

網路早就不是以前那個樣子了。現在你打開的幾乎每個網站,背後都是 JavaScript 在驅動,內容也會即時載入——像是無限捲動、彈出視窗,還有那些得點一下、兩下才會露出資訊的儀表板。事實上,現在高達 98.7% 的網站都使用 JavaScript,這也代表只會讀取靜態 HTML 的老派爬蟲工具,往往會漏掉一大堆有價值的資料。如果你曾經試著從現代電商網站抓商品價格,或從互動地圖擷取房地產列表,就會明白那種挫折:你要的資料,根本不在原始碼裡。
這時候,Selenium 就派上用場了。作為一個花了多年在做自動化工具的人(沒錯,也爬過不少網站),我可以很肯定地說:對任何需要即時、動態資料的人來說,學會 Selenium 幾乎就像多了一項超能力。在這篇實作導向的 Selenium 網頁爬蟲教學中,我會帶你一步步走過關鍵流程——從環境設定到自動化——也會示範如何把 Selenium 和 Thunderbit 搭配使用,產出結構化、可直接匯出的資料。不管您是商業分析師、業務專業人士,還是單純好奇的 Python 使用者,都能帶著實用技能和幾個笑點離開(畢竟,調試 XPath 選擇器這件事,真的很磨人)。
什麼是 Selenium?為什麼要用它來做網頁爬蟲?
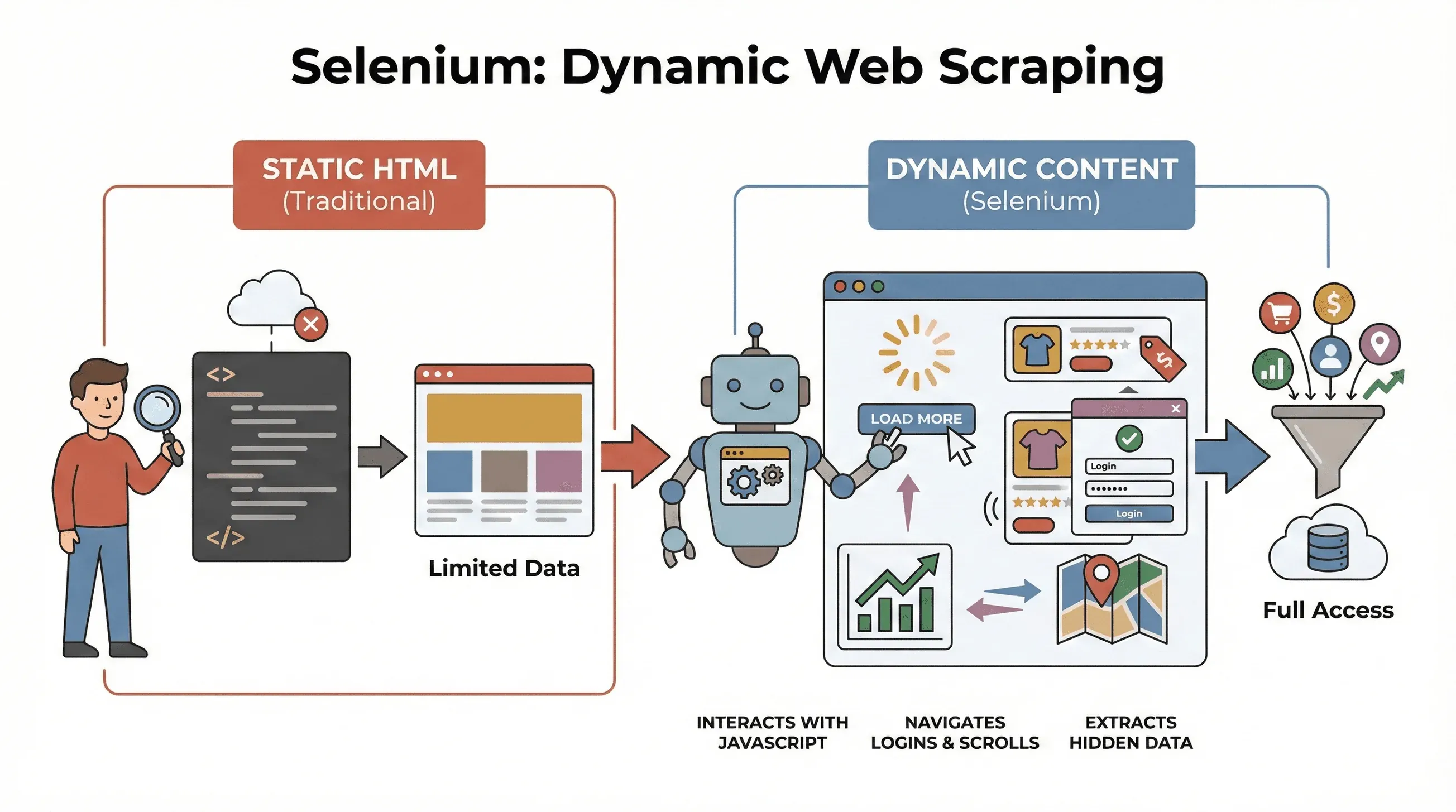 先從基礎開始。Selenium 是一個開源框架,讓您可以用程式控制真實的網頁瀏覽器——像是 Chrome 或 Firefox。您可以把它想成一個機器人,能像真人一樣打開頁面、點按鈕、填表單、捲動頁面,甚至執行 JavaScript。這一點很重要,因為多數現代網站不會一開始就把所有資料攤在眼前;相反地,它們通常會在您和頁面互動之後,才把內容動態載入出來。
先從基礎開始。Selenium 是一個開源框架,讓您可以用程式控制真實的網頁瀏覽器——像是 Chrome 或 Firefox。您可以把它想成一個機器人,能像真人一樣打開頁面、點按鈕、填表單、捲動頁面,甚至執行 JavaScript。這一點很重要,因為多數現代網站不會一開始就把所有資料攤在眼前;相反地,它們通常會在您和頁面互動之後,才把內容動態載入出來。
什麼是資料爬取?2026 完整指南 Get Started Free
為什麼這對爬蟲很重要? BeautifulSoup 或 Scrapy 這類傳統工具很適合處理靜態 HTML,但對於初始頁面載入後才由 JavaScript 載入的內容,它們就看不到了。相較之下,Selenium 可以即時和頁面互動,因此特別適合:
- 抓取只有按下「載入更多」後才會出現的商品列表
- 擷取會動態更新的價格或評論
- 在登入表單、彈出視窗或無限捲動頁面之間操作
- 從儀表板、地圖或其他互動式元素中擷取資料
簡單來說,當您要抓的資料只會在頁面載入完成後,或使用者操作之後才出現時,Selenium 就是最合適的工具。
Python Selenium 網頁爬蟲的關鍵步驟
用 Selenium 做爬蟲,核心上可以拆成三個步驟:
| 步驟 | 您要做什麼 | 為什麼重要 |
|---|---|---|
| 1. 環境設定 | 安裝 Selenium、WebDriver 與 Python 套件 | 先把工具備齊,避免卡在設定 |
| 2. 定位元素 | 用 ID、class、XPath 等方式找到要抓的資料 | 就算資料被 JavaScript 藏起來,也能鎖定正確內容 |
| 3. 擷取與儲存資料 | 擷取文字、連結或表格,並存成 CSV/Excel | 把原始網頁資料轉成可用內容 |
接下來,我們會用實際範例一步步拆解每個步驟,程式碼您可以直接複製、修改,再拿去和朋友炫耀。
步驟 1:設定你的 Python Selenium 環境
首先,您需要安裝 Selenium 和瀏覽器驅動程式(例如 Chrome 的 ChromeDriver)。好消息是,現在這件事比以前簡單多了。
安裝 Selenium
打開終端機,執行:
pip install selenium
取得 WebDriver
- Chrome: 下載 ChromeDriver(請確認版本和您的 Chrome 相符)。
- Firefox: 下載 GeckoDriver。
小技巧: 從 Selenium 4.6 開始,您可以使用 Selenium Manager 自動下載驅動程式,所以甚至不一定還需要手動處理 PATH 環境變數(文件)。
你的第一個 Selenium 腳本
這是一個 Selenium 的快速「hello world」:
from selenium import webdriver
driver = webdriver.Chrome() # 或 webdriver.Firefox()
driver.get("https://example.com")
print(driver.title)
driver.quit()
疑難排解提示:
- 如果出現「找不到驅動程式」錯誤,請檢查 PATH,或直接使用 Selenium Manager。
- 確認瀏覽器版本和驅動程式版本相符。
- 如果您是在沒有圖形介面的 headless 伺服器上執行,請參考下方的無頭模式建議。
步驟 2:定位網頁元素以進行資料擷取
接下來就是有趣的部分:告訴 Selenium 您要抓哪些資料。網站由各種元素組成——div、span、table 等等,而 Selenium 提供了多種方式來找到它們。
常見的定位方式
By.ID:根據唯一的 ID 找元素By.CLASS_NAME:根據 CSS class 找元素By.XPATH:使用 XPath 表達式(彈性很高,但也可能比較脆弱)By.CSS_SELECTOR:使用 CSS 選擇器(很適合複雜查詢)
以下是實際用法:
from selenium.webdriver.common.by import By
# 透過 ID 找元素
price = driver.find_element(By.ID, "price").text
# 透過 XPath 找元素
title = driver.find_element(By.XPATH, "//h1").text
# 用 CSS 選擇器找所有商品圖片
images = driver.find_elements(By.CSS_SELECTOR, ".product img")
for img in images:
print(img.get_attribute("src"))
小技巧: 優先使用最簡單、最穩定的定位方式(ID > class > CSS > XPath)。如果您抓取的頁面會延遲載入資料,請使用顯式等待:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
wait = WebDriverWait(driver, 10)
price_elem = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, ".price")))
這樣可以避免資料還沒出現,腳本就先崩潰。
步驟 3:擷取並儲存資料
一旦找到元素,接下來就是把資料抓下來,存到有用的地方。
擷取文字、連結與表格
假設您在爬取一個商品表格:
data = []
rows = driver.find_elements(By.XPATH, "//table/tbody/tr")
for row in rows:
cells = row.find_elements(By.TAG_NAME, "td")
data.append([cell.text for cell in cells])
使用 Pandas 存成 CSV
import pandas as pd
df = pd.DataFrame(data, columns=["名稱", "價格", "庫存"])
df.to_csv("products.csv", index=False)
您也可以存成 Excel(df.to_excel("products.xlsx")),甚至透過 API 直接推送到 Google Sheets。
完整範例:抓取商品標題與價格
from selenium import webdriver
from selenium.webdriver.common.by import By
import pandas as pd
driver = webdriver.Chrome()
driver.get("https://example.com/products")
data = []
products = driver.find_elements(By.CLASS_NAME, "product-card")
for p in products:
title = p.find_element(By.CLASS_NAME, "title").text
price = p.find_element(By.CLASS_NAME, "price").text
data.append([title, price])
driver.quit()
df = pd.DataFrame(data, columns=["標題", "價格"])
df.to_csv("products.csv", index=False)
Selenium、BeautifulSoup 與 Scrapy:Selenium 到底有什麼特別?
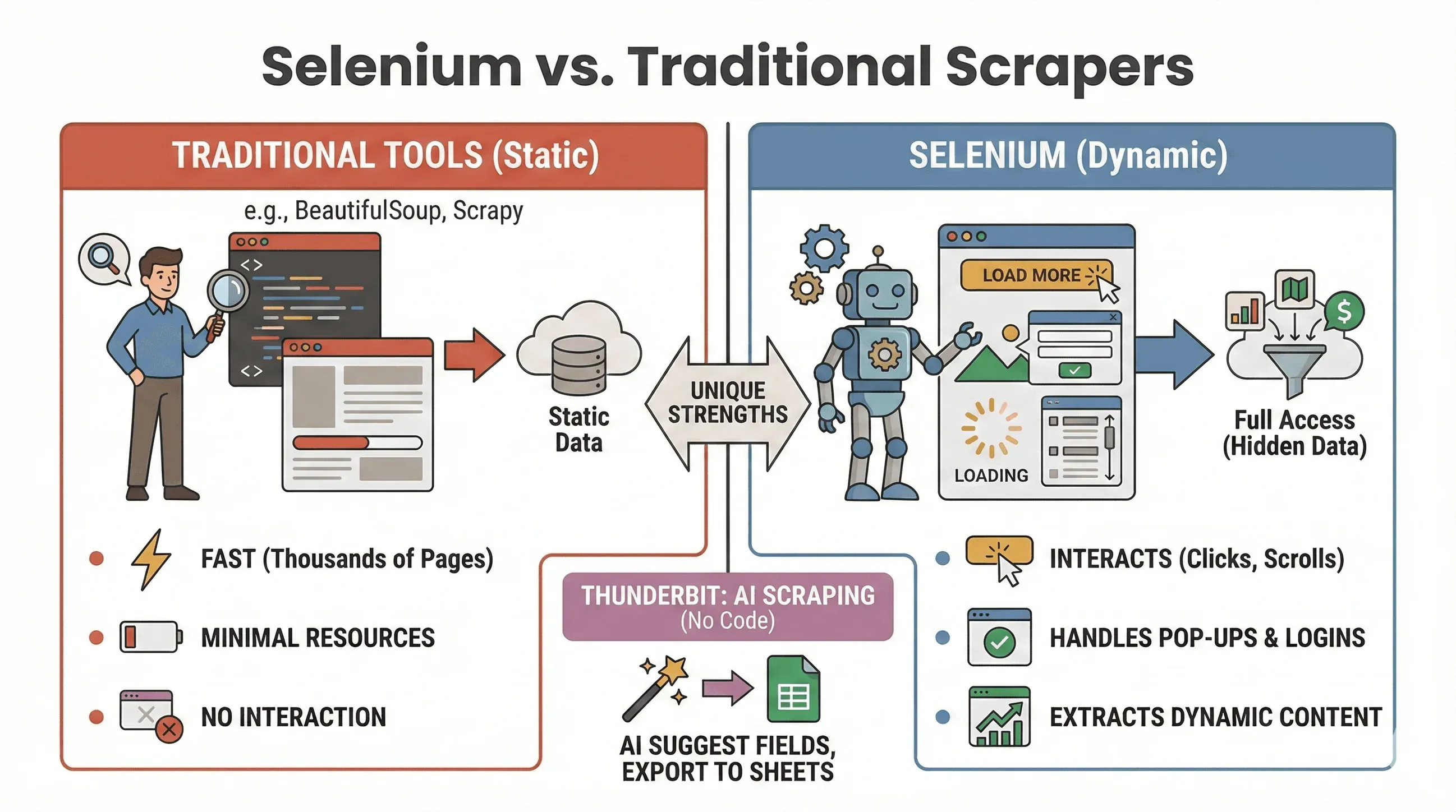 來把這個爭論講清楚:什麼時候該用 Selenium,什麼時候 BeautifulSoup 或 Scrapy 會更合適?以下是快速比較:
來把這個爭論講清楚:什麼時候該用 Selenium,什麼時候 BeautifulSoup 或 Scrapy 會更合適?以下是快速比較:
| 工具 | 最適合 | 支援 JavaScript 嗎? | 速度與資源使用 |
|---|---|---|---|
| Selenium | 動態/互動式網站 | 是 | 較慢,較占記憶體 |
| BeautifulSoup | 簡單的靜態 HTML 爬取 | 否 | 非常快,輕量 |
| Scrapy | 高流量靜態網站爬取 | 有限* | 極快、非同步、低 RAM |
| Thunderbit | 無程式碼、商業資料爬取 | 是(AI) | 小型/中型任務很快 |
*Scrapy 可以透過外掛處理某些動態內容,但這不是它的強項(ScrapingBee)。
什麼時候用 Selenium:
- 資料只有在點擊、捲動或登入後才會出現
- 需要和彈出視窗、無限捲動或動態儀表板互動
- 靜態爬蟲根本不夠用
什麼時候用 BeautifulSoup/Scrapy:
- 資料已經存在於初始 HTML 中
- 需要快速爬取上千個頁面
- 想盡量降低資源使用
如果您想完全跳過寫程式,Thunderbit 也能透過 AI 幫您爬取動態網站——只要點一下「AI 建議欄位」,就能匯出到 Sheets、Notion 或 Airtable。(下方會再詳細說明。)
如何用 AI 抓取任何網站 Get Started Free
使用 Selenium 與 Python 自動化網頁爬蟲任務
老實說:沒有人想在凌晨 2 點醒來,只為了手動執行一個爬蟲腳本。好消息是,您可以用 Python 的排程工具,或作業系統的排程器(例如 Linux/Mac 的 cron,或 Windows 的工作排程器)來自動化 Selenium 任務。
使用 schedule 函式庫
import schedule
import time
def job():
# 你的爬蟲程式碼寫在這裡
print("正在爬取...")
schedule.every().day.at("09:00").do(job)
while True:
schedule.run_pending()
time.sleep(1)
或使用 Cron(Linux/Mac)
把這行加入您的 crontab,讓它每小時執行一次:
0 * * * * python /path/to/your_script.py
自動化小技巧:
- 以無頭模式執行 Selenium(見下方),避免圖形介面跳出視窗。
- 記錄錯誤,並在出問題時主動發送警示給自己。
- 一定要用
driver.quit()關閉瀏覽器,釋放資源。
提升效率:更快、更穩定的 Selenium 爬蟲技巧
Selenium 很強,但如果使用不當,也可能又慢又吃資源。以下是加速並避免常見問題的方法:
1. 使用無頭模式
不需要一直看著 Chrome 開開關關。無頭模式會讓瀏覽器在背景執行:
from selenium.webdriver.chrome.options import Options
opts = Options()
opts.headless = True
driver = webdriver.Chrome(options=opts)
2. 封鎖圖片與其他不必要內容
如果您只是要抓文字,何必載入圖片?把它們擋掉可以加快頁面載入:
prefs = {"profile.managed_default_content_settings.images": 2}
opts.add_experimental_option("prefs", prefs)
3. 使用高效率的定位方式
- 優先使用 ID 或簡單的 CSS 選擇器,而不是複雜的 XPath。
- 避免使用
time.sleep()——改用顯式等待(WebDriverWait)。
4. 隨機化延遲
加入隨機暫停,模擬真人瀏覽,降低被封鎖的機率:
import random, time
time.sleep(random.uniform(1, 3))
5. 視需要輪換 User Agent 和 IP
如果您爬取量很大,可以輪換 user agent 字串,並考慮使用代理伺服器來避開簡單的反機器人機制。
6. 管理 session 與錯誤
- 使用 try/except 區塊,優雅處理找不到元素的情況。
- 記錄錯誤並截圖,方便除錯。
想看更多最佳化技巧,可以參考 BrowserStack 的指南。
進階:結合 Selenium 與 Thunderbit,輸出結構化資料
這裡才是真正有趣的地方——尤其是當您想省下資料清理和匯出的時間時。
當您用 Selenium 抓到原始資料後,可以再用 Thunderbit 來:
- 自動辨識欄位: Thunderbit 的 AI 可以讀取您爬下來的頁面或 CSV,並建議欄位名稱(「AI 建議欄位」)。
- 子頁面爬取: 如果您有一串網址(像是商品頁),Thunderbit 可以逐一訪問並替您的表格補充更多細節——不需要額外寫程式。
- 資料增強: 即時翻譯、分類或分析資料。
- 匯出到任何地方: 一鍵匯出到 Google Sheets、Airtable、Notion、CSV 或 Excel。
工作流程範例:
- 用 Selenium 抓取一串商品網址與標題。
- 將資料匯出成 CSV。
- 打開 Thunderbit,匯入 CSV,讓 AI 建議欄位。
- 使用 Thunderbit 的子頁面爬取功能,從每個商品網址抓取更多細節(例如圖片或規格)。
- 將最終的結構化資料集匯出到 Sheets 或 Notion。
這個組合可以省下好幾個小時的人工整理,讓您專注在分析,而不是處理亂七八糟的資料。想進一步了解這個流程,請參考 Thunderbit 的 Selenium 指南。
用 Thunderbit AI 匯出 Selenium 資料
Selenium 網頁爬蟲的最佳實踐與疑難排解
網頁爬蟲有點像釣魚:有時您會釣到大魚,有時卻只會勾到水草。以下是保持腳本穩定又合乎倫理的方法:
最佳實踐
- 尊重 robots.txt 和網站條款: 永遠先確認允許爬取。
- 控制請求頻率: 不要把伺服器壓垮——加入延遲,並留意 HTTP 429 錯誤。
- 有 API 就優先用 API: 如果資料有公開 API,請直接使用,通常更安全也更穩定。
- 只爬取公開資料: 避免涉及個資或敏感資訊,也要注意隱私法規。
- 處理彈出視窗與 CAPTCHA: 可以用 Selenium 關閉彈窗,但 CAPTCHA 很難自動化處理。
- 隨機化 user agent 與延遲: 有助於降低偵測與封鎖風險。
常見錯誤與修正方式
| 錯誤 | 代表什麼 | 如何修正 |
|---|---|---|
NoSuchElementException | 找不到元素 | 重新確認定位方式;使用等待 |
| 逾時錯誤 | 頁面或元素載入太慢 | 增加等待時間;檢查網路速度 |
| 驅動程式/瀏覽器版本不符 | Selenium 無法啟動瀏覽器 | 更新驅動程式與瀏覽器版本 |
| Session 當掉 | 瀏覽器意外關閉 | 使用無頭模式;管理資源 |
想看更多疑難排解技巧,請參考 Thunderbit 的 Selenium 教學。
結論與重點回顧
動態網頁爬取不再只是硬核開發者的專利了。透過 Python Selenium,您可以自動控制任何瀏覽器,與最棘手的 JavaScript 密集型網站互動,並擷取商業所需的資料——無論是用於銷售、研究,還是單純滿足好奇心。請記住:
- Selenium 是動態、互動式網站的首選工具。
- 三個關鍵步驟: 環境設定、定位、擷取與儲存。
- 把腳本自動化, 才能定期更新資料。
- 透過無頭模式、智慧等待與高效率定位方式, 提升速度與穩定性。
- 將 Selenium 與 Thunderbit 結合, 讓資料結構化與匯出更輕鬆——尤其適合想跳過試算表整理痛點的人。
準備好親自試試了嗎?先從上面的程式碼範例開始;當您準備把爬蟲能力升級到下一個層次時,不妨試試 Thunderbit,享受即時、AI 驅動的資料清理與匯出。如果您還想看更多內容,也歡迎前往 Thunderbit Blog 深入閱讀教學、攻略,以及最新的網頁自動化趨勢。
祝您爬得順利——願您的選擇器總能找到您要的東西。
免費試用 Thunderbit 人工智慧網頁爬蟲 Get Started Free
常見問題
1. 為什麼我應該用 Selenium 來做網頁爬蟲,而不是 BeautifulSoup 或 Scrapy?
Selenium 非常適合爬取動態網站,因為內容通常會在使用者操作或 JavaScript 執行後才載入。BeautifulSoup 和 Scrapy 雖然處理靜態 HTML 更快,但無法和動態元素互動,也不能模擬點擊和捲動。
2. 我要怎麼讓我的 Selenium 爬蟲跑得更快?
使用無頭模式、封鎖圖片與不必要資源、使用高效率的定位方式,並加入隨機延遲來模擬真人瀏覽。更多技巧請參考 BrowserStack 的指南。
3. 我可以排程讓 Selenium 爬蟲自動執行嗎?
可以!您可以使用 Python 的 schedule 函式庫,或作業系統的排程器(cron 或工作排程器)按固定間隔執行腳本。自動化爬蟲能幫助您讓資料保持最新。
4. 用 Selenium 抓下來的資料,最好的匯出方式是什麼?
可以用 Pandas 將資料存成 CSV 或 Excel。若需要更進階的匯出(Google Sheets、Notion、Airtable),可以把資料匯入 Thunderbit,並使用它的一鍵匯出功能。
5. 在 Selenium 裡,我要怎麼處理彈出視窗和 CAPTCHA?
您可以透過定位並點擊關閉按鈕來關閉彈出視窗。CAPTCHA 就困難得多——如果遇到它們,可以考慮改用人工繞過方式或 CAPTCHA 解題服務,並且務必遵守網站服務條款。
想看更多爬蟲教學、AI 自動化技巧,或取得最新的商業資料工具資訊嗎?歡迎訂閱 Thunderbit Blog,或前往我們的 YouTube 頻道 看實作示範。
深入了解




