

讓我帶你回到第一次嘗試從電商網站抓取產品資料的時候。當時我手上有 Python、一杯咖啡,還有一個夢想:做出 Amazon 的價格追蹤器。幾個小時後,原本所謂的「快速專案」已經變成一團 XPath 選擇器、分頁處理難題,以及多到我不想承認的除錯工作。如果你曾經試過用程式碼整理網頁資料,大概很懂那種感覺——既興奮,又忍不住想問「這到底為什麼這麼複雜?」
重點是:網頁爬蟲不再只是資料科學家或工程師的專利。對銷售團隊、電商經理、行銷人員,以及任何想把網路上的雜訊轉成商業洞察的人來說,它都已經是必備技能。事實上,網頁爬蟲軟體市場在2024 年達到 10.1 億美元,預計到 2032 年將成長至 24.9 億美元,而且這條成長曲線還看不到趨緩。不過,雖然 Python 和 Scrapy 這類框架依然是大規模、客製化爬取的黃金標準,它們其實並不算對新手友善。所以在這篇教學裡,我會帶你一步步了解 Scrapy——以真實的 Amazon 使用情境為例——並且介紹一個對非程式設計者友善得多、由 AI 驅動的替代方案:Thunderbit。
什麼是 Scrapy Python?你的網頁爬蟲利器
先從基礎開始。Scrapy 是一個專為網頁爬取與抓取而生的開源 Python 框架。你可以把它想成一套全方位工具組,用來打造客製化 spider(也就是 Scrapy 對 crawler 的稱呼),讓它能瀏覽網站、追蹤連結、處理分頁,並且大規模擷取結構化資料。
Scrapy 跟單純使用 Python 的 requests 和 BeautifulSoup 有什麼不同?這些函式庫雖然很適合簡單、一次性的抓取,但 Scrapy 是為了大型、複雜專案而設計的,像是你需要:
- 爬取數千頁內容(例如:電商目錄中的每一個商品)
- 自動追蹤連結並處理分頁
- 以非同步方式處理資料,提升速度
- 用可重複的方式結構化、清理與匯出資料
簡單來說,Scrapy 就像網頁爬蟲界的瑞士刀——強大、靈活,但對新手來說也有點嚇人。
為什麼要用 Scrapy Python 做網頁爬蟲?
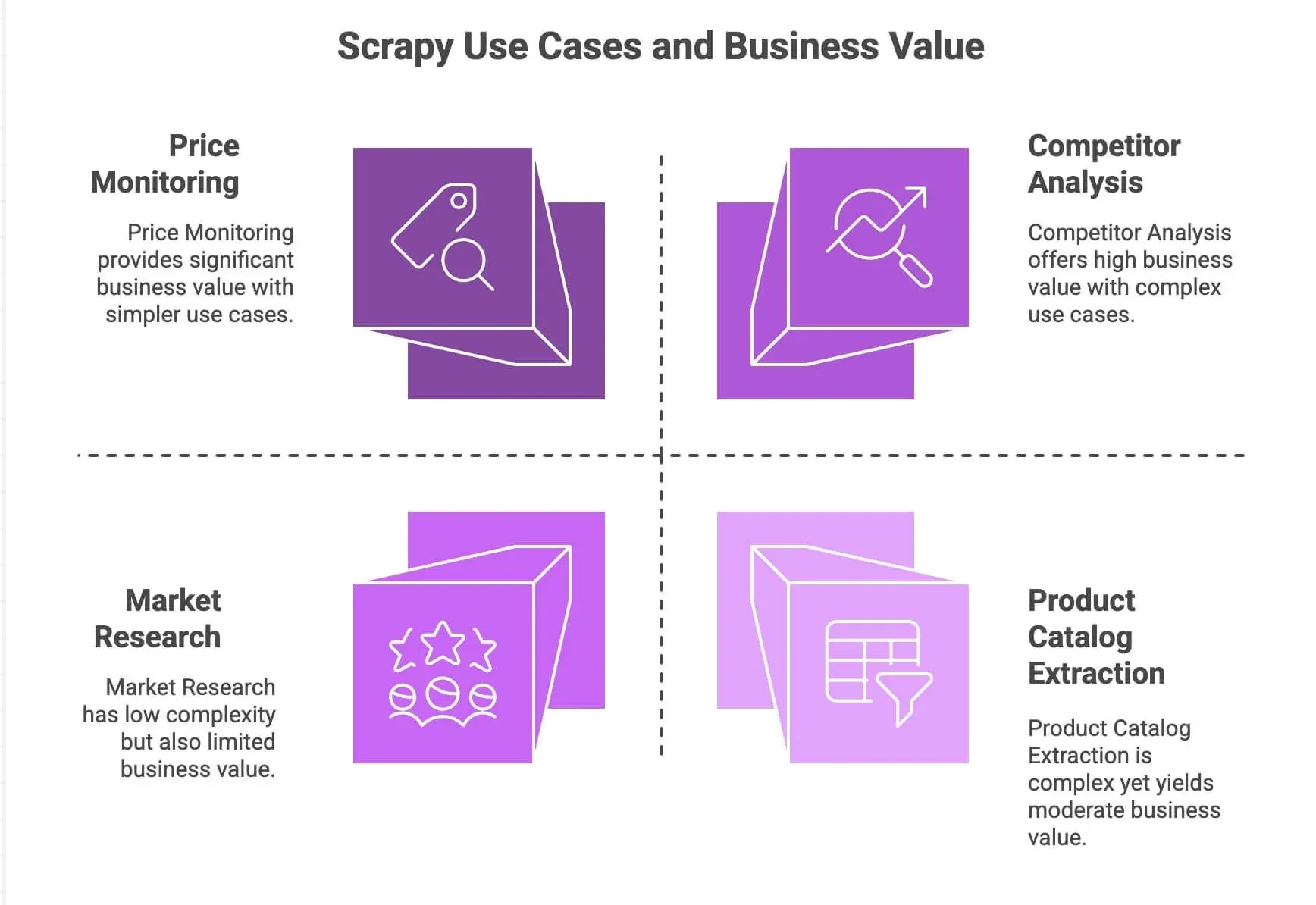
那麼,為什麼開發者和資料團隊總是會選 Scrapy?以下是它最突出的幾個原因:
| 使用情境 | Scrapy 優勢 | 商業價值 |
|---|---|---|
| 價格監控 | 支援分頁、非同步請求、排程 | 讓你搶先掌握競爭對手、動態定價 |
| 產品目錄擷取 | 可追蹤連結、擷取結構化資料 | 建立產品資料庫、支援分析流程 |
| 競品分析 | 可擴展、對網站變動較有韌性 | 追蹤趨勢、新品上市、庫存狀況 |
| 市場研究 | 模組化管線,方便清理/轉換資料 | 彙整評論、進行情緒分析 |
Scrapy 的非同步引擎(建構於 Twisted 之上)讓它能平行抓取多個頁面,因此速度快、可擴充性高。它的模組化設計讓你可以輕鬆加入自訂邏輯,例如代理伺服器、User-Agent 或資料清理步驟。再加上管線(pipelines),你可以依需求處理、驗證與匯出資料——CSV、JSON、資料庫,通通可以。
對有 Python 技能的團隊來說,Scrapy 是個超強工具。不過說實話,它對一般商業使用者來說,並不是那種「裝了就能直接用」的東西。
建立你的 Scrapy Python 環境
準備動手了嗎?以下是從零開始設定 Scrapy 的方法:
1. 安裝 Scrapy
先確認你已安裝 Python 3.10 以上版本(Scrapy 2.15.x 已在 2026 年停止支援 3.9)。接著打開終端機並執行:
pip install scrapy
再用以下指令確認安裝成功:
scrapy version
如果你用的是 Windows 或 Anaconda,建議設定虛擬環境,避免相依套件衝突。Scrapy 可在 Windows、macOS 和 Linux 上執行。
2. 建立新的 Scrapy 專案
我們先建立一個名為 amazonscraper 的新專案:
scrapy startproject amazonscraper
你會得到像這樣的資料夾結構:
amazonscraper/
├── scrapy.cfg
├── amazonscraper/
│ ├── __init__.py
│ ├── items.py
│ ├── pipelines.py
│ ├── middlewares.py
│ ├── settings.py
│ └── spiders/
這些檔案是做什麼的?
scrapy.cfg:專案設定檔(通常很少會碰到)items.py:定義你的資料模型(例如包含名稱、價格等欄位的 Product)pipelines.py:用來清理、驗證與匯出資料middlewares.py:進階功能(代理伺服器、自訂標頭)settings.py:調整 Scrapy 的行為(並行數、延遲等)spiders/:實際爬取邏輯所在的位置
如果你現在已經開始覺得有點眼花撩亂,也不用擔心。很多非程式背景的人都會在這一步開始冒冷汗。
建立 Python 爬蟲:使用 Scrapy 抓取 Amazon 產品資料
我們來看一個真實案例:抓取 Amazon 搜尋結果中的產品資料。(提醒一下:Amazon 的服務條款不允許爬取,而且他們對反機器人措施相當嚴格。這裡僅供教學用途!)
1. 建立 Spider
在 spiders/ 資料夾中,建立一個名為 amazon_spider.py 的檔案:
import scrapy
class AmazonSpider(scrapy.Spider):
name = "amazon_example"
allowed_domains = ["amazon.com"]
start_urls = ["https://www.amazon.com/s?k=smartphones"]
def parse(self, response):
products = response.xpath("//div[@data-component-type='s-search-result']")
for product in products:
yield {
'name': product.xpath(".//span[@class='a-size-medium a-color-base a-text-normal']/text()").get(),
'price': product.xpath(".//span[@class='a-price-whole']/text()").get(),
'rating': product.xpath(".//span[@aria-label]/text()").get()
}
next_page = response.xpath("//li[@class='a-last']/a/@href").get()
if next_page:
yield scrapy.Request(url=response.urljoin(next_page), callback=self.parse)
這段程式在做什麼?
- 我們從 Amazon 的「智慧型手機」搜尋結果頁開始。
- 對每個商品,我們用 XPath 選擇器擷取名稱、價格和評分。
- 我們再找「下一頁」連結,並告訴 Scrapy 繼續追蹤,接著抓取更多商品。
2. 執行你的 Spider
在專案根目錄中執行:
scrapy crawl amazon_example -o products.json
搞定——Scrapy 會一路爬過搜尋結果、追蹤分頁,並把資料存成 JSON 檔。
處理分頁與動態內容
Scrapy 內建追蹤連結與處理分頁的功能,是它的強項之一。不過,動態內容呢——也就是透過 JavaScript 載入資料的頁面?Scrapy 預設只能看到靜態 HTML。如果你要抓取由 JavaScript 載入的內容(例如無限捲動或彈出式評論),就需要搭配 Selenium 或 Splash 這類工具。那又是另一個大坑了。
使用 Scrapy Python 處理與匯出資料
一旦你抓到資料,通常接下來會想把它清理好,然後匯出到有用的地方。
- 管線(Pipelines): 在
pipelines.py裡,你可以寫 Python 類別來清理、驗證或增強資料(例如把價格轉成數字、刪掉不完整的列,甚至呼叫翻譯 API)。 - 匯出: Scrapy 可以透過
o參數直接匯出成 CSV、JSON 或 XML。若要做更進階的匯出(例如推送到 Google 試算表),你就得額外寫程式碼或使用第三方函式庫。
想做情緒分析或翻譯產品描述?你需要整合外部 API 或 Python 函式庫——Scrapy 本身沒有內建這些功能。
隱藏成本:Scrapy Python 對商務使用者的挑戰
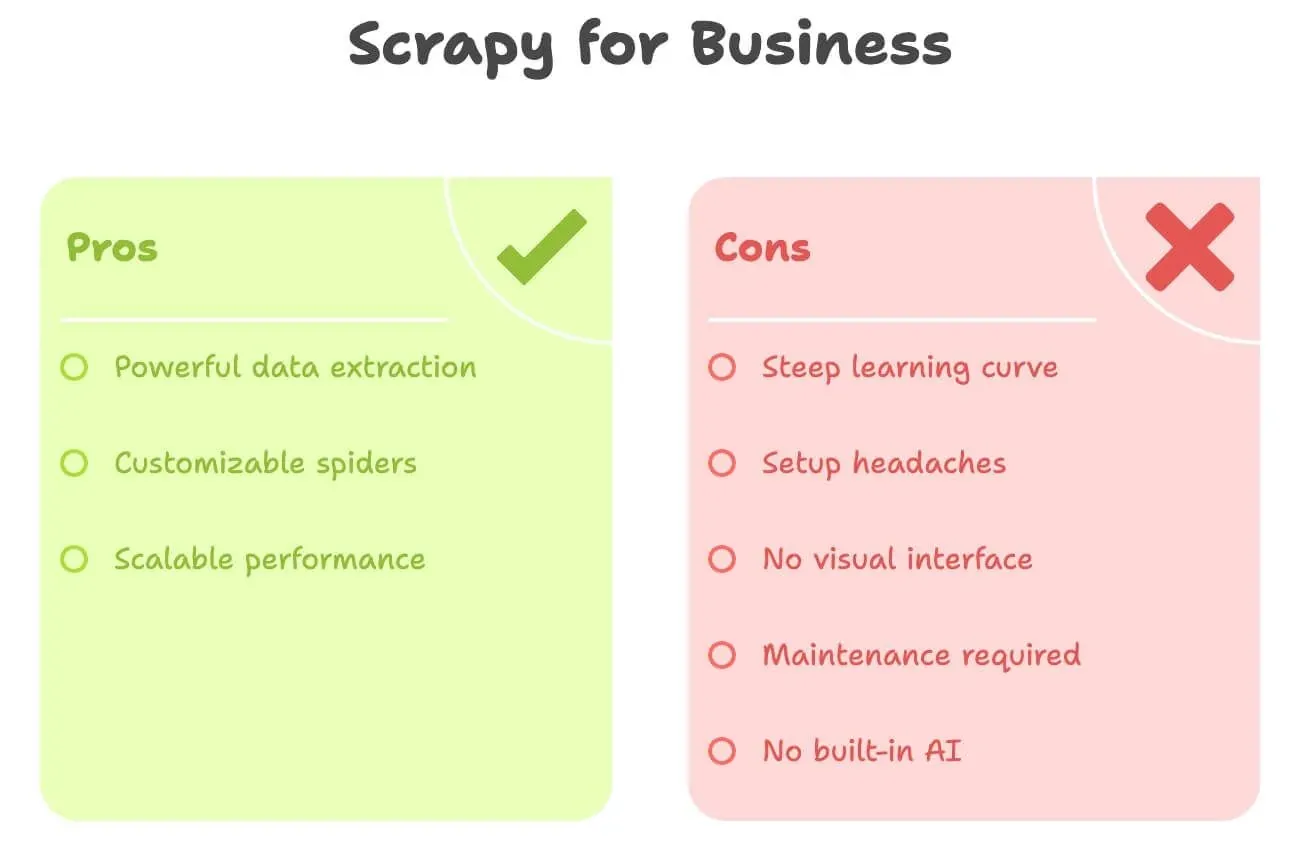
說真的:Scrapy 很強,但對非開發者來說,它並不算友善。以下是多數商務使用者最常卡關的地方:
- 學習曲線陡峭: 你需要懂 Python、HTML、XPath/CSS 選擇器,以及 Scrapy 的專案結構。要上手可能得花上幾天甚至幾週。
- 安裝麻煩: 安裝 Python、管理相依套件、排除錯誤都很費工,尤其在 Windows 上。
- 沒有視覺化介面: 一切都得寫程式。你不能直接點選頁面來挑資料。
- 維護成本: 網站一改版,你的 spider 就可能壞掉,而且修復責任都落在你身上。
- 沒有內建 AI: 想翻譯、摘要或做情緒分析?都得另外寫程式。
下面快速比較一下:
| 挑戰 | Scrapy(Python) | 商務使用者需求 |
|---|---|---|
| 需要寫程式 | 是 | 希望不用寫程式 |
| 設定時間 | 幾小時(或幾天) | 幾分鐘 |
| 維護成本 | 持續進行(網站變動) | 盡量最低 |
| 資料匯出 | CSV/JSON(需手動整合) | 直接匯出到 Excel/Sheets/Notion |
| AI 功能 | 沒有(需自行整合) | 內建翻譯/情緒分析 |
如果你是單打獨鬥的行銷人、業務或營運主管,Scrapy 可能會讓你覺得像是拿著火箭筒去打水球。
認識 Thunderbit:Scrapy Python 的免程式替代方案
這就是 Thunderbit 登場的地方。作為一個長年打造自動化工具的人,我可以很肯定地說:多數商務使用者並不是想寫程式,他們只是想要資料,而且要快。
Thunderbit 是一款以 Chrome 擴充功能形式提供的人工智慧網頁爬蟲。它專為非技術使用者設計,讓你可以:
- 幾個點擊就從任何網站抓資料
- 用自然語言描述你要的欄位(例如「產品名稱、價格、評分」)
- 自動處理分頁與子頁面
- 直接匯出到 Excel、Google 試算表、Airtable 或 Notion
- 即時翻譯、摘要或分析情緒
不用 Python,不用選擇器,也不用擔心維護。
如何用 AI 抓取任何網站 Get Started Free
Thunderbit 的設計目標,就是讓想要快速推進的商務使用者,把繁重工作交給 AI。
Thunderbit vs. Scrapy Python:並排比較
讓我們直接對照一下:
| 面向 | Scrapy(Python) | Thunderbit(AI 工具) |
|---|---|---|
| 所需技能 | Python、HTML、選擇器 | 不需要——點選與自然語言即可 |
| 設定時間 | 幾小時(安裝、寫程式、除錯) | 幾分鐘(安裝 Chrome 擴充功能、登入) |
| 資料結構化 | 手動(定義 items、pipelines) | AI 自動辨識欄位並建議資料欄 |
| 分頁/子頁面 | 需要寫程式 | 一鍵處理(AI 負責) |
| 翻譯 | 自訂程式碼或 API 整合 | 內建——只要切換「翻譯」即可 |
| 情緒分析 | 外部函式庫/API | 內建——新增「情緒」欄位即可 |
| 匯出選項 | CSV/JSON(手動匯入 Sheets/Excel) | 一鍵匯出到 Excel、Google 試算表、Airtable、Notion |
| 維護 | 手動(網站改版就要更新程式) | AI 會自動適應小幅網站變動 |
| 規模 | 最適合大型、持續性的專案 | 最適合快速任務、中等規模(數百到數千列) |
| 成本 | 免費(但耗費時間/開發資源) | 有免費方案+付費方案(每月 9 美元起,但能省下大量時間與麻煩) |
什麼時候該選 Scrapy Python,什麼時候該選 Thunderbit 來做網頁爬蟲?
我的判斷原則很簡單:
- 適合用 Scrapy,如果:
- 你是開發者,或團隊裡有開發者
- 你需要抓取數萬頁,或建立客製化、持續性的資料流程
- 網站結構非常複雜,或需要進階邏輯
- 你想完全掌控,而且不介意後續維護
- 適合用 Thunderbit,如果:
- 你不寫程式(或不想寫)
- 你需要快速拿到資料,用於一次性或重複性的商業任務
- 你希望內建翻譯、情緒分析或資料增強
- 你更重視速度與彈性,而不是極致客製化
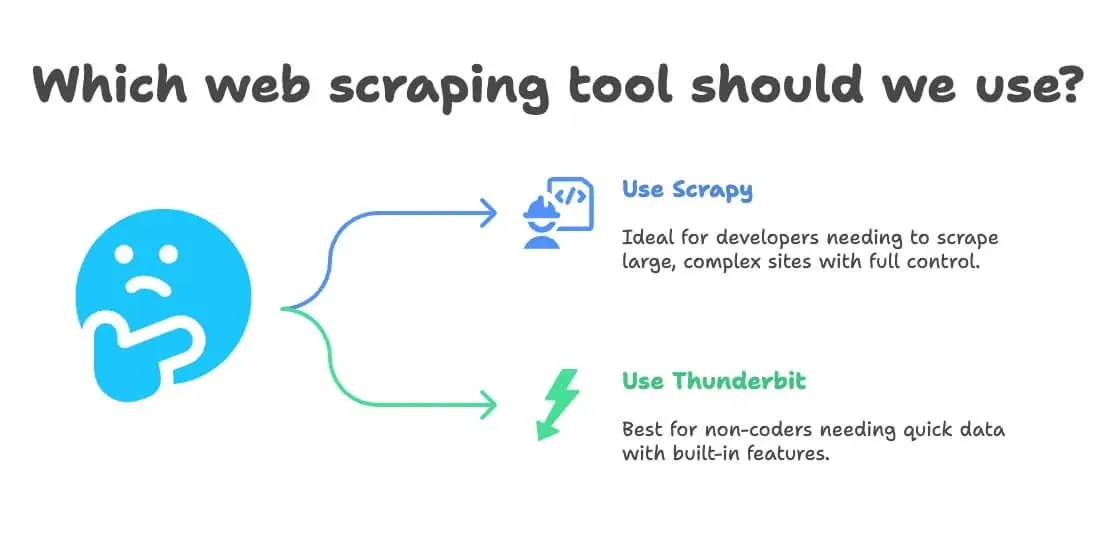
這裡有個快速決策流程:
- 你會寫 Python 嗎?
- 會 → Scrapy 或 Thunderbit(若想快速見效)
- 不會 → Thunderbit
- 你的專案是不是很大,而且會持續進行?
- 是 → Scrapy
- 否 → Thunderbit
- 你需要翻譯或情緒分析嗎?
- 需要 → Thunderbit
- 不需要 → 兩者皆可
一步一步來:用 Thunderbit 抓取 Amazon 產品資料(免程式)
我們把前面的 Amazon 範例重新做一次——這次用更簡單的方法。
1. 安裝 Thunderbit
- 下載 Thunderbit Chrome 擴充功能
- 註冊帳號(有免費方案)
2. 前往 Amazon 並搜尋你的產品
- 開啟 Amazon.com,搜尋「laptops」或任何你想抓取的產品
3. 在頁面上啟動 Thunderbit
- 點擊瀏覽器中的 Thunderbit 圖示
- 側邊面板會開啟,並辨識出 Amazon 頁面
4. 使用 AI 建議欄位
- 點擊 「AI 建議欄位」
- Thunderbit 的 AI 會掃描頁面,並建議像「產品名稱」、「價格」、「評分」、「評論數」這類欄位
- 你可以依需求新增或刪除欄位(想要「產品網址」或「Prime 資格」?直接輸入就行)
5. 啟用分頁與子頁面抓取
- 切換 分頁:Thunderbit 會自動點擊「下一頁」並抓完所有頁面
- 切換 子頁面抓取:Thunderbit 會逐一前往每個商品詳情頁,擷取額外資訊(例如描述或 ASIN 編號)
6. 執行抓取
- 點擊 抓取
- 看著 Thunderbit 一頁一頁即時收集資料
7. 翻譯與情緒分析(選用)
- 想翻譯產品描述?替該欄位開啟「翻譯」
- 想分析評論情緒?新增一個「情緒」欄位——Thunderbit 的 AI 會自動填入
8. 匯出資料
- 點擊 匯出
- 選擇 Excel、Google 試算表、Airtable 或 Notion
- 你的資料立刻可用——不用手動匯入,也不用處理 CSV
9. 設定定期抓取(選用)
- 設定排程(例如每天早上 8 點)
- Thunderbit 會自動執行抓取,並更新到你選擇的目的地
就這麼簡單。沒有程式碼,沒有選擇器,也沒有維護壓力。只有可直接用於商務的資料。
加碼技巧:讓你的網頁爬取專案發揮更多價值
不管你用的是 Scrapy、Thunderbit,還是其他工具,以下是我從實戰中學到的幾個最佳做法:
- 驗證資料: 一定要檢查是否有遺漏或異常值(例如 $0 的價格、空白名稱)
- 遵守規範: 檢查網站服務條款、尊重
robots.txt,不要讓伺服器負載過高 - 聰明自動化: 用排程維持資料新鮮度,但不要比需要的頻率更常抓取
- 善用免費工具: Thunderbit 內建免費的電子郵件、電話與圖片提取器,對開發名單或內容整理都很有幫助
- 為分析而整理: 直接匯出到 Sheets/Excel,方便快速篩選、樞紐分析與視覺化
想看更多技巧,可以造訪 Thunderbit 部落格 或他們的用 AI 抓取任何網站指南。
如何用 AI 將網站資料抓取到 Excel Get Started Free
想看更多技巧,可以造訪 Thunderbit 部落格 或他們的用 AI 抓取任何網站指南。
結論:讓網頁爬取更簡單——為你的團隊選對工具
結論很直接:Scrapy 對開發者來說是超強工具,但對大多數商務使用者而言,功能有些過頭了。 如果你熟悉 Python,而且需要建立客製化的大型爬蟲,Scrapy 會是很好的選擇。但如果你想更快上手、跳過程式碼,並取得內建翻譯與情緒分析的資料,Thunderbit 會更適合你。
我親眼看過 Thunderbit 為非技術團隊省下多少時間與挫折。你可以在幾分鐘內,從「我希望我有這些資料」變成「它已經在我的試算表裡了」——不是幾小時,也不是幾天。再加上 AI 建議欄位、子頁面抓取與一鍵匯出等功能,現在把網路轉成商業情報,從來沒有這麼簡單。
所以下次當你需要抓取產品資料、監控價格,或建立名單時,不妨問問自己:你想寫 Python,還是想要結果?試試 Thunderbit 的免費方案,親自看看網頁爬蟲可以有多簡單。
想深入了解嗎?歡迎查看 Thunderbit 官方網站、下載 Chrome 擴充功能,或到 Thunderbit 部落格 深入閱讀網頁爬取最佳實踐。
延伸閱讀:
免責聲明:請務必確保你的網頁爬取行為符合網站條款與當地法律。若有疑問,請諮詢法律顧問——沒有人想因為一份試算表就收到停止侵害通知,還被叫成那個「爬蟲」的人。
作者:Thunderbit 共同創辦人暨執行長 Shuai Guan。我在 SaaS、自動化與 AI 領域累積多年經驗——讓你不必重走這條路。
試用 AI 網頁爬蟲 Get Started Free




