

在我第 50 次把 Indeed 上的職缺標題複製貼到試算表時,我開始懷疑自己的人生選擇。如果你曾經試著用程式化方式從 Indeed 擷取結構化資料,你一定懂這個笑點:403 錯誤不是 bug,而是 Indeed 防禦系統的一部分。
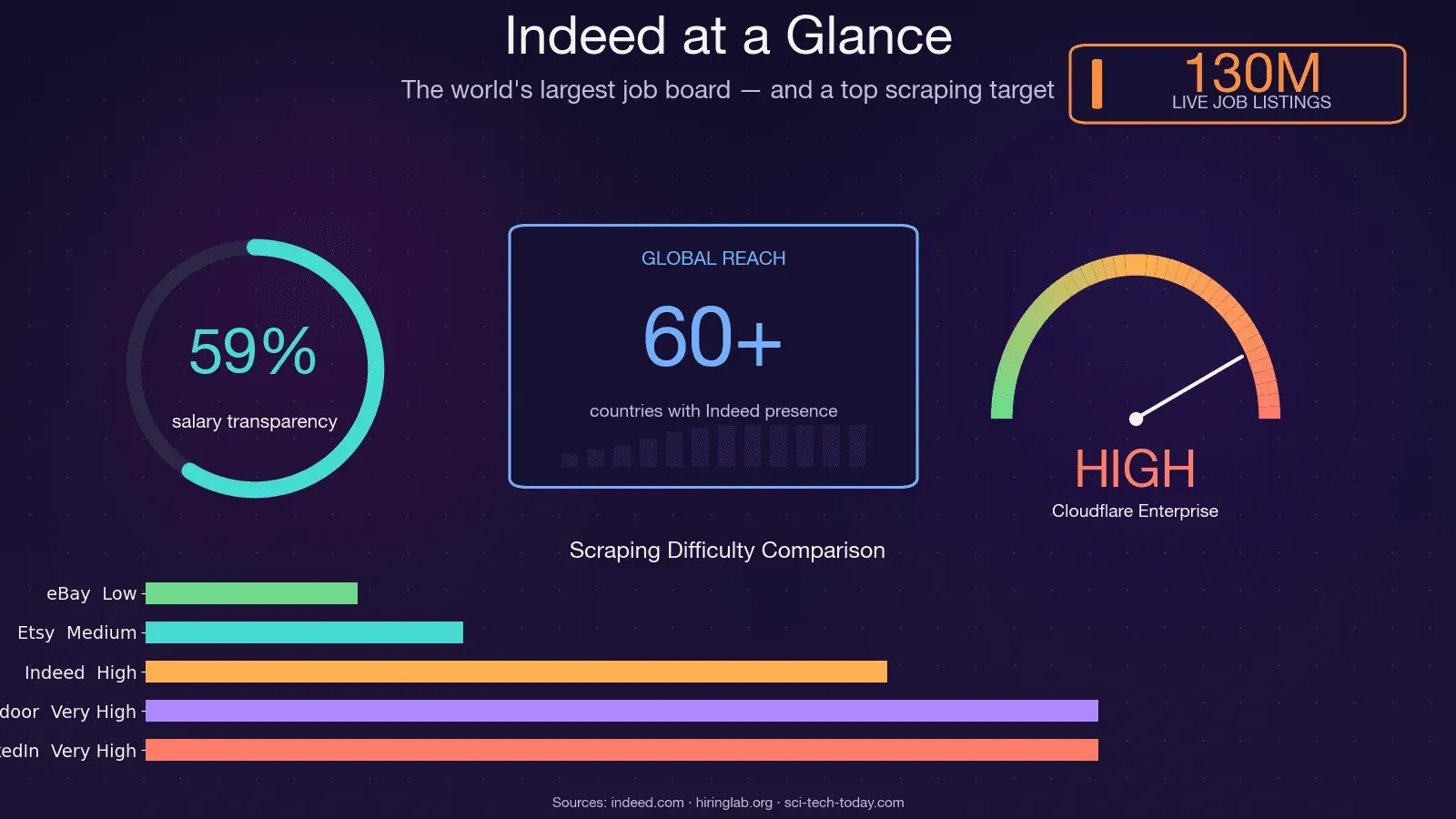
Indeed 是全球最大的求職平台,每月約有 3.5 億不重複訪客、隨時約有 1.3 億則職缺,並在 60 多個國家營運。這讓它成為全球最豐富的職場資料來源之一,也讓它成為最難抓取的網站之一。開源爬蟲 JobFunnel(GitHub 上有數千顆星)在歷經多年與反機器人大戰後,已於 2025 年 12 月被維護者本人 封存。維護者自己也說得很直接:「所有使用者都能抓到一些職缺,但很快就會遇到 captcha,接著抓取失敗,最後什麼職缺都拿不到。」 另一位貢獻者甚至回報,第一次請求就遇到 CAPTCHA on the very first request。所以,沒錯——這絕對不是個簡單的抓取目標。這篇指南會帶你走過所有用 Python 抓取 Indeed 的實用方法,示範如何真正撐過 403 門檻;如果你想完全跳過除錯,我也會展示一個使用 Thunderbit 的免程式替代方案。
用 Python 抓取 Indeed 是什麼意思?
網頁爬蟲的核心,就是自動從網頁中擷取結構化資料。當我們說用 Python 抓取 Indeed,意思是寫一支程式去拜訪 Indeed 的搜尋結果頁與職缺詳情頁,讀取底層 HTML(或嵌入資料),然後把職稱、公司、地點、薪資與描述等欄位整理成可用格式——例如 CSV、資料庫或 Google 試算表。
常見會用到的 Python 套件包括 Requests(HTTP 請求)、BeautifulSoup(HTML 解析),以及 Selenium 或 Playwright(瀏覽器自動化)。但 Indeed 不是一般的靜態網站;它是混合型架構:伺服器渲染的 HTML,加上內嵌的 JSON 狀態資料,再由 Cloudflare Bot Management 擋在前面。也就是說,你的爬蟲得先處理 JavaScript 渲染內容、輪換的 CSS 類別名稱,以及積極的反機器人防護——然後才能開始解析第一個職缺標題。
而且到了 2026 年,也沒有官方、免費、唯讀的 Indeed API。以前的 Publisher Jobs API 大約在 2020 年已停用,現在剩下的主要是雇主端功能(Job Sync、Sponsored Jobs)。所以,實務上只剩兩條路:抓取,或付費給第三方資料供應商。
為什麼要抓取 Indeed 的職缺資料?
抓取 Indeed 的商業理由很直接:手動瀏覽成千上萬筆職缺根本不實際,而且這些資料本身非常有價值。
| 使用情境 | 受益對象 | 範例 |
|---|---|---|
| 開發潛在客戶 | 業務與招募團隊 | 建立附聯絡資訊的招募中公司名單 |
| 職場市場研究 | 分析師、人資團隊 | 找出熱門技能、各地區薪資基準 |
| 競爭情報 | 雇主、派遣/人力資源公司 | 監控競爭對手的招募趨勢與薪資開價 |
| 個人求職自動化 | 求職者 | 彙整多地區符合條件的職缺 |
| 機器學習模型訓練資料 | 資料科學家 | 以歷史職缺資料建立薪資預測模型 |
Indeed Hiring Lab 自己的研究也 證實:職缺發布資料與 BLS JOLTS 高度相關,可作為美國勞動市場近乎即時的代理指標。避險基金會把職缺發布速度當作另類資料訊號。人資團隊會用抓下來的薪資區間做薪酬基準比較。招募人員則會從正在積極招人的公司建立潛在名單。
一個實務提醒:Indeed 上的薪資資料雖然越來越完整,但仍不夠齊全。到了 2025 年中,美國約有 59% 的職缺包含薪資資訊,但只有約 22% 提供精確金額,其餘多半只有區間。任何基於 Indeed 薪資資料的分析,都應把這種缺漏考慮進去。
如何選擇用 Python 抓取 Indeed 的方法
抓取 Indeed 沒有唯一「正確」的方法。最好的做法取決於你的技術程度、需要多少資料,以及你願意承受多少維護成本。我測過四種主流方法,下面是比較:
| 評估標準 | BS4 + Requests | Selenium | 隱藏 JSON(window.mosaic) | 免程式(Thunderbit) |
|---|---|---|---|---|
| 難度 | 初學者 | 中階 | 中階到進階 | 幾乎不用(2 次點擊) |
| 速度 | 快 | 慢(瀏覽器渲染) | 快 | 快(雲端抓取) |
| JS 渲染內容 | 否 | 是 | 是(內嵌資料) | 是 |
| 反機器人韌性 | 低 | 中 | 中高 | 高(自動處理) |
| HTML 變動時的維護成本 | 高(選擇器容易壞) | 高 | 中(JSON 結構較穩) | 幾乎沒有(AI 會自適應) |
| 最適合 | 快速原型 | 動態頁面、需登入頁面 | 大量結構化資料 | 非工程人員、快速出結果 |
這篇指南會逐一介紹每種方法。如果你是 Python 開發者,請看 BS4、隱藏 JSON 與 Selenium 章節。如果你不是工程背景,或者只是受夠了 403 除錯,請直接跳到 Thunderbit 章節。
開始之前
- 難度: 初學者到中階(Python 章節);無(Thunderbit 章節)
- 所需時間: Python 環境設定與第一次抓取約 20–60 分鐘;使用 Thunderbit 約 2 分鐘
- 你需要準備: Python 3.9+、程式編輯器、Chrome 瀏覽器,以及(免程式路線)Thunderbit Chrome 擴充功能
為 Indeed 抓取設定 Python 環境
在開始寫任何抓取程式碼之前,先把環境準備好。
安裝必要套件
建立虛擬環境並安裝所需套件:
python -m venv indeed_env
source indeed_env/bin/activate # 在 Windows 上:indeed_env\Scripts\activate
# HTTP + 解析方案
pip install requests beautifulsoup4 lxml httpx
# 隱藏 JSON 方案(推薦)
pip install curl_cffi parsel tenacity
# 瀏覽器自動化方案
pip install selenium
幾點補充:
curl_cffi是 2026 年抓取受 Cloudflare 保護網站的預設選擇。它能模擬真實瀏覽器的 TLS 指紋,而一般requests和httpx做不到。這在反機器人章節會再說明。- Selenium 4.6+ 內建 Selenium Manager,所以你不必再手動下載 ChromeDriver——它會自動管理瀏覽器元件。
- BeautifulSoup 的解析後端請用
lxml。它大約比標準庫的html.parser快 1.5 倍。
建立專案結構
保持簡單就好:
indeed_scraper/
├── scraper.py
├── requirements.txt
└── output/
下面所有程式範例都以 scraper.py 為基礎。
如何使用 BeautifulSoup 抓取 Indeed
這是最適合初學者的方式:用 requests 取得頁面,再用 BeautifulSoup 解析 HTML。它上手最快,但在 Indeed 上也最脆弱。
步驟 1:建立 Indeed 搜尋網址
Indeed 的搜尋網址有固定格式:
https://www.indeed.com/jobs?q=<query>&l=<location>&start=<offset>
例如,搜尋「data analyst」,地點是「Austin, TX」,從第一頁開始:
from urllib.parse import urlencode
params = {
"q": "data analyst",
"l": "Austin, TX",
"start": 0,
}
url = f"https://www.indeed.com/jobs?{urlencode(params)}"
print(url)
# https://www.indeed.com/jobs?q=data+analyst&l=Austin%2C+TX&start=0
Indeed 的分頁每 10 筆一頁,總筆數上限為 1,000 筆(start <= 990)。任何大於 990 的 offset 都會悄悄回傳同一頁。
步驟 2:用正確的標頭送出 HTTP 請求
Indeed 會立刻封鎖使用 Python 預設 user-agent 的請求。你需要真實感較高的標頭:
import requests
headers = {
"User-Agent": (
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36"
),
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Referer": "https://www.indeed.com/",
}
response = requests.get(url, headers=headers, timeout=30)
print(response.status_code)
如果你拿到 200,代表暫時通過了。如果是 403,就表示被 Cloudflare 擋下了。(後面會教你怎麼撐過去。)
步驟 3:從 HTML 解析職缺列表
用 BeautifulSoup 選取職缺卡片元素。請鎖定 data-testid 屬性——它比 Indeed 會亂變的 CSS 類別名稱穩定得多:
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.text, "lxml")
cards = soup.find_all("div", attrs={"data-testid": "slider_item"})
jobs = []
for card in cards:
title_el = card.find("h2", class_="jobTitle")
title = title_el.get_text(strip=True) if title_el else None
company = card.find(attrs={"data-testid": "company-name"})
location = card.find(attrs={"data-testid": "text-location"})
link = title_el.find("a")["href"] if title_el and title_el.find("a") else None
jobs.append({
"title": title,
"company": company.get_text(strip=True) if company else None,
"location": location.get_text(strip=True) if location else None,
"url": f"https://www.indeed.com{link}" if link else None,
})
print(f"找到 {len(jobs)} 筆職缺")
步驟 4:處理分頁
透過遞增 start 參數來迴圈抓取各頁:
import time, random
all_jobs = []
for page in range(0, 50, 10): # 前 5 頁
params["start"] = page
url = f"https://www.indeed.com/jobs?{urlencode(params)}"
response = requests.get(url, headers=headers, timeout=30)
# ... 如上解析 ...
all_jobs.extend(jobs)
time.sleep(random.uniform(3, 6))
這種方法的限制
老實說:BS4 + Requests 是 2026 年抓取 Indeed 最弱的一種方法。純 requests 使用 Python 標準庫的 TLS,會產生 Cloudflare 一眼就能辨識出「不是瀏覽器」的 JA3 指紋。它也不支援 Indeed 會回傳的 HTTP/2。你很可能在抓幾頁之後就被擋下。至於 CSS 選擇器?Indeed 會經常 輪換 像 css-1m4cuuf 和 jobsearch-JobComponent-embeddedBody-1n0gh5s 這類類別名稱——因此任何依賴它們的選擇器都像是計時炸彈。
這種方法適合單頁快速原型;如果你要認真大量抓取,請改用隱藏 JSON 方案。
如何使用隱藏 JSON 資料抓取 Indeed
這是我推薦給多數 Python 開發者的方法。與其解析脆弱的 HTML 元素,不如直接從 Indeed 頁面原始碼裡嵌入的 JavaScript 變數中擷取結構化資料:window.mosaic.providerData["mosaic-provider-jobcards"]。
你關心的每個欄位——職稱、公司、地點、薪資、職缺 key、發布日期、遠端標記——都已經在這個 JSON 區塊裡了。不需要執行 JavaScript。這個 schema 至少從 2023 年以來就相當 穩定,比 DOM 選擇器耐用得多。
步驟 1:抓取頁面 HTML
請用 curl_cffi 取代 requests——它能模擬真實瀏覽器的 TLS 指紋,這對撐過 Cloudflare 非常關鍵:
from curl_cffi import requests as cffi_requests
response = cffi_requests.get(
"https://www.indeed.com/jobs?q=python+developer&l=Remote&start=0",
impersonate="chrome124",
headers={
"Accept-Language": "en-US,en;q=0.9",
"Referer": "https://www.indeed.com/",
},
timeout=30,
)
print(response.status_code, len(response.text))
為什麼要用 curl_cffi?它是建立在 curl-impersonate 之上的 Python 封裝,能完整重現真實瀏覽器的 TLS ClientHello、HTTP/2 SETTINGS frame 與標頭順序。它是目前唯一仍持續維護、且能在一次請求中同時突破 JA3/JA4 與 Akamai H2 指紋 的 Python HTTP 客戶端。支援的模擬目標包含 chrome120、chrome124、chrome131、Safari 與 Edge 版本。
步驟 2:用正則表達式擷取 JSON
這個 JSON 區塊會嵌在 <script> 標籤中。用 regex 把它抓出來:
import re, json
MOSAIC_RE = re.compile(
r'window\.mosaic\.providerData\["mosaic-provider-jobcards"\]=(\{.+?\});',
re.DOTALL,
)
match = MOSAIC_RE.search(response.text)
if match:
data = json.loads(match.group(1))
results = data["metaData"]["mosaicProviderJobCardsModel"]["results"]
print(f"在隱藏 JSON 中找到 {len(results)} 筆職缺")
else:
print("找不到隱藏 JSON——可能是被擋下,或頁面結構改變")
步驟 3:從 JSON 解析職缺欄位
results 裡的每個項目都比頁面上顯示的資訊還完整:
jobs = []
for job in results:
jobs.append({
"jobkey": job["jobkey"],
"title": job["title"],
"company": job.get("company"),
"location": job.get("formattedLocation"),
"remote": job.get("remoteLocation"),
"salary": (job.get("salarySnippet") or {}).get("text"),
"posted": job.get("formattedRelativeTime"),
"job_type": job.get("jobTypes"),
"easy_apply": job.get("indeedApplyEnabled"),
"url": f"https://www.indeed.com/viewjob?jk={job['jobkey']}",
})
這個 JSON 常常還包含薪資估算、分類屬性(技能標籤),以及公司評分,而這些不一定會出現在渲染後的 HTML 中。
步驟 4:抓取多頁資料
使用 JSON 裡的 tierSummaries 了解總筆數,然後進行迴圈:
import time, random
all_jobs = []
for start in range(0, 50, 10): # 前 5 頁
url = f"https://www.indeed.com/jobs?q=python+developer&l=Remote&start={start}&sort=date"
response = cffi_requests.get(
url,
impersonate="chrome124",
headers={"Accept-Language": "en-US,en;q=0.9", "Referer": "https://www.indeed.com/"},
timeout=30,
)
match = MOSAIC_RE.search(response.text)
if match:
data = json.loads(match.group(1))
results = data["metaData"]["mosaicProviderJobCardsModel"]["results"]
all_jobs.extend([{
"jobkey": j["jobkey"],
"title": j["title"],
"company": j.get("company"),
"location": j.get("formattedLocation"),
"salary": (j.get("salarySnippet") or {}).get("text"),
"url": f"https://www.indeed.com/viewjob?jk={j['jobkey']}",
} for j in results])
time.sleep(random.uniform(3, 7))
print(f"總計抓取 {len(all_jobs)} 筆職缺")
為什麼隱藏 JSON 更穩定
window.mosaic.providerData 的結構比 CSS 類別名稱變動少得多。你可以在不解析雜亂 HTML 的情況下取得乾淨、結構化的資料。當然,你還是需要反機器人處理(標頭、延遲、代理)——我們接下來會說。
如何使用 Selenium 抓取 Indeed
Selenium 是瀏覽器自動化路線。當你需要跟頁面互動時,它很有用——例如點進職缺詳情面板、處理需要登入的內容,或擷取初始 HTML 裡沒有的動態載入描述。
什麼時候該用 Selenium,而不是 HTTP 客戶端?
- Indeed 會動態載入部分內容(右側面板的完整職缺描述)
- 你需要抓取需要 session 狀態或登入的頁面
- 你做的是小規模抓取,速度不是關鍵
快速示範
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
import time
options = Options()
options.add_argument("--disable-blink-features=AutomationControlled")
# options.add_argument("--headless=new") # Headless 比較容易被偵測,使用時要小心
driver = webdriver.Chrome(options=options)
driver.get("https://www.indeed.com/jobs?q=data+engineer&l=New+York")
time.sleep(3)
cards = driver.find_elements(By.CSS_SELECTOR, "[data-testid='slider_item']")
for card in cards:
try:
title = card.find_element(By.CSS_SELECTOR, "h2.jobTitle").text
company = card.find_element(By.CSS_SELECTOR, "[data-testid='company-name']").text
location = card.find_element(By.CSS_SELECTOR, "[data-testid='text-location']").text
print(f"{title} | {company} | {location}")
except Exception:
continue
driver.quit()
限制
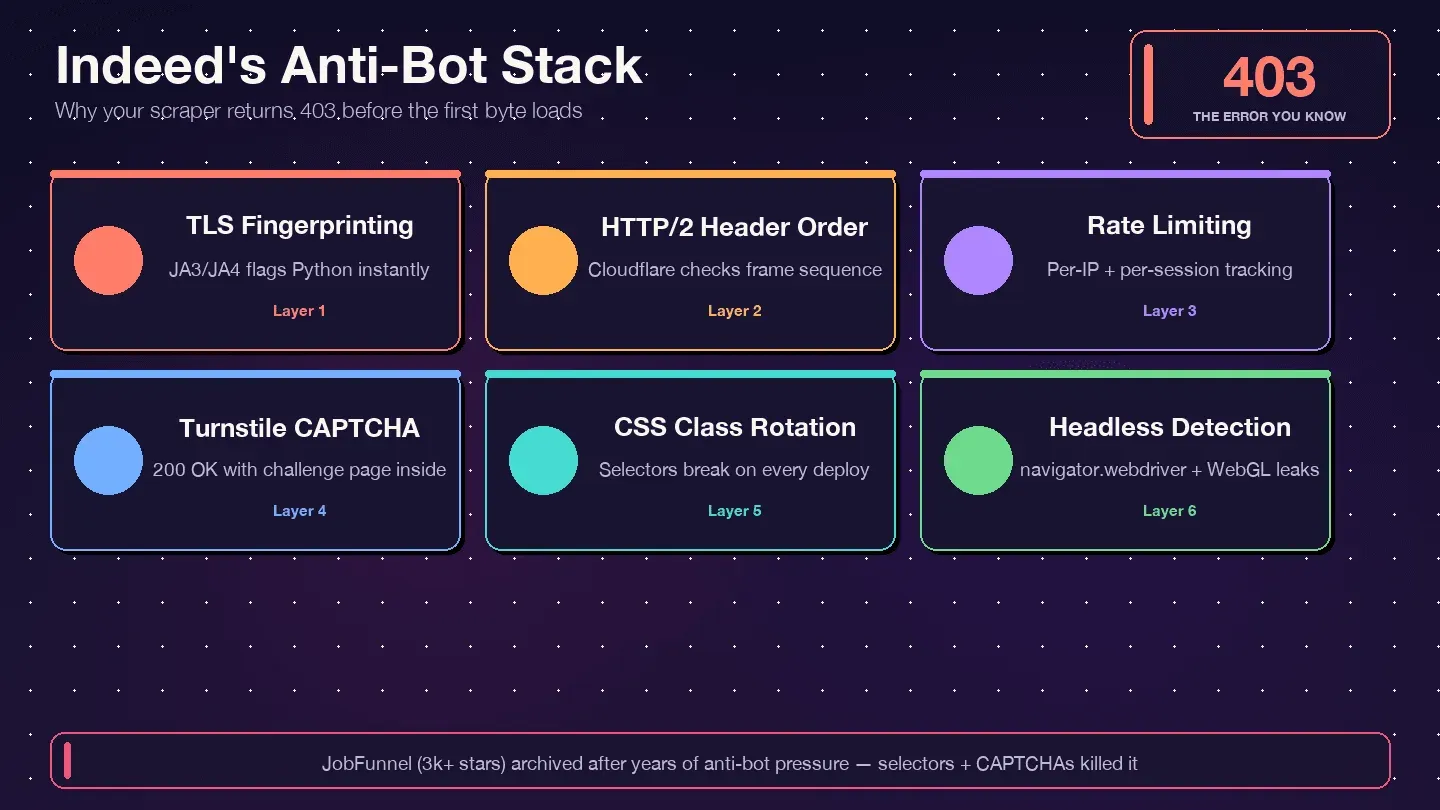
Selenium 很慢——每一頁都要完整渲染瀏覽器。Headless Chrome 會被 Indeed 的反機器人系統 偵測到(Cloudflare 會檢查 navigator.webdriver、WebGL vendor 字串、插件數量等等)。就算是 undetected-chromedriver,也只是延後偵測,並不能永久避免。而且跟 BS4 一樣,當 Indeed 更新介面時,你的選擇器也會壞掉。
對大多數用途來說,隱藏 JSON 方案能更快拿到相同資料,而且維護成本更低。只有在你真的需要瀏覽器時,才保留 Selenium。
如何在用 Python 抓取 Indeed 時避免 403 錯誤
這一段最重要。如果你是從焦躁的 Google 搜尋結果點進來的,那你來對地方了。
為什麼 Indeed 會封鎖你的爬蟲
Indeed 使用 Cloudflare Bot Management 搭配 Cloudflare Turnstile——不是 DataDome,也不是 PerimeterX。回應標頭就能看出來:server: cloudflare、cf-ray,以及 __cf_bm bot-management cookie。Cloudflare 會檢查你的 TLS 指紋(JA3/JA4)、HTTP/2 標頭順序、請求模式,以及瀏覽器行為訊號。只要其中任何一項看起來不像真人,你就可能收到 403、429、503,或者——最狡猾的情況——回傳 200 OK,但內容其實是 Turnstile 驗證頁,而不是真正的職缺資料。
輪換 User-Agent 與請求標頭
固定不變的 User-Agent 是最快被封鎖的方法。請從一組真實、現代的字串中輪換。重點是:Chrome 的次版本欄位在 User-Agent Reduction 後已固定為 0.0.0——不要自己亂編非零次版本,不然反機器人會直接標記你。
import random
USER_AGENTS = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36 Edg/145.0.3800.97",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:128.0) Gecko/20100101 Firefox/128.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 "
"(KHTML, like Gecko) Version/17.4 Safari/605.1.15",
]
headers = {
"User-Agent": random.choice(USER_AGENTS),
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br, zstd",
"Referer": "https://www.indeed.com/",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "same-origin",
}
也要確保你的 sec-ch-ua Client Hints 與 UA 版本一致。像 sec-ch-ua: "Chrome";v="131" 卻搭配宣稱 Chrome 145 的 User-Agent,會立刻變成紅旗。
在請求之間加入隨機延遲
固定間隔很容易被模式偵測抓到。請使用隨機抖動:
import time, random
# 每次請求之間
time.sleep(random.uniform(3, 6))
# 被封鎖後的重試退避
def backoff_sleep(attempt):
base = 4
sleep_time = base * (2 ** attempt) + random.uniform(0, 2)
time.sleep(min(sleep_time, 60))
來自 ScrapeOps 與 WebScraping.AI 的實務共識是:每個 IP 每次請求間隔 3–6 秒,且在輪換之前,每個 IP 每個 session 的請求數最好不要超過約 100 次。
使用代理輪換
這是成功與否的最大關鍵。來自 AWS/GCP 等資料中心的代理,面對 Cloudflare Enterprise 目標時成功率大約只有 5–15%,對 Indeed 幾乎算是不能用。住宅代理再加上正確的 TLS 指紋,成功率可提升到 80–95%。
PROXIES = [
"http://user:pass@us.residential.example:7777",
"http://user:pass@us.residential.example:7778",
"http://user:pass@us.residential.example:7779",
]
proxy = random.choice(PROXIES)
response = cffi_requests.get(
url,
impersonate="chrome124",
headers=headers,
proxies={"https": proxy},
timeout=30,
)
2026 年的住宅代理價格,大致落在每 GB 4–8.50 美元,實際取決於供應商與承諾方案。就 Indeed 而言,建議先從小型代理池開始,再視需要擴充。
妥善處理 403、429 與 503 狀態碼
不要只是盲目重試。不同狀態碼代表不同狀況:
def fetch_with_retry(url, proxy_pool, max_retries=5):
for attempt in range(max_retries):
proxy = random.choice(proxy_pool)
headers["User-Agent"] = random.choice(USER_AGENTS)
try:
r = cffi_requests.get(
url,
impersonate=random.choice(["chrome124", "chrome120", "edge101"]),
headers=headers,
proxies={"https": proxy},
timeout=30,
)
# 檢查最麻煩的「200 但其實是驗證頁」情況
if r.status_code == 200 and "cf-turnstile" not in r.text and "Just a moment" not in r.text:
return r
if r.status_code == 403:
print(f"403 — 被封鎖。切換代理,第 {attempt + 1} 次嘗試")
elif r.status_code == 429:
print(f"429 — 速率受限。放慢速度。")
elif r.status_code == 503:
print(f"503 — 伺服器過載或 JS 驗證。")
backoff_sleep(attempt)
except Exception as e:
print(f"請求錯誤:{e}")
backoff_sleep(attempt)
raise RuntimeError(f"重試 {max_retries} 次後仍失敗:{url}")
「200 但其實是驗證頁」是最棘手的情況。只要把 200 視為成功之前,一定要先在回應內容中搜尋 cf-turnstile 或 Just a moment 這類標記。
更簡單的替代方案:讓 Thunderbit 幫你處理反機器人
如果你不想自己維護代理池、標頭輪換與 TLS 指紋模擬,Thunderbit 的雲端抓取會自動處理 CAPTCHA、代理輪換與反機器人防護。免代理設定、免 curl_cffi 配置、也不用 CAPTCHA 解題套件。當你只是想快點拿到資料,這是阻力最小的路徑。
為什麼你的 Indeed 爬蟲總是壞掉,以及如何修正
403 牆是急性痛點;慢性痛點則是維護——今天能用的爬蟲,下週可能就壞掉,默默回傳空資料或過期結果。
Indeed 如何破壞你的選擇器
Indeed 會積極輪換 CSS 類別名稱。Bright Data 的指南 明確提醒 像 css-1m4cuuf、css-1rqpxry 這類 class「看起來是隨機產生的——很可能是在建置時產生。」A/B 測試代表不同使用者可能同時看到不同版面。DOM 重構也經常在毫無通知下發生。
JobFunnel 的經驗很有代表性。有貢獻者回報:「CaptchaBuster 已成功緩解 captcha,而之所以仍然無法成功抓取頁面,是因為 beautiful soup 的選擇器過時了。」 不是爬蟲被封鎖,而是它在解析錯誤的元素。
策略:優先用隱藏 JSON,而不是解析 DOM
window.mosaic.providerData 這個區塊至少從 2023 年起就相當穩定。metaData.mosaicProviderJobCardsModel.results[] 這條路徑到 2026 年仍是 標準做法。DOM 選擇器每月都可能壞,JSON 擷取則通常只會每年壞一次,甚至不會。
策略:用 data 屬性,不要用 class 名稱
當你真的必須碰 DOM 時,請鎖定功能性屬性:
| 選擇器 | 用途 |
|---|---|
[data-testid="slider_item"] | 每個職缺卡片容器 |
[data-testid="job-title"] 或 h2.jobTitle > a | 職缺標題連結 |
[data-testid="company-name"] | 雇主名稱 |
[data-testid="text-location"] | 地點文字 |
每張卡片上的 data-jk="<jobkey>" | 最穩定的錨點——自 2019 年以來都沒變 |
加入斷言檢查,偵測過時的選擇器
不要讓爬蟲在毫無結果的情況下默默運行。每次抓取後都加上檢查:
results = parse_hidden_json(html)
assert len(results) > 0, (
f"Indeed 在 start={start} 時回傳空結果集——"
"可能被封鎖、遭遇 CAPTCHA,或選擇器已漂移。"
f"回應前 500 字元:{html[:500]}"
)
在失敗時,記錄原始回應的前 500–2000 個字元。這樣你就能立刻判斷自己拿到的是 Turnstile 驗證頁、登入牆,還是 schema 變更。也建議每天用固定查詢(例如 q=python&l=remote)跑一次 CI 級別的 smoke test,確認結果不是零筆。
AI 替代方案:永不輕易壞掉的爬蟲
Thunderbit 的 AI 每次都會重新讀取頁面結構,不依賴硬寫死的選擇器或 regex。當 Indeed 改變 HTML 時,Thunderbit 會自動適應。這正好解決了論壇使用者一再提到的主要痛點:維護成本。如果你曾經一早醒來,看到 Slack 訊息說「爬蟲又回傳空白列了」,你就知道不用一直修它有多重要。
不寫 Python 也能抓 Indeed:免程式替代方案
大多數競品指南都預設你會寫 Python 程式碼。但論壇上的真實回饋卻不同。使用者常說像是 「就是一直有 bug 和錯誤,太難了」,甚至有人建議直接找 Fiverr 的人幫忙拿資料。如果這很像你,那這一段就是你的逃生出口。
如何用 Thunderbit 抓取 Indeed(逐步教學)
步驟 1: 從 Chrome 線上應用程式商店安裝 Thunderbit Chrome 擴充功能。可免費開始。
步驟 2: 在瀏覽器中開啟 Indeed 的搜尋結果頁,例如 https://www.indeed.com/jobs?q=data+analyst&l=Austin%2C+TX。
步驟 3: 點擊瀏覽器工具列上的 Thunderbit 圖示,然後按 「AI 建議欄位」。Thunderbit 的 AI 會掃描頁面,自動辨識職稱、公司、地點、薪資、職缺網址與發布日期等欄位。你可以檢視並調整建議欄位——刪掉不需要的欄位,或用白話描述你想要的內容來新增自訂欄位。
步驟 4: 按 「抓取」。Thunderbit 會從頁面擷取資料,並以結構化表格顯示。你應該會看到已設定欄位的職缺列表。
透過子頁面抓取補充資訊
完成列表頁抓取後,按 「抓取子頁面」,Thunderbit 就會逐一拜訪每個職缺詳情頁。它能抓出完整職缺描述、資格條件、福利與申請連結——完全不需要額外設定。這等於你再寫一支 Python 爬蟲逐一拜訪每個 /viewjob?jk=<jobkey> URL,但 Thunderbit 只要一鍵就能完成。
自動處理分頁
Thunderbit 會自動處理 Indeed 的點擊式分頁。不需要你手動組合 offset URL,也不需要寫分頁迴圈。它會逐頁點選並彙整結果。
匯出到你喜歡的工具
將抓取資料免費匯出到 CSV、Excel、Google Sheets、Airtable 或 Notion——完全免費。你不需要自己寫 csv.writer() 或 pandas.to_csv()。
什麼時候該用 Python,什麼時候該用 Thunderbit
| 情境 | 最佳工具 |
|---|---|
| 自訂資料管線、透過 cron/Airflow 排程自動化 | Python |
| 整合進大型程式碼庫 | Python |
| 高度客製化的解析邏輯 | Python |
| 一次性研究或市場分析 | Thunderbit |
| 非技術團隊成員需要資料 | Thunderbit |
| 立刻拿到資料,不想除錯 403 | Thunderbit |
| 零設定就能補抓子頁面資訊 | Thunderbit |
時間比較:Python 環境設定 + 反機器人除錯 = 幾小時到幾天(尤其是第一次)。Thunderbit = 同樣資料不到 2 分鐘。我不是說 Python 不對——我是說,得看你真正需要什麼。
抓取 Indeed 合法嗎?你需要知道的事
前幾名的 Indeed 抓取指南幾乎都沒提合法性,這很讓人意外,畢竟論壇上常有人問:「抓取 Indeed 合法嗎?」這不是法律意見,但可以先看看目前的情勢。
Indeed 的服務條款
Indeed 的服務條款(indeed.com/legal)並沒有一條全面的「禁止抓取」條款。唯一明確禁止自動化的內容是 A.3.5 節,禁止 「使用任何自動化、腳本或機器人來自動化 Indeed Apply 流程。」 這個限制只針對 Apply 流程,並不涵蓋對公開職缺列表的被動閱讀。Indeed 主要的執法工具是技術手段——Cloudflare 驗證、IP 封鎖、裝置指紋辨識——而不是法庭訴訟。
相關法律先例
最常被引用的美國案例是 hiQ Labs v. LinkedIn。第 9 巡迴上訴法院在 2022 年 4 月裁定,抓取公開可存取資料「很可能不違反 CFAA」(Computer Fraud and Abuse Act,電腦詐欺與濫用法)。不過,hiQ 後來仍因 違反合約而被認定有責,因為其員工建立了假的 LinkedIn 個人檔案並接受了服務條款。
更近期的 Meta v. Bright Data(加州北區,2024 年 1 月)則給出了更清楚的裁定。法官 Chen 認定 Facebook 與 Instagram 的服務條款「不禁止登出狀態下對公開資料的抓取」。Meta 在隔月主動撤回了剩餘主張。
Indeed 的 robots.txt
Indeed 的 robots.txt 對預設 User-agent: * 大範圍禁止 /jobs/ 與 /job/,但明確允許 Googlebot 與 Bingbot 存取 /viewjob?——也就是個別職缺詳情頁。AI 訓練爬蟲(GPTBot、CCBot、anthropic-ai)則被嚴格限制。robots.txt 在美國不具法律拘束力,但遵守它是最佳實務,也能證明你是善意行事。
負責任抓取的實務準則
- 只抓取公開可見資料——不要登入,也不要建立假帳號
- 尊重速率限制:每個 IP 每 3–6 秒 1 次請求,並維持低併發
- 不要把抓來的資料重新發布成你自己的職缺網站
- 資料僅用於個人或內部研究,不要未經許可商業轉售
- 丟棄或雜湊化你不需要的 PII;對接近個資的資料設定保留上限
- 如果你要大規模營運,或在歐盟/英國操作,請諮詢律師——GDPR 第 14 條的資訊告知義務會適用於抓取到的個資
風險層級來看:個人求職自動化屬於低風險端;大規模商業轉售 Indeed 資料則屬於高風險端。
結論與重點整理
用 Python 抓取 Indeed 做得到,但它不是那種週末寫完就能放著不管的專案。Indeed 的 Cloudflare 防護、輪換選擇器與強勢反機器人措施,代表你必須用正確的工具,也要有正確的期待來面對它。
我會把這篇內容濃縮成以下幾點:
- Indeed 是網路上最豐富的職場資料來源——每月 3.5 億訪客、1.3 億職缺——但它也會強力反制爬蟲。
- 隱藏 JSON 擷取(
window.mosaic.providerData)是最穩健的 Python 方法。 這個 schema 幾年來都很穩,而 CSS 選擇器每月都可能壞。 - 帶有瀏覽器模擬的
curl_cffi是 2026 年 Cloudflare 保護網站的預設 HTTP 客戶端。 純requests和httpx光靠 TLS 指紋就會被擋。 - 一定要搭配輪換標頭、隨機延遲與住宅代理,才能避免 403。資料中心代理對 Cloudflare Enterprise 幾乎沒用。
- 加入斷言檢查,讓你能立刻知道是選擇器壞了,還是拿到的是驗證頁而不是真實資料。
- 對非技術使用者,或只想快速拿到結果的人來說, Thunderbit 提供了免程式、AI 驅動的路徑,能自動適應網站變更——不用代理、不用除錯、也不用維護。
如果你想試試免程式路線,Thunderbit 提供免費方案,你可以不需承諾就先在 Indeed 上測試。若你要走 Python 路線,以上程式範例是很好的起點——只要記得把反機器人韌性當成第一優先,而不是事後補救。
想了解更多網頁爬蟲方法與工具,請參考我們的指南:如何使用 Python 進行網頁爬蟲、最佳自動化網頁爬蟲工具、以及如何避免被封鎖地進行網頁爬蟲。你也可以在 Thunderbit YouTube 頻道 觀看教學影片。
試試 Thunderbit,更快抓取 Indeed 資料 Get Started Free
常見問題
哪些 Python 套件最適合抓取 Indeed?
如果是 HTTP 請求,curl_cffi 是 2026 年最強的選擇——它能模擬真實瀏覽器的 TLS 指紋,這對繞過 Cloudflare 至關重要。對防護較弱的目標,支援 HTTP/2 的 httpx 也可以作為備案。HTML 解析方面,BeautifulSoup4 搭配 lxml 仍是標準做法。若是瀏覽器自動化,Playwright(搭配 playwright-stealth)或 undetected-chromedriver 都可用,但兩者都愈來愈容易被偵測。隱藏 JSON regex 方案(window.mosaic.providerData)則能完全避開繁重的解析工作。
為什麼我抓取 Indeed 時一直出現 403 錯誤?
Indeed 使用 Cloudflare Bot Management,會檢查你的 TLS 指紋(JA3/JA4)、HTTP/2 標頭順序、請求模式與瀏覽器行為。如果你用的是純 requests,TLS 指紋一眼就會被看成 Python 腳本——403 甚至在標頭被讀取前就會出現。解法是改用帶瀏覽器模擬的 curl_cffi、輪換真實的 User-Agent、加入隨機延遲(3–6 秒),以及使用住宅代理。另外也要留意「200 但其實是 Turnstile 驗證頁」的情況——記得掃描回應內容中的 cf-turnstile 標記。
可以不寫程式就抓取 Indeed 嗎?
可以。像 Thunderbit 這類工具,讓你只要幾個點擊就能擷取 Indeed 職缺列表——安裝 Chrome 擴充功能、開啟 Indeed 搜尋頁、點「AI 建議欄位」,再按「抓取」即可。Thunderbit 的 AI 會自動辨識職稱、公司、地點與薪資等欄位,也會自動處理分頁、子頁面補充資訊(完整職缺描述)與反機器人保護。你可以免費匯出到 CSV、Google Sheets、Airtable 或 Notion。
Indeed 的 HTML 結構多久會改一次?
Indeed 會定期輪換 CSS 類別名稱(例如 css-1m4cuuf 這類隨機雜湊字串),並在不通知的情況下重構 DOM 元素。A/B 測試也意味著不同使用者可能同時看到不同版面。隱藏 JSON 方案(window.mosaic.providerData)穩定得多——至少從 2023 年起 schema 就一直很一致。當你非得使用 DOM 選擇器時,請鎖定 data-testid 與 data-jk(job key),不要依賴 CSS 類別。
抓取 Indeed 合法嗎?
根據第 9 巡迴法院在 hiQ v. LinkedIn(2022)與 Meta v. Bright Data(2024)的判決,對公開可存取的 Indeed 職缺網址,在登出狀態下進行抓取,在美國通常不太可能構成 CFAA 責任。Indeed 的服務條款只明確禁止自動化 Apply 流程,並未全面禁止對公開列表的被動閱讀。儘管如此,仍應負責任地抓取:不要登入、不要建立假帳號、尊重速率限制、不要把資料重新發布成自己的職缺網站,並依 GDPR/CCPA 小心處理任何個資(招募人員姓名、電子郵件等)。若是商業規模操作,請諮詢律師。
延伸閱讀




