Walmart 會在某些商品上。如果你曾經試著用程式追蹤這件事,應該很懂那種痛:腳本前 20 分鐘都還正常,接著就默默開始回傳偽裝成一般 200 OK 回應的 CAPTCHA 頁面。
我在 Thunderbit 的資料擷取工作中,花了很多時間研究 Walmart 的反機器人防線,現在想把我學到的一切整理給你——哪些方法在 2025 年真的有效、哪些「無聲失敗」會把資料污染掉,以及自己寫爬蟲、付費用抓取 API,或直接用免程式工具之間,該怎麼取捨。這篇指南會涵蓋三種擷取方式(HTML 解析、__NEXT_DATA__ JSON、內部 API 攔截)、多數教學文完全略過的可上線錯誤處理,還有一套誠實的決策框架,幫你選對方法。不管你是要寫 Python,還是只想在中午前拿到一份滿滿價格的試算表,這裡都能找到答案。
為什麼要用 Python 抓取 Walmart?
Walmart 是全球營收最高的零售商——FY2025 營收達,並且。網站上大約有,而 Walmart 財務長也提到 marketplace 上有。其中約,這代表商品目錄變動非常大——賣家進出頻繁、變體常改,庫存也每天翻轉。
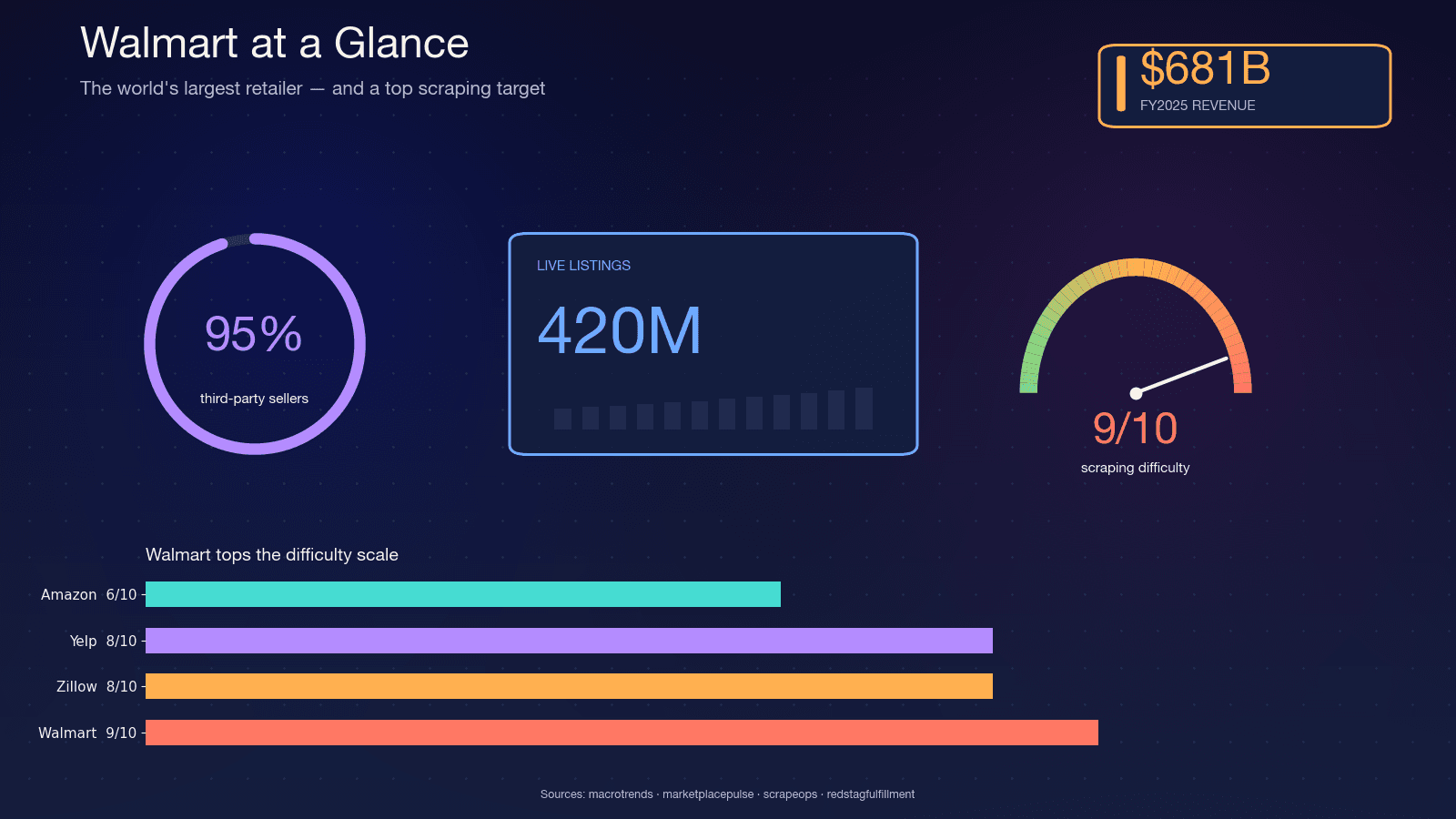
也正因為這種波動,抓取資料才有意義。季度報告抓不到夜間爬取才能看見的變化。以下是我最常看到的使用情境:
| 使用情境 | 需要這些資料的人 | 擷取內容 |
|---|---|---|
| 競品價格監控 | 電商營運、動態定價工具 | 價格、促銷、MAP 合規性 |
| 商品目錄補強 | 銷售與商品團隊 | 描述、圖片、規格、變體 |
| 庫存可用性追蹤 | 供應鏈、代發賣家 | 庫存狀態、賣家資訊 |
| 市場研究與趨勢分析 | 行銷、產品經理 | 評分、評論、分類組合 |
| 潛在客戶開發 | 銷售團隊 | 賣家名稱、商品數量、分類 |
光是,並預估在 2033 年成長到 50.9 億美元。消費者行為也推動了這筆支出:,而且 83% 會在多個網站之間比價。
Python 是這類工作的預設語言。Apify 的 2026 Infrastructure Report 指出,,而核心套件 requests 每週下載量約有。如果你要做任何規模的爬取,幾乎可以肯定會用 Python。
為什麼 Walmart 是最難抓取的網站之一
Walmart 之所以特別難抓,是因為它串聯了兩套商業反機器人產品: 作為邊緣 WAF 與 TLS 指紋辨識層,以及 作為行為式 JavaScript 挑戰層。Scrape.do 形容這個組合是「罕見而且極難繞過」。
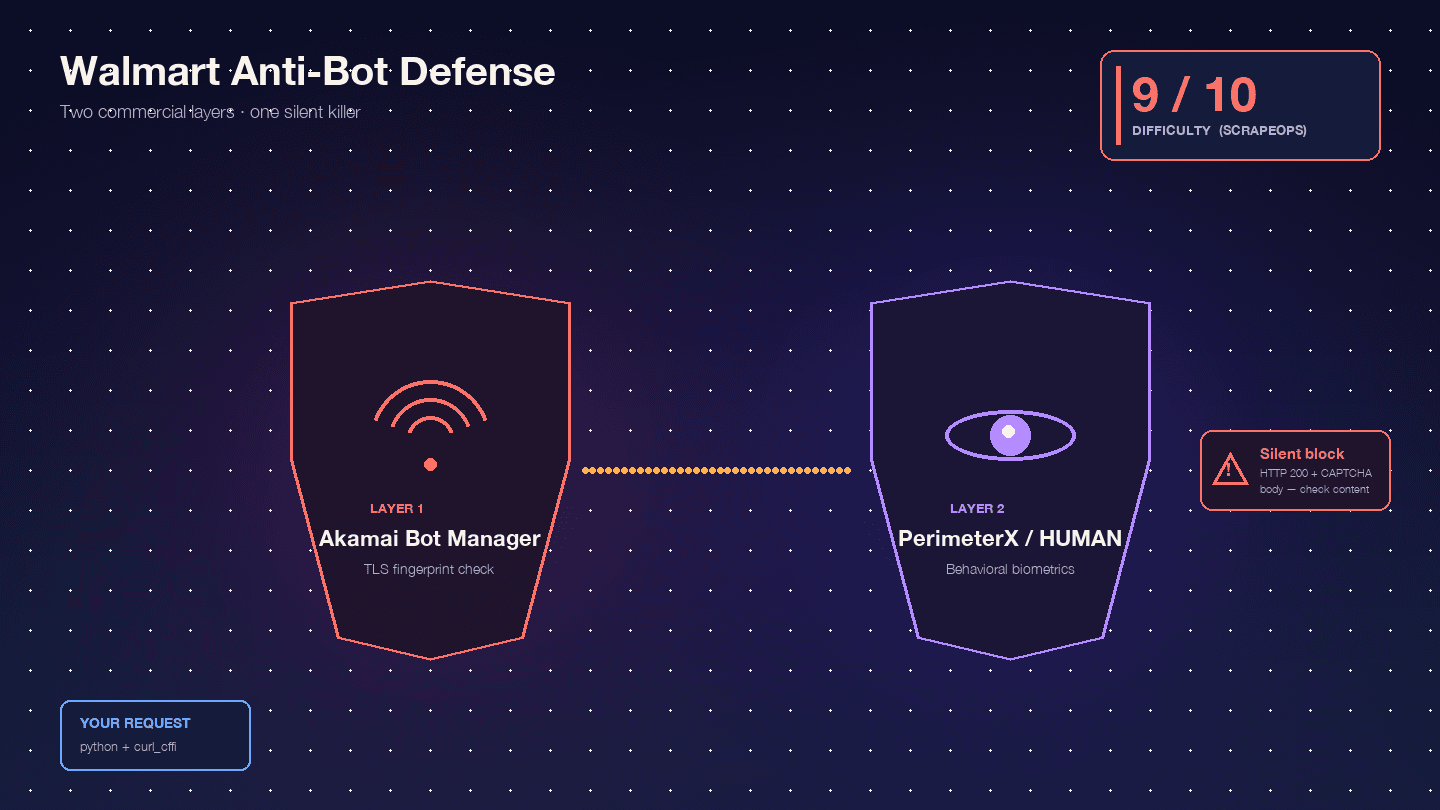
,光是 Akamai 就是 9/10。以我的經驗來看,這個評分差不多準確。
你真正要面對的是這些:
Akamai Bot Manager 會檢查你的 TLS 指紋(JA3/JA4 雜湊)、HTTP/2 frame 排序、header 順序與大小寫,以及 session cookies(_abck、ak_bmsc)。一般 Python requests 發出的 TLS 指紋,並不像任何真實瀏覽器,Akamai 會在請求還沒到 Walmart 伺服器前就先擋下來。
PerimeterX/HUMAN 會在 Akamai 之後執行,它會跑 JavaScript 指紋辨識(px.js),檢查 navigator 屬性、canvas 渲染、WebGL、音訊環境,以及行為生物特徵(滑鼠移動、捲動速度、鍵盤輸入節奏)。最常見的失敗畫面,就是惡名昭彰的——你必須長按按鈕大約 10 秒,系統會在這段時間蒐集行為訊號。Oxylabs 直白地說:「Walmart 使用的是由 PerimeterX 提供的『Press & Hold』型 CAPTCHA,幾乎不可能靠程式解掉。」
真正危險的是無聲封鎖。Walmart 會回傳HTTP 200 但內容是 CAPTCHA,而不是 403。:「Walmart 即使顯示的是 CAPTCHA 頁面,也會回傳 200 OK 狀態碼。你不能只靠狀態碼判斷請求是否成功。」你的腳本會把 CAPTCHA HTML 當成「找不到商品」繼續往下跑,結果半份資料集都變成垃圾,而且你完全不知情。
接著還有門店範圍資料問題。Walmart 的價格與庫存是依地點而定,受 locDataV3 和 assortmentStoreId 這類 cookies 控制。沒有正確 cookies 時,你拿到的是「全國預設」資料,看起來完整,卻和真實消費者看到的內容不一致。缺少 cookies 不會直接跳封鎖頁,而是會產生錯誤資料卻沒有任何可見失敗,這更糟。
從 Walmart 擷取資料的三種方法,以及它們的比較
在進入逐步教學之前,先看看三種主要擷取方式。多數競品教學只會講一兩種,我會把三種都講清楚,讓你依自己的情境挑選。
| 方法 | 可靠性 | 資料完整性 | 反機器人難度 | 維護負擔 |
|---|---|---|---|---|
| HTML + BeautifulSoup | ⚠️ 低(selector 會隨部署失效) | 中等 | 高 | 高 |
__NEXT_DATA__ JSON | ✅ 不錯 | 高 | 中高 | 中 |
| 內部 API 攔截 | ✅ 最佳 | 最高(變體、庫存、評論) | 中高 | 低(結構化 JSON) |
| Thunderbit(免程式) | ✅ 不錯 | 高 | 低(由 AI 處理) | 無 |
對 Walmart 來說,HTML 解析是最差的選項——網站採用 Next.js bundle,而且 hashed CSS class 名稱每次部署都會變。__NEXT_DATA__ JSON 才是務實解法,也是 2024–2026 年所有認真的開源 Walmart 爬蟲都在用的方法。內部 API 攔截最強,但也帶有多數教學不會講清楚的限制。而如果你根本不需要自訂資料管線,Thunderbit 就是最適合的選擇。
設定 Python 環境來抓取 Walmart
你需要的是:
- 難度: 中等
- 所需時間: 設定約 30 分鐘,加上實作時間
- 你需要準備: Python 3.10+、pip、程式編輯器,以及(若要正式上線)代理服務或抓取 API
先建立專案資料夾與虛擬環境:
1mkdir walmart-scraper && cd walmart-scraper
2python -m venv venv
3source venv/bin/activate # Windows 上:venv\Scripts\activate安裝必要套件:
1pip install curl_cffi parsel beautifulsoup4 lxmlcurl_cffi 是 2025 年處理高難度目標站的標準工具。它是 libcurl 的綁定,能精準模擬瀏覽器 TLS 指紋。:「Walmart 會把 TLS 指紋辨識當作機器人偵測的一部分,即使把 User-Agent 設成真瀏覽器,也不會繞過。」單純的 requests 或 httpx 不管你怎麼設 headers,都無法通過 Akamai。真正有差的是 curl_cffi 搭配 impersonate="chrome124"。
你也會需要 json(內建)、csv(內建)、time、random 和 logging,用來實作後面會提到的正式環境模式。
逐步教學:用 Python 抓取 Walmart 商品頁
步驟 1:抓取 Walmart 商品頁
第一件事,是發出一個不會立刻被封鎖的 HTTP 請求。以下是 2024–2026 年 Scrapfly、Scrapingdog、Oxylabs 與 ScrapeOps 都在使用的標準 header 組合:
1from curl_cffi import requests
2> This paragraph contains content that cannot be parsed and has been skipped.
3session = requests.Session(impersonate="chrome124")
4url = "https://www.walmart.com/ip/Apple-AirPods-Pro-2nd-Generation/1752657021"
5response = session.get(url, headers=HEADERS)這裡真正扛起大部分工作的,是 impersonate="chrome124" 這個參數。它會讓 curl_cffi 對齊 Chrome 124 的 TLS ClientHello、HTTP/2 frame 排序,以及 pseudo-header 順序。沒有它,Akamai 會先看到 Python 特有的 JA3 雜湊,然後在請求還沒到 Walmart 應用層之前就把你擋下來。
被封鎖的回應長什麼樣: 如果你在回應 HTML 標題中看到 "Robot or human?",或回應被重新導向到 walmart.com/blocked,代表你已經被抓到了。麻煩的是,Walmart 常常會直接回傳 200 狀態碼,但內容其實是 CAPTCHA,所以只看 response.ok 並不夠。
只要是生產用途或重複使用,你都需要住宅代理。資料中心 IP 會被 Akamai 的 IP 信譽系統迅速標記。我會在下方的正式環境章節完整說明錯誤處理與代理策略。
步驟 2:從 __NEXT_DATA__ JSON 解析商品資料
Walmart.com 是 Next.js 應用,伺服器渲染的 HTML 會把完整 hydration payload 塞進單一 script 標籤:<script id="__NEXT_DATA__" type="application/json">。這就是金礦。
:「到 2026 年,Walmart 仍使用 Next.js,且結構化 JSON 存在於 __NEXT_DATA__ script 標籤中,因此隱藏資料擷取比傳統 CSS selector 解析更可靠。」幾乎所有高知名度的開源 Walmart 爬蟲——、、——都在用這個方法。
以下是擷取方式:
1import json
2from parsel import Selector
3sel = Selector(text=response.text)
4raw = sel.xpath('//script[@id="__NEXT_DATA__"]/text()').get()
5data = json.loads(raw)
6product = data["props"]["pageProps"]["initialData"]["data"]["product"]
7idml = data["props"]["pageProps"]["initialData"]["data"].get("idml", {})多數教學到這裡就停了。下面是一份完整的 JSON 路徑對照表,列出你真正會在意的欄位——已依 2024–2026 年的即時 Walmart 頁面驗證:
This paragraph contains content that cannot be parsed and has been skipped.
longDescription 這個路徑是最容易踩雷的地方。2023 年的 ScrapeHero 文章把它放在 product.longDescription,但 2024 之後的資料來源都一致把它放在同層的 idml key。一定要先讀 idml.longDescription,再在舊頁面上回退到 product.longDescription。
以下是使用 .get() 鏈結的安全擷取模式:
1def extract_product(data):
2 product = data["props"]["pageProps"]["initialData"]["data"]["product"]
3 idml = data["props"]["pageProps"]["initialData"]["data"].get("idml", {})
4 price_info = product.get("priceInfo", {})
5 current_price = price_info.get("currentPrice", {})
6 image_info = product.get("imageInfo", {})
7> This paragraph contains content that cannot be parsed and has been skipped.
8如果你完全不想碰 JSON 路徑導航,[Thunderbit 的 AI](https://thunderbit.com/) 會自動辨識並結構化這些欄位——不需要手動對應路徑。你只要點一下「AI 建議欄位」,它就會讀取頁面並產生表格。但如果你是在建立自訂資料管線,上面的對照表就是你的參考基準。
9### 步驟 3:攔截 Walmart 的內部 API 端點,取得更豐富資料
10幾乎沒有競品文章把這方法講清楚。它是最強的擷取路徑,也是最複雜的一種。
11Walmart 前端會呼叫一個[建立在 Apollo Gateway 上的聯邦 GraphQL 後端](https://medium.com/walmartglobaltech/federated-graphql-walmart-bfc85c2553de)。這些端點都掛在 `www.walmart.com/orchestra/*` 底下:
12- `/orchestra/pdp/graphql/...` — 商品詳情 hydration + 變體切換
13- `/orchestra/snb/graphql/...` — 搜尋與瀏覽分頁
14- `/orchestra/reviews/graphql/...` — 分頁評論
15這些 API 會回傳乾淨、結構化的 JSON,而 `__NEXT_DATA__` 有時候會截斷這些資料——例如變體層級定價、即時庫存數量、完整評論分頁。
16**多數部落格文章避而不談的關鍵點:** Walmart 使用的是 [Apollo persisted queries](https://crawlee.dev/blog/graphql-persisted-query)。請求主體只送出 SHA-256 雜湊(`persistedQuery.sha256Hash`),不會送出 query 文字。如果伺服器不認得這個雜湊,就會得到 `PersistedQueryNotFound`。Walmart 會在部署時輪替這些雜湊。這也是為什麼沒有高知名度的開源 Walmart 爬蟲會直接公開可複製貼上的 `/orchestra/` 程式碼。
17這個方法最務實、也最誠實的做法,是用 DevTools 來操作:
181. 在 Chrome 打開 Walmart 商品頁
192. 開啟 DevTools → Network 分頁,篩選「Fetch/XHR」
203. 正常瀏覽頁面——點變體、捲到評論區、切換門店位置
214. 留意回傳商品資料的 `/orchestra/*` 請求
225. 在請求上按右鍵 →「Copy as cURL」
236. 再用 `curl_cffi` 把 cURL 指令轉成 Python
24以下是一個重放 API 呼叫的範例:
25```python
26import json
27from curl_cffi import requests
28session = requests.Session(impersonate="chrome124")
29# 先拜訪商品頁,讓 session 變暖
30session.get("https://www.walmart.com/ip/some-product/1234567", headers=HEADERS)
31> This paragraph contains content that cannot be parsed and has been skipped.
32api_response = session.post(api_url, headers=api_headers, json=payload)
33api_data = api_response.json()session 變暖這一步非常關鍵。Walmart 的 PerimeterX cookies(_px3、_pxhd、ACID)必須先透過初始 HTML 取得並設好,後面的 API 呼叫才會成功。沒有這些 cookies,你就會拿到 412 或 403。
什麼時候該用這個方法: 當你需要 __NEXT_DATA__ 沒有包含的資料——例如深層變體價格、第一批以外的分頁評論、或即時庫存數量。對多數情境來說,__NEXT_DATA__ 已經夠用,而且簡單得多。
抓取 Walmart 搜尋結果與多頁資料
搜尋結果也遵循類似的 __NEXT_DATA__ 模式,但 JSON 路徑不同:
1search_url = "https://www.walmart.com/search?q=laptops&page=1"
2response = session.get(search_url, headers=HEADERS)
3sel = Selector(text=response.text)
4raw = sel.xpath('//script[@id="__NEXT_DATA__"]/text()').get()
5data = json.loads(raw)
6search_result = data["props"]["pageProps"]["initialData"]["searchResult"]
7items = search_result["itemStacks"][0]["items"]
8# 過濾贊助商品
9organic_items = [i for i in items if i.get("__typename") == "Product"]
10for item in organic_items:
11 print(item.get("name"), item.get("priceInfo", {}).get("currentPrice", {}).get("price"))分頁的做法是遞增 page 參數:&page=1、&page=2,依此類推。不過這裡有個沒寫在文件裡的上限:無論實際總頁數多少,Walmart 都只允許搜尋結果最多 25 頁。 :「不管可用總頁數是多少,Walmart 都將可存取的結果頁上限設為 25 頁。」
要取得更深的覆蓋範圍,可以試這些繞法:
- 切換排序:同一查詢先跑
&sort=price_low,再跑&sort=price_high,大約可拿到 50 頁的覆蓋 - 價格區間切片:加上
&min_price=X&max_price=Y,把目錄拆成更小區段 - 分類切片:在特定分類內搜尋,不要全站搜尋
也要注意,itemStacks 是陣列。Scrapfly 在 repo 裡直接寫死 [0],但分類頁與瀏覽頁有時會出現多個 stack(例如「Top picks」、「More results」)。更穩健的寫法是遍歷所有 stacks:
1for stack in search_result.get("itemStacks", []):
2 for item in stack.get("items", []):
3 if item.get("__typename") == "Product":
4 # 處理 item
5 pass另外值得一提的是:Walmart 的 robots.txt。商品詳情頁(/ip/...)和大多數分類頁(/cp/...)則沒有被禁止。如果你在意合規性,建議先從商品頁與分類樹開始,而不是搜尋頁。
別讓無聲封鎖毀掉你的資料:可上線的錯誤處理
多數教學到這裡就崩了。它們只示範怎麼抓一頁、解析一個商品,然後就收工。到了正式環境,你會一次抓幾千頁,而且 Walmart 也在積極阻擋你。Demo 爬蟲和真正能運作的爬蟲,差別就在於它怎麼處理失敗。
在資料被污染前,先偵測無聲封鎖
Walmart 爬蟲最重要的函式,就是封鎖偵測器。根據 、、 與 等供應商的共識,你至少需要四個獨立檢查:
1BLOCK_MARKERS = (
2 "Robot or human",
3 "Press & Hold",
4 "Press & Hold",
5 "px-captcha",
6 "perimeterx",
7)
8def is_walmart_blocked(response) -> bool:
9 # 1. 重新導向到專用封鎖端點
10 if "/blocked" in str(response.url):
11 return True
12 # 2. 明確的狀態碼
13 if response.status_code in (403, 412, 428, 429, 503):
14 return True
15 # 3. 200 OK 但內容是 CAPTCHA(無聲封鎖案例)
16 body = response.text or ""
17 if any(m.lower() in body.lower() for m in BLOCK_MARKERS):
18 return True
19 # 4. 回應長度檢查——真正的 PDP 通常有 300–900 KB
20 if len(response.content) < 50_000 and "/ip/" in str(response.url):
21 return True
22 return False第四項檢查——回應長度——可以抓出那種被簡化過的頁面:它們沒有明顯 CAPTCHA 標記,但也沒有你要的商品資料。
使用指數退避與抖動的重試邏輯
請求失敗時,不要立刻猛打 Walmart。標準做法是使用帶抖動的指數退避,避免重試節奏同步:
1import time
2import random
3import logging
4from curl_cffi import requests as cffi_requests
5log = logging.getLogger("walmart")
6def fetch_with_retry(session, url, max_retries=5, base_delay=2, max_delay=60):
7 for attempt in range(max_retries):
8 try:
9 response = session.get(url, headers=HEADERS, timeout=15)
10 if response.status_code in (429, 503):
11 raise Exception(f"Throttled: {response.status_code}")
12 if is_walmart_blocked(response):
13 raise Exception("Silent block detected")
14 return response
15 except Exception as e:
16 if attempt == max_retries - 1:
17 raise
18> This paragraph contains content that cannot be parsed and has been skipped.
19 return None這個抖動(random.uniform(0, 3))不是裝飾而已——它能讓多個爬蟲工作者不同步,避免整批爬蟲在同一秒重試,觸發 Akamai 的速率偵測。
速率限制
和 對 Walmart 的建議都收斂到:每個請求間隨機延遲 3–6 秒——「在頁面載入之間等待 3–6 秒,並且把延遲隨機化。」
1import time
2import random
3def rate_limited_fetch(session, url):
4 response = fetch_with_retry(session, url)
5 time.sleep(random.uniform(3.0, 6.0))
6 return response如果規模更大,可以考慮用 aiolimiter 做非同步速率限制:
1from aiolimiter import AsyncLimiter
2limiter = AsyncLimiter(max_rate=10, time_period=60) # 每分鐘 10 個請求資料驗證
即使回應沒有被封鎖,解析後的資料也可能是錯的(門店錯誤、payload 降級)。在寫出之前先驗證:
1def validate_product(product):
2 """如果商品資料看起來合理,就回傳 True。"""
3 if not product.get("name"):
4 return False
5> This paragraph contains content that cannot be parsed and has been skipped.
6 if product.get("availabilityStatus") not in ("IN_STOCK", "OUT_OF_STOCK", "LIMITED_STOCK"):
7 return False
8 return TrueSession 記錄
追蹤每個 session 的成功率。當 10 分鐘內低於 80%,就代表有東西變了——可能是 IP 已經被燒掉、cookies 過期,或 Walmart 部署了新的反機器人規則。
1class ScrapeMetrics:
2 def __init__(self):
3 self.total = 0
4 self.success = 0
5 self.blocks = 0
6 self.errors = 0
7 def record(self, result):
8 self.total += 1
9 if result == "success":
10 self.success += 1
11 elif result == "blocked":
12 self.blocks += 1
13 else:
14 self.errors += 1
15 @property
16 def success_rate(self):
17 return (self.success / self.total * 100) if self.total > 0 else 0
18> This paragraph contains content that cannot be parsed and has been skipped.
19不花俏,但這正是讓資料保持乾淨的關鍵。
20## 自己寫 Python、用抓取 API,還是免程式工具?如何選擇抓取 Walmart 的方式
21很多開發者會直接跳進去寫自訂爬蟲,卻沒有先問這是不是最適合的做法。[ScrapeOps 把 Walmart 的難度評為 9/10](https://scrapeops.io/websites/walmart/)。論壇使用者也常說它「基本上就是 9/10」,並懷疑「是不是需要專門的網頁抓取 API 才不會太大材小用」。答案取決於資料量、預算與工程能力。
22<Table content={`| **因素** | **DIY Python(requests + 代理)** | **抓取 API(Oxylabs、Bright Data 等)** | **免程式工具([Thunderbit](https://thunderbit.com/))** |
23|---|---|---|---|
24| 拿到第一筆資料的設定時間 | 幾小時 | 15–60 分鐘 | 約 2 分鐘 |
25| 上線到可用的設定時間 | 40–80 小時 | 4–16 小時 | 約 30 分鐘 |
26| 反機器人處理 | 你自己處理(很難) | 由供應商處理 | 自動處理 |
27| 小規模成本(<1K 頁/月) | 低(代理成本約 $4–8/GB) | $40–$49/月起 | 免費–$15/月 |
28| 大規模成本(10 萬頁以上/月) | 單次請求成本更低 | 單次請求成本較高 | 視情況而定 |
29| 客製化程度 | 完全掌控 | API 參數 | 受介面/欄位限制 |
30| 持續維護 | 每月 4–8 小時 | 幾乎為零 | 無(AI 自動適應) |
31| 最適合誰 | 建立自訂資料管線的開發者 | 中等規模的正式爬取 | 商務使用者、快速單次擷取 |`} />
32### 什麼時候 DIY Python 最合理
33如果你已經有代理合約、需要嚴格控制 headers、郵遞區號或賣家群組,或你每月要索引數百萬頁、單筆 API 費用會快速累積,DIY 就很有道理;或者你需要本地部署或合規保證。代價是真實的工程時間:一個可上線的 Scrapy spider,要處理分頁、重試、代理輪換、TLS 模擬,以及多種頁型 schema,通常需要[40–80 小時的資深 Python 工時](https://scrapeops.io/python-web-scraping-playbook/python-scrape-walmart/),之後還要每月 4–8 小時維護,因為 Walmart 會輪換指紋。
34### 什麼時候抓取 API 能幫你省時間
35抓取 API 會替你處理反機器人層,讓你不用自己扛。[ScrapeOps 基準測試](https://scrapeops.io/websites/walmart/)顯示,Walmart 上 [**Zyte API 成功率達 99%**](https://scrapeops.io/websites/walmart/),[**Scrape.do 則有 98%**](https://scrapeops.io/websites/walmart/)。像 [ScraperAPI](https://www.scraperapi.com/pricing/)、[Oxylabs](https://oxylabs.io/products/scraper-api/ecommerce)、[Scrapingdog](https://www.scrapingdog.com/pricing/) 這類工具,入門方案大約是每月 $40–$49。如果你是 2–5 人的團隊、每月抓取量在 1 萬到 100 萬頁之間,API 幾乎總是比較對的選擇。你用每次請求的成本,換到零維護。
36### 什麼時候免程式工具才是正解
37[Thunderbit](https://thunderbit.com/) 適合的是完全不同的一群人。如果你是 PM、分析師或電商營運,今天下午就想把 Walmart 商品資料放進試算表,而不是等到下個衝刺,那免程式工具就是最誠實的答案。
38工作流程很簡單:安裝 [Thunderbit Chrome 擴充功能](https://chromewebstore.google.com/detail/thunderbit-ai-web-scraper/hbkblmodhbmcakopmmfbaopfckopccgp),打開 Walmart 商品頁或搜尋頁,點「AI 建議欄位」,Thunderbit 的 AI 就會讀頁面並建議欄位(商品名稱、價格、評分等)。按下「抓取」,資料就會填進表格。再匯出到 Excel、Google Sheets、Airtable 或 Notion——全都免費,沒有付費牆。
39Thunderbit 在雲端處理反機器人問題,所以你不用碰 CAPTCHA、代理或 TLS 指紋辨識。AI 也會自動適應版面變化,因此沒有維護負擔。對於完全不想碰 JSON 路徑導航的人來說,這是阻力最小的路。
40誠實的限制是:Thunderbit 不是為每天 10 萬頁以上設計的。信用額度與雲端上限,會讓高量匯入相較於原生 API 不划算。除非工具本身支援,否則你也無法固定特定郵遞區號或 ASN。若是持續性的高流量管線,DIY 或抓取 API 仍然是較好的選擇。
41**粗略價格估算:** 在 Thunderbit 上抓 1,000 筆 Walmart 商品列,大約需要 2,000 credits(Starter/Pro 方案約 $0.60–$1.10)。這和 Oxylabs 的 Walmart API 差不多,且在低量情境下比多數業餘等級的抓取 API 更便宜。[查看 Thunderbit 定價](https://thunderbit.com/pricing)以取得最新資訊。
42<SideCard url={"https://thunderbit.com/"} title={"用 AI 抓取 Walmart 商品資料"} description={""} />
43## 匯出你抓到的 Walmart 資料
44拿到資料後,你需要把它放到有用的地方。以下三種格式足以應付大多數需求:
45**CSV**——分析師真的會打開的最低公分母格式:
46```python
47import csv
48> This paragraph contains content that cannot be parsed and has been skipped.
49請使用 `utf-8-sig` 編碼,才能相容 Excel。BOM 標記可以避免 Excel 把特殊字元弄壞。
50**JSONL**——爬蟲管線的正式格式:
51```python
52import json
53import gzip
54def export_jsonl(products, filename="walmart_products.jsonl.gz"):
55 with gzip.open(filename, "at", encoding="utf-8") as f:
56 for p in products:
57 f.write(json.dumps(p, ensure_ascii=False) + "\n")(中斷寫入通常只會損失最後一行)、可用串流方式處理且記憶體占用固定,還能保留像變體與評論這類巢狀資料。
Excel——適合一次性交接給分析師:
1from openpyxl import Workbook
2def export_excel(products, filename="walmart_products.xlsx"):
3 wb = Workbook(write_only=True)
4 ws = wb.create_sheet("Products")
5 ws.append(["Name", "Price", "Availability", "Rating", "Reviews", "Seller"])
6 for p in products:
7 ws.append([p.get("name"), p.get("price"), p.get("availability"),
8 p.get("rating"), p.get("review_count"), p.get("seller")])
9 wb.save(filename)對非 Python 使用者來說,Thunderbit 也把匯出流程包好了:可一鍵匯出到 Google Sheets、Airtable、Notion、Excel、CSV 和 JSON——基本方案全都免費。如果你要持續監控,Thunderbit 的排程爬蟲功能也能自動重複執行擷取。
關於排程有一個提醒:。GitHub Actions 的 runner 位於 Azure IP 段,Walmart 的反機器人會立刻封鎖。請改用 VPS 上的 APScheduler,或把所有流量都經由住宅代理轉送。
抓取 Walmart 的法律與倫理指南
論壇使用者也直接表達了這個顧慮:「我不介意和開發者玩貓捉老鼠,但我很擔心和他們的法務團隊玩。」
Walmart 的使用條款在未經「事先書面明示同意」的情況下,使用「任何機器人、蜘蛛…或其他手動或自動裝置來擷取、索引、『抓取』、『資料探勘』或以其他方式蒐集任何素材」。
Walmart 的 robots.txt /search、/account、/api/ 以及數十個內部端點。商品詳情頁(/ip/...)和評論頁(/reviews/product/)則沒有被禁止。
hiQ v. LinkedIn 判例(第 9 巡迴法院,)確立了抓取公開可見資料通常不太可能違反聯邦 CFAA。不過同一法院後來又裁定,並對其下達。更近期的 2024 年判決(、)進一步限縮了 CFAA,並建立了著作權優先排除的抗辯,但那些裁定都建立在特定使用條款語句上,無法直接套用到 Walmart。
實務建議: 不要把伺服器壓爆。尊重速率限制。不要抓取個資或使用者資料。負責任地使用資料。以適度速率抓取公開 Walmart 商品頁、供個人研究,和以商業規模對抗 Walmart 條款的風險等級完全不同。如果你要基於 Walmart 資料打造產品,請找律師,並研究 Walmart 官方的。
免責聲明: 這是教育資訊,不是法律建議。
結論與重點整理
由於 Walmart 採用雙層 Akamai + PerimeterX 反機器人堆疊,用 Python 抓 Walmart 是一項。不是不可能,但你需要正確的工具與模式。
重點整理:
__NEXT_DATA__JSON 擷取是多數情境下最務實的選擇。 這也是所有認真的 2024–2026 開源 Walmart 爬蟲在使用的方法。PDP 的基本路徑是props.pageProps.initialData.data.product,搜尋/瀏覽頁則是searchResult.itemStacks。curl_cffi搭配impersonate="chrome124"是必需的。 單靠requests或httpx,不管 headers 怎麼設,都過不了 Akamai 的 TLS 指紋辨識。- 無聲封鎖才是真正的危險。 Walmart 會回傳 200 OK 但內容是 CAPTCHA。請檢查 response 內容,不要只看狀態碼。
- 正式爬蟲需要的不只是 happy-path 程式碼。 帶抖動的指數退避、四種信號的封鎖偵測、每個請求 3–6 秒的速率限制、資料驗證與 session 健康監控,都是必備。
- 透過
/orchestra/*攔截內部 API 很強,但也很脆弱。 把它當作針對特定資料需求的 DevTools 練習,而不是主要擷取方式。 - Walmart 會把搜尋結果上限限制在 25 頁。 可以透過切換排序與價格區間切片來擴大覆蓋範圍。
- 誠實選擇你的方法: 有自訂需求、資料量高的開發者適合 DIY Python;沒有爬蟲工程師的中型團隊適合抓取 API;想今天下午就把資料放進 Google Sheets 的商務使用者,適合 。
如果你想先試試免程式路線,有免費方案——你可以先抓幾頁 Walmart 頁面,親自看看結果。如果你要走 Python 路線,這篇文章裡的程式模式都已經過生產驗證。不管哪條路,現在你都有了 Walmart 防線的地圖,以及穿越它們的三條路徑。
想看更多網頁爬取技巧,可以參考我們的指南:、、以及。你也可以到 觀看教學影片。
常見問題
抓取 Walmart 商品資料合法嗎?
Walmart 的使用條款禁止在未經書面同意下進行自動化抓取。第 9 巡迴法院在 hiQ v. LinkedIn(2022)案中確立,聯邦 CFAA 不太可能適用於抓取公開頁面,但同案最後仍以對抓取方不利。以適度速率抓取公開商品頁供個人研究,和商業規模擷取的風險完全不同。如果你要基於 Walmart 資料建立商業模式,請先諮詢律師。
為什麼我的 Walmart 爬蟲一直被封鎖?
最常見的原因包括:使用一般 requests 或 httpx(會產生 Akamai 會立刻標記的 Python 特有 TLS 指紋)、headers 缺失或錯誤、沒有代理輪換、每頁請求速度快於 3–6 秒、以及 session cookies 缺失(_px3、_abck、locDataV3)。請改用 impersonate="chrome124" 的 curl_cffi、使用住宅代理,並實作本文所述的封鎖偵測與重試模式。
用 Python 可以從 Walmart 抓到哪些資料?
商品名稱、價格(當前價與回復價)、圖片、簡短與詳細描述、評分、評論數、庫存可用狀態、賣家名稱、製造商資訊、變體選項(尺寸、顏色)以及分類位置。使用 __NEXT_DATA__ 方法時,這些都會以結構化 JSON 提供。內部 API 攔截還能額外回傳變體層級價格、即時庫存數量與分頁評論資料。
抓取 Walmart 需要代理嗎?
需要,凡是正式用途或重複使用都需要。——就算 headers 完美,非住宅 IP 還是會被 Akamai 的 IP 信譽系統標記。必須使用住宅或行動代理。資料中心 IP 幾乎會立刻失效。你可以粗估每 1,000 頁約需 $3–$17,視代理供應商與方案而定。
可以不用寫程式就抓 Walmart 嗎?
可以。 是一個 AI 驅動的 Chrome 擴充功能,只要兩步就能抓 Walmart:先點「AI 建議欄位」自動偵測商品資料欄位,再按「抓取」把資料擷取出來。它會在雲端處理反機器人挑戰,並可直接匯出到 Excel、Google Sheets、Airtable 或 Notion——全部免費。它最適合分析師、PM 與需要快速拿到資料、但不想自己建立自訂管線的商務使用者。若是高流量或高度客製化的抓取,Python 或抓取 API 仍然更適合。
了解更多