你註冊了 ScraperAPI,看到 Hobby 方案標示著「100,000 credits」,於是開始抓資料。三天後,你的儀表板顯示這些 credits 已經少了 80%,而你大概只抓了 6,000 個頁面。到底發生了什麼事?答案就是 credit multiplier(額度倍率)機制,這也是幾乎沒有任何評測真正講清楚、但卻最重要的關鍵。
我花了好幾週深入研究 ScraperAPI 的文件,整理五家競品的實際價格資料,還讀遍了 Reddit 和 Capterra 上找得到的每一篇討論與評論。這篇 ScraperAPI 評測,就是我當初團隊第一次評估抓取 API 時最希望能找到的文章。我會帶你看 credits 的真實算式,說明 ScraperAPI 哪些地方表現出色、哪些地方完全不行,彙整 G2、Capterra 和 Reddit 上真實使用者的聲音,最後也會坦白告訴你:你到底需不需要 scraping API。
ScraperAPI 是什麼?又是為誰設計的?
ScraperAPI 是一款網頁爬取 API,專門處理大規模抓取背後那些繁瑣的基礎建設:透過 進行 proxy 輪換、自動處理 CAPTCHA、JavaScript 渲染,以及自動重試。你只要透過簡單的 API 呼叫送出網址,它就會回傳 HTML;如果你使用它的結構化資料端點,也能直接拿到解析後的 JSON。這家公司成立於 2018 年,創辦人是 Daniel Ni,總部位於拉斯維加斯,目前服務 ,包含 Deloitte、Sony 和 Alibaba,每月處理 。
它主要面向的是開發團隊與技術營運人員,用來打造客製化的抓取流程。如果你不寫程式,ScraperAPI 其實不是為你設計的(後面會再說明)。
核心功能包括:proxy 輪換、JavaScript 渲染、地區定位、熱門網站的結構化資料端點,以及請求失敗時的自動重試。
但最容易被多數評測忽略的一點是:如果你不了解倍率機制,ScraperAPI 價格頁上那些看起來很漂亮的 credits 數字,其實很容易造成誤解。所以我們先從這裡開始。
ScraperAPI 的 Credit 系統到底怎麼運作?(這是大多數評測跳過的重點)
ScraperAPI 採用 credit 計費制度。基本概念很簡單:1 次 API 請求 = 1 credit。問題是,實際情況幾乎從來不是這樣。真正的 credit 成本取決於兩件事:你抓取的網域,以及你啟用的功能選項。而這些成本會以不直覺的方式疊加。
每位使用者在註冊前都應該先看到的 Credit 倍率表

在你還沒打開任何參數之前,網站類型就已經決定了你的基礎 credit 成本:
| 網域類別 | 每次請求的基礎 Credits | 範例 |
|---|---|---|
| 一般網站 | 1 | 部落格、新聞網站、簡單 HTML |
| 電商網站 | 5 | Amazon、eBay、Walmart |
| SERP(搜尋引擎結果頁) | 25 | Google、Bing |
| 社群媒體 | 30 |
除此之外,功能選項還會額外增加 credits:
| 參數 | 額外 Credits | 備註 |
|---|---|---|
render=true(JS 渲染) | +10 | 所有方案皆適用 |
screenshot=true | +10 | 所有方案皆適用 |
premium=true(premium proxy) | +10 | 所有方案皆適用 |
ultra_premium=true | +30 | 僅付費方案可用 |
| 反機器人繞過(Cloudflare、DataDome、PerimeterX) | 每項 +10 | 系統自動偵測,不是你手動選擇 |
premium=true + render=true 同時啟用 | +25 | 不是 +20 |
ultra_premium=true + render=true 同時啟用 | +75 | 不是 +40 |
最後這一列才是關鍵。功能一旦組合,成本會比單獨相加更高。premium proxy(+10)加上 JavaScript 渲染(+10),直覺上應該是多 +20 credits,但 ScraperAPI 會收 。ultra-premium(+30)加上 JavaScript 渲染(+10)理論上應該是 +40,但實際上是 ——幾乎翻倍。這種非線性疊加沒有被明顯標示,而這正是使用者抱怨 credits 消失得比預期還快的主因。
以下參數不會額外耗費 credits:wait_for_selector、country_code、session_number、device_type、output_format、keep_headers=true、autoparse=true。
每個方案實際能拿到什麼:從免費版到企業版
以下是 ScraperAPI 目前的 :
| 方案 | 每月價格 | 年繳(每月) | API Credits | 併發執行緒 | 地區定位 |
|---|---|---|---|---|---|
| 免費版 | $0 | — | 1,000 | 5 | 不支援 |
| Hobby | $49 | $44 | 100,000 | 20 | 僅美國與歐盟 |
| Startup | $149 | $134 | 1,000,000 | 50 | 僅美國與歐盟 |
| Business | $299 | $269 | 3,000,000 | 100 | 國家級定位(50+ 國家) |
| Scaling | $475 | $427 | 5,000,000 | 200 | 國家級定位 |
| Enterprise | 客製 | 客製 | 5,000,000+ | 200+ | 國家級定位 |
接著看看每 1,000 次請求在各方案下的實際成本,並把倍率算進去:
| 方案 | 標準(1×) | JS 渲染(10×) | 電商(5×) | SERP(25×) | Ultra-Premium + JS(75×) |
|---|---|---|---|---|---|
| Hobby ($49) | $0.49 | $4.90 | $2.45 | $12.25 | $36.75 |
| Startup ($149) | $0.15 | $1.49 | $0.75 | $3.73 | $11.18 |
| Business ($299) | $0.10 | $1.00 | $0.50 | $2.49 | $7.48 |
| Scaling ($475) | $0.10 | $0.95 | $0.48 | $2.38 | $7.13 |
一個標榜「100,000 credits」的 $49/月方案,在抓取受保護網站、且同時啟用 ultra-premium 與 JavaScript 渲染時,實際只能拿到 1,333 次請求。換算下來,每 1,000 頁成本高達 ——甚至比許多全託管抓取服務還貴。
為什麼 credits 會比你想像中更快用完?
有三件事最容易讓使用者措手不及。
第一:依網域自動計價。 你不需要手動勾選 Amazon 的 5 倍或 Google 的 25 倍倍率;只要 ScraperAPI 偵測到網域,就會自動套用。同樣地,反機器人繞過的 credits(Cloudflare、DataDome、PerimeterX 各 +10)也會在偵測到時自動加入。
第二:credits 不會結轉。 沒用完的 credits 會在 ,不會累積到下個月。
第三點更讓人頭痛:Pay-As-You-Go 只提供給 Scaling 方案($475/月)以上的使用者。 如果你在 Hobby、Startup 或 Business 方案中途把 credits 用完,只能等到下一個計費週期,期間會直接被停用。你唯一的選擇就是升級到更高級別。
Reddit 上有使用者表示,原本被報價每 1 個 Amazon request 算 1 credit,60 million credits 要價 $3,600;但付款後卻被無預警套用 5 倍倍率。結果原本以為可用 6,000 萬次請求的方案,實際只剩 1,200 萬次——比預期少了 。
DataPipeline 的 Credit 陷阱
ScraperAPI 的免程式 DataPipeline 功能(可排程抓取並透過 webhook 傳送)使用的是另一套、而且明顯更高的 credit 計算方式。最基本的一般請求,在 DataPipeline 裡要花 :
| 請求類型 | 標準 API | DataPipeline | 倍率 |
|---|---|---|---|
| 基本一般請求 | 1 | 6 | 6× |
| 基本電商請求 | 5 | 10 | 2× |
| 基本 SERP | 25 | 30 | 1.2× |
| Ultra-premium + JS(一般網站) | 75 | 80 | 1.07× |
許多使用者以為 no-code pipeline 也會沿用標準 credit 成本,結果發現基本請求就燒掉 6 倍 credits。這些資訊雖然有寫,但你得花時間自己去挖。
真實每次請求成本:ScraperAPI 與競品比較
如果不把倍率算進去,首頁價格根本沒有意義。我整理了五家供應商的最新價格,並以大約 $300/月的方案作為基準,比較三種常見情境。
基本 HTML 抓取(不含 JS、不含 premium proxy)
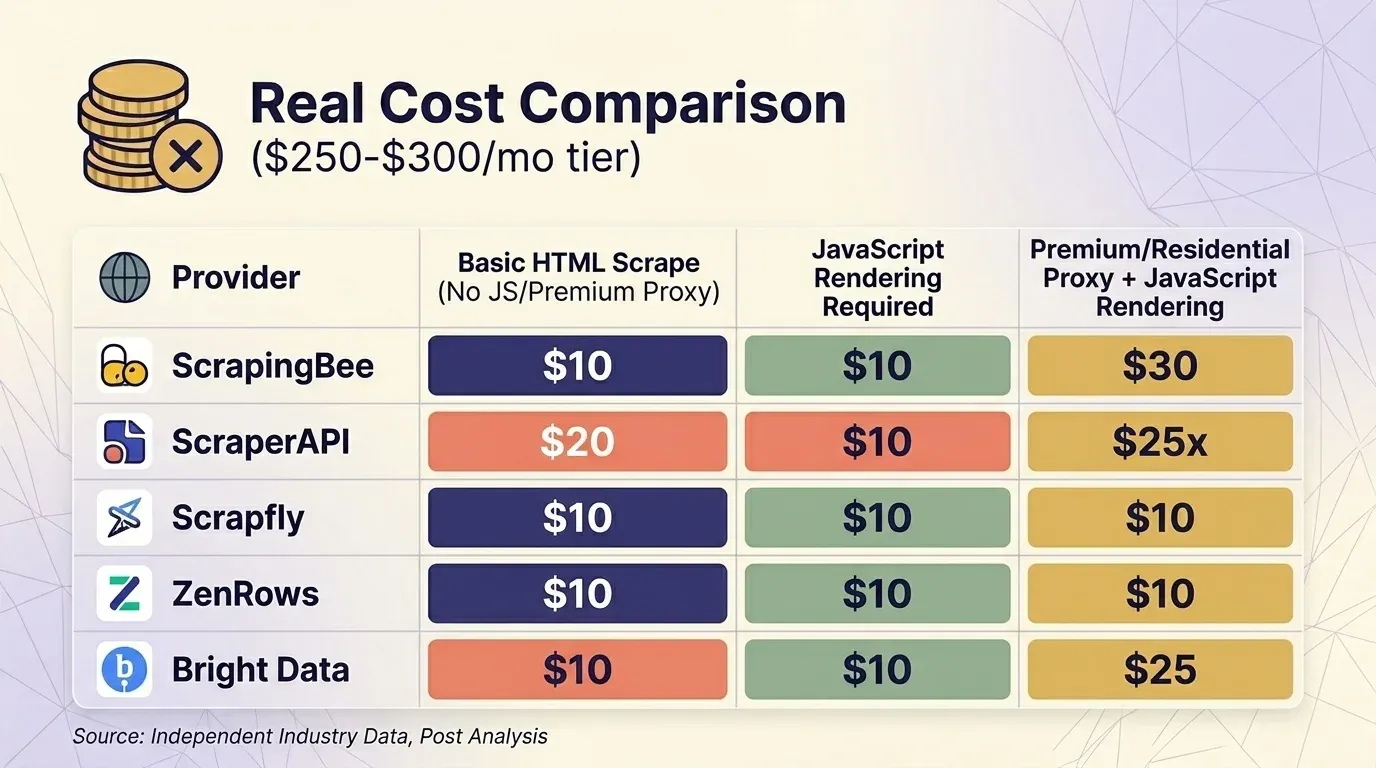
| 供應商 | 方案 | 每次請求 Credits | 實際請求數 | 每 1K 成本 |
|---|---|---|---|---|
| ScrapingBee | Business $249 | 1 | 3,000,000 | $0.08 |
| ScraperAPI | Business $299 | 1 | 3,000,000 | $0.10 |
| Scrapfly | Startup $250 | 1 | 2,500,000 | $0.10 |
| ZenRows | Business $300 | $0.28/1K | ~1,071,000 | $0.28 |
| Bright Data | PAYG | $1.50/1K | ~200,000 | $1.50 |
需要 JavaScript 渲染
| 供應商 | 方案 | 每次請求 Credits | 實際請求數 | 每 1K 成本 |
|---|---|---|---|---|
| ScrapingBee | Business $249 | 5(預設開啟) | 600,000 | $0.42 |
| Scrapfly | Startup $250 | 6 | 416,667 | $0.60 |
| ScraperAPI | Business $299 | 10 | 300,000 | $1.00 |
| ZenRows | Business $300 | 5× | ~214,000 | $1.40 |
| Bright Data | PAYG | 固定費率 | ~200,000 | $1.50 |
premium / residential proxy + JavaScript 渲染(受保護網站)
| 供應商 | 方案 | 每次請求 Credits | 實際請求數 | 每 1K 成本 |
|---|---|---|---|---|
| Bright Data | PAYG | 固定費率 | ~200,000 | $1.50 |
| ScrapingBee | Business $249 | 25 | 120,000 | $2.08 |
| ScraperAPI | Business $299 | 25 | 120,000 | $2.49 |
| Scrapfly | Startup $250 | 31 | 80,645 | $3.10 |
| ZenRows | Business $300 | 25× | ~42,857 | $7.00 |
Bright Data 的 Web Unlocker 是唯一一個 的供應商——所有請求都採固定費率。在約 $300 的方案區間裡,ScrapingBee 和 ScraperAPI 在受保護網站抓取上都算有競爭力,而 ZenRows 則是最貴的。
要特別注意一點:ScrapingBee ,而且成本是 5 倍。如果你要拿 ScrapingBee 跟 ScraperAPI 直接比較,請務必確認兩邊用的是相同的渲染設定。
另外,Scrape.do 的獨立分析指出,ScraperAPI 平均成本約為 ——「比測試過的任何其他供應商都高」;平均回應時間也達到 ,可說是「市面上最慢的供應商之一」。這些資訊在你決定是否採用前,很值得先知道。
站點層級成功率:ScraperAPI 哪裡強、哪裡弱
沒有任何抓取 API 能對所有網站都表現一樣好。來自 Scrapeway(2026 年 4 月)的獨立測試,呈現出非常明顯的兩極化結果。
依網站類別看表現
| 目標網站 | 成功率 | 平均速度 | 每 1K 成本(Business 方案) | |---|---|---|---|---| | Zillow | 100% | 10.5 秒 | $0.49 | | Etsy | 99% | 4.8 秒 | $4.90 | | Amazon | 98% | 6.5 秒 | $2.45 | | LinkedIn | 95% | 17.8 秒 | $14.70 | | Walmart | 93% | 11.4 秒 | $2.45 | | Indeed | 90% | 15.8 秒 | $4.90 | | StockX | 84% | 3.9 秒 | $4.90 | | Realtor.com | 12% | 11.8 秒 | $0.49 | | Instagram | 0% | — | — | | Booking.com | 0% | — | — | | Twitter/X | 0% | — | — |
整體平均成功率約為 ,略高於產業平均 58.2–59.5%。平均回應時間介於 5.2–7.3 秒,也優於產業平均 9.8 秒。
ScraperAPI 表現好的地方
ScraperAPI 在 電商(Amazon、Walmart、Etsy)和 房地產(Zillow)類型上真的很強。這些網站的結構化資料端點能高可靠度地回傳解析後 JSON。如果你的主要需求是抓 Amazon 商品頁或 Google SERP,ScraperAPI 算是合理選擇。
ScraperAPI 表現差的地方
社群媒體幾乎是死角。 Instagram、Twitter/X 和 Booking.com 在獨立測試中都呈現 0% 成功率。LinkedIn 雖然有 95% 成功率,但每次請求要 30 credits,成本相當高。
需要登入的網站明確不支援。 ScraperAPI 雖然可透過 session_number 保留 session,但它 。它無法處理表單填寫、雙因素驗證或複雜的驗證流程。
受保護目標會出現舊資料。 ScraperAPI 會對難抓的目標套用 ,這代表如果你抓的是即時性很高的資料(例如價格、庫存),拿到的結果可能最多落後 10 分鐘。
在 Proxyway 的 2025 年基準測試中,ScraperAPI 在 Google 上的成功率是 ,只有 81.72%。
網站類別表現摘要
| 網站類別 | ScraperAPI 表現 | 已知問題 | 可考慮替代方案 | |---|---|---|---|---| | Amazon / 電商 | ✅ 很強(SDP 端點) | 大量使用時 credit 消耗高 | Thunderbit 模板(一鍵使用,模板本身不按每列收費) | | Google SERP | ✅ 很強 | 地區定位要額外付費;某項基準測試中 Google 成功率最低 | — | | 房地產(Zillow) | ✅ 非常好(100%) | — | — | | Instagram / 社群媒體 | ❌ 0% 成功率 | 完全失敗 | Playwright + proxies(自行架設) | | 重 JS 的 SPA 網站 | ⚠️ 中等 | 需要 10 倍 credit 的 headless 渲染 | Scrapfly、ZenRows | | 需要登入的網站 | ❌ 因 ToS 禁止 | 不支援 session / 驗證流程 | Thunderbit 瀏覽器爬取(使用你的登入狀態) | | Booking.com / 旅遊 | ❌ 0% 成功率 | 完全失敗 | Bright Data |
真實使用者怎麼說:G2、Capterra、Reddit 的聲量整理
我整理了三個平台的回饋。以下是目前評分:
| 平台 | 評分 | 評論數 |
|---|---|---|
| G2 | 4.4/5 | 16 |
| Capterra | 4.6/5 | 62 |
| Trustpilot | 4.5/5 | 43 |
Capterra 的子評分如下:易用性 4.9/5、客服 4.6/5、功能 4.5/5、CP 值 4.5/5。
依主題整理的情緒摘要
| 主題 | 正面訊號 | 負面訊號 |
|---|---|---|
| 安裝與文件 | 「設定超簡單,幾分鐘內就能開始抓資料。」— Latenode 社群;Capterra 易用性 4.9/5 | — |
| 價格透明度 | 「入門價格相對親民」(多則 Capterra 評論) | 「credits 成本拆解很難懂」— John S., Founder,Capterra(2025 年 2 月);「價格漲了 1000%,品質卻變差」— CTO, Online Media, Capterra(2022 年 9 月) |
| 穩定性 | 「抓 Amazon/Google 很不錯」(G2、Capterra) | 「大量任務時 ScraperAPI 會變得不太穩」— emcarter,Latenode;「某些目標網站失敗率高達 80%」(Reddit) |
| 客戶支援 | 「團隊回應很快」(Capterra) | 有使用者表示曾被 報價一個價格,最後卻以 5 倍費率計費,且事前完全沒說明(Reddit) |
| 長期價值 | 只對成功(200/404)請求收費 | 「如果你在跑大規模業務,費用很快就會累積起來」;自行打造基礎架構從長遠來看「更划算」— mikezhang,Latenode |
結論很明確:ScraperAPI 在初期上手體驗上評價不錯,對熱門且支援良好的目標網站也相當穩定。爭議主要集中在價格驚喜(倍率、意外漲價)與較難網站上的可靠度。
ScraperAPI 的結構化資料端點:值得付出額外 credits 嗎?
ScraperAPI 提供 ,涵蓋 5 個平台,回傳的是解析後 JSON,而不是原始 HTML:
- Amazon(3 個端點):可依 ASIN 取得商品資訊、搜尋結果、競品 offers。回傳 18+ 欄位,包含價格、評分、描述、評論、BSR、圖片、賣家資訊等。支援 。
- Google(5 個端點):(自然搜尋結果、知識圖譜、影片、相關問題、分頁)、Shopping、Maps、News、Jobs。
- Walmart(4 個端點):商品、搜尋、分類、評論。
- eBay(2 個端點):商品、搜尋。
- Redfin(4 個端點):搜尋、房仲資訊、租屋物件、待售房源。
SDEs 在所有方案都可使用,包括免費版。ScraperAPI 宣稱支援的 SDE 網域有 ,不過獨立基準測試會因網站不同而呈現更細緻的結果。
資料完整度
Amazon 的 SDP 是 ScraperAPI 最強的產品之一。它能回傳非常完整的欄位:價格、評論、BSR、變體、圖片、賣家資訊等等。Google SERP 的 SDP 也能回傳自然結果、廣告、精選摘要與 People Also Ask。對這兩個平台來說,資料完整度確實不錯。
Credit 效率:SDE vs. 自行解析
在 Business 方案($299/月、300 萬 credits)下,透過 SDE 抓 10,000 個 Amazon 商品會消耗 50,000 credits(每筆 5 credits)——大約只占方案金額的 $5。若你改用標準請求自己寫解析器,每筆只要 1 credit,總共只需 10,000 credits,但你得投入開發時間去建立與維護解析邏輯。
對沒有開發資源的小團隊來說,SDE 能省下真實時間。
但對有工程能力、而且大規模抓取的團隊來說,5 倍的 credit 溢價就很難合理化。
SDPs 與免程式爬蟲模板怎麼比?
這個比較比多數評測更重要。 提供 Amazon、Shopify、Zillow,以及 的即用型爬蟲模板,不需要寫程式,而且模板本身不按每列額外收費。
| 比較項目 | ScraperAPI SDP(Amazon) | Thunderbit Amazon 模板 |
|---|---|---|
| 設定時間 | 30–60 分鐘(程式碼 + API 整合) | 約 2 分鐘(安裝擴充功能、打開 Amazon、點選模板) |
| 每 1,000 筆商品成本(Business 方案) | 約 $5(50,000 credits,以 $0.10/credit 計) | 約 $16.50(1,000 列 × 1 credit,以 Pro 每 credit $0.0165 計) |
| 回傳欄位 | 18+(非常完整) | 商品名稱、價格、評分、評論、圖片、URL 等 |
| 匯出選項 | JSON(需要程式解析) | Excel、CSV、Google Sheets、Airtable、Notion,一鍵完成 |
| 維護成本 | 由 ScraperAPI 維護 SDP | 由 Thunderbit 團隊維護模板 |
| 技術門檻 | 需要 Python/Node.js | 不需要 |
對於每天處理高流量 Amazon 抓取的開發團隊來說,ScraperAPI 的 SDP 在大規模下每筆商品成本更有優勢。若你只是想把 Amazon 資料快速放進試算表、不想寫程式,Thunderbit 的設定與使用速度會快非常多。
你真的需要 scraping API 嗎?多數評測忽略的免程式路線
很多搜尋「Scraper API review」的人,其實還沒有決定要不要走 API 工作流。他們只是想先搞清楚:自己到底需不需要這種工具。
出乎意料的是,很多人其實不需要。網頁抓取 API 市場雖然已經是 ,年複合成長率達 14–18%,但主要推動者是企業工程團隊,而不是那位只想從網站抓 500 筆名單的業務營運主管。
Scraping API vs. 免程式工具:並排決策框架
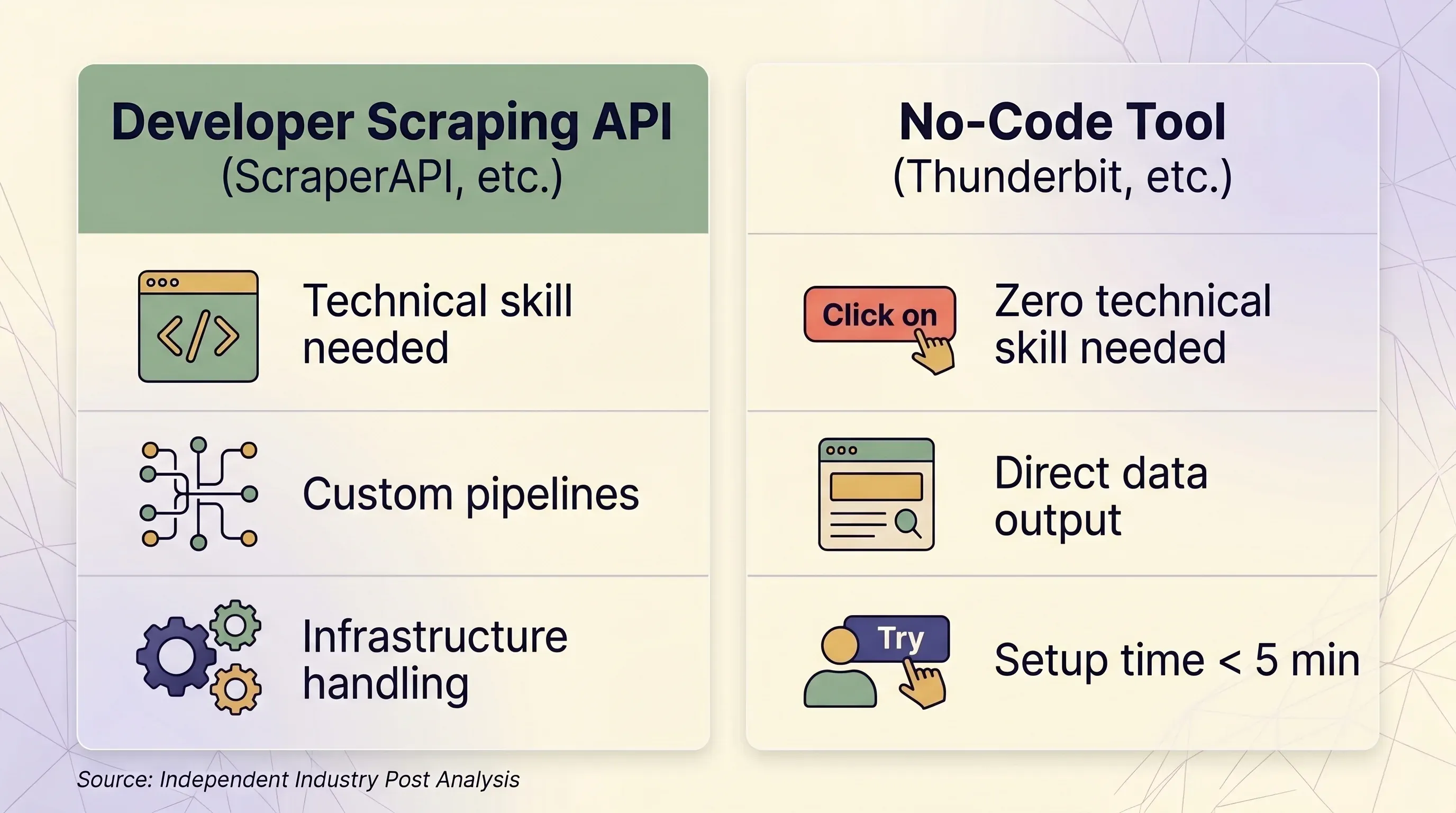
| 比較項目 | Scraping API(ScraperAPI 等) | 免程式工具(Thunderbit 等) | |---|---|---|---| | 最適合誰 | 需要大規模打造資料管線的開發者 | 商務使用者、行銷、業務團隊、研究人員 | | 技術需求 | Python/Node.js、HTTP 概念、JSON 解析 | 不需要——直接在瀏覽器點選操作 | | 設定時間 | 至少 1–2 小時(寫程式 + 測試 + 除錯) | 5 分鐘內 | | 反機器人處理 | premium proxies(每次 10–75 credits) | 真實瀏覽器 session,自然避開指紋偵測 | | 需要登入的網站 | ❌ ScraperAPI ToS 明確禁止 | ✅ 瀏覽器爬取 使用你現有的登入狀態 | | 規模(頁面/天) | 每月 10 萬–300 萬+ 次請求 | 彈性使用,通常每天少於 1,000 頁 | | 資料輸出 | 原始 HTML 或 JSON(需要自己寫解析) | 結構化列/欄,開箱即用 | | 匯出 | JSON、CSV(需程式) | Excel、CSV、Google Sheets、Airtable、Notion、Word、JSON | | 維護成本 | 需要更新 selector、重試邏輯與基礎架構 | 幾乎沒有——AI 每次都會重新讀取頁面結構 | | 計費單位 | 依請求收費(浮動:1–75 credits/請求) | 依列數收費(1 credit = 1 列,子頁面為 2) | | 入門價格 | $49/月,100K credits | 年繳 $9/月,5,000 credits | | 免費方案 | 每月 1,000 credits、5 併發 | 每月 6 頁、每頁 30 credits | | 價格可預測性 | 低——倍率容易造成意外費用 | 高——1 列永遠就是 1 credit |
什麼情況下適合用 Scraping API
- 你有開發或工程團隊
- 你需要每天以程式化方式抓取 10 萬頁以上
- 你需要高度客製化 request headers、sessions 和 retry 邏輯
- 你的目標網站支援度高(Amazon、Google、Walmart、Zillow)
什麼情況下 Thunderbit 這類免程式工具更合適
- 你在銷售、電商營運、行銷或房地產領域,而不是工程部門
- 你需要從很多不同網站抓資料,但不想為每個網站寫客製解析器
- 你想直接匯出到 Excel、Google Sheets、Airtable 或 Notion
- 你需要抓取需要登入的網站(Thunderbit 的 會使用你的 session)
- 你希望 AI 每次都重新讀頁,不想因網站版面變動而維護程式碼
- 你需要子頁面抓取:Thunderbit 可以自動逐筆拜訪詳細頁並補充資料
的流程真的很簡單:安裝擴充功能,進到任一頁面,點選「AI Suggest Fields」,再按「Scrape」,最後匯出即可。AI 會自動判斷頁面上的資料並建議欄位,你不需要自己寫 selector 或程式碼。想更了解原理,可以看看我們的 。
在 2024 年經歷過雲端成本超支,而採用 usage-based pricing 卻沒有妥善控管的公司,因為帳單爆量而導致 。如果你曾被浮動 API 成本嚇過,那麼 per-row 計費的可預測性就值得考慮。
ScraperAPI 優缺點一眼看懂
| 優點 | 缺點 |
|---|---|
| 強大的 proxy 基礎建設(4,000 萬+ IP、50+ 國家) | credit 倍率機制很混亂,功能疊加成本高於單項加總 |
| 文件完善、初始設定容易(Capterra 易用性 4.9/5) | credits 不會跨月結轉 |
| 在 Amazon、Google、Zillow、Etsy 上穩定 | Instagram、Twitter/X、Booking.com 成功率為 0% |
| 只對成功請求(200/404)收費 | 404 回應仍會消耗 credits |
| 18 個結構化資料端點,輸出解析後 JSON | 明確禁止抓取需要登入的網站 |
| 所有方案都可用,包含免費版 | Pay-As-You-Go 只提供給 Scaling($475/月)以上 |
| 7 天無條件退款政策 | 對困難目標有 10 分鐘強制快取,可能拿到舊資料 |
| 年增長率 30–35%,代表持續在開發 | DataPipeline 最多可花到標準 API 的 6 倍 credits |
| — | 超過美國與歐盟的地區定位需要 Business 方案($299/月) |
| — | 沒有主動用量警示,必須自己查看儀表板 |
如果你決定要用 ScraperAPI,這些實用建議會很有幫助
每天監控你的 Credit 消耗
ScraperAPI 的 提供使用統計,包括平均延遲、抓取網域與併發等資訊。不過,它沒有主動的用量警示——credits 快不夠時,不會寄 email 或簡訊提醒。你得自己手動查看。分析歷史在 Hobby/Startup 只保留 2 週,在 Business 以上則保留 6 個月。
建議你在第一個月每天都設提醒檢查儀表板,先摸清楚在特定目標上 credits 的消耗速度。
先用免費方案測試目標網站
先用 1,000 credits 免費額度(再加上 7 天、5,000 credits 試用)測試你的目標網站成功率,再決定是否升級付費方案。記錄哪些網站需要 JavaScript 渲染或 premium proxies,這樣你才能在算月費時更接近真實成本。
如果目標不需要,就別開高級功能
ScraperAPI 不會自動開啟 premium proxies 或 JavaScript 渲染——你必須明確設定 render=true、premium=true 或 ultra_premium=true。但依網域計價是自動的:Amazon 永遠是 5 credits,Google 永遠是 25,LinkedIn 永遠是 30。反機器人繞過的 credits(Cloudflare、DataDome、PerimeterX 各 +10)也會在偵測到時自動加入。批次執行前,務必要知道這點。
支援的網站盡量使用結構化資料端點
如果你要抓 Amazon 或 Google,SDE 雖然更耗 credits,但能省下開發時間。至於不支援的網站,建議評估 會不會比自己寫解析器更快、更便宜。
為不穩定的目標準備備案
如果 ScraperAPI 在某個特定網站的成功率低於 90%,就考慮改走其他供應商,或使用瀏覽器型工具。對需要登入的網站,ScraperAPI 就是行不通——你需要像 這種能在你的瀏覽器 session 內操作的工具。
先知道這些坑
- 404 回應也會消耗 credits——ScraperAPI 對 200 和 404 都會計費
- 取消的請求仍會收費——如果你在 70 秒處理視窗結束前取消,仍會被計費
- 困難目標有 10 分鐘強制快取——可能拿到舊資料
- Pay-As-You-Go 只提供給 Scaling($475/月)以上——低階方案用完就會被切斷
- 超過美國與歐盟的地區定位需要 Business 方案($299/月)
重點結論:ScraperAPI 適合你嗎?
研究完之後,我的結論如下:
- ScraperAPI 是開發團隊的穩定選擇,特別適合抓 Amazon、Google、Walmart、Zillow 這類高流量、支援度高的目標。結構化資料端點確實實用,proxy 基礎建設規模也很大,文件品質高於平均。
- credit 倍率機制是最大風險。 如果你不了解倍率怎麼疊加,就很容易超支。標示的 credits 和實際可抓頁數之間,可能有 5–75 倍差距。在付費前,務必先針對你的實際情境算清楚。
- 可靠度非常看網站。 ScraperAPI 在電商和房地產上很強,在職缺網站與社群媒體上普通,但在 Instagram、Twitter/X 與 Booking.com 上幾乎完全沒用。不要以為它對所有網站都同樣有效。
- 對非技術團隊來說,ScraperAPI 並不是好選擇。 如果你在銷售、行銷或營運部門,需要的是不用寫程式就能拿到結構化資料,那像 這樣的免程式工具,只要兩下就能做到——還有 AI 欄位辨識、直接匯出試算表、子頁面補資料,以及幾乎不用維護的優點。可以看看 ,或到 看教學影片。
- 如果你是預算有限的開發者,先用 ScraperAPI 的免費方案在你的實際目標上測試,再跟 ScrapingBee、Scrapfly 和 Bright Data 比較每次請求的實際成本。最便宜的選項,完全取決於你的使用情境與功能需求。
想看看這些數字在你的抓取需求上怎麼算嗎?你可以先從 ScraperAPI 的免費方案測試目標網站,或 看看兩下點擊能做到什麼程度。想了解更多 ,也可以直接看我們的方案頁。
常見問題
ScraperAPI 是免費的嗎?
是,ScraperAPI 提供每月 ,另有 7 天、5,000 credits 的試用。不過,JavaScript 渲染、premium proxy,或高成本網域(Amazon = 5×、Google = 25×、LinkedIn = 30×)的倍率會讓你的實際可用量遠低於 1,000 次請求。免費方案不提供 ultra-premium proxies。
ScraperAPI 每次請求要多少錢?
這非常取決於功能選項和目標網域。抓簡單 HTML 網站的標準請求要 1 credit;抓 Amazon 要 5 credits;抓 Google SERP 要 25 credits;加上 JavaScript 渲染則多 10 credits;如果把 ultra-premium proxy 和 JavaScript 渲染一起用,每次請求要 75 credits。在 Hobby 方案($49/月、100K credits)下,成本可能從每次約 $0.00049(標準請求)到每次約 $0.0368(ultra-premium + JS)不等。更完整的費用請參考上方表格。
ScraperAPI 適合抓 Amazon 嗎?
ScraperAPI 的 Amazon Structured Data 端點是它最強的功能之一,在獨立基準測試中有 ,而且會輸出非常完整的解析後 JSON(18+ 欄位)。但每個 Amazon 請求至少要 5 credits,所以一旦放大規模,成本會快速累積。對於想把 Amazon 資料直接放進試算表、又不想寫程式的小團隊來說, 提供了一鍵完成、直接匯出的替代方案。
ScraperAPI 最好的替代方案有哪些?
如果你是開發者: (基本 HTML 最便宜)、(JavaScript 渲染表現不錯)、(受保護網站表現最佳,不論是否渲染都採固定費率)、以及 。如果你不是技術背景:可以選 ——這是一款免程式、AI 驅動的 Chrome 擴充功能,可直接匯出到 Excel、Google Sheets、Airtable 和 Notion。更深入的比較可參考我們的 。
ScraperAPI 可以抓需要登入的網站嗎?
ScraperAPI 支援透過 session_number 參數保留 session(多次請求使用同一 IP),但它 。它無法處理表單填寫、雙因素驗證或複雜的驗證流程。對需要登入的網站來說,像 這種可直接使用你現有瀏覽器 session 的瀏覽器型工具,才是更可靠的選擇。
延伸閱讀