

讓我帶你回到不算太久以前:我坐在書桌前,手裡拿著咖啡,盯著一份比週日晚上冰箱還空的試算表。業務團隊要競品定價資料,行銷同事要新的潛在客戶名單,營運團隊則要來自十幾個網站的產品列表——而且是昨天就要。我知道資料就在那裡,但要怎麼拿到?那才是真正的挑戰。如果你也曾覺得自己像在跟複製貼上玩數位打地鼠,你並不孤單。
快轉到今天,局勢已經大不相同。網頁爬蟲已經從宅宅的副業專案,變成核心商業策略。JavaScript 和 Node.js 如今站上舞台中央,從一次性腳本到完整的資料管線都靠它們驅動。不過話說回來:雖然工具前所未有地強大,學習曲線有時還是像穿著夾腳拖去爬聖母峰一樣陡。所以,無論你是商務使用者、資料愛好者,還是單純厭倦手動輸入資料的人,這篇指南都適合你。我會拆解整個生態系、必備函式庫、常見痛點,以及為什麼有時候最聰明的做法,是讓 AI 來扛下最費力的部分。
為什麼 JavaScript 與 Node.js 網頁爬蟲對企業很重要
先從「為什麼」開始。到了 2026 年,網頁資料早就不是加分題,而是攸關成敗的關鍵。根據近期研究,73% 的公司認為公開網頁資料能幫助更快、更準確地做決策,而企業資料預算中約有 42% 已經投入網頁資料蒐集。包含網頁爬蟲在內的替代資料市場,規模已達 49 億美元,而且還在快速成長。
那麼,這波淘金潮是誰在推動?以下是幾個最常見的商業應用場景:
- 競爭定價與電商: 零售商會抓取競爭對手網站的價格與庫存資料,有時甚至能讓銷售額提升 4% 以上。
- 潛在客戶開發與銷售情報: 業務團隊會自動蒐集名錄與社群平台上的電子郵件、電話號碼與公司資訊。
- 市場研究與內容彙整: 分析師會抓取新聞、評論與情緒資料,用來洞察趨勢並做預測。
- 廣告與廣告科技: 廣告科技公司會即時追蹤廣告版位與競爭對手活動。
- 房地產與旅遊: 相關業者會抓取房源列表、價格與評論,以支援估價模型與市場分析。
- 內容與資料彙整平台: 各平台會整合多來源資料,驅動比較工具與儀表板。
JavaScript 和 Node.js 已成為這類任務的首選技術堆疊,尤其當越來越多網站依賴動態、由 JavaScript 渲染的內容時。Node.js 擅長非同步操作,非常適合大規模爬取。再加上豐富的函式庫生態系,你可以從快速腳本一路做出穩健、可上線的爬蟲。
什麼是資料爬取,以及如何在 2025 年完成它 Get Started Free
核心流程:JavaScript 與 Node.js 網頁爬蟲如何運作
先來釐清一般的網頁爬蟲流程。無論你要抓的是簡單部落格,還是充滿 JavaScript 的電商網站,步驟其實都大同小異:
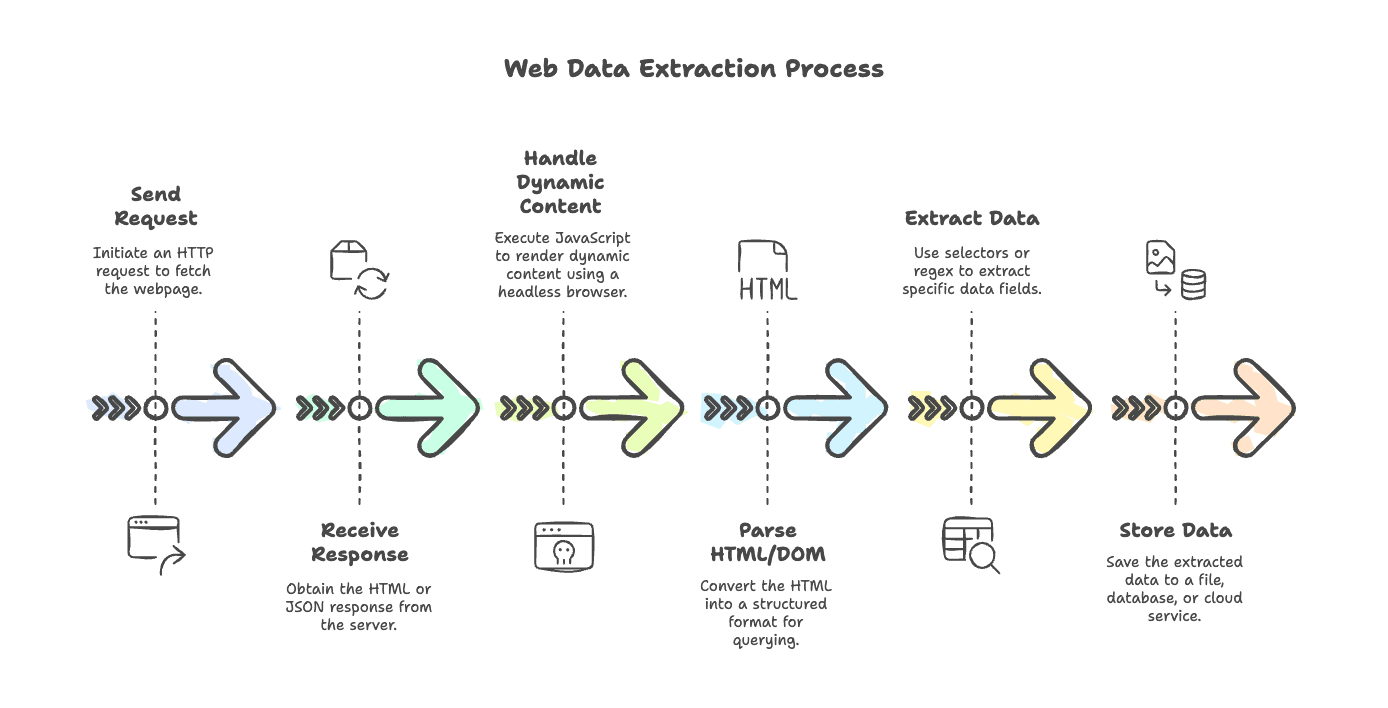
- 送出請求: 使用 HTTP 用戶端抓取頁面(例如
axios、node-fetch或got)。 - 接收回應: 從伺服器取得 HTML(有時也可能是 JSON)。
- 處理動態內容: 如果頁面是由 JavaScript 渲染,就用無頭瀏覽器(例如 Puppeteer 或 Playwright)執行腳本並取得最終內容。
- 解析 HTML/DOM: 使用解析器(
cheerio、jsdom)把 HTML 轉成可查詢的結構。 - 擷取資料: 用選擇器或正則表達式抓出需要的欄位。
- 儲存資料: 把結果存到檔案、資料庫或雲端服務。
每個步驟都有對應的工具與最佳實務,接下來我們一一拆開來看。
JavaScript 網頁爬蟲必備的 HTTP 請求函式庫
任何爬蟲的第一步,都是發送 HTTP 請求。Node.js 提供了不少選擇,既有經典款,也有現代派。以下整理幾個最熱門的函式庫:
1. Axios
這是一個同時支援 Node 與瀏覽器、以 Promise 為基礎的 HTTP 用戶端。對多數爬蟲需求來說,它就像瑞士刀一樣萬用。
const axios = require('axios');
const response = await axios.get('https://example.com/api/items', { timeout: 5000 });
console.log(response.data);
優點: 功能完整、支援 async/await、可自動解析 JSON、具備攔截器與代理支援。
缺點: 稍微重一些,資料處理方式有時會讓人覺得有點「魔法感」。
2. node-fetch
在 Node.js 中實作瀏覽器的 fetch API。輕量而現代。
import fetch from 'node-fetch';
const res = await fetch('https://api.github.com/users/github');
const data = await res.json();
console.log(data);
優點: 輕巧,對前端 JavaScript 使用者來說介面熟悉。
缺點: 功能較少、錯誤處理需手動完成、代理設定較冗長。
3. SuperAgent
一個老牌、可鏈式呼叫的 HTTP 函式庫。
const superagent = require('superagent');
const res = await superagent.get('https://example.com/data');
console.log(res.body);
優點: 成熟、支援表單、檔案上傳與外掛。
缺點: API 風格稍微老派,依賴也比較大。
4. Unirest
簡單、語言中立的 HTTP 用戶端。
const unirest = require('unirest');
unirest.get('https://httpbin.org/get?query=web')
.end(response => {
console.log(response.body);
});
優點: 語法簡單,適合快速腳本。
缺點: 功能較少,社群活躍度較低。
5. Got
一個功能強大、速度快的 Node.js HTTP 用戶端,還支援進階功能。
import got from 'got';
const html = await got('https://example.com/page').text();
console.log(html.length);
優點: 快、支援 HTTP/2、重試與串流。
缺點: 只適用 Node,新手可能會覺得 API 有點密集。
6. Node 內建的 http/https
你也可以直接走傳統路線:
const https = require('https');
https.get('https://example.com/data', (res) => {
let data = '';
res.on('data', chunk => { data += chunk; });
res.on('end', () => {
console.log('回應長度:', data.length);
});
});
優點: 不需要額外依賴。
缺點: 冗長、以 callback 為主、沒有 Promise。
在這裡查看詳細的功能比較與程式碼範例。
如何為專案選擇合適的 HTTP 用戶端
那麼,該怎麼選對工具?我通常會看這幾點:
- 易用性: Axios 與 Got 都很適合 async/await,語法也乾淨。
- 效能: Got 與 node-fetch 較精簡快速,適合高併發爬取。
- 代理支援: Axios 與 Got 都很容易做代理輪換。
- 錯誤處理: Axios 預設會對 HTTP 錯誤丟出例外;node-fetch 則需要手動檢查。
- 社群: Axios 與 Got 社群活躍,也有大量範例。
我的快速建議:
- 快速腳本或原型: node-fetch 或 Unirest。
- 正式爬取: Axios(功能完整)或 Got(效能佳)。
- 瀏覽器自動化: Puppeteer 或 Playwright 會在內部處理請求。
HTML 解析與資料擷取:Cheerio、jsdom 與更多選擇
當你拿到 HTML 之後,就需要把它轉成真正可用的資料。這時候解析器就派上用場了。
Cheerio
你可以把 Cheerio 想成伺服器端的 jQuery。它速度快、輕量,非常適合靜態 HTML。
const cheerio = require('cheerio');
const $ = cheerio.load('<ul><li class="item">Item 1</li></ul>');
$('.item').each((i, el) => {
console.log($(el).text());
});
優點: 極快、API 熟悉、能處理雜亂 HTML。
缺點: 不會執行 JavaScript,只能看到 HTML 裡已有的內容。
jsdom
jsdom 會在 Node.js 裡模擬類瀏覽器的 DOM。它可以執行簡單腳本,比 Cheerio 更像「真正的瀏覽器」。
const { JSDOM } = require('jsdom');
const dom = new JSDOM(`<p id="greet">Hello</p><script>document.querySelector('#greet').textContent += ", world!";</script>`);
console.log(dom.window.document.querySelector('#greet').textContent);
優點: 可執行腳本,支援完整 DOM API。
缺點: 比 Cheerio 慢且重,不是真正的瀏覽器。
什麼時候該用正則表達式或其他解析方法
在網頁爬蟲中,正則表達式就像辣醬——適量很好用,但千萬別什麼都往上倒。正則適合用在:
- 從文字中擷取模式(電子郵件、電話號碼、價格)。
- 清理或驗證爬回來的資料。
- 從大量文字或 script 標籤中抓資料。
範例:從文字中擷取數字
const text = "總銷售量:1,234 件";
const match = text.match(/([\d,]+)\s*件/);
if (match) {
const units = parseInt(match[1].replace(/,/g, ''));
console.log("售出數量:", units);
}
不過不要試圖用正則解析整份 HTML——這種情況請改用 DOM 解析器。更多爬蟲正則技巧。
處理動態網站:Puppeteer、Playwright 與無頭瀏覽器
現代網站都很愛 JavaScript。有時候,你要的資料根本不在初始 HTML 裡,而是頁面載入後才由腳本渲染出來。這時候就輪到無頭瀏覽器登場。
Puppeteer
這是 Google 出品、可控制 Chrome/Chromium 的 Node.js 函式庫。你可以把它想成一個會幫你點擊、捲動頁面的機器人。
const puppeteer = require('puppeteer');
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
const title = await page.$eval('h1', el => el.textContent);
console.log(title);
await browser.close();
優點: 完整的 Chrome 渲染、API 簡單、很適合動態內容。
缺點: 只支援 Chromium、資源消耗較高。
Playwright
這是 Microsoft 較新的函式庫,支援 Chromium、Firefox 與 WebKit。你可以把它視為 Puppeteer 的更酷、跨瀏覽器版表親。
const { chromium } = require('playwright');
const browser = await chromium.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
const content = await page.textContent('h1');
console.log(content);
await browser.close();
優點: 跨瀏覽器、可平行處理多個 context、元素自動等待。
缺點: 學習曲線稍高、安裝包較大。
Nightmare
這是一個以 Electron 為基礎的自動化工具,幾年前曾經很受歡迎。它的倉庫已被移到 segment-boneyard GitHub 組織——那是 Segment 存放停止維護專案的停車場——而最後一次 npm 版本發布已經是 2019 年。我不會在 2026 年把它用在新專案上;如果你接手的腳本還在用它,那就先維持,但若是新案子,請直接跳到 Playwright 或 Puppeteer。
無頭瀏覽器方案比較
| 面向 | Puppeteer(Chrome) | Playwright(多瀏覽器) | Nightmare(Electron) |
|---|---|---|---|
| 瀏覽器支援 | Chrome/Edge | Chrome、Firefox、WebKit | Chrome(舊版) |
| 效能與規模 | 快,但偏重 | 快,平行能力更好 | 較慢、穩定性較差 |
| 動態爬取 | 非常優秀 | 非常優秀,且功能更多 | 適合簡單網站 |
| 維護狀態 | 持續維護 | 非常活躍 | 已封存(segment-boneyard,最後一次 npm 發布為 2019) |
| 最適合 | Chrome 爬取 | 複雜、跨瀏覽器任務 | 簡單、舊有工作流程 |
我的建議: 新的複雜專案請用 Playwright。Puppeteer 對只做 Chrome 的任務仍然很棒。Nightmare 比較適合懷舊,或拿來維護舊腳本。
支援工具:排程、環境、CLI 與資料儲存
真實世界中的爬蟲,不只是抓取與解析而已。以下是我常依賴的支援工具:
排程:node-cron
讓爬蟲自動定時執行。
const cron = require('node-cron');
cron.schedule('0 9 * * MON', () => {
console.log('每週一早上 9 點爬取');
});
環境管理:dotenv
把密鑰與設定檔變數留在程式碼外。
require('dotenv').config();
const apiKey = process.env.API_KEY;
CLI 工具:chalk、commander、inquirer
- chalk: 美化終端機輸出顏色。
- commander: 解析命令列選項。
- inquirer: 提供互動式提示,接收使用者輸入。
資料儲存
- fs: 寫入檔案(JSON、CSV)。
- lowdb: 輕量級 JSON 資料庫。
- sqlite3: 本機 SQL 資料庫。
- mongodb: 適合大型專案的 NoSQL 資料庫。
範例:將資料儲存為 JSON
const fs = require('fs');
fs.writeFileSync('output.json', JSON.stringify(data, null, 2));
JavaScript 與 Node.js 傳統網頁爬蟲的痛點
老實說,傳統爬蟲並不是只有陽光和彩虹。以下是我見過、也親身感受過的最大痛點:

- 學習門檻高: 你得搞懂 DOM、選擇器、非同步邏輯,有時還得處理瀏覽器的特殊行為。
- 維護成本高: 網站一改版,選擇器就失效,你得不停修補程式。
- 擴充性差: 每個網站都需要自己的腳本;沒有真正的「一套通吃」。
- 資料清理複雜: 爬回來的資料通常很亂,清理、格式化與去重本身就是一份工作。
- 效能受限: 瀏覽器自動化速度慢,而且在大規模任務下非常吃資源。
- 封鎖與反機器人措施: 網站會擋爬蟲、跳 CAPTCHA,或把資料藏在登入後面。
- 法律與倫理的灰色地帶: 你得處理服務條款、隱私與合規問題。
Thunderbit vs. 傳統網頁爬蟲:一場生產力革命
現在來談談大家心裡的大象:如果你可以跳過所有程式碼、選擇器與維護工作呢?
這就是 Thunderbit 出場的地方。身為共同創辦人兼執行長,我可能有點偏心,但請聽我說完——Thunderbit 就是為想要資料、不要麻煩的商務使用者而打造。
Thunderbit 的比較方式
| 面向 | Thunderbit(AI 零程式碼) | 傳統 JS/Node 爬取 |
|---|---|---|
| 設定 | 2 次點擊,免寫程式 | 寫腳本、除錯 |
| 動態內容 | 在瀏覽器內直接處理 | 需要無頭瀏覽器腳本 |
| 維護 | AI 可自動適應變化 | 需手動更新程式 |
| 資料擷取 | AI 建議欄位 | 手動選擇器 |
| 子頁面爬取 | 內建,一鍵完成 | 每個網站都要迴圈與撰寫程式 |
| 匯出 | Excel、Sheets、Notion | 手動整合檔案/資料庫 |
| 後處理 | 摘要、標記、格式化 | 需要額外程式或工具 |
| 誰都能用 | 只要有瀏覽器的人都能用 | 只有開發者能用 |
Thunderbit 的 AI 會讀取頁面、建議欄位,並在短短幾次點擊內完成資料擷取。它能處理子頁面、適應版面變動,甚至在抓取時同步摘要、標記或翻譯資料。你可以匯出到 Excel、Google Sheets、Airtable 或 Notion,完全不需要技術設定。
Thunderbit 特別適合的場景:
- 追蹤競爭對手 SKU 與價格的電商團隊
- 抓取潛在客戶與聯絡資訊的業務團隊
- 整合新聞或評論的市場研究人員
- 抓取房源列表與物件資訊的房地產經紀人
對於高頻率、攸關營運的爬取任務,Thunderbit 能大幅節省時間。若是客製化、大規模、或深度整合的專案,傳統腳本仍然有它的用武之地;但對多數團隊來說,Thunderbit 是從「我需要資料」到「我已經拿到資料」最快的路徑。
看看 Thunderbit Chrome 擴充功能的實際操作 或到 Thunderbit 部落格 了解更多應用案例。
快速參考:熱門 JavaScript 與 Node.js 網頁爬蟲函式庫
這份清單能幫你快速掌握 2026 年的 JavaScript 爬蟲生態系:
HTTP 請求
- Axios:以 Promise 為基礎,功能完整的 HTTP 用戶端。
- node-fetch:Node.js 的 Fetch API。
- Got:快速、進階的 HTTP 用戶端。
- SuperAgent:成熟、可鏈式呼叫的 HTTP 請求工具。
- Unirest:簡單、語言中立的用戶端。
HTML 解析
動態內容
- Puppeteer:無頭 Chrome 自動化。
- Playwright:多瀏覽器自動化。
- Nightmare:基於 Electron 的舊版瀏覽器自動化工具。
排程
- node-cron:Node.js 中的 cron 工作。
CLI 與工具
儲存
框架
- Crawlee:Apify 提供的高階爬蟲與抓取框架。截至 2026 年 5 月,JavaScript/TypeScript 版本已到 v3.16,屬於較成熟的主線(Python 移植版較新)。它把 Puppeteer、Playwright、Cheerio 與 JSDOM 包在同一個 API 後面,內建代理輪換與佇列機制——如果你常常得替自己的爬蟲重複搭相同的腳手架,這會很有幫助。
(請務必查看最新文件與 GitHub 倉庫以確認更新。)
學習 JavaScript 網頁爬蟲的推薦資源
想再深入一點嗎?這裡有一份精選資源清單,幫你提升爬蟲實力:
官方文件與指南
教學與課程
- freeCodeCamp:The Ultimate Guide to Web Scraping with Node.js
- YouTube:Web Scraping with Node.js(freeCodeCamp)
- DigitalOcean:如何使用 Node.js 與 Puppeteer 抓取網站
開源專案與範例
社群與論壇
書籍與完整指南
- O’Reilly 的《Web Scraping with Python》(用來理解跨語言概念)
- Udemy/Coursera 的《Web Scraping in Node.js》課程
(也請隨時確認最新版本與更新。)
如何使用 AI 抓取任何網站 Get Started Free
結論:為你的團隊選擇正確做法
結論很簡單:JavaScript 與 Node.js 為網頁爬蟲提供了驚人的能力與彈性。你可以打造從簡單粗暴的腳本,到穩健、可擴充的爬蟲,什麼都行。但能力越大,維護工作也越大。傳統腳本最適合需要完全控制權、而且願意持續維護的客製化工程型專案。
對其他所有人——商務使用者、分析師、行銷人員,以及只想拿到資料的人——像 Thunderbit 這類現代無程式碼方案,真的會讓人眼前一亮。Thunderbit 的 AI Chrome 擴充功能能在幾分鐘內完成資料擷取、結構化與匯出,而不是花上好幾天。免寫程式、免選擇器、免煩惱。
那麼,哪種方法最適合你?如果你的團隊有工程能力,而且需求獨特,那就深入 Node.js 工具箱。如果你想要速度、簡單,以及把注意力放在洞察而不是基礎架構上,那就試試 Thunderbit。無論哪條路,網路都是你的資料庫——去把資料拿回來吧。
如果你哪天卡住了,記得:就連最厲害的爬蟲,一開始也是從空白頁面和一杯濃咖啡開始的。祝你爬取愉快。
想進一步了解 AI 驅動的爬取,或親眼看看 Thunderbit 的實際操作嗎?
如果你有問題、故事,或最喜歡的爬蟲恐怖經驗,歡迎在留言區留下來,或直接聯絡我。我很喜歡看見大家如何把網路變成自己的資料遊樂場。
保持好奇、保持咖啡因,並且用更聰明的方式爬取,而不是更費力。
試用 AI 網頁爬蟲 Get Started Free
常見問題:
1. 為什麼要在 2025 年用 JavaScript 和 Node.js 做網頁爬蟲?
因為現代網站大多是用 JavaScript 建構的。Node.js 速度快、適合非同步,還有豐富的生態系(例如 Axios、Cheerio、Puppeteer),從簡單抓取到大規模動態內容爬取都能支援。
2. 用 Node.js 抓取網站的典型流程是什麼?
通常會像這樣:
請求 → 處理回應 →(可選)執行 JS → 解析 HTML → 擷取資料 → 儲存或匯出
每個步驟都可以交給像 axios、cheerio 或 puppeteer 這類專門工具來處理。
3. 要怎麼抓取動態、由 JavaScript 渲染的頁面?
使用像 Puppeteer 或 Playwright 這類無頭瀏覽器。它們會載入完整頁面(包含 JS),因此可以抓到使用者實際看到的內容。
4. 傳統爬蟲最大的挑戰是什麼?
- 網站結構變動
- 反機器人偵測
- 瀏覽器資源成本
- 手動資料清理
- 長期維護負擔高
這些問題讓大規模或不友善於開發者的爬取方式很難長期維持。
5. 什麼時候該用 Thunderbit 這類工具,而不是自己寫程式?
當你需要速度、簡單,而且不想撰寫或維護程式時,就該用 Thunderbit。它特別適合銷售、行銷或研究團隊,需要快速擷取並結構化資料,尤其是來自複雜或多頁網站的資料。




