我還記得第一次想從網站抓產品資料的時候,畫面上滿滿的跑鞋讓我以為:「把這些名稱和價格丟進 Excel,應該很簡單吧?」結果幾個小時後,我卻卡在 JavaScript 錯誤、搞不清楚的選擇器,對那些能從零寫出網頁爬蟲的人,真的打從心底佩服。
如果你也有過類似經驗——不管你是做銷售、電商還是營運,只是想快點拿到即時數據來做決策——你絕對不是孤單一人。這幾年,網頁爬蟲的需求暴增。事實上,全球,預計到 2030 年還會再翻一倍。不過,傳統爬蟲工具通常需要一點技術底子。所以這次我想帶你看看兩種完全不同的做法:一種是用 Cypress、需要寫程式的方式,另一種則是用 這種 AI 驅動、完全免寫程式的快速解決方案。我們會以 當範例。
不管你是想練 JavaScript 的開發者,還是只想輕鬆拿到資料的商務夥伴,這篇教學都能幫你輕鬆搞定資料抓取,讓你不用再為這些事煩惱,也不用犧牲週末。
什麼是網頁爬蟲?為什麼企業都在用?
簡單來說,網頁爬蟲就是讓電腦自動幫你從網站上抓資料。你不用再一個一個複製貼上產品名稱、價格或聯絡方式,這些瑣事交給軟體就好。
那這對企業有什麼好處?現在的數據就像新時代的石油(或燕麥奶,看你愛哪一種)。銷售、電商、營運等公司都靠網頁爬蟲來:
- 開發潛在客戶:自動從名錄或社群平台抓聯絡方式。
- 監控競爭對手價格與產品趨勢——大約。
- 分析顧客評價:自動抓評論和評分,掌握市場聲音。
- 自動化重複性研究:省下原本要花好幾小時甚至幾天的人工作業。
而且這些努力真的有回報:都說公開網路數據讓他們決策更快、更精準。換句話說,如果你還沒開始用網頁爬蟲,可能已經錯過不少商機和洞察。
認識 Cypress:熱門的網頁爬蟲工具
來聊聊工具。Cypress 是一套開源框架,原本是做網頁自動化測試用的。你可以把它想像成一個機器人,會自動點按鈕、填表單、檢查網站功能有沒有壞掉。不過因為 Cypress 能在真實瀏覽器裡跑、支援 JavaScript 動態網站,所以也很適合拿來當網頁爬蟲(雖然有點另類)。
那 Cypress 跟常見的 Python 爬蟲(像 BeautifulSoup 或 Scrapy)有什麼差別?簡單比較一下:
- Cypress:特別適合抓動態、JavaScript 渲染的內容。需要會 JavaScript 和 Node.js,彈性高、功能強大,但比較偏開發者。
- Python 爬蟲:像 BeautifulSoup 或 Scrapy 這類適合大規模抓靜態 HTML,生態系很完整,但遇到需要瀏覽器渲染的網站就比較麻煩。
如果你本來就會 JavaScript 或有自動化測試經驗,Cypress 很適合你。但如果你對寫程式沒興趣,別擔心,後面還有完全免寫程式的選擇。
實作教學:用 Cypress 抓 Adidas 男款跑鞋資料
現在來實戰一下,用 Cypress 寫一個爬蟲,目標是從 抓產品名稱、價格、圖片和連結,最後匯出成檔案。
1. 建立 Cypress 開發環境
首先,你要先安裝 和 npm。準備好後,打開終端機輸入:
1mkdir adidas-scraper
2cd adidas-scraper
3npm init -y
4npm install cypress --save-dev這樣就建立好新專案並安裝 Cypress。接著啟動 Cypress:
1npx cypress openCypress 會自動幫你建立 cypress/ 目錄和範例測試檔案。你可以把範例刪掉,自己新增一個檔案,例如 cypress/e2e/adidas-scraper.cy.js。
2. 觀察網站結構,找出要抓的資料
打開 ,在瀏覽器右鍵點產品,選「檢查」。你會發現每個產品都包在一個卡片區塊,裡面有名稱、價格、圖片和連結。
舉例來說,可能會看到:
1<div class="product-card">
2 <a href="/us/adizero-sl2-running-shoes/XYZ123.html">
3 <img src="..." alt="Adizero SL2 Running Shoes"/>
4 <div class="product-price">$130</div>
5 <div class="product-name">Adizero SL2 Running Shoes -- Men's Running</div>
6 </a>
7</div>記得注意像 .gl-price 這種 class 名稱,找出 HTML 結構的規律,這樣才能正確告訴 Cypress 要抓哪些資料。
3. 撰寫 Cypress 程式碼進行資料擷取
以下是一個簡單的 Cypress 腳本範例:
1// cypress/e2e/adidas-scraper.cy.js
2describe('Scrape Adidas Running Shoes', () => {
3 it('collects product name, price, image, and link', () => {
4 cy.visit('<https://www.adidas.com/us/men-running-shoes>');
5 const products = [];
6 cy.get('a[href*="/us/"][href*="running-shoes"]').each(($el) => {
7 const name = $el.find('*:contains("Running Shoes")').text().trim();
8 const price = $el.find('.gl-price').text().trim();
9 const imageUrl = $el.find('img').attr('src');
10 const link = $el.attr('href');
11 products.push({ name, price, image: imageUrl, link: `https://www.adidas.com$\{link\}` });
12 }).then(() => {
13 cy.writeFile('cypress/output/adidas_products.json', products);
14 });
15 });
16});這段程式碼在做什麼?
cy.visit()進入網頁。cy.get()選出所有符合 Adidas 產品連結格式的元素。.each()逐一處理每個產品,抓名稱、價格、圖片和連結。- 把資料存進陣列,最後寫成 JSON 檔案。
如果 Adidas 網站結構有變,記得調整選擇器。不過這個範例已經能應付大多數情境。
4. 匯出與應用抓到的資料
執行腳本(用 Cypress 介面或 npx cypress run),然後檢查 cypress/output/adidas_products.json 檔案。你會看到像這樣的資料:
1[
2 {
3 "name": "Adizero SL2 Running Shoes Men's Running",
4 "price": "$130",
5 "image": "<https://assets.adidas.com/images/w_280,h_280,f_auto,q_auto:sensitive/.../adizero-SL2-shoes.jpg>",
6 "link": "<https://www.adidas.com/us/adizero-sl2-running-shoes/XYZ123.html>"
7 },
8 ...
9]接下來你可以把 JSON 轉成 CSV,丟進 Excel 分析,或匯入 BI 工具。如果想進階一點,還能自動化每天執行,做價格監控。
用 Cypress 抓網頁常見的挑戰
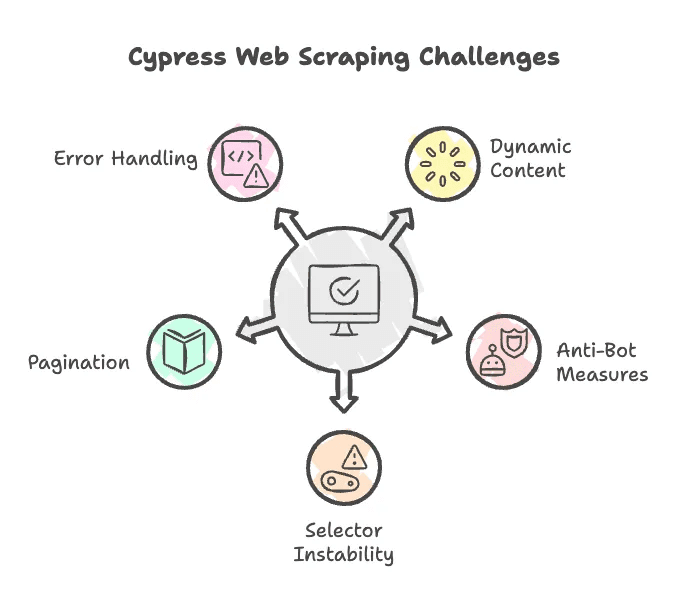
說真的,網頁爬蟲不會永遠順利。用 Cypress 會遇到這些常見問題(附上解法):
- JavaScript 動態內容:Cypress 能處理動態資料,但有時要等元素載入或手動滾動頁面觸發 lazy loading。可以用
cy.wait()或滾動指令幫忙。 - 反爬蟲機制:有些網站會檢查用戶代理或限制請求頻率。Cypress 在真實瀏覽器執行有優勢,但遇到嚴格防護時,可能要用代理伺服器或偽造標頭等進階技巧。
- 選擇器不穩定:如果 Adidas 改了 HTML 結構或 class 名稱,腳本就會失效。要定期檢查並更新選擇器。
- 分頁處理:大多數產品頁都有多頁內容,需要寫邏輯自動點「下一頁」並彙整所有資料。
- 錯誤處理:Cypress 主要設計給測試用,遇到缺漏元素時會直接報錯。建議加上判斷,讓腳本能優雅處理異常。
如果你覺得光是為了抓一份鞋子清單就像在修電腦科學學位,別擔心,這正是我們打造 Thunderbit 的原因。
太複雜?Thunderbit 兩步驟輕鬆搞定網頁資料
如果你不想碰 Node.js、不想研究選擇器,也不想 debug JavaScript,那就試試 這款 AI 網頁爬蟲 Chrome 擴充功能。它專為商務用戶設計,讓你完全免寫程式、免設定,輕鬆拿到你要的資料。
Thunderbit 有哪些優點?
- 完全免寫程式、免調選擇器:只要點幾下,AI 自動幫你搞定。
- 一套模板,多站通用:Thunderbit 的 AI 能自動適應不同頁面結構,不用每次都重新設定。
- 支援瀏覽器與雲端爬取:可依需求選擇速度或精準度。
- 自動處理分頁與子頁面:Thunderbit 能自動點擊多頁,甚至進入產品詳情頁補資料。
- 免費匯出:一鍵匯出到 Excel、Google Sheets、Airtable 或 Notion,沒有隱藏收費。
以下用 Thunderbit 抓 Adidas 頁面,帶你快速上手。
實作教學:用 Thunderbit 抓 Adidas 資料
1. 安裝 Thunderbit Chrome 擴充功能
先到 。只要 30 秒,比我早上找咖啡杯還快。
註冊免費帳號——Thunderbit 提供免費試用(10 頁)和免費方案(每月 6 頁),不用刷卡就能直接體驗。
2. 用 AI 智慧欄位自動抓資料
- 開啟 。
- 點瀏覽器上的 Thunderbit 擴充功能圖示,側邊欄會自動彈出。
- 按下 「AI 智慧欄位」,Thunderbit 的 AI 會自動掃描頁面,辨識出產品名稱、價格、圖片和連結,並預覽前幾筆資料。
- 想調整欄位?可以直接改名或新增欄位。想進階一點,還能用自然語言指令(像「也抓取可選顏色數量」)讓 AI 幫你擴充資料。
- 點 「開始抓取」,Thunderbit 會自動擷取所有資料,遇到多頁會自動翻頁。如果想抓每個產品的更多細節,也能啟用子頁面爬取功能,Thunderbit 會自動進入每個產品頁補資料。
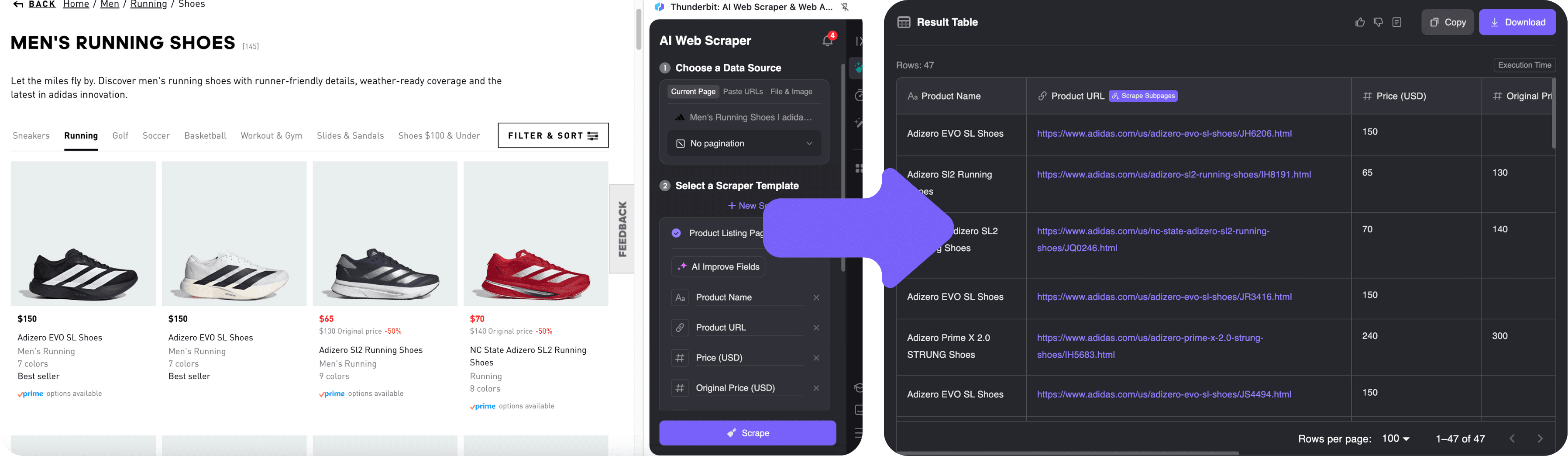
3. 匯出與應用你的資料
抓完後,在 Thunderbit 側邊欄檢查資料表。你可以:
- 一鍵匯出到 Excel、Google Sheets、Airtable 或 Notion。
- 下載成 CSV 或 JSON 檔案。
- 匯出圖片、Email、電話等多種資料型態——Thunderbit 支援常見格式。
而且匯出完全免費,沒有「驚喜收費」的陷阱。
想學更多技巧,歡迎參考我們的 或逛逛 看更多教學。
Cypress vs Thunderbit:哪種網頁爬蟲工具適合你?
來比較一下 Cypress 和 Thunderbit,重點整理如下:
| Aspect | Cypress (程式碼爬蟲) | Thunderbit (無程式碼 AI 爬蟲) |
|---|---|---|
| 安裝難度 | 需安裝 Node.js、npm 並具備 JavaScript 技能,對非技術人員較不友善。 | 安裝 Chrome 擴充功能、登入帳號,幾分鐘內即可開始,完全免寫程式。 |
| 技術門檻 | 需懂 JavaScript 及 DOM/CSS 選擇器,入門門檻高。 | 完全免寫程式,採用自然語言與點選介面。 |
| 執行速度 | 撰寫與除錯腳本需花數小時,遇到複雜頁面或分頁更費時。 | 幾個步驟即可完成,分頁與子頁面自動處理。 |
| 彈性 | 極高彈性——可自訂邏輯、處理登入、驗證碼、API 整合等。 | 適合標準網頁結構,AI 可處理大多數網站,極特殊情境可能需手動調整。 |
| 對網站變動的適應力 | 腳本易受 HTML 結構變動影響,需常常維護。 | AI 能自動適應小幅度版面變動,Thunderbit 團隊持續優化模型。 |
| 擴展性 | 可處理中等規模資料,但瀏覽器爬取大量頁面較慢。 | 雲端爬取可處理數百頁,採用點數制,適合商務需求。 |
| 適合對象 | 需要高度自訂與精細控制的開發者或技術人員,適合一次性或複雜流程。 | 想快速、無痛抓取資料的商務用戶,適合重複性任務如價格監控、名單開發、資料整理,特別適合電商、名錄、評論等標準頁面。 |
總結:**Cypress 給你極致彈性,Thunderbit 則主打速度與簡單。**如果你熱愛寫程式、喜歡挑戰,Cypress 很適合你。如果你只想快速拿到資料(尤其老闆還催著要),Thunderbit 絕對是你的好幫手。
重點整理:怎麼選最適合你的網頁爬蟲方案
- 網頁爬蟲已經是現代企業的必備工具——不管是監控競爭對手、開發潛在客戶,還是分析市場趨勢。
- Cypress 適合開發者自訂流程,能處理動態網站和複雜需求,但學習曲線高、需要持續維護。
- Thunderbit 則為所有人設計。這款讓你兩步驟就能完成爬蟲,免寫程式、免設定,分頁、子頁面、匯出通通免費。
- 如果你需要極致彈性又不怕寫程式,選 Cypress。
- 如果你想省時省力、避開技術障礙、快速拿到乾淨資料,Thunderbit 是最佳選擇——特別適合銷售、電商、行銷、營運等商務場景。
想看更多實例,歡迎逛逛 ,有關、等教學。
下次當你面對一整頁跑鞋,想把資料整理進試算表時,記得你有很多選擇。祝你抓取順利!
常見問題
1. 什麼是 Cypress?它怎麼用在網頁爬蟲?
Cypress 是一款基於 JavaScript 的測試工具,能和動態網站互動,非常適合抓 JavaScript 渲染的內容。
2. 用 Cypress 抓網站會遇到哪些挑戰?
常見問題包括網站結構變動、延遲載入、反爬蟲機制,以及處理分頁或缺漏元素等複雜情境。
3. 有沒有更簡單、免寫程式的網頁爬蟲方法?
有,Thunderbit 是一款 AI 驅動的 Chrome 擴充功能,只要幾個步驟就能抓資料,完全免寫程式、免設定、免調選擇器。
延伸閱讀: