是一款 AI 網頁爬蟲 Chrome 擴充功能,能幫商業使用者運用 AI 從網站擷取資料。核心矛盾在於:ScrapingBee 定價頁看起來很划算,但等你真的把它用在正式環境、開始跑大量任務後,credits 可能會以 5 倍到 75 倍的基礎費率快速消耗。這篇 scrapingbee 評測會從五個多數文章都略過的角度切入:大規模使用下的真實成本、選擇器式擷取與 AI 擷取的差異、非開發者的使用難度、擷取後的資料流程,以及 2026 年的可靠度基準。如果你正在替團隊評估 ScrapingBee,不管你是開發者、銷售營運負責人,還是創辦人,這篇分析都能幫你快速抓到重點。
ScrapingBee 是什麼?快速認識一下
ScrapingBee 是一個網頁爬蟲 API,負責處理代理輪替、JavaScript 渲染和 CAPTCHA 解決,讓開發者能從網站擷取資料,不必自行打造爬蟲基礎架構。你只要送出帶參數的 HTTP 請求,就能拿回 HTML(某些端點則會回傳 JSON)。它沒有可視化或點擊式介面可用來建立爬取任務。
它的核心功能包括:
- 輪替與高級代理(classic、premium、stealth、residential)
- 無頭瀏覽器渲染(完整 Chrome,且預設開啟)
- 自動繞過 CAPTCHA
- Google Search API(結構化 JSON:自然結果、廣告、地圖、知識圖譜、People Also Ask、圖片、新聞)
- 截圖擷取(標準、整頁,或指定 CSS 選擇器)
- 地理定位(透過 country_code 參數)
- CSS/XPath 擷取規則(以 JSON 聲明式設定,回傳結構化 JSON)
- Amazon、Walmart、YouTube 與 ChatGPT 專用 API
- AI 擷取(約於 2024–2025 加入):ai_query、ai_extract_rules、ai_selector 參數(每次請求 +5 credits)
- CLI 工具(約於 2025–2026 上線):批次處理、爬取、sitemap 解析、CSV 增強、排程 cron jobs、代理升級
ScrapingBee 成立於 2019 年、總部在法國,到了 2026 年初,營收大約成長到 ,客戶超過 2,500 家(包含 SAP、Zapier、Deloitte、Zillow)——而且全程靠 4–6 人小團隊自力成長。2025 年 6 月,,交易金額達八位數。品牌與領導團隊仍維持獨立,而客服團隊也已 ,以便提供更好的時區覆蓋。
有一點很重要:ScrapingBee 到現在仍然沒有原生的視覺化建置器、拖拉點選式 GUI,或內建的網頁儀表板排程器。排程功能必須依賴 CLI 工具、cron jobs,或第三方自動化工具(Zapier、Make、n8n)。他們所發布的「no-code」教學,其實是在講怎麼搭配 Make 和 Zapier,不是自家原生的免程式介面。
ScrapingBee 真正適合誰?
ScrapingBee 是為熟悉 Python 或 cURL 呼叫、懂得讀 HTML、也能建立 CSS/XPath 選擇器的開發者而設計的。文件內容偏程式導向,以 Python 和 cURL 範例為主。某位在 的評論者提到,他們「沒有提供 JavaScript 範例」,另一位則形容文件「很厚,讀完得花上一天到一週」。
但到了 2026 年,搜尋「ScrapingBee review」的人群已經不只後端工程師。還包括要建立名單的行銷經理、補強 CRM 資料的 sales ops 團隊、監控競品價格的電商營運,以及替團隊評估工具的創辦人。以下每個章節,我都會標註某項功能或限制究竟對開發者、商業使用者,還是兩者都重要。
ScrapingBee 價格方案一覽
以下是 ScrapingBee 目前的方案等級(截至 2026 年 4 月):
| 方案 | 每月價格 | 每月 API credits | 並行請求數 |
|---|---|---|---|
| Freelance | $49 | 250,000 | 10 |
| Startup | $99 | 1,000,000 | 50 |
| Business | $249 | 3,000,000 | 100 |
| Business+ | $599 | 8,000,000 | 200 |
| Enterprise | 聯絡業務 | 4,100 萬以上 | 自訂 |
年繳方案可享 。免費試用提供 1,000 API credits,不需信用卡。Google Search API 在收購後也已從每次呼叫 25 credits 。
乍看之下,這些 credit 數字很慷慨,但實際上並非如此。
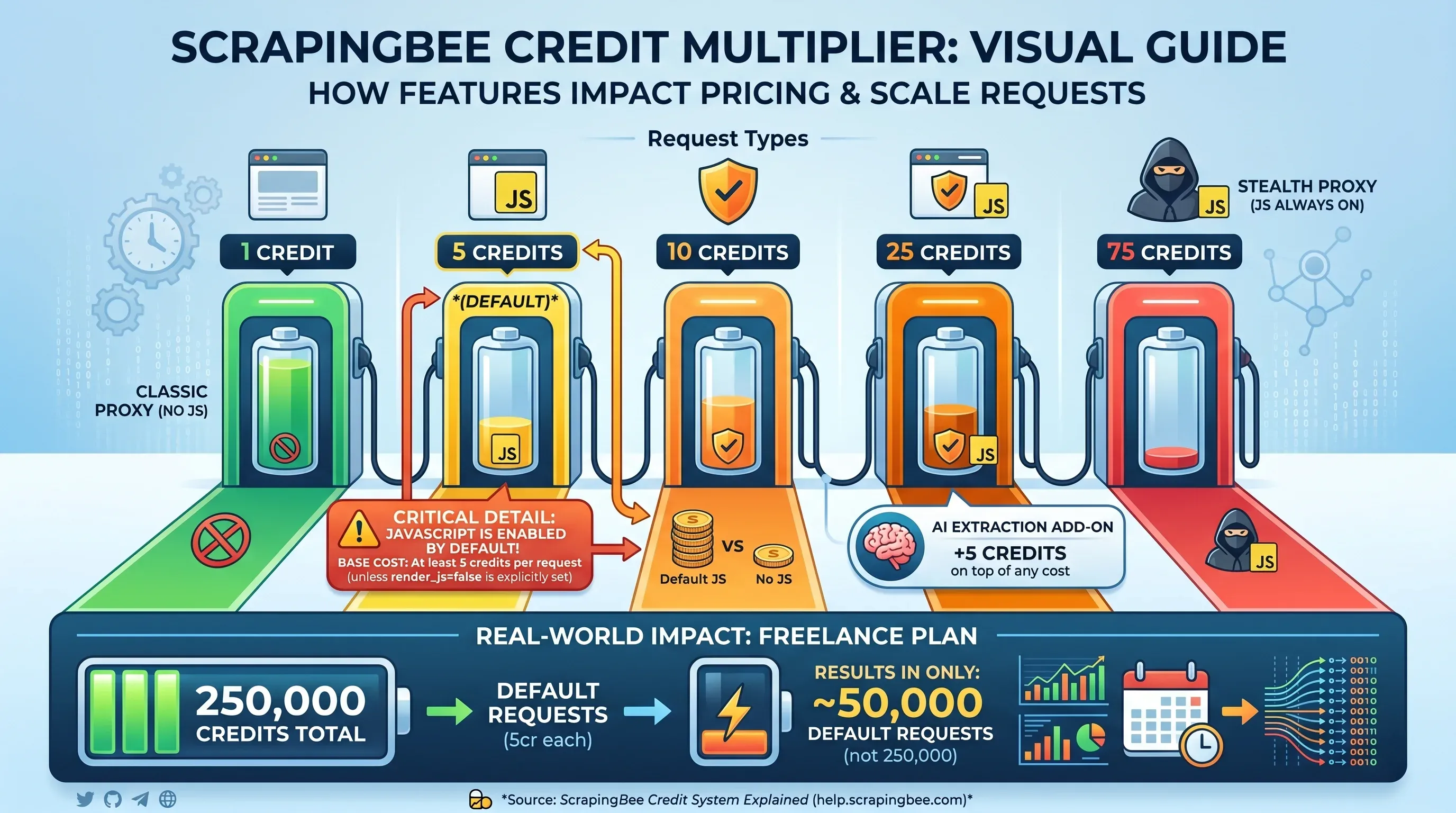
Credit 倍數表
這就是 ScrapingBee 定價變複雜的地方。標示的 credit 數量,不等於你能抓多少頁;實際消耗取決於你每次請求啟用了哪些功能:
| 請求類型 | 每次請求消耗 credits |
|---|---|
Classic proxy,不啟用 JS 渲染(render_js=false) | 1 credit |
| Classic proxy,啟用 JS 渲染(預設) | 5 credits |
| Premium proxy,不啟用 JS 渲染 | 10 credits |
| Premium proxy,啟用 JS 渲染 | 25 credits |
| Stealth proxy(JS 永遠開啟) | 75 credits |
| AI 擷取加購 | 在基礎費用上 +5 credits |
關鍵細節: JavaScript 渲染是 的。只要你沒有明確設定 render_js=false,每次請求至少都要 5 credits。也就是說,Freelance 方案的 250,000 credits,實際上只夠 50,000 次預設請求,不是 250,000 次。
沒人會告訴你的隱藏 Credit 算法
以下是 ScrapingBee 在不同情境、不同方案下,抓取 10,000 頁時的實際成本:
| 情境 | 所需 credits | Freelance ($49/25萬) | Startup ($99/100萬) | Business ($249/300萬) |
|---|---|---|---|---|
| 10K 頁面(靜態 HTML,1 cr) | 10,000 | ✅ 足夠($0.20/1K) | ✅ 足夠($0.10/1K) | ✅ 足夠($0.08/1K) |
| 10K 頁面(JS 渲染,5 cr) | 50,000 | ✅ 足夠($0.98/1K) | ✅ 足夠($0.50/1K) | ✅ 足夠($0.42/1K) |
| 10K 頁面(premium proxy + JS,25 cr) | 250,000 | ⚠️ 剛好到上限($4.90/1K) | ✅ 足夠($2.48/1K) | ✅ 足夠($2.08/1K) |
| 10K 頁面(stealth proxy,75 cr) | 750,000 | ❌ 遠超上限 | ✅ 勉強可用($7.43/1K) | ✅ 足夠($6.23/1K) |
同樣是 10,000 頁,成本可能從 每千頁 $0.20 到 $7.43 不等,完全取決於代理與渲染設定。而且你通常得先試了之後,才知道自己需要哪種配置。
預算情境:每月 10,000 頁的名單開發
某個銷售團隊每月抓取 10,000 個公司頁面來做 lead generation。現在多數 B2B 網站都用 React 或 Vue,所以必須開啟 JS 渲染:
- 所需 credits: 50,000(10K × 5 credits)
- Freelance 方案($49): 足夠,還剩 20 萬 credits
- 但如果目標網站需要 premium proxies: 250,000 credits —— 正好是一個 Freelance 方案的配額,沒有任何緩衝
- 如果還需要 stealth proxies: 750,000 credits —— 必須升到 Startup 方案,每月 $99
預算情境:每月 100,000 頁的電商價格監控
某個電商團隊要監控競品網站上的 100,000 個商品頁面:
| 設定 | 所需 credits | 需要的方案 | 每月成本 |
|---|---|---|---|
| 靜態 HTML(1 cr) | 100,000 | Freelance | $49 |
| JS 渲染(5 cr) | 500,000 | Startup | $99 |
| Premium proxy + JS(25 cr) | 2,500,000 | Business | $249 |
| Stealth proxy(75 cr) | 7,500,000 | Business+ | $599 |
同樣的工作,月費可從 $49 到 $599 不等。這不是四捨五入的誤差,而是因設定不同而產生的 12 倍成本差距。
「$49 的入門價,是爬蟲 API 市場最具誤導性的數字。」—
「當你使用 JavaScript 渲染或進階功能時,credits 消耗得非常快,讓小型專案或爬取量不穩定的團隊更難合理化這筆支出。」— Nick S,經理,電腦軟體業,
而且沒用完的 credits 不會 。
ScrapingBee 的成本和競品怎麼比?

以下以中階方案做公平比較:
| 情境(每 1K 頁) | ScrapingBee ($99/100萬) | ScraperAPI ($149/100萬) | Scrapfly ($100/100萬) |
|---|---|---|---|
| 靜態 HTML | $0.10 | $0.15 | $0.10 |
| JS 渲染頁面 | $0.50 | $1.64 | $0.60 |
| Premium + JS | $2.48 | $3.73 | $3.00 |
| Stealth/超高級 + JS | $7.43 | $11.18 | N/A |
在靜態頁與 JS 渲染頁面上,ScrapingBee 通常是最便宜或並列最便宜。 一直是最貴的——它的 JS 渲染要加 +10 credits,而 ScrapingBee 和 Scrapfly 都是 +5 credits。不過 的獨立測試,當把真實網站複雜度算進去後,結果就不同了:
| 服務 | 平均每 1K 請求成本 | 成功率 | 平均回應時間 |
|---|---|---|---|
| Scrape.do | $0.80 | 98.19% | 4.7s |
| ScrapingBee | $3.90 | 92.69% | 11.7s |
| Scrapfly | $4.11 | — | — |
| ZenRows | $4.48 | 92.64% | 10.0s |
| ScraperAPI | $8.49 | 92.70% | 15.7s |
Thunderbit 的 Credit 模型:完全不同的思路
採用的是更簡單的定價方式:1 credit = 1 筆輸出資料列,不會因 JS 渲染、代理類型或目標網域而乘上不同倍數。子頁面爬取則是每列 2 credits。
| 方案 | 每月價格 | Credits | 每列成本 |
|---|---|---|---|
| Free | $0 | 每月 6 頁 | 免費 |
| Starter | $15 | 500 | $0.030 |
| Pro 1 | $38 | 3,000 | $0.013 |
| Pro 2 | $75 | 6,000 | $0.013 |
| Pro 3 | $125 | 10,000 | $0.013 |
| Pro 4 | $249 | 20,000 | $0.012 |
如果你用 Thunderbit 抓取 10,000 筆來自高 JS 依賴電商網站的商品清單,無論這些網站需不需要 JavaScript 渲染、premium proxies 或反機器人繞過,你都只要付 每月 $125。但用 ScrapingBee 的話,同樣工作可能從 $49 跳到 $599,完全看設定。預算可預測性,真的很重要。
CSS 選擇器 vs. AI 擷取:你應該知道的維護成本
大多數 ScrapingBee 評測都會直接略過這一點。對於打算在數月或數年內持續大規模爬取的人來說,這其實可能是最重要的考量。
ScrapingBee 使用 CSS/XPath 選擇器 從 HTML 擷取資料。你要先以 JSON 物件定義擷取規則,再由 ScrapingBee 回傳符合條件的資料。這在一開始通常很順利,問題是後續會發生什麼。
選擇器失效問題
當目標網站改版——例如 class 名稱、DOM 結構、框架版本變動——你的 CSS 選擇器就可能失效。在成熟的爬蟲系統中,如果同時運行 2,500+ 個任務,研究顯示每週約有 ,也就是每週得修 30–35 次,才能維持抽取器正常運作。對於抓取 50 個網站的組織來說,年度維護工時約 850–1,300 小時,以完整人力成本估算,費用高達 $64,000–$156,000。
很多團隊都會低估這件事。初估通常只抓每月 10–15 小時,但實際情況往往高出 (每月 40–90 小時)。一個安靜失敗——也就是選擇器壞了卻持續回傳空資料、還沒人收到警報——估計會造成 $38,000–$57,000 的損失,包含業績流失、排名回復與人力時間。
常見原因包括:框架更新時重新命名 CSS class、目標外層新增 container、React/Vue/Angular 版本升級導致 DOM 重組、A/B 測試產生動態 class 名稱,以及反爬蟲混淆機制。
AI 擷取可將維護工作量降低 60–80%
2025 年一項 DataRobot 研究發現,AI 驅動的爬蟲在網站改版後,相較傳統選擇器式爬蟲可減少 。時間分配比例幾乎直接翻轉:
| 指標 | 傳統(CSS 選擇器) | AI 驅動 |
|---|---|---|
| 改版後維護量 | 基準 | 減少 70% |
| 時間分配(建置:維護) | 20%:80% | 5%:95%(依數據) |
| 整體維護降低 | 基準 | 降低 60–80% |
| JS 密集頁面的速度 | 基準 | 快 30–40% |
建置時間:寫選擇器 vs. AI 建議欄位
ScrapingBee 的建置流程: 檢查頁面原始碼 → 找出 CSS 選擇器 → 用 JSON 寫擷取規則 → 測試與除錯 → 處理頁面變化的例外狀況 → 持續監控是否失效 → 網站更新後再修正壞掉的選擇器。
Thunderbit 的建置流程: 在 Chrome 打開頁面 → 點一下「AI Suggest Fields」→ AI 讀取頁面並提出適合的欄位與資料類型 → 點「Scrape」。不用寫選擇器,也不用看原始碼。Thunderbit 的 AI 由多個基礎模型(ChatGPT、Gemini、Claude、DeepSeek R1)驅動,能像人一樣視覺化讀取網頁內容。
Thunderbit 的 又多了一層彈性:每個欄位都能加上自訂 AI 指令,在擷取時直接轉換資料——像是格式化日期、翻譯文字、分類商品、拆分姓名、標準化電話號碼。這等於省掉 ScrapingBee 使用者還得自己另外做的後處理步驟。
結構化輸出:原始 HTML vs. 可直接使用的資料列
| 面向 | ScrapingBee(選擇器式) | Thunderbit(AI 驅動) | |---|---|---|--- | 預設輸出 | 原始 HTML | 具結構的資料列與型別欄位 | | 結構化擷取 | 需要自己寫 CSS/XPath 規則,或使用 AI 加購(+5 credits) | AI 自動辨識欄位 | | 支援的資料類型 | 文字(需自行解析 HTML) | 文字、數字、日期、URL、Email、電話、圖片 | | 對版面變動的韌性 | ⚠️ 需要手動更新選擇器 | ✅ AI 每次都會重新讀頁面 | | 所需技術能力 | Python/cURL、CSS 選擇器、HTML 理解 | 幾乎不需要——Chrome 擴充功能兩步完成 | | 長期維護 | 持續進行中(每週 1–2% 失效率) | 很少(AI 會自動適應) |
ScrapingBee 也新增了 AI 擷取功能(ai_query、ai_extract_rules),部分緩解了選擇器維護問題。但這些功能會在基礎成本上每次再加 +5 credits,而且本質上它仍是以 API 為核心,沒有視覺化介面。
ScrapingBee 對非開發者友善嗎?老實講,沒有那麼友善
ScrapingBee 不適合非技術使用者。它就是一個 API。你得寫程式才能用。如果你是行銷經理或 sales ops 負責人,看到這裡其實就已經很清楚了。
非技術使用者使用 ScrapingBee 時,實際上會遇到以下步驟:
- 寫 API 呼叫,可用 Python、cURL 或其他語言
- 理解 HTTP 參數,像
render_js=true、premium_proxy=true、country_code=us - 解析原始 HTML 回應,通常還要搭配 BeautifulSoup 之類的函式庫
- 撰寫 CSS 選擇器,擷取特定欄位資料
- 處理分頁,自己寫 crawl 邏輯(ScrapingBee 只負責單頁請求)
- 建立資料管線,負責清理、結構化與儲存擷取結果
沒有拖拉式建置器,沒有點選式介面,也沒有你正在抓什麼的視覺預覽。
「有學習曲線,而且文件很厚,讀完得花上一天到一週。」— Arvind K,業主,金融服務業,
「他們的系統很講究,要花一段時間才能學會他們的代碼和結構。」—
開發者很喜歡這種設計。有評論者形容它「完全是 API 導向:非常現代、優雅,而且就是能用」。但開發者眼中的「好上手」,和想不寫程式就建立名單的人眼中的「好上手」,完全是兩回事。
什麼時候 no-code 方案更合理?
提供的是完全不同的體驗:
- 在 Chrome 打開網頁,並確認已安裝擴充功能
- 點「AI Suggest Fields」——AI 會掃描頁面,提出欄位(Product Name、Price、Rating、URL 等)以及適當的資料類型
- 檢視並自訂——可新增、刪除、重新命名欄位,也能加 Field AI Prompts 做轉換
- 點「Scrape」——資料會被擷取成結構化資料列
- 匯出——一鍵輸出到 Google Sheets、Airtable、Notion、Excel、CSV 或 JSON(所有匯出都免費)
不用 API、不用選擇器、也不用寫程式。Thunderbit 截至 2026 年 4 月支援 。
對於常見網站,Thunderbit 也提供 ——已預先建立並持續維護的 Amazon、Zillow、Shopify、LinkedIn、Google Maps、Instagram、eBay、Apollo 等範本。你甚至不需要等 AI 建議欄位,模板就已經準備好了。
此外,Thunderbit 還內建幾個 ,不需要任何方案:email extractor、電話號碼提取器和圖片提取器,對只想快速抓資料的銷售與行銷團隊特別方便。
決策框架:誰適合用哪一款
| 如果你是… | 最適合 |
|---|---|
| 熟悉 API 與 HTML 解析的開發者 | ScrapingBee 或 ScraperAPI |
| 想拿結構化資料、但不想自己寫選擇器的技術使用者 | Thunderbit API(Extract 端點) |
| 沒有寫程式能力的商業使用者(銷售、行銷、電商營運) | Thunderbit Chrome 擴充功能 |
| 需要排程監控、又不想處理 DevOps 的團隊 | Thunderbit Scheduled Scraper(自然語言排程) |
| 要做 LLM/RAG 管線,且需要乾淨 markdown 的團隊 | Thunderbit Distill API 或 Firecrawl |
| 重視預算可預測性、不想要 credit 倍數的人 | Thunderbit(1 credit = 1 列) |
擷取完之後,資料到底去哪了?
爬取只完成了一半。另一半——把資料送到真正有用的地方——才是大多數 ScrapingBee 評測會沉默的部分。
ScrapingBee:輸出原始 HTML,管線自己做
ScrapingBee 預設回傳的是原始 HTML。接下來你得自己:
- 用 BeautifulSoup 或 lxml 解析 HTML
- 去除導覽列、頁尾、腳本和樣式(這些通常佔 )
- 擷取指定欄位
- 轉成結構化格式
- 處理分頁與錯誤狀態
- 儲存與分發資料
「ScrapingBee 回傳的是原始 HTML。AI agent 需要的是乾淨 markdown、語意搜尋和 webhooks。」—
ScrapingBee 確實提供 return_page_markdown=true 和 return_page_text=true 這類可選替代輸出,而 Google Search API 也會回傳結構化 JSON。不過預設流程,以及一般通用爬取體驗,依然是你得自己處理的原始 HTML。
使用者通常還得再搭配其他工具:BeautifulSoup/lxml 做解析、Pandas 做資料清理、cron/Airflow 做排程、自訂 crawl 邏輯處理多頁爬取,還有 。從「我抓到了」到「我能用了」,中間還隔著一整段工程。
Thunderbit:結構化輸出,加上內建匯出
Thunderbit 會直接回傳具結構的資料列與明確資料型別(文字、數字、日期、URL、email、電話、圖片),可直接匯出。所有方案都能免費匯出:
| 匯出目的地 | 費用 |
|---|---|
| Excel (.xlsx) | 免費 |
| Google Sheets | 免費(直接整合) |
| Airtable | 免費(直接整合) |
| Notion | 免費(直接整合) |
| CSV | 免費 |
| JSON | 免費 |
對於已經把 Google Sheets 或 Airtable 當作 CRM 或營運中樞的團隊來說,這等於直接少了一整層工程。匯出到 Notion 或 Airtable 時,圖片也會上傳到圖片庫,讓使用者可以直接在內容中看到,這個小細節在實務上非常加分。
ScrapingBee 的整合生態系
ScrapingBee 也提供第三方整合:(8,000+ 應用整合)、(3,000+ 應用)、n8n 和 Microsoft Power Automate。這些工具可以把原始 HTML 接到你要用的目的地工具,但同時也會增加成本、複雜度,以及新的故障點。
對開發者來說:Thunderbit 的 Open API
如果你是想做程式化資料管線的人,Thunderbit 也提供 Open API,包含兩個關鍵端點:
- Distill 端點——把頁面轉成乾淨 Markdown,非常適合 LLM/RAG 管線(每次呼叫 1 credit)
- Extract 端點——回傳符合使用者自訂 schema 的結構化 JSON(每次呼叫 20 credits)
- 批次處理——每次請求最多可處理 100 個 URL
這代表 Thunderbit 同時服務 no-code 使用者(Chrome 擴充功能)和開發者(Open API),而且都是同一套 AI 引擎。不要只問「能不能抓」,更該問「資料最後會去哪裡?」
2026 可靠度檢查:ScrapingBee 在正式環境撐得住嗎?
較早期的 Reddit 討論串(2021–2023)有不少對 ScrapingBee 可靠度的抱怨。到了 2026 年,這些問題還存在嗎?我整理了六項獨立基準測試,結果是混合的——而且有時甚至互相矛盾。
Scrapeway 雙週基準測試(2026 年 4 月)
整體:——在 9 個服務中排第 7。
| 網站 | 成功率 |
|---|---|
| Amazon | 48% |
| 41% | |
| Indeed | 38% |
| Etsy | 21% |
| Booking | 17% |
| Realtor | 0% |
| StockX | 0% |
| Twitter/X | 0% |
| Zillow | 0% |
| Walmart | 0% |
| 0% |
Scrapingdog 直接對比測試(2025)
| 網站 | ScrapingBee | Scrapingdog | ScraperAPI |
|---|---|---|---|
| Amazon | 100% | 100% | 100% |
| Glassdoor | 0% | 100% | 100% |
| eBay | 100% | 100% | 100% |
| Walmart | 40% | 100% | 100% |
| 90% | 100% | 80% |
Proxyway 基準測試(2025 年 12 月)
- 每秒 10 次請求時成功率 72.98%——在高負載下下降 12 個百分點
- 平均回應時間 25.46 秒——是該組測試中最慢的
Scrape.do 基準測試(2025–2026)
- 單一網站表現不錯:Amazon 99.11%、Indeed 99.29%、GitHub 100%、X/Twitter 99.6%
- 但在 Capterra 上很弱:成功率只有 59%,回應時間達 36 秒
整體趨勢
數據顯示出很明確的模式:
- ScrapingBee 在主流、保護程度中等的網站表現不錯——Amazon、eBay、GitHub、Indeed 經常都有 90–100% 成功率
- ScrapingBee 在高保護網站上會完全失敗——LinkedIn、Zillow、Realtor.com、StockX、Twitter 在多項測試中都出現 0%
- 在高負載下效能會明顯下降——每秒 2 次請求時 84%,到每秒 10 次請求時掉到 73%
- 基準測試結果因方法不同而差異極大——從 33.3%(Scrapeway,網站類型廣泛)到 92.69%(Scrape.do,中等難度目標)都有
ScrapingBee 的 (137 則評論)是一個正面訊號,但高分不一定代表它在長期、大規模正式環境中的可靠度同樣出色。真正換掉它的使用者,常提到的是失敗率提高和成本上升,而不是一開始不會用。
「非常正面。ScrapingBee 穩定、可預測,而且很容易整合到正式環境。」— 已驗證評論者,CEO,
ScrapingBee 表現出「不一致的可靠度」,尤其是「Glassdoor 成功率 0%」以及「」。
AI 爬取如何以不同方式處理可靠度
Thunderbit 的 AI 會即時讀取渲染後的頁面,每次工作階段都會自動適應反機器人機制與版面變化。兩種爬取模式分別對應不同的可靠度需求:
- Cloud scraping——在 Thunderbit 雲端伺服器上執行,一次可處理最多 50 頁,特別適合 Amazon、Zillow、Shopify 這類大型公開抓取任務
- Browser scraping——在使用者本機的 Chrome 瀏覽器執行,使用使用者自己的登入狀態;非常適合 LinkedIn、私人儀表板、SaaS 平台這類 API 工具(像 ScrapingBee)無法透過驗證讀取內容的網站
Thunderbit 也針對熱門網站提供 ,這些範本已預先建立並持續維護,即使網站結構改變也能繼續運作。對於 ScrapingBee 在多項測試中顯示 0% 成功率的網站(如 LinkedIn、Zillow),Thunderbit 的 browser scraping 模式——使用你自己的登入狀態——本質上就是完全不同的做法。
ScrapingBee vs. 主要替代方案:並排比較
| 面向 | ScrapingBee | Thunderbit | ScraperAPI | Scrapfly |
|---|---|---|---|---|
| 類型 | 只有 API | Chrome 擴充功能 + API | 只有 API | 只有 API |
| 起始價格 | $49/月 | 免費($0) | $49/月 | $30/月 |
| Credit 模型 | 倍數制(1×–75×) | 1 credit = 1 列(無倍數) | 倍數制(1×–75×) | 倍數制(1×–30×) |
| AI 擷取 | 有(每次請求 +5 credits) | 內建(AI Suggest Fields) | 無原生 AI | 有 |
| No-code 選項 | 沒有(僅 API) | 有(Chrome 擴充功能) | 沒有(僅 API) | 沒有(僅 API) |
| 結構化輸出 | 需 CSS 規則或 AI 加購 | 預設提供(型別欄位) | 特定網站有結構化端點 | 視情況而定 |
| 匯出目的地 | 原始 HTML/JSON(自己做) | Excel、Sheets、Airtable、Notion、CSV、JSON(全免費) | 原始 HTML/JSON | 原始 HTML/JSON |
| 子頁面爬取 | 手動(自己寫 crawl 邏輯) | 內建(每列 2 credits) | 手動 | 手動 |
| 排程爬取 | 只有 CLI(沒有儀表板排程器) | 內建(自然語言) | 沒有內建 | 沒有內建 |
| 免費方案 | 1,000 credits 試用 | 每月 6 頁,永久免費 | 5,000 credits(7 天試用) | 1,000 credits |
| JS 渲染預設 | 開啟(成本 5×) | 內建(不加價) | 關閉 | 關閉 |
| 學習曲線 | 高(API + 選擇器) | 低(兩步完成) | 高(API + 選擇器) | 高(API) |
| 最適合 | 想要代理控制的開發者 | 商業使用者 + 開發者 | 想要結構化端點的開發者 | 想要 ASP 繞過的開發者 |
| Capterra 評分 | 4.9/5(137 則評論) | — | 4.6/5(62 則評論) | 4.9/5(221 則評論) |
ScrapingBee vs. Thunderbit:關鍵差異
最大的差異,其實可歸結為架構與受眾:
- 只有 API vs. Chrome 擴充功能 + API: ScrapingBee 每一次互動都要寫程式。Thunderbit 則同時提供給 no-code 使用者的 與給開發者的 Open API——同一套 AI 引擎,兩種介面。
- 選擇器式 vs. AI 驅動擷取: ScrapingBee 要你自己撰寫與維護 CSS/XPath 選擇器。Thunderbit 的 AI 會自動建議欄位,網站改版時也能自動適應。
- 原始 HTML vs. 可直接使用的結構化資料列: ScrapingBee 回傳的是要你自行解析的 HTML。Thunderbit 則回傳帶型別、已標記好的資料列,你可以一鍵 。
- 子頁面爬取: Thunderbit 會自動拜訪每個詳細頁並補強主表,內建完成,不必自己寫 crawl 邏輯。ScrapingBee 則要你自己處理。
- 即時模板: Thunderbit 已經為熱門網站(Amazon、Zillow、Shopify、LinkedIn、Google Maps、eBay)準備好可直接使用的模板。ScrapingBee 雖然有 Amazon 和 Walmart 的專用 API,但你仍得自己寫程式去使用。
其他值得注意的替代方案
- —— 每 1K 請求成本最低,獨立測試為 $0.80,成功率 98.19%;起價 $29/月
- Apify —— 以 actor 為核心的平台,G2 有 415+ 則評論(4.7/5),但「Pricing Issues」是第一大抱怨
- —— AI/LLM 原生,回傳 markdown,相較原始 HTML 可少 67% token;開源核心;起價 $16/月
- —— 企業級方案,擁有 7,200 萬以上 IP;起價 $499/月;採固定費率定價
- ZenRows —— 5,500 萬 residential IP,內建 Amazon/Walmart/Zillow 範本;起價 $69/月
哪一款爬蟲工具最適合你的團隊?
依情境給你直接建議:
- 如果你是開發者,正在打造自訂爬蟲管線,而且想要細緻的代理控制 → ScrapingBee 或 ScraperAPI。你會拿到更細的 HTTP 參數、代理類型選擇,以及完整的渲染控制;只是要把 credit 倍數成本算進去。
- 如果你是銷售或行銷團隊,想從網站拿到名單,卻不想寫程式 → 。兩步拿到結構化資料,一步匯出到 Google Sheets。沒有 API、沒有選擇器、也不用解析 HTML。
- 如果你需要快速取得熱門網站的結構化資料 → Thunderbit 即時範本。Amazon、Zillow、Shopify、LinkedIn——都已預先建立並持續維護,不用再做 AI 設定。
- 如果你要定期監控價格或庫存,而且不想碰 DevOps → Thunderbit Scheduled Scraper。直接用自然語言描述間隔(例如「每週一早上 9 點」),讓它自動執行。
- 如果你在打造 LLM/RAG 管線,且需要大規模乾淨 Markdown → Thunderbit Distill API 或 Firecrawl。兩者都能回傳適合 AI 消費的 markdown。
- 如果你重視預算可預測性,不想要 credit 倍數 → Thunderbit。1 credit = 1 列,不論 JS 渲染或代理類型。
總持有成本不只是 API 價格而已。它還包含建置時間 + 維護工時 + 解析工程 + 資料匯出流程。ScrapingBee 的標價確實有競爭力,但完整成本圖景就不是那麼漂亮了。
這篇 ScrapingBee 評測的重點結論
有五個值得記住的發現:
- Credit 成本在大規模使用時會快速倍增。 $49 的入門價,在需要 JS 渲染與 premium proxies 時,很容易變成 $599 以上。Thunderbit 的固定 1 credit per row 模型,消除了這種不確定性。
- CSS 選擇器會帶來持續的維護成本,而 AI 擷取可以避免。 使用 AI 驅動工具,維護工作預期可減少 ,網站更新時也不會因選擇器壞掉而中斷。
- 非開發者在 ScrapingBee 上會面臨明顯學習門檻。 它是 API-only 工具,需要寫程式、檢查 HTML,還要自己建立選擇器。商業使用者應該考慮 no-code 替代方案。
- 資料匯出需要自建工程。 ScrapingBee 預設回傳原始 HTML;管線得自己搭。Thunderbit 則能免費把結構化資料匯出到 。
- 可靠度在某些網站很好,但在另一些網站就不穩定。 ScrapingBee 在 Amazon 和 eBay 表現不錯,但在 LinkedIn、Zillow 和其他幾個高防護網站上會出現 0%。
ScrapingBee 對於想要由代理管理 HTTP 存取、並保有細緻控制權的開發者來說,仍然是個不錯的工具。但 2026 年的網頁爬蟲市場,明顯正往 AI 驅動、no-code 工具移動——而 正是為這個轉變而設計。你可以先試試免費方案(每月 6 頁免費,或搭配免費試用取得更多),親自感受差異。
常見問題
ScrapingBee 在 2026 年還值得用嗎?
要看你的技術能力和使用規模。對於抓取靜態頁、量體中等的開發者來說,ScrapingBee 提供的是文件完善、支援回應也不錯的 API,而且有 。但如果你是商業使用者、需要大規模爬取,或希望不用寫程式就拿到結構化資料,那麼像 Thunderbit 這類 AI 驅動替代方案,價值更高,總持有成本也低得多。
ScrapingBee 可以不用寫程式嗎?
不行。ScrapingBee 是 API-only 工具,必須寫程式(Python、cURL 或類似方式)並理解 HTTP 參數。它沒有用來建立爬取任務的視覺化介面。非技術使用者可以考慮 no-code 選項,例如 ,不用寫任何程式也能抓資料並匯出。
ScrapingBee 每頁真正要花多少錢?
這取決於你啟用哪些功能。靜態 HTML 頁面消耗 1 credit。JS 渲染頁面(預設)消耗 。premium-proxy + JS 頁面消耗 25 credits。stealth-proxy 頁面消耗 75 credits。AI 擷取另外再加 +5 credits。若使用 Freelance 方案($49/25萬 credits),靜態頁面約是每 1,000 頁 $0.20,stealth-proxy 頁面則約每 1,000 頁 $14.70。上方的詳細成本表有完整拆解。
2026 年最好的 ScrapingBee 替代方案有哪些?
主要替代方案包括 (AI 驅動、no-code Chrome 擴充功能 + API,1 credit = 1 列)、(給開發者的 API,並針對特定網站提供結構化端點)、(擅長反機器人繞過的開發者 API)、(獨立測試中每次請求成本最低)、以及 (AI/LLM 原生,回傳乾淨 markdown)。每款工具都有不同的甜蜜點——Thunderbit 適合商業使用者與預算可預測性,ScraperAPI 和 Scrapfly 適合想控代理的開發者,Firecrawl 則適合 LLM 管線。
ScrapingBee 能抓 JavaScript 很重的網站嗎?
可以,但使用 rotating proxy 會是基礎 credits 的 5 倍,premium proxy 則是 25 倍。JavaScript 渲染本來就 ,所以除非你明確關掉,不然你本來就在付 5 倍費率。Thunderbit 會自動處理 JS 渲染,而且不會乘上 credit 倍數——不管頁面怎麼建構,都是 1 credit per row。
延伸閱讀