Google 早在 2018 年就關閉了 Flights API,但機票價格依然天天在變——單一國內航線在 48 小時內甚至可能波動高達 17 次。若你想用程式化方式取得這些資料,抓取網頁幾乎是目前唯一可行的辦法。
我花了不少時間測試各種從 Google 取得航班資料的方法,而整個環境也在 2025 年 1 月 Google 推出 SearchGuard 後出現巨大變化。在這篇指南中,我會帶你用 Playwright 打造一個可運作的 Google Flights Python 爬蟲,示範如何應對大多數人都會卡住的反機器人機制,接著再把它延伸成可自動執行的票價追蹤器與提醒系統。如果你想完全跳過寫程式,我也會介紹一個用 的免程式替代方案,大約兩分鐘就能得到相同成果。
為什麼要用 Python 擷取 Google Flights?
Google Flights 幾乎主導了機票搜尋市場。它在美國行動裝置上的曝光率已飆升至 47.6%,超越所有主要 OTA。背後的旅遊比價搜尋市場在 2024 年估值達 83.3 億美元,年複合成長率為 30.2%。但自從 QPX Express API 在 2018 年 4 月 10 日永久關閉後,官方就不再提供任何程式化存取這些資料的方法。
同時,機票價格在同一行程上可能波動高達 50%,最低與最高價平均差距約 20 美元。像 Delta 這類航空公司甚至使用 77 個票價區間來進行動態定價。到了 2026 年初,美國平均來回機票約為 408 美元,而機票價格年增幅達 14.9%。
平台強勢、沒有 API、價格又極度不穩。這就是為什麼用 Python 抓 Google Flights,成了 GitHub 和各大旅遊論壇上最熱門的專案之一。
以下這些族群最能受益:
| 使用者類型 | 使用情境 | 主要效益 |
|---|---|---|
| 一般旅客 | 長期追蹤特定航線票價 | 平均每張機票可省下 50 美元 |
| 旅行社 | 競爭票價情報分析 | 即時監控票價一致性 |
| 企業差旅團隊 | 跨航線成本最佳化 | 企業差旅可節省 10–30% |
| 開發者 | 建立票價比較應用程式 | 程式化取得票價資料 |
| 研究人員 | 分析航空票價波動 | 學術與市場研究用途 |
論壇上的使用者也很直接地說明他們為什麼改用抓取:像是「Google Flights API 已停用,所以我應該改用網頁爬取」這類說法很常見。而且投資報酬率確實存在——Hopper 表示他們每天分析超過 50 億筆票價報價,預測準確率高達 95%;Expedia 2026 年的資料則顯示,提前 8–15 天訂票可讓國內航線平均省下約 25 美元。
你可以從 Google Flights 抓到哪些資料?
Google Flights 的結果頁面其實包含相當豐富的欄位。通常可取得的資料包括:
- 航空公司名稱(含標誌)
- 起飛時間與機場代碼
- 抵達時間與機場代碼
- 總飛行時間
- 轉機次數與轉機細節(機場、時間、是否過夜)
- 票價(依幣別顯示)
- 二氧化碳排放量(kg CO2e,並與一般航班做百分比比較)
- 艙等、航班號、機型
- 座位空間資訊
- 附加服務(Wi‑Fi、插座、影音串流)
- 價格等級指標(低/一般/高)
- 延誤警示(例如「經常延誤超過 30 分鐘」)
實際可取得的欄位會因航線、日期與票種(單程或來回)而有所不同。以下是一筆抓取到的航班資料,轉成 JSON 後大致長這樣:
1{
2 "search_date": "2026-04-16",
3 "route": "SFO-JFK",
4 "departure_date": "2026-05-15",
5 "flights": [
6 {
7 "airline": "United Airlines",
8 "flight_number": "UA123",
9 "departure_time": "08:00",
10 "departure_airport": "SFO",
11 "arrival_time": "16:35",
12 "arrival_airport": "JFK",
13 "duration_minutes": 335,
14 "stops": 0,
15 "price_usd": 287,
16 "price_level": "low",
17 "co2_kg": 156,
18 "co2_vs_typical": "-12%",
19 "travel_class": "Economy"
20 }
21 ]
22}建立 Python 環境
在開始寫爬蟲之前,先把基本環境準備好。
先決條件:
- 難度: 中等
- 所需時間: 完整教學約 1–2 小時
- 你需要準備: Python 3.7+、基礎 Python 知識、Chromium 系瀏覽器
安裝必要套件
我們會使用 Playwright 進行瀏覽器自動化(Google Flights 完全由 JavaScript 渲染——只送 HTTP 請求是拿不到有用內容的),另外再加上幾個輔助套件:
1pip install playwright playwright-stealth pandas
2playwright install chromium- Playwright — 無頭瀏覽器自動化工具,可處理 JavaScript 渲染,內建等待機制
- playwright-stealth — 修補常見的機器人偵測訊號
- pandas — 之後用來做資料分析與 CSV 匯出
為什麼選 Playwright,而不是 Selenium 或 requests
單靠 requests + BeautifulSoup 無法處理 Google Flights,因為頁面內容完全是 JavaScript 動態渲染的。你需要一個真正的瀏覽器。
| 功能 | Playwright | Selenium | requests + BS4 |
|---|---|---|---|
| JS 渲染 | 完整支援 | 完整支援 | 不支援 |
| 速度 | 整體快 42% | 基準 | 不適用 |
| 非同步支援 | 原生支援 | 只支援順序執行 | 不適用 |
| 記憶體使用 | 少 30% | 較高 | 最低 |
| 規避機器人偵測 | 表現佳(搭配 stealth) | 較容易被偵測 | 不適用 |
Playwright 更快、更現代,也更適合非同步流程。就 Google Flights 這個案例來說,它是最明確的首選。
逐步教學:如何用 Python 擷取 Google Flights
這是整篇教學的核心,我們會一步一步完成爬蟲。
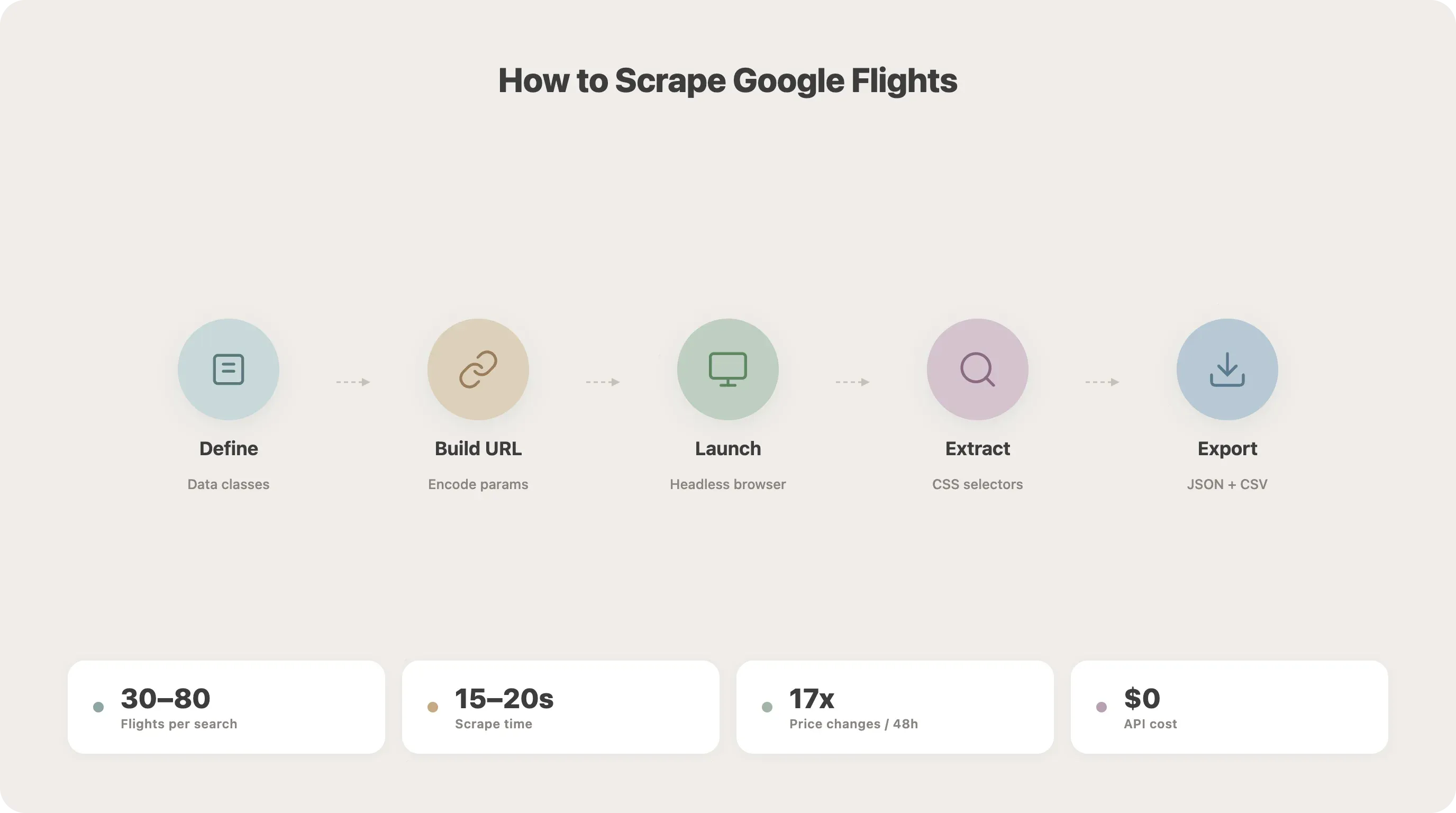
步驟 1:先定義資料結構
先用 Python dataclass 把搜尋參數和航班資料整理好。這樣程式碼會更清楚,之後擴充也更容易。
1from dataclasses import dataclass, field
2from typing import Optional, List
3@dataclass
4class SearchParams:
5 origin: str # 例如 "SFO"
6 destination: str # 例如 "JFK"
7 departure_date: str # 例如 "2026-05-15"
8 return_date: Optional[str] = None
9 trip_type: str = "one-way" # "one-way" 或 "round-trip"
10 travel_class: str = "economy"
11@dataclass
12class FlightData:
13 airline: str = ""
14 departure_time: str = ""
15 arrival_time: str = ""
16 duration: str = ""
17 stops: str = ""
18 price: str = ""
19 co2_emissions: str = ""每個欄位都會對應到我們稍後要從頁面擷取的內容。先把資料結構定好,後面就不需要一直丟雜亂的字典。
步驟 2:理解 Google Flights 的網址結構
Google Flights 會把搜尋參數編碼到 tfs URL 參數中,使用 Base64 編碼的 Protobuf。你可以嘗試逆向解析這段編碼,但更簡單的方法是直接建立一個自然語言查詢網址。
最簡單的格式如下:
1https://www.google.com/travel/flights?q=flights+from+SFO+to+JFK+on+2026-05-15&curr=USD如果你想更有彈性,也可以用程式動態產生網址:
1def build_flights_url(origin: str, destination: str, date: str) -> str:
2 base = "https://www.google.com/travel/flights"
3 query = f"flights from {origin} to {destination} on {date}"
4 return f"{base}?q={query.replace(' ', '+')}&curr=USD"另一種作法是逆向工程 Protobuf 編碼,控制會更精細,但一旦 Google 改了內部格式就可能失效。GitHub 上像 這類函式庫,就是透過 Protobuf 解碼來完全避開 HTML 解析,不過這屬於更進階的做法。
步驟 3:啟動瀏覽器並前往 Google Flights
以下是 Playwright 的設定。我們一開始就搭配 playwright-stealth,盡量降低被偵測的風險。
1import asyncio
2from playwright.async_api import async_playwright
3from playwright_stealth import Stealth
4async def scrape_flights(params: SearchParams) -> List[FlightData]:
5 async with Stealth().use_async(async_playwright()) as pw:
6 browser = await pw.chromium.launch(
7 headless=True,
8 args=[
9 "--disable-blink-features=AutomationControlled",
10 "--disable-dev-shm-usage",
11 "--no-first-run",
12 ]
13 )
14 context = await browser.new_context(
15 viewport={"width": 1920, "height": 1080},
16 user_agent=(
17 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
18 "AppleWebKit/537.36 (KHTML, like Gecko) "
19 "Chrome/125.0.0.0 Safari/537.36"
20 ),
21 locale="en-US",
22 timezone_id="America/New_York",
23 )
24 # 預先設定 cookie,同意提示可直接跳過
25 await context.add_cookies([{
26 "name": "SOCS",
27 "value": "CAESHwgBEhJnd3NfMjAyNTAyMjctMF9SQzIaBXpoLUNOIAEaBgiAy6O-Bg",
28 "domain": ".google.com",
29 "path": "/"
30 }])
31 page = await context.new_page()正式環境建議使用無頭模式(除錯時可改成 headless=False),同時設定合理的視窗大小與使用者代理,並先預設 SOCS cookie 以跳過同意彈窗——這部分在後面的反機器人章節會再細講。
步驟 4:前往搜尋結果頁
載入剛剛組好的網址,並等待航班結果出現:
1 url = build_flights_url(
2 params.origin, params.destination, params.departure_date
3 )
4 await page.goto(url, wait_until="networkidle")
5 # 等待航班結果載入
6 await page.wait_for_selector(
7 "li.pIav2d", timeout=15000
8 )如果這裡逾時,通常代表同意彈窗擋住了頁面(可回頭看步驟 3 的 cookie 解法),或者 Google 直接送出 CAPTCHA。我們會在反機器人章節同時處理這兩種情況。
步驟 5:載入所有航班結果
Google Flights 會把部分結果藏在「顯示更多航班」按鈕後面。你需要一直點它,直到所有結果都展開:
1 # 不斷點擊「顯示更多航班」,直到沒有更多結果
2 while True:
3 try:
4 more_button = page.locator(
5 'button:has-text("Show more flights")'
6 )
7 if await more_button.is_visible(timeout=3000):
8 await more_button.click()
9 await page.wait_for_timeout(2000)
10 else:
11 break
12 except Exception:
13 break這個迴圈會點擊按鈕、等待 2 秒讓新內容渲染,再在按鈕不見時停止。根據我的測試,多數航線會有 1–3 頁結果。
步驟 6:用 CSS selector 擷取航班資料
接著就來解析頁面上的實際航班資料。以下是目前有效的 selector(截至 2026 年 4 月驗證;為什麼要特別標示日期,後面維護章節會說明):
1 flights = []
2 cards = await page.query_selector_all("li.pIav2d")
3 for card in cards:
4 flight = FlightData()
5 # 航空公司名稱
6 airline_el = await card.query_selector(
7 "div.sSHqwe span:not([class])"
8 )
9 if airline_el:
10 flight.airline = (await airline_el.inner_text()).strip()
11 # 起飛時間
12 dep_el = await card.query_selector(
13 'span[aria-label*="Departure time"]'
14 )
15 if dep_el:
16 flight.departure_time = (await dep_el.inner_text()).strip()
17 # 抵達時間
18 arr_el = await card.query_selector(
19 'span[aria-label*="Arrival time"]'
20 )
21 if arr_el:
22 flight.arrival_time = (await arr_el.inner_text()).strip()
23 # 飛行時間
24 dur_el = await card.query_selector("div.gvkrdb")
25 if dur_el:
26 flight.duration = (await dur_el.inner_text()).strip()
27 # 轉機次數
28 stops_el = await card.query_selector("div.EfT7Ae span")
29 if stops_el:
30 flight.stops = (await stops_el.inner_text()).strip()
31 # 票價
32 price_el = await card.query_selector(
33 "div.FpEdX span"
34 )
35 if price_el:
36 flight.price = (await price_el.inner_text()).strip()
37 # 二氧化碳排放量
38 co2_el = await card.query_selector("div.O7CXue")
39 if co2_el:
40 flight.co2_emissions = (
41 await co2_el.get_attribute("aria-label") or ""
42 ).strip()
43 flights.append(flight)
44 await browser.close()
45 return flights要注意的是,像 pIav2d、sSHqwe、FpEdX 這類 class 名稱是 Google Closure Compiler 產生的,任何版本更新都可能改掉。相較之下,aria-label selector 會穩定得多。後面我會補充完整的維護策略。
步驟 7:把結果存成 JSON 或 CSV
最後,加上時間戳記把抓到的資料存下來(這對後續追蹤票價非常重要):
1import json
2from datetime import datetime
3from dataclasses import asdict
4async def main():
5 params = SearchParams(
6 origin="SFO",
7 destination="JFK",
8 departure_date="2026-05-15"
9 )
10 flights = await scrape_flights(params)
11 output = {
12 "search_date": datetime.now().isoformat(),
13 "params": asdict(params),
14 "flights": [asdict(f) for f in flights],
15 }
16 with open("flights.json", "w") as f:
17 json.dump(output, f, indent=2)
18 # 也存成 CSV
19 import pandas as pd
20 df = pd.DataFrame([asdict(f) for f in flights])
21 df["search_date"] = datetime.now().isoformat()
22 df["route"] = f"{params.origin}-{params.destination}"
23 df.to_csv("flights.csv", index=False)
24 print(f"Scraped {len(flights)} flights")
25asyncio.run(main())執行後,你應該會看到 flights.json 與 flights.csv 兩個檔案。根據我的測試,一次 SFO-JFK 搜尋通常會回傳 30–80 個航班選項,整個流程大約需要 15–20 秒。
Google Flights 反機器人生存指南
大多數教學都會停在這裡,但大多數爬蟲也會死在這裡。Google 在 2025 年 1 月部署了 ,幾乎一夜之間讓大部分 SERP 爬蟲失效。Google 自己也把它描述為「投入了數萬小時人力與數百萬美元資金」的成果。Google Flights 的抓取難度被評為 。
幾乎沒有競品文章會深入講這一塊,但這正是大家的爬蟲失效的頭號原因。下面就來看你會遇到什麼,以及該怎麼處理。

在請求之間加入隨機延遲
對抗速率限制最簡單的方法。只要兩行程式碼,中等效果:
1import time
2import random
3time.sleep(random.uniform(3, 7))把它加在頁面跳轉之間。固定間隔(例如每次都剛好 5 秒)很容易被標記,務必加入隨機性。
使用者代理輪替
每次請求都送出同一組 user-agent 很容易被看出來。建議從清單中隨機挑選:
1import random
2USER_AGENTS = [
3 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/125.0.0.0 Safari/537.36",
4 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14_5) AppleWebKit/605.1.15 Safari/605.1.15",
5 "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
6 "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:126.0) Gecko/20100101 Firefox/126.0",
7]
8user_agent = random.choice(USER_AGENTS)繞過無頭瀏覽器偵測
Google 會檢查 navigator.webdriver 旗標和其他自動化訊號。playwright-stealth 可以處理大部分問題,但你也應該加上步驟 3 裡提到的啟動參數。重點旗標如下:
1args=[
2 "--disable-blink-features=AutomationControlled",
3 "--disable-dev-shm-usage",
4 "--no-first-run",
5]這樣就能避開基本偵測。SearchGuard 的手法更深入,還會監測滑鼠速度、鍵盤輸入間隔與捲動模式;但對中等流量的抓取來說,stealth 模式加上真實的延遲通常已經足夠。
代理輪替:資料中心 vs. 家用代理
如果你的查詢量不只幾次,就需要代理。兩者差異很大:
| 功能 | 資料中心代理 | 家用代理 |
|---|---|---|
| 速度 | 100–1,000 Mbps | 10–100 Mbps |
| Google 成功率 | 20–40% | 85–95% |
| 成本 | 每 IP 每月 0.10–0.50 美元 | 每 GB 5–15 美元 |
| 被偵測風險 | 高 | 非常低 |
在抓取受保護網站時,家用代理的單次成功請求成本大約便宜 180 倍。2026 年的供應商價格:Smartproxy 從每 GB 7 美元起,Bright Data 為每 GB 8.40 美元,Oxylabs 為每 GB 8 美元。
在 Playwright 中加入代理的方式如下:
1browser = await pw.chromium.launch(
2 proxy={"server": "http://proxy-host:port",
3 "username": "user", "password": "pass"}
4)處理 cookie 同意彈窗
不少使用者都提到「我同意條款」彈窗會擋路:像是「一開始 Google 會先跳出『我同意條款與條件』的視窗」。最乾淨的做法就是預先設定 SOCS cookie(步驟 3 已示範)。如果這招不行,就直接點掉:
1try:
2 accept_btn = page.locator('button:has-text("Accept all")')
3 if await accept_btn.is_visible(timeout=3000):
4 await accept_btn.click()
5 await page.wait_for_timeout(1000)
6except Exception:
7 pass # 沒有彈窗注意:按鈕文字會因語言而不同——德文是「Alle akzeptieren」,法文是「Tout accepter」。
反機器人快速參考
| 技術 | 難度 | 有效性 | 需要程式碼嗎? |
|---|---|---|---|
| 隨機延遲(2–7 秒) | 低 | 中 | 2 行 |
| 使用者代理輪替 | 低 | 中 | 5 行 |
| 繞過無頭偵測 | 中 | 高 | Playwright 啟動參數 |
| playwright-stealth 外掛 | 中 | 基礎網站可達 60–80% | pip install |
| 代理輪替(資料中心) | 中 | 中 | 設定即可 |
| 代理輪替(家用) | 中 | 成功率 85–95% | 設定即可 |
| 預設 cookie 同意(SOCS) | 低 | 必要 | 1 行 |
建議的安全頻率是:搭配 IP 輪替時,請求間隔維持 10–20 秒。Google 的門檻大約是每個 IP 每分鐘 100 次請求,若單一 IP 持續每天超過 1,000 次請求,可能會觸發暫時封鎖。
為什麼你的 Google Flights selector 一直壞掉,以及怎麼修
這幾乎是最常見的痛點。論壇上充滿了類似「我拿回來的全是 14 個空清單」這種抱怨。每篇教學都會給你 selector,但很少有人解釋為什麼它們會壞。
Google Flights 的 selector 為什麼會變
主要有三個原因:
-
Closure Compiler 混淆。 Google 使用 和
goog.setCssNameMapping()來產生像BVAVmf、YMlIz這樣的 class 名稱。這些名稱每次建置都可能變,甚至每週都換。 -
A/B 測試。 不同使用者會同時看到不同的 HTML 結構。你的爬蟲在自己電腦上能跑,不代表別的地區也能跑。
-
語系差異。 歐盟使用者看到的術語、版面,甚至資料欄位都可能與美國使用者不同。
寫出更穩健的 selector
優先選擇和「意義」綁定,而不是和外觀綁定的 selector:
1# 很脆弱——每次建置都可能壞掉
2price_el = await card.query_selector("div.BVAVmf > div.YMlIz")
3# 比較穩健——綁定無障礙標籤
4 dep_el = await card.query_selector('span[aria-label*="Departure time"]')
5# 也很穩健——用文字比對
6more_btn = page.locator('button:has-text("Show more flights")')selector 穩定性排序(由穩到不穩):
aria-label屬性——和無障礙設計綁定,較少變動data-*屬性——功能性用途明確標記role屬性——ARIA role 本身有語意- 文字型 selector——比對畫面上的文字
- 子字串 class 比對——例如
[class*="price"] - 完整混淆 class 名稱——能避就避
加入驗證函式
不要讓 selector 壞掉卻悄悄產生空資料。應該及早發現:
1import logging
2logger = logging.getLogger(__name__)
3def validate_flight(data: FlightData) -> bool:
4 required = ["airline", "price", "departure_time",
5 "arrival_time", "duration"]
6 valid = True
7 for field_name in required:
8 if not getattr(data, field_name, ""):
9 logger.warning(
10 f"缺少 '{field_name}' —— selector 可能需要更新"
11 )
12 valid = False
13 return valid每一筆抓到的航班都跑一次這個檢查。如果開始出現警告,就表示該打開頁面檢查並更新 selector 了。
selector 維護策略
- 每月檢查一次 selector,或者在輸出品質下降時立即檢查
- 把 selector 集中放在獨立設定檔,方便快速更新
- 本文中的 selector 最後驗證時間:2026 年 4 月
- 也可以考慮 作為替代方案——它使用 Protobuf 解碼而不是 CSS selector,能完全避開這個問題(但當 Google 改變內部資料格式時,它也有自己的脆弱性)
從一次性抓取,升級成自動化的 Google Flights 票價追蹤器
大多數教學都停在「存成 JSON」這一步。但這篇文章的標題是「票價提醒」,所以我們現在把它做完。
![]()
排程讓爬蟲自動執行
方案 1:Python schedule 套件(最簡單、跨平台):
1import schedule
2import time
3def run_scraper():
4 asyncio.run(main())
5schedule.every().day.at("06:00").do(run_scraper)
6schedule.every().day.at("18:00").do(run_scraper)
7while True:
8 schedule.run_pending()
9 time.sleep(60)方案 2:cron job(Linux/Mac):
1# 每天早上 6 點與晚上 6 點執行
20 6,18 * * * cd /path/to/scraper && python scraper.py方案 3:Windows Task Scheduler — 建立一個基本工作,依你想要的排程執行 python scraper.py。
這些方案的代價是:你需要一台永遠開著的機器。如果你放在會睡眠的筆電上,就會漏抓。
保存歷史票價資料
把原本覆蓋 JSON 檔的方式,改成持續追加到 SQLite 資料庫:
1import sqlite3
2from datetime import datetime
3def init_db():
4 conn = sqlite3.connect("flights.db")
5 conn.execute("""
6 CREATE TABLE IF NOT EXISTS flights (
7 id INTEGER PRIMARY KEY AUTOINCREMENT,
8 scrape_date TEXT NOT NULL,
9 route TEXT NOT NULL,
10 airline TEXT,
11 departure_time TEXT,
12 arrival_time TEXT,
13 duration TEXT,
14 stops TEXT,
15 price_usd REAL,
16 co2_emissions TEXT
17 )
18 """)
19 conn.execute(
20 "CREATE INDEX IF NOT EXISTS idx_route_date "
21 "ON flights(route, scrape_date)"
22 )
23 conn.commit()
24 return conn
25def save_flight(conn, route: str, flight: FlightData):
26 price_num = float(
27 flight.price.replace("$", "").replace(",", "")
28 ) if flight.price else None
29 conn.execute(
30 "INSERT INTO flights "
31 "(scrape_date, route, airline, departure_time, "
32 "arrival_time, duration, stops, price_usd, co2_emissions) "
33 "VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?)",
34 (datetime.now().isoformat(), route, flight.airline,
35 flight.departure_time, flight.arrival_time,
36 flight.duration, flight.stops, price_num,
37 flight.co2_emissions)
38 )
39 conn.commit()持續抓一週、每天兩次後,你就有足夠資料開始觀察趨勢了。
分析票價趨勢並設定提醒
從歷史資料中找出最便宜的選項:
1import pandas as pd
2import sqlite3
3conn = sqlite3.connect("flights.db")
4df = pd.read_sql_query(
5 "SELECT * FROM flights WHERE route = 'SFO-JFK'", conn
6)
7summary = df.groupby("scrape_date")["price_usd"].agg(
8 ["min", "max", "mean"]
9)
10cheapest = df.loc[df["price_usd"].idxmin()]
11print(
12 f"最便宜票價:${cheapest['price_usd']:.0f},"
13 f"日期:{cheapest['scrape_date']}({cheapest['airline']})"
14)當價格低於你的門檻時,就寄出 email 提醒:
1import smtplib
2from email.mime.text import MIMEText
3def send_price_alert(route, price, threshold, recipient):
4 msg = MIMEText(
5 f"票價下跌通知!{route}:${price:.0f} "
6 f"(已低於你設定的 ${threshold:.0f} 門檻)"
7 )
8 msg["Subject"] = f"航班優惠:{route} 價格 ${price:.0f}"
9 msg["From"] = "alerts@example.com"
10 msg["To"] = recipient
11 with smtplib.SMTP_SSL("smtp.gmail.com", 465) as server:
12 server.login("alerts@example.com", "your_app_password")
13 server.send_message(msg)
14# 每次抓取後檢查是否有優惠
15min_price = df["price_usd"].min()
16threshold = 250
17if min_price < threshold:
18 send_price_alert("SFO-JFK", min_price, threshold,
19 "you@email.com")建議的抓取頻率:個人票價追蹤每天兩次就夠了(隨機時間可降低被偵測風險)。若是商業監控,可提升到每 4–6 小時一次。只有在短期特價促銷期間,才建議暫時提高到每小時一次。
更簡單的做法:Thunderbit 的排程爬蟲
如果你覺得 cron、長期運作的伺服器、以及代理設定太像一堆要維護的基礎設施,那麼 的排程爬蟲可以不用這些額外負擔,完成同樣的需求。你只要用自然語言描述抓取頻率,貼上 Google Flights 網址,爬蟲就會在 Thunderbit 的雲端基礎架構上自動執行——內建反機器人處理,結果還能直接匯出到 。它不完全等同於完整的 Python 方案(彈性較少),但如果你的目標只是做一份「票價追蹤表」,那它就是最快的路徑。你可以先試試看 。
當 Python 太重:不用寫程式也能抓 Google Flights
把前面那些都做完後,我必須老實說:這真的有不少零件。不是每個人都需要這麼高的控制度。selector 會壞、代理要輪替、cron 要監控。如果你的目標只是「定期把票價放進試算表」,其實有更快的選項。
比較:自己寫 Python、API 服務、Thunderbit
| 方案 | 設定時間 | 需要寫程式嗎 | 反機器人處理 | 排程 | 成本 |
|---|---|---|---|---|---|
| 自己動手寫 Playwright(本教學) | 1–2 小時 | 需要 Python(中等程度) | 需手動設定 | 手動(cron) | 免費 + 代理成本 |
| SerpApi Google Flights endpoint | 15 分鐘 | 只需 API 呼叫 | 已處理 | 透過 API | 每月約 50 美元以上 |
| Thunderbit Chrome 擴充功能 | 2 分鐘 | 不需要 | 雲端爬取 | 內建排程 | 有免費方案 |
關於 SerpApi,值得注意的是:Google 在 2025 年 12 月對 SerpApi 提起 DMCA 訴訟,理由是他們的請求量在兩年間成長了 25,000%。如果你正在評估 API 供應商,這樣的法律不確定性值得納入考量。
Thunderbit 如何抓取 Google Flights
在 Chrome 裡打開你的 Google Flights 搜尋結果,點擊 Thunderbit 的「AI 建議欄位」按鈕——AI 會讀取頁面並建議像航空公司、票價、起飛時間、轉機次數這些欄位;接著檢查建議欄位,按下「抓取」即可。結果會以表格顯示,你可以匯出到 Excel、Google Sheets、Airtable 或 Notion——而且免費方案就能用。
若是專注在票價追蹤這個用途,Thunderbit 的排程爬蟲與 (可同時處理 50 個頁面)可以直接取代整套 cron + 代理 + 伺服器基礎架構。
Python 的優勢是完全可控、客製化無上限;Thunderbit 的優勢是速度快、幾乎不用維護。請依照你的實際需求選擇。如果你想進一步了解免程式抓取方式,可以看看我們整理的 。

抓取 Google Flights 合法嗎?你需要知道的事
論壇使用者經常會問:「直接抓 Google Flights 會違反 Google 的服務條款嗎?」 這確實是合理的疑慮,尤其在 API 已停用、又沒有官方替代方案的情況下。
違反服務條款 vs. 法律責任
Google 服務條款(2024 年 5 月 22 日更新)明定,使用者不得「透過任何自動化方式(例如 robots、spiders 或 scrapers)存取或使用服務或內容」。違反 ToS 屬於違約(民事範疇),不等於犯罪。
最重要的法律先例是 hiQ v. LinkedIn(第九巡迴上訴法院,2022 年),該案確認抓取公開可得資料不違反《電腦詐欺與濫用法》(CFAA)。不過,該案最後是以和解結束;而 Google 在 2025 年 12 月對 SerpApi 的訴訟,則改用不同的法律理論——DMCA 第 1201 條(繞過技術保護措施),潛在風險可能更高。
負責任抓取的最佳做法
- 限制請求速率——搭配 IP 輪替,每次延遲 10–20 秒
- 不要抓取個人資料——機票價格屬於公開顯示的彙總資料
- 不要以程式方式繞過 CAPTCHA(這正是 DMCA 風險區)
- 將資料用於個人研究,不要在沒有授權的情況下做成競品商業產品
- 若有官方 API,優先考慮官方方案
替代資料來源
如果你覺得抓取對你的情境太冒險,也有合法的 API 選項:
| 供應商 | 成本 | 免費方案 | 備註 |
|---|---|---|---|
| SerpApi | 每月 75–3,750+ 美元 | 每月 250 次搜尋 | 直接提供 Google Flights JSON(目前有法律爭議) |
| Kiwi Tequila | 免費(聯盟模式) | 無限 | 適合新創與測試 |
| Amadeus | 按量計費 | 每月 2,000 次請求 | 400+ 航空公司,含訂票能力 |
| Skyscanner | 客製化 | 需審核 | 52 個市場、30 種語言 |
如果你想看完整脈絡,我們也寫過一篇更深入的 分析。
結論與重點整理
內容很多,我幫你整理成最重要的幾點:
- Python + Playwright 是抓取 Google Flights 最有彈性的方案,但需要持續維護
- 反機器人措施(延遲、user-agent 輪替、家用代理)不是可選項,而是可靠運作的必要條件,尤其在 SearchGuard 上線後更是如此
- selector 很常壞——盡量使用
aria-label和文字型 selector,記得驗證輸出並安排維護時間 - 用
schedule或 cron 自動化,就能把一次性抓取變成真正的票價追蹤器,累積歷史資料並寄出 email 提醒 - 提供免程式替代方案,內建排程、雲端爬取與反機器人處理——如果你的目標是做一份票價追蹤表,而不是寫程式專案,它會非常適合
- 注意法律界線——控制頻率、只抓公開資料,商業用途則要考慮 API 替代方案
你可以直接使用這篇教學的程式碼,或安裝 走快速路線。不管選哪種方式,你都不必再手動重整 Google Flights,而是讓票價追蹤自動跑起來。
若想學更多 Python 抓取技巧,歡迎參考我們的 與 指南。
常見問題
1. 不用 Python,也能抓 Google Flights 嗎?
可以。像 SerpApi 和 Kiwi Tequila 這類 API 服務,可以透過 API 呼叫提供結構化的航班資料(不需要瀏覽器自動化)。如果你要完全不寫程式, 也能直接從瀏覽器抓 Google Flights 結果,搭配 AI 建議欄位與一鍵匯出功能。
2. Google 會阻擋航班資料抓取嗎?
Google 會使用機器人偵測(SearchGuard)、CAPTCHA 與速率限制。只要搭配正確的反機器人措施——隨機延遲、user-agent 輪替、家用代理、以及 stealth 瀏覽器設定——中等流量下仍然可以維持穩定抓取。上面的反機器人章節有具體技巧與門檻。
3. 做票價追蹤時,多久抓一次 Google Flights 比較好?
每天兩次(時間隨機)就足以做個人票價觀察,而且能把被偵測風險降到較低。若是商業監控,可提高到每 4–6 小時一次並搭配代理輪替。除非是短期特價活動,否則不建議每小時抓一次,因為被封鎖的機率會明顯上升。
4. 有免費的 Google Flights API 嗎?
官方的 Google QPX Express API 已在 2018 年 4 月停用,沒有免費的官方替代方案。最接近的免費選項是 (聯盟模式,搜尋次數無上限)。SerpApi 每月提供 250 次免費搜尋。對多數使用者來說,抓取或像 Thunderbit 這樣的免程式工具,都是更實際的做法。
5. 為什麼我的 Google Flights CSS selector 一直抓到空資料?
Google 使用 Closure Compiler 產生會混淆的 class 名稱,而且每次建置都可能改變。A/B 測試和語系差異也會讓不同使用者看到不同的 HTML 結構。解法是:改用 aria-label 屬性與文字型 selector,而不是 class 名稱;加上驗證函式及早發現失效;並每月檢查一次 selector。詳細策略請參考 selector 維護章節。
延伸閱讀