")
time.sleep(random.uniform(2, 6)) # 隨機延遲
3. 加入代理輪換(可選)
proxies = [
"<http://proxy1.example.com:8000>",
"<http://proxy2.example.com:8000>",
# 更多代理
]
for i, url in enumerate(urls):
proxy = {"http": proxies[i % len(proxies)]}
headers = {"User-Agent": ua.random}
response = requests.get(url, headers=headers, proxies=proxy)
# ...其餘程式碼
4. 處理 Cookie 與 Session
session = requests.Session()
for url in urls:
response = session.get(url, headers=headers)
# ...其餘程式碼
5. 疑難排解小提示
- 如果您看到大量 403/429 錯誤,請放慢請求速度或換新的代理。
- 如果遇到 CAPTCHA,可考慮改用 Selenium 或 CAPTCHA 解題服務。
- 一定要檢查網站的
robots.txt與服務條款。
結論與重點整理
Python 網頁爬蟲很強大——但隨著反機器人技術演進,被封鎖的風險也一直存在。避免封鎖的最佳方式是什麼?把技術最佳實踐(輪換代理、智慧標頭、隨機延遲、session 處理與無頭瀏覽器)和對網站規則與倫理的尊重結合起來。
但有時候,就算是最好的 Python 技巧也還是不夠。這就是Thunderbit這類 AI 工具登場的時候——免寫程式、專門處理版面變動與分頁,而且是為不想晚上還在盯 Selenium 任務的商務使用者所打造。
想看看爬資料可以有多簡單嗎?下載 Thunderbit 的 Chrome 擴充功能親自試試看——或者造訪我們的部落格了解更多爬蟲技巧與教學。
常見問題
1. 為什麼網站會封鎖 Python 網頁爬蟲?
網站封鎖爬蟲是為了保護資料、避免伺服器過載,並防止自動化機器人濫用服務。若 Python 腳本使用預設標頭、不處理 Cookie,或在太短時間內送出太多請求,就很容易被辨識出來。
2. 用 Python 爬資料時,避免被封鎖最有效的方法有哪些?
使用輪換代理、設定逼真的 user-agent 與標頭、隨機化請求時間、管理 Cookie/session,並搭配 Selenium 或 Playwright 等工具模擬人類行為。
3. 和 Python 腳本相比,Thunderbit 如何幫助避免封鎖?
Thunderbit 使用 AI 去適應網站版面、模擬真人瀏覽,並自動處理子頁面與分頁。它透過更像真實使用者、並即時更新策略來降低被封鎖風險——不需要寫程式或代理伺服器。
4. 什麼時候該用 Python 爬蟲,什麼時候該用像 Thunderbit 這樣的 AI 工具?
如果您需要自訂邏輯、要整合其他 Python 程式碼,或是只爬簡單網站,就用 Python。若您需要快速、可靠、可擴展的爬取——尤其是面對複雜、常改版或會積極封鎖腳本的網站時——就用 Thunderbit。
5. 網頁爬蟲合法嗎?
針對公開可取得的資料,網頁爬蟲本身是合法的,但您必須遵守各網站的服務條款、隱私政策與相關法律。切勿爬取敏感或私人資料,並且務必以合乎倫理且負責任的方式進行爬取。
準備好更聰明而不是更辛苦地爬資料了嗎?試試 Thunderbit,把封鎖遠遠甩開。
延伸閱讀:
- 用 Python 抓取 Google 新聞:逐步指南
- 用 Python 打造 Best Buy 價格追蹤工具
- 網頁爬蟲不被封鎖的 14 種方法
- 網頁爬蟲時避免被封鎖的 10 個最佳技巧
試用 AI 網頁爬蟲 Get Started Free




