

想像一下:你剛把網站上線,正準備迎接湧入的大批潛在客戶,卻發現一半流量竟然是……機器人。不是科幻片裡那種,而是數位爬蟲——搜尋引擎、AI 機器人、分析蜘蛛——日以繼夜地在你的網站裡四處探查,像一場看不見終點的無形賓客遊行。到了 2026 年,這早就不只是伺服器日誌裡的一個有趣註腳;它已經成了新常態。了解是誰(或什麼)在爬取你的網站、多久爬一次,以及為什麼要爬,現在已經是經營任何線上業務的核心。
作為在 SaaS、自動化與 AI 領域打滾多年的老兵,我一路看著網路爬取從幕後的技術細節,變成企業最前線的挑戰。數字相當驚人:如今機器人已占全網路流量將近一半,在某些地方甚至比真人還多。隨著 AI 驅動的爬蟲大量抓取內容來訓練大型語言模型,風險也前所未有地升高——無論是基礎架構、預算,還是品牌形象都會受到影響。接下來,我們就來看看最新的網路爬取統計、產業基準,以及這一切在 2026 年對你的業務意味著什麼。
2026 年的網路爬取:整體版圖一覽
用 AI 從任何網站擷取資料 Get Started Free
網路爬取的規模與複雜度都已經來到全新層次。每天都有數十億筆自動化請求穿梭於網際網路之間,背後是越來越龐大的爬蟲群。過去主角主要是 Googlebot 和 Bingbot 這類搜尋引擎機器人,負責索引頁面,讓使用者能在搜尋結果中找到它們。但現在,AI 資料爬蟲、社群媒體抓取器、分析機器人等新角色也紛紛加入。
先看最重要的數字,但這會因你採用哪把尺而不同。Cloudflare 的 Year in Review 2025 顯示,截至 2025 年 12 月初,機器人與 AI 爬蟲合計約占其網路上 53% 的 HTML 請求,真人流量則降至 47%。Imperva 觀察自家企業客戶基礎,在其 Bad Bot Report 2026(2026 年 4 月 29 日發布)中也得出相同結論——2025 年全年為 53% 機器人、47% 真人,比前一年的 51/49 更偏向機器人。兩個非常不同的觀察角度,卻得到同一個結果:自動化流量現在已經是網路流量的大半。真正的變化不只是數量,而是成員結構。過去搜尋索引器主宰機器人欄位;到了 2026 年,越來越多比例來自替聊天機器人與答案引擎蒐集資料的 AI 訓練爬蟲。
如今的版圖比以往更為多元:
- 良性機器人: 搜尋索引器、正常運作監控工具、合法資料抓取器。
- 惡意機器人: 垃圾訊息、駭客攻擊、未經授權的抓取。
- AI 爬蟲: 新登場的角色,負責蒐集內容供 AI 訓練與即時回答使用。
AI 爬蟲的行為常常和搜尋引擎同行不同。它們可能會抓取整個頁面內容進行語意分析,而不只是索引關鍵字;而且流量通常很大——有時幾天內就會對網站發出數百萬次請求。結果就是?網路爬取已成為無所不在、持續成長且愈來愈多元的現象,把傳統索引與 AI 對資料的旺盛需求混在一起。
每個企業都該知道的網路爬取關鍵統計
來看看 2026 年正在塑造網路版圖的數據。這些統計不只是茶餘飯後的冷知識,而是你應該用來調整基礎架構、內容策略與獲利表現的基準。
機器人 vs. 真人:流量大戰誰占上風?
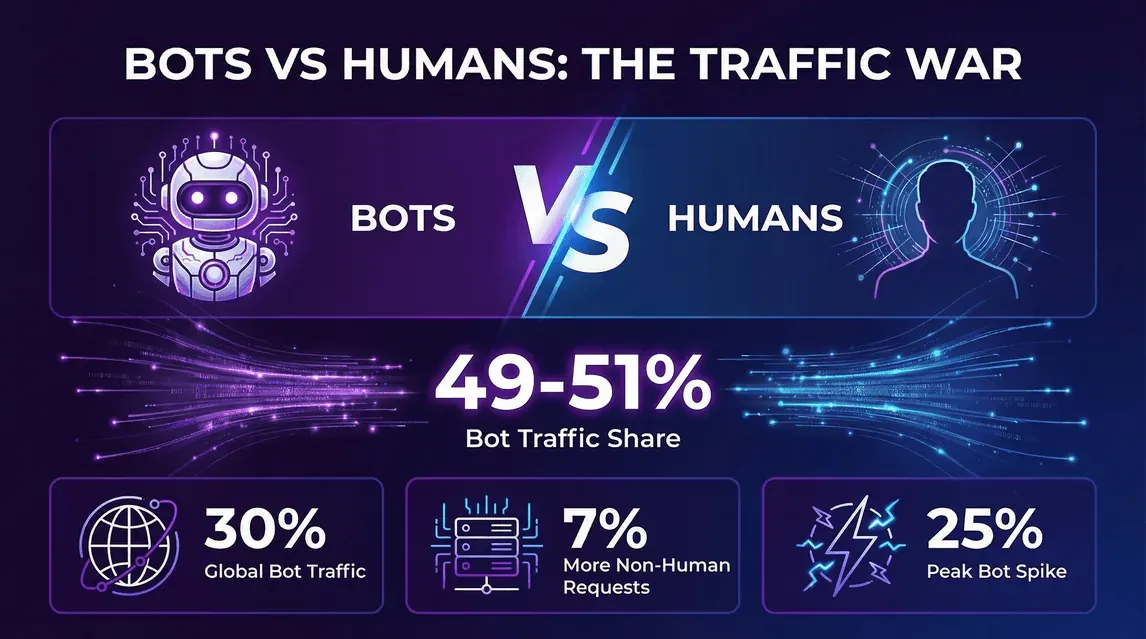
- Imperva,Bad Bot Report 2026(2026 年 4 月): 2025 年自動化流量占全部網路流量的 53%,高於 2024 年的 51%。相對地,真人流量從 49% 下降到 47%。
- Cloudflare Year in Review 2025: 截至 2025 年 12 月 2 日,Cloudflare 網路上的 HTML 請求中,47% 來自真人、44% 來自非 AI 機器人,另有約 9% 來自 AI 機器人與 Googlebot 的合計。
- 這不是某一季的短暫波動——Imperva 自 2019 年以來的機器人占比每年都在上升,而 2024 到 2025 的跳升主要是由 AI 訓練爬蟲帶動,不是一般常見的抓取/憑證填充組合。
- 對網站主的意義: 如果你的分析工具沒有排除機器人,原始請求數約有一半根本不是人。若只根據原始日誌來規劃基礎架構而不區分機器人,通常會高估需求;反過來,若機器人處理能力不足,受影響的也會是那一半真正的人類流量。
AI 爬蟲的爆發
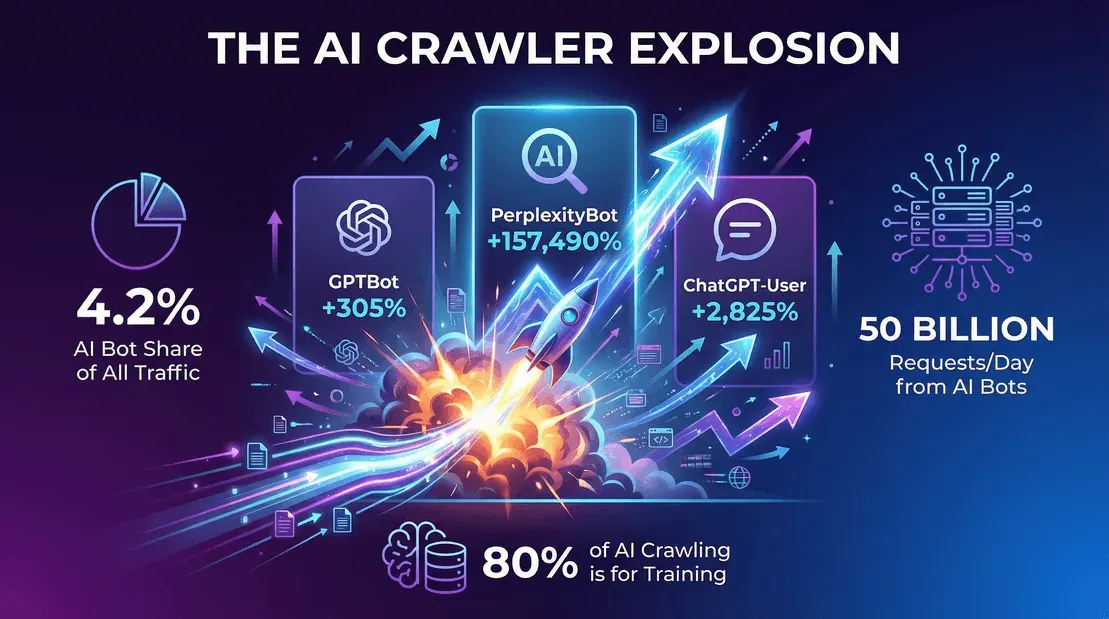
- AI 機器人流量占比仍在攀升。 根據 Cloudflare 的 Year in Review 2025,到了 2025 年底,AI 機器人(不含 Googlebot)約占 4.2% 的 HTML 請求,單是 Googlebot 又占了另外 4.5%。三年前還不存在的分類,如今規模已經幾乎和 Googlebot 本身相當。
- OpenAI 的 GPTBot 從 2025 年 5 月占爬蟲請求的 7.7%,降到 2025 年底占 2.4% 的唯一頁面請求(Cloudflare YIR 2025)。這個百分比看起來比較小,是因為 Cloudflare 改用了「唯一頁面」作為分母,也因為市場越來越擁擠。不過以原始量來看,GPTBot 仍是公開網路上前三大的 AI 爬蟲之一。
- Anthropic 的 ClaudeBot 在 2025 年底與 Meta-ExternalAgent 並列,約占 2.4% 的唯一頁面請求。ClaudeBot 的相對占比在年度比較中一度下滑(在 Cloudflare 2024 年 5 月至 2025 年 5 月的區間中下降了 46%),之後又隨 Anthropic 加大再訓練而回升。
- PerplexityBot 在絕對量上仍然很小——2025 年底約占 0.06% 的唯一頁面請求——但它的成長曲線是所有主要 AI 機器人中最陡的。
- Googlebot 仍然是公開網路上單一規模最大的爬蟲,而且差距非常大。Cloudflare 的 Year in Review 顯示,它的唯一頁面量大約是 PerplexityBot 的 200 倍。
流量放在脈絡中看
以下是一個真實案例,來自 2025 年底的一則 Reddit 討論串——一位開發者拉出了 30 天的伺服器日誌:
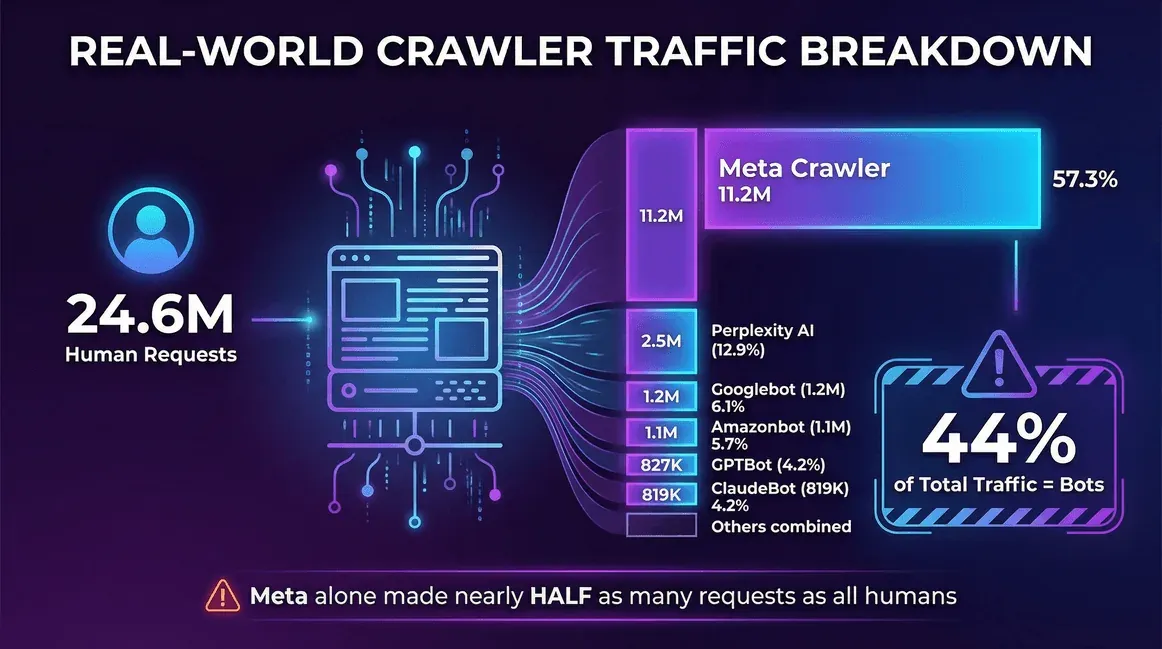
| 流量來源 | 請求數(每月) | 爬蟲占比 |
|---|---|---|
| 真實使用者(真人) | 24,647,904 | -- |
| Meta 爬蟲(Facebook) | 11,175,701 | 57.3% |
| Perplexity AI | 2,512,747 | 12.9% |
| Googlebot | 1,180,737 | 6.1% |
| Amazonbot | 1,120,382 | 5.7% |
| OpenAI GPTBot | 827,204 | 4.2% |
| ClaudeBot(Anthropic) | 819,256 | 4.2% |
| Bingbot | 599,752 | 3.1% |
| ChatGPT-User(OpenAI) | 557,511 | 2.9% |
| Ahrefs Crawler | 449,161 | 2.3% |
| ByteDance Spider | 267,393 | 1.4% |
在這個網站上,機器人占了 44% 的總流量——而 Meta 的爬蟲單獨就發出的請求量,幾乎相當於所有真人使用者總和的一半。
全局視角
- 爬蟲流量(搜尋 + AI 機器人)在 2024 年 5 月到 2025 年 5 月之間,對一組固定網站成長了 18%(blog.cloudflare.com)。
- 在某些大型 CDN 上,LLM 訓練機器人幾乎占了所有「機器人」流量的 80%(webscraft.org)。
- 到了 2025 年底,Cloudflare 網路上單是 AI 機器人每天就有約 500 億次爬蟲請求(webscraft.org)。
AI 爬蟲的崛起:AI 如何改變網路爬取
來談談房間裡那頭大象——或者該說,是那隻機器人。AI 爬蟲不只是替搜尋索引你的網站;它們正在吞噬內容,用來訓練大型語言模型,或提供即時的 AI 回答。而且它們的規模,甚至會讓最雄心勃勃的搜尋引擎都相形失色。
是什麼推動了 AI 爬蟲的爆發?
- 資料飢渴的 AI 模型: 現代 LLM 需要龐大且多元的資料集。網路就是它們的自助餐,而你的內容就在菜單上。
- 訓練 vs. 即時回答: 大約 80% 的 AI 機器人爬取是為了訓練用途,不只是為了回答即時查詢。
- 新的爬取模式: AI 機器人會以巨量突發流量攻擊網站,有時在幾天內就爬完數百萬頁,尤其是在模型重新訓練或更新時。
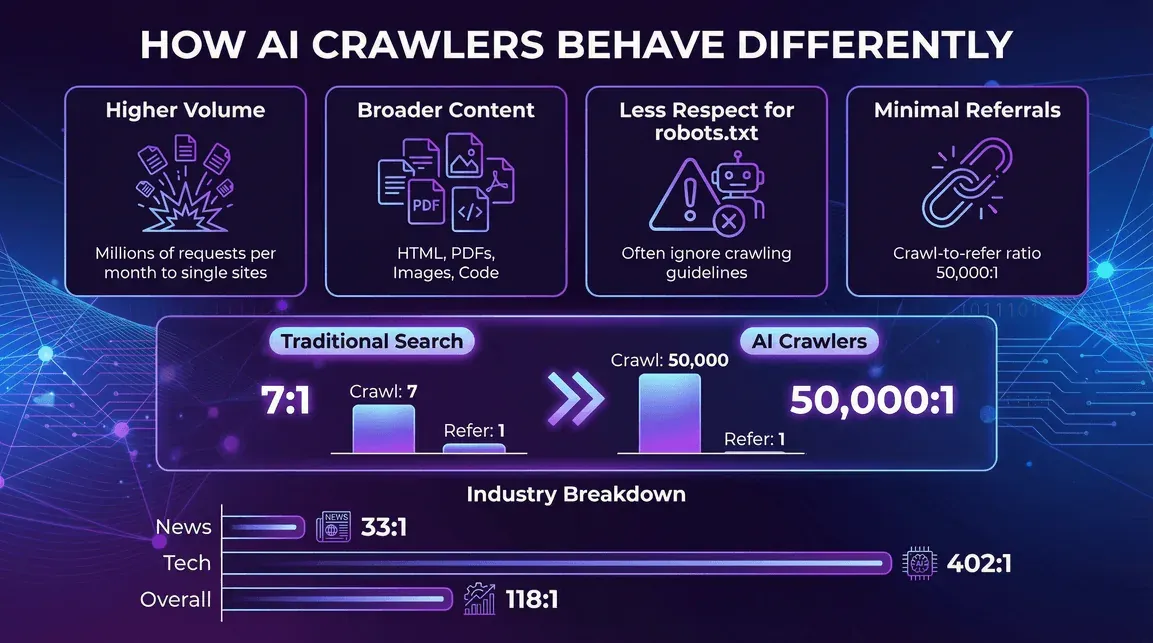
AI 爬蟲的行為有何不同
- 每個爬蟲的流量更高: 單一 AI 機器人每月就可能對同一個網站產生數百萬次請求(Reddit 範例)。
- 涵蓋更廣的內容類型: 不只 HTML,PDF、圖片、程式碼,通通都抓。
- 對 robots.txt 的尊重較少: 有些 AI 爬蟲會忽略,或只部分遵守爬取規範(blog.cloudflare.com)。
- 回傳的推薦流量很少。 這也是出版社最該擔心的部分。Cloudflare 在 2025 年 7 月的 crawl-to-click 分析中指出,Anthropic 約為 每 38,000 個被爬頁面只帶來 1 次轉介訪問,OpenAI 為 1,091:1,Perplexity 為 194:1。相比之下,Google 的傳統搜尋爬蟲每爬幾頁通常還會帶回一次轉介流量。AI 爬蟲拿走很多,回來很少——而且隨著更多答案直接在聊天機器人介面中呈現,而不是讓使用者點進網站,這個落差只會愈來愈大。
各產業的 AI 爬蟲流量
不是每個產業被爬取的程度都一樣。例如:
- 新聞與出版: AI 爬蟲活動非常密集,但轉介比略好一些(例如 Perplexity 在新聞網站上的 crawl-to-refer 比率是 33:1,而整體為 118:1)(blog.cloudflare.com)。
- 科技與電子: GPTBot 與 Amazonbot 佔主導,而 crawl-to-refer 比率仍然偏高(例如 OpenAI 在科技產業的比率是 402:1)(blog.cloudflare.com)。
- 金融、學術與其他產業: 每個部門都有自己的機器人組合與轉介率,但趨勢很明確:AI 爬蟲無所不在,而且多數幾乎不會把多少流量帶回來。
2026 年最活躍的網路爬蟲:誰爬得最多?
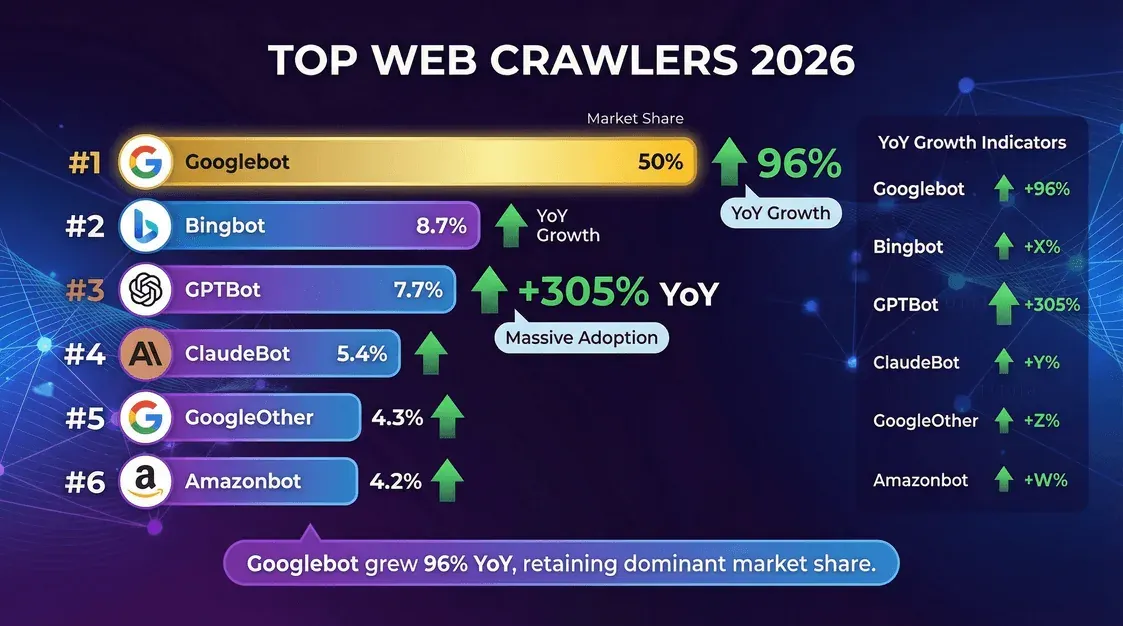
這場爬取大戲的主角有哪些?以下是根據 Cloudflare 2025 年中資料整理的排行榜:
| 爬蟲(擁有者) | 唯一頁面請求占比(2025 年 10–11 月) | 備註 |
|---|---|---|
| Googlebot(Google) | 11.6% | 仍然是單一最大爬蟲。Cloudflare YIR 2025:流量約為 PerplexityBot 的 200 倍。 |
| GPTBot(OpenAI) | 3.6% | 最大的專用 AI 訓練爬蟲。由於 Cloudflare 更改分母且 AI 機器人領域變得更擁擠,較 2025 年 5 月的占比下降。 |
| Bingbot(Microsoft) | 2.6% | 同時驅動 Bing 搜尋與 Copilot grounding。 |
| Meta-ExternalAgent | 2.4% | Meta 用於 Llama 訓練的內容擷取爬蟲。2025 年躋身前五。 |
| ClaudeBot(Anthropic) | 2.4% | 2025 年後期在前期明顯年減後回升。 |
| Applebot(Apple) | 成長快速 | 根據對 Cloudflare 資料的次級分析,在 2026 年第 1 季快速躍升至第一梯隊。 |
| PerplexityBot | 0.06% | 絕對占比很小,但在主要 AI 機器人中相對成長最快。 |
來源:Cloudflare Year in Review 2025,以 2025 年 10 至 11 月爬取的唯一頁面占比計算。注意:這裡的分母不同於早期報告中使用的 2025 年 5 月「全部爬蟲請求占比」——排行榜可相互對照,但百分比不能直接比較。
幾個重點:
- Googlebot 依然稱王,負責全部爬取活動的一半。
- GPTBot 與 Meta 的爬蟲 是成長最快的兩個,GPTBot 的占比一年內就翻了三倍。
- PerplexityBot 與 ChatGPT-User 代理雖然總占比不大,但成長速度非常驚人。
網路爬取基準:爬取速度、吞吐量與效能
 網路爬取不只是看量,還要看速度與效率。以下是你在 2026 年需要知道的爬取速度與效能基準。
網路爬取不只是看量,還要看速度與效率。以下是你在 2026 年需要知道的爬取速度與效能基準。
爬取速度:爬蟲抓頁面有多快?
- 爬取速度 通常以每秒頁數(或每秒請求數)來衡量(IBM)。
- 執行緒/平行連線: 執行緒越多,理論爬取速度越高。舉例來說,200 個執行緒、每個網站 2 秒延遲,可達到每秒約 100 頁(IBM)。
- 真實世界基準: 在一台不錯的伺服器叢集上,最佳化良好的爬蟲通常可達每秒 100 到 200 頁。
- Google 與 Bing: 很可能在全球層級每秒抓取數千頁,分散於數百萬個網站上。
影響爬取速度的因素
- 執行緒/平行擷取數量: 執行緒越多,速度越快(直到碰到其他瓶頸)。
- 活躍網站數量: 同時爬取多個網域,吞吐量會成倍增加。
- 爬取延遲/等待時間: 延遲越長,爬取速度越慢。
- 資源限制: 頻寬、CPU、資料庫寫入速度都可能成為瓶頸。
- 目標網站效能: 緩慢或限速的網站會拖慢爬取速度。
例如,如果你的爬蟲有 100 個執行緒、每個網站延遲 1 秒,你可能每秒可抓取約 100 頁——除非你的資料庫跟不上,那瓶頸就會落在儲存,而不是網路。
網路爬取的商業影響:成本、機會與風險
網路爬取不只是技術上的趣味現象,更是會真實影響營運的商業議題。
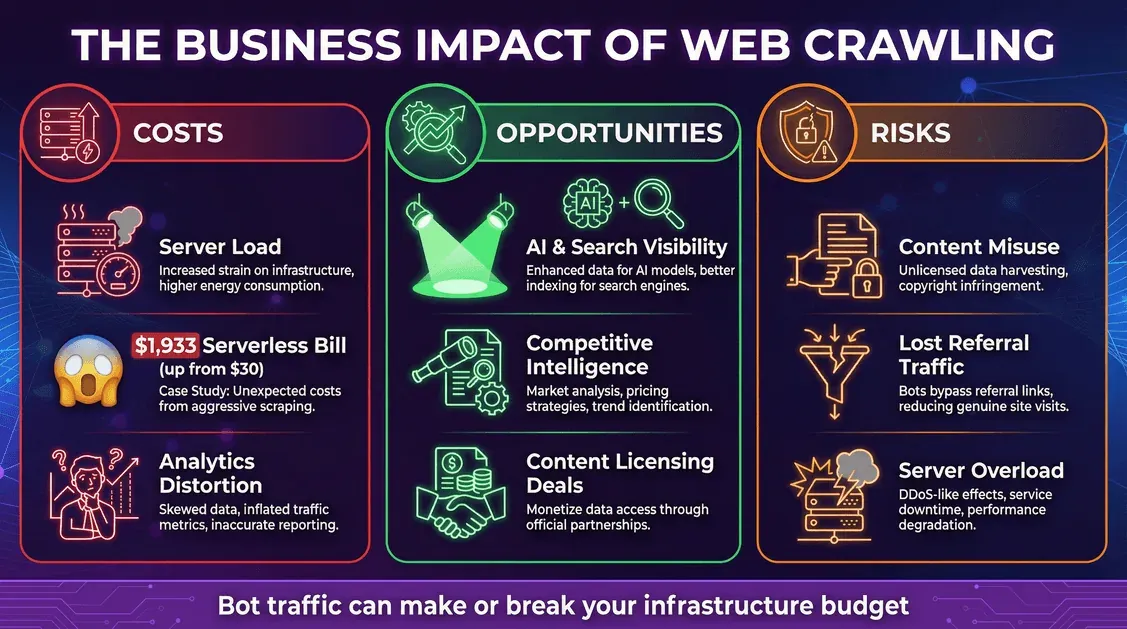
成本:基礎架構與意外帳單
- 伺服器負載: 每一次機器人請求都會消耗 CPU、記憶體與頻寬。
- 雲端帳單: 如果你使用按量計費模式(例如 serverless),機器人可能會讓費用暴增。有位開發者看到 Meta 的爬蟲一個月產生 1,100 萬次請求,導致 serverless 帳單從 30 美元飆到 1,933 美元。
- 分析失真: 機器人會扭曲你的網站分析數據,讓你更難解讀真實使用者行為。
機會:曝光與資料槓桿
- AI 與搜尋能見度: 被納入 AI 訓練資料或搜尋索引,能提升品牌觸及率(blog.cloudflare.com)。
- 競爭情報: 企業會用爬蟲進行市場研究、價格監控等工作。
- 變現: 有些出版商現在正把內容授權給 AI 公司(digiday.com)。
風險:內容濫用與流量流失
- 內容濫用: AI 爬蟲可能把你的內容吸收到模型裡,有時沒有明確授權或補償。
- 轉介流量流失: AI 回答可能直接滿足使用者需求,卻不把人導回你的網站,造成「去中介化」。
- 資安與停機: 激進的爬蟲可能壓垮伺服器,造成延遲或服務中斷。
管理網路爬蟲流量:最佳實務
那麼,要怎麼避免機器人把你的午餐,或者雲端預算吃光?
1. 優化 robots.txt
- 使用
robots.txt來允許或禁止特定機器人。多數有信譽的爬蟲(例如 Googlebot)會遵守,但不少 AI 機器人未必如此(blog.cloudflare.com)。 - 截至 2025 年中,約有 14% 的頂尖網站開始加入針對 AI 機器人的明確規則(blog.cloudflare.com)。
2. 使用機器人管理工具
- Web Application Firewall(WAF)與機器人管理服務可以封鎖或限速可疑流量。
- Cloudflare 與其他供應商提供機器人緩解功能,甚至還有供內容創作者使用的「AI Audit」工具(blog.cloudflare.com)。
3. 實施速率限制與快取
- 對單一機器人快速連續的請求做速率限制。
- 在可行的情況下,把快取內容提供給機器人——不要讓它們觸發昂貴的 serverless 函式或資料庫查詢(Reddit 範例)。
4. 監控並分析機器人流量
- 持續查看你的伺服器日誌。了解哪些機器人在抓你、多久抓一次、什麼時候抓。
- 針對異常流量尖峰設定警示。
5. 提前掌握新興標準
- 留意新的 meta 標籤或 HTTP 標頭,用來表達 AI 使用權限(例如
<meta name="ai:allow" content="no">)。 - 持續關注產業倡議,例如 ContentSignals.org 以及像 x402 這類支付協議。
2026 年及未來值得關注的網路爬取趨勢
2025 年什麼是資料抓取,以及如何操作 Get Started Free
網路爬取版圖正在快速演變。以下是我正在關注、你也該注意的幾個方向:
- AI 驅動的爬取只會持續增加: 預期會有更多 AI 機器人,爬取更多內容類型(文字、圖片、影片)。
- 內容授權與支付標準。 「狂野西部」的說法已經開始顯得過時。Anthropic 在 2025 年底就訓練資料爭議與作者達成 15 億美元和解,創下截至目前出版商與 AI 之間最大的和解案。Meta 也與 CNN、Fox News、People Inc. 和 USA Today 簽下多年內容授權協議,而 2025 年較早的 AP–Google 與 Axios–OpenAI 案例,如今已被視為模板,而非例外。新訴訟仍在持續出現——2026 年 5 月 5 日,五家出版商在曼哈頓起訴 Meta——所以法律版圖遠未定型,但方向已經很清楚:內容正在被估值、被付費,也被訴訟,而不只是被抓取。在協議層面,x402 與 ContentSignals.org 正逐漸被視為機器支付與機器授權層的重要候選方案。
- 監管即將到來: 預期會有更多法律明確規範機器人能做什麼、不能做什麼,特別是 AI 訓練資料部分(reuters.com)。
- 內容使用的技術標準: 留意新的 meta 標籤、robots.txt 擴充規則,以及可機器讀取的機器人聲明。
- 出版商與 AI 的合作: 與其被動挨打,越來越多出版商將會與 AI 公司協商結構化資料來源或 API。
結論:這些網路爬取統計對你的業務代表什麼
結論很簡單:2026 年,網路爬取已經是主導性力量,而且還在持續升溫。自動化機器人——尤其是 AI 爬蟲——現在已經負責你網站流量中的很大一部分,且它們對基礎架構、預算與內容策略的影響只會愈來愈大。
你該怎麼做?
- 預期高機器人流量: 依此規劃你的基礎架構、預算與監控。
- 了解你的爬蟲: 不是每個機器人都一樣,要對不同類型採取不同策略。
- 監控你的指標: 把機器人流量跟真人訪客一樣追蹤。
- 保護你的內容與荷包: 善用技術控制、法律協議與新興標準。
- 放大正面效益: 被收錄進 AI 與搜尋索引能提升品牌能見度——只要確保你也有獲得相應價值。
- 保持資訊更新並快速調整: 爬取生態正在快速變動,持續關注新的標準、法規與商業模式。
身為一個多年來一直在打造自動化與 AI 工具、現在又在 Thunderbit 工作的人,我可以很肯定地說:在這個新時代真正能勝出的企業,是把網路爬取視為策略優先事項,而不只是技術困擾的企業。不管你做的是銷售、電商、行銷還是不動產,了解網路爬取統計與產業基準,現在已經是基本門檻。
所以下次你打開伺服器日誌,看到滿滿的機器人排隊出現時,別只是嘆口氣就關掉。善用這些數據。建立你的基準。調整策略。也請記得:在 AI 時代,機器人不只是要來——它們早就已經在這裡了。讓它們替你工作,而不是反過來。
保持警覺、保持好奇,願你的伺服器日誌永遠站在你這邊。
想進一步了解網路抓取、自動化與 AI 驅動的生產力嗎?歡迎前往 Thunderbit 部落格 查看深度解析、操作教學與最新趨勢。如果你已準備好掌握自己的資料,也可以試試 Thunderbit Chrome 擴充功能 進行 AI 網頁爬取——不用寫程式、沒有麻煩,直接拿到成果。
試用 AI 網頁爬蟲 Get Started Free
引用與延伸閱讀:




