

2024 年 5 月 1 日,荷蘭資料保護主管機關(AP)發了一份新聞稿,標題直白到讓整個歐洲的資料團隊倒抽一口氣:「爬取幾乎總是違法。」
做業務開發、電商營運、房仲分析的人,只要工作流程裡有一段是靠網頁資料撐起來的,看到這種句子都會開始盤算:我手上那幾支爬蟲,到底算不算踩線?
Thunderbit 每天都在跟這類團隊打交道——監控競品價格的、開發名單的、做市場調查的。他們的困擾其實很一致:把「is web scraping legal in Europe」丟進搜尋列,翻回來的答案十篇有九篇寫著「視情況而定」。專案期限就在下週,待爬網址已經排了一整欄,這種答案幫不上任何忙。
所以這篇文章換個方式處理:直接把法規原文、各國 DPA 指引、實際開罰紀錄與判例整理成可以執行的東西——一份六道門檻的決策清單、一張把三大監管機關防護措施整合起來的對照表、2022 到 2026 年的真實罰款金額,還有一套從設定到匯出的實作流程。不管你要抓的是 Amazon 商品價格,還是名錄裡的 B2B 聯絡資料,看完至少能知道界線畫在哪裡、自己站在哪一側。
網頁爬蟲在做什麼?為什麼歐洲企業非搞懂不可
網頁爬蟲就是把網站上的資料自動擷取成結構化格式——試算表、資料庫或 CRM 都可以。與其手動複製貼上兩百個頁面的商品名稱與價格,不如讓爬蟲逐頁走過去,把你指定的欄位排成整齊的欄與列。
對沒有工程資源的團隊來說,這件事之所以重要,是因為網頁資料直接餵給商業決策:業務從名錄裡撈名單、電商經理每天盯競品定價、房地產分析師追各平台的刊登趨勢、市場研究人員大規模蒐集公開評論與評分。全球網頁爬蟲市場成長得很快,企業每天處理的資料量是以百萬筆計的。
問題在於,歐洲的監管環境跟美國不是同一套邏輯。GDPR、資料庫指令,加上還在持續演變的各國 DPA 指引,共同得出一個結論:「公開可得」不等於「可以隨便用」。荷蘭 DPA 主席 Aleid Wolfsen 那句話講得很精準——「公開不會自動等於允許爬取。」
先弄懂規則不是加分項,而是乾淨資料集與六位數罰金之間的分水嶺。
在歐洲爬資料合不合法?先給結論
網頁爬蟲在歐洲本身並不違法。真正決定結果的是三件事:你爬什麼資料、你用什麼方式爬、你爬來做什麼。
在歐盟,爬蟲同時被三層法律罩著,而且這三層會互相重疊:
- GDPR——只要擷取到個人資料(姓名、電子郵件、電話號碼、IP 位址,甚至可以重新識別的假名化識別碼),就適用。
- 歐盟資料庫指令——保護那些在資料整理上投入「實質投資」的資料庫。
- 合約/服務條款法——不少網站在 ToS 裡明文禁止爬取,而歐盟法院確實會執行這類條款。
也就是說,就算你抓的完全不是個人資料,還是可能撞上資料庫權利或合約法。每一個爬取專案,這三層都得分別檢查過一遍。
三層法規拆開來看
GDPR:只要碰到個人資料就啟動
任何足以識別出特定個人的資料都會觸發 GDPR 義務——姓名、電子郵件、電話號碼、IP 位址、照片,以及可被重新識別的假名化資料。從你開始擷取個人資料的那一刻起,你在 GDPR 底下就是「資料控制者」,隨之而來的責任有四項:
- 合法依據(第 6 條): 處理資料要有法律理由。大規模爬取幾乎不可能走「同意」這條路——你沒辦法在蒐集數百萬人公開貼出的資訊之前,一個一個去徵求同意。實務上最常引用的是合法利益(第 6(1)(f) 條),但它要求你完成一份有紀錄的三步驟測試:(1)你的利益正當,(2)處理對達成該利益是必要的,(3)在考量資料主體合理期待之後,不會對其權利造成不成比例的影響。
- 透明度(第 14 條): 資料不是直接向當事人蒐集的,所以你有義務通知他們——通常是一個月內——說明你蒐集了什麼、為什麼蒐集、他們可以怎麼行使權利。如果逐一通知不具比例性,就得公開一份涵蓋第 14 條全部要素的一般性通知。
- 資料最小化: 只拿實際會用到的欄位。目標是商品價格,就別順手把賣家的電子郵件也帶回來。
- 儲存限制與權利管理: 設定保留期限、處理刪除請求,並提供查詢資料來源的管道。
EDPB ChatGPT 工作小組報告(2024 年 5 月通過)又補上一層要求:蒐集、前處理、訓練、提示與輸出,每一個處理階段都要各自做合法依據分析。EDPB 沒有否定爬取可以主張合法利益,但它堅持完整的三步驟評估與對應防護措施缺一不可。
歐盟資料庫指令:保護的是「組織方式」
資料庫指令給了資料庫創作者一項 sui generis 權利,前提是他們在取得、驗證或呈現資料上投入了「實質投資」。爬取行為如果擷取了這類資料庫的「實質部分」,就有侵權疑慮。
實務上這道門檻並不低。從大型零售商網站抓幾百筆商品價格,通常構不成問題;但如果你把競爭對手整份目錄——好幾萬筆刊登資料——批量下載回來,尤其這會影響資料庫創作者回收投資的能力,那就另當別論了。歐盟法院已經在多起案件裡處理過這條線,核心判準始終是比例原則。
以商業爬蟲的常見做法而言——從商品頁擷取特定欄位、比較同類別的刊登資料——資料庫指令的風險相對低。但不是零,設計爬取範圍時值得先納入考量。
服務條款:最容易被忽略的那個變數
這一層踩雷率最高。很多網站在服務條款裡直接禁止爬取。在歐洲,違反 ToS 屬於民事範疇(不是刑事),但仍可能引來禁制令、合約訴訟以及實際的財務損失。
要分清楚兩種形式。browsewrap 是被動條款,通常只是頁尾一條不起眼的連結,執行難度較高,因為使用者從來沒有主動同意過。clickwrap 則要求你勾選方框或按下「我同意」,這種在法庭上就好用得多。
歐盟的指標案件是 Ryanair v. PR Aviation:即使資料庫權利不適用,法院仍然對爬蟲方執行了 Ryanair 的 ToS,理由是對方已經同意條款。所以爬之前務必先翻一次網站條款。碰到明文禁止爬取的 clickwrap 協議,就要謹慎處理——或者乾脆改走 API。
DSM 指令與 AI 法:研究與 TDM 的例外
也不是所有爬取都受同一套限制。數位單一市場(DSM)指令(2019)引進了兩項文字與資料探勘(TDM)例外:
- 第 3 條: 研究機構與文化遺產組織可以在合法取得的內容上進行 TDM。
- 第 4 條: 任何人——包含商業實體——都可以進行 TDM,除非權利人已明確選擇退出(例如透過 robots.txt、ai.txt 或 TDMRep 標頭)。
歐盟 AI 法(第 53 條) 再往上疊一層:AI 模型提供者必須遵守 TDM 退出機制,並記錄訓練資料來源。
但這裡有個關鍵但書:上述例外涵蓋的是著作權與資料庫權利,跟 GDPR 無關。TDM 只要碰到個人資料,你仍然得另外找到一個站得住腳的 GDPR 合法依據。

六道門檻:這個網站到底能不能爬
法律文章寫到最後都會落回「視情況而定」,但真正需要的是:情況要怎麼判斷?以下把判斷流程拆成六道門檻,每一道都給明確標準,結果只有三種——✅ 可繼續、⚠️ 需加強防護、🛑 停止。
步驟 1:資料是個人資料還是非個人資料?
非個人資料(商品價格、SKU 編號、未與個人連結的商業地址):監管負擔較低。資料庫指令與 ToS 還是要查,但 GDPR 不適用。✅ 進入步驟 3。
個人資料(姓名、電子郵件、電話號碼、照片,以及任何與個人連結的識別資訊):GDPR 適用。⚠️ 進入步驟 2。
步驟 2:適用哪一項 GDPR 合法依據?
- 同意: 對大規模爬取幾乎不可行。🛑 除非你的情境非常狹窄而具體。
- 合法利益(第 6(1)(f) 條): 最常見的依據,代價是一份有紀錄的三步驟測試:
- 你的利益正當(依 CJEU 2024 年在 C-621/22 的裁決,商業利益也可能成立)。
- 為達成這項利益,處理是必要的。
- 權衡測試:把資料主體的合理期待放進來衡量後,你的利益仍不會凌駕其權利。
- 權衡測試要在爬取之前就寫下來。 如果你講不清楚那些資料主體憑什麼會預期資料被這樣使用,那就是紅旗。⚠️ 完成有紀錄的合法利益評估後再繼續。
步驟 3:網站的 ToS 有沒有限制爬取?
- 禁止爬取的 clickwrap 協議: 🛑 高風險。請改找其他資料來源或官方 API。
- browsewrap 或沒有 ToS 限制: ⚠️ 風險較低,但仍要尊重 robots.txt 與各種技術性反對訊號。
步驟 4:資料庫指令適不適用?
- 目標是不是一個在資料組織上投入實質投資的資料庫?
- 你的爬取會不會擷取該資料庫的「實質部分」?
- 兩題都是:⚠️ 有 sui generis 侵權疑慮,請限縮擷取範圍。
步驟 5:有沒有研究或 TDM 例外可以主張?
- 註冊研究機構或文化遺產組織?DSM 指令第 3 條可能適用。✅
- 商業性 TDM?檢查第 4 條的退出訊號(robots.txt、ai.txt、TDMRep)。網站已選擇退出的話,🛑 這個來源就此打住。
步驟 6:DPA 建議的防護措施都上了嗎?
前五道都過關的話,最後一步是把 CNIL、荷蘭 DPA 與 EDPB 建議的防護措施實際落地。細節在下一節。✅ 防護措施配置完成後繼續。
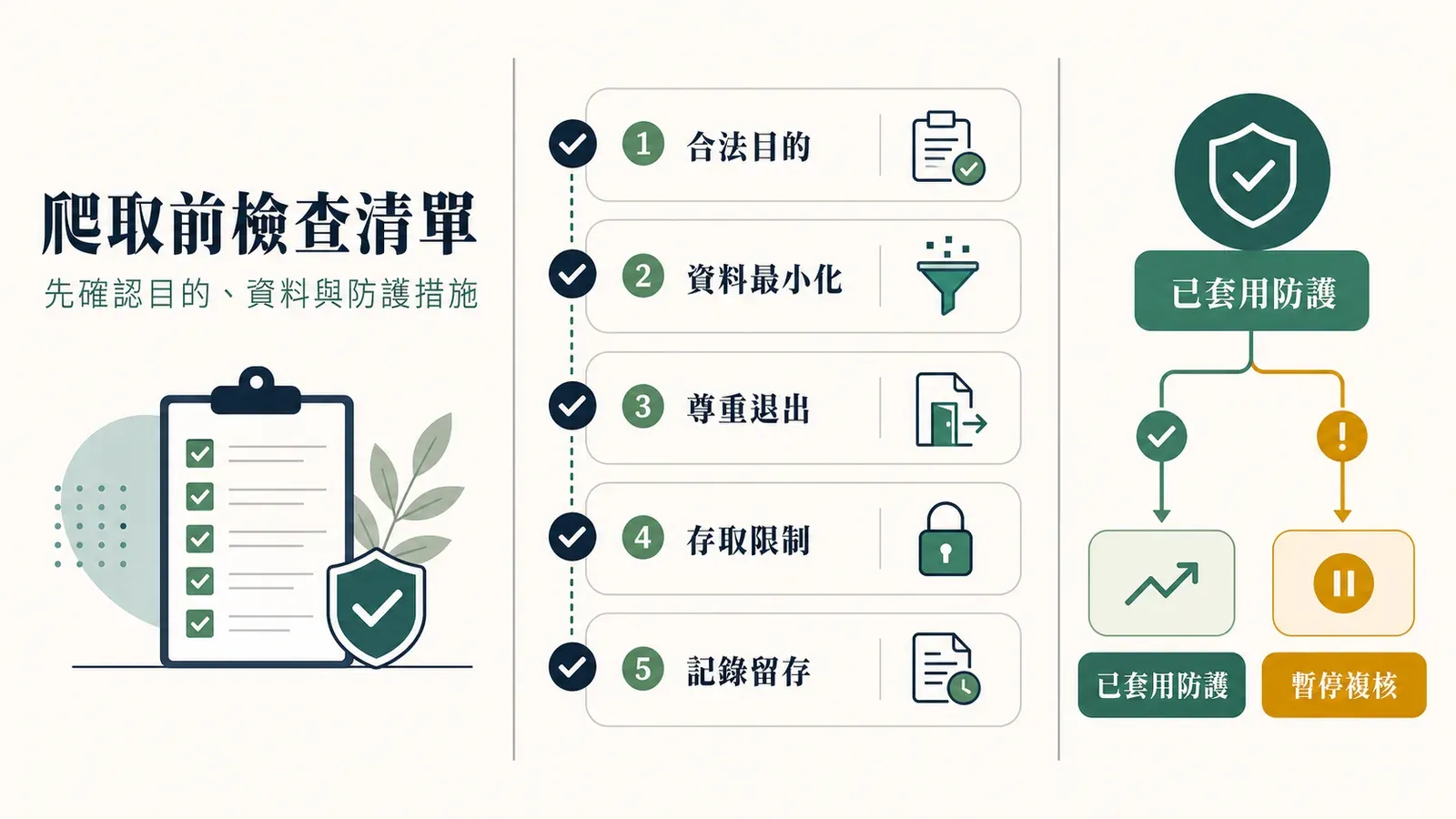
三大監管機關的防護措施,一次對照
歐洲對爬蟲議題出手最積極的三個機關——CNIL、荷蘭 AP、EDPB——各自都出過指引,但幾乎沒有人把它們整合在同一張表裡。以下這張表依據CNIL 網頁爬取重點說明、荷蘭 AP 指引與EDPB ChatGPT 工作小組報告整理而成。
| 防護措施 | CNIL | 荷蘭 DPA(AP) | EDPB 工作小組 | 實作建議 |
|---|---|---|---|---|
| 第 14 條透明度通知 | ✅ 必要 | ✅ 必要 | ✅ 必要 | 公開通知,列出來源類別、用途、合法依據、保留期限、權利聯絡管道與 DPO 聯絡方式 |
| 爬取前 DPIA | ✅ 建議(高風險時為強制) | ✅ 必要 | ✅ 必要 | 上線前先記錄權衡測試、資料類別、風險與緩解措施 |
| 資料最小化 | ✅ 必要(定義精確蒐集標準) | ✅ 必要 | ✅ 必要 | 設定爬蟲只擷取需要的欄位;立即刪除無關資料 |
| 速率限制/尊重 robots.txt | ✅ 必要(排除透過 robots.txt/CAPTCHA 表示反對的網站) | — | — | 解析 robots.txt、設定請求間隔、標示使用者代理字串 |
| 假名化/匿名化 | ⚠️ 建議(蒐集後立即執行) | ✅ 強烈建議 | ✅ 建議 | 對 ID 做雜湊或隨機化;移除個人檔案網址;若不需要識別身分,模糊處理臉部 |
| 保留期限 | ✅ 需明確限制 | ✅ 越短越好 | ✅ 需明確限制 | 自動化刪除排程;將原始快取與擷取出的事實分開 |
| 退出/黑名單機制 | ✅ 建議(可酌情預先反對) | ✅ 必要(第 21 條反對權) | ✅ 必要 | 提供退出表單、網域黑名單、個人層級排除機制 |
| 排除敏感來源 | ✅ 必要(健康論壇、未成年人網站、色情網站、族譜網站) | ✅ 必要 | ✅ 必要 | 為健康、宗教、政治、生物辨識、未成年人等來源維持預設封鎖清單 |
工具層面能幫上忙的,主要是把「資料最小化」變成預設行為。Thunderbit 的「AI 建議欄位」讓使用者精確指定要擷取哪些欄位——價格、SKU、商品名稱——爬蟲就只會收這些。這跟把整個頁面大量下載回來是兩回事:你選的是符合目的限制與資料最小化原則的結構化欄位。當然,沒有任何工具能把不合規的爬取變成合法,法律分析永遠排在前面。
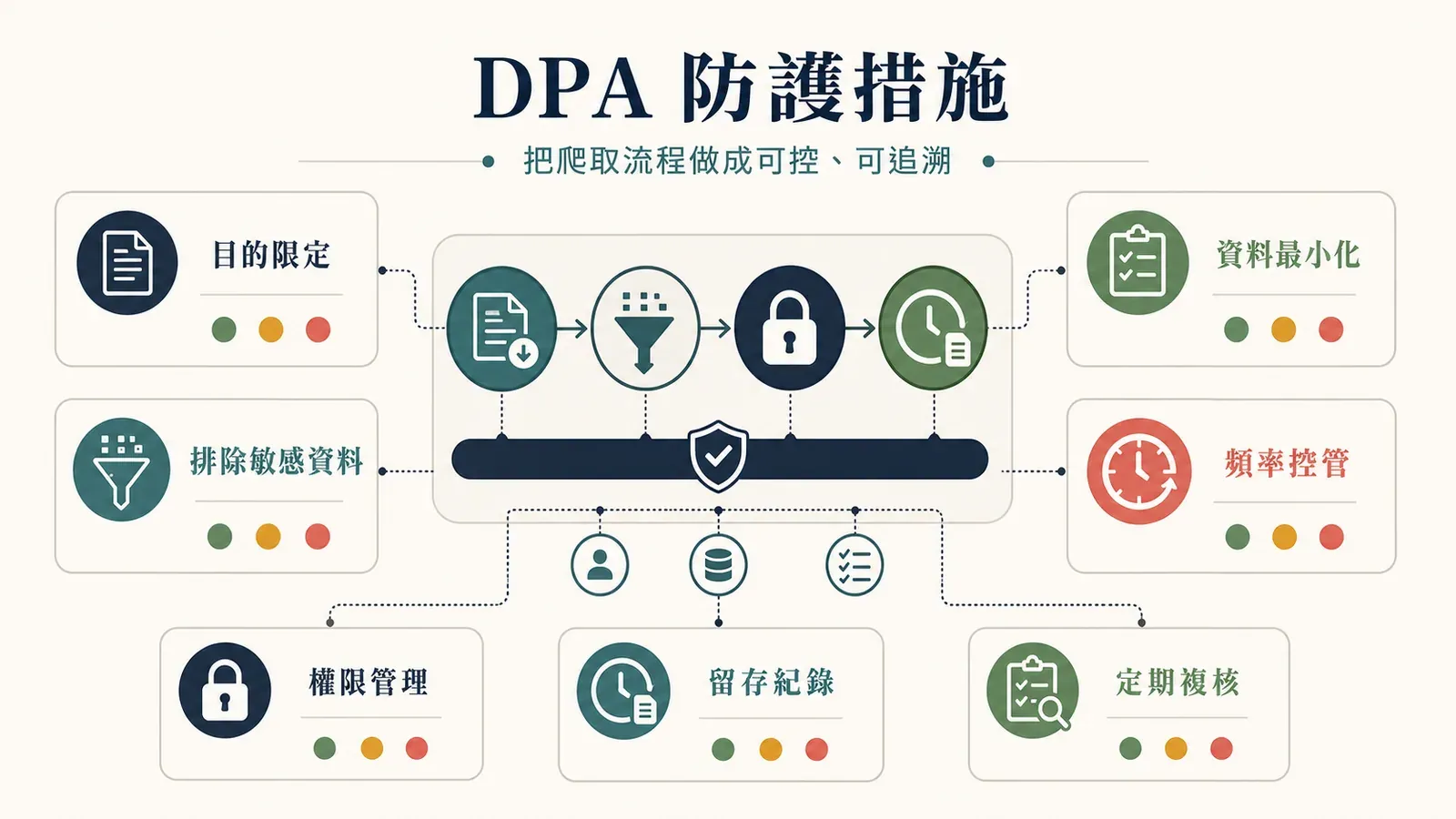
依產業看:你的使用情境風險落在哪一格
論壇上被問最多的其實不是「爬取合不合法」,而是「我這種爬取合不合法」。抽象的 GDPR 理論回答不了這題,所以直接按常見商業用途拆開。
| 使用情境 | 資料類型 | 主要法律風險 | 可能結果 |
|---|---|---|---|
| 電商價格監控(公開商品刊登) | 非個人資料(價格、SKU、商品名稱) | 資料庫指令 sui generis;違反 ToS | 若沒有個人資料,且沒有系統性擷取資料庫的「實質部分」,整體風險通常較低 |
| B2B 名單開發(從名錄取得聯絡資訊) | 個人資料(姓名、電子郵件、電話號碼) | GDPR 第 6 條合法依據;第 14 條通知;電子通訊的 ePrivacy | 風險較高——需要有紀錄的合法利益權衡測試,加上通知義務 |
| 房地產刊登(入口網站中的房產資料) | 混合型(地址可能是非個人資料;屋主姓名是個人資料) | 資料庫指令;ToS;若與屋主連結則受 GDPR 約束 | 中等風險——將屋主資料匿名化、檢查 ToS、尊重 robots.txt |
| AI 訓練資料(大規模網頁內容爬取) | 若未過濾,可能包含個人資料 | GDPR + 歐盟 AI 法第 53 條 TDM 義務 | 風險很高——必須同時符合 GDPR 與 AI 法;需要退出機制與強健過濾 |
落在低風險那一格的情境(例如公開電商資料),用帶結構化模板的工具反而能壓低風險,因為它只會抓指定的非個人欄位,不會夾帶多餘內容——Thunderbit 的 Amazon 與 Shopify 即時範本就是這個定位。至於牽涉個人資料的高風險情境,例如名單開發,順序不能反過來:法律分析先做,工具後選。再聰明的爬蟲也沒辦法把不合規的蒐集變成合規。
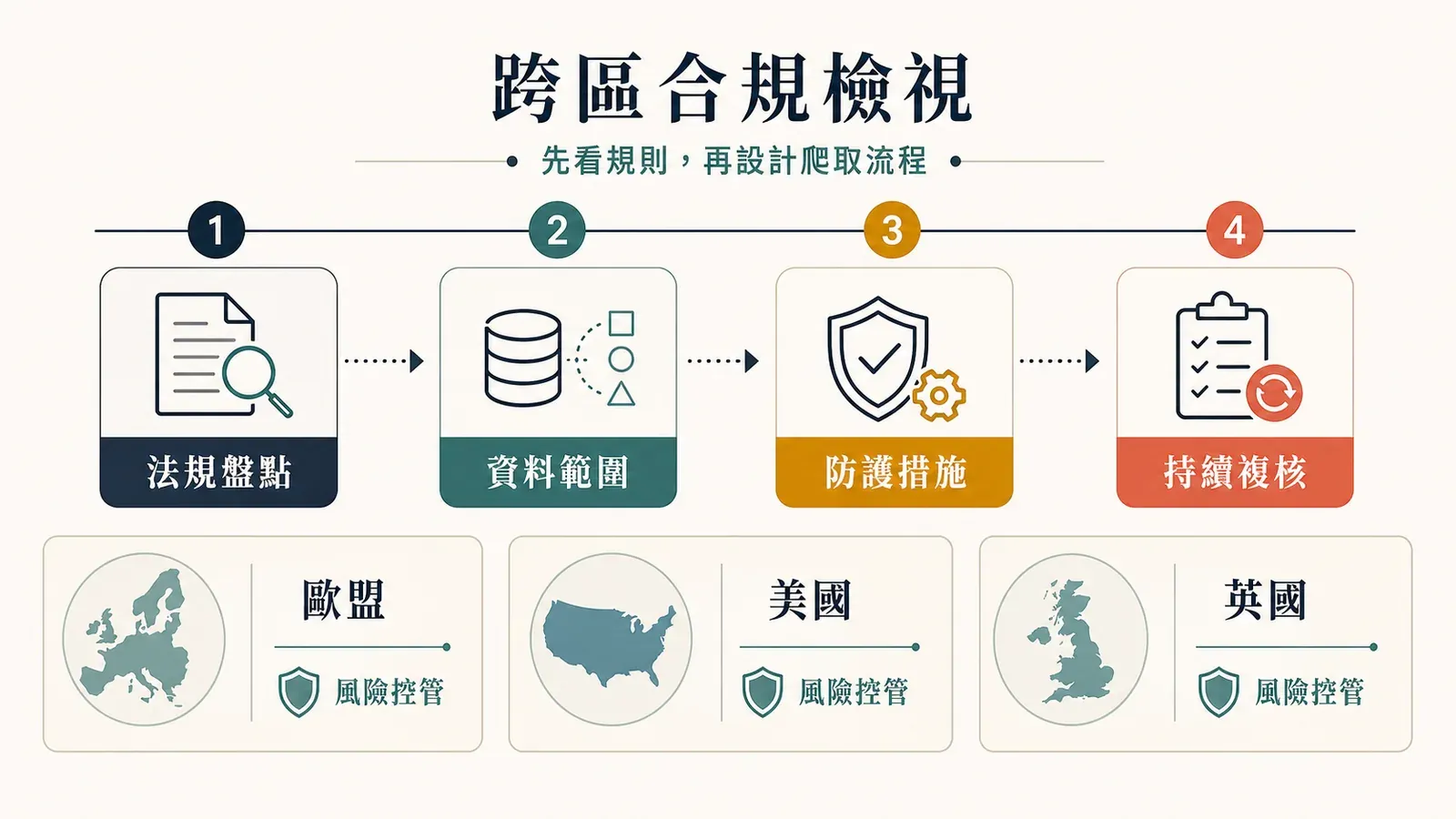
歐盟、美國、英國:同一件事,三套規則
業務只要跨境,就得知道這三邊的差異在哪。以下直接並列。
| 面向 | 歐盟 | 美國 | 英國(脫歐後) |
|---|---|---|---|
| 主要法規 | GDPR + 資料庫指令 + ePrivacy | CFAA + 州法(聯邦資料隱私較有限) | UK GDPR + 2018 年資料保護法 |
| 公開資料爬取 | 若涉及個人資料,仍需 GDPR 合法依據 | 一般在 hiQ v. LinkedIn 後屬合法(公開資料) | 與歐盟相近;適用 ICO 指引 |
| ToS 執行 | 民事問題;Ryanair v. PR Aviation 曾執行 sui generis 權利 | Van Buren 限縮了 CFAA;違反 ToS 不等於刑事 | 民事問題,與歐盟類似 |
| 資料庫保護 | sui generis 權利(強) | 沒有對應的聯邦權利 | 保留 sui generis 權利 |
| AI/TDM 例外 | DSM 指令第 3–4 條;AI 法第 53 條 | 沒有聯邦 TDM 例外(適用合理使用原則) | 英國正在研究 TDM 例外(截至 2026 年仍停滯) |
| 主要執法機關 | 各國 DPA(CNIL、荷蘭 AP 等) | FTC + 州檢察長 | ICO |
| 近期趨勢 | 越來越嚴格(荷蘭 AP:個人資料「幾乎總是違法」) | hiQ 之後較寬鬆 | 中度;大致跟隨歐盟方向 |
要記住的重點只有一句:只要你爬的是歐洲網站,或是關於歐洲居民的資料,就算公司登記在美國或英國,適用的還是歐盟規則。
真的被抓到會怎樣?2022–2026 執法紀錄
問題背後的問題其實是「風險有多大」。以下整理 2022 年到 2026 年 4 月之間,所有公開的、涉及網頁爬取或爬取個人資料的 DPA 執法案件。
| 年份 | 執法機關 | 對象 | 違規內容 | 罰款/結果 |
|---|---|---|---|---|
| 2022 | 義大利 Garante | Clearview AI | 未具合法依據爬取人臉影像 | 2,000 萬歐元罰款 + 禁令 + 刪除命令 |
| 2022 | 希臘資料保護機關 | Clearview AI | 同上——人臉辨識爬取 | 2,000 萬歐元罰款 + 禁令 + 刪除 |
| 2022 | CNIL(法國) | Clearview AI | 人臉辨識資料庫 | 2,000 萬歐元罰款 + 每日 10 萬歐元可能罰則 |
| 2023 | CNIL(法國) | Clearview AI | 未遵守 2022 年命令 | 520 萬歐元罰鍰 |
| 2023 | 奧地利 DSB | Clearview AI | 從公開網路取得 300 億以上人臉影像 | 刪除 + EU 代表人命令(未公布罰款) |
| 2024 | 荷蘭 AP | Clearview AI | 非法蒐集人臉辨識資料 | 3,050 萬歐元罰款 + 合規命令 |
| 2024 | CNIL(法國) | KASPR | 為名單開發而爬取 LinkedIn 聯絡資料 | 24 萬歐元罰款——1.6 億筆聯絡人、受限可見資料、保留 5 年 |
| 2024 | 愛爾蘭 DPC | X / Grok | 將公開貼文用於 AI 訓練 | 暫停協議;2025 年啟動法定調查 |
| 2024 | 愛爾蘭 DPC | Meta | 規劃將公開 Facebook/Instagram 內容用於 LLM 訓練 | Meta 暫停歐盟 AI 訓練計畫 |
| 2024 | 義大利 Garante | OpenAI | ChatGPT 訓練資料與透明度 | 開出 1,500 萬歐元罰款,並於 2026 年 3 月被[羅馬法院撤銷](https://economictimes.indiatimes.com/tech/technology/italian-court-overturns-openai-fine-in-landmark-ai-privacy-ruling/articleshow/119434771.cms) |
歐盟/歐洲經濟區在爬蟲/公開網路這個類別的罰鍰總額:超過 9,500 萬歐元(不含已被撤銷的 OpenAI 罰款)。
值得注意的是這些案件的共同輪廓:全部都是大規模、毫無差別地蒐集生物辨識或個人資料,而且完全沒有合法依據。Clearview 抓的是數十億張臉部影像;KASPR 抓了 1.6 億筆聯絡資料,其中包含受限可見的 LinkedIn 個人檔案資料,還保存了五年。
反過來看,有比例、有明確目標的公開非個人資料爬取——商品價格、SKU 編號這一類——到目前為止還沒有成為執法對象。這不代表風險是零,但至少可以把數字放回正確的尺度上看。
實作:15 分鐘跑完一次合規爬取
- 難度: 初學者
- 所需時間: 約 15 分鐘(含合規檢查)
- 你需要準備: Chrome 瀏覽器、Thunderbit 擴充功能(免費版即可)、目標網址,以及上方清單的快速檢查
步驟 1:先寫下目的與欄位清單
工具都還沒打開之前,先把兩件事寫下來:你為什麼需要這批資料、你具體需要哪些欄位。這不只是工作習慣的問題,它就是 GDPR 目的限制與資料最小化原則要求的東西。
「我需要 50 個 Amazon 商品頁的商品名稱、價格與庫存狀態,用來更新競品定價試算表」——這叫具體。「我想把 Amazon 上的東西全部爬下來」——這不叫。前者通得過最小化測試,後者過不了。
步驟 2:跑一次六道門檻
照上面的「這個可以爬嗎」清單逐項確認。任何一道出現 🛑,先停下來諮詢法律顧問再說。
把前面那個 Amazon 定價的例子丟進門檻裡跑一次:資料屬於非個人資料(價格、SKU、商品名稱)✅,不涉及 GDPR 個人資料問題✅,Amazon 的 ToS 必須查(它確實限制爬取,所以有官方產品資料 API 可用時應優先考慮)⚠️,50 個商品的量體對資料庫指令來說風險低✅。
步驟 3:挑對爬取方式
| 方法 | 易用性 | 合規支援 | 維護成本 | 準確度 |
|---|---|---|---|---|
| 手動複製貼上 | 低 | 不適用(由你控制複製內容) | 高(耗時) | 容易出錯 |
| 程式碼爬蟲(Python、Scrapy) | 低(需要寫程式) | 內建無 | 高(網站改版就壞) | 維護得當則高 |
| Thunderbit(AI 驅動) | 非常高 | 內建欄位層級最小化 | 低(AI 可適應頁面變化) | 高 |
| 官方 API | 中 | 最高(結構化、經授權的存取) | 低 | 最高 |
沒有開發團隊的商務使用者,走 Thunderbit 這條路最快。而目標網站如果有官方 API(例如 Amazon 的 Product Advertising API),API 永遠是最安全的選擇,代價是資料量與欄位通常會被限制。
步驟 4:把爬蟲設定成合規模式
在 Thunderbit 裡的操作順序:
- 前往目標頁面(例如 Amazon 商品刊登頁)。
- 點擊 Chrome 工具列上的 Thunderbit 圖示,選擇「AI 建議欄位」。AI 會掃描頁面,建議「商品名稱」、「價格」、「評分」、「庫存狀態」之類的欄位。
- 把不需要的欄位刪掉。 如果 AI 建議了「賣家名稱」或「賣家電子郵件」,而你只要定價資料,就直接移除。這就是資料最小化在實務上的樣子。
- 用欄位 AI 提示詞補上指令,例如「排除個人識別資訊」或「只擷取公開價格資料」。
- 公開電商網站選雲端爬取(速度快、不需登入);需要驗證的網站則選瀏覽器爬取。
- 按下「爬取」之前,先確認 robots.txt 沒有擋掉你的使用情境。在瀏覽器直接開
[domain]/robots.txt就能查。
跑完之後畫面上應該是一份表格預覽,欄位就是你設定的那幾個——沒有多出來的個人資料,也沒有用不到的中繼資料。
步驟 5:匯出之後也要負責
爬完可以把資料匯出到 Excel、Google Sheets、Airtable 或 Notion,Thunderbit 這幾種匯出都免費。
接下來還有三件事:
- 設定保留期限。 不要無限期留著爬回來的資料。每週監控價格的話,上個月的原始資料多半已經沒有用途。
- 如果蒐集到個人資料(例如名單開發),要記錄合法依據、公開第 14 條透明度通知,並建立處理退出與刪除請求的流程。
- 刪除排程能自動就自動。 Thunderbit 的排程爬蟲可以固定間隔重複執行,欄位設定維持不變,每一次執行都留在同一組合規參數裡。
幾個能長期省麻煩的習慣
跟重視合規的團隊聊下來,真正有效的做法其實不多,但每一條都值得變成流程:
- 每次爬新網站前先看 ToS。 花兩分鐘,可能省下好幾個月的法律麻煩。
- 有 API 就用 API。 結構清楚、經過授權,路徑最安全。爬蟲該是備案,不是預設。
- 只要專案涉及大規模個人資料,就做 DPIA。 CNIL 已經指出 AI 訓練資料集屬於高風險,而 DPIA 就是你的責任證明。專案規模小一點,把分析寫下來也不吃虧。
- 保留爬取紀錄。 爬了什麼、什麼時候爬、來源是哪裡、合法依據為何、保留多久。哪天 DPA 找上門,這份紀錄就是你的底氣。
- 盯著監管更新。 DPA 指引變動很快——CNIL 在 2026 年 1 月才發布新的 AI 爬取說明,EDPB 後續也預期會出更多意見。今天的規則,明天可能更緊。
- 敏感來源一律不碰。 CNIL 的強制排除清單涵蓋健康論壇、以未成年人為主的網站、色情網站、族譜網站,以及高度結構化的個資網站。要做爬取專案,就維持一份預設封鎖清單。
- 自動化流量本身已經是監管視角的一部分。 Akamai 報告指出 2024 年機器人流量占整體網路流量的 42%;Thales/Imperva 的發現則是自動化 bot 流量首次超越人類流量,2024 年來到 51%。監管機關愈來愈把 bot 行為、請求速率與規避機制當成風險與不公平的證據。標示 user agent、做速率限制、尊重反對訊號,這些不只是禮貌,在法律上是有分量的。
結論
網頁爬蟲在歐洲並不違法,但它被規範得很清楚,尤其是碰到個人資料的時候。
最後的法律結果取決於三個變數:你爬的是什麼(個人 vs. 非個人)、你怎麼爬(ToS、robots.txt、速率限制、欄位層級最小化)、你為什麼爬(有紀錄的目的與合法依據)。執法紀錄講得很明白:真正把企業推到七位數、八位數罰款的,是對個人資料做大規模、無差別、毫無合法依據的蒐集。在有防護措施的前提下,針對公開非個人資料做有比例、有目標的爬取,屬於完全不同的風險層級。
可以直接照做的框架是這四條:
- 每個爬取專案動工前,先跑一次決策清單。
- 把 DPA 建議的防護措施上齊(透明度、最小化、保留期限限制、退出機制)。
- 選內建合規支援的工具。 Thunderbit 的 AI 欄位選擇、結構化擷取,加上免費匯出到 Google Sheets、Excel、Airtable 與 Notion,能讓你只爬需要的資料——不多,也不少。
- 全部留下紀錄。 權衡測試、來源清單、保留排程、DPIA。監管機關來問的時候,你的檔案就是防線。
最後照慣例提醒:這篇文章僅供資訊參考,不構成法律建議。涉及大規模個人資料的高風險情境,請諮詢合格的隱私律師。法規還在演變,而出錯的代價是真的。
想實際體驗合規、有目標的網頁擷取,可以從 Thunderbit 免費版開始小規模試——定義欄位、只爬需要的資料,幾下點擊就能匯出。逐步教學則放在我們的 YouTube 頻道。
試試 AI 網頁爬蟲,進行合規資料擷取 Get Started Free
常見問題
1. 資料是公開可得的話,在歐洲爬取就合法嗎?
只要資料包含個人資訊,公開可得並不會讓它脫離 GDPR。荷蘭 DPA 的說法是:「公開不會自動等於允許爬取。」非個人的公開資料(商品價格、SKU)風險通常較低,但資料庫指令與網站服務條款仍然要查。
2. 可以從歐洲網站爬電子郵件和電話號碼嗎?
電子郵件與電話號碼在 GDPR 底下屬於個人資料。你需要合法依據——通常是合法利益,並附上有紀錄的權衡測試——同時必須依第 14 條通知當事人。CNIL 在 2024 年就因為 KASPR 爬取 LinkedIn 聯絡資料而未具備足夠透明度與合法依據,開出 24 萬歐元罰款,可見這是執法相當活躍的一塊。
3. 歐洲非法爬取的最高罰金是多少?
荷蘭 DPA 在 2024 年對 Clearview AI 從公開網路非法蒐集人臉辨識資料,處以 3,050 萬歐元罰款。歐盟其他幾個 DPA 也分別對 Clearview 各開罰 2,000 萬歐元。2022 到 2026 年間,歐盟/歐洲經濟區與爬蟲相關的罰款總額已超過 9,500 萬歐元。
4. 遵守 robots.txt 就等於合法嗎?
遵守 robots.txt 是最佳實務,也符合CNIL 的強制防護措施,但它本身不構成合法性保證。涉及個人資料時你仍然要遵守 GDPR,另外還有資料庫指令與網站服務條款。把它當成多層合規框架裡的一層就好。
5. 歐洲和美國的爬蟲法律差在哪?
歐盟明顯嚴格得多。GDPR 適用於任何個人資料,即使是公開可得的也一樣;資料庫指令則替有組織的資料集提供強力保護。美國沒有對應這兩部法律的聯邦法,在 hiQ v. LinkedIn 之後,爬取公開資料在美國一般是被允許的。脫歐後的英國介於兩者之間,UK GDPR 與保留下來的資料庫權利大致沿用歐盟規則,執法機關則換成 ICO。對跨境企業而言,歐盟規則就是最高門檻——而且只要你爬的是歐盟居民的資料,公司設在哪裡都一樣適用。
延伸閱讀




