「你可以有資料而沒有資訊,但不可能有沒有資料的資訊。」 — *
最近的估計顯示,網路上有超過 個網站,而且每天大約會新增 200 萬篇內容。這片資料汪洋裡其實藏著不少能幫助決策的寶貴洞見,但有個關鍵問題:其中約有 是非結構化資料,得再加工才有用。這就是網頁爬蟲工具派上用場的地方,對任何想善用線上資料的人來說都少不了它。
如果你剛接觸網頁爬取,像 和 這些詞可能會讓你有點卻步。不過到了 AI 時代,這些門檻其實沒那麼高了。現在的 AI 驅動爬蟲工具,能讓你在不需要深厚技術背景的情況下快速上手。這些工具可以幫你快速蒐集、處理資料,不需要寫程式也能用。
最佳網頁爬蟲工具與軟體
- ——適合想要好上手、而且結果出色的人工智慧網頁爬蟲
- ——適合即時監控與大量資料擷取
- ——適合整合多種應用程式的無程式碼自動化
- ——適合有經驗、想用視覺化方式操作的使用者
- ——適合強大的無程式碼爬取,並避開 IP 封鎖與機器人偵測
- ——適合進階 AI 驅動資料擷取 API 與知識圖譜
試試用 AI 進行網頁爬取
試試看吧!你可以一邊看,一邊點擊、探索並執行工作流程。
網頁爬取是怎麼運作的?
網頁爬取的核心,就是從網站抓資料。你給工具一組指令,它就會把你需要的文字、圖片或其他內容,從網頁中提取成表格。這種方式很實用,無論是追蹤電商網站價格、蒐集研究資料,甚至只是整理出一份好用的 Excel 試算表或 Google Sheets,都派得上用場。
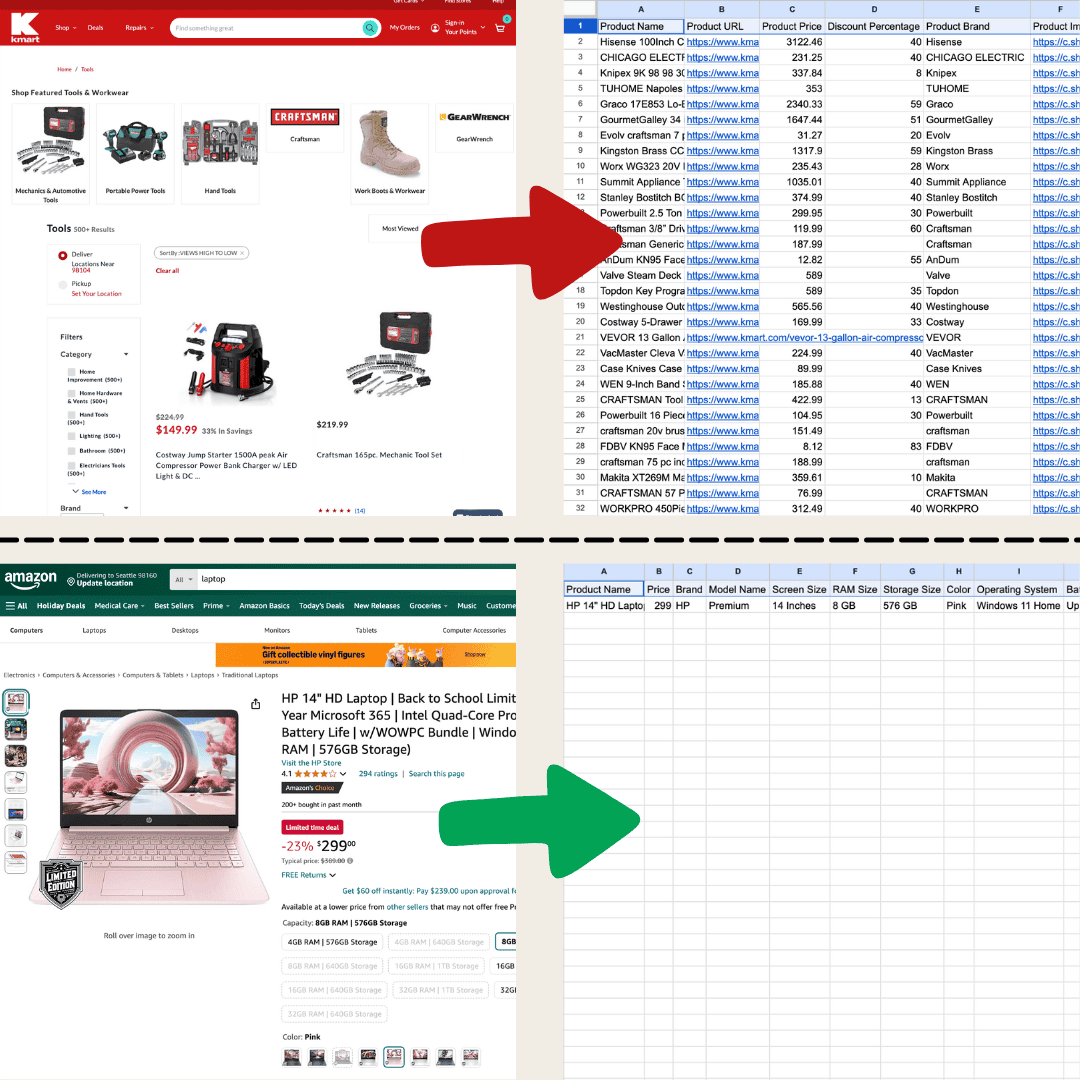 我用 Thunderbit 的人工智慧網頁爬蟲做出了這張圖。
我用 Thunderbit 的人工智慧網頁爬蟲做出了這張圖。
做法其實有好幾種。最簡單的方式,當然是自己手動複製貼上,但如果資料量很大,這會非常耗工。所以大多數人會採用三種方法之一:傳統網頁爬蟲、AI 網頁爬蟲,或自訂程式碼。
傳統網頁爬蟲 是根據頁面結構,先設定要抓哪些特定資料規則。舉例來說,你可以設定它從某些 HTML 標籤中擷取商品名稱或價格。這類工具最適合不太常變動的網站,因為只要版型一改,你就得回去調整爬蟲設定。
 使用傳統爬蟲需要花很長時間學習,設定過程很可能要點上好幾十下。
使用傳統爬蟲需要花很長時間學習,設定過程很可能要點上好幾十下。
AI 網頁爬蟲 基本上就是:ChatGPT 先讀完整個網站,再依照你的需求擷取內容。它可以同時處理資料擷取、翻譯與摘要。這類工具利用自然語言處理來分析並理解網站版面,因此面對網站改版時通常更有彈性。比方說,網站只是稍微調整了區塊順序,AI 網頁爬蟲可能就能自行適應,不需要你重寫任何設定。所以,它們特別適合結構比較複雜、或經常變動的網站。
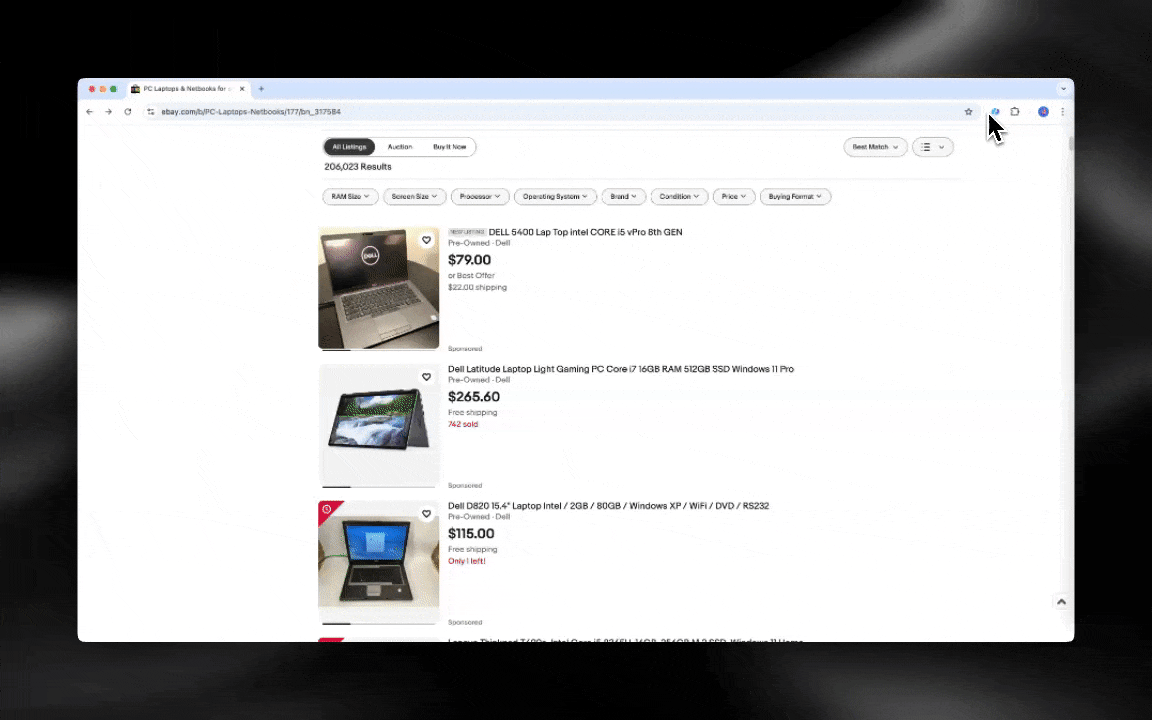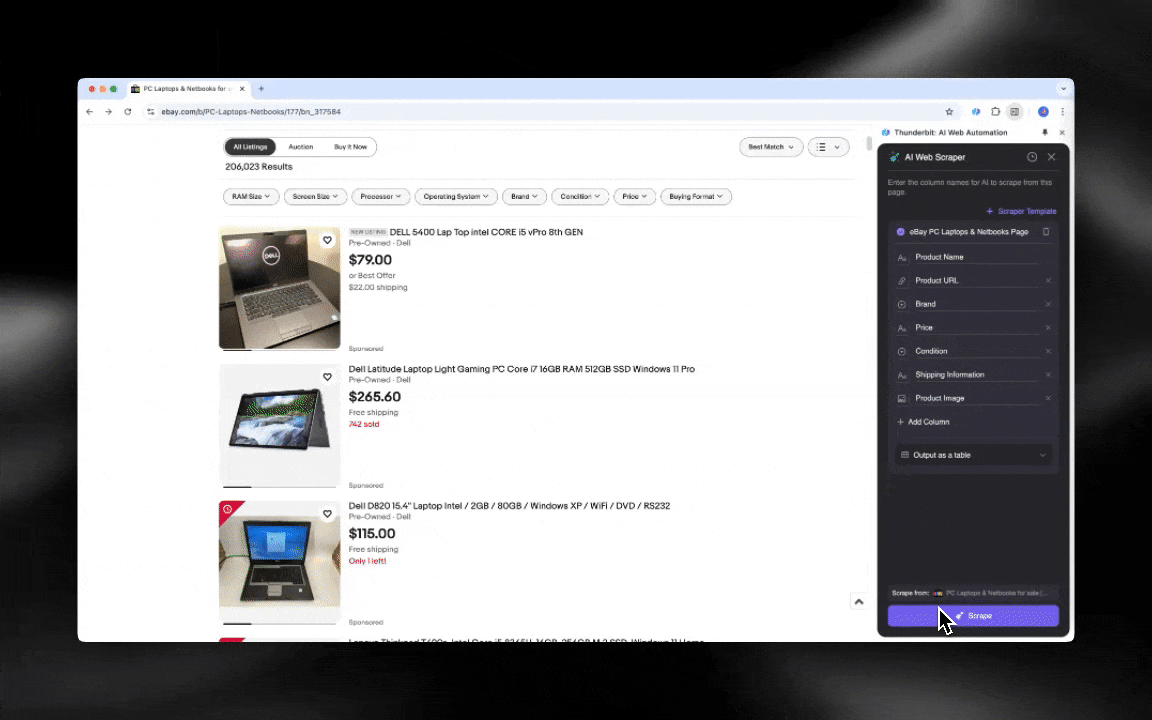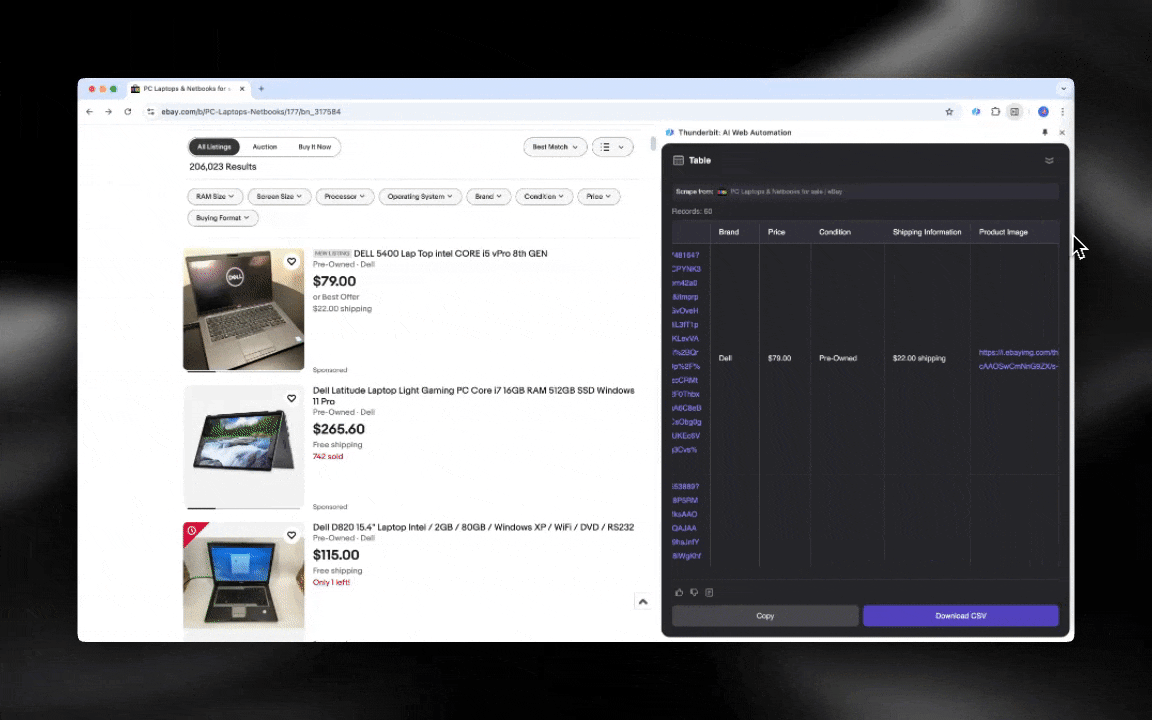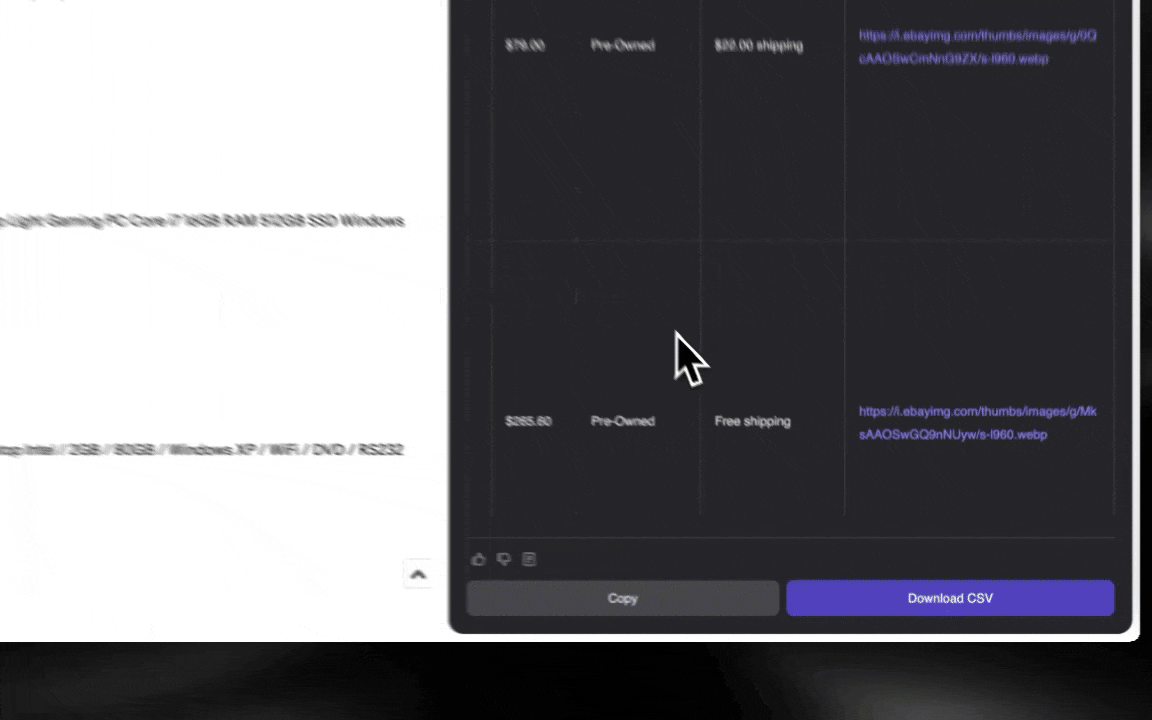 AI 網頁爬蟲非常容易上手,只要幾下點擊就能拿到詳細資料!
AI 網頁爬蟲非常容易上手,只要幾下點擊就能拿到詳細資料!
那你該選哪一種? 這要看情況。如果你熟悉程式調整,或需要在熱門網站上大量蒐集資料,傳統爬蟲會非常有效率。但如果你剛接觸網頁爬取,或希望工具能跟著網站更新一起調整,那通常 AI 網頁爬蟲會是更好的選擇。下面的表格會提供更詳細的情境!
| 情境 | 最佳選擇 |
|---|---|
| 在目錄、購物網站,或任何列表型網站上進行輕量級爬取 | AI Web Scraper |
| 頁面資料少於 200 列,用傳統網頁爬蟲建立爬蟲太耗時 | AI Web Scraper |
| 你要擷取的資料需要特定格式才能上傳到別處,例如抓取聯絡資訊上傳到 HubSpot | AI Web Scraper |
| 大規模使用的網站,例如數萬個 Amazon 商品頁或 Zillow 房源列表 | 傳統網頁爬蟲 |
一眼看懂最佳網頁爬蟲工具與軟體
| 工具 | 價格 | 主要功能 | 優點 | 缺點 |
|---|---|---|---|---|
| Thunderbit | 每月 9 美元起,提供免費方案 | 人工智慧網頁爬蟲、自動偵測並格式化資料、支援多種格式、一鍵匯出、介面友善。 | 無需寫程式、AI 支援、可整合 Google Sheets 等應用程式 | 大規模爬取可能較慢,進階功能費用較高 |
| Browse AI | 每月 48.75 美元起,提供免費方案 | 無程式碼介面、即時監控、大量資料擷取、工作流程整合。 | 介面友善,可與 Google Sheets 和 Zapier 整合 | 複雜頁面需要額外設定,大量爬取可能逾時 |
| Bardeen AI | 每月 60 美元起,提供免費方案 | 無程式碼自動化、可整合 130 多個應用程式、MagicBox 可將任務轉為工作流程。 | 整合範圍廣,適合企業擴充使用 | 新手學習曲線較陡,設定較耗時 |
| Web Scraper | 本機免費使用,雲端版每月 50 美元 | 視覺化建立任務,支援動態網站(AJAX/JavaScript),雲端爬取。 | 對動態網站效果不錯 | 需要一定技術知識才能最佳設定 |
| Octoparse | 每月 119 美元起,提供免費方案 | 無程式碼爬取、自動偵測頁面元素、支援排程任務的雲端爬取、常見網站範本庫。 | 功能強大,適合動態網站,且能處理限制 | 複雜網站需要學習成本 |
| Diffbot | 每月 299 美元起 | 資料擷取 API、無規則 API、非結構化文字的 NLP、完整知識圖譜。 | AI 擷取能力強,API 整合豐富,適合大規模爬取 | 非技術使用者有學習曲線,設定需要時間 |
AI 時代最佳網頁爬蟲
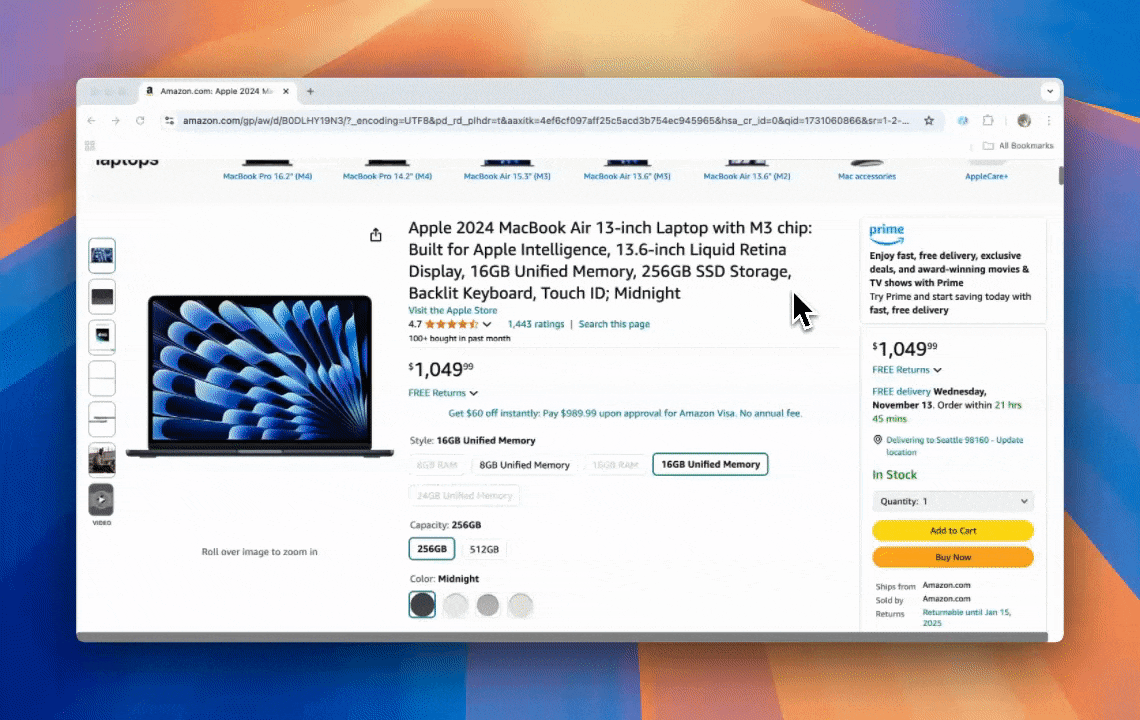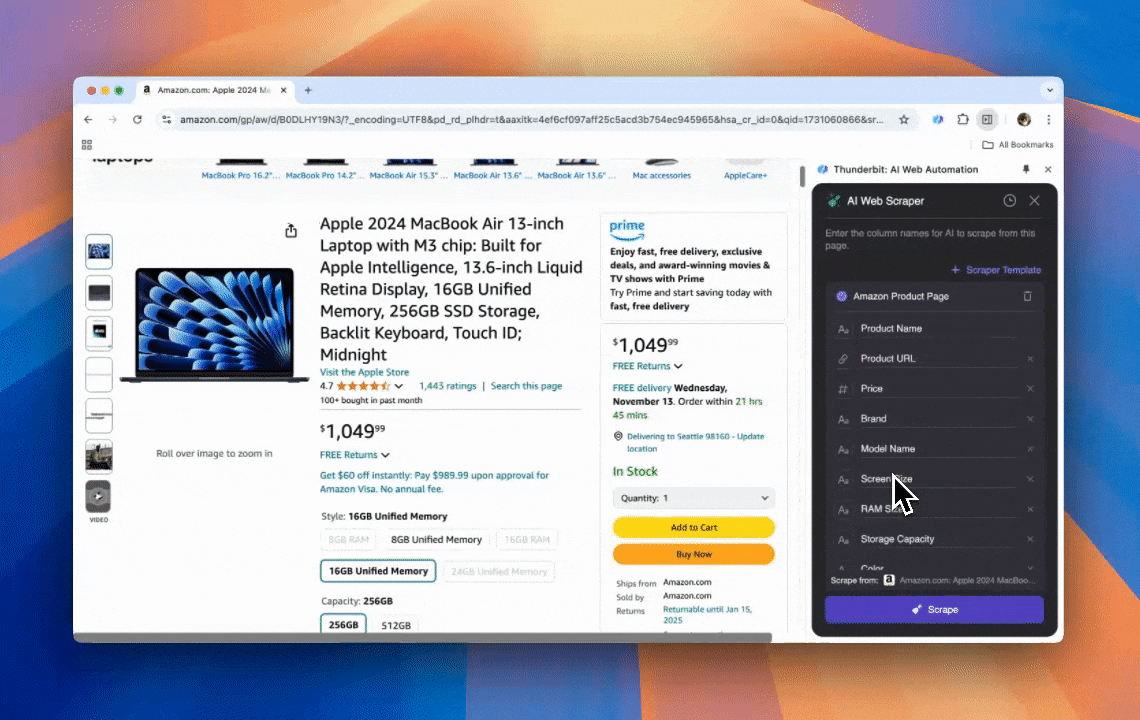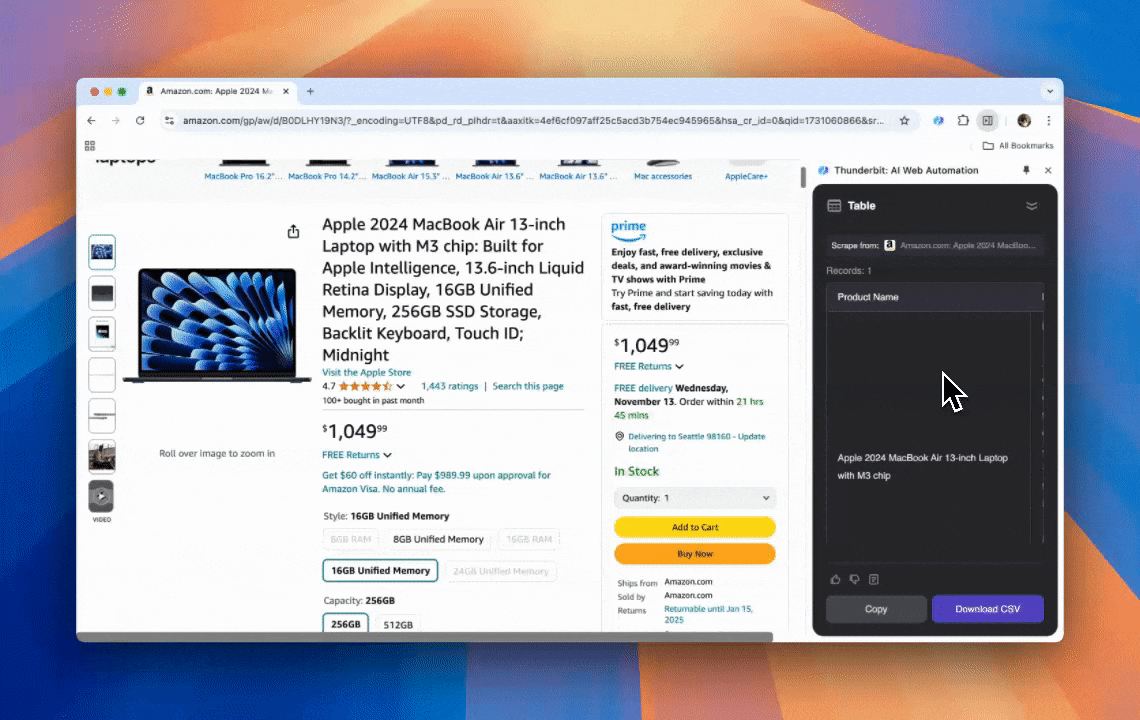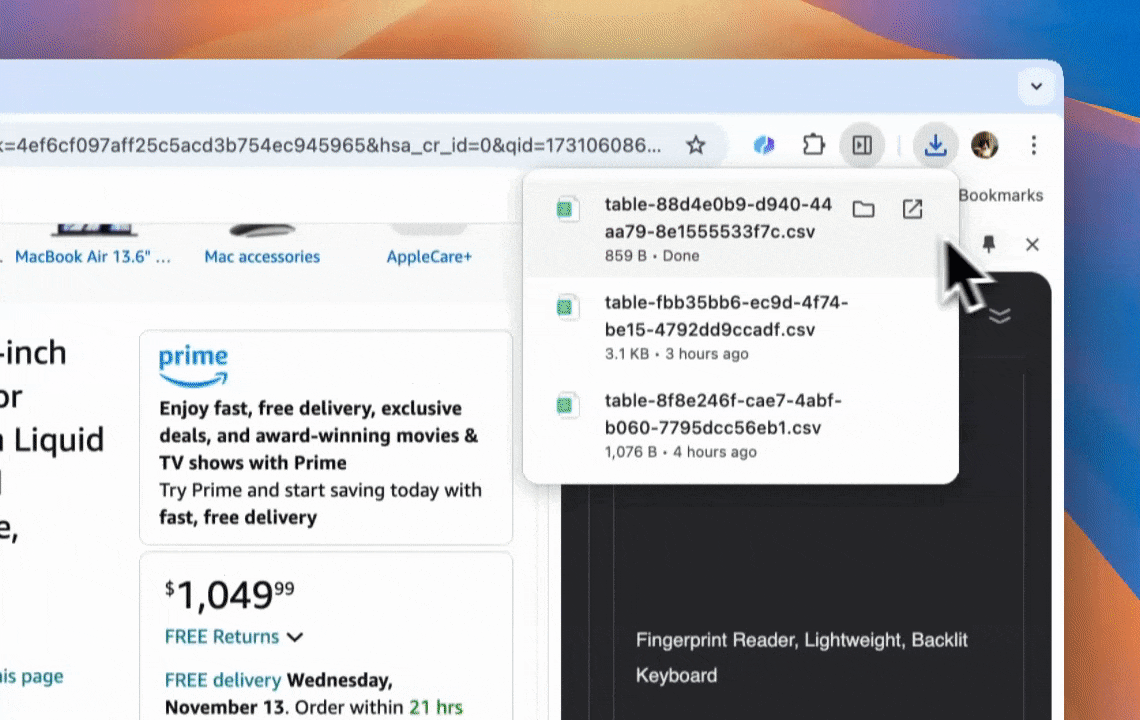
Thunderbit 是一款功能強大、好上手的 AI 網頁自動化工具,讓沒有程式背景的使用者也能輕鬆擷取與整理資料。搭配它的 ,Thunderbit 的 讓資料爬取變得更簡單——使用者可以快速提取網頁資料,不必手動操作網頁元素,也不需要針對不同版型逐一建立爬蟲。
主要功能
- AI 驅動的彈性:Thunderbit 的 AI Web Scraper 會自動偵測並格式化網頁資料,不需要再設定 CSS 選擇器。
- 最簡單的爬取體驗:你只需要在要擷取的頁面上點一下「AI 建議欄位」,再點一下「爬取」就完成了。
- 支援多種資料格式:Thunderbit 可以爬取 URL、圖片,並以多種格式顯示擷取資料。
- 自動化資料處理:Thunderbit 的 AI 能即時重新格式化資料,包括摘要、分類,以及翻譯成所需格式。
- 輕鬆匯出資料:只要一鍵即可將資料匯出到 Google Sheets、Airtable 或 Notion,讓資料管理更簡單。
- 介面友善:直覺式介面讓各種程度的使用者都能輕鬆上手。
價格
Thunderbit 提供分級方案,從每月 9 美元起,包含 5,000 點數。最高可到每月 199 美元,包含 240,000 點數。年繳方案則會一次提供全部點數。
優點:
- 強大的 AI 支援,簡化資料擷取與處理。
- 無需寫程式,任何程度的使用者都能使用。
- 很適合名錄、購物網站等輕量級爬取。
- 整合能力強,可直接匯出到主流應用程式。
缺點:
- 大規模資料爬取為了確保準確性,可能需要一些時間。
- 某些進階功能可能需要付費訂閱。
想了解更多? 先從開始,或看看如何用 Thunderbit。
最適合資料監控與大量擷取的網頁爬蟲
Browse AI
Browse AI 是一款穩健的無程式碼資料爬取工具,設計目的是協助使用者在不寫程式的情況下擷取與監控資料。Browse AI 雖然有一些 AI 功能,但還不到完整 AI 爬取的程度。不過,它確實讓新手更容易開始使用。
主要功能
- 無程式碼介面:只要簡單點擊,就能建立自訂工作流程。
- 即時監控:透過機器人追蹤網頁變化,並提供更新資訊。
- 大量資料擷取:一次最多可處理 50,000 筆資料。
- 工作流程整合:可串接多個機器人,進行更複雜的資料處理。
價格
每月 48.75 美元起,包含 2,000 點數。另有免費方案,每月提供 50 點數,供你試用基本功能。
優點:
- 可與 Google Sheets 和 Zapier 整合。
- 內建機器人簡化常見資料擷取工作。
缺點:
- 複雜頁面可能需要額外設定。
- 大量爬取速度可能不穩定,有時會逾時。
最適合工作流程整合的網頁爬蟲
Bardeen AI
Bardeen AI 是一款無程式碼自動化工具,透過串接各種應用程式來簡化工作流程。雖然它會用 AI 來建立自訂自動化,但靈活性仍不如完整的 AI 爬取工具。
主要功能
- 無程式碼自動化:讓使用者只要點擊幾下就能建立工作流程。
- MagicBox:用簡單語言描述任務,Bardeen AI 會把它轉成工作流程。
- 廣泛整合選項:可整合超過 130 個應用程式,包括 Google Sheets、Slack 和 LinkedIn。
價格
每月 60 美元起,包含 1,500 點數(約 1,500 列資料)。免費方案每月提供 100 點數,可試用基本功能。
優點:
- 豐富的整合選項可支援多種商業需求。
- 彈性高,且適合各種規模的企業擴充使用。
缺點:
- 新使用者可能需要時間學習整個平台。
- 初始設定可能較耗時。
最適合有經驗使用者的視覺化網頁爬蟲
Web Scraper
沒錯,你沒聽錯:這個工具就叫「Web Scraper」。Web Scraper 是 Chrome 和 Firefox 上很受歡迎的瀏覽器擴充功能,讓使用者可以不用寫程式就擷取資料,並以視覺化方式建立爬取任務。不過,你可能得花幾天看完上面的教學、邊學邊練,才能真正掌握這個工具。如果你想讓爬取這件事對腦袋更輕鬆,選 AI Web Scraper 會更好。
主要功能
- 視覺化建立:讓使用者透過點擊網頁元素來建立爬取任務。
- 支援動態網站:可處理 AJAX 請求與 JavaScript,適合動態網站。
- 雲端爬取:可透過 Web Scraper Cloud 排程任務,進行定期爬取。
價格
本機版可免費使用;付費方案的雲端功能從每月 50 美元起。
優點:
- 對動態網站效果不錯。
- 本機版免費。
缺點:
- 要達到最佳設定需要一定技術知識。
- 版面變動時需要做較複雜的測試。
最適合避開 IP 封鎖與機器人偵測的網頁爬蟲
Octoparse
Octoparse 是一款多功能軟體,適合比較技術型的使用者在不寫程式的情況下蒐集與監控特定網頁資料,特別適合大量資料需求。Octoparse 不依賴使用者的瀏覽器運作;相反地,它透過雲端伺服器進行資料爬取。因此,它可以提供多種方式來繞過 IP 封鎖與某些網站的機器人偵測。
主要功能
- 無程式碼操作:使用者不需寫程式就能建立爬取任務,對不同技術程度的人都很友善。
- 智慧自動偵測:會自動偵測頁面資料,快速辨識可擷取的元素,簡化設定流程。
- 雲端爬取:支援 24/7 雲端資料爬取與排程任務,方便彈性擷取資料。
- 豐富的範本庫:提供數百個預設範本,讓使用者不用複雜設定,就能快速取得熱門網站資料。
價格
Octoparse 的方案每月 119 美元起,包含 100 個任務。另有每月 10 個任務的免費方案,可用來測試基本功能。
優點:
- 功能強大,支援動態網站爬取,且具備很高的適應性。
- 能提供處理爬取限制與動態內容問題的方案。
缺點:
- 複雜的網站結構可能需要更多時間設定。
- 新使用者可能需要時間學習操作技巧。
最適合進階 AI 資料擷取 API 的網頁爬蟲
Diffbot
Diffbot 是一款進階網頁資料擷取工具,利用 AI 將非結構化網頁內容轉換成結構化資料。透過強大的 API 與知識圖譜,Diffbot 協助使用者從網路擷取、分析並管理資訊,適用於多種產業與應用場景。
主要功能
- 資料擷取 API:Diffbot 提供無規則資料擷取 API,使用者只要提供 URL,就能自動擷取資料,不必為每個網站自訂規則。
- 自然語言處理 API:可從非結構化文字中擷取結構化實體、關係與情緒傾向,協助使用者建立自己的知識圖譜。
- 知識圖譜:Diffbot 擁有全球最大規模之一的知識圖譜,連結大量實體資料,包括個人與組織的詳細資訊。
價格
Diffbot 的方案每月 299 美元起,包含 250,000 點數(約等於 250,000 次以 API 為基礎的網頁擷取)。
優點:
- 無規則資料擷取能力強,適應性高。
- API 整合選項豐富,容易接到既有系統。
- 支援大規模資料爬取,適合企業級應用。
缺點:
- 初始設定對非技術使用者來說可能需要一些學習時間。
- 使用時必須撰寫程式來呼叫 API。
爬蟲可以用來做什麼?
如果你剛接觸網頁爬取,下面幾個常見應用可以幫你快速入門。很多人會用爬蟲來抓取 Amazon 商品列表、從 Zillow 擷取房地產資料,或蒐集 Google Maps 的商家資訊。但這些只是開始——你也可以用 Thunderbit 的 從幾乎任何網站蒐集資料,讓日常工作流程更省時、更有效率。不論是做研究、追蹤價格,還是建立資料庫,網頁爬取都能替你把網路上的資料變成真正可用的資源。
常見問題
-
網頁爬取合法嗎?
網頁爬取通常是合法的,但必須遵守網站服務條款,以及你所存取資料的性質。請務必先查看相關政策,並遵循法律規範。
-
使用網頁爬蟲工具需要程式能力嗎?
這裡介紹的大多數工具都不需要程式能力,不過像 Octoparse 和 Web Scraper 這類工具,若使用者具備基本的網頁結構知識與一些程式思維,通常能發揮得更好。
-
有免費的網頁爬蟲工具嗎?
有,像 BeautifulSoup、Scrapy 和 Web Scraper 都有免費工具可用,而且有些工具也提供功能有限的免費方案。
-
網頁爬取常見的挑戰有哪些?
常見挑戰包括處理動態內容、CAPTCHA、IP 封鎖與複雜的 HTML 結構。進階工具與技巧可以有效解決這些問題。
延伸閱讀:
-
用 AI 工作,輕鬆無負擔。