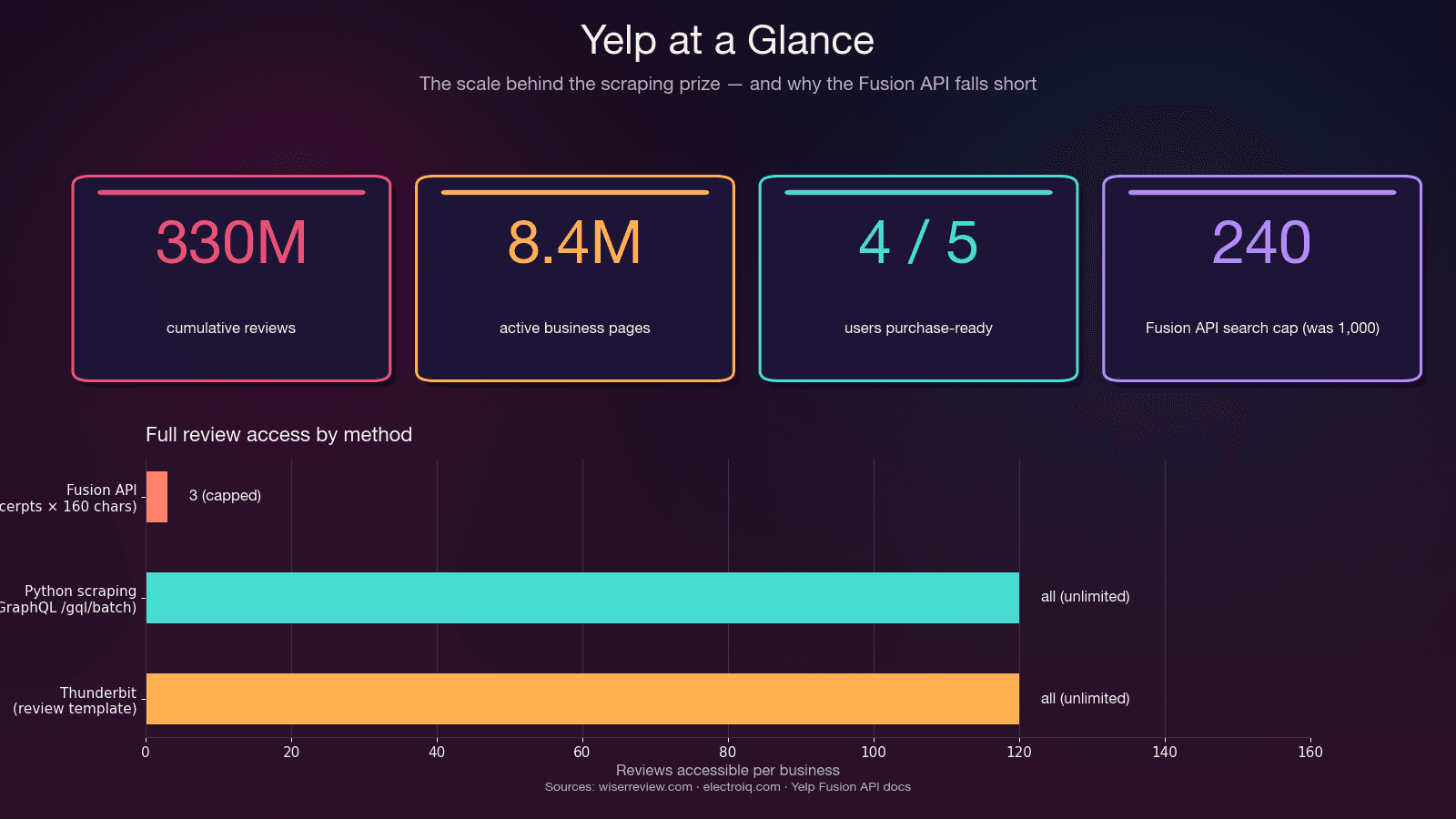
Yelp 目前累積了 ,分布在 上——而且,想把這些資料整理成可用格式,從來沒有現在這麼難。Yelp 在 2024–2025 年加強反機器人措施後,默默地讓大多數現有的 Python 抓取教學失效了。
如果你最近嘗試執行 Yelp 爬蟲,卻一直碰到 403 錯誤、空白 HTML 回應,或是半年前根本不存在的 CAPTCHA,那不是你的錯覺。Yelp 現在會進行 TLS/JA3 指紋辨識、輪換混淆過的 CSS 類名,還會嚴格評估 IP 信譽——這代表教學文還在推薦的 requests + BeautifulSoup 舊方法,第一個請求就會死掉。我花了好幾週測試各種方法對抗 Yelp 現行架構,這篇指南會整理出 2025 年真正有效的做法:官方 Fusion API(以及為什麼它可能還不夠)、一套完整的 Python 抓取流程與分層防封鎖策略,還有一個只要兩步、完全不必寫程式的替代方案 ,適合只想拿到資料、不想陷入除錯地獄的讀者。
為什麼要用 Python 抓取 Yelp?哪些人真的會受益?
在寫任何一行程式碼之前,先問一個問題:Yelp 資料到底能帶來什麼商業價值?這個平台不只是餐廳評論網站,它其實是一個即時的在地商家資料庫,包含結構化聯絡資訊、評分、分類、營業時間,以及數億則顧客評論。
以下是最常受益的族群,以及他們通常會抓取哪些內容:
| 使用情境 | 關鍵資料欄位 | 重要原因 |
|---|---|---|
| 業務開發與名單蒐集 | 商家名稱、電話、網站、地址、分類、評分 | 建立鎖定在地中小企業的潛在客戶名單 — 5 位 Yelp 使用者中有 4 位 到站時已接近購買決策 |
| 競爭情報 | 評論、星等、評論數、情緒傾向 | 監控競爭對手口碑、找出服務缺口、追蹤趨勢 |
| 市場研究與 NLP | 完整評論文字、日期、評論者中繼資料 | 情緒分析、主題建模 — Yelp 評論是學術研究中 最常用的 NLP 語料之一 |
| 房地產與選址 | 商家密度、分類組合、地區評論品質 | 連鎖與零售據點選址 — Yelp 也把這類資料做成 Location Intelligence 企業產品 |
| 電商與營運 | 價格訊號、顧客抱怨、服務時間 | 觀察競爭對手如何被評價,找出營運模式 |
核心其實很一致:真正的目標是結構化資料,而 Python 只是其中一種取得方式。有些讀者想保有完整程式控制權;也有人只需要一份奧斯汀水電工聯絡名單的試算表。這篇文章兩條路都會涵蓋。
Yelp Fusion API 與 Python 網頁抓取:到底該選哪個?
很多教學都直接跳過這個決策,沒有先判斷官方的 (現在改名為「Yelp Places API」)是否已經足夠。依我的經驗,先做這個評估可以省下大量時間,因為 API 很適合某些需求,但對另一些需求則完全不夠用。
Fusion API 實際能拿到什麼
Fusion API 提供結構化的商家搜尋、商家詳情、自動完成,以及評論端點。它是授權的、文件完整,也不需要任何反機器人技巧。
但真正卡關的是評論端點。以下是 Yelp 員工在 GitHub 上確認過的內容:
「Yelp API 不會回傳完整評論文字。預設只提供 3 則、每則 160 字元的評論摘錄。」 —
這不是 bug,而是設計如此。API 硬性限制最多 3 則評論摘要(Premium 版最多 7 則),而且每則都只會截到約 160 字元。沒有評論中繼資料(有幫助/有趣/很酷的投票)、沒有評論者歷史、也沒有店家回覆。而且在 2023 年 5 月之後,,從原本的 5,000 次大幅下修。入門方案價格從 起。
判斷框架
| 比較項目 | Yelp Fusion API | Python 網頁抓取 | Thunderbit(免寫程式) |
|---|---|---|---|
| 完整評論 | ❌ 只有 3 則摘要(每則約 160 字) | ✅ 透過 GraphQL 取得所有評論 | ✅ 取得所有可見評論 |
| 速率限制 | 300–500/日(新帳號);5,000(舊帳號) | 自行管理(靠代理成本) | 以點數計費 |
| 設定成本 | 約 15 分鐘(API key + SDK) | 幾小時到幾天 | 約 2 分鐘 |
| 商家欄位 | 約 20 個結構化欄位 | 不限(可解析 HTML/JSON) | AI 建議欄位 |
| 防封鎖處理 | 不適用(授權 API) | 必須自己做 | 自動處理 |
| 法規風險 | ✅ 授權 | ⚠️ ToS 灰色地帶 | ⚠️ 與抓取相同 |
| 成本 | 最低每月 29 美元 | 免費(+ 代理費用 $0.75–$4/GB) | 有免費方案 |
| 維護成本 | 低(API 穩定) | 高(選擇器會壞、反機器人升級) | 低(AI 會重新適應) |
**適合使用 Fusion API 的情況:**你只需要基本商家資訊、小規模查詢,或需要授權整合,而且每家商店只要 3 則評論摘要就夠。
**適合使用 Python 抓取的情況:**你需要完整評論文字、某商家的全部評論、評論中繼資料、單次搜尋超過 240 筆結果,或預算低於每月 29 美元。
**適合使用 Thunderbit 的情況:**你想快速拿到資料,不想寫或維護程式。下面的免程式段落會更詳細說明。
免寫程式的捷徑:用 Thunderbit 抓取 Yelp(不需要 Python)
在深入 Python 之前,先給真正目標是「資料」而不是「練程式」的讀者一條最快路徑。多數競品文章都預設你會 Python,但在 Thunderbit 的實務經驗裡,我發現搜尋「scrape Yelp」的人有很大一部分其實是業務、營運主管和小型企業主,他們只想要一份在地商家試算表,不想先上 TLS 指紋辨識的速成課。
已經內建 Yelp 範本:
- — 擷取商家名稱、評分、聯絡資訊、地址、營業時間、分類
- — 擷取評論者帳號、評論內容、評分、日期、評論者所在地
實際使用方式
- 在 Chrome 中打開 Yelp 搜尋結果頁或商家頁
- 在 中點選 AI Suggest Fields,AI 會讀取頁面並建議欄位(商家名稱、評分、評論數、價格區間、分類、地址、電話、網址)
- 點選 Scrape — 完成
如果使用預建的 Yelp 範本,流程更簡單:打開範本,點 Scrape 就行。
子頁面抓取 會自動完成資料補全:從 Yelp 搜尋結果頁開始,開啟子頁面抓取後,Thunderbit 會逐一拜訪每個商家頁,抓取營業時間、完整評論、網站、照片與設施資訊,不需要額外設定。
分頁也會自動處理 — 不管是點擊式分頁還是捲動式載入,都已內建支援。(想了解原理,可參考我們的 。)
所有方案都可免費匯出 — Excel、Google Sheets、Airtable、Notion、CSV、JSON,全都支援。沒有 pandas,沒有寫 CSV 的程式碼。
時間比較
| 時間 | Python 爬蟲 | Thunderbit |
|---|---|---|
| 第一次執行 | 幾小時到幾天(寫選擇器、處理分頁、代理、重試邏輯) | 使用內建 Yelp 範本約 30 秒 |
| Yelp 調整標記時 | 手動重寫選擇器 | 再點一次 AI Suggest Fields,自動重新適應 |
| IP 被封時 | 除錯、輪換代理池、重新測試 | 雲端模式自動處理 IP 輪替 |
| 匯出到 Google Sheets | 自己寫 OAuth + pandas 串接 | 一鍵完成,免費 |
如果你先試 Thunderbit,發現它已經滿足需求,那就可以直接跳過本文剩下內容。如果你需要完整程式控制、客製欄位,或每月規模超過幾千筆資料,再繼續往下看。
抓取 Yelp 可用哪些 Python 套件?該怎麼選
「我該用 Scrapy、BS4+requests,還是 Selenium?」這是 r/webscraping 裡最常看到的 Yelp 問題之一。但每篇教學都只介紹自己喜歡的函式庫,卻沒說為什麼。下面直接講結論。
2025 年的現實:requests + BeautifulSoup 在 Yelp 上已經壞掉了
幾乎所有 Yelp 教學都在推薦的那套:pip install requests beautifulsoup4,在 2025 年會 第一個請求就被封鎖。不是第 50 個,是第一個。
原因是:Python 的 requests 套件帶出的 TLS/JA3 指紋,和任何真實瀏覽器都對不上。Yelp 的反機器人層會在 TLS 握手階段就把它標記掉,甚至在讀到你的 User-Agent 之前就擋下來。我做了多次測試——新 IP、真實 headers、隨機延遲——但只要是原生 requests,還是立刻收到 403 Forbidden。
套件選擇矩陣
| 函式庫 | 最適合 | 支援 JS? | 可抗機器人? | 學習曲線 | 速度 |
|---|---|---|---|---|---|
requests + BeautifulSoup | ❌ | ❌ | 非常低 | 快(直到被封) | |
httpx async + parsel | 大規模非同步抓取 | ❌ | ❌ | 低 | 非常快 |
curl_cffi + parsel | Yelp 專用:TLS 模擬 | ❌ | ✅ TLS/JA3/HTTP2 | 低 | 非常快 |
Scrapy 2.14 | 含分頁的完整爬取流程 | 部分(透過 scrapy-playwright) | AutoThrottle、重試 middleware | 中高 | 快 |
Selenium 4.43 / Playwright 1.58 | JS 很重的頁面、CAPTCHA 變通方案 | ✅ | 部分 | 中等 | 慢(約 10–30 頁/分鐘) |
| Thunderbit | 不會寫程式、快速擷取 | ✅(瀏覽器) | 內建(雲端模式) | 非常低 | 快 |
curl_cffi 的關鍵突破
真正改變我 Yelp 抓取流程的函式庫是 ——它是 curl-impersonate 的 Python 封裝。它輸出的 TLS/JA3 + HTTP/2 指紋與真實 Chrome 完全一致,而且 API 幾乎可直接取代 requests:
1from curl_cffi import requests
2r = requests.get(
3 "https://www.yelp.com/biz/some-restaurant",
4 impersonate="chrome131",
5)
6print(r.status_code, len(r.text))光是這個改動——from curl_cffi import requests 加上 impersonate="chrome131"——就能繞過 Yelp ,而且不必啟動瀏覽器。以我的測試來看,這就是「立刻 403」和「正常回傳 200」的差別。
我對 2025 年 Yelp 抓取的推薦技術棧: curl_cffi + parsel + jmespath + residential proxies。如果你需要完整抓取流程與排程功能,可以再包一層 Scrapy 2.14,並使用基於 curl_cffi 的 downloader middleware。
建立 Python 環境,開始抓取 Yelp
- 難度: 中等
- 所需時間: 設定約 15 分鐘,做出可用爬蟲約 1–2 小時
- 你需要準備: Python 3.10+(建議 3.12)、終端機,以及可選的 residential proxy 供應商
步驟 1:建立虛擬環境並安裝套件
1python3.12 -m venv .venv
2source .venv/bin/activate # Windows 上:.venv\Scripts\activate
3pip install "curl_cffi>=0.11" "parsel>=1.9" "jmespath>=1.0" pandas各套件用途:
curl_cffi— 用 Chrome 的 TLS 指紋發送 HTTP 請求(反機器人繞過關鍵)parsel— 解析 HTML 的 CSS/XPath 選擇器(與 Scrapy 同樣引擎,但更輕量)jmespath— 宣告式 JSON 查詢(處理 Yelp 內嵌 JSON 比巢狀 dict 存取更乾淨)pandas— 將資料匯出為 CSV / Excel
選配但很實用:
1pip install fake-useragent # 注意:這個 repo 在 2026 年 4 月已封存,但仍可安裝逐步教學:如何用 Python 抓取 Yelp
這是核心教學。讓整個流程更穩定的關鍵洞見是:不要依賴 CSS 選擇器,改抓隱藏 JSON。 Yelp 會在建置時隨機化 CSS 類名(這週是 y-css-14xwok2,下週可能變 y-css-hcq7b9),所以任何綁死這些類名的爬蟲都會在幾週內失效。相較之下,內嵌 JSON payload —— application/ld+json schema 與 react-root-props —— 是穩定的。
步驟 2:抓取 Yelp 搜尋結果
Yelp 搜尋網址格式很固定:https://www.yelp.com/search?find_desc={term}&find_loc={location}。搜尋結果資料會以 JSON 形式嵌在 <script data-id="react-root-props"> 標籤裡,而不是藏在一堆 CSS 類名中。
1import re, json, jmespath
2from curl_cffi import requests
3from parsel import Selector
4HEADERS = {
5 "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
6 "AppleWebKit/537.36 (KHTML, like Gecko) "
7 "Chrome/124.0.0.0 Safari/537.36",
8 "accept": "text/html,application/xhtml+xml,application/xml;q=0.9,"
9 "image/avif,image/webp,image/apng,*/*;q=0.8",
10 "accept-language": "en-US,en;q=0.9",
11 "accept-encoding": "gzip, deflate, br",
12 "cookie": "intl_splash=false",
13}
14def scrape_search(term: str, location: str, max_pages: int = 3):
15 results = []
16 for page in range(max_pages):
17 url = (f"https://www.yelp.com/search?"
18 f"find_desc={term}&find_loc={location}&start={page * 10}")
19 r = requests.get(url, headers=HEADERS, impersonate="chrome131")
20 if r.status_code != 200:
21 print(f"第 {page} 頁被封鎖:{r.status_code}")
22 break
23 sel = Selector(text=r.text)
24 script = sel.xpath(
25 "//script[@data-id='react-root-props']/text()"
26 ).get() or ""
27 m = re.search(r"react_root_props\s*=\s*(\{.*?\});", script, re.S)
28 if not m:
29 print(f"第 {page} 頁找不到 react-root-props —— 可能是軟封鎖")
30 break
31 data = json.loads(m.group(1))
32 businesses = jmespath.search(
33 "legacyProps.searchAppProps.searchPageProps"
34 ".mainContentComponentsListProps"
35 "[?searchResultBusiness].searchResultBusiness.{"
36 "name: name, url: businessUrl, rating: rating, "
37 "reviews: reviewCount, phone: phone, "
38 "neighborhoods: neighborhoods}",
39 data,
40 ) or []
41 results.extend(businesses)
42 import time, random
43 time.sleep(random.uniform(3, 7))
44 return results你應該會拿到一串 dict,內含商家名稱、網址、評分與評論數。如果回應裡缺少 react-root-props,代表你拿到的是被封鎖的空殼頁面——請更換 IP 再試一次。
Cookie: intl_splash=false 是 Yelp 國家地區跳轉頁的標準解法。沒加的話,非美國 IP 常會先看到一個看起來像軟封鎖、但其實不是的 splash 頁。
步驟 3:抓取 Yelp 商家頁
搜尋結果中的每個商家網址,都會導向一個資料更完整的細節頁。最穩定的擷取目標是 <script type="application/ld+json"> 區塊——裡面包含 Yelp 為 SEO 保留的 schema.org 結構化資料,而且不會刻意混淆。
1def scrape_business(biz_url: str) -> dict:
2 url = f"https://www.yelp.com{biz_url}" if biz_url.startswith("/") else biz_url
3 r = requests.get(url, headers=HEADERS, impersonate="chrome131")
4 if r.status_code != 200:
5 return {"url": url, "error": r.status_code}
6 sel = Selector(text=r.text)
7 biz_id = sel.css('meta[name="yelp-biz-id"]::attr(content)').get()
8 for raw in sel.css('script[type="application/ld+json"]::text').getall():
9 try:
10 data = json.loads(raw)
11 except json.JSONDecodeError:
12 continue
13 for node in (data if isinstance(data, list) else [data]):
14 if node.get("@type") in (
15 "Restaurant", "LocalBusiness", "FoodEstablishment",
16 "HealthAndBeautyBusiness", "HomeAndConstructionBusiness",
17 ):
18 return {
19 "biz_id": biz_id,
20 "name": node.get("name"),
21 "rating": (node.get("aggregateRating") or {}).get("ratingValue"),
22 "review_count": (node.get("aggregateRating") or {}).get("reviewCount"),
23 "address": node.get("address"),
24 "telephone": node.get("telephone"),
25 "price_range": node.get("priceRange"),
26 "hours": node.get("openingHours"),
27 "url": url,
28 }
29 return {"biz_id": biz_id, "url": url}meta[name="yelp-biz-id"] 的值是編碼後的商家 ID,後面抓評論端點時會用到。先把它抓下來——下一步會用到。
步驟 4:用分頁抓取 Yelp 評論
這就是 Fusion API 做不到、而抓取能做到的地方。Yelp 內部的 GraphQL 批次端點會回傳完整評論文字、評論者資訊、日期、評分與投票數——這些都是 API 不會給的。
端點是 https://www.yelp.com/gql/batch,而且 GetBusinessReviewFeed 操作有一個固定的 documentId。分頁則透過 base64 編碼的 cursor 來進行。
1import base64
2GQL_URL = "https://www.yelp.com/gql/batch"
3DOC_ID = "ef51f33d1b0eccc958dddbf6cde15739c48b34637a00ebe316441031d4bf7681"
4def fetch_reviews(enc_biz_id: str, num_pages: int = 5):
5 all_reviews = []
6 for page in range(num_pages):
7 offset = page * 10
8 cursor = base64.b64encode(
9 json.dumps({"version": 1, "offset": offset}).encode()
10 ).decode()
11 payload = [{
12 "operationName": "GetBusinessReviewFeed",
13 "variables": {
14 "encBizId": enc_biz_id,
15 "reviewsPerPage": 10,
16 "after": cursor,
17 "sortBy": "DATE_DESC",
18 "language": "en",
19 },
20 "extensions": {
21 "operationType": "query",
22 "documentId": DOC_ID,
23 },
24 }]
25 r = requests.post(
26 GQL_URL,
27 json=payload,
28 headers={
29 **HEADERS,
30 "content-type": "application/json",
31 "x-apollo-operation-name": "GetBusinessReviewFeed",
32 "apollographql-client-name": "yelp-main-frontend",
33 },
34 impersonate="chrome131",
35 )
36 if r.status_code != 200:
37 print(f"評論擷取失敗,offset {offset}:{r.status_code}")
38 break
39 data = r.json()
40 # 解析回應結構並抽出評論
41 try:
42 reviews = data[0]["data"]["business"]["reviews"]["edges"]
43 for edge in reviews:
44 node = edge.get("node", {})
45 all_reviews.append({
46 "reviewer": node.get("author", {}).get("displayName"),
47 "rating": node.get("rating"),
48 "date": node.get("localizedDate"),
49 "text": node.get("text", {}).get("full"),
50 })
51 except (KeyError, IndexError, TypeError):
52 break
53 import time, random
54 time.sleep(random.uniform(3, 7))
55 return all_reviews每頁會回傳 10 則評論。只要把 base64 cursor 裡的 offset 往上加,就能分頁抓取。sortBy 參數支援 DATE_DESC(最新優先)、RATING_ASC、RATING_DESC 等排序方式。
步驟 5:匯出你抓到的 Yelp 資料
1import pandas as pd
2# 假設你已經收集到 businesses 和 reviews
3df_businesses = pd.DataFrame(businesses)
4df_businesses.to_csv("yelp_businesses.csv", index=False)
5df_reviews = pd.DataFrame(all_reviews)
6df_reviews.to_csv("yelp_reviews.csv", index=False)
7# 或是儲存成 JSON,更有彈性
8import json
9with open("yelp_data.json", "w") as f:
10 json.dump({"businesses": businesses, "reviews": all_reviews}, f, indent=2)如果你走免程式路線,Thunderbit 也能把相同資料直接匯出到 Excel、Google Sheets、Airtable 或 Notion,不需要 pandas 或寫檔程式碼。
防封鎖實戰:如何抓取 Yelp 而不被擋下來
這一段就是本文存在的核心原因。自 2024 年底以來,Yelp 的反機器人措施明顯升級—— 全都上場。大多數現有指南都已過時,因為它們是出現這波嚴打之前寫的。
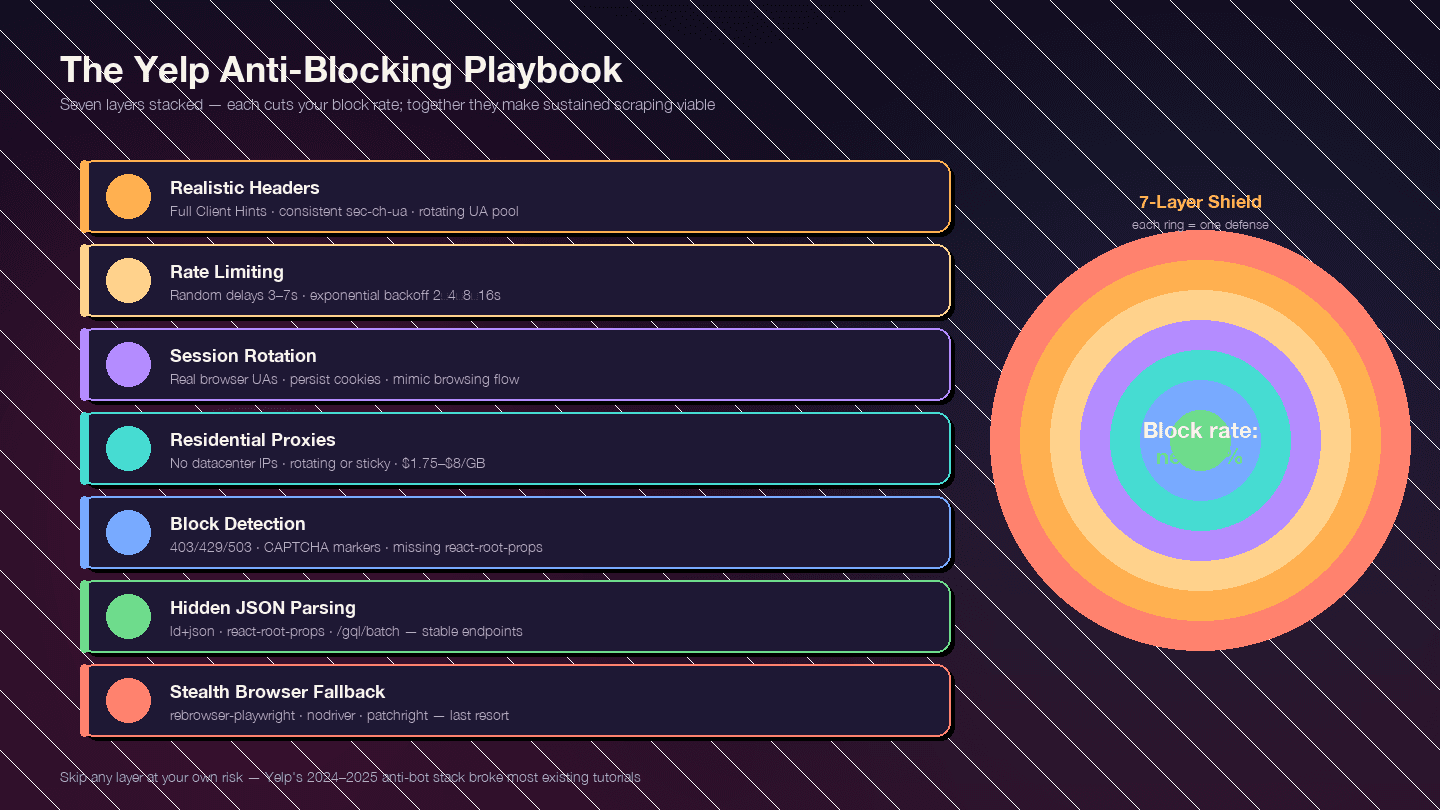
策略必須分層處理。每一層都能降低封鎖率;疊在一起,才有機會穩定抓取。
第 1 層:真實的請求標頭
預設 Python requests 會送出 User-Agent: python-requests/2.x——這種一眼就會被擋。但就算 User-Agent 看起來像真的,也還不夠。Yelp 會檢查完整的 標頭組合是否一致。
1FULL_HEADERS = {
2 "authority": "www.yelp.com",
3 "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
4 "AppleWebKit/537.36 (KHTML, like Gecko) "
5 "Chrome/124.0.0.0 Safari/537.36",
6 "accept": "text/html,application/xhtml+xml,application/xml;q=0.9,"
7 "image/avif,image/webp,image/apng,*/*;q=0.8",
8 "accept-language": "en-US,en;q=0.9",
9 "accept-encoding": "gzip, deflate, br",
10 "sec-ch-ua": '"Chromium";v="124", "Google Chrome";v="124", "Not-A.Brand";v="99"',
11 "sec-ch-ua-mobile": "?0",
12 "sec-ch-ua-platform": '"Windows"',
13 "sec-fetch-dest": "document",
14 "sec-fetch-mode": "navigate",
15 "sec-fetch-site": "same-origin",
16 "sec-fetch-user": "?1",
17 "upgrade-insecure-requests": "1",
18 "referer": "https://www.yelp.com/",
19 "cookie": "intl_splash=false",
20}最容易被標記的三個錯誤:
- UA 說是 Chrome,但
sec-ch-ua缺失或版本與 UA 不一致 sec-ch-ua-platform顯示「Windows」,但 UA 字串卻是 macOS- 同一個 IP 對數千次請求都用完全相同的 UA——請輪換 10–20 組近期的 Chrome / Firefox / Safari 字串
第 2 層:限速與隨機延遲
可預測的請求節奏很可疑。加入隨機 sleep,並在出錯時做指數退避。
1import random, time
2def polite_get(client_get, url, attempt=0):
3 r = client_get(url, headers=FULL_HEADERS, impersonate="chrome131")
4 if r.status_code in (403, 429, 503):
5 if attempt >= 4:
6 raise RuntimeError(f"{url} 在第 {attempt + 1} 次嘗試後仍被封鎖")
7 backoff = 2 ** (attempt + 1) + random.random()
8 print(f" 收到 {r.status_code},{backoff:.1f} 秒後重試(第 {attempt + 1} 次)")
9 time.sleep(backoff)
10 return polite_get(client_get, url, attempt + 1)
11 time.sleep(random.uniform(3, 7))
12 return r| 參數 | 建議值 |
|---|---|
| 請求間隨機等待 | random.uniform(3, 7) 秒 |
| 遇到 429/403/503 的退避 | 2 → 4 → 8 → 16 秒,最多 5 次嘗試 |
| 每個 IP 的同時工作數 | 1(每個 IP 序列化;並行請用代理) |
| 單個 residential IP 的長期速率上限 | 約 1 次 / 5 秒(約 12 rpm) |
第 3 層:User-Agent 與 Session 輪換
使用一組真實瀏覽器的 User-Agent 池來輪替。保留 session 與 cookie,模擬真實瀏覽行為——Yelp 會用 cookie 做偵測,每次請求都開新 session 反而可疑。
1UA_POOL = [
2 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
3 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14_4_1) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
4 "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:125.0) Gecko/20100101 Firefox/125.0",
5 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14.4; rv:125.0) Gecko/20100101 Firefox/125.0",
6 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14_4_1) AppleWebKit/605.1.15 Safari/17.4.1",
7 # 再加 5–10 組近期字串
8]第 4 層:代理輪換
只要有一定流量,你就需要 residential proxies。資料中心 IP 和免費代理在 Yelp 上幾乎沒用——Yelp 的 IP 信譽層會預先封鎖 AWS、GCP 和 DigitalOcean 的 IP 範圍。
| 供應商 | 入門 $/GB | 備註 |
|---|---|---|
| IPRoyal | $1.75/GB | 最便宜;也是最常被引用的 Yelp 教學來源 |
| Decodo(前 Smartproxy) | $3.20–$3.50 | 量大時 GB/美元比最佳 |
| Bright Data | $4.00(按量付費) | 1.5 億+ IP 池;有專門的 Yelp Proxies 頁面 |
| Oxylabs | $6.00–$8.00 | 高階方案;1,000 萬+ IP |
| Aluvia(行動 SIM) | $3.00 | 真實美國電信商行動 IP,特別為 Yelp 抓取定位 |
輪換式 residential proxy(每次請求換 IP)最適合大量搜尋結果爬取。Sticky session(同一個 IP 維持 10 分鐘)則更適合在商家頁 → 評論 → 分頁流程中保留 cookie。
第 5 層:偵測與處理封鎖
不是每種封鎖都長一樣。Yelp 常常給你一個通用的「頁面不可用」外殼,而不是 CAPTCHA,這也是為什麼天真的爬蟲會以為自己拿到資料,實際上卻只收到空白回應。
1BLOCK_MARKERS = (
2 "captcha", "px-captcha", "page not available",
3 "access denied", "unusual traffic",
4)
5def is_blocked(resp):
6 if resp.status_code in (401, 403, 429, 503):
7 return True
8 body = resp.text.lower()
9 if any(m in body for m in BLOCK_MARKERS):
10 return True
11 # 如果是搜尋頁或商家頁,但 react-root-props 不見了,
12 # 代表 Yelp 回傳的是被剝離過的封鎖頁
13 if "react-root-props" not in body and "/biz/" in str(resp.url):
14 return True
15 return False| 訊號 | 代表意義 |
|---|---|
| HTTP 403 | 硬封鎖 — IP / header / TLS 已被判定失效 |
| HTTP 429 | 速率限制 — 通常可透過退避恢復 |
| HTTP 503 | 通用封鎖或服務降載 |
重新導向到 /error 或出現 "page not available" 內容 | 軟封鎖 |
| 幾乎空白,只有 | 正在等待 JS 的挑戰頁 |
內容中出現 captcha / g-recaptcha / px-captcha | 升級封鎖 — 需要 CAPTCHA |
清單頁缺少 react-root-props | 被剝離過的封鎖回應 |
第 6 層:更穩的解析方式——抓隱藏 JSON,不要抓 CSS 選擇器
值得再強調一次:Yelp 會在建置時隨機化 CSS 類名。綁定 h3.y-css-14xwok2 的爬蟲,等 Yelp 下次部署成 h3.y-css-hcq7b9 時,很快就會壞掉。
真正不會亂動的是:
<script type="application/ld+json">— schema.org 結構化資料(名稱、地址、電話、評分、營業時間)<script data-id="react-root-props">— 以 JSON 存放的完整搜尋結果資料https://www.yelp.com/gql/batch— 具有穩定documentId的 GraphQL 評論端點
如果你還在解析 CSS 類名,其實等於把基礎蓋在沙上。改解析 JSON 才是正解。
第 7 層:隱身瀏覽器備援方案
只有在 curl_cffi + residential proxies 真的過不去時,才升級到 headless browser——通常是 Yelp 送出 JavaScript challenge page 或 CAPTCHA 的時候。
對 95% 的商家/搜尋/評論抓取來說,curl_cffi + 隱藏 JSON + residential proxies 比瀏覽器更快、更便宜、也更穩定。但如果你真的需要瀏覽器:
| 工具 | 2025 狀態 | 備註 |
|---|---|---|
| rebrowser-playwright | 建議起手式 | 直接可用的 Playwright 修正版,修補 CDP 洩漏 |
| nodriver | Chrome 隱身最佳之一 | undetected-chromedriver 的後繼者;完全避開 WebDriver 協定 |
| patchright | 持續維護的 Playwright 分支 | 可通過現代偵測測試 |
| playwright-stealth | 成熟穩定 | 會修補 navigator.webdriver,並從 UA 中移除 HeadlessChrome |
Yelp 上別用原生 Selenium,太容易被指紋辨識了。
Yelp Fusion API vs. Python 抓取 vs. Thunderbit:完整比較
| 面向 | Yelp Fusion API | Python 抓取 | Thunderbit |
|---|---|---|---|
| 完整評論文字 | ❌ 3 則摘要 × 約 160 字 | ✅ 無上限(GraphQL) | ✅ 內建評論範本 |
| 評論中繼資料(投票、店家回覆) | ❌ | ✅ | ✅ 透過 AI 建議欄位 |
| 照片 | ❌(Base 方案為 0) | ✅ 無上限 | ✅ |
| 每次搜尋最多結果 | 240(2024 前為 1,000) | 無上限(可分頁) | 無上限 |
| 每日速率限制 | 300–500(新帳號)/ 5,000(舊帳號) | 只受代理預算限制 | 以點數計費(Pro 版每月 3,000) |
| 設定成本 | 約 15 分鐘 | 幾小時到幾天 | 約 2 分鐘 |
| 防封鎖處理 | 不適用 | 你的問題 | 已處理(雲端模式) |
| 法律風險 | 低(授權) | 中(ToS 灰色地帶) | 中(與抓取相同) |
| 成本(入門) | 每月 29 美元 | 約 $0.75–$4/GB 代理費 + 開發時間 | 免費方案 |
| 成本(大量使用) | 每月 $643+ | 每月 $50–$500 代理費 + 開發時間 | 每月 $38–$49 |
| 資料匯出 | JSON | CSV/JSON(自己寫) | Excel / Sheets / Airtable / Notion — 免費 |
| 維護成本 | 低 | 高(選擇器會壞、反機器人升級) | 低(AI 會重新適應) |
抓取 Yelp 的法律與倫理提醒
我不是律師,以下內容也不是法律建議。不過,過去兩年法律環境的變化夠大了,在投入 Yelp 抓取專案前,至少要先知道基本規則。
Yelp 的服務條款怎麼說: 明確禁止使用「任何機器人、蜘蛛程式……或其他自動化設備」去「存取、擷取、複製、抓取或索引」服務的任何部分。條款還新增了關於「AI Technologies 和/或其他自動化工具」的描述。
:「Yelp 不允許任何網站抓取行為。」
robots.txt 的內容: Yelp 的 對 User-agent: * 一律 Disallow: /,並且特別封鎖 GPTBot、ClaudeBot、PerplexityBot、CCBot 和 Meta-ExternalAgent。只有 Googlebot、Bingbot 與少數社群媒體爬蟲被白名單放行。
真正重要的法律先例: 在 (加州北區法院,2024 年 1 月)中,法院認定抓取公開可見、未登入的資料,並不違反 Meta 的服務條款。關鍵差異在於:未登入的公開資料 vs. 登入後資料。 也建立了抓取公開資料大致不會違反 CFAA 的方向,但 hiQ 最後仍在州法侵權主張(動產侵入、挪用)上敗訴,還被判賠 50 萬美元。
實務建議:
- 只抓公開可見、未登入頁面
- 控制請求速率(本指南中的延遲設計,同時也是倫理上的限速)
- 不要轉賣附帶使用者姓名的原始評論文字——請尊重評論者隱私
- 遵守當地資料保護法(CCPA、GDPR)
- 不要登入後再抓取——這會跨過授權界線
- 把商家資訊(名稱/地址/電話/評分)視為公開事實資料;把評論文字視為更敏感內容
實際情況請諮詢法律專業人士。
結語
三條路,同一個目標。
Yelp Fusion API 是最受授權、維護成本最低的選項,但它只提供 3 則評論摘要,而且起價是每月 29 美元。Python 抓取則能讓你完整掌握 Yelp 的每一項資料,但也需要真正的投入:curl_cffi 做 TLS 指紋模擬、residential proxies、隨機延遲、隱藏 JSON 解析,以及隨著 Yelp 防禦升級而持續維護。Thunderbit 則能讓你從「我需要 Yelp 資料」直接變成「這是我的試算表」,大約只要 30 秒,完全不用寫程式,也不用設定代理。
2025 年真正有效的防封鎖要點是:帶完整 Client Hints 的真實 headers、用 curl_cffi 模擬 TLS 指紋、隨機延遲與指數退避、residential proxy 輪換,以及最重要的——解析隱藏 JSON(application/ld+json 和 react-root-props),而不是脆弱的 CSS 選擇器。
還不確定哪條路適合你?先試試 。如果它已經滿足需求,你就省下了好幾小時;如果你需要更多控制權——完整程式化流程、客製欄位、與 CRM 的緊密整合——上面的 Python 指南就能幫上忙。若你想更深入了解抓取工具版圖,也可以看看我們整理的 或 。
常見問題
可以用 Python 免費抓取 Yelp 嗎?
可以——使用 curl_cffi、parsel 和 jmespath 這類免費函式庫。不過只要規模稍微大一點(超過幾十頁),你就需要付費的 residential proxies,價格大約從 起。Thunderbit 也提供免費方案,每月可擷取 6 頁,適合快速、免寫程式的抓取需求。
Yelp 會封鎖爬蟲嗎?
會,而且非常積極。Yelp 使用 。原生 requests 第一個請求就會被封。本文介紹的分層防封鎖策略——curl_cffi 做 TLS 模擬、真實 headers、隨機延遲與 residential proxies——才是 2025 年有效的方法。
Yelp Fusion API 比抓取更好嗎?
要看你的需求。API 是授權且風險較低,但它只會回傳 ,搜尋結果上限是 240 筆,而且起價每月 29 美元。如果你需要完整評論文字、評論中繼資料,或每天超過幾百筆資料,那抓取才是唯一選項。
要怎麼用 Python 抓取 Yelp 評論?
使用 curl_cffi 並設定 impersonate="chrome131" 來抓商家頁,從 <meta name="yelp-biz-id"> 取出編碼後的商家 ID,接著對 https://www.yelp.com/gql/batch 發送 GetBusinessReviewFeed 操作,並透過 base64 編碼的 after cursor 做分頁。上方教學段落已提供逐步程式碼。 也是不錯的參考實作。
可以不寫程式抓 Yelp 嗎?
可以—— 已內建 和 範本。打開 Yelp 頁面,點 AI Suggest Fields,再點 Scrape 即可。匯出到 Google Sheets、Excel、Airtable 和 Notion 在所有方案都免費,包括免費方案。
了解更多