想像一下:現在已經是 2025 年,你一邊喝著早上的咖啡,一邊想知道 Walmart 那台你關注很久的 65 吋電視到底有沒有降價——或者你是電商老闆,必須隨時掌握 Walmart 的價格、庫存和顧客評價。每天手動檢查每個商品頁?那根本是苦工,還超級無聊。但只要你會一點 Python,加上網頁爬蟲的基本功,這些繁瑣的流程都能自動化,輕鬆取得大量有價值的數據。
我這幾年一直在幫企業打造自動化和 AI 工具。Walmart 網頁爬蟲就是那種能把冗長調查變成幾行程式碼的「秘密武器」——這篇文章會帶你一步步上手。你會學到什麼是 walmart 抓取、2025 年它對企業的價值,以及怎麼用 Python 打造一個穩定的 walmart 網頁爬蟲。咖啡準備好(或你最愛的 debug 零食)就開工吧!
什麼是 walmart 抓取?2025 年基礎解析
簡單說,walmart 抓取就是用軟體自動從 Walmart 網站擷取商品、價格、評論等資料——通常就是寫一個像極速瀏覽器的腳本。你不用再手動複製貼上(真的沒人愛這種事),只要寫個 Python 腳本,抓取 Walmart 頁面、提取你要的資訊,然後存下來分析。
為什麼選 Python?因為 Python 就是網頁爬蟲界的萬用工具:語法簡單、函式庫齊全(像 Requests、BeautifulSoup、pandas),還有超大的社群分享經驗和範例。不管你是個人研究還是企業團隊,Python 都能讓抓取 walmart 變得很簡單,就算不是專業工程師也能輕鬆上手。
不過要注意,個人用途(像追蹤幾個商品價格)和商業用途(例如監控上千個 SKU 來獲取競爭情報)在規模和技術挑戰上差很多——尤其是 Walmart 到 2025 年都還沒提供公開產品 API()。
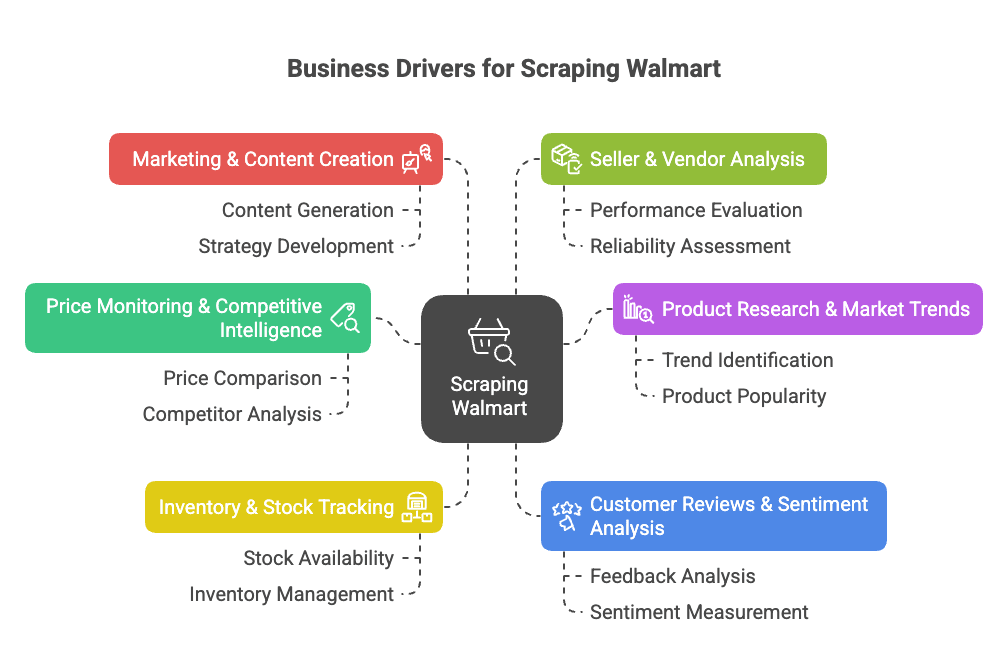
為什麼要抓取 walmart?商業價值解析
Walmart 不只是美國最大的實體零售商,現在更是線上銷售巨頭,2023 年網路銷售額超過 ,電商佔總銷售近 18%()。這代表有超大量商品、價格、評論和趨勢等著你分析。
那為什麼要抓取 walmart?這裡有幾個主要商業動機:
- 價格監控與競爭情報: 即時追蹤 Walmart 價格、促銷和商品變動,優化你的定價與產品策略()。
- 商品研究與市場趨勢: 分析 Walmart 的商品組合、規格和分類趨勢,發現市場缺口或新機會()。
- 庫存與存貨追蹤: 監控商品庫存狀態,優化供應鏈或搶佔競爭對手缺貨時機()。
- 顧客評論與情感分析: 匯整並分析評論,改進產品或找出痛點()。
- 行銷與內容創作: 觀察哪些商品標註「熱銷」,怎麼呈現,以及哪些內容最能帶動轉換()。
- 賣家與供應商分析: 找出表現最好的第三方賣家或未授權商品()。
這張表快速整理應用場景、受益對象和帶來的效益:
| 應用場景 | 受益對象 | 效益與投資報酬 |
|---|---|---|
| 價格監控 | 定價與銷售團隊 | 即時競爭對手價格、動態定價、保護利潤 |
| 商品組合與目錄分析 | 產品管理、商品企劃 | 發現缺口、推出新品、提升目錄完整性 |
| 庫存追蹤 | 營運與供應鏈 | 更佳需求預測、避免缺貨、優化配送 |
| 顧客評論與情感 | 產品開發、顧客體驗 | 以數據驅動產品改進、提升滿意度 |
| 市場趨勢與分析 | 策略與市場研究 | 把握趨勢、輔助決策、搶先進入新市場 |
| 內容與定價策略 | 行銷與電商團隊 | 優化定價、學習高效內容 |
| 賣家監控 | 銷售與合作夥伴團隊 | 尋找合作夥伴、保護品牌、監控未授權賣家 |
一句話總結:walmart 抓取能省時、省力、提升營收,讓你在數據上領先對手。不用每天手動檢查 50 頁,腳本幾分鐘就能抓下上千筆資料()。
walmart 抓取對電商、銷售和市場研究團隊來說就是顛覆性的利器。有了對的工具,你能自動化數據收集,把時間花在分析洞察,而不是重複勞動。
用 Python 抓取 walmart:你需要準備什麼?
開始抓取前,先把 Python 環境準備好。你會用到:
- Python 3.9 以上(建議 3.11 或 3.12)
- Requests:抓網頁
- BeautifulSoup (bs4):解析 HTML
- pandas:整理和匯出數據
- json:處理 JSON(內建)
- 瀏覽器開發者工具:檢查 Walmart 頁面結構(F12)
- pip:安裝 Python 套件
快速安裝指令:
1pip install requests beautifulsoup4 pandas想讓專案更乾淨?可以建立虛擬環境:
1python3 -m venv walmart-scraper
2source walmart-scraper/bin/activate # Mac/Linux
3# 或
4walmart-scraper\\Scripts\\activate.bat # Windows測試環境:
1import requests, bs4, pandas
2print("Libraries loaded successfully!")看到訊息就代表一切 OK。
步驟 1:建立你的 Python walmart 網頁爬蟲
先把專案架構好:
- 建立專案資料夾(像
walmart_scraper/)。 - 打開你的編輯器(VSCode、PyCharm、Notepad++ 都可以)。
- 新建腳本檔案(像
walmart_scraper.py)。
啟動範本:
1import requests
2from bs4 import BeautifulSoup
3import pandas as pd
4import json現在可以準備抓取 Walmart 商品頁面了。
步驟 2:用 Python 抓取 Walmart 商品頁面
要抓取 Walmart,首先要取得商品頁的 HTML。但要注意:Walmart 的反爬蟲很兇。直接用 requests.get(url),很快就會遇到「你是人還是機器人?」的驗證。
訣竅是什麼?模仿真實瀏覽器。 也就是要設定像 Chrome 或 Firefox 的 headers,例如 User-Agent 和 Accept-Language。
範例:
1headers = {
2 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0 Safari/537.36",
3 "Accept-Language": "en-US,en;q=0.9"
4}
5response = requests.get(url, headers=headers)
6html = response.text小技巧: 用 requests.Session() 維持 cookies,更像真人:
1session = requests.Session()
2session.headers.update(headers)
3session.get("<https://www.walmart.com/>") # 先訪問首頁設置 cookies
4response = session.get(product_url)記得檢查 response.status_code(應該是 200)。如果出現奇怪頁面或驗證碼,請放慢速度、換 IP 或暫停一下。Walmart 的反爬蟲真的很兇()。
應對 Walmart 反爬蟲措施
Walmart 會用 Akamai、PerimeterX 等技術檢查你的 IP、headers、cookies,甚至 TLS 指紋。怎麼降低被偵測風險?
- 一定要設定真實 headers(如上)。
- 控制請求頻率——每頁間隔 3–6 秒。
- 隨機延遲,不要像機器人一樣規律。
- 大量抓取時輪換代理(後面會說)。
- 遇到驗證碼就暫停,不要硬闖。
想更進階,可以用 curl_cffi 讓 Python 請求更像 Chrome()。但大多數情況下,headers 和耐心就夠了。
步驟 3:用 BeautifulSoup 擷取 Walmart 商品資料
接下來就是重點:提取你要的資料。Walmart 網站用 Next.js 架構,大部分商品資訊都藏在 <script id="__NEXT_DATA__"> 的 JSON 裡。
抓取方式:
1from bs4 import BeautifulSoup
2import json
3soup = BeautifulSoup(html, "html.parser")
4script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
5if script_tag:
6 json_text = script_tag.string
7 data = json.loads(json_text)這樣你就拿到一個包含所有商品資訊的 Python 字典。一般商品頁的資料位置:
1product_data = data["props"]["pageProps"]["initialData"]["data"]["product"]然後提取你要的欄位:
1name = product_data.get("name")
2price_info = product_data.get("price", {})
3current_price = price_info.get("price")
4currency = price_info.get("currency")
5rating_info = product_data.get("rating", {})
6average_rating = rating_info.get("averageRating")
7review_count = rating_info.get("numberOfReviews")
8description = product_data.get("shortDescription") or product_data.get("description")為什麼用 JSON? 因為結構清楚、穩定,不容易因為 HTML 微調而失效,還能拿到更多細節()。
處理動態內容與 JSON 資料
有時評論或庫存狀態是用 JavaScript 或 API 動態載入。好消息是,初始 JSON 通常已經包含大部分你要的資訊。如果沒有,可以用瀏覽器開發者工具的 Network 面板找出 API 端點,模仿請求。
但大多數商品資料,__NEXT_DATA__ JSON 就夠用了。
步驟 4:儲存與匯出 Walmart 資料
資料抓下來後,建議用結構化格式儲存——CSV、Excel 或 JSON 都很方便。用 pandas 實作:
1import pandas as pd
2product_record = {
3 "商品名稱": name,
4 "價格 (USD)": current_price,
5 "評分": average_rating,
6 "評論數": review_count,
7 "描述": description
8}
9df = pd.DataFrame([product_record])
10df.to_csv("walmart_products.csv", index=False)如果抓多個商品,就把每筆資料加進 list,最後再建立 DataFrame。
想匯出 Excel?用 df.to_excel("walmart_products.xlsx", index=False)(需安裝 openpyxl)。匯出 JSON:df.to_json("walmart_products.json", orient="records", indent=2)。
小提醒: 匯出後一定要抽查資料,確保和網站一致。最怕抓了一千筆價格,結果全是 None,只因為欄位名稱被改了。
步驟 5:擴大你的 walmart 網頁爬蟲規模
想抓更多商品?這樣做:
1product_urls = [
2 "<https://www.walmart.com/ip/Apple-AirPods-Pro-2nd-Generation/720559357>",
3 "<https://www.walmart.com/ip/SAMSUNG-65-Class-QLED-4K-Q60C/180355997>",
4 # ...更多網址
5]
6all_records = []
7for url in product_urls:
8 resp = session.get(url)
9 # ...如前解析與提取...
10 all_records.append(product_record)
11 time.sleep(random.uniform(3, 6)) # 禮貌一點!如果沒有網址清單,可以從搜尋結果頁抓取商品連結,再逐一抓取()。
但要注意: 快速抓取數百上千頁,幾乎一定會被封鎖 IP。這時就需要代理伺服器。
walmart 抓取用代理與爬蟲 API
代理伺服器能幫你輪換 IP,降低被封鎖風險。可以購買住宅代理(看起來像真人),或用代理池。用法如下:
1proxies = {
2 "http": "<http://your.proxy.address>:port",
3 "https": "<https://your.proxy.address>:port"
4}
5response = session.get(url, proxies=proxies)大規模抓取時,也可以考慮 爬蟲 API——這類服務會自動處理代理、驗證碼,甚至 JavaScript 渲染。你只要傳 Walmart 網址,對方就回傳資料(有時直接給你 JSON)。
快速比較:
| 方式 | 優點 | 缺點 | 適合對象 |
|---|---|---|---|
| 自行用 Python + 代理 | 完全掌控、適合小規模、成本低 | 需維護、代理費用、易被封鎖 | 開發者、客製需求 |
| 第三方爬蟲 API | 簡單、反爬蟲自動處理、易擴展 | 大量時成本高、彈性較低、依賴第三方 | 企業用戶、大規模、追求快速成果 |
如果你不會寫程式,或只想快速拿到資料, 只要點兩下——不用寫程式、不用代理、沒煩惱。(後面會再介紹。)
walmart 抓取常見挑戰與解法
walmart 抓取並不是一路順風。常見問題和對策如下:
- 強力反爬蟲措施: Walmart 會檢查 IP、headers、cookies、TLS 指紋、JavaScript。解法:設定真實 headers、用 session、加延遲、輪換代理()。
- 驗證碼(CAPTCHA): 遇到驗證碼就暫停,稍後再試。若頻繁遇到,可考慮驗證碼解決服務,但會增加成本與複雜度()。
- 網站結構變動: Walmart 經常更新網站。爬蟲失效時,重新檢查 JSON 結構並調整程式。模組化設計有助於維護。
- 分頁與子頁面: 大量抓取時要處理分頁。用迴圈並設好終止條件,確保不會漏抓或重複抓()。
- 數據量與速率限制: 大規模抓取時,分批請求並將部分結果寫入硬碟。不要一次把 10 萬筆資料全載入記憶體。
- 法律與道德問題: 只抓取公開資料,遵守 Walmart 條款,不要對伺服器造成過大負擔。若商業用途,務必確認合規。
什麼時候該用託管型工具? 如果你花在解決驗證碼的時間比分析數據還多,建議考慮 Thunderbit 或爬蟲 API。對非技術用戶來說,無程式碼工具通常最省事()。
Python walmart 抓取完整範例程式
這裡有一份完整、帶註解的 Python Walmart 商品頁抓取腳本:
1import requests
2from bs4 import BeautifulSoup
3import json
4import pandas as pd
5import time
6import random
7# 建立 session 與 headers
8session = requests.Session()
9session.headers.update({
10 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0 Safari/537.36",
11 "Accept-Language": "en-US,en;q=0.9"
12})
13# 先訪問首頁設置 cookies
14session.get("<https://www.walmart.com/>")
15# 商品網址清單
16product_urls = [
17 "<https://www.walmart.com/ip/Apple-AirPods-Pro-2nd-Generation/720559357>",
18 "<https://www.walmart.com/ip/SAMSUNG-65-Class-QLED-4K-Q60C/180355997>",
19 # 可自行新增更多網址
20]
21all_products = []
22for url in product_urls:
23 try:
24 response = session.get(url)
25 except Exception as e:
26 print(f"Request error for \{url\}: \{e\}")
27 continue
28 if response.status_code != 200:
29 print(f"Failed to fetch \{url\} (status \{response.status_code\})")
30 continue
31 soup = BeautifulSoup(response.text, "html.parser")
32 script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
33 if not script_tag:
34 print(f"No data script found for \{url\} - possibly blocked or changed page format.")
35 continue
36 try:
37 data = json.loads(script_tag.string)
38 except json.JSONDecodeError as e:
39 print(f"JSON parse error for \{url\}: \{e\}")
40 continue
41 try:
42 product_info = data["props"]["pageProps"]["initialData"]["data"]["product"]
43 except KeyError:
44 print(f"Product data not found in JSON for \{url\}.")
45 continue
46 name = product_info.get("name")
47 brand = product_info.get("brand", {}).get("name") or product_info.get("brand", "")
48 price_obj = product_info.get("price", {})
49 price = price_obj.get("price")
50 currency = price_obj.get("currency")
51 orig_price = price_obj.get("priceStrikethrough") or price_obj.get("price_strikethrough")
52 rating_obj = product_info.get("rating", {})
53 avg_rating = rating_obj.get("averageRating")
54 review_count = rating_obj.get("numberOfReviews")
55 desc = product_info.get("description") or product_info.get("shortDescription") or ""
56 product_record = {
57 "URL": url,
58 "商品名稱": name,
59 "品牌": brand,
60 "價格": price,
61 "幣別": currency,
62 "原價": orig_price,
63 "平均評分": avg_rating,
64 "評論數": review_count,
65 "描述": desc
66 }
67 all_products.append(product_record)
68 # 隨機延遲,降低被偵測風險
69 time.sleep(random.uniform(3.0, 6.0))
70df = pd.DataFrame(all_products)
71print(df.head(5))
72df.to_csv("walmart_scrape_output.csv", index=False)可以自訂:
- 在
product_urls加入更多網址。 - 根據需求調整提取欄位。
- 根據風險承受度調整延遲時間。
結論與重點整理
重點回顧:
- walmart 抓取能解鎖價格、商品、評論等關鍵數據,對 2025 年的競爭情報、定價、產品開發超級重要。
- Python 是最佳工具:用 Requests、BeautifulSoup、pandas,就算不是高手也能寫出穩定爬蟲。
- 反爬蟲防禦很強:模仿瀏覽器 headers、用 session、加延遲、規模大時輪換代理。
- 從
__NEXT_DATA__JSON 擷取資料:比直接抓 HTML 更穩定、乾淨。 - 用 pandas 匯出分析資料:可存成 CSV、Excel 或 JSON。
- 擴大規模要有策略:大規模時建議用代理或爬蟲 API。若不懂程式, 可一鍵抓取 Walmart(還有其他網站),還能免費匯出到 Excel、Google Sheets、Airtable 或 Notion()。
建議:
從小規模開始——先抓一個商品,再抓幾個。確認資料正確,尊重 Walmart 條款,不要對伺服器造成負擔。需求擴大時,考慮用託管工具或 API,省時又省力。如果你 debug Python debug 到心累,記得:用 Thunderbit,兩下就能抓 Walmart,AI 幫你搞定所有細節()。
想深入了解網頁爬蟲、數據自動化或 AI 生產力?歡迎瀏覽 。
祝你抓數據順利,資料永遠新鮮、正確、無驗證碼困擾!
P.S. 如果你半夜兩點還在抓 Walmart,邊碎念邊 debug,別擔心——每個數據人都經歷過。Debug 只是讓你更強大的必經之路。
常見問答
1. 用 Python 抓取 Walmart 網站資料是否合法?
抓取公開資料作為個人或非商業分析通常沒問題,但商業用途可能涉及法律與道德風險。請務必查閱 Walmart 服務條款,避免違反速率限制、造成伺服器負擔或抓取敏感資料。
2. 用 Python 可以抓到哪些 Walmart 資料?
你可以抓取商品名稱、價格、品牌、描述、顧客評論、評分、庫存狀態等——尤其是解析 Walmart <script id="__NEXT_DATA__"> 裡的結構化 JSON。
3. 如何避免抓取 Walmart 被封鎖?
設定真實 headers、維持 session、每次請求間隨機延遲(3–6 秒)、輪換代理,避免短時間內大量請求。大規模專案建議用爬蟲 API 或 Thunderbit 這類自動處理反爬蟲的工具。
4. 可以大規模抓取上百上千個 Walmart 商品頁嗎?
可以,但需管理代理、控制請求速率,必要時用爬蟲 API。Walmart 反爬蟲很強,沒準備好就擴大規模容易被封鎖或遇到驗證碼。
5. 不會寫程式怎麼抓 Walmart?
像 Thunderbit 人工智慧網頁爬蟲 Chrome 擴充這類工具,讓你不用寫一行程式就能抓取 Walmart 商品頁。它自動處理反爬蟲,支援匯出到 Excel、Notion、Sheets,非常適合非技術用戶或需要快速洞察的商業團隊。