

網頁爬蟲現在已經是各行各業搶快、搶商機的秘密武器了——不管你是做銷售、營運、電商還是房仲,網路上滿滿的數據等著你去挖掘。不過,想要把這些資料有效抓下來,尤其遇到互動性高、動態載入的網站,真的不是那麼簡單。其實,到了 2025 年,網頁爬蟲預計會帶動一個快要 490 億美元 的全球市場,而且 超過九成企業 都已經靠數據分析來做決策。只是,現在的網站越做越複雜——像是無限滾動、彈跳視窗、JavaScript 動態內容——傳統的爬蟲工具常常會卡關。
用 AI 從任何網站輕鬆抓資料 Get Started Free
這時候,Selenium 就像救星一樣出現了。Selenium 就是網頁爬蟲界的萬用瑞士刀,可以自動化真實瀏覽器的操作,讓你連最難搞、最動態的網站都能順利把資料撈下來。如果你曾經想過「要是能像真人一樣點一點、把資料抓下來就好了」,那 Selenium 絕對是你的神隊友。這篇教學會帶你一步步學會 selenium 網頁爬蟲的精髓——不用什麼電腦專業背景也能輕鬆上手。
Selenium 網頁爬蟲是什麼?快速認識
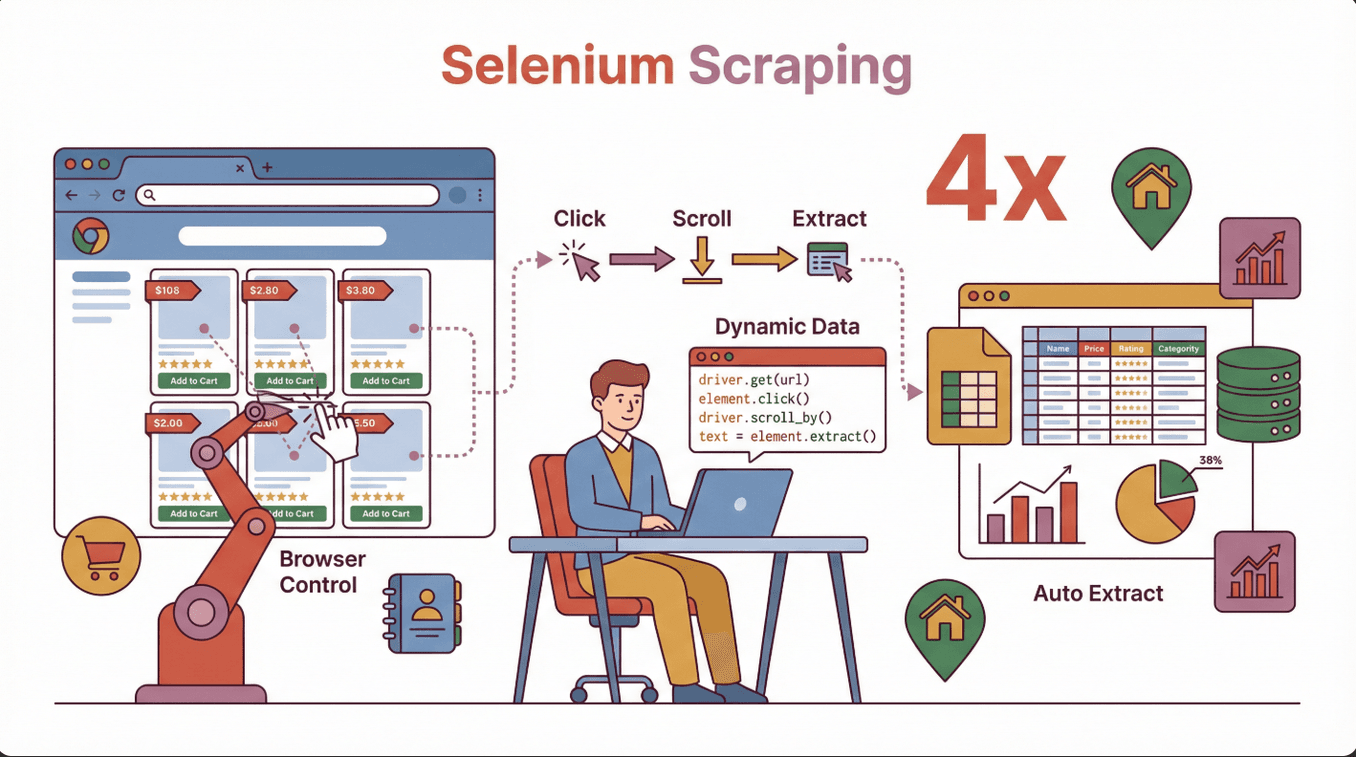 簡單說,用 Selenium 做網頁爬蟲,就是用 Selenium 函式庫寫程式去操控真實的瀏覽器(像 Chrome 或 Firefox),模擬人類的操作——點按鈕、填表單、滑動頁面等等。跟只能讀靜態 HTML 的傳統爬蟲比起來,Selenium 能像真人一樣跟網站互動,特別適合抓那些靠 JavaScript 動態載入的資料。
簡單說,用 Selenium 做網頁爬蟲,就是用 Selenium 函式庫寫程式去操控真實的瀏覽器(像 Chrome 或 Firefox),模擬人類的操作——點按鈕、填表單、滑動頁面等等。跟只能讀靜態 HTML 的傳統爬蟲比起來,Selenium 能像真人一樣跟網站互動,特別適合抓那些靠 JavaScript 動態載入的資料。
Selenium 適合的商業應用場景:
- 電商:抓商品清單、價格、評論,應付滾動載入的頁面。
- 銷售與名單開發:從需要登入或多步驟導航的名錄中提取聯絡資訊。
- 房地產:收集互動地圖或彈窗背後的物件資訊。
- 市場調查:從現代化、類 App 網站收集競品數據。
如果你用爬蟲抓資料卻發現一堆資訊都沒撈到,很可能就是那些資料是頁面載入後才出現的——Selenium 能像真人一樣等、點、互動,把這些資料一網打盡(參考 BrowserStack)。
為什麼選 Selenium?跟其他網頁爬蟲工具比一比
市面上網頁爬蟲工具超多——像 BeautifulSoup、Scrapy、Thunderbit 等等。那為什麼要用 Selenium?重點在這裡:
| 工具 | 最適合用途 | 支援 JavaScript? | 互動性 | 速度 | 易用性 |
|---|---|---|---|---|---|
| Selenium | 動態、互動性高的網站 | 是 | 完整 | 較慢 | 中等 |
| BeautifulSoup | 簡單、靜態 HTML 頁面 | 否 | 無 | 快 | 容易 |
| Scrapy | 大型、靜態或半動態網站 | 有限(需外掛) | 有限 | 非常快 | 中等 |
| Thunderbit | 商業用戶快速、免寫程式抓取 | 是(AI 驅動) | 有限 | 快 | 非常容易 |
Selenium 的優勢:
- 能搞定大量 JavaScript、無限滾動、彈窗等複雜情境。
- 可以登入、點擊、填表單——就像真人操作。
- 適合抓互動後才出現的資料。
什麼時候該用 Selenium?
- 你要的資料是頁面載入後才出現(例如 JavaScript 動態生成)。
- 需要跟網站互動(登入、點擊、滾動)。
- 網站結構複雜,或是 SPA(單頁應用程式)。
什麼時候該用其他工具?
- 網站內容單純、靜態——用 BeautifulSoup 或 Scrapy 速度更快。
- 想要免寫程式、商業友善的工具——Thunderbit 適合快速任務(參考 Thunderbit Blog)。
Selenium 安裝與設定:新手也能輕鬆上手
剛開始用 Selenium 可能會覺得有點複雜,其實照著步驟來很快就能搞定。
1. 安裝 Python(如果還沒裝)
大部分 Selenium 教學都用 Python,也支援 Java、C# 等語言。直接去 python.org 下載安裝。
2. 用 pip 安裝 Selenium
打開終端機或命令提示字元,輸入:
pip install selenium
(參考 BrowserStack)
3. 下載瀏覽器驅動程式
Selenium 需要「驅動程式」來控制瀏覽器。Chrome 用 ChromeDriver,Firefox 用 GeckoDriver。
- 查瀏覽器版本:打開 Chrome,輸入
chrome://settings/help。 - 下載對應驅動程式:ChromeDriver 下載點。
- 解壓縮並設定路徑:把驅動程式放到資料夾,並把路徑加到系統 PATH。
小提醒: 驅動程式版本一定要跟瀏覽器版本一致,不然會出現 chromedriver executable needs to be available in the path 這種錯誤(參考 Stack Overflow)。
4. 測試環境有沒有裝好
在 Python 輸入:
from selenium import webdriver
driver = webdriver.Chrome() # 或 Firefox()
driver.get("https://www.google.com")
print(driver.title)
driver.quit()
如果瀏覽器有打開還有印出標題,代表安裝成功!
常見問題排查:
- PATH 沒設好——再檢查一次環境變數。
- 驅動/瀏覽器版本不符——兩個都要一起更新。
- 權限問題——Mac/Linux 可能要
chmod +x chromedriver。
Selenium 網頁爬蟲實作:從零開始寫第一支爬蟲
來看一個簡單範例,抓電商網站的商品名稱,步驟如下:
1. 匯入 Selenium 並設定驅動程式
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
2. 開啟目標網頁
driver.get("https://example-ecommerce.com/products")
3. 等待內容載入(如有需要)
遇到動態內容時,建議用顯式等待:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
wait = WebDriverWait(driver, 10)
wait.until(EC.presence_of_element_located((By.CLASS_NAME, "product-title")))
4. 擷取資料
products = driver.find_elements(By.CLASS_NAME, "product-title")
for product in products:
print(product.text)
5. 關閉瀏覽器
driver.quit()
說明: Selenium 會自動打開瀏覽器,等商品載入,抓所有 class 是 product-title 的元素,然後印出文字。
Selenium 擷取動態內容的實用技巧
現在的網站幾乎都很動態——像無限滾動、彈窗、點擊才出現的內容。這裡有幾個常見處理方式:
1. 等待元素出現
網站資料不一定馬上載入,建議用顯式等待:
wait.until(EC.presence_of_element_located((By.ID, "dynamic-content")))
2. 滾動頁面載入更多內容
遇到無限滾動頁面:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
可以重複執行多次載入更多資料。
3. 處理彈跳視窗
自動關閉彈窗:
try:
close_button = driver.find_element(By.CLASS_NAME, "close-popup")
close_button.click()
except:
pass # 沒有彈窗就略過
4. 操作表單與按鈕
自動填寫搜尋欄或點擊「下一頁」:
search_box = driver.find_element(By.NAME, "search")
search_box.send_keys("laptop")
search_box.submit()
實戰例子: 像房仲網站的物件清單要滑動才會載入,或商品評論要點分頁才會顯示。
常見錯誤排查:Selenium 網頁爬蟲疑難雜症
就算是老手也常遇到問題,這裡整理最常見的狀況和解法:
| 問題 | 解決方法 |
|---|---|
| 找不到元素 | 用等待、檢查選擇器、換不同定位方式 |
| 逾時錯誤 | 增加等待時間、檢查內容是否載入慢 |
| CAPTCHA 或機器人偵測 | 降低請求速度、隨機化操作、使用代理 |
| 驅動/瀏覽器版本不符 | 兩者都更新到相容版本 |
| 網站版面變動 | 定期更新選擇器並測試腳本 |
| 執行速度慢 | 減少瀏覽器操作、可用無頭模式 |
小提醒: Selenium 因為模擬真人操作,速度本來就比其他工具慢(參考 Reddit)。如果要抓大量資料,建議分批或考慮其他方案。
擷取到的資料怎麼匯出跟應用?
資料抓下來後,通常會想存成檔案方便後續分析。常見流程如下:
1. 存成 List 或 DataFrame
import pandas as pd
data = []
for product in products:
data.append({"name": product.text})
df = pd.DataFrame(data)
2. 匯出成 CSV 或 Excel
df.to_csv("products.csv", index=False)
# 或
df.to_excel("products.xlsx", index=False)
(參考 GeeksforGeeks)
3. 整合到商業工具
- 匯入 Google Sheets 或 Airtable。
- 用 Zapier 或 API 自動化資料流。
小技巧: 匯入前先清理格式不一致或缺漏的資料(參考 Thunderbit Blog)。
Selenium + Thunderbit:複雜資料擷取的黃金組合
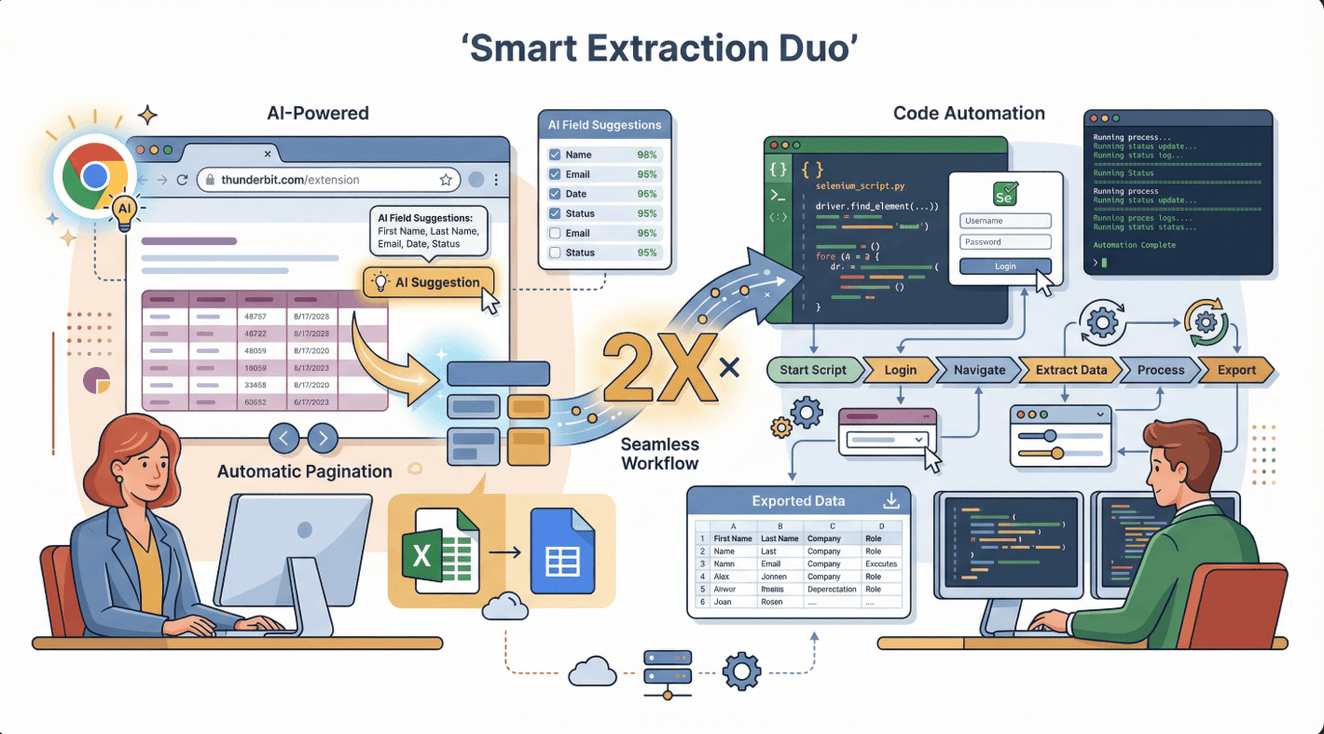 老實說,Selenium 很強大,但不是每個情境都最方便或最快。這時候 Thunderbit 就能補位。Thunderbit 是一款 AI 驅動的網頁爬蟲 Chrome 擴充功能,幾乎不用設定、也不用寫程式,點幾下就能從大多數網站抓到資料。
老實說,Selenium 很強大,但不是每個情境都最方便或最快。這時候 Thunderbit 就能補位。Thunderbit 是一款 AI 驅動的網頁爬蟲 Chrome 擴充功能,幾乎不用設定、也不用寫程式,點幾下就能從大多數網站抓到資料。
兩者怎麼搭配?
- Thunderbit 適合快速抓表格、清單、簡單頁面等結構化資料。很適合銷售、電商、研究團隊快速取得結果。
- Selenium 則適合需要自動化複雜互動(像登入、多步驟流程、點擊後才出現的資料)。
進階工作流: 先用 Thunderbit 處理簡單部分,遇到登入或互動內容再用 Selenium。甚至可以把 Thunderbit 匯出的資料再交給 Selenium 進階處理。
Thunderbit 優勢:
- AI 智慧欄位建議——只要點「AI 建議欄位」就能自動選取。
- 支援分頁、子頁面,直接匯出到 Excel、Google Sheets、Notion、Airtable。
- 免維護——AI 會自動適應網站變動(參考 Thunderbit Blog)。
合法與道德:用 Selenium 做網頁爬蟲要注意什麼?
網頁爬蟲很強大,但也有法律與道德責任。這裡有幾個合規建議:
1. 先看網站服務條款
爬資料前一定要檢查網站條款。有些網站明確禁止爬蟲,有些則允許個人用途(參考 RoboRabbit)。
2. 尊重 robots.txt
robots.txt 會告訴你哪些內容可以被爬。網址通常是 https://website.com/robots.txt(參考 RoboRabbit)。
3. 避免抓取敏感或個資
不要爬健康、財務或個人隱私資料——這可能觸法甚至吃上官司(參考 RoboRabbit)。
4. 禮貌爬取:控制速率與標示身份
不要對伺服器造成太大負擔——加上延遲、適當標示爬蟲身份。
5. 有官方 API 優先用
如果網站有公開 API,建議優先使用,最安全也最穩定。
合規爬蟲檢查清單:
- 詳讀並遵守網站條款與 robots.txt。
- 只抓公開、非敏感資料。
- 控制請求速率,避免影響網站運作。
- 依規定標註資料來源。
- 隨時關注當地法規(參考 Apify Blog)。
需要更大規模?什麼時候該超越 Selenium?
Selenium 很適合中小型任務,但也有極限:
限制:
- 執行速度比其他工具慢(因為要跑真實瀏覽器)。
- 資源消耗大——同時開多個瀏覽器會拖慢電腦。
- 不適合一次抓數千、數萬頁。
什麼時候該升級?
- 需要大規模爬取(數千、數百萬頁)。
- 想要雲端自動化或定時爬取。
- 需要進階功能(像代理輪換、重試、分散式爬蟲)。
其他選擇:
- Thunderbit:商業用戶想要快速、免寫程式、AI 輔助爬蟲(參考 Thunderbit Pricing)。
- Scrapy:開發者打造大型、分散式爬蟲(參考 Oxylabs)。
- 託管 API:像 ScraperAPI、Apify,適合自動化、可擴展的爬蟲(參考 ScrapingBee)。
| 工具 | 最適合用途 | 優點 | 缺點 |
|---|---|---|---|
| Selenium | 複雜、互動性高 | 幾乎可抓任何網站、完全掌控 | 慢、資源消耗大 |
| Thunderbit | 商業用戶、快速抓取 | 免寫程式、AI、匯出方便 | 進階控制較少 |
| Scrapy | 大型、開發團隊 | 快速、可擴展、可自訂 | 需寫程式、互動性較低 |
| 託管 API | 企業、全自動 | 可擴展、免維護 | 成本較高、彈性較低 |
總結與重點回顧
用 Selenium 做網頁爬蟲,讓你輕鬆取得動態、互動性高的網站資料。當你需要模擬真人操作(點擊、滾動、登入等),Selenium 就是首選。重點整理如下:
- Selenium 最適合:動態網站、JavaScript 內容、互動式流程。
- 安裝小技巧:瀏覽器與驅動版本要一致、PATH 設定正確、動態內容要用等待。
- 搭配 Thunderbit:簡單任務用 Thunderbit 快速搞定,遇到複雜互動再用 Selenium。
- 合規第一:務必檢查網站條款、robots.txt,避免抓取敏感資料。
- 大規模任務:考慮託管 API 或雲端工具。
如果你是新手,建議先寫一支 Selenium 腳本抓商品名稱或價格,再試試 Thunderbit 處理下一個商業數據專案——免費體驗,幫你省下大量人工整理時間(參考 Thunderbit Chrome Extension Download Page)。
想學更多?歡迎逛逛 Thunderbit Blog 看更多教學,或訂閱我們的 YouTube 頻道 觀看逐步操作影片。
常見問答
1. Selenium 和其他網頁爬蟲工具有什麼不同?
Selenium 能控制真實瀏覽器,能跟動態、JavaScript 很重的網站互動——這是傳統爬蟲(像 BeautifulSoup)做不到的。特別適合需要點擊、登入等用戶操作的網站。
2. Selenium 安裝最常見的錯誤有哪些?
最常見問題是瀏覽器跟驅動版本不符、驅動沒加到 PATH,以及沒用等待導致動態內容沒抓到。記得檢查版本並用顯式等待。
3. Selenium 和 Thunderbit 可以一起用嗎?
當然可以。Thunderbit 適合快速、免寫程式的抓取,Selenium 處理複雜互動。很多團隊會用 Thunderbit 抓簡單資料,Selenium 處理進階任務。
4. 用 Selenium 做網頁爬蟲合法嗎?
只要遵守網站條款、尊重 robots.txt、不抓敏感資料、不造成伺服器負擔,基本上是合法的。請依當地法規負責任地使用爬蟲。
5. 什麼時候該考慮不用 Selenium?
如果需要快速抓大量頁面、或想自動化雲端爬蟲,建議用 Thunderbit、Scrapy 或託管 API。Selenium 適合中小型、互動性高的任務。
準備好成為網頁爬蟲高手了嗎?下次專案就用 Selenium 試試看——也別忘了體驗 Thunderbit,最快速擷取商業數據的利器。
體驗人工智慧網頁爬蟲 Get Started Free
延伸閱讀




