

打開終端機,輸入一行指令,看著原始網路資料像是剛破解《駭客任務》一樣傾瀉而來,這種感覺到現在還是很迷人。對開發者和技術型重度使用者來說,cURL 就像那根魔法棒——這個看起來不起眼的命令列工具,其實默默運作在數十億台裝置上,從雲端伺服器到你的智慧冰箱都少不了它。即使到了 2026 年,市面上已經有各式各樣無程式碼和 AI 擷取工具,使用 cURL 進行網頁爬蟲仍然是任何追求速度、控制力與可腳本化流程的人最常用的方法之一。
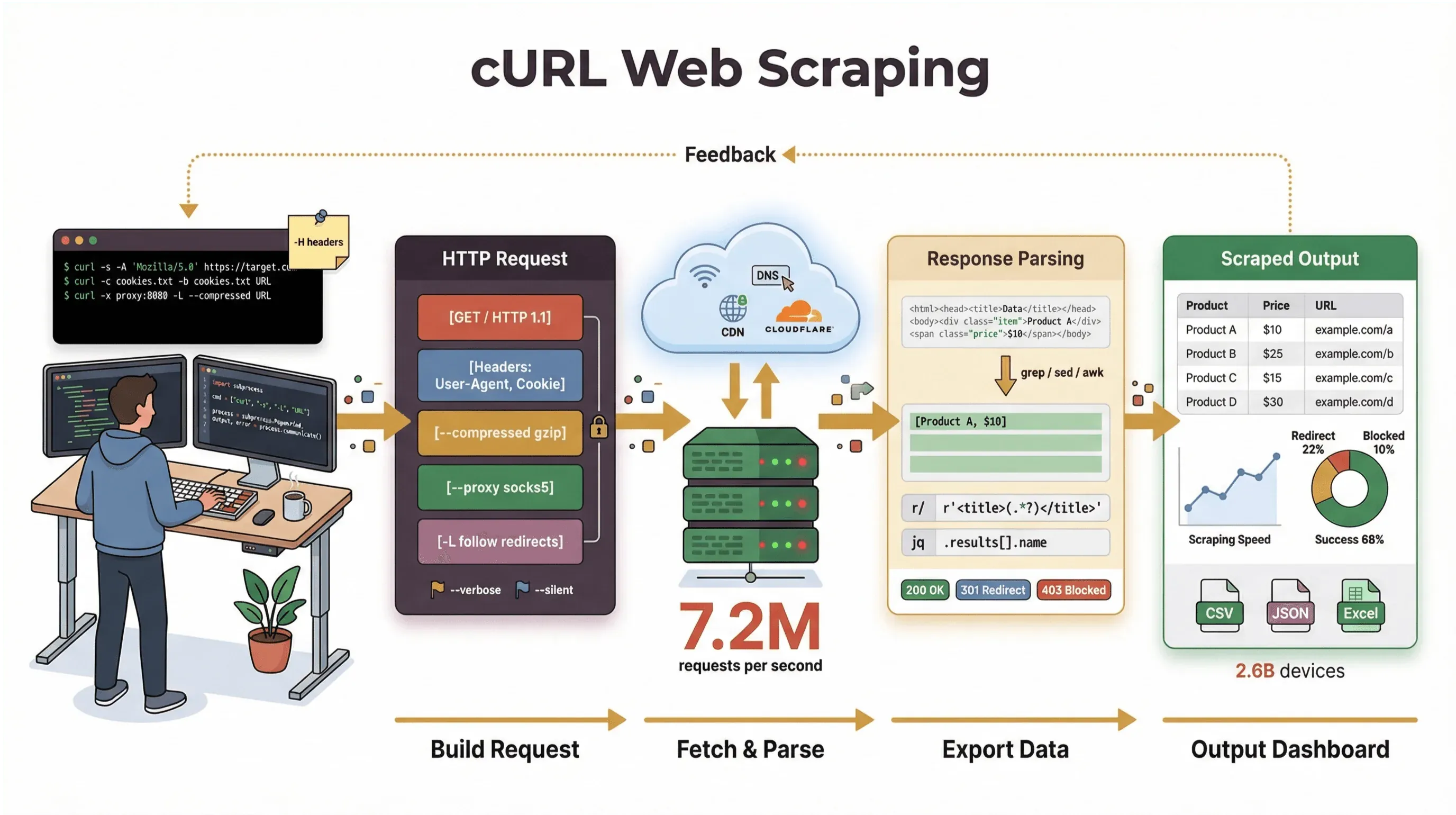 我花了好幾年打造自動化工具、協助團隊處理網頁資料;每當需要抓頁面、除錯 API,或是快速做個爬取流程原型時,我還是會先想到 cURL。在這篇指南裡,我會帶你完整了解 cURL 網頁爬蟲教學,從基礎到進階技巧一次涵蓋,包含實際指令範例、實用建議,以及 cURL 擅長之處與卡關時機的清楚分析。若你比較偏向商務使用者,不想碰命令列,我也會示範我們的 AI 網頁爬蟲 Thunderbit 如何讓你從「我需要這些資料」直接走到「這是我的試算表」,只要兩次點擊,完全不用寫程式。
我花了好幾年打造自動化工具、協助團隊處理網頁資料;每當需要抓頁面、除錯 API,或是快速做個爬取流程原型時,我還是會先想到 cURL。在這篇指南裡,我會帶你完整了解 cURL 網頁爬蟲教學,從基礎到進階技巧一次涵蓋,包含實際指令範例、實用建議,以及 cURL 擅長之處與卡關時機的清楚分析。若你比較偏向商務使用者,不想碰命令列,我也會示範我們的 AI 網頁爬蟲 Thunderbit 如何讓你從「我需要這些資料」直接走到「這是我的試算表」,只要兩次點擊,完全不用寫程式。
讓我們開始,看看為什麼 cURL 在 2026 年依然與網頁爬蟲息息相關、該怎麼有效使用它,以及什麼時候該升級到更強大的工具。
什麼是 cURL?網頁爬蟲的基礎
從本質上來說,cURL 是一個用來透過 URL 傳輸資料的命令列工具與函式庫。它已經存在將近 30 年了——沒錯,真的有這麼久——而且無所不在:嵌入作業系統、驅動腳本,並在超過 兩百億次安裝 中安靜地處理資料傳輸。只要你曾經用一行指令抓網頁、測試 API 或下載檔案,很有可能你已經用過 cURL。
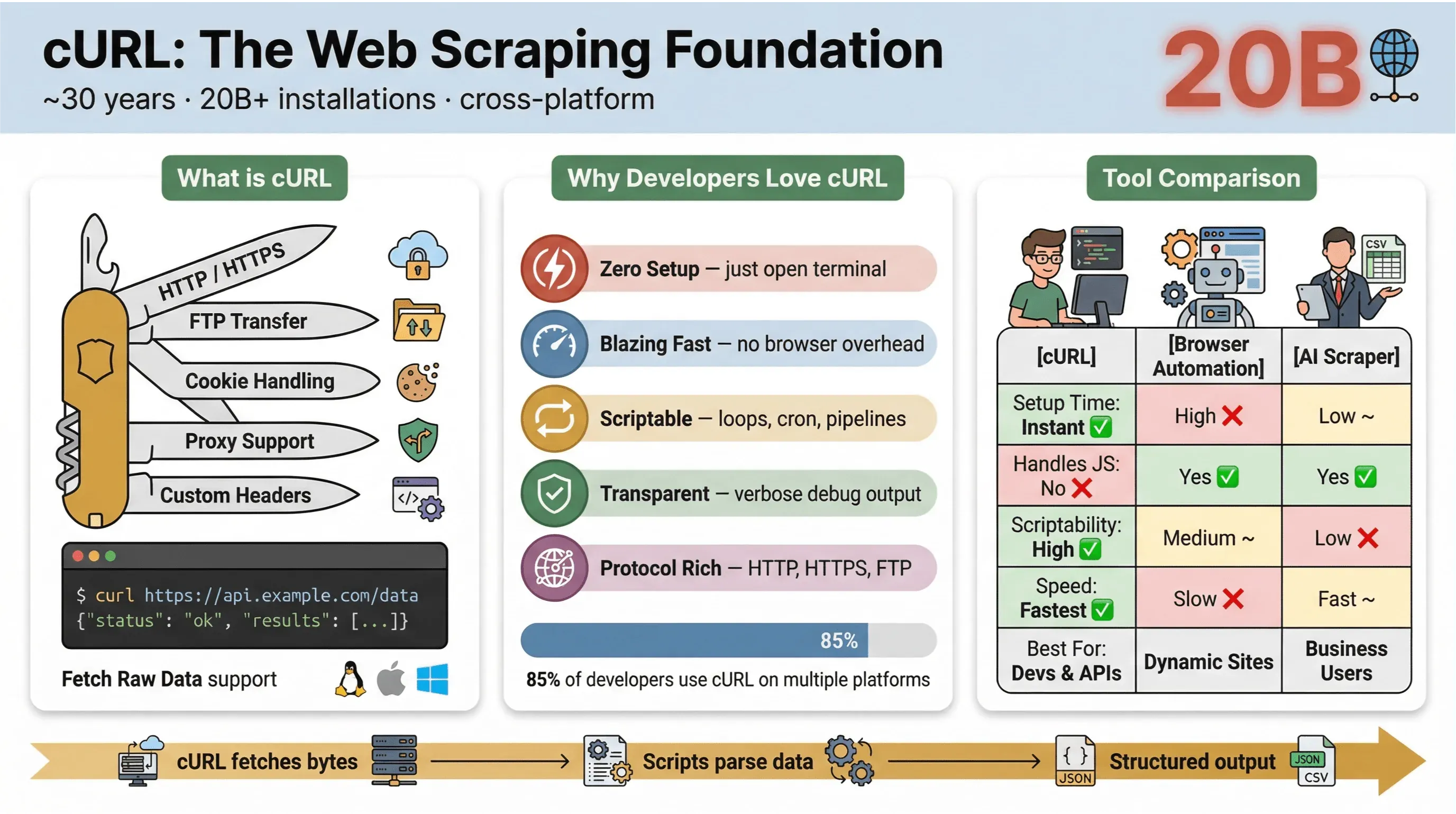 以下是 cURL 在網頁爬蟲領域特別受歡迎的原因:
以下是 cURL 在網頁爬蟲領域特別受歡迎的原因:
- 輕量且跨平台: 可在 Linux、macOS、Windows,甚至嵌入式裝置上執行。
- 支援多種協定: 可處理 HTTP、HTTPS、FTP 等等。
- 可腳本化: 非常適合自動化、排程工作與膠水程式。
- 不需要使用者互動: 專為非互動式使用而設計,非常適合批次作業與管線流程。
但先說清楚:cURL 的主要工作是抓取原始資料——HTML、JSON、圖片,應有盡有。它不會幫你解析、渲染或結構化這些資料。你可以把 cURL 想成網頁爬蟲的「第一哩路」:它先把位元組抓回來,但後續還需要其他工具(例如 Python 腳本、grep/sed/awk,或 AI 網頁爬蟲)把資料整理成結構化資訊。
如果你想看官方文件,可以參考 cURL 的 HTTP scripting guide。
為什麼要用 cURL 進行網頁爬蟲?(cURL 網頁爬蟲教學)
既然現在有這麼多新工具,為什麼開發者和技術使用者還是一直回頭用 cURL 來做網頁爬蟲?以下是 cURL 的亮點:
- 設定極少: 不必安裝、不必處理依賴,只要打開終端機就能開始。
- 速度快: 不需要等瀏覽器載入,立即抓取資料。
- 可腳本化: 很容易迴圈處理多個 URL、自動化請求、串接指令。
- 協定與功能支援完整: 可處理 cookie、proxy、重新導向、自訂標頭等。
- 透明度高: 搭配詳細與除錯輸出,可以清楚看到每一步發生了什麼。
根據 2025 cURL 使用者調查,85.7% 的受訪者表示他們使用 cURL 命令列工具,而 96.2% 表示他們在 Linux 上使用它——Linux 仍然以壓倒性優勢成為 cURL 的首選平台。
--- 它依然是處理 HTTP 請求、快速抓資料和排除問題的瑞士刀。
以下是 cURL 與其他爬取方式的快速比較:
| 功能 | cURL | 瀏覽器自動化(例如 Selenium) | AI 網頁爬蟲(例如 Thunderbit) |
|---|---|---|---|
| 設定時間 | 立即 | 高 | 低 |
| 可腳本化程度 | 高 | 中等 | 低(不需程式碼) |
| 處理 JavaScript | 否 | 是 | 是(Thunderbit:透過瀏覽器) |
| Cookie/工作階段支援 | 手動 | 自動 | 自動 |
| 資料結構化 | 手動(之後再解析) | 手動(之後再解析) | AI/範本式 |
| 最適合 | 開發者、快速抓取 | 複雜、動態網站 | 商務使用者、結構化匯出 |
簡而言之:cURL 在快速、可腳本化的資料抓取上幾乎無敵,尤其適合靜態頁面、API,或你想自動化簡單流程時。但一旦你需要解析複雜 HTML、處理 JavaScript,或匯出結構化資料,就會想要更專門的工具。
入門:cURL 網頁爬蟲基本指令範例
讓我們直接上手。以下會一步一步示範如何使用 cURL 完成基本的網頁爬蟲任務。
使用 cURL 擷取原始 HTML
最簡單的用途:抓取網頁的 HTML。
curl https://books.toscrape.com/
這個指令會抓取 Books to Scrape 的首頁,這是一個公開的網頁爬蟲示範網站。你會在終端機看到原始 HTML 輸出——可以留意 <title> 之類的標籤,或像 “In stock.” 這樣的片段。
將輸出儲存成檔案
想把 HTML 存下來之後再解析嗎?使用 -o 參數:
curl -o page.html https://books.toscrape.com/
現在你會得到一個包含完整 HTML 內容的 page.html 檔案。這非常適合之後再進一步分析,或搭配其他工具解析。
使用 cURL 傳送 POST 請求
需要提交表單或與 API 互動嗎?使用 -d 參數來發送 POST 請求。以下以 httpbin 為例,這是一個專門用來測試 HTTP 的網站:
curl -X POST https://httpbin.org/post -d "key1=value1&key2=value2"
你會收到一個 JSON 回應,內容會回顯你提交的資料,非常適合測試與原型開發。
檢視標頭與除錯
有時候你會想看回應標頭,或是除錯請求:
-
只看標頭(HEAD 請求):
curl -I https://books.toscrape.com/ -
包含標頭與內容:
curl -i https://httpbin.org/get -
詳細/除錯輸出:
curl -v https://books.toscrape.com/
這些參數能幫你了解底層到底發生了什麼,對排錯來說非常重要。
以下是這些指令的快速參考表:
| 任務 | 指令範例 | 備註 |
|---|---|---|
| 抓取 HTML | curl URL | 將 HTML 輸出到終端機 |
| 儲存成檔案 | curl -o file.html URL | 將輸出寫入檔案 |
| 檢視標頭 | curl -I URL 或 curl -i URL | -I 只看 HEAD,-i 則會將標頭與內容一起輸出 |
| 傳送 POST 表單資料 | curl -d "a=1&b=2" URL | 傳送以表單編碼的資料 |
| 除錯請求/回應 | curl -v URL | 顯示詳細的請求/回應資訊 |
更多範例可參考 cURL 官方 scripting 文件。
進階:用 cURL 做更高階的網頁爬蟲(cURL 網頁爬蟲)
當你掌握基礎後,cURL 還能開啟更多進階功能,應付更複雜的爬取任務。
處理 Cookie 與工作階段
許多網站需要 cookie 來維持登入狀態或追蹤使用者。使用 cURL,你可以在多次請求之間儲存並重用 cookie:
# 登入後儲存 cookie
curl -c cookies.txt https://example.com/login
# 後續請求使用 cookie
curl -b cookies.txt https://example.com/account
這樣你就能模擬瀏覽器工作階段,並存取登入後才看得到的頁面(前提是沒有 JavaScript 驗證)。
偽裝 User-Agent 與自訂標頭
有些網站會根據你的 User-Agent 或標頭提供不同內容。預設情況下,cURL 會將自己標示為「curl/VERSION」,這可能導致被封鎖或看到不同內容。若要模擬瀏覽器:
curl -A "Mozilla/5.0 (Windows NT 10.0; Win64; x64)" https://example.com/
你也可以設定自訂標頭,例如語言偏好:
curl -H "Accept-Language: en-US,en;q=0.9" https://example.com/
這有助於你取得與真實瀏覽器相同的內容。
使用 Proxy 進行網頁爬蟲
需要透過 proxy 轉送請求嗎(例如做地區測試或避免 IP 封鎖)?使用 -x 參數:
curl -x http://proxy.example.org:4321 https://remote.example.org/
只要記得負責任地使用 proxy,並遵守網站的服務條款即可。
自動化多頁爬取
想抓多個頁面,例如分頁的商品列表嗎?可以用簡單的 shell 迴圈:
for p in $(seq 2 5); do
curl -s -o "books-page-${p}.html" \
"https://books.toscrape.com/catalogue/category/books_1/page-${p}.html"
sleep 1
done
這段指令會抓取 Books to Scrape 目錄的第 2 到第 5 頁,並將每頁存成獨立檔案。(第 1 頁就是首頁。)
cURL 網頁爬蟲的限制:你必須知道的事
雖然我很喜歡 cURL,但它不是萬靈丹。以下是它的侷限:
- 不執行 JavaScript: cURL 無法處理需要 JavaScript 才能渲染內容,或需要解決反機器人挑戰的頁面 (developers.cloudflare.com)。
- 需要手動解析: 你拿到的是原始 HTML 或 JSON,還得自己解析,通常要再加上其他腳本或工具。
- 工作階段處理有限: 管理複雜登入、token 或多步驟表單時,流程很容易變得混亂。
- 沒有內建資料結構化: cURL 不會自動把網頁轉成列、表格或試算表。
- 容易被反機器人偵測: 現在很多網站都採用更進階的機器人防護(JavaScript、指紋辨識、CAPTCHA),這些都不是 cURL 能輕易繞過的 (datadome.co)。
以下是快速比較表:
| 限制 | 只用 cURL | 現代爬取工具(例如 Thunderbit) |
|---|---|---|
| JavaScript 支援 | 否 | 是 |
| 資料結構化 | 手動 | 自動(AI/範本) |
| 工作階段處理 | 手動 | 自動 |
| 反機器人繞過 | 有限 | 進階(瀏覽器式/AI) |
| 使用難度 | 技術性高 | 非技術使用者也能上手 |
對靜態頁面與 API 來說,cURL 非常出色;但只要是更動態或受保護的網站,你就需要往更上層的工具鏈走。
Thunderbit vs. cURL:非技術使用者的最佳網頁爬蟲方式
現在來談談 Thunderbit,我們的 AI 網頁爬蟲 Chrome 擴充功能。如果你是業務、行銷或營運人員,只想把網站資料抓到 Excel、Google Sheets 或 Notion,而不想碰命令列,那 Thunderbit 就是為你設計的。
Thunderbit 與 cURL 的比較如下:
| 功能 | cURL | Thunderbit |
|---|---|---|
| 使用介面 | 命令列 | 點選式操作(Chrome 擴充功能) |
| AI 欄位建議 | 否 | 是(AI 讀取頁面並建議欄位) |
| 處理分頁/子頁面 | 手動腳本 | 自動(AI 偵測並擷取) |
| 資料匯出 | 手動(解析+儲存) | 直接匯出到 Excel、Google Sheets、Notion、Airtable |
| JavaScript/受保護頁面 | 否 | 是(瀏覽器式爬取) |
| 不需程式碼 | 否(需要撰寫腳本) | 是(任何人都能使用) |
| 免費方案 | 永久免費 | 最多可免費抓取 6 個頁面(試用加成後為 10 個) |
有了 Thunderbit,您只要打開擴充功能,點一下「AI 建議欄位」,就能讓 AI 幫您判斷要擷取哪些資料。您可以抓表格、清單、商品細節,甚至自動前往子頁面。接著,直接把資料匯出到您最常用的商務工具,不需要解析,也不必頭痛。
Thunderbit 受到全球超過 10 萬名使用者 信賴,特別受到需要快速取得結構化資料的銷售、電商與房地產團隊歡迎。
試用 Thunderbit Chrome 擴充功能進行網頁爬蟲
想試試看嗎?在這裡下載 Chrome 擴充功能。
結合 cURL 與 Thunderbit:彈性的網頁爬蟲策略
如果你本來就是技術使用者,其實不必二選一。事實上,很多團隊會把 cURL 和 Thunderbit 一起用,取得最大的彈性:
- 用 cURL 做原型: 先快速測試端點、檢視標頭,並理解網站如何回應。
- 用 Thunderbit 擴大規模: 當你需要結構化資料、多頁爬取,或重複執行的流程時,就改用 Thunderbit 的點選式擷取與直接匯出。
以下是一個市場研究的範例流程:
- 使用 cURL 抓取幾個頁面並檢查 HTML 結構。
- 找出你要的資料欄位(例如商品名稱、價格、評論)。
- 打開 Thunderbit,點選「AI 建議欄位」,讓 AI 幫你設定爬蟲。
- 抓取所有頁面(包含子頁面或分頁清單)並匯出到 Google Sheets。
- 分析、分享並採取行動——完全不需要手動解析。
以下是快速決策表:
| 情境 | 使用 cURL | 使用 Thunderbit | 兩者並用 |
|---|---|---|---|
| 快速抓取 API 或靜態頁面 | ✅ | ||
| 需要將結構化資料放進試算表 | ✅ | ||
| 除錯標頭/cookie | ✅ | ||
| 爬取動態/大量 JavaScript 的頁面 | ✅ | ||
| 建立可重複、無程式碼的流程 | ✅ | ||
| 先做原型,再擴大規模 | ✅ | ✅ | 混合式流程 |
使用 cURL 網頁爬蟲時常見的挑戰與陷阱
在你開始大幅使用 cURL 之前,先來談談實務上會遇到的挑戰:
- 反機器人系統: 現在很多網站都使用更進階的防護(JavaScript 挑戰、CAPTCHA、指紋辨識),cURL 無法繞過 (developers.cloudflare.com)。
- 資料品質問題: HTML 變動、欄位缺失或版面不一致,都可能讓你的腳本失效。
- 維護成本: 只要網站一改版,你就得更新解析邏輯。
- 法律與合規風險: 抓取資料前,務必先查看網站服務條款、robots.txt,以及相關法規。資料公開,不代表你就能隨意使用 (calawyers.org, polsinelli.com)。
- 擴充限制: cURL 很適合小型任務,但若是大規模爬取,你就得管理 proxy、速率限制與錯誤處理。
除錯與合規建議:
- 永遠從允許抓取或示範網站開始(例如 Books to Scrape)。
- 尊重速率限制,不要狂打端點。
- 未經合法依據,不要抓取個人資料。
- 如果遇到 JavaScript 或 CAPTCHA 牆,考慮切換成像 Thunderbit 這類瀏覽器式工具。
逐步摘要:如何使用 cURL 抓取網站
以下是 cURL 網頁爬蟲的快速檢查清單:
- 確認目標 URL: 先從靜態頁面或 API 端點開始。
- 抓取頁面:
curl URL - 將輸出儲存成檔案:
curl -o file.html URL - 檢查標頭/除錯:
curl -I URL、curl -v URL - 傳送 POST 資料:
curl -d "a=1&b=2" URL - 處理 cookie/工作階段:
curl -c cookies.txt ...、curl -b cookies.txt ... - 設定自訂標頭/User-Agent:
curl -A "..." -H "..." URL - 跟隨重新導向:
curl -L URL - 視需要使用 proxy:
curl -x proxy:port URL - 自動化多頁爬取: 使用 shell 迴圈或腳本。
- 解析並結構化資料: 視需要搭配其他工具/腳本。
- 若要結構化、無程式碼爬取,或處理動態頁面,改用 Thunderbit。
結論與重點:選對網頁爬蟲工具
使用 AI 從任何網站抓取資料 Get Started Free
在 2026 年,使用 cURL 進行網頁爬蟲對技術使用者來說依然是一項強大的技能,尤其適合快速抓資料、做原型與自動化。cURL 的速度、可腳本化程度與普及性,使它成為每位開發者工具箱裡的基本配備。但隨著網站越來越動態、越來越多防護,而商務使用者又希望不用寫程式就能取得結構化資料,像 Thunderbit 這樣的工具正在重新定義可能性。
重點整理:
- 靜態頁面、API 與快速原型適合用 cURL——尤其是你想完全掌控流程時。
- 當你需要結構化資料、要處理動態/大量 JavaScript 的頁面,或想要無程式碼、適合商務使用者的流程時,請改用 Thunderbit(或其他類似的 AI 網頁爬蟲)。
- 兩者並用最有彈性:先用 cURL 做原型,再用 Thunderbit 擴大規模並整理結構。
- 永遠負責任地爬取資料——尊重網站條款、速率限制與法律界線。
想親自看看網頁爬蟲可以多簡單嗎?試用 Thunderbit 免費 Chrome 擴充功能 ,親身體驗 AI 驅動的資料擷取。如果你想再深入一點,也可以看看 Thunderbit Blog 的更多教學、技巧與產業洞見。你也可能會喜歡:
祝你抓取順利——願你的資料永遠乾淨、結構化,而且只要一行指令(或一次點擊)就能到手。
常見問題
1. cURL 能處理由 JavaScript 渲染的網頁嗎?
不能,cURL 無法執行 JavaScript。它只會擷取伺服器送出的原始 HTML。如果頁面需要 JavaScript 才能渲染內容或解決反機器人挑戰,cURL 就無法存取資料。這種情況下,請使用像 Thunderbit 這類瀏覽器式工具。
2. 我要怎麼把 cURL 輸出直接存成檔案?
使用 -o 參數:curl -o filename.html URL。這樣會把回應本文寫入檔案,而不是顯示在終端機中。
3. cURL 和 Thunderbit 在網頁爬蟲上的差別是什麼?
cURL 是一個用來抓取原始網路資料的命令列工具,很適合技術使用者和自動化流程。Thunderbit 是一個 AI 驅動的 Chrome 擴充功能,專為想從任何網站擷取結構化資料、處理動態頁面,並直接匯出到 Excel 或 Google Sheets 等工具的商務使用者設計,而且不需要寫程式。
4. 用 cURL 抓取網站是否合法?
根據近期法院判決,抓取公開資料在美國通常是合法的,但仍應先查看網站的服務條款、robots.txt 與相關法律。未經許可,不要抓取個人或受保護資料,並遵守速率限制與道德規範 (calawyers.org, polsinelli.com)。
5. 什麼時候我應該從 cURL 轉換到像 Thunderbit 這類更進階的工具?
如果你需要爬取動態/大量 JavaScript 的頁面、想把結構化資料放進試算表,或偏好無程式碼流程,Thunderbit 會是更好的選擇。cURL 適合快速、技術性任務;Thunderbit 則更適合商務場景與可重複執行的資料擷取。
想看更多網頁爬蟲技巧與教學,歡迎造訪 Thunderbit Blog 或查看我們的 YouTube 頻道。
試用 Thunderbit AI 網頁爬蟲 Get Started Free




