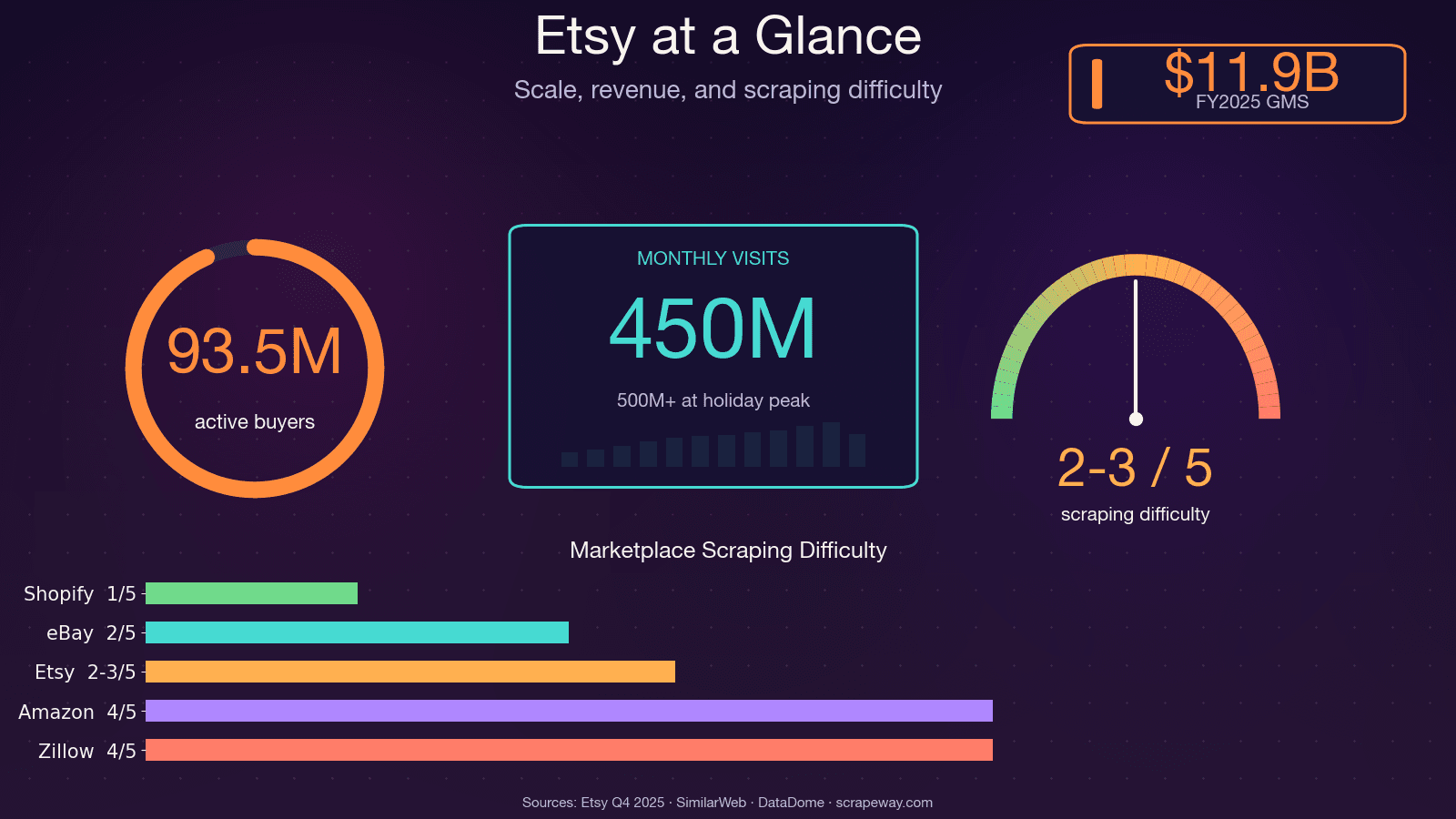
Etsy 目前擁有超過 1 億筆活躍商品、560 萬位賣家,以及每月約 4.5 億次造訪。這代表有大量公開可用的資料,包含定價、趨勢、評論與競爭對手資訊——如果你曾經想靠人工蒐集這些資料,你一定懂那種痛苦。
我曾經有一個週末,為了市場研究專案手動整理競品商品。做到第 30 個商品時,我開始懷疑自己一路走來的每個人生選擇,怎麼最後會落到那張試算表上。Etsy 資料其實非常有價值,無論是價格分析、產品開發、利基市場探索,還是賣家基準比較,都派得上用場——前提是你真的能大規模取得它。這份指南就是為了這件事而寫:一份完整教學,帶你用 Python 抓取 Etsy 的四種主要頁面(搜尋結果、商品頁、商店頁與評論),也會誠實說明 Etsy 的反機器人防護,並提供一個完全不寫程式碼的替代方案,給那些想直接跳過腳本的人。
用 Python 抓取 Etsy 是什麼意思?
網頁爬蟲,簡單來說,就是寫程式去拜訪網頁,並自動擷取你需要的資料——像是商品名稱、價格、描述、圖片、評分、評論、商店資訊——再把它整理成試算表或資料庫這類結構化格式。
Python 是做這類工作的首選語言。它對初學者很友善、社群龐大,而且擁有非常完整的爬蟲生態系:Requests(用來抓取頁面)、BeautifulSoup(用來解析 HTML)、Selenium 和 Playwright(用來自動化瀏覽器),以及 pandas(用來整理與匯出資料)。Python 在 Stack Overflow 的年度開發者調查中一直穩居最熱門語言前 3 名,而它的爬蟲相關套件也常是 PyPI 上下載量最高的一批。
當你抓取 Etsy 時,其實是在從 Etsy 傳給瀏覽器的 HTML(有時還包含隱藏的 JSON)中提取資料。你可以擷取的內容包括:
- 商品名稱、價格、描述、圖片與變體
- 賣家/商店資訊(名稱、銷售數、地點、評分)
- 評分與完整評論文字
- 搜尋結果清單、分類與趨勢訊號
為什麼要抓取 Etsy?能直接帶來 ROI 的真實應用場景
抓取 Etsy 不只是技術練習——它是一種競爭優勢。無論你是賣家、產品經理,還是資料分析師,只要能隨手取得結構化的 Etsy 資料,就能直接影響你的營收表現。
| 使用情境 | 你要抓取的內容 | 受益對象 | 商業影響 |
|---|---|---|---|
| 競爭定價分析 | 搜尋結果 + 商品價格 | 電商營運、賣家 | 動態定價平均可提升 5–22% 營收 |
| 利基與趨勢發掘 | 搜尋結果、熱門商品清單 | 創辦人、分析師 | 提早發現熱門利基(例如「preppy pajamas」搜尋量成長 +1,112%) |
| 產品開發與優化 | 評論、商品細節 | 產品團隊 | 某廚具品牌透過評論情緒資料,在 60 天內奪回 #1 暢銷品地位 |
| SEO 與關鍵字研究 | 搜尋結果、商品標題/標籤 | 行銷團隊 | 找出高需求、低競爭關鍵字 |
| 賣家基準比較 | 商店頁、銷售數 | 業務團隊、分析師 | 以每筆 $0.01–0.10 的成本建立高品質潛在名單,遠低於購買名單 |
| 庫存與存貨監控 | 商品可用性 | 電商營運 | 更快因應競爭對手的庫存變化 |
這些用例都需要來自不同 Etsy 頁面類型的資料——這也正是這份教學會涵蓋四種頁面的原因。
節省時間:人工 vs. 自動化
- 人工研究 Etsy: 每個商品 30–45 分鐘(100 個商品要 50–75 小時)
- 自動化抓取: 100 筆清單只要 2–5 分鐘
- AI 驅動的爬取速度快 ,準確率最高可達 99.5%
Etsy API 與網頁爬蟲:該怎麼選?
在你寫任何一行程式碼之前,值得先問:我該使用 Etsy 官方 API,還是直接抓網站?這是我在論壇上最常看到的問題之一,而答案取決於你需要什麼資料。
Etsy API 能做什麼、不能做什麼
Etsy 提供 API v3,並採用 OAuth 2.0 驗證。它可用來存取你自己商店的資料——商品、訂單、收據。但限制也很明顯:
- 競爭對手資料: API 大多只限於你自己的商店。你無法取得其他賣家的定價、銷售或商品清單。
- 評論: 沒有能批次取得完整評論文字的強健端點。
- 速率限制: 預設每秒 10 次請求、每天 10,000 次請求。offset 上限為 12,000 筆紀錄。
- AI/ML 使用: 在應用審核中明確被拒絕。
- 文件: 社群抱怨很多——範例不足、端點已棄用、支援回應慢。
什麼時候網頁爬蟲更適合
如果你需要競品情報、評論情緒、跨商店分析,或是 API 沒有提供的資料,爬蟲就是更好的選擇。代價是你得面對 Etsy 的反機器人防護(下面會詳細說明),而且也需要投入一些設定成本。
比較表:API vs. 爬蟲 vs. 無程式碼
| 比較項目 | Etsy 官方 API | Python 網頁爬蟲 | Thunderbit(無程式碼) |
|---|---|---|---|
| 商品價格存取 | ✅(欄位有限) | ✅ 完整 HTML/JSON-LD | ✅ AI 可擷取任何可見欄位 |
| 評論資料 | ❌ 無法批次取得 | ✅ 透過評論端點/HTML | ✅ 子頁面抓取 |
| 競爭對手商店資料 | ❌ 只能自己的商店 | ✅ 任何公開商店 | ✅ 任何公開商店 |
| 需要驗證 | ✅ OAuth 2.0 | ⚠️ 登入資料需 Cookie | ⚠️ 登入需瀏覽器爬取 |
| 反機器人風險 | 無 | 高(DataDome) | 已處理(瀏覽器原生) |
| 設定時間 | 中(API 金鑰、OAuth) | 高(程式碼 + 代理) | 約 2 分鐘 |
如果你需要競品資料、評論或跨商店分析,API 真的不夠用。這就是最誠實的答案。
在寫程式前,先選好你的 Python 爬取方式
我在 Reddit 和 Stack Overflow 上最常看到的一個問題是:「我該用 Requests + BeautifulSoup、Selenium、代理 API,還是其他東西?」正確答案取決於你的技術能力、預算和使用情境。
| 方法 | 最適合 | 學習曲線 | 能處理 JS 嗎? | 反機器人處理 | 成本 |
|---|---|---|---|---|---|
| Requests + BeautifulSoup | 想要完全控制的開發者 | 中 | ❌ | 手動處理(headers、proxies) | 免費 + 代理成本 |
| Selenium / Playwright | JS 很重的頁面、登入流程 | 高 | ✅ | 部分(瀏覽器指紋) | 免費 + 代理成本 |
| 代理 API 服務 | 大規模 + 繞過反機器人 | 中 | ✅(透過 API) | ✅ 內建 | 每月 $49 起 |
| Thunderbit(無程式碼) | 非工程師、快速擷取 | 很低 | ✅(瀏覽器原生) | ✅(瀏覽器工作階段) | 有免費方案 |
如果你想完全掌控流程,而且對 Python 很熟,就選 Requests + BeautifulSoup。如果你需要 JS 渲染或登入流程,就用 Selenium。如果你想大規模繞過反機器人,考慮代理服務。如果你想拿到 Etsy 資料,但不想寫或維護程式碼,Thunderbit 很值得一看——後面會再談。
Etsy 怎麼反擊:理解 DataDome 反機器人防護
大多數爬蟲教學都會叫你「直接用代理」然後跳過。但對 Etsy 來說,這還不夠。Etsy 使用 DataDome,這是網路上最積極的反機器人系統之一。 也把 Etsy 當成成功案例,並提到爬蟲曾占 Etsy 運算成本約 1%。
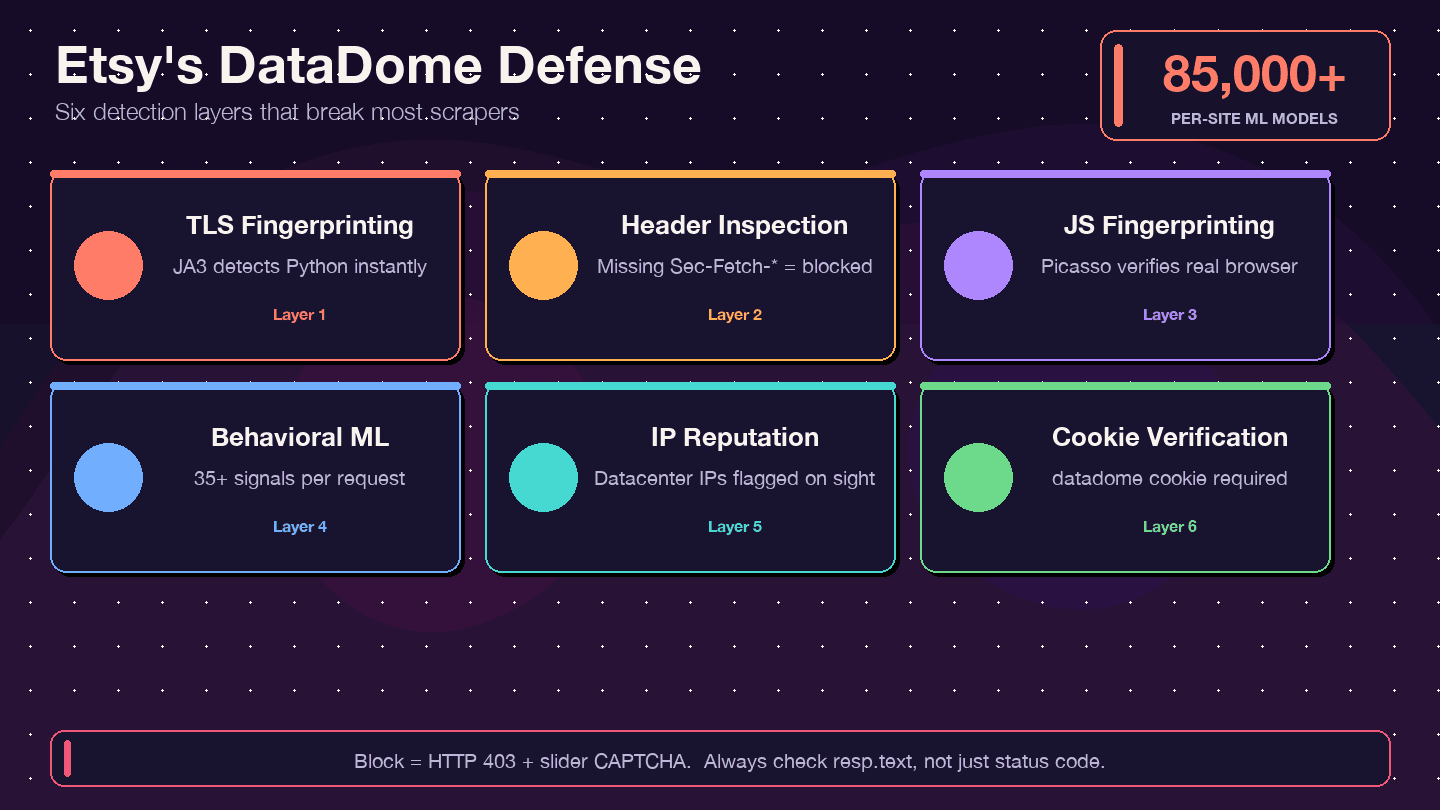
DataDome 是什麼?它怎麼運作?
DataDome 不只是檢查你的 IP 位址,它會跑一套多層次偵測機制:
- TLS 指紋辨識(JA3): Python 的
requests套件有非常獨特的 TLS 特徵,DataDome 可以立刻辨識出來。 - HTTP 標頭/協定檢查: 會檢查瀏覽器標頭是否完整且一致——缺少或順序錯誤的標頭都是警訊。
- JavaScript 指紋辨識(Picasso protocol): 會在瀏覽器內執行 JS 挑戰,確認你是真人。
- 行為式機器學習: 每次請求會分析 35+ 種信號,每個站點還有 85,000+ 個模型。
- IP 信譽評分: 資料中心 IP 會立即被標記。
- Cookie 驗證:
datadomecookie 必須存在且有效。
你被封鎖的跡象,以及如何確認
最常見的陷阱之一:你收到 200 OK 回應,但 HTML 其實是 CAPTCHA 頁面,不是你要的資料。其他跡象包括:
- 403 Forbidden 錯誤
- 重新導向迴圈
- 回應內容包含
ddJavaScript 物件或滑塊 CAPTCHA HTML
一定要檢查回應內容本身,而不是只看狀態碼。簡單檢查如下:
1if "captcha" in resp.text.lower() or "datadome" in resp.text.lower():
2 print("被封鎖了!收到的是 CAPTCHA 頁面,不是資料。")能降低偵測風險的標頭與 Cookie
你無法保證不被封鎖,但真實的標頭與 Cookie 管理可以大幅降低風險:
1session = requests.Session()
2session.headers.update({
3 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/133.0.0.0 Safari/537.36",
4 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8",
5 "Accept-Language": "en-US,en;q=0.9",
6 "Accept-Encoding": "gzip, deflate, br",
7 "Sec-Ch-Ua": '"Chromium";v="133", "Not-A.Brand";v="99", "Google Chrome";v="133"',
8 "Sec-Ch-Ua-Mobile": "?0",
9 "Sec-Ch-Ua-Platform": '"Windows"',
10 "Sec-Fetch-Dest": "document",
11 "Sec-Fetch-Mode": "navigate",
12 "Sec-Fetch-Site": "none",
13 "Upgrade-Insecure-Requests": "1",
14})另外也很重要:
- 使用
requests.Session()在多次請求之間保留 cookies。 - 在請求之間 加入隨機延遲(2–7 秒)。
- 模擬 referrer 鏈: 先拜訪首頁,再到搜尋頁,最後到商品頁。
- 若要大規模操作,住宅代理輪換 是必要的。資料中心 IP 幾乎會立刻被標記。
這些技巧只能降低偵測機率,無法完全消除。若是高流量爬取,你很可能還是需要代理服務或以瀏覽器為基礎的方案。
設定 Python 環境來抓取 Etsy
開始前:
- 難度: 中級
- 所需時間: 約 30–60 分鐘(設定 + 第一次抓取)
- 你需要的東西: Python 3.8+、pip、程式編輯器、Chrome 瀏覽器(用於 DevTools 檢查)
安裝依賴套件
建立專案資料夾、設定虛擬環境,然後安裝需要的函式庫:
1mkdir etsy-scraper && cd etsy-scraper
2python -m venv venv
3source venv/bin/activate # Windows:venv\activate
4pip install requests beautifulsoup4 lxml pandas- requests — 抓取網頁
- beautifulsoup4 — 解析 HTML
- lxml — 更快的 HTML 解析器(可選,但建議)
- pandas — 將資料結構化並匯出為 CSV/Excel
如果之後你需要瀏覽器自動化(例如登入或處理 JS 很重的頁面),也可以再安裝:
1pip install selenium在寫程式前,先了解 Etsy 的頁面結構
有個技巧可以省下大量時間:Etsy 在大多數頁面都會把結構化商品資料嵌在 <script type="application/ld+json"> 標籤中。這些 JSON-LD 資料已經整理好——商品名稱、價格、評分、圖片——所以你不需要為每個欄位都去跟脆弱的 CSS selector 纏鬥。
打開任一 Etsy 商品頁,按右鍵選「檢視原始碼」,然後搜尋 application/ld+json。你會找到一個包含 @type: Product 的區塊,裡面大多就是你需要的資料。搜尋結果頁則會有 @type: ItemList。
CSS selector 還是可以當備用方案(例如 JSON-LD 沒有的運費資訊或評論文字),但 JSON-LD 應該是你的第一站。
第 1 步:用 Python 抓取 Etsy 搜尋結果
搜尋結果是大多數 Etsy 爬蟲專案的起點——不管你是在監控某個利基市場、追蹤競品定價,還是建立商品資料庫。
建立搜尋 URL
Etsy 的搜尋 URL 格式如下:
1https://www.etsy.com/search?q=\{keyword\}&ref=pagination&page=\{page_number\}如果是多字詞查詢,請把空格做 URL 編碼(例如 handmade+jewelry 或 handmade%20jewelry)。ref=pagination 參數會讓請求看起來更像是真實的瀏覽器導覽。
其他常用參數包括:order(most_relevant、price_asc、price_desc、date_desc)、min_price、max_price、ship_to、free_shipping=true。每頁會回傳 48 筆項目。
發送請求並解析 HTML
1import requests
2from bs4 import BeautifulSoup
3import json
4import time
5import random
6headers = {
7 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
8 "Accept-Language": "en-US,en;q=0.9",
9 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
10}
11def scrape_etsy_search(query, max_pages=3):
12 all_products = []
13 for page in range(1, max_pages + 1):
14 url = f"https://www.etsy.com/search?q=\{query\}&ref=pagination&page=\{page\}"
15 resp = requests.get(url, headers=headers, timeout=30)
16 if "captcha" in resp.text.lower():
17 print(f"第 \{page\} 頁被封鎖了。請試著加入延遲或代理。")
18 break
19 soup = BeautifulSoup(resp.text, "lxml")
20 for script in soup.find_all("script", type="application/ld+json"):
21 data = json.loads(script.string)
22 if data.get("@type") == "ItemList":
23 for item in data.get("itemListElement", []):
24 all_products.append({
25 "name": item.get("name"),
26 "url": item.get("url"),
27 "image": item.get("image"),
28 "price": item.get("offers", {}).get("price"),
29 "currency": item.get("offers", {}).get("priceCurrency"),
30 "position": item.get("position"),
31 })
32 time.sleep(random.uniform(2, 5))
33 return all_products從 JSON-LD 擷取清單資料
itemListElement 陣列會提供每個商品的名稱、URL、圖片、價格與幣別。如果你還需要星等評分或結果數量(這些不一定在 JSON-LD 中),就改用 CSS selector:
- 商品卡片:
.v2-listing-card - 標題:
h3.v2-listing-card__title - 價格:
span.currency-value - 連結:
a.listing-link(href)
處理分頁
用迴圈跑每一頁,並在每次請求之間加入隨機延遲。Etsy 通常會根據查詢回傳最多 20–250 頁。
1results = scrape_etsy_search("handmade+jewelry", max_pages=5)
2print(f"已抓取 {len(results)} 個商品。")在我的測試中,抓 5 頁大約只花了 20 秒——相較於手動複製貼上 30 分鐘以上,差很多。
第 2 步:用 Python 抓取 Etsy 商品頁
一旦你從搜尋結果拿到商品 URL,下一步就是從每個商品頁抓取更詳細的資料。
取得商品頁
1def scrape_etsy_product(url):
2 resp = requests.get(url, headers=headers, timeout=30)
3 soup = BeautifulSoup(resp.text, "lxml")
4 for script in soup.find_all("script", type="application/ld+json"):
5 data = json.loads(script.string)
6 if data.get("@type") == "Product":
7 offers = data.get("offers", {})
8 price = offers.get("price") or offers.get("lowPrice")
9 rating_data = data.get("aggregateRating", {})
10 return {
11 "name": data.get("name"),
12 "description": data.get("description", "")[:500],
13 "brand": data.get("brand", {}).get("name") if isinstance(data.get("brand"), dict) else data.get("brand"),
14 "category": data.get("category"),
15 "price": price,
16 "currency": offers.get("priceCurrency"),
17 "availability": offers.get("availability"),
18 "rating": rating_data.get("ratingValue"),
19 "review_count": rating_data.get("reviewCount"),
20 "images": data.get("image", []),
21 "sku": data.get("sku"),
22 "material": data.get("material"),
23 }
24 return None處理價格變體
有些商品只有單一的 offers.price。其他商品(例如有尺寸或顏色變體)則會使用 offers.lowPrice 和 offers.highPrice。上面的程式會先抓 price,若沒有就退回讀取 lowPrice,因此兩種情況都能處理。
透過 CSS selector 擷取其他欄位
對於 JSON-LD 沒有的資料——像運送資訊、變體選項、完整賣家細節——你就需要 CSS selector:
- 標題:
h1[data-buy-box-listing-title] - 變體:
select[data-selector-id]或div[data-option-set] - 運送:運送區塊附近的
div.wt-text-caption
取捨是這樣:JSON-LD 更乾淨,也比較不容易因版面變動而壞掉。CSS selector 雖然脆弱,但能覆蓋更多欄位。
第 3 步:用 Python 抓取 Etsy 商店頁
這一段通常是很多競品指南直接略過的部分——但對業務團隊和競爭分析師來說,它可能是最有價值的。
建立商店 URL 並抓取頁面
1def scrape_etsy_shop(shop_name):
2 url = f"https://www.etsy.com/shop/\{shop_name\}"
3 resp = requests.get(url, headers=headers, timeout=30)
4 soup = BeautifulSoup(resp.text, "lxml")
5 # 從 HTML 擷取商店中繼資料(不在 JSON-LD 中)
6 sales_el = soup.select_one("div.shop-sales-reviews a")
7 rating_el = soup.find("input", {"name": "initial-rating"})
8 location_el = soup.select_one("div.shop-location")
9 shop_data = {
10 "name": shop_name,
11 "sales": sales_el.text.strip() if sales_el else None,
12 "rating": rating_el["value"] if rating_el else None,
13 "location": location_el.text.strip() if location_el else None,
14 }
15 # 從 JSON-LD 擷取商品清單
16 listings = []
17 for script in soup.find_all("script", type="application/ld+json"):
18 data = json.loads(script.string)
19 if data.get("@type") == "ItemList":
20 for item in data.get("itemListElement", []):
21 listings.append({
22 "name": item.get("name"),
23 "url": item.get("url"),
24 "price": item.get("offers", {}).get("price"),
25 })
26 shop_data["listings"] = listings
27 return shop_data你可以從商店頁擷取什麼
商店頁上的 JSON-LD 是 @type: ItemList——它涵蓋商品清單,但不包含銷售數、地點或評分這類商店層級中繼資料。這些欄位你需要 CSS selector:
| 資料點 | 選擇器 | 備註 |
|---|---|---|
| 商店名稱 | h1 或 meta title | 通常在頁面標題中 |
| 總銷售數 | div.shop-sales-reviews a | 文字如「12,345 sales」 |
| 星等評分 | input[name="initial-rating"] 的 value | 數值 1–5 |
| 地點 | div.shop-location | 城市、國家 |
| 加入時間 | div.shop-info | 日期文字 |
商店資料對於建立潛在名單、競品基準比較,或找出某個利基市場中的暢銷賣家特別有價值。
第 4 步:用 Python 抓取 Etsy 評論
評論是 Etsy 上最有價值、也最棘手的資料點之一。完整的評論文字、評分與日期不會直接出現在初始頁面 HTML 裡;它們是透過內部 API 端點載入的。
方法 1:找出 Etsy 內部評論 API 端點
在 Chrome 中打開商品頁,開啟 DevTools(F12),切到 Network 分頁,然後往下滑到評論區。你會看到一個 POST 請求,類似這樣:
1https://www.etsy.com/api/v3/ajax/bespoke/member/neu/specs/deep_dive_reviews這個端點會回傳包含評論卡片的 HTML 片段。要使用它,你需要:
- listing_id — 從商品 URL 取得的數字 ID
- shop_id — 從商品頁 HTML 用正則抓出來
- csrf_nonce — 從頁面上的
<meta>標籤抓出來
擷取 ID 與 CSRF Token
1import re
2def get_review_params(product_url):
3 resp = requests.get(product_url, headers=headers)
4 html = resp.text
5 listing_id = product_url.split("/")[-1].split("?")[0]
6 shop_id_match = re.search(r'"shopId"\s*:\s*(\d+)', html)
7 shop_id = shop_id_match.group(1) if shop_id_match else None
8 soup = BeautifulSoup(html, "lxml")
9 csrf_meta = soup.find("meta", {"name": "csrf_nonce"})
10 csrf = csrf_meta["content"] if csrf_meta else None
11 return listing_id, shop_id, csrf用分頁抓取評論
1def scrape_reviews(listing_id, shop_id, csrf, max_pages=5):
2 session = requests.Session()
3 session.headers.update(headers)
4 all_reviews = []
5 for page in range(1, max_pages + 1):
6 payload = {
7 "specs": {
8 "deep_dive_reviews": {
9 "module_path": "neu/specs/deep_dive_reviews",
10 "listing_id": listing_id,
11 "shop_id": shop_id,
12 "page": page,
13 }
14 }
15 }
16 resp = session.post(
17 "https://www.etsy.com/api/v3/ajax/bespoke/member/neu/specs/deep_dive_reviews",
18 json=payload,
19 headers={"x-csrf-token": csrf, "Content-Type": "application/json"},
20 )
21 data = resp.json()
22 html_fragment = data.get("output", {}).get("deep_dive_reviews", "")
23 review_soup = BeautifulSoup(html_fragment, "lxml")
24 for card in review_soup.select("div.review-card"):
25 rating_el = card.find("input", {"name": "rating"})
26 text_el = card.select_one("div.wt-text-body")
27 user_el = card.select_one("a[data-review-username]")
28 date_el = card.select_one("p.wt-text-body-small")
29 all_reviews.append({
30 "rating": rating_el["value"] if rating_el else None,
31 "text": text_el.text.strip() if text_el else None,
32 "reviewer": user_el.text.strip() if user_el else None,
33 "date": date_el.text.strip() if date_el else None,
34 })
35 time.sleep(random.uniform(2, 5))
36 return all_reviews方法 2:直接從 HTML 解析評論(備用)
如果 API 方法失敗了(例如 CSRF token 有問題),你可以直接從商品頁 HTML 解析第一頁評論。限制是:靜態 HTML 裡通常只會有第一批評論。若要更多,就得使用 API 或像 Selenium 這類瀏覽器自動化工具。
處理需要登入的資料:抓取你自己的 Etsy 商店
這是其他教學幾乎不會提到的缺口,但它確實是很多賣家的需求——特別是想擷取自己訂單、營收與統計資料的 Etsy 賣家。
問題在於:光靠 requests 無法存取你的 Etsy 儀表板,因為它不會帶著你的登入工作階段 cookie。
選項 1:用 Selenium 手動登入並擷取 Cookie
用 Selenium 開啟瀏覽器,手動登入(或自動化登入),然後在驗證後繼續抓取:
1from selenium import webdriver
2driver = webdriver.Chrome()
3driver.get("https://www.etsy.com/signin")
4# 在瀏覽器視窗中手動登入,然後:
5input("登入完成後按 Enter...")
6cookies = driver.get_cookies()
7# 接著使用 driver.get() 前往儀表板頁面並進行抓取你也可以把 Selenium 工作階段中的 cookies 存起來,之後再和 requests.Session() 一起使用,這樣在完成第一次登入後,抓取速度會更快、負擔也更輕。
選項 2:匯出瀏覽器 Cookie 再交給 Requests 使用
用瀏覽器擴充功能(例如「EditThisCookie」)匯出你目前的 Etsy 工作階段 cookies,然後載入到 Requests session:
1import requests
2session = requests.Session()
3# 加入從瀏覽器匯出的 cookies
4session.cookies.set("uaid", "YOUR_UAID_VALUE", domain=".etsy.com")
5session.cookies.set("user_prefs", "YOUR_USER_PREFS_VALUE", domain=".etsy.com")
6# ... 視需要加入其他 session cookies
7resp = session.get("https://www.etsy.com/your/orders", headers=headers)最簡單的路:Thunderbit 的瀏覽器爬取模式
因為 是直接在你的 Chrome 瀏覽器中執行,所以它會自動沿用你目前登入 Etsy 的工作階段。你不需要寫驗證程式碼,也不需要匯出 cookie——只要打開你的 Etsy 儀表板就能開始抓。這對於擷取訂單、營收、統計資料以及其他只有賣家才能看到的資料,真的非常實用。
匯出並使用你抓到的 Etsy 資料
儲存成 CSV 或 JSON
1import pandas as pd
2df = pd.DataFrame(results)
3df.to_csv("etsy_products.csv", index=False, encoding="utf-8")
4df.to_json("etsy_products.json", orient="records", indent=2)最佳做法:在檔名中加入時間戳、使用 UTF-8 編碼,並處理商品名稱中的特殊字元(Etsy 賣家很愛用表情符號和帶重音的字元)。
匯出到 Google Sheets、Airtable 或 Notion
對 Python 使用者來說,像 gspread(Google Sheets)或 Airtable API 這類函式庫,可以讓你用程式把資料送出去。但如果你用的是 ,匯出到 Google Sheets、Excel、Airtable 和 Notion 全部都免費,而且一鍵完成。不需要 API 金鑰,也不用設 OAuth。
跳過程式碼:如何用 Thunderbit 抓取 Etsy(無程式碼替代方案)
不是每個人都想寫 Python 腳本、維護代理設定,或在凌晨兩點除錯 CSS selector。如果你正好是這種人,這裡就是你用 取得 Etsy 資料的方法。
安裝 Thunderbit Chrome 擴充功能
前往 安裝 Thunderbit。建立免費帳號——免費方案每月提供 ,而且所有匯出都免費。
在任何 Etsy 頁面上使用 AI 建議欄位
前往 Etsy 的搜尋頁、商品頁或商店頁,然後在 Thunderbit 側邊欄點選 「AI 建議欄位」。AI 會掃描頁面並推薦欄位——商品名稱、價格、評分、圖片、商店名稱、標籤、運送資訊。你可以依需要調整或新增欄位。
點擊抓取並匯出
按下 「抓取」 就能擷取目前頁面的資料。若是多頁結果,可以使用 Thunderbit 的分頁抓取。若你想把一串商品 URL 補齊每個商品頁的詳細資料(描述、評論、運送資訊),就用 子頁面抓取——Thunderbit 會自動逐一拜訪連結並抓取額外資料。
匯出到 Excel、Google Sheets、Airtable 或 Notion——全部免費。
什麼時候 Thunderbit 比 Python 更適合抓 Etsy
- 不需要代理設定或反機器人程式碼。 Thunderbit 在你真正的 Chrome 瀏覽器裡執行,所以會沿用你的工作階段,在 DataDome 看來就像一般使用者。
- AI 會自動適應版面變化。 Etsy 前端更新時,不用擔心 selector 壞掉。
- 非常適合一次性研究、競品分析,或非技術團隊成員使用。 如果你只需要快速拿到一份資料集,就不必先架 Python 環境。
- 子頁面抓取 可以在不用寫巢狀迴圈的情況下,為商品 URL 名單補上詳細資料。
想看實際操作,可以到 。
Python vs. Thunderbit:6 個月成本比較
| 因素 | Python 自建 | Thunderbit |
|---|---|---|
| 設定時間 | 8–20 小時 | 5 分鐘內 |
| 6 個月成本(含人力、代理) | $2,720–9,450 | $90–228 |
| 每月維護 | 4–10+ 小時(selector 更新 = 80%+ 額外負擔) | 0–1 小時 |
| 反機器人處理 | 住宅代理,信用成本為正常的 85 倍 | 瀏覽器式,原生繞過 DataDome |
| 資料品質 | 高(但要投入大量心力) | 高(AI 驅動) |
我不是說 Python 是錯的選擇——如果你需要完全控制、自訂邏輯,或要整合到更大的資料管線裡,程式碼依然是王道。但對多數只想拿 Etsy 資料的商業使用者來說,ROI 算下來通常會偏向無程式碼工具。
抓取 Etsy 的法律與倫理提醒
每一篇爬蟲文章都有人問我合法性,所以這裡給你簡短版:
- Etsy 的使用條款明確禁止自動化存取。 不過 Etsy 比較依賴技術性防護(DataDome),而不是走訴訟路線——目前沒有已知專門針對爬蟲的 Etsy 訴訟案例。
- 只抓公開可得的資料。 不要繞過驗證,也不要去存取你不擁有的私人賣家儀表板。
- 請使用合理的請求頻率。 每次請求間隔 2–7 秒,不要狂轟 Etsy 伺服器。
- 遵守
robots.txt。 Etsy 允許搜尋頁,但限制部分路徑。 - 依照 GDPR 等隱私法規,妥善處理個資。
- 若是商業規模的爬取計畫,請諮詢法律顧問。
想了解更多背景,可以參考我們關於 的文章——其中也包含 Meta v. Bright Data(2024),該案確認了公開資料抓取的合法性。
收尾:重點整理
這篇文章涵蓋了很多內容。最後我希望你帶走的是這幾點:
- Etsy 的 JSON-LD 結構化資料,讓多數欄位的擷取比直接解析原始 HTML 更乾淨。
- DataDome 是真實的障礙——如果你要用 Python 大規模抓取,請搭配正確的標頭、延遲、Cookie 管理與住宅代理。
- Etsy API 有明顯限制。 如果你需要評論、競爭對手商店,或跨賣家分析,爬蟲才是實際可行的路。
- Thunderbit 提供無程式碼替代方案,可原生處理反機器人與驗證——如果你不想維護腳本,真的值得一試。
- 永遠要負責任地抓取,並尊重 Etsy 的條款。
如果你想不寫程式就開始,請。或者直接用這份教學中的 Python 程式碼,打造你自己的客製化爬蟲——願你的 selector 永遠不要在星期五下午壞掉。
更多爬蟲教學,請參考我們的 與 精選整理。
常見問題
1. 用 Python 抓取 Etsy 合法嗎?
抓取公開可得的資料,通常在近期法律判例下是允許的(例如 Meta v. Bright Data、hiQ v. LinkedIn)。不過 Etsy 的使用條款禁止自動化存取,所以在抓取前一定要先查看他們的 ToS 和 robots.txt。若是大規模或商業用途,請諮詢法律顧問。
2. 我可以在不被封鎖的情況下抓取 Etsy 嗎?
Etsy 使用 DataDome,這是目前最難纏的反機器人系統之一。真實的標頭、請求延遲、Cookie 持久化與住宅代理輪換,都能幫助降低封鎖風險。Thunderbit 的瀏覽器原生方式因為是在你真的 Chrome 工作階段中運作,所以能避開大多數偵測。
3. Etsy 有沒有可以取代爬蟲的 API?
有,Etsy 提供 API v3,但它大多只限於你自己的商店資料,而且沒有強大的評論存取能力。大多數競品情報與跨商店分析的用例,仍然需要爬蟲。
4. 我需要哪些 Python 套件才能抓 Etsy?
至少需要:requests、beautifulsoup4、pandas(用來匯出)以及 json(內建)。如果是 JS 很重或需要登入的頁面,再加上 selenium。如果想要更快的 HTML 解析,請用 lxml。
5. 我要怎麼專門抓 Etsy 評論?
Etsy 評論是透過內部 API 端點(/api/v3/ajax/bespoke/member/neu/specs/deep_dive_reviews)載入的。你需要先從商品頁擷取 listing ID、shop ID 和 CSRF token,然後帶分頁資訊對該端點發送 POST。若失敗,也可以直接從商品頁 HTML 解析第一批評論——這兩種方法在本教學中都有逐步說明。
延伸閱讀