如果你的 Glassdoor 爬蟲在 2022 年跑得好好的,現在卻只會回傳 403,那你不是唯一一個遇到這種狀況的人。從論壇到社群,到處都看得到同樣的問題:「有人知道為什麼這個爬蟲現在不能用了嗎?」
簡單講:Glassdoor 已經整個變了。Recruit Holdings 在 2025 年 7 月把 Glassdoor 整併進 Indeed,並裁撤了 ,同時也把反機器人防護全面升級到連最基本的 Selenium 和 requests 型爬蟲,都會在第一個 HTML 位元組載入前就被擋下來。到了 2026 年 2 月,Glassdoor 的登入流程也已經全面改由 Indeed Login 處理——所以任何還在照抄 Glassdoor 舊登入表單的教學,從架構上就已經失效。與此同時,這個平台仍保有超過 ,涵蓋 。這些資料對 HR 基準分析、競爭情報、業務開發都很有價值——前提是你要先拿得到。本指南是經過這些變動後仍然可用的版本,並且一次涵蓋 Glassdoor 的三種資料類型(職缺、評論與薪資)。我會用可運作的 2025 程式碼帶你走一遍 Python 做法,清楚說明到底是什麼在擋你、又該怎麼突破,最後也會示範一個不寫程式的替代方案,適合想省掉工程細節的人。
為什麼 2025 年還要用 Python 抓 Glassdoor?
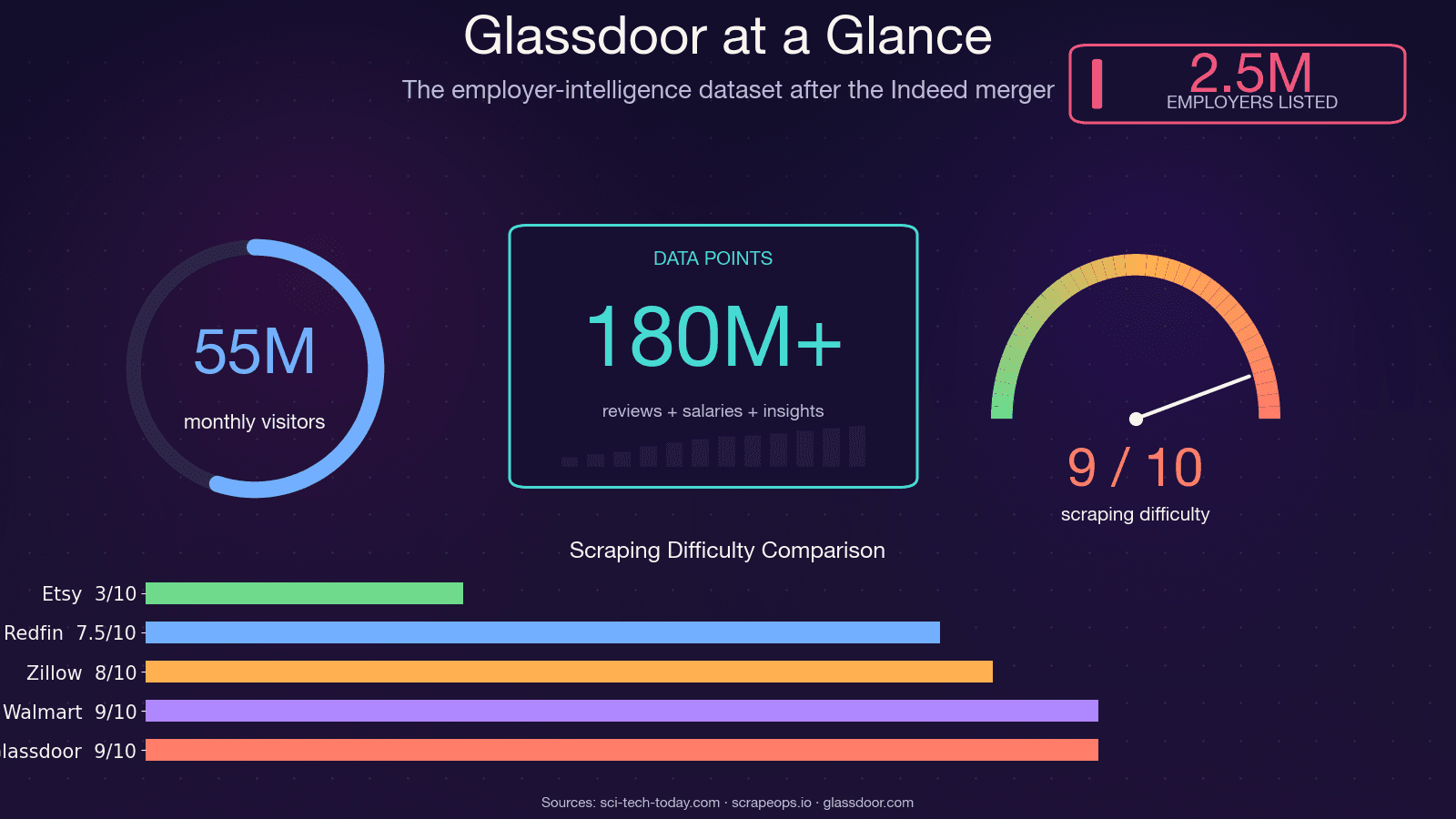
Glassdoor 不只是求職網站,它也是網路上最完整的雇主情報資料庫之一——大約有 會使用它,每月也有約 5,500 萬不重複訪客。這些頁面背後的資料,其實支撐著不少部門的重要決策。
以下是不同團隊實際怎麼用 Glassdoor 資料:
| 應用情境 | 需要的資料類型 | 受益對象 |
|---|---|---|
| 薪資基準比較 | 薪資分布、樣本數 | HR、總獎酬、營運 |
| 競爭對手招募追蹤 | 職缺清單、刊登速度 | 業務、策略、投資/企業發展 |
| 雇主品牌監測 | 評論內容、評分趨勢、CEO 核准率 | HR、行銷、公關 |
| 開發潛在客戶(成長型公司) | 職缺清單 + 公司資訊 | 業務團隊、SDR |
| 市場/學術研究 | 三種資料全部 | 分析師、顧問、研究人員 |
當美國勞工統計局在 2025 年 10 月政府停擺期間無法發布職缺數據時,Glassdoor 自家經濟研究團隊直接。這也說明了,現在機構級分析師有多重視這類資料。
Python 之所以還是首選語言,關鍵在於它的生態系真的很完整——Playwright 可做瀏覽器自動化、parsel/lxml 可做解析、curl_cffi 能繞過 TLS 指紋辨識,再加上龐大的社群一直在分享可用做法。問題不在 Python;問題在於 Glassdoor 現在真的難抓很多。
如果你想要一個不用寫程式的 Glassdoor 資料擷取替代方案,Thunderbit 可以幫你抓取職缺、評論與薪資頁面,而且不用自己建立和維護 Python 技術棧。
你到底能抓到哪些 Glassdoor 資料?
多數教學只會講職缺清單。但根據我追蹤過的論壇串、GitHub issue 與 Reddit 提問,使用者最想要的其實是沒人教的兩種資料:評論與薪資。以下是三大類資料可擷取內容的完整整理。
職缺清單
這是最容易取得的資料類型。你可以抓到:職稱、公司名稱、地點、薪資估計、公司評分、刊登日期、Easy Apply 標記,以及職缺連結。職缺清單在未登入狀態下有部分可見,不過 Glassdoor 可能在翻了幾頁後跳出登入視窗。
公司評論
這部分最適合拿來做雇主品牌分析。可擷取欄位包括:整體評分、分項評分(工作與生活平衡、文化與價值觀、多元與包容、職涯機會、薪酬與福利、高階管理)、優點文字、缺點文字、評論者職稱、評論日期,以及在職狀態。完整評論內容需要登入,未登入時你只會看到摘要,完整的優缺點文字則會被擋住。
薪資資料
這是需求最高、同時也最令人頭痛的資料類型。你可以擷取:職稱、底薪區間、總薪酬區間、薪資回報數量,以及地點。不過薪資頁面完全需要登入,Glassdoor 有時還會再加上一個「貢獻資料才能解鎖」流程,要求你先提交自己的薪資才能看別人的。市面上沒有其他教學提供可用程式碼來處理這件事——我們會在本文補上。
哪些內容需要登入、哪些不需要
這張表可以幫你少踩坑,避免抓到一半才發現頁面其實是空的:
| 資料類型 | 未登入可否使用? | 備註 |
|---|---|---|
| 職缺標題與基本資訊 | 大多可以 | 可能在翻閱幾頁後跳出彈窗 |
| 完整職缺描述 | 部分可用 | 常在看 2~3 次後被限制 |
| 公司評論(完整文字) | 不行,需登入 | 可見摘要,完整內容被鎖 |
| 薪資資料 | 不行,需登入 | 也可能要求「貢獻後解鎖」 |
為什麼你舊的 Glassdoor 爬蟲大多已經壞掉?
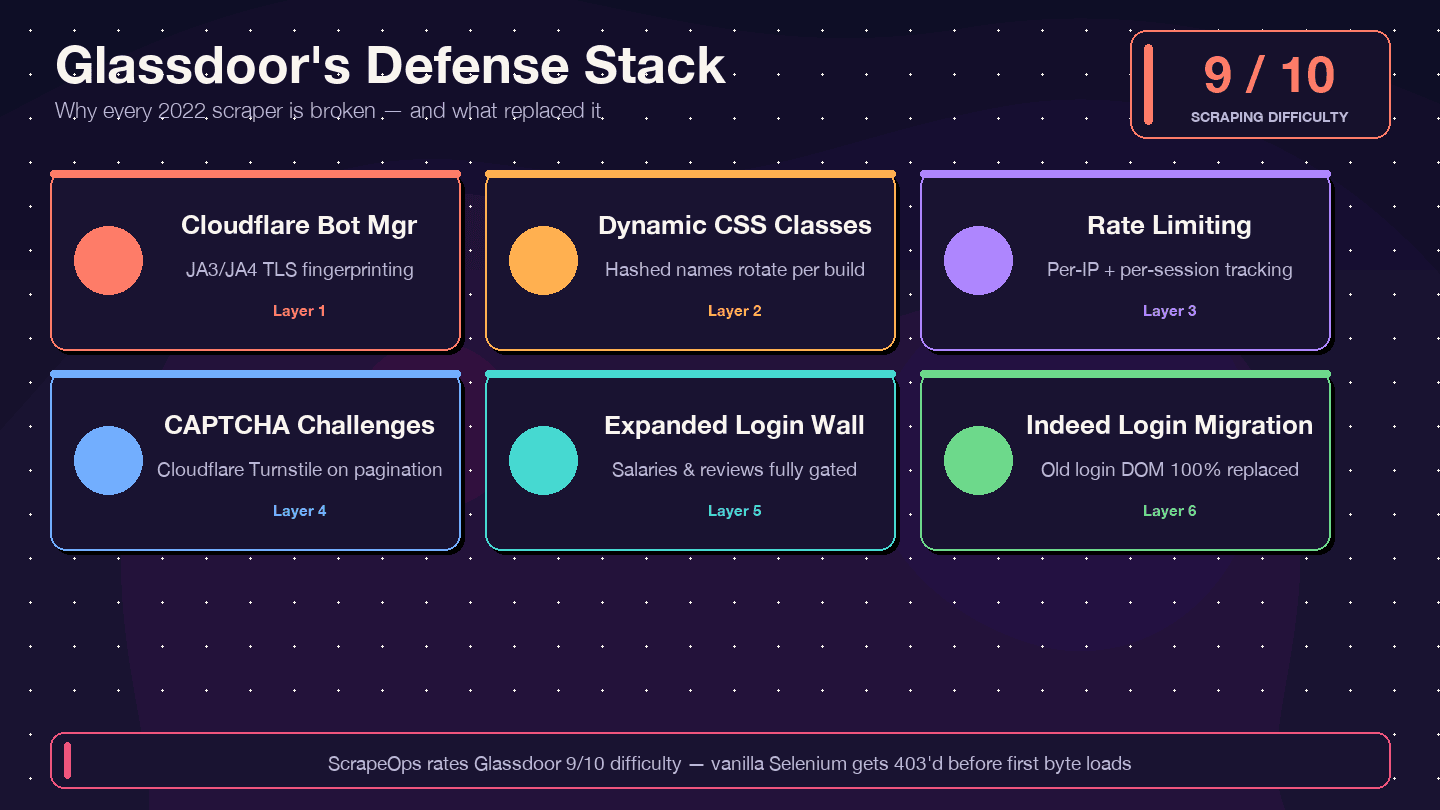
我先直接講結論:如果你還在複製 2021~2023 年的教學程式,它現在幾乎不可能再跑。GitHub 上最熱門的舊版 Glassdoor Selenium 爬蟲之一(,約 1.4k stars)有 12 個以上未解決 issue,包含「Glassdoor 新 UI 設計」、「Cloudflare 反機器人防護」與「NoSuchElementException」。這個 repo 基本上已經停更。。,繞過難度則是 8/10。
以下是變動內容,以及舊程式為何失效:
| 防護層 | 改變了什麼 | 對舊爬蟲的影響 |
|---|---|---|
| Cloudflare Bot Management | 自 2024 年起更嚴格檢查 JA3/JA4 指紋 | 基礎 requests/Selenium 腳本會立刻收到 403 |
| 動態 CSS class 名稱 | 每次部署都重新隨機化 class 名稱 | 教學文中的舊 CSS selector 會悄悄失效 |
| 速率限制 + session 追蹤 | 每個 IP 與每個 session 的限制更嚴格 | 爬到的頁數更少就會被封鎖 |
| CAPTCHA 挑戰(很可能是 Cloudflare Turnstile) | 更常出現,尤其在分頁時 | Headless 瀏覽器容易觸發挑戰 |
| 擴大的登入牆 | 更多頁面類型都要求驗證 | 薪資與評論頁會回傳空資料 |
| Indeed Login 遷移(2026 年 2 月) | Glassdoor 登入表單被完全替換 | 所有鎖定舊登入 DOM 的程式都失效 |
也明確警告:「Glassdoor 以高阻擋率著稱,所以如果你在執行 Python 程式時看到 None,很可能代表你已經被擋了。」而 則講得更直接:「用 requests 或 httpx 發送簡單 HTTP 請求,會立刻被擋下來。」
接下來我會示範的對策——Patchright(Playwright 的隱匿版分支)、data-test 屬性 selector、輪換住宅代理、以及已驗證的持久化 session——就是專門拿來處理這些防線的。
Glassdoor API 與 Python 爬蟲:先選對方法
很多論壇都會問:「我是不是直接用 Glassdoor API 就好?」答案是:不行。
。開發者入口雖然名義上還在,但實際上會。而且它從來就沒有公開的評論 endpoint——MatthewChatham 的爬蟲之所以存在,正是因為「Glassdoor 沒有提供評論 API」。在 Indeed 的 Publisher API 架構下,也沒有針對評論或薪資的遷移方案。
誠實比較如下:
| 因素 | Glassdoor Partner API v1 | Python 爬取 | Thunderbit(無程式碼) |
|---|---|---|---|
| 存取方式 | 不再接受新申請 | 開放(需自行實作) | Chrome 擴充功能 |
| 職缺清單 | 功能有限/已退場 | 可取得,但需花工夫 | 可用 |
| 公司評論 | 從未公開提供 | 可以(需登入) | 可以(透過瀏覽器模式) |
| 薪資資料 | 從未公開提供 | 可以(需登入) | 可以 |
| 速率限制 | 未公開 | 由你自己控制 | 以額度計算 |
| 設定成本 | 無法註冊新應用 | 幾小時到幾天 | 約 2 分鐘 |
| 維護成本 | 不適用 | 高(HTML 一變就壞) | 低(AI 會重新建議欄位) |
如果你需要的是評論或薪資資料——而大多數讀到這裡的人都是——那麼 Python 爬取或無程式碼工具就是你唯一實際可行的選項。
開始之前
- 難度: 中階(你應該對 Python 與終端機有基本熟悉度)
- 所需時間: 完整設定約 30~60 分鐘;之後每種資料類型約 10 分鐘
- 你需要準備:
- Python 3.10+(建議 3.11 或 3.12)
- 已安裝 Chrome 瀏覽器
- 一個 Glassdoor 帳號(免費,抓薪資與評論需要)
- 住宅代理輪換服務(如果你要抓超過少量頁面)
- 選用:,如果你想走免程式碼路線
2025 年用 Python 抓 Glassdoor 的工具與函式庫
現在的工具選擇已經大幅改變。以下是目前真正能對付 Glassdoor 防護的方法。
為什麼 Patchright 是抓 Glassdoor 的最佳選擇
是 Playwright 的隱匿分支,修補了 Runtime.Enable 的 CDP 洩漏——這正是原生 Playwright 在受 Cloudflare 保護網站上會失敗的關鍵技術原因。它使用與 Playwright 完全相同的 API,所以如果你會 Playwright,就能直接上手 Patchright。最新版本 1.58.2(2026 年 3 月)目前仍持續維護中。
與其他方案相比:
- 原生 Playwright: 會因 Runtime.Enable 洩漏而在 Glassdoor 登入頁被偵測
- Selenium + undetected-chromedriver: undetected-chromedriver 的最後一次釋出是在 2024 年 2 月,基本上已經算是舊世代。 顯示它「在我們測試的每個網域都失敗」
- requests + BeautifulSoup: 無法渲染 JavaScript,且會立刻被 Cloudflare 的 TLS 指紋辨識擋下
- : 如果頁面在初始 HTML 就送出
__NEXT_DATA__,它是走快速路徑的絕佳選擇(比瀏覽器快 10~20 倍),但無法處理登入或中間挑戰頁
支援函式庫
- parsel(1.11.0)或 lxml(6.0.4):快速 HTML/XPath 解析
- csv 或 pandas:資料匯出
- asyncio:非同步抓取,加快分頁速度
代理:只能用住宅代理
Glassdoor 的 Cloudflare 層會特別針對資料中心 ASN 發起挑戰。。入門價格約為 (促銷價)或 的 3.00 美元/GB。若要生產環境使用,依量級預算每 GB 3~8 美元較合理。
不管代理品質多好,每次請求之間都要加上隨機延遲(至少 3~8 秒,長時間跑批建議 5~15 秒)。
第 1 步:設定 Python 環境
先建立專案資料夾並安裝推薦套件:
1mkdir glassdoor-scraper && cd glassdoor-scraper
2python3.11 -m venv .venv
3source .venv/bin/activate
4pip install --upgrade pip
5# 核心套件
6pip install patchright==1.58.2 parsel==1.11.0
7# 安裝瀏覽器二進位檔
8patchright install chromium
9# 選用:用於快速擷取 __NEXT_DATA__
10pip install "curl_cffi==0.15.0"你應該會看到 Patchright 下載 Chromium 二進位檔。如果 patchright install chromium 失敗,請檢查磁碟空間是否足夠(約 300MB),以及你的 Python 版本是否為 3.10+。
第 2 步:啟動 Patchright 並前往 Glassdoor
以下是能順利對抗 Glassdoor Cloudflare 層的基礎啟動方式:
1from patchright.sync_api import sync_playwright
2import random, time
3with sync_playwright() as p:
4 browser = p.chromium.launch(
5 headless=False, # headless 仍然比較容易被偵測
6 channel="chrome", # 使用真正的 Chrome,而不是內建 Chromium
7 )
8 context = browser.new_context(
9 viewport={"width": 1440, "height": 900},
10 locale="en-US",
11 timezone_id="America/New_York",
12 user_agent=(
13 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
14 "AppleWebKit/537.36 (KHTML, like Gecko) "
15 "Chrome/134.0.0.0 Safari/537.36"
16 ),
17 )
18 page = context.new_page()
19 page.goto(
20 "https://www.glassdoor.com/Job/new-york-data-engineer-jobs-"
21 "SRCH_IL.0,8_IC1132348_KO9,22.htm"
22 )
23 # 關閉登入覆蓋層——資料其實仍在 DOM 裡
24 page.add_style_tag(content="""
25 #HardsellOverlay, .LoginModal { display: none !important; }
26 body { overflow: auto !important; position: initial !important; }
27 """)
28 page.wait_for_selector("[data-test='jobListing']")
29 print("頁面載入完成——已看見職缺列表。")這裡有幾個重點。channel="chrome" 會讓 Patchright 使用你本機安裝的 Chrome 二進位檔,而不是它自帶的 Chromium,這樣瀏覽器指紋會更像真實使用者。add_style_tag 這個技巧則是直接把 Glassdoor 的登入彈窗(#HardsellOverlay)隱藏掉,而不用真的去點任何按鈕。「所有內容其實都還在,只是被覆蓋層蓋住了」——HTML 裡本來就有資料,不管彈窗有沒有顯示。
你應該會看到 Chrome 視窗開啟、進入 Glassdoor 職缺搜尋頁,並在沒有登入彈窗阻擋的情況下顯示職缺卡片。
第 3 步:抓取 Glassdoor 職缺清單
找出穩定的 selector
Glassdoor 會在每次部署時重新隨機化 CSS class 名稱,所以 2023 年教學中的 .jobCard_xyz123 之類 selector,今天只會悄悄回傳空值。正確做法是改用 data-test 屬性,這是 Glassdoor 內部測試用的慣例標記,通常在發版間都相當穩定。
以下是職缺欄位的 selector 對照表:
| 欄位 | Selector |
|---|---|
| 職缺卡片容器 | [data-test="jobListing"] |
| 職稱 | [data-test="job-title"] |
| 職缺連結 | a[data-test="job-link"] |
| 公司名稱 | [data-test="employer-name"] |
| 地點 | [data-test="emp-location"] |
| 薪資區間 | [data-test="detailSalary"] |
| 公司評分 | [data-test="rating"] |
| 刊登日期 | [data-test="job-age"] |
| 下一頁分頁 | [data-test="pagination-next"] |
擷取職缺資料
1from parsel import Selector
2import csv, random, time
3def scrape_jobs(page, max_pages=5):
4 all_jobs = []
5 for page_num in range(1, max_pages + 1):
6 html = page.content()
7 sel = Selector(text=html)
8 cards = sel.css('[data-test="jobListing"]')
9 if not cards:
10 print(f"第 {page_num} 頁:找不到卡片,可能被擋或 selector 已變更。")
11 break
12 for card in cards:
13 job = {
14 "title": card.css('[data-test="job-title"]::text').get("").strip(),
15 "company": card.css('[data-test="employer-name"]::text').get("").strip(),
16 "location": card.css('[data-test="emp-location"]::text').get("").strip(),
17 "salary": card.css('[data-test="detailSalary"]::text').get("").strip(),
18 "rating": card.css('[data-test="rating"]::text').get("").strip(),
19 "link": card.css('a[data-test="job-link"]::attr(href)').get(""),
20 "posted": card.css('[data-test="job-age"]::text').get("").strip(),
21 }
22 if job["link"] and not job["link"].startswith("http"):
23 job["link"] = "https://www.glassdoor.com" + job["link"]
24 all_jobs.append(job)
25 print(f"第 {page_num} 頁:已抓到 {len(cards)} 筆職缺")
26 # 分頁
27 next_btn = page.query_selector('[data-test="pagination-next"]')
28 if next_btn and page_num < max_pages:
29 next_btn.click()
30 time.sleep(random.uniform(3, 8))
31 page.wait_for_selector("[data-test='jobListing']")
32 else:
33 break
34 return all_jobs存成 CSV
1def save_to_csv(jobs, filename="glassdoor_jobs.csv"):
2 if not jobs:
3 print("沒有可儲存的職缺資料。")
4 return
5 keys = jobs[0].keys()
6 with open(filename, "w", newline="", encoding="utf-8") as f:
7 writer = csv.DictWriter(f, fieldnames=keys)
8 writer.writeheader()
9 writer.writerows(jobs)
10 print(f"已將 {len(jobs)} 筆職缺儲存到 {filename}")關於分頁上限要注意:不管總數多少,Glassdoor 搜尋結果大約只開放到 30 頁。如果你需要更完整的覆蓋範圍,應該用篩選器(地點、職務類型、薪資區間)把每次搜尋縮小,而不是硬要翻超過上限。
我實測抓 5 頁職缺(大約 75 筆)搭配隨機延遲,約花了 45 秒。若用人工複製貼上,同樣的工作至少要 20 分鐘。
第 4 步:抓取 Glassdoor 公司評論
這一段是其他教學幾乎都不會提供可運作程式碼的地方。評論正是雇主情報最有價值的來源——情緒傾向分析、文化信號、管理警訊都藏在這裡。
前往評論頁
評論網址格式如下:/Reviews/{Company}-Reviews-E{id}.htm。你可以先在 Glassdoor 搜尋公司,再從網址中找出雇主 ID。
1def navigate_to_reviews(page, company_reviews_url):
2 page.goto(company_reviews_url)
3 page.add_style_tag(content="""
4 #HardsellOverlay, .LoginModal { display: none !important; }
5 body { overflow: auto !important; position: initial !important; }
6 """)
7 page.wait_for_selector('[data-test="review"]', timeout=15000)隱藏的 BFF Endpoint(最乾淨的做法)
我研究後最大的發現是:Glassdoor 評論其實有一個可正常運作的內部 JSON API,完全不需要解析 HTML。 有記錄這個 endpoint,而且它比直接從 DOM 抓資料可靠得多。
1import json, re, requests
2def get_review_ids(page):
3 """從評論頁 HTML 擷取 employerId 與 dynamicProfileId。"""
4 html = page.content()
5 sel = Selector(text=html)
6 script_text = sel.xpath(
7 "//script[contains(text(), 'profileId')]/text()"
8 ).get("")
9 employer_match = re.search(r'"employer"\s*:\s*(\{[^}]+\})', script_text)
10 if employer_match:
11 meta = json.loads(employer_match.group(1))
12 return meta.get("id"), meta.get("profileId")
13 return None, None
14def fetch_reviews_bff(page, employer_id, profile_id, max_pages=5):
15 """呼叫 Glassdoor 內部 BFF endpoint 取得結構化評論資料。"""
16 all_reviews = []
17 cookies = {c["name"]: c["value"] for c in page.context.cookies()}
18 for pg in range(1, max_pages + 1):
19 payload = {
20 "applyDefaultCriteria": True,
21 "employerId": employer_id,
22 "dynamicProfileId": profile_id,
23 "employmentStatuses": ["REGULAR", "PART_TIME"],
24 "language": "eng",
25 "onlyCurrentEmployees": False,
26 "page": pg,
27 "pageSize": 10,
28 "sort": "DATE",
29 "textSearch": "",
30 }
31 resp = requests.post(
32 "https://www.glassdoor.com/bff/employer-profile-mono/employer-reviews",
33 json=payload,
34 cookies=cookies,
35 headers={"Content-Type": "application/json"},
36 )
37 if resp.status_code != 200:
38 print(f"BFF 在第 {pg} 頁回傳 {resp.status_code}")
39 break
40 data = resp.json()
41 reviews = data.get("data", {}).get("employerReviews", {}).get("reviews", [])
42 total_pages = data.get("data", {}).get("employerReviews", {}).get("numberOfPages", 1)
43 for r in reviews:
44 all_reviews.append({
45 "title": r.get("summary", ""),
46 "rating": r.get("ratingOverall"),
47 "pros": r.get("pros", ""),
48 "cons": r.get("cons", ""),
49 "author_role": r.get("jobTitle", {}).get("text", ""),
50 "date": r.get("reviewDateTime", ""),
51 "recommend": r.get("isRecommend"),
52 })
53 print(f"評論第 {pg}/{total_pages} 頁:取得 {len(reviews)} 則評論")
54 if pg >= total_pages:
55 break
56 time.sleep(random.uniform(3, 6))
57 return all_reviews這個 BFF endpoint 會直接回傳乾淨的 JSON,包含所有評論欄位——不用 HTML 解析,也不怕 CSS selector 壞掉。你需要的是已登入的 Playwright session cookie(第 6 步會說明),以及先從評論頁 HTML 中擷取 employerId 和 dynamicProfileId。
評論的 HTML 備援 selector
如果 BFF endpoint 改了,或你比較想走 DOM 解析,以下是穩定的 data-test selector:
| 欄位 | Selector |
|---|---|
| 評論容器 | [data-test="review"] |
| 標題 | [data-test="review-title"] |
| 整體評分 | [data-test="overall-rating"] |
| 優點 | [data-test="pros"] |
| 缺點 | [data-test="cons"] |
| 日期 | [data-test="review-date"] |
| 作者職稱 | [data-test="author-jobTitle"] |
第 5 步:抓取 Glassdoor 薪資資料
薪資頁面是完全鎖登入的。你必須先有已登入 session(第 6 步),這段程式才會回傳真實資料。
前往薪資頁
薪資網址格式為:/Salary/{Company}-Salaries-E{id}.htm,分頁格式則是 _P{n}.htm。
1def scrape_salaries(page, salary_url, max_pages=3):
2 all_salaries = []
3 for pg in range(1, max_pages + 1):
4 url = salary_url if pg == 1 else salary_url.replace(".htm", f"_P{pg}.htm")
5 page.goto(url)
6 page.add_style_tag(content="""
7 #HardsellOverlay { display: none !important; }
8 body { overflow: auto !important; position: initial !important; }
9 """)
10 time.sleep(random.uniform(3, 7))
11 html = page.content()
12 sel = Selector(text=html)
13 items = sel.css('[data-test="salary-item"]')
14 if not items:
15 print(f"薪資第 {pg} 頁:沒有資料,可能是登入限制或被封鎖。")
16 break
17 for item in items:
18 salary = {
19 "job_title": item.css('[class*="SalaryItem_jobTitle__"]::text').get("").strip(),
20 "salary_range": item.css('[class*="SalaryItem_salaryRange__"]::text').get("").strip(),
21 "count": item.css('[class*="SalaryItem_salaryCount__"]::text').get("").strip(),
22 }
23 all_salaries.append(salary)
24 print(f"薪資第 {pg} 頁:已抓到 {len(items)} 筆資料")
25 return all_salaries請注意 [class*="SalaryItem_jobTitle__"] 這種前綴比對方式。Glassdoor 薪資頁使用 CSS module 的雜湊 class 名稱(例如 SalaryItem_jobTitle__XWGpT),其中 hash 後綴每次部署都會變。前綴通常穩定,但 hash 不會。千萬不要把完整 class 名稱寫死。
第 6 步:突破 Glassdoor 的登入牆
這是解鎖薪資資料與完整評論文字的關鍵。做法是:先在可見瀏覽器中手動登入一次,把已驗證 session 狀態存起來,之後每次抓取都直接重用。
儲存你的已登入 session
先執行這個腳本一次。它會打開 Chrome 視窗,前往 Glassdoor 登入頁(現在會重新導向到 Indeed Login),並等待你手動登入:
1import asyncio
2from pathlib import Path
3from patchright.async_api import async_playwright
4STATE_FILE = Path("glassdoor_state.json")
5async def login_and_save():
6 async with async_playwright() as p:
7 browser = await p.chromium.launch(headless=False, channel="chrome")
8 context = await browser.new_context(
9 viewport={"width": 1366, "height": 800},
10 locale="en-US",
11 )
12 page = await context.new_page()
13 await page.goto("https://www.glassdoor.com/profile/login_input.htm")
14 print("請在瀏覽器視窗中登入,登入完成後回到終端機按 Enter...")
15 input()
16 await context.storage_state(path=str(STATE_FILE))
17 print(f"已將 session 儲存到 {STATE_FILE}")
18 await browser.close()
19asyncio.run(login_and_save())登入並按下 Enter 後,Patchright 會把 cookies 與 local storage 全部存到 glassdoor_state.json。這個檔案會包含你的 gdId、GSESSIONID、cf_clearance 和驗證 token。
在抓取時重用 session
之後每次抓取都載入這個儲存狀態,就不需要再手動登入:
1async def scrape_with_auth(target_url):
2 async with async_playwright() as p:
3 browser = await p.chromium.launch(headless=True, channel="chrome")
4 context = await browser.new_context(
5 storage_state="glassdoor_state.json"
6 )
7 page = await context.new_page()
8 await page.goto(target_url)
9 await page.add_style_tag(
10 content="#HardsellOverlay{display:none!important}"
11 )
12 await page.wait_for_load_state("networkidle")
13 html = await page.content()
14 await browser.close()
15 return html這個已儲存的 session 通常可維持 20~30 分鐘的活躍使用時間,之後 Glassdoor 可能會再次要求驗證。若你要長時間跑批,建議加一個檢查:如果某頁理應有資料卻抓到 0 筆,就重新執行登入腳本更新 state 檔。
偵測與關閉登入彈窗
針對只是部分頁面被遮住的情況(例如職缺列表有資料,但上面蓋著 modal),前面提過的 CSS 注入方式就很有用:
1page.add_style_tag(content="""
2 #HardsellOverlay, .LoginModal { display: none !important; }
3 body { overflow: auto !important; position: initial !important; }
4""")這只適用於 HTML 本身已經包含資料、只是被覆蓋層遮住的頁面。若是伺服器端直接鎖住的頁面(薪資、深層評論頁),那就只有第 6 步的已驗證 session 這條路。
讓你的 Glassdoor 爬蟲更穩定的技巧
Glassdoor 的前端會頻繁更新。以下做法能讓你的爬蟲更有韌性。
優先使用 data-test 屬性,而不是 class 名稱
Glassdoor 會隨機化 CSS class 名稱,但 data-test 屬性通常比較穩定。永遠優先使用 [data-test="jobListing"],而不是 .jobCard_abc123。如果沒有 data-test(例如薪資欄位 class),就用前綴比對模式:[class*="SalaryItem_jobTitle__"]。
輪換代理並加入隨機延遲
請使用住宅代理輪換服務——資料中心 IP 幾乎會立刻被挑戰。每次頁面載入之間加入 3~8 秒的隨機延遲(長時間批次建議 5~15 秒)。如果可以,盡量避開美國商業時段,因為那時 Cloudflare 的行為偵測通常最嚴格。
監控是否壞掉
建議在爬蟲裡加一個簡單檢查:如果理論上應該有資料的頁面最後卻抓到 0 筆,先把它當成 selector 失效,而不是資料真的為空,並立即發出警示。每週跑一次小型測試爬取,提早發現破損——Glassdoor 會在沒有公告的情況下直接更新前端。
在可行時使用 __NEXT_DATA__ 快速路徑
Glassdoor 是一個 Next.js + Apollo GraphQL 應用。很多頁面會在 <script id="__NEXT_DATA__"> 裡放入完整的 GraphQL cache JSON。解析這段資料比直接抓 DOM 更穩定,而且:
1import json
2def extract_next_data(html):
3 sel = Selector(text=html)
4 raw = sel.css("script#__NEXT_DATA__::text").get()
5 if raw:
6 return json.loads(raw)["props"]["pageProps"].get("apolloCache", {})
7 return None這會回傳結構化的 Apollo cache,裡面包含所有職缺、評論與薪資欄位——完全不需要 CSS selector。因為它就是支撐 Glassdoor React 前端的同一份資料,所以是目前最穩定的擷取方式。
不想寫程式?用 Thunderbit 抓 Glassdoor 也可以
不是每個讀這篇的人都是工程師。HR、招募、銷售營運分析師與市場研究人員同樣需要 Glassdoor 資料——而他們不該為了拿到資料,就得自己管理 Playwright context 和代理輪換。
是一款 AI 網頁爬蟲 Chrome 擴充功能,不需要寫一行程式,就能抓到同樣的職缺、評論與薪資資料。我確實是 Thunderbit 團隊的一員,所以先說清楚這點——但我把它放進來的原因,是它真的解決了 Glassdoor 抓取中最難的兩個問題。
Thunderbit 在 Glassdoor 上怎麼運作
流程只要兩步:
- 在 Chrome 中打開任何 Glassdoor 頁面(職缺搜尋、公司評論、薪資頁)
- 在 Thunderbit 側邊欄點選 AI 建議欄位,AI 會讀取頁面 DOM 並自動建議欄位(職稱、公司、評分、薪資區間、優點、缺點等)
- 點選 開始爬取,資料就會被擷取成表格,不需要 CSS selector 或瀏覽器自動化程式碼
Thunderbit 內建了一個 ,一次執行就能抓出每家公司 23 個以上欄位。若是職缺、評論或薪資頁,通用的 AI 建議欄位流程也能處理任何 Glassdoor URL。
不寫程式也能處理登入牆
這正是 Thunderbit 在 Glassdoor 上的結構性優勢。瀏覽器模式直接在你自己的 Chrome 工作階段中執行——如果你已經在 Chrome 登入 Glassdoor,Thunderbit 會自動沿用那些 cookies。會擋住伺服器端爬蟲的薪資與評論登入牆,在這裡根本不成問題。沒有 cookie 管理、沒有持久化 context、沒有 session 程式碼。
用子頁面爬取補充資料
你可以先從列表頁開始(例如搜尋結果中的 30 家公司),讓 Thunderbit 先列出所有列項,再啟用去拜訪每家公司的評論或薪資頁,補齊完整描述、評論文字或薪資細節。
匯出到商務工具
不同於輸出 CSV 或 JSON 的 Python 腳本,Thunderbit 可以直接匯出到 Google Sheets、Airtable、Notion 或 Excel,而且所有方案都免費提供這項功能。對需要協作分析資料的團隊尤其實用。
Python vs. Thunderbit:什麼情境用哪個?
| 情境 | 建議做法 |
|---|---|
| 建立可重複執行的資料管線 | Python + Patchright |
| 一次性研究或小型團隊專案 | Thunderbit |
| 需要對每個欄位做程式化控制 | Python |
| 今天就要拿到 Glassdoor 資料、且不是工程師 | Thunderbit |
| 一次抓 1,000+ 頁 | Python + 代理 |
| 抓 30 家公司並補充擴充資料 | 兩者都可,但 Thunderbit 設定更快 |
Thunderbit 的價格從免費方案開始(每月 6 頁),可獲得 3,000 credits。以每列 1 credit 計算(子頁面爬取每列 2 credits),大約足以支援每月 33 次、每次 30 家公司補充資料的任務。
抓 Glassdoor 合法嗎?
我簡短講重點。Glassdoor 的明確禁止自動化爬取:「未經我們明確書面許可,你不得使用任何 robot、spider、scraper……來存取本服務。」
不過,法律實務上比單一條款更複雜:
- (加州北區,2024 年 1 月):法院認為,如果你從未登入,就不算同意該服務條款,而公開的未登入爬取不違反條款
- hiQ Labs v. LinkedIn(第九巡迴):CFAA 不適用於對公開可存取資料的自動化蒐集——但假帳號與登入後爬取是另一回事
- Van Buren v. United States(美國最高法院,2021):縮限了 CFAA 中「超越授權存取」的解釋
實務上的重點是:不登入就抓公開職缺,法律風險相對較低。若你是用已登入 session 進行抓取,等於你在註冊時已接受服務條款,而條款又明確禁止這類行為。這對 Python 腳本與 Thunderbit 的瀏覽器模式都同樣適用。
不管怎樣,這些倫理原則還是值得遵守:
- 速率限制要遠低於真人瀏覽速度
- 不要擷取或轉售可識別個人身分的評論者資訊
- 尊重 robots.txt 規範
- 只抓你實際需要的欄位
結論:哪種方法最適合你?
這篇指南已經涵蓋 Glassdoor 的三種資料類型——職缺、評論與薪資——並提供可運作的 2025 程式碼,能應對 Indeed Login 遷移、Cloudflare Bot Management,以及讓舊教學全部失效的 CSS module class 名稱輪換問題。
以下是決策框架:
| 你的情況 | 最佳做法 |
|---|---|
| 開發者,正在建立資料管線 | Python + Patchright(照上面的步驟做) |
| 一次性研究或週期性小量擷取 | Thunderbit(免程式碼、瀏覽器式) |
| 只需要少量基本職缺資訊 | 先看看 Glassdoor API 是否還能用(大概率不行) |
| 明確需要薪資或評論資料 | 必須用 Python 爬取或 Thunderbit——API 從來沒提供這些 |
| 非工程師團隊,需要共享資料 | Thunderbit → 匯出到 Google Sheets |
Glassdoor 的防護只會持續演進。Selector 會失效,新挑戰也會出現。把這篇指南加到書籤吧——如果你想更深入了解網頁爬取工具與技巧,也可以參考我們的文章:、、以及。你也可以到 觀看實作教學。
常見問題
1. 不登入可以抓 Glassdoor 嗎?
可以,針對大多數職缺資料和頂層公司評分是可以的。但若要完整薪資拆解,或超過前幾頁的完整評論內容,就不行了。#HardsellOverlay 只是 CSS 覆蓋層——底層 HTML 仍保有第一頁資料——但更深層的內容則是被 Glassdoor 的「先給才拿」牆擋在伺服器端。
2. 2025 年抓 Glassdoor 最好用的 Python 函式庫是什麼?
Patchright(Playwright 的隱匿分支)是預設推薦。它修補了原生 Playwright 的 Runtime.Enable CDP 洩漏,而這正是 Cloudflare 會明確檢查的項目。對於在初始 HTML 就送出 __NEXT_DATA__ 的列表頁,搭配 impersonate="chrome124" 的 curl_cffi 速度可快 10~20 倍,但它無法處理需要登入的頁面。
3. 要怎麼避免抓 Glassdoor 時被封鎖?
使用 Patchright 或 rebrowser-playwright(不要用原生 Playwright 或 Selenium)。輪換住宅代理——資料中心 IP 幾乎會立刻被挑戰。每頁之間加入 3~8 秒的隨機延遲。保留 cookie(gdId、cf_clearance、GSESSIONID)跨請求使用。也要預期 session 大約 20~30 分鐘就會再次被要求驗證。
4. 有沒有可以取代爬蟲的 Glassdoor API?
實際上沒有。舊版 Partner API ,公開評論 endpoint 從未存在,而 Indeed 的 Publisher API 也沒有遷移方案。對評論與薪資資料來說,爬取或使用像 Thunderbit 這類無程式碼工具才是唯一實際可行的方法。
5. Glassdoor 爬蟲多久會壞一次?
很頻繁。Glassdoor 會在沒有公告的情況下部署前端變動,而且 CSS module class 名稱的 hash 每次發版都會輪換。最穩定的擷取策略是:(1) data-test 屬性 selector、(2) __NEXT_DATA__ JSON 區塊、(3) 內部 BFF 評論 endpoint。建議內建 0 結果檢查,並每週跑一次小型測試爬取,提早發現壞掉的地方。
延伸閱讀