Zillow 擁有超過 ,而要怎麼大規模把這些資料抓下來,向來都是房地產資料工作裡最常被提到、也最讓人頭痛的一件事。如果你曾經試著抓取 Zillow,結果最後只看到 CAPTCHA 頁面,而不是房源資料,其實你一點都不孤單。
我花了不少時間研究和測試不同的 Zillow 抓取方式——包括用 Python,以及我們在 Thunderbit 打造的無程式碼工具。這篇指南會把這兩條路線都講清楚。無論你是想要完整的 Python 教學與反爬策略,還是只想在午餐前把 200 筆房源放進試算表,這裡都能找到適合你的內容。我們會說明 Zillow 資料為什麼重要、網站底層結構長什麼樣、一步一步的 Python 教學、爬蟲失敗的真正原因,以及如何自動化定期抓取來監控價格變化。
為什麼要抓取 Zillow 資料?
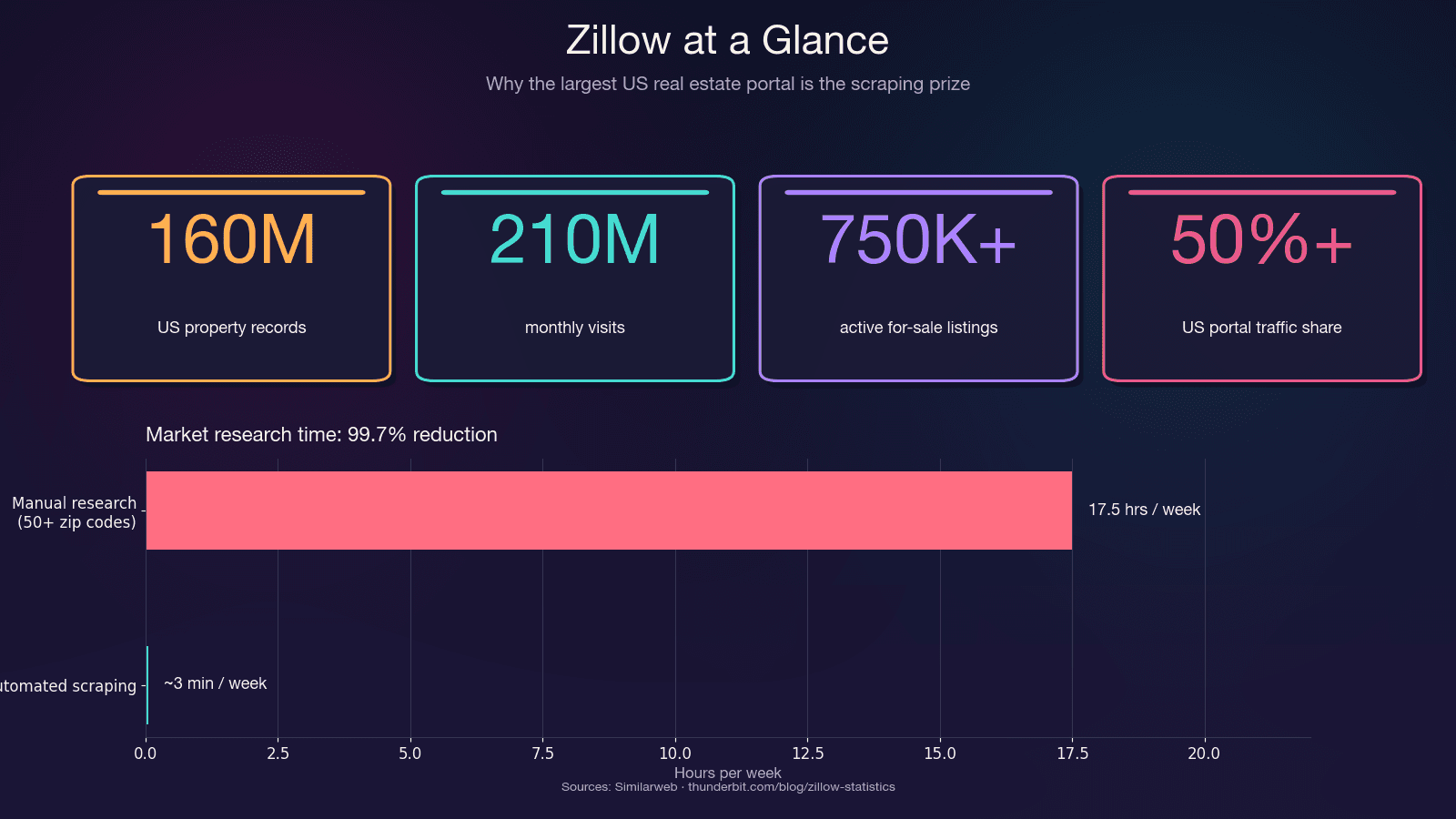
Zillow 是美國住宅房地產資料最大的資料庫之一。它每月吸引超過 ,平台上大約有 75 萬筆以上正在銷售中的房源,以及 190 萬筆租屋房源。它掌握了超過美國房地產入口網站流量的 50%,比第二名競爭者還多出一倍以上。
在開始寫 Python 之前,先了解一件事:用 Python 抓 Zillow 並不是唯一選項,選錯方法可能會浪費你很多時間。像 httpx 和 BeautifulSoup 這類 Python 工具需要中階技術能力,還要手動處理 headers 和 proxies,速度中等(每頁 1–3 秒),而且維護成本高,雖然本身免費;Selenium 或 Playwright 能透過渲染 JavaScript 來改善反爬處理,但速度較慢(每頁 5–15 秒),維護也不輕鬆;ScraperAPI 或 ScrapFly 這類抓取 API 速度快、內建反反爬機制,維護需求中等,但每月成本大約 30–599 美元;Zillow 官方 API 經由 Bridge Interactive 提供,速度快、維護成本低,但功能受限,費用大約每月 500 美元;而像 Thunderbit 這類無程式碼工具對初學者更友善、速度快、因為 AI 自適應幾乎不需要維護,通常還有免費方案。
單看省下的時間就很驚人。針對 50 個以上郵遞區號做人工研究,可能一週就會吃掉 15–20 小時。自動化抓取只要幾分鐘就能完成同樣的工作——時間成本直接減少 99.7%。
抓取 Zillow 的所有方法:Python、API、無程式碼比較
在進入 Python 程式之前,先知道「用 Python 抓 Zillow」並不是唯一解。選錯方式會浪費很多時間。下面用表格讓你快速比較,方便你直接挑選:
| 方法 | 技能門檻 | 反反爬處理 | 速度 | 維護成本 | 費用 |
|---|---|---|---|---|---|
| Python + httpx/BeautifulSoup | 中階 | 手動處理(headers、proxies) | 中等(1–3 秒/頁) | 高(選擇器容易壞) | 免費 |
| Python + Selenium/Playwright | 中階 | 較佳(可渲染 JS) | 慢(5–15 秒/頁) | 高 | 免費 |
| 抓取 API(ScraperAPI、ScrapFly) | 中階 | 內建 | 快 | 中等 | 每月 $30–599 |
| Zillow 官方 API(Bridge Interactive) | 初學者–中階 | 不適用 | 快 | 低 | 約每月 $500,且存取受限 |
| 無程式碼工具(Thunderbit) | 初學者 | 內建(AI 自動適應) | 快 | 幾乎不用維護(AI 會重新讀取頁面) | Freemium |
如果你現在就需要資料,又不想寫程式,先用 Thunderbit。
如果你想了解底層運作,或需要完整客製化,那就繼續看 Python 教學。
2 分鐘完成:用 Thunderbit 抓 Zillow(免寫程式)
在深入 Python 之前,先給只想快速拿到 Zillow 資料的人一條捷徑——不用安裝 Python、不用設定 proxy、不用維護選擇器。我們在 Thunderbit 做這個流程,就是為了讓你不用付出工程成本,也能拿到結構化的房地產資料。
難度: 初學者
所需時間: 約 2 分鐘
你需要準備: Chrome 瀏覽器、(免費方案可用)
步驟 1:安裝 Thunderbit 並打開 Zillow
先從 Chrome 線上應用程式商店安裝 Thunderbit 擴充功能。接著前往 Zillow 的搜尋結果頁,例如搜尋德州休士頓的房屋。
步驟 2:點選「AI Suggest Fields」
打開 Thunderbit 側邊欄,點擊「AI Suggest Fields」。AI 會自動讀取頁面,並建議欄位:價格、地址、臥室、浴室、坪數、Zestimate、房源網址等。依我測試,通常不用任何手動設定就能辨識出 20 多個欄位。
步驟 3:點選「Scrape」
按下 Scrape 按鈕,資料就會以結構化表格形式顯示在擴充功能中。Thunderbit 會自動處理 Zillow 的分頁機制,不管是點擊式翻頁還是無限捲動都可以。
步驟 4:用子頁面抓取補充資料
如果你想要更深入的詳細頁資料,例如稅務紀錄、學校評分或歷史價格,使用「Scrape Subpages」即可補強表格。Thunderbit 會逐一打開每個房源網址並擷取額外欄位,不需要再寫任何程式。
步驟 5:匯出
可以匯出到 Google Sheets、Excel、Airtable 或 Notion。匯出功能是免費的。
為什麼 Thunderbit 特別適合抓 Zillow
真正的優勢在於穩定性。Thunderbit 的 AI 每次抓取時都會重新讀取頁面結構。當 Zillow 調整版面時(這種情況很常發生),你不需要去修那些脆弱的 CSS 選擇器。AI 會自動適應。這確實解決了程式化爬蟲最讓人頭痛的「天生脆弱」問題。
你可以從 Zillow 抓到哪些資料?(20+ 欄位)
大多數教學只會抓價格和地址就結束了。但 Zillow 房源其實還有更多可擷取的資料——下面是參考表:
| 欄位 | 資料位置 | 擷取難度 |
|---|---|---|
| 刊登價格 | 搜尋頁 + 詳細頁 | 容易 |
| 地址 / 郵遞區號 | 搜尋頁 + 詳細頁 | 容易 |
| Zestimate | 搜尋頁 + 詳細頁 | 容易 |
| 價格歷史(每筆事件) | 詳細頁 | 困難(巢狀 JSON) |
| 稅務歷史 | 詳細頁 | 困難(巢狀 JSON) |
| 臥室 / 浴室 / 坪數 | 搜尋頁 + 詳細頁 | 容易 |
| 建成年份 | 詳細頁 | 容易 |
| HOA 管理費 | 詳細頁 | 中等 |
| 步行分數 / 大眾運輸分數 | 詳細頁(iframe) | 困難(需要 JS 渲染) |
| 學校評分 | 詳細頁 | 中等 |
| 土地面積 | 詳細頁 | 容易 |
| 在 Zillow 上的天數 | 搜尋頁 | 容易 |
| 房仲 / 經紀公司 | 搜尋頁 + 詳細頁 | 中等 |
| MLS 編號 | 詳細頁 | 容易 |
| 物件類型 | 搜尋頁 + 詳細頁 | 容易 |
| 緯度 / 經度 | __NEXT_DATA__ JSON | 中等 |
| 物件描述文字 | 詳細頁 | 容易 |
| 照片網址 | 搜尋頁 + 詳細頁 | 中等 |
| 租金 Zestimate | 詳細頁 | 中等 |
| 附近可比成交 | 詳細頁 | 困難 |
那些標示為「困難」的欄位——像是價格歷史、稅務歷史、可比成交——都藏在詳細頁的巢狀 JSON 裡。下面的 Python 章節會示範如何精準抓出來。如果你想跳過程式部分,Thunderbit 的 AI Suggest Fields 可以自動辨識大多數欄位,而它的 Subpage Scraping 也能自動抓取詳細頁資料。
建立 Python 環境來抓 Zillow
難度: 中階
所需時間: 安裝約 5 分鐘,完整教學約 30 分鐘
你需要準備: Python 3.8 以上、Chrome 瀏覽器(用來檢查頁面)、文字編輯器或 IDE
安裝必要套件:
1pip install httpx beautifulsoup4 pandas lxml各套件用途如下:
- httpx — 比
requests更快,且支援 async 的 HTTP 用戶端 - beautifulsoup4 + lxml — HTML 解析
- pandas — 匯出成 CSV / Excel
- 選用:selenium 或 playwright,若你需要渲染 JavaScript 較重的頁面
在抓取前先理解 Zillow 的頁面結構
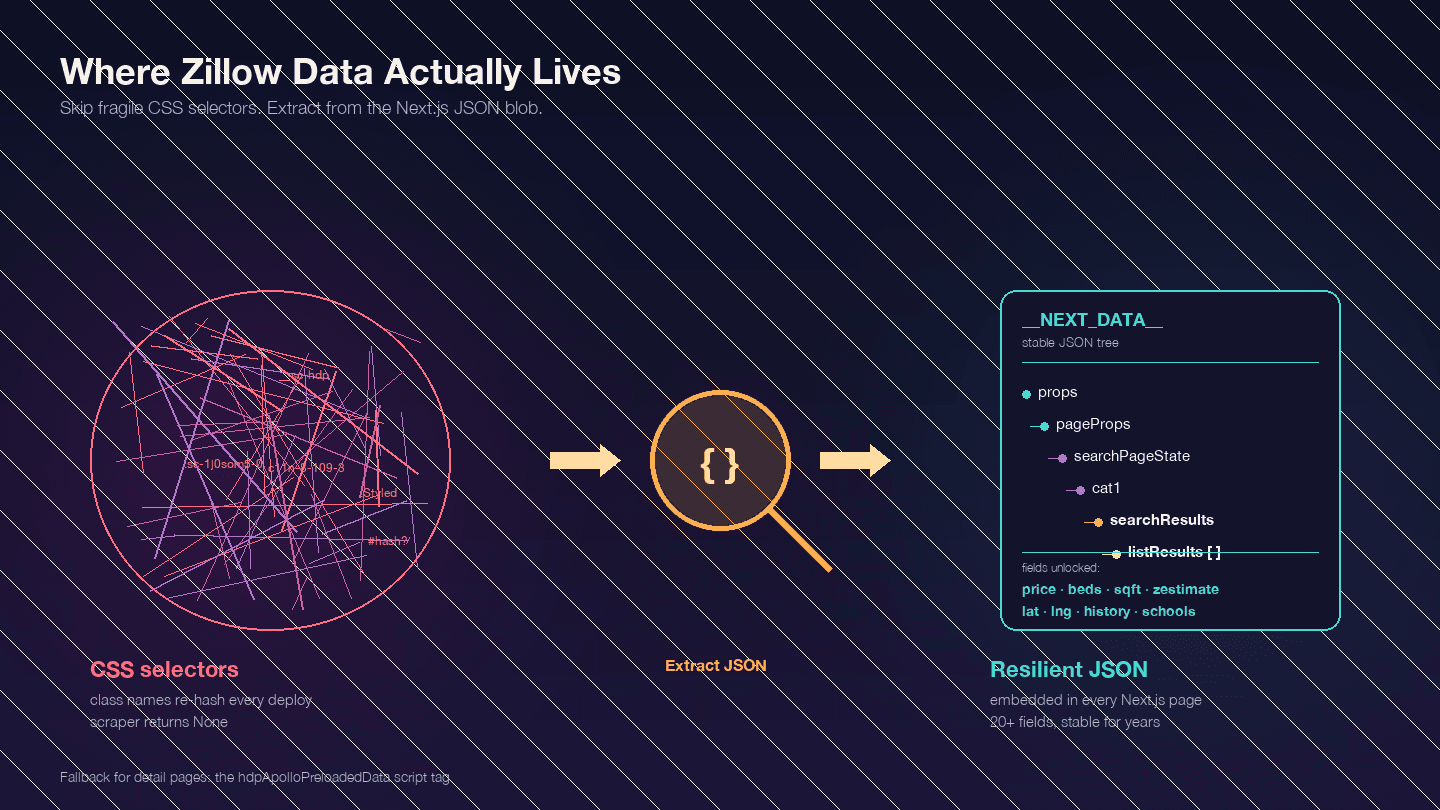
在寫任何程式之前,這是最重要的一件事。Zillow 是一個 Next.js 應用程式——這一點可從 佐證。這代表你要的資料大多不在可見的 HTML 元素裡,而是嵌在 <script id="__NEXT_DATA__"> 的 JSON 區塊中。
打開任何 Zillow 房源頁,按 F12,進入 Elements,搜尋 __NEXT_DATA__。你會找到一個超大的 JSON 物件,裡面包含所有房源資料——價格、座標、物件細節、價格歷史、稅務紀錄、學校評分等等。
為什麼這很重要?因為 Zillow 的 CSS class 名稱是雜湊生成的(由 styled-components 產生),而且每次部署都會變。像 StyledPropertyCardHomeDetailsList-c11n-8-109-3__sc-1j0som5-0 這類 class,下週就可能變成完全不同的雜湊值。任何依賴 CSS 選擇器的爬蟲都會經常壞掉。
相較之下,直接讀取 __NEXT_DATA__ JSON 會穩定得多,因為它完全不依賴 HTML 結構。
搜尋結果常見的 JSON 路徑:
| 路徑 | 內容 |
|---|---|
props.pageProps.searchPageState.cat1.searchResults.listResults | 搜尋結果陣列 |
props.pageProps.searchPageState.cat1.searchResults.mapResults | 地圖檢視結果 |
props.pageProps.searchPageState.cat1.searchList.totalPages | 可用總頁數 |
至於詳細頁,有些使用 __NEXT_DATA__,有些則使用另一個名為 hdpApolloPreloadedData 的 script 標籤。下面的程式會同時處理兩種情況。
一步一步:如何用 Python 抓 Zillow
步驟 1:設定 HTTP Headers,避免一開始就被擋
直接送出一個 httpx.get() 到 Zillow,回來的不是房源資料,而是 CAPTCHA 頁。Zillow 會同時使用 PerimeterX(HUMAN Security) 和 Cloudflare——這兩者在抓取基準測試中都被評為 。系統會檢查你的 TLS 指紋、HTTP headers 和 IP 信譽。
以下是截至 2025 年仍可用的最低限度 headers:
1import httpx
2headers = {
3 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
4 "(KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
5 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,"
6 "image/avif,image/webp,*/*;q=0.8",
7 "Accept-Language": "en-US,en;q=0.9",
8 "Accept-Encoding": "gzip, deflate, br",
9 "Sec-Ch-Ua": '"Chromium";v="124", "Google Chrome";v="124", "Not-A.Brand";v="99"',
10 "Sec-Ch-Ua-Platform": '"Windows"',
11 "Sec-Fetch-Dest": "document",
12 "Sec-Fetch-Mode": "navigate",
13 "Sec-Fetch-Site": "none",
14 "Sec-Fetch-User": "?1",
15 "Upgrade-Insecure-Requests": "1",
16}Sec-Ch-Ua 這組 headers 很關鍵。很多教學會省略它——這也是為什麼那些程式在對抗 PerimeterX 時根本不會成功。
步驟 2:抓取 Zillow 搜尋結果頁
Zillow 的搜尋網址有固定規則。以休士頓、德州為例:
- 第 1 頁:
https://www.zillow.com/houston-tx/ - 第 2 頁:
https://www.zillow.com/houston-tx/2_p/ - 第 3 頁:
https://www.zillow.com/houston-tx/3_p/
每頁大約有 41 筆房源。Zillow 最多只保留 20 頁結果(約 820 筆房源)。如果你要更大的資料集,就需要依地理區域拆分(後面會提到)。
以下是透過擷取 __NEXT_DATA__ JSON 來抓搜尋結果的程式:
1from bs4 import BeautifulSoup
2import json
3import time
4import random
5def scrape_zillow_search(url):
6 """從 Zillow 搜尋結果頁抓取房源資料。"""
7 response = httpx.get(url, headers=headers, timeout=15)
8 if response.status_code != 200:
9 print(f"{url} 回傳狀態碼 {response.status_code}")
10 return []
11 soup = BeautifulSoup(response.text, "lxml")
12 script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
13 if not script_tag:
14 print("找不到 __NEXT_DATA__,很可能已被 CAPTCHA 擋下")
15 return []
16 next_data = json.loads(script_tag.string)
17 try:
18 results = (
19 next_data["props"]["pageProps"]["searchPageState"]
20 ["cat1"]["searchResults"]["listResults"]
21 )
22 except KeyError:
23 print("JSON 結構不符合預期,Zillow 可能已變更格式")
24 return []
25 listings = []
26 for item in results:
27 listing = {
28 "zpid": item.get("zpid"),
29 "address": item.get("addressStreet"),
30 "city": item.get("addressCity"),
31 "state": item.get("addressState"),
32 "zipcode": item.get("addressZipcode"),
33 "price": item.get("unformattedPrice") or item.get("price"),
34 "beds": item.get("beds"),
35 "baths": item.get("baths"),
36 "sqft": item.get("area"),
37 "zestimate": item.get("zestimate"),
38 "days_on_zillow": item.get("daysOnZillow"),
39 "listing_url": item.get("detailUrl"),
40 "img_src": item.get("imgSrc"),
41 "property_type": item.get("hdpData", {}).get("homeInfo", {}).get("homeType"),
42 "latitude": item.get("latLong", {}).get("latitude"),
43 "longitude": item.get("latLong", {}).get("longitude"),
44 }
45 listings.append(listing)
46 return listings若要抓多頁,請加入延遲循環:
1all_listings = []
2base_url = "https://www.zillow.com/houston-tx/"
3for page in range(1, 6): # 前 5 頁
4 url = base_url if page == 1 else f"{base_url}{page}_p/"
5 print(f"正在抓取第 {page} 頁...")
6 page_listings = scrape_zillow_search(url)
7 all_listings.extend(page_listings)
8 # 每次隨機等待 3–7 秒
9 delay = random.uniform(3, 7)
10 time.sleep(delay)
11print(f"總共抓到 {len(all_listings)} 筆房源")如果一切正常,你會看到結構化的房源資料持續累積到 all_listings。如果結果是空的,請看下面的「爬蟲為什麼會壞掉」章節。
步驟 3:抓取 Zillow 房源詳細頁
搜尋結果只會提供基本資料。詳細頁則包含更深層的資訊:價格歷史、稅務歷史、學校評分、房仲資訊與物件描述。步驟 2 中取得的每個房源網址都會連到詳細頁。
Zillow 詳細頁有兩種可能的資料格式。以下程式可同時處理:
1def scrape_zillow_detail(url):
2 """從 Zillow 房源頁抓取詳細物件資料。"""
3 response = httpx.get(url, headers=headers, timeout=15)
4 if response.status_code != 200:
5 return None
6 soup = BeautifulSoup(response.text, "lxml")
7 # 先嘗試 __NEXT_DATA__(最常見)
8 script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
9 if script_tag:
10 next_data = json.loads(script_tag.string)
11 try:
12 cache_str = next_data["props"]["pageProps"]["componentProps"]["gdpClientCache"]
13 cache = json.loads(cache_str)
14 first_key = next(iter(cache))
15 prop = cache[first_key]["property"]
16 return extract_property_fields(prop)
17 except (KeyError, StopIteration):
18 pass
19 # 備援:hdpApolloPreloadedData
20 apollo_tag = soup.find("script", {"id": "hdpApolloPreloadedData"})
21 if apollo_tag:
22 raw = json.loads(apollo_tag.string)
23 api_cache = json.loads(raw["apiCache"])
24 for key, value in api_cache.items():
25 if "ForSale" in key or "property" in str(value)[:100]:
26 prop = value.get("property", value)
27 return extract_property_fields(prop)
28 return None
29def extract_property_fields(prop):
30 """從 Zillow 物件 JSON 中萃取結構化欄位。"""
31 return {
32 "zpid": prop.get("zpid"),
33 "zestimate": prop.get("zestimate"),
34 "rent_zestimate": prop.get("rentZestimate"),
35 "description": prop.get("description"),
36 "year_built": prop.get("yearBuilt"),
37 "lot_size": prop.get("lotSize"),
38 "hoa_fee": prop.get("monthlyHoaFee"),
39 "mls_id": prop.get("mlsid"),
40 "broker_name": prop.get("brokerName") or prop.get("attributionInfo", {}).get("brokerName"),
41 "price_history": [
42 {
43 "date": event.get("date"),
44 "event": event.get("event"),
45 "price": event.get("price"),
46 }
47 for event in prop.get("priceHistory", [])
48 ],
49 "tax_history": [
50 {
51 "year": record.get("time"),
52 "tax_paid": record.get("taxPaid"),
53 "value": record.get("value"),
54 }
55 for record in prop.get("taxHistory", [])
56 ],
57 "schools": [
58 {
59 "name": school.get("name"),
60 "rating": school.get("rating"),
61 "distance": school.get("distance"),
62 }
63 for school in prop.get("schools", [])
64 ],
65 }接著把房源網址逐一跑過去,並加入延遲:
1detail_data = []
2for listing in all_listings[:10]: # 先從 10 筆開始測試
3 detail_url = listing.get("listing_url")
4 if not detail_url:
5 continue
6 if not detail_url.startswith("http"):
7 detail_url = f"https://www.zillow.com{detail_url}"
8 print(f"正在抓取詳細頁:{detail_url}")
9 detail = scrape_zillow_detail(detail_url)
10 if detail:
11 detail_data.append({**listing, **detail})
12 time.sleep(random.uniform(3, 8))做到這一步後,你應該會拿到一串 dictionary,每筆都同時包含搜尋層級與詳細頁層級的資料。
步驟 4:處理分頁,抓取多頁資料
如果某個地區超過 820 筆房源(也就是 20 頁上限),你就需要按地理區域拆分。Zillow 內部 API 支援 mapBounds 參數。策略很簡單:把地圖切成四象限,分開抓取。
1def split_bounds(bounds):
2 """將地圖範圍切成 4 個象限。"""
3 mid_lat = (bounds["north"] + bounds["south"]) / 2
4 mid_lng = (bounds["east"] + bounds["west"]) / 2
5 return [
6 {"north": bounds["north"], "south": mid_lat, "east": bounds["east"], "west": mid_lng},
7 {"north": bounds["north"], "south": mid_lat, "east": mid_lng, "west": bounds["west"]},
8 {"north": mid_lat, "south": bounds["south"], "east": bounds["east"], "west": mid_lng},
9 {"north": mid_lat, "south": bounds["south"], "east": mid_lng, "west": bounds["west"]},
10 ]對大多數使用情境來說——例如監控某一地區 50–200 筆房源——標準網址分頁就夠用了。象限拆分法主要是給全市或全州等大範圍抓取使用。
步驟 5:匯出你抓到的 Zillow 資料
用 pandas 將所有資料存成 CSV:
1import pandas as pd
2df = pd.DataFrame(detail_data)
3df.to_csv("zillow_houston_listings.csv", index=False)
4print(f"已匯出 {len(df)} 筆房源到 zillow_houston_listings.csv")如果要輸出成 JSON:
1with open("zillow_houston_listings.json", "w") as f:
2 json.dump(detail_data, f, indent=2)如果你想連匯出都省略,Thunderbit 可以免費直接匯出到 Google Sheets、Airtable 和 Notion——如果你想立刻把資料放進協作環境,這會非常方便。
為什麼 Zillow 爬蟲常壞掉,以及如何打造更穩定的版本
這是生存指南。
根據我的經驗,Zillow 爬蟲主要會因為三個原因壞掉,而且每個原因都有對應的具體解法。
PerimeterX 與 CAPTCHA:為什麼你的請求只會拿到空資料
Zillow 的 PerimeterX 會同時檢查多個訊號:TLS 指紋、HTTP headers、IP 信譽和請求模式。當它偵測到自動化行為時,回傳的不是房源資料,而是「Press & Hold」CAPTCHA 頁面。
實際失敗情境: 你用預設 Python headers 發出請求,回應 HTML 裡是 PerimeterX 挑戰腳本,而不是物件資料,結果 BeautifulSoup 根本找不到 __NEXT_DATA__ 標籤。
解法: 使用步驟 1 裡完整仿瀏覽器的 headers。如果你要送出超過幾十次請求,也需要 proxy 輪換(下面會講)。如果是重度抓取,可以考慮用 curl_cffi 並設定 impersonate="chrome"——它是唯一能模擬真實 Chrome TLS 指紋的 Python HTTP 用戶端。
動態 CSS 選擇器:為什麼 BeautifulSoup 會回傳 None
如果你使用像 .list-card-price 或帶雜湊的 class 名稱作為 CSS 選擇器,Zillow 每次部署新程式時,你的爬蟲都會壞掉。
Zillow 使用 styled-components,會產生像 StyledPropertyCardHomeDetailsList-c11n-8-109-3__sc-1j0som5-0 這種 class 名稱,而且雜湊部分每次 build 都會變。
解法: 完全不要用 CSS 選擇器。改成像上面的程式一樣,直接從 __NEXT_DATA__ JSON 區塊擷取資料。這種方法多年來都很穩定,因為 JSON 結構比 HTML 標記變動少得多。
如果你真的必須解析 HTML,請找 data-test 屬性(例如 data-test="property-card"),或使用像 [class*="PropertyCard"] 這種字串比對 class 的方式。不過 JSON 擷取仍然是更可靠的路徑。
Proxy 輪換與指數退避:能撐過 IP 封鎖的程式碼
資料中心 IP 會被 Zillow 。你需要住宅 proxy 才能穩定存取。安全速率:每個 IP 每 3–8 秒 1 次請求,控制在每小時約 500 次以下。
下面是一個帶有指數退避與 jitter 的重試裝飾器:
1import random
2import time
3def backoff_with_jitter(attempt, base_delay=2, max_delay=60):
4 """AWS 風格的 full jitter 指數退避。"""
5 delay = min(max_delay, base_delay * (2 ** attempt))
6 return random.uniform(0, delay)
7def fetch_with_retry(url, max_retries=5):
8 for attempt in range(max_retries):
9 try:
10 response = httpx.get(url, headers=headers, timeout=15)
11 if response.status_code == 200:
12 return response
13 if response.status_code in (403, 429):
14 delay = backoff_with_jitter(attempt, base_delay=5)
15 print(f"被封鎖({response.status_code})。{delay:.1f} 秒後重試...")
16 time.sleep(delay)
17 continue
18 except Exception as e:
19 if attempt == max_retries - 1:
20 raise
21 time.sleep(backoff_with_jitter(attempt))
22 return None再來是一個簡單的 proxy 輪換池:
1class ProxyPool:
2 def __init__(self, proxies):
3 self.proxies = proxies
4 self.index = 0
5 self.failures = {}
6 def get_next(self):
7 proxy = self.proxies[self.index % len(self.proxies)]
8 self.index += 1
9 return {"http://": proxy, "https://": proxy}
10 def report_failure(self, proxy):
11 self.failures[proxy] = self.failures.get(proxy, 0) + 1
12 if self.failures[proxy] > 3:
13 self.proxies.remove(proxy)
14# 用法:
15pool = ProxyPool(proxies=[
16 "http://user:pass@residential1.example.com:8080",
17 "http://user:pass@residential2.example.com:8080",
18])如果你在找 proxy 供應商, 提供每 GB 約 1 美元的住宅 proxy(是最便宜的選項),而 IPRoyal 和 Smartproxy 則是每 GB 4–7 美元左右的穩定中階選擇。
零維護替代方案
如果你是經常抓 Zillow,又已經厭倦修壞掉的選擇器或管理 proxy 池,Thunderbit 的 AI 每次抓取都會重新讀取頁面結構。沒有要維護的選擇器,也不用配置 proxy。它確實解決了程式化爬蟲最常見的脆弱問題。
自動化 Zillow 抓取:排程與價格監控
我和每一位房地產投資人聊過後都發現,大家最想要的就是這個功能,但沒有其他 Zillow 抓取指南會完整講:定期自動抓取,用來追蹤價格變化。
給 Python 使用者:Cron Job 與價格變動偵測
設定一個 cron job,每週執行一次爬蟲,並標記價格變化:
1import pandas as pd
2from datetime import datetime
3def detect_price_changes(new_data, historical_file, threshold=0.05):
4 """比較新抓取結果與歷史資料,標示變動幅度超過 threshold 的項目。"""
5 try:
6 old = pd.read_csv(historical_file)
7 except FileNotFoundError:
8 new_data.to_csv(historical_file, index=False)
9 print("第一次執行——已儲存基準資料。")
10 return pd.DataFrame()
11 merged = new_data.merge(old, on="zpid", suffixes=("_new", "_old"))
12 merged["price_change_pct"] = (
13 (merged["price_new"] - merged["price_old"])
14 / merged["price_old"]
15 )
16 alerts = merged[merged["price_change_pct"].abs() > threshold]
17 # 將新資料加上時間戳後追加保存
18 new_data["scraped_at"] = datetime.now().isoformat()
19 new_data.to_csv(historical_file, mode="a", header=False, index=False)
20 return alerts把它加到 crontab,每週一早上 6 點執行:
10 6 * * 1 cd /path/to/scraper && python zillow_monitor.py實際例子:每週監控 50 筆德州奧斯汀房源。每週一,腳本抓取目前價格,與前一週比較,並輸出一份 CSV,標示任何超過 5% 的降價。
給非工程師:Thunderbit Scheduled Scraper
Thunderbit 的 Scheduled Scraper 讓你可以用自然語言描述間隔(例如「每週一上午 9 點」)、輸入 Zillow 搜尋網址,然後按下排程。每次執行後資料會自動匯出到 Google Sheets。沒有 Python、沒有 cron、也不用自己維護伺服器。這對需要穩定監控價格、但沒有工程支援的房仲或營運團隊來說特別實用。
如何負責任地抓取 Zillow
以下幾點提醒你保持在合理範圍內:
- 只抓取公開可見的資料。 不要存取登入牆後或需要驗證的頁面。
- 控制合理的請求頻率。 每次請求間隔 3–8 秒,不要狂打伺服器。
- 不要抓取個人或私人用戶資料。 房源上的房仲姓名與經紀公司資訊是公開資訊;使用者帳號資料不是。
- 以合乎倫理的方式儲存與使用資料。 市場研究、投資分析、潛在客戶開發都屬於合理用途;垃圾訊息不是。
- 法律背景: 確立了抓取公開可存取資料並不違反 CFAA。 也維持了類似原則。不過,Zillow 的服務條款仍限制自動化存取,而他們通常是透過 IP 封鎖與 CAPTCHA 來執行,而非直接採取法律行動。請務必查看最新指引,並尊重 。
選擇最適合你的 Zillow 抓取方式
最好的路徑取決於你的情況:
想要快、又不想寫程式? 大約 2 分鐘就能把 Zillow 搜尋頁變成結構化試算表。AI 會自動適應版面變更、處理分頁,而且匯出免費。安裝 後,直接在 Zillow 搜尋頁試試看。
想要完全掌控? 使用本指南中的 Python 程式。為了穩定性,請從 __NEXT_DATA__ JSON 擷取,而不是用 CSS 選擇器。設定正確的瀏覽器仿真 headers,並透過住宅 proxy 輪換與指數退避來提升可靠性。
要擴大規模? 像 這類抓取 API(Zillow 成功率 99%)或 ScraperAPI,會幫你處理 proxy 與 CAPTCHA 基礎設施,費用依流量每月約 30–599 美元。
要長期追蹤價格? 用價格變動偵測腳本建立 cron job,或者直接用 Thunderbit 的 Scheduled Scraper,走零維護路線。
資料就在那裡。真正的問題只剩下:你想花多少工程時間把它抓出來。若你想了解更多如何把網頁資料放進試算表,可以看看我們的 或 ,掌握最新平台資料。你也可以在 看教學影片。
常見問題
可以免費用 Python 抓 Zillow 嗎?
可以——httpx、BeautifulSoup 和 pandas 都是免費且開源的。代價是時間:你得自己處理 headers、proxy 輪換與選擇器維護。初始設定預計要花 4–8 小時,之後每當 Zillow 改版,還要每月再花 4–10 小時維護。如果你想完全省去程式成本,Thunderbit 也有免費方案。
Zillow 有官方 API 嗎?
Zillow 已在 2021 年 9 月停用免費公開 API。現在需透過 Bridge Interactive 取得,必須通過審核,費用大約每月 500 美元,主要面向持牌房地產專業人士。對大多數使用者——投資人、研究人員、進行市場分析的房仲——來說,抓取是比較實際的替代方案。Zillow 仍會在 提供免費可下載 CSV 的研究資料,包括 Zillow Home Value Index 和 Zillow Observed Rent Index。
我該怎麼避免抓 Zillow 時被封鎖?
三件事:(1) 使用真實感更高的瀏覽器 headers,包含 Sec-Ch-Ua——這是大多數教學漏掉、也是 PerimeterX 最先檢查的 header;(2) 輪換住宅 proxy——資料中心 IP 會被立即列入黑名單;(3) 直接從 __NEXT_DATA__ JSON 擷取資料,而不是依賴 HTML 選擇器,避免版面變動導致壞掉。每個 IP 的請求頻率控制在 3–8 秒一次。或者直接使用像 Thunderbit 這種會自動處理反反爬保護的工具。
不寫程式,抓 Zillow 最好的方式是什麼?
Thunderbit 的 AI Web Scraper 是最快的路徑。安裝 ,打開 Zillow 搜尋頁,點選「AI Suggest Fields」自動辨識欄位,再點「Scrape」。你可以免寫程式直接匯出到 Google Sheets、Excel、Airtable 或 Notion。AI 每次都會重新讀取頁面,所以 Zillow 改版時也不容易壞。
Zillow 網站結構多久會變一次?這會怎麼影響爬蟲?
Zillow 會頻繁更新,有時甚至每週都會部署。因為他們使用 styled-components,CSS class 名稱會隨每次部署改變,依賴 CSS 選擇器的爬蟲就會常常壞掉。對 Python 來說,最穩定的方法是從 __NEXT_DATA__ JSON 區塊擷取,因為它的結構變動頻率低得多。如果你想要零維護方案,Thunderbit 的 AI 每次抓取都會重新讀取頁面結構,並自動適應版面變化。
延伸閱讀