數據的價值無可限量,甚至比系統本身還要珍貴。
- ,萬維網之父、電腦科學家
每天,Google 要處理 次搜尋:這些搜尋不只是解答日常疑問,更蘊藏著市場趨勢、競爭對手動態、消費者行為等豐富洞見。不論你是業務、 專家還是行銷人員,都能從中挖掘出有價值的資訊,轉化成具體的商業策略。
還在用土法煉鋼的方式一個一個複製貼上嗎?該是時候跟這種低效率說掰掰了。
這篇文章會帶你認識什麼是 Google SERP、它有哪些有價值的資料,並介紹三種 Google SERP 爬蟲的實用方法,包含最簡單上手、無需寫程式的人工智慧網頁爬蟲 。
什麼是 Google 搜尋結果頁(SERP)?
(搜尋引擎結果頁)就是你在 Google、 或 等搜尋引擎輸入關鍵字後看到的那個頁面。這是所有網路流量的起點,也是你點擊任何連結前的第一站。
SERP 最大的特色就是即時性:演算法一更新、新功能一上線、關鍵字熱度一變、網站內容一調整,搜尋結果馬上就會跟著變動。而且搜尋引擎還會根據你的搜尋紀錄和地理位置個人化結果,也就是說,同一時間不同人看到的 SERP 可能完全不一樣。這也讓非技術背景的人要從這些非結構化網頁中高效擷取資料變得更有挑戰。
而 Google 目前在全球搜尋引擎市佔率超過 ,所以搞懂 Google SERP 的結構和應用,對企業來說絕對是關鍵。
Google SERP 包含哪些資料?
Google SERP 的結構
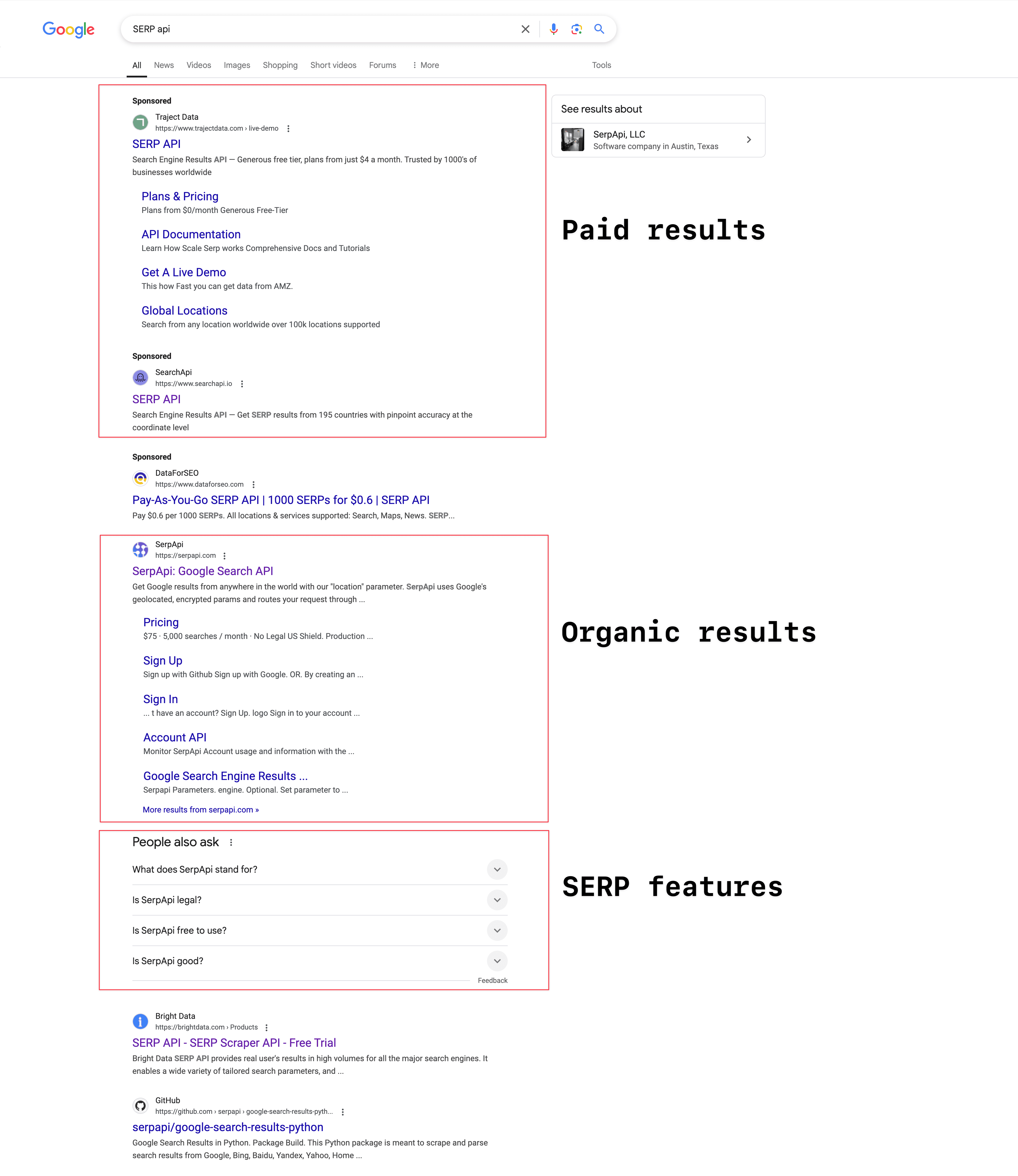
根據你搜尋的內容不同,Google SERP 的版面也會有所變化,但大致上可以分成三大區塊:
-
付費廣告:標示為「廣告」或「贊助」的搜尋結果。網站主付費給 Google,讓自己的網站排在自然搜尋結果的上方或下方。是否出現廣告會依據用戶查詢內容而定。根據 ,2023 年 Google 廣告收入高達 2,645.9 億美元。
-
自然搜尋結果:根據相關性與頁面排名自動顯示的非付費結果。每則結果通常包含標題、簡介(meta description)與網址。
-
SERP 功能:Google 為了提升用戶體驗不斷新增的功能,例如精選摘要(featured snippets)、AI 總覽、大家也在問(PAA)、知識面板、在地商家資訊、影片、圖片、購物結果等。
可擷取的資料類型
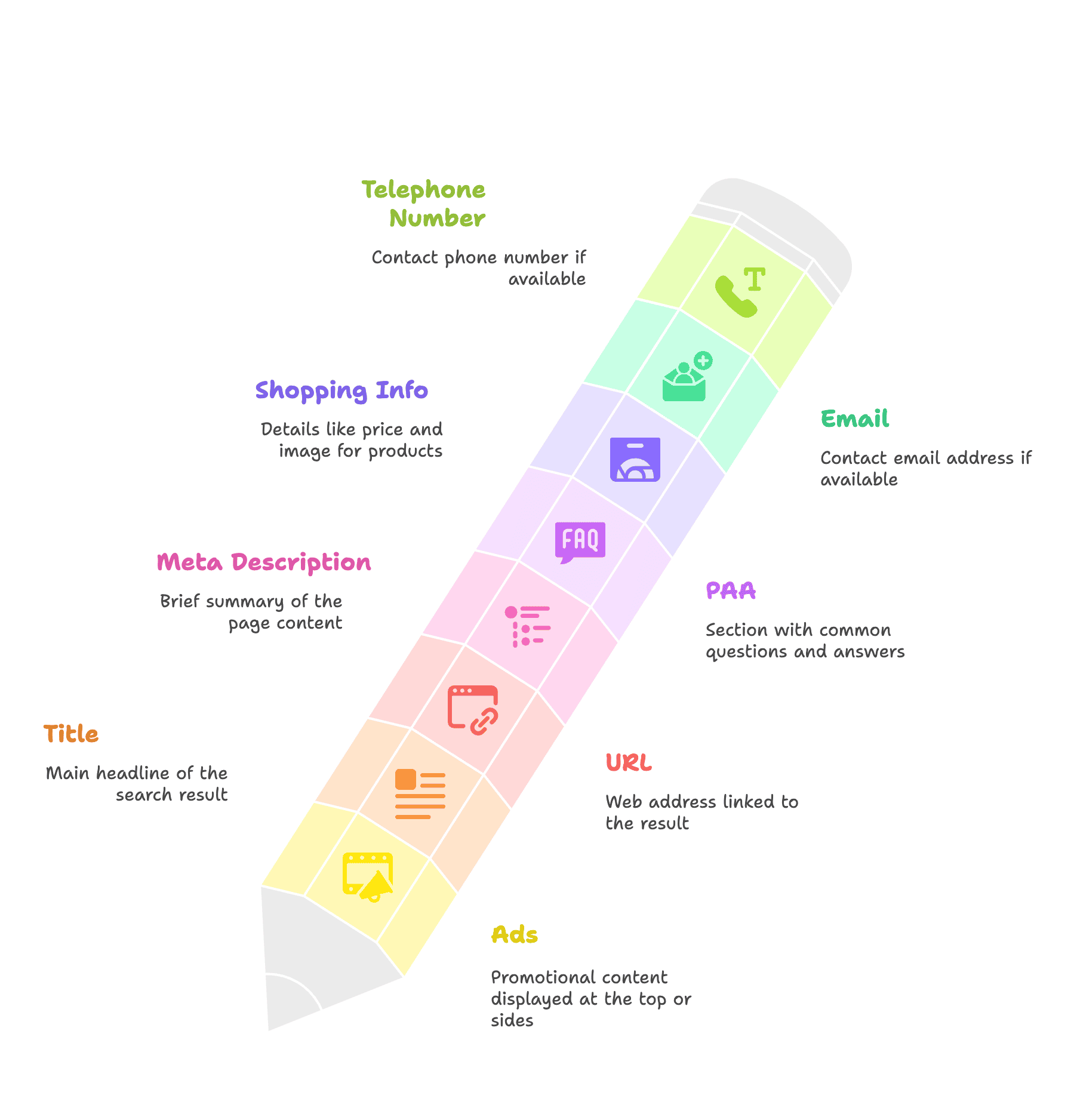
了解 SERP 結構後,你可以針對下列資訊進行擷取,包括但不限於:
- 廣告
- 標題
- 網址
- 簡介(Meta Description)
- PAA 問題盒
- 購物資訊:價格、圖片
- 電子郵件
- 聯絡電話
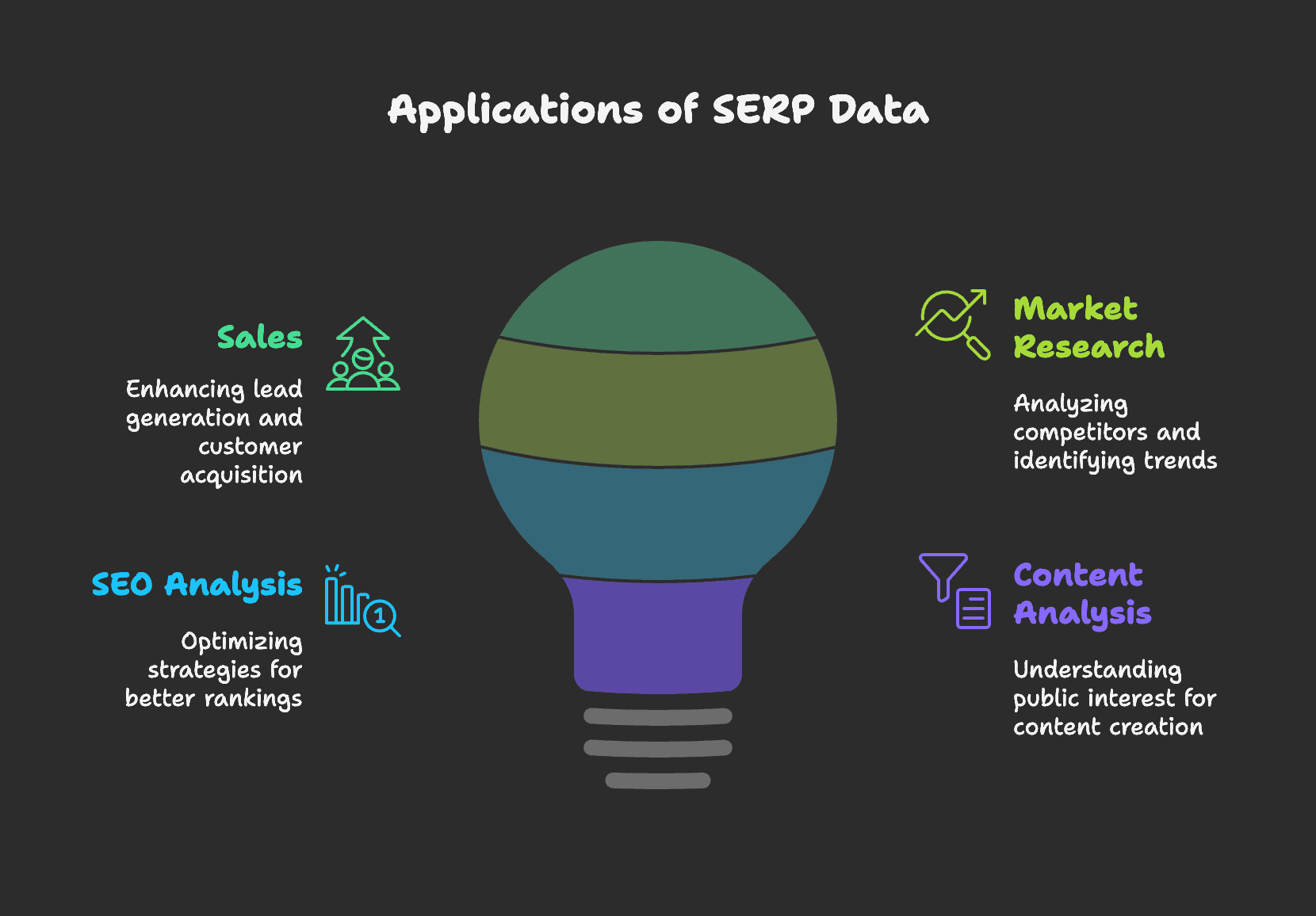
SERP 資料能做什麼?
業務開發
透過精準的搜尋指令,業務團隊可以高效挖掘潛在客戶與商機,甚至從社群平台抓取聯絡方式(如 email、電話),大幅提升名單質量。下文會有詳細教學,說明如何利用 SERP 從 Instagram 擷取業務名單。
市場研究
SERP 結果能幫助行銷人員更有效率地進行競品分析,例如抓取競爭對手的廣告與產品資訊,洞悉其策略並優化自身行銷方案。
SERP 也是預測市場趨勢的利器。分析 SERP 關鍵字熱度變化,能發現新興市場機會。例如經營服飾店時,若發現「永續時尚」相關搜尋量激增,就能及時調整商品策略。
SEO 分析
SERP 是 SEO 專家的基礎工具。透過分析 SERP 資料,能調整關鍵字策略、優化網站內容,提升搜尋排名。
以 PAA(大家也在問)為例,抓取這些相關問題並追蹤變化,有助於發掘用戶關心的議題,進一步優化網站內容。
內容分析
對新聞媒體或自媒體來說,抓取 Google 新聞結果有助於掌握熱門話題與趨勢,指引內容製作方向。你可以參考我們的教學,了解如何用網頁爬蟲抓取文章。
如何抓取 Google 搜尋結果頁?
了解 SERP 資料的應用後,下一步就是:該怎麼收集這些資料?
手動複製貼上雖然可行,但面對大量資料時效率極低。隨著技術進步,尤其是 AI 的發展,現在可以利用網頁爬蟲自動化大量資料收集。以下介紹三種主流方法:
方法一:使用 Thunderbit 人工智慧網頁爬蟲
是一款無需寫程式的人工智慧網頁爬蟲,能協助你從網站中擷取任何想要的資料。你可以直接套用我們的,也能自訂欄位。以下以業務開發(Leads Generation)為例,說明如何用 Thunderbit 找到高質量名單:
-
步驟 1:將 Thunderbit 加入 Chrome 擴充功能,並用 Google 帳號或 email 登入。
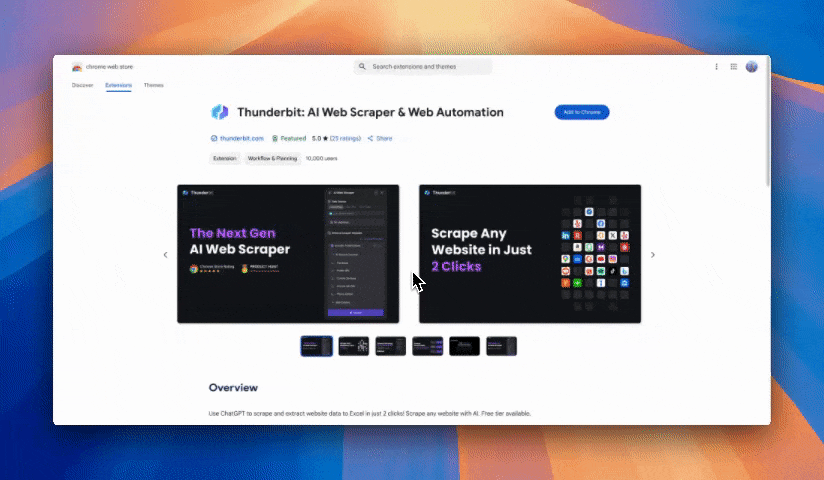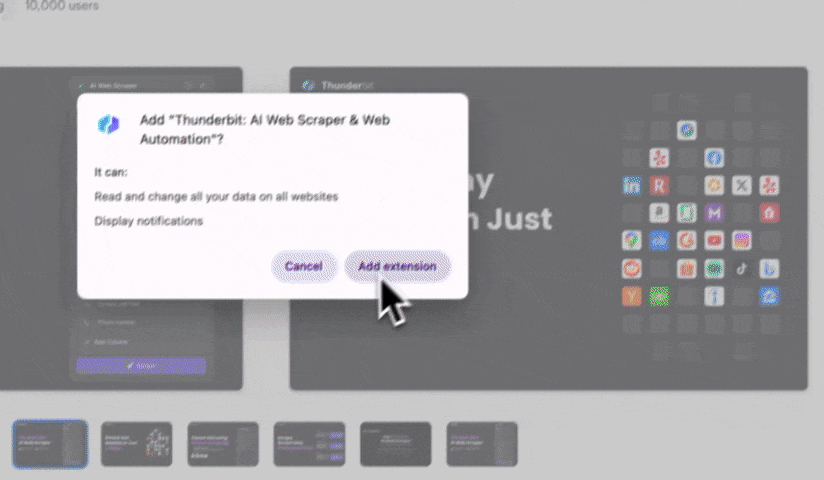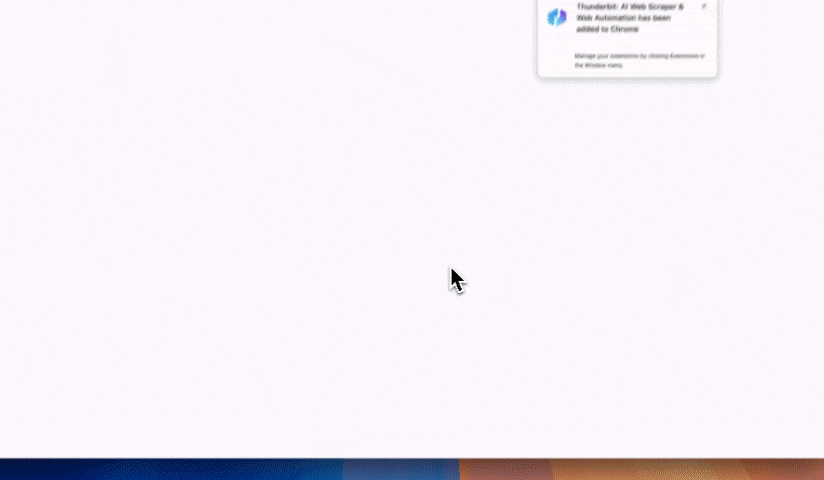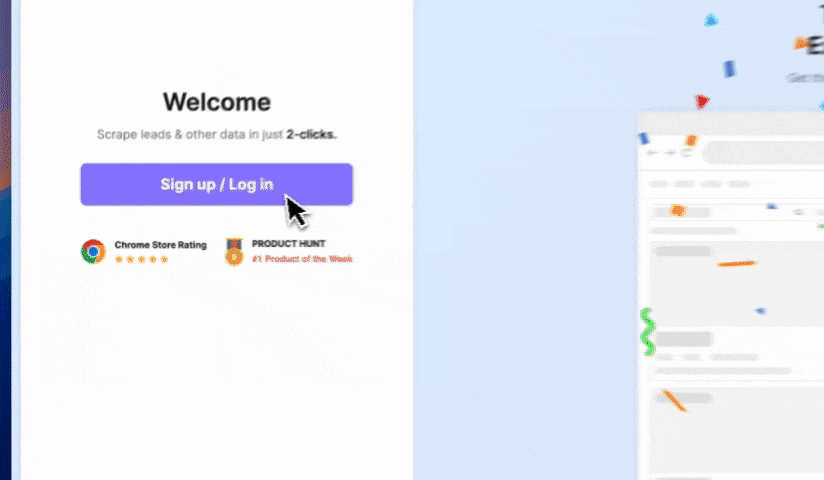
-
步驟 2:輸入你的搜尋指令。
想要更精準篩選結果,超級好用。
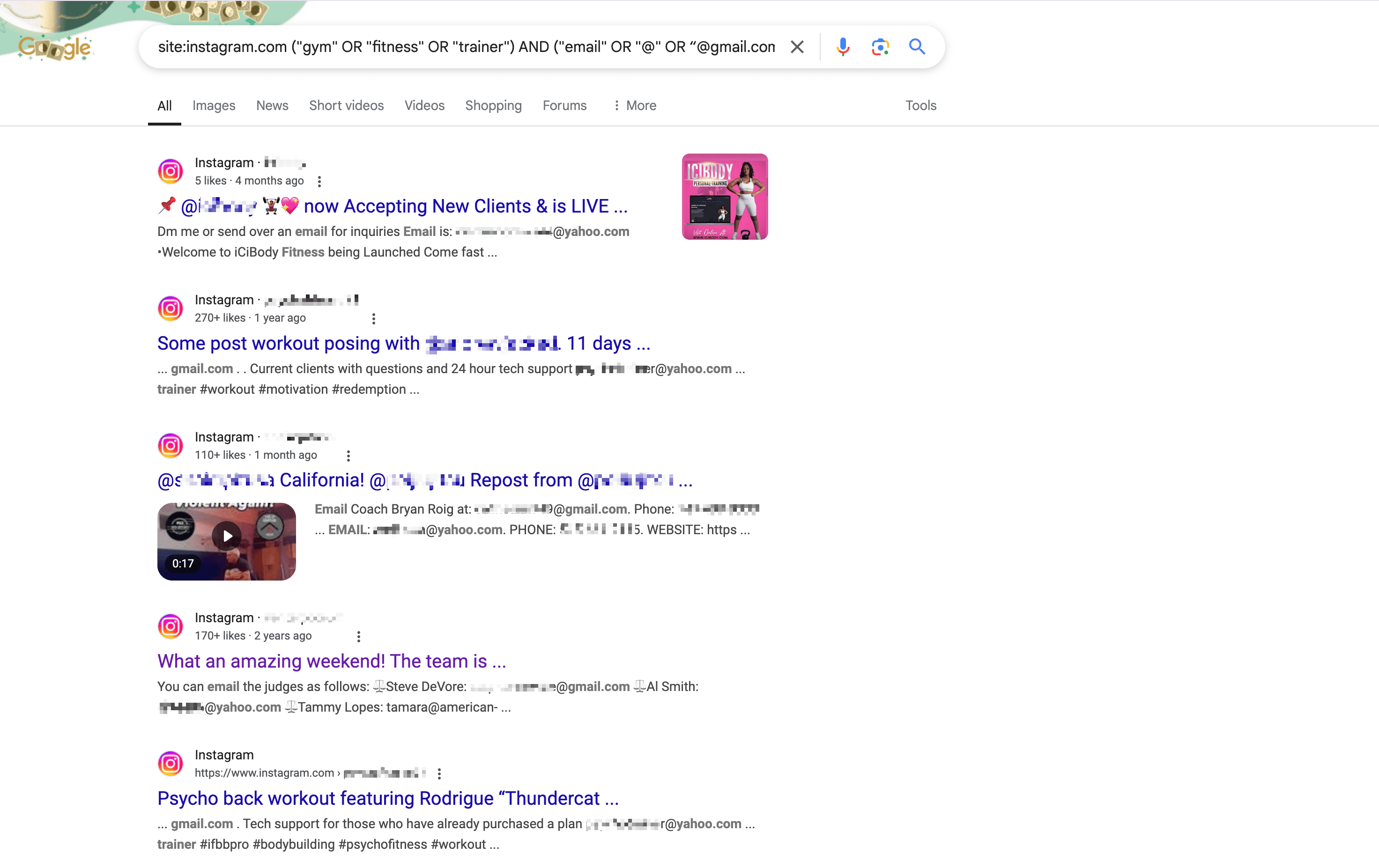
例如,以下是 產生的搜尋語法,用來找出 Instagram 上與健身相關且有 email 的洛杉磯用戶:
1site:instagram.com ("gym" OR "fitness" OR "trainer") AND ("email" OR "@" OR “@gmail.com“ or ”@yahoo.com“ ) AND ("Los Angeles" OR "LA" OR "California")把這個指令貼到 Google 搜尋,按下 Enter,就能看到所有相關資訊。
-
步驟 3:啟動 Thunderbit 並開始抓取
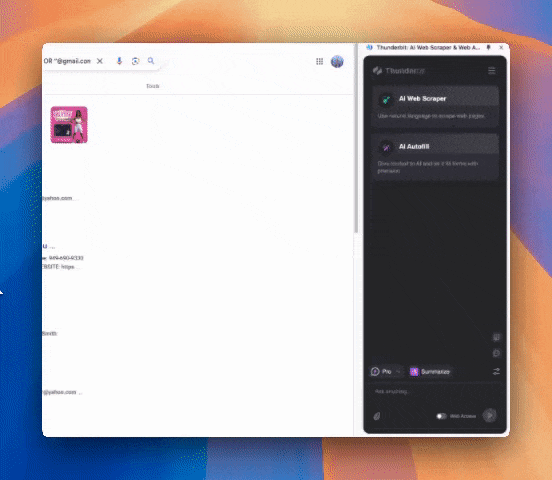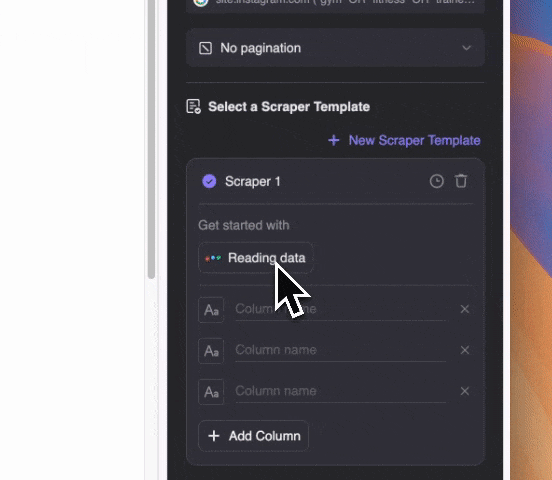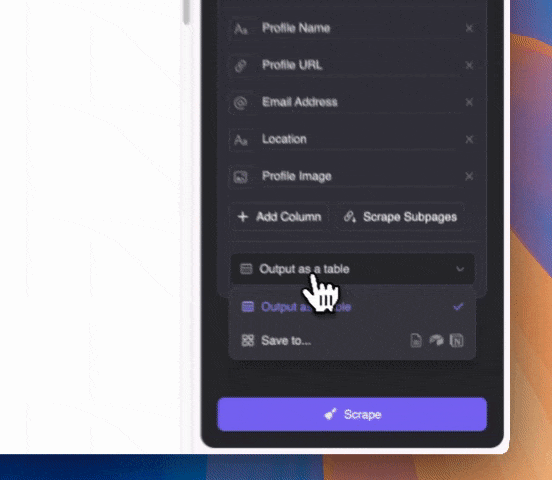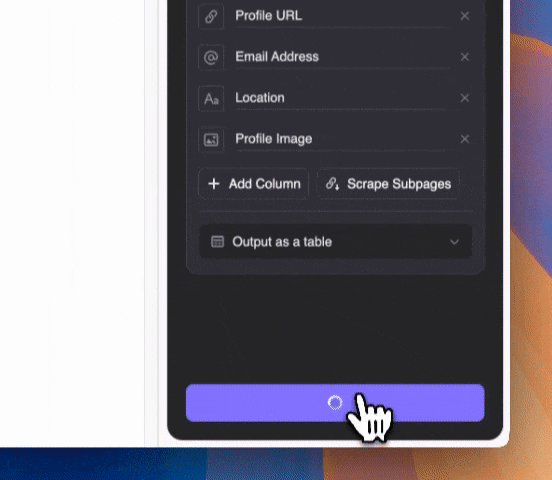 你可以用自然語言描述想要抓取的內容(也可點選「新增欄位詳細說明」進一步自訂)。資料可匯出成表格,或直接同步到 Notion、Airtable、Google Sheets。
你可以用自然語言描述想要抓取的內容(也可點選「新增欄位詳細說明」進一步自訂)。資料可匯出成表格,或直接同步到 Notion、Airtable、Google Sheets。Thunderbit 利用 AI 技術協助你抓取資料,即使 email 混在 Google SERP 的摘要文字中,AI 也能精準辨識並擷取。
點擊「開始抓取」後,等一下就能看到結果!
方法二:傳統網頁爬蟲工具
傳統網頁爬蟲也能批量抓取 Google SERP 資料。以 WebScraper.io 為例,操作步驟如下:
- 安裝 Web Scraper 擴充功能,打開 Chrome 開發者工具。
- 點選「Create new sitemap」,將起始網址設為 Google 搜尋結果頁。
- 設定選擇器,指定要抓取的資料欄位。
| Selector Name | Type | Selector | Multiple? |
|---|---|---|---|
| name | Text | select the user’s name | No ❌ |
| profile | Text | select the meta description on this page | No ❌ |
-
執行爬蟲並匯出資料。
-
若要從 Excel 中擷取 email,可用正則表達式公式:
1text=REGEXEXTRACT(A2,"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}")(假設 A2 是你的個人簡介欄位)
這樣就能自動抓出所有 email。
這種方法的缺點是需要懂一點網頁結構,且只要網站版面一變(甚至一天內就可能變動),就得重新設定選擇器。
方法三:Google 官方 API 或第三方 SERP API
Google 提供 ,讓你用程式自動取得搜尋結果。你需要建立 、取得 API 金鑰,並用 Python requests 發送請求。不過,這種方式只能取得 Google 官方開放的資料,且有嚴格的存取限制,若想高度自訂就不太適合。
更常見的做法是使用第三方 SERP 爬蟲 API(如 Zen SERP、SerpApi、ScrapingBee),這類服務雖然能突破部分限制,但同樣需要寫程式、設定請求流程。舉例來說,你得先寫程式抓取所有 Instagram 個人頁網址,再進一步擷取 bio 區塊的 email,對於不懂程式的商業用戶來說門檻較高。
1import requests
2from bs4 import BeautifulSoup
3import re
4# SerpApi credentials
5SERP_API_KEY = "your_serpapi_key"
6SEARCH_QUERY = "marketing consultant site:instagram.com"
7# Step 1: Fetch Instagram profile URLs from SerpApi
8def get_instagram_profiles(query):
9 url = "https://serpapi.com/search"
10 params = {
11 "engine": "google",
12 "q": query,
13 "api_key": SERP_API_KEY
14 }
15 response = requests.get(url, params=params)
16 data = response.json()
17 profile_urls = []
18 for result in data.get("organic_results", []):
19 link = result.get("link")
20 if "instagram.com" in link:
21 profile_urls.append(link)
22 return profile_urls
23# Step 2: Extract email from Instagram bio section
24def extract_email_from_bio(profile_url):
25 headers = {"User-Agent": "Mozilla/5.0"}
26 response = requests.get(profile_url, headers=headers)
27 if response.status_code != 200:
28 return None
29 soup = BeautifulSoup(response.text, "html.parser")
30 bio_section = soup.find("meta", attrs={"name": "description"})
31 if bio_section:
32 bio_content = bio_section.get("content", "")
33 emails = re.findall(r"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}", bio_content)
34 return emails if emails else None
35 return None
36# Example usage
37if __name__ == "__main__":
38 profiles = get_instagram_profiles(SEARCH_QUERY)
39 print("Found Instagram Profiles:", profiles)
40 for profile in profiles:
41 emails = extract_email_from_bio(profile)
42 if emails:
43 print(f"Emails found in \{profile\}: \{emails\}")
44 else:
45 print(f"No email found in \{profile\}")三種方法比較
想要最快速、無技術門檻地取得資料?→ 推薦
想要完全自訂欄位,且懂一點 HTML/CSS?→ 選擇傳統網頁爬蟲
需要大規模、低成本存取數百萬筆資料,且有技術人員協助?→ 可考慮第三方 SERP API
Google 爬蟲是否合法?
說到網頁爬蟲,合法性絕對是大家最關心的問題之一。?簡單來說:要看情況。不同國家、用途、網站條款與抓取內容,法律規範都不一樣,沒有絕對的答案。
Google 的明確禁止自動化抓取其服務內容。不過,根據一般法律原則,。此外,抓取用途(商業或非營利)也會影響合法性。
建議你在進行爬蟲前,務必詳閱網站條款、只抓取公開資料,並避免將資料用於非法用途。若有大規模需求,最好還是諮詢專業法律意見。
總結
數據被譽為「」,而 Google SERP 正是尚未被充分開發的金礦。誰能最快將 SERP 資料轉化為行動策略,誰就能在競爭激烈的市場中搶得先機。無論是業務開發、市場研究還是 SEO,SERP 資料都能發揮巨大價值。
根據你的技術背景、預算、資料規模與應用場景,本文介紹了最前沿的 AI 網頁爬蟲 Thunderbit、傳統爬蟲工具與 SERP API。
如果你想一鍵抓取所有搜尋結果,Thunderbit 絕對是你的首選——現在就看看!
FAQ
1. 我可以從 Google 搜尋結果頁(SERP)抓取哪些資料?
你可以擷取標題、網址、簡介、廣告、精選摘要、購物資訊(如價格、圖片)、大家也在問、email、電話等多種資料。
2. Thunderbit 與傳統網頁爬蟲或 SERP API 有何不同?
是一款無需寫程式、以 AI 為核心的 Chrome 擴充功能,讓你用自然語言描述需求即可抓取結構化資料,無需設定選擇器或撰寫程式。傳統爬蟲需技術設定,API 則需寫程式且有存取限制。
3. 用 Thunderbit 抓取 Google 搜尋結果需要技術背景嗎?
不需要。Thunderbit 專為非技術用戶設計,只要用白話描述想要的資料,AI 就能自動幫你抓取。
4. 抓取到的資料可以匯出到 Google Sheets 或 Notion 嗎?
可以。Thunderbit 支援直接匯出到 Google Sheets、Airtable、Notion,或下載成表格,方便你即時應用。
5. 抓取 Google SERP 資料有哪些實際應用?
常見應用包括業務名單開發、競品研究、SEO 分析、趨勢追蹤、內容規劃等。例如業務可找聯絡方式,行銷人員可分析廣告版位,SEO 可追蹤關鍵字表現與相關問題。