執行摘要
提出的是一個政策問題:全球最常被造訪的網站中,有多少正在告訴 AI 爬蟲哪些事能做、哪些事不能做?
這份延伸報告追問的是背後的營運問題:robots.txt 作為如今被要求承載這些政策的基礎設施,到底有多可靠?
答案其實不太樂觀。robots.txt 之所以還能運作,是因為它公開、成本低、機器可讀,爬蟲也早就認得它。但今天它被要求承擔的內容,早已遠遠超出當初的設計。到了 2026 年,這個純文字檔裡可能同時出現 SEO 爬取控制、網站地圖索引、舊式搜尋引擎擴充、AI 訓練排除、Cloudflare 注入的政策詞彙、版權保留聲明,以及針對未來爭議的法律措辭。
這就是組態債。
本報告背後的資料集,和原始 AI 爬蟲研究相同,都是 Tranco Top 10,000 網站的爬取結果。在 10,000 個網域中,有 6,638 個回傳可讀的 robots.txt;另外 610 個回傳 404,依協定視為隱含允許。這讓我們得以針對機器人存取決策分析 7,248 個網站,並針對組態複雜度分析 6,638 份實際檔案。
有六個發現特別突出:
-
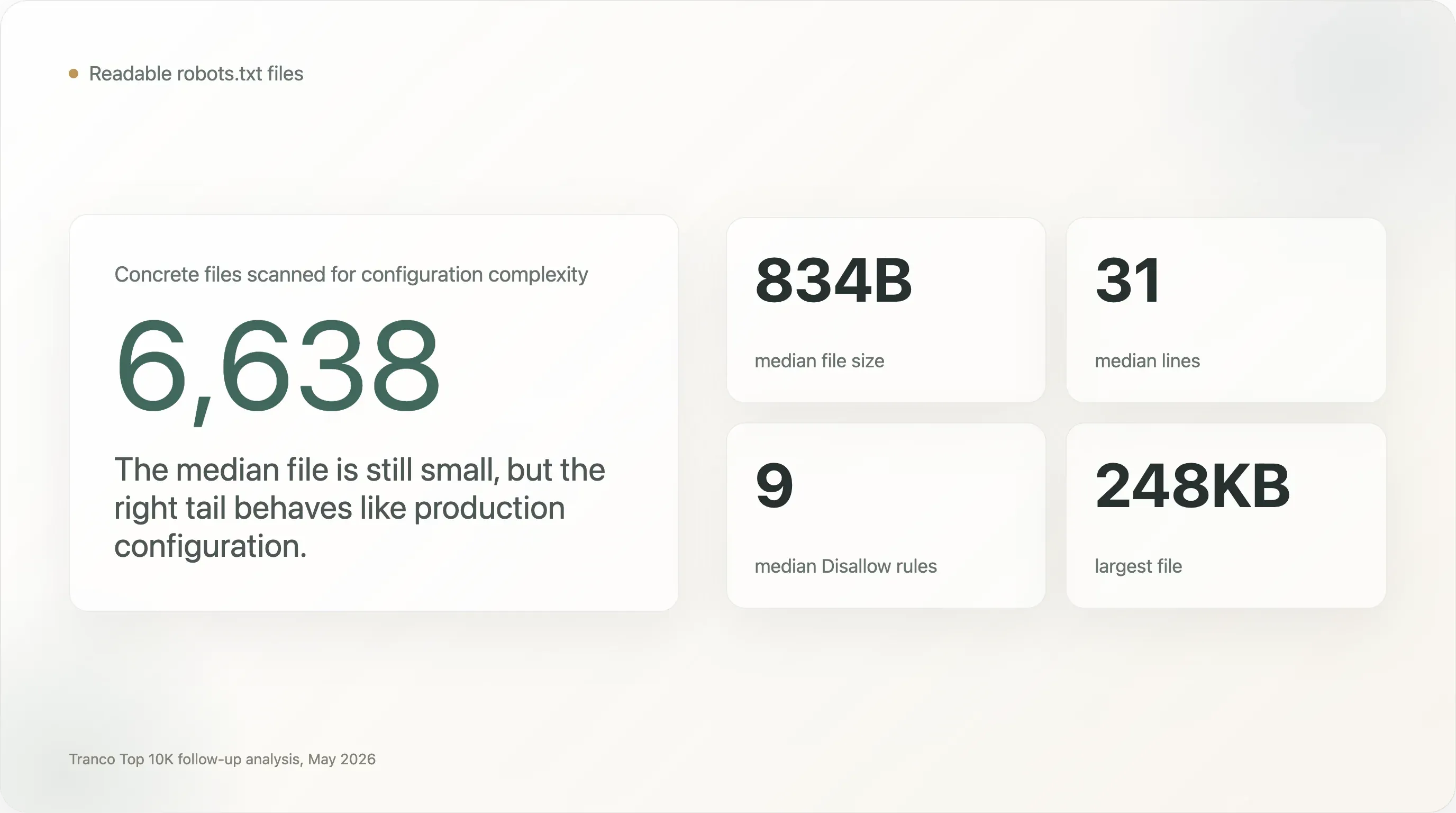
大多數
robots.txt檔案都很小,但尾端極度複雜。 中位數檔案只有 834 位元組與 31 行。不過,有 1,005 份檔案至少 5 KB,273 份至少 20 KB,28 份至少 100 KB。樣本中最大的檔案達 248 KB。 -
數百個頂級網站運行的檔案,更像正式營運組態,而不是政策備忘。 中位數檔案只有 9 條
Disallow指令,但有 707 個網站至少有 100 條Disallow規則,13 個網站至少有 1,000 條,240 個網站列出至少 50 個 user agent,110 個網站列出至少 100 個 user agent。 -
協定漂移不是理論問題。 在 6,638 份可讀檔案中,有 685 份包含
Crawl-delay,303 份包含Host,200 份包含Clean-param,9 份包含Request-rate,5 份包含Visit-time,另有 271 份包含 Cloudflare 風格的Content-Signal語言。這些並不完全屬於同一套乾淨標準,而是長期累積下來的爬蟲民俗。 -
Googlebot 被視為特殊公民。 562 個可分析網域至少封鎖了一個傳統搜尋爬蟲。在其中 404 個案例裡,Googlebot 被允許,但至少有一個其他搜尋爬蟲被封鎖。AI 爬蟲歧視並不是在一個中立生態中出現;
robots.txt早就寫進了搜尋引擎層級的差異。 -
AI 政策讓這筆組態債更明顯。 1,377 份可讀檔案包含 AI 政策語言;719 份包含版權、服務條款、授權或權限語言;501 份同時包含兩者。這份檔案已經同時是機器介面與法律文件。它有用,但也很脆弱。
-
最棘手的檔案不一定是最反 AI 的檔案。 電商、旅遊、社群、金融、學術與新聞網站,會因為不同原因產生複雜檔案:爬取預算控制、舊路徑、使用者產生內容、權利保留,以及針對機器人的例外規則。AI 規則只是疊加在一個本來就很混亂的基礎上。
主要結論是:robots.txt 仍然是公開網路上最重要的爬蟲政策介面,但如果沒有在爬蟲身分、AI 使用詞彙與政策可稽核性上完成生態標準化,它對高風險 AI 治理來說就是脆弱的基礎。
方法論
本報告沿用 Thunderbit 原始 AI 爬蟲政策分析對 Tranco Top 10,000 網域的資料集。
輸入資料如下:
tranco_top10k.csv— 原始 Tranco Top 10K 網域清單。out/fetch_meta.csv— 擷取狀態、位元組數、協定、重新導向結果與錯誤中繼資料。out/sites.csv— 網域、排名、類別、語言與robots.txt狀態。out/site_meta.csv— 每個網站一筆分析列,包含樣板類別、AI 封鎖旗標、檔案大小與機器人政策摘要欄位。out/bot_status.csv— 每個網域與爬蟲一筆資料,包含該機器人是否被封鎖,以及是否存在特定規則。raw_robots/— 6,638 個回傳狀態200的網站所快取的robots.txt內容。
在這份延伸研究中,我們針對每份可讀的 robots.txt 檔案掃描了:
- 檔案大小與行數;
- 實際啟用、非註解行數;
User-agent、Disallow、Allow與Sitemap指令數量;- 舊式或非核心指令,例如
Crawl-delay、Host、Clean-param、Request-rate與Visit-time; - AI 時代詞彙,包括
Content-Signal、llms.txt、AI、LLM、機器學習、TDM 與2019/790; - 法律詞彙,例如版權、服務條款、授權、允許與權利保留措辭;
- 針對 Googlebot、Bingbot、DuckDuckBot、Slurp、Baiduspider 與 YandexBot 的搜尋爬蟲處理方式。
本報告也定義了一個簡單的組態債分數作為初步篩選工具。它結合了檔案大小、user agent 數量、Disallow 數量、Allow 數量、非標準指令數量,以及 AI 政策與法律語言的混合程度。這個分數不是要衡量絕對正確性,而是用來找出那些可能難以維護、審查或推理的檔案。
所有衍生表格與圖表都包含在交付資料夾中。
發現一:中位數檔案很簡單;尾端並不簡單
一般來說,公開網路上的典型 robots.txt 檔案還是很小。
在 6,638 份可讀檔案中:
| 指標 | 中位數 | P90 | P95 | P99 | 最大值 |
|---|---|---|---|---|---|
| 檔案大小 | 834 位元組 | 6.7 KB | 15.8 KB | 76.0 KB | 248.3 KB |
| 行數 | 31 | 238 | 332 | 1,008 | 4,998 |
| 實際啟用行數 | 23 | 198 | 282 | 837 | 4,998 |
User-agent 指令 | 1 | 21 | 39 | 137 | 823 |
Disallow 指令 | 9 | 103 | 176 | 422 | 4,997 |
Allow 指令 | 1 | 17 | 33 | 69 | 890 |
這個分布很重要,因為 robots.txt 常被想像成一個小小的宣告:
1User-agent: *
2Disallow: /private/對高流量網路來說,這種心智模型對一個相當可觀的少數網站並不適用。
在這份資料集中:
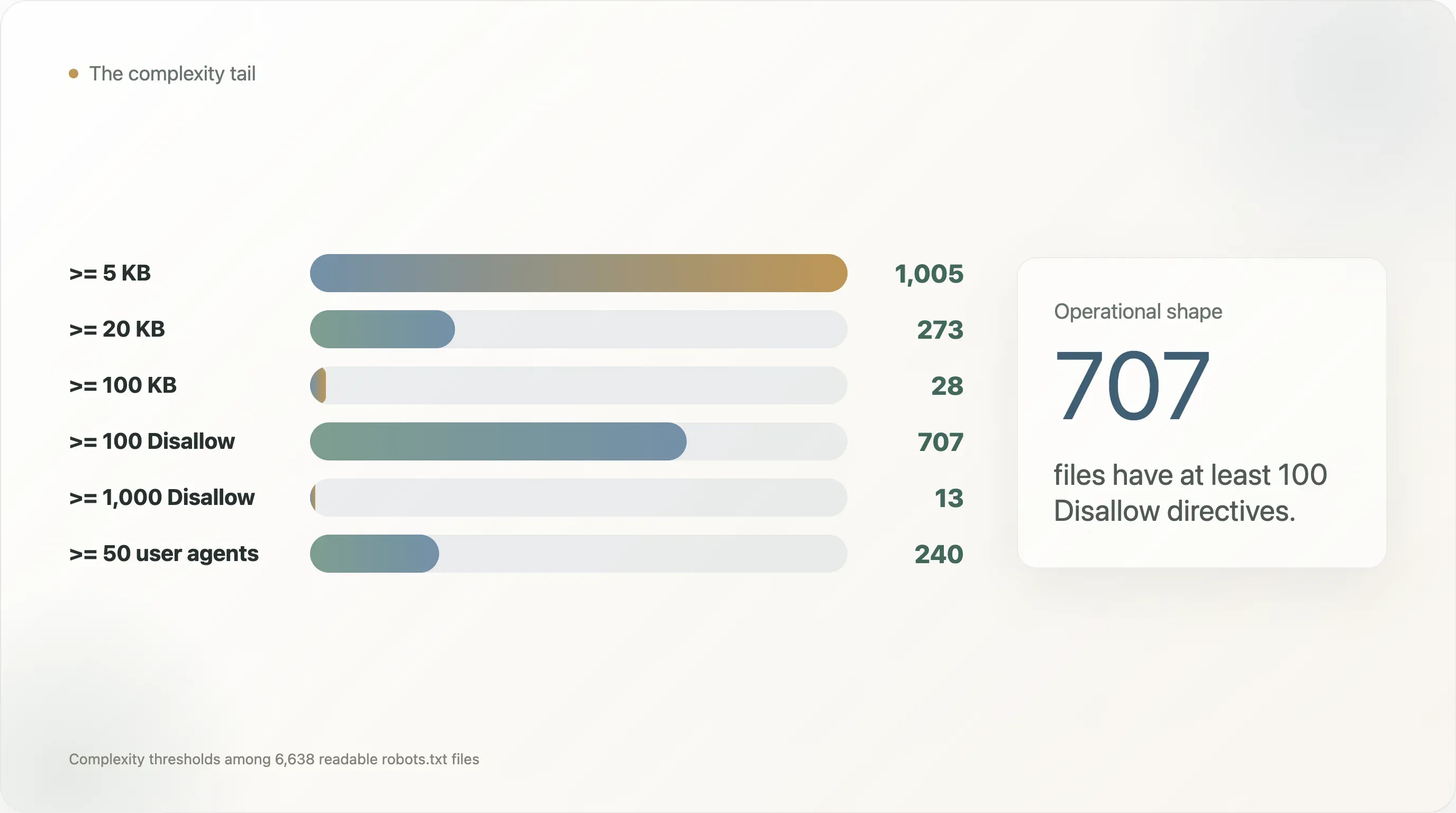
| 複雜度門檻 | 網站數 |
|---|---|
robots.txt 大於或等於 5 KB | 1,005 |
| 大於或等於 20 KB | 273 |
| 大於或等於 100 KB | 28 |
至少 50 條 User-agent 指令 | 240 |
至少 100 條 User-agent 指令 | 110 |
至少 100 條 Disallow 指令 | 707 |
至少 1,000 條 Disallow 指令 | 13 |
至少 100 條 Allow 指令 | 40 |
最大、最複雜的檔案並不是學術趣聞,而是真實的高流量網站:
| 網域 | 排名 | 類別 | 位元組數 | User-agent | Disallow | Allow |
|---|---|---|---|---|---|---|
linkedin.com | 17 | social | 114,341 | 76 | 4,184 | 281 |
runescape.com | 5,226 | unknown | 113,393 | 1 | 4,997 | 0 |
academia.edu | 832 | academia | 57,384 | 63 | 2,044 | 227 |
etsy.com | 286 | ecommerce | 51,320 | 3 | 1,621 | 120 |
thepaper.cn | 9,395 | news | 56,867 | 1 | 1,496 | 0 |
opentable.com | 4,137 | unknown | 70,494 | 32 | 1,683 | 176 |
alfabank.ru | 2,625 | finance | 73,158 | 2 | 1,566 | 133 |
這些檔案更像正式路由表,而不是政策口號。它們編碼了多年來的產品上線、舊路徑、封鎖參數模式、爬蟲例外、SEO 實驗、CDN 決策,以及現在的 AI 爬蟲規則。
尾端不只是 AI 故事。在 273 份大小達 20 KB 以上的檔案中,131 份含有 AI 政策語言,142 份沒有。至於至少有 100 條 Disallow 指令的 707 份檔案中,只有 207 份包含 AI 政策語言。換句話說,AI 並沒有造成大型檔案問題;它是在多年一般網站營運已經把這個檔案塞滿路徑規則、網站地圖參照與爬蟲例外之後才進來的。
這很重要,因為可維護性取決於結構,而不只是意圖。一份簡短、直接封鎖 AI 的檔案,可能很容易稽核;一份 70 KB 的電商或旅遊檔案,即使完全沒提 AI,也可能難以稽核。風險不在於每一份大型檔案都錯,而在於實際政策對負責它的人來說,已經太難驗證。
營運風險很直接:robots.txt 越長,出版者、平台工程師、法務或 SEO 負責人就越難回答一個基本問題:這份檔案到底允許了什麼?
而這個問題早已不再簡單。按照 RFC 式解析規則,爬蟲可能會匹配更具體的 user-agent 群組,而不是 User-agent: *;較長的路徑匹配可能覆蓋較短的路徑;Allow 與 Disallow 指令會依優先順序互相作用;而泛用的全封鎖規則,可能在檔案撰寫時根本不存在的爬蟲出現後,意外把它們也納入。
對 30 行的檔案,人工還能推理;對有數千行、而且列了幾十個命名機器人的檔案,沒人應該只靠直覺。
發現二:robots.txt 承載的,不只是爬取規則
AI 爬蟲爭議讓 robots.txt 在政治上變得可見,但這個檔案本來就早已在承擔與爬取無關的責任。
現代頂級網站的 robots.txt 可能包含:
- 爬蟲路徑控制;
- 網站地圖探索;
- 搜尋引擎專屬擴充;
- 爬取速率提示;
- 主機名稱正規化提示;
- URL 參數清理提示;
- CDN 注入的政策詞彙;
- 版權保留文字;
- AI 訓練排除;
- 供人閱讀的法律註記。
資料集清楚顯示了這層層疊加。
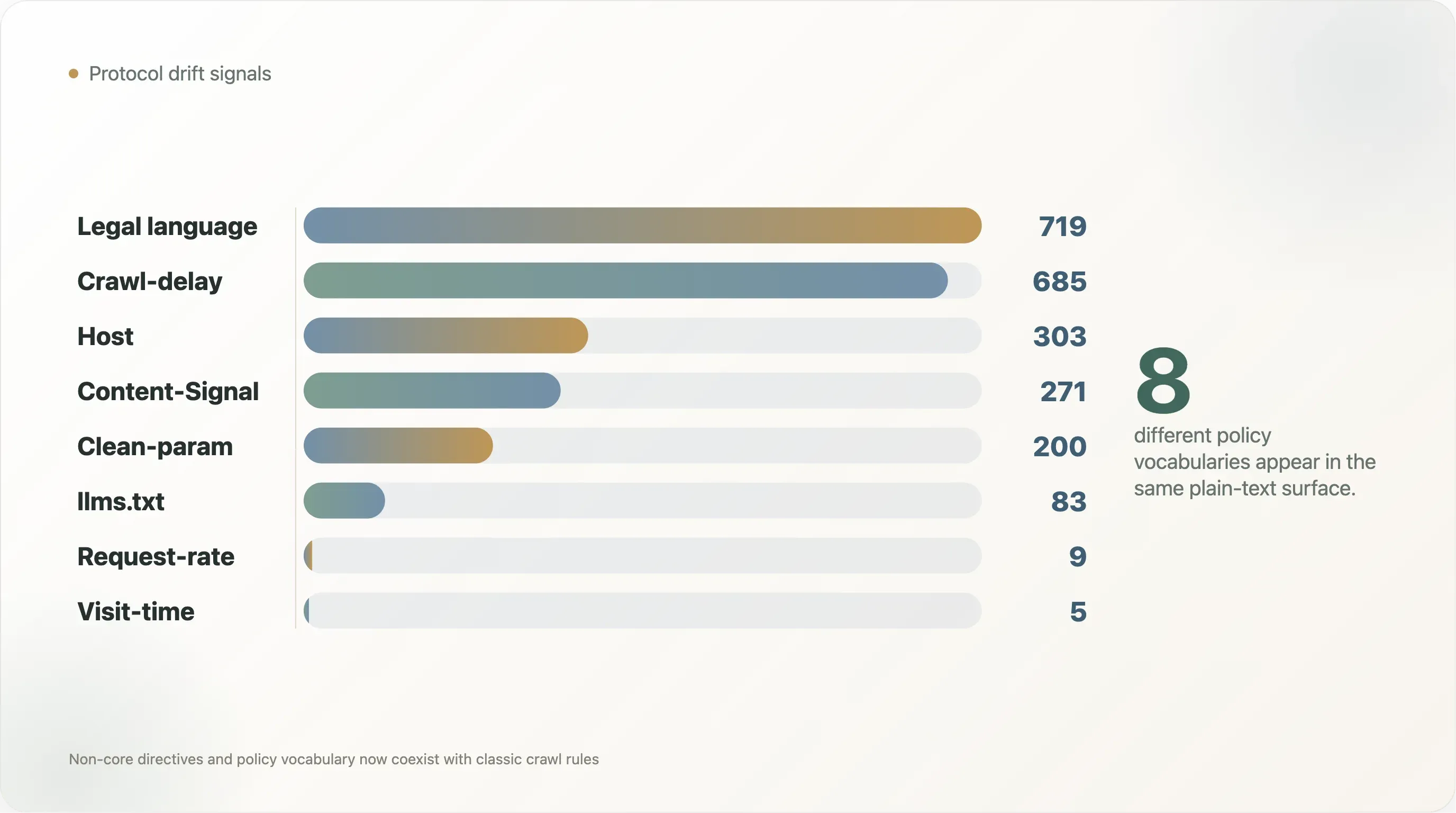
| 訊號 | 檔案數 | 占可讀檔案比例 |
|---|---|---|
Crawl-delay | 685 | 10.3% |
Host | 303 | 4.6% |
Clean-param | 200 | 3.0% |
Content-Signal | 271 | 4.1% |
Request-rate | 9 | 0.1% |
Visit-time | 5 | 0.1% |
提及 llms.txt | 83 | 1.3% |
| 版權、服務條款、授權或權限語言 | 719 | 10.8% |
| AI 政策語言 | 1,377 | 20.7% |
其中有些指令是特定爬蟲廣為認可的;有些是舊式慣例;有些是供應商專用;有些甚至根本不是爬蟲指令,而是藏在註解裡的法律或產品語言。
這就是協定漂移的樣子。
Crawl-delay 是個好例子。許多網站營運者都很熟悉它,但主流爬蟲的支援並不一致。Host 與 Clean-param 歷來常與 Yandex 行為有關。Content-Signal 屬於 Cloudflare 的 AI 時代政策詞彙。llms.txt 則是一種提議中的鄰近探索格式,並非普遍被承認的標準。然而,這些內容卻經常與經典的 User-agent 與 Disallow 規則並列出現在同一種檔案中。
數字也顯示,舊式與新式慣例如今共存。Crawl-delay 出現在 685 份檔案中,是含有 Content-Signal 的 271 份檔案的兩倍多。Host 出現在 303 份、Clean-param 出現在 200 份,多半反映搜尋引擎時代的慣例。儘管 AI 搜尋圈對 llms.txt 討論很多,可在可讀檔案中提到它的只有 83 份。現實中的網路並沒有收斂成單一詞彙,而是在堆疊詞彙。
問題不在於任何單一擴充一定錯,而在於這份檔案已經變成一個沒有版本控制的容器,裝著好幾套彼此重疊的治理系統。
這帶來三種債務:
- 語義債。 不同爬蟲可能以不同方式解讀同一份檔案。
- 所有權債。 SEO、法務、基礎設施、安全與產品團隊都可能有理由編輯這份檔案,但未必有任何單一團隊對整體政策負責。
- 稽核債。 一個網站可以發布看起來很明確的政策,但其實只有解析器能判斷真正的行為。
AI 讓這件事更重要,因為風險已經變了。當舊式爬取速率提示被忽略,結果可能只是多一點流量;但當 AI 訓練排除語意含糊時,結果可能成為版權或授權爭議中的證據。
發現三:這份檔案同時成了機器介面與法律文件
原始 AI 爬蟲報告顯示,在可分析網站中,有 17.0% 明確寫了 AI 專屬規則。這份延伸報告則檢視這些政策增加了多少文字負擔。
在 6,638 份可讀的 robots.txt 檔案中:
- 1,377 份包含 AI 政策語言;
- 719 份包含版權、條款、授權、權利或權限語言;
- 271 份包含
Content-Signal; - 83 份提到
llms.txt。
真正有意思的是這些重疊區:
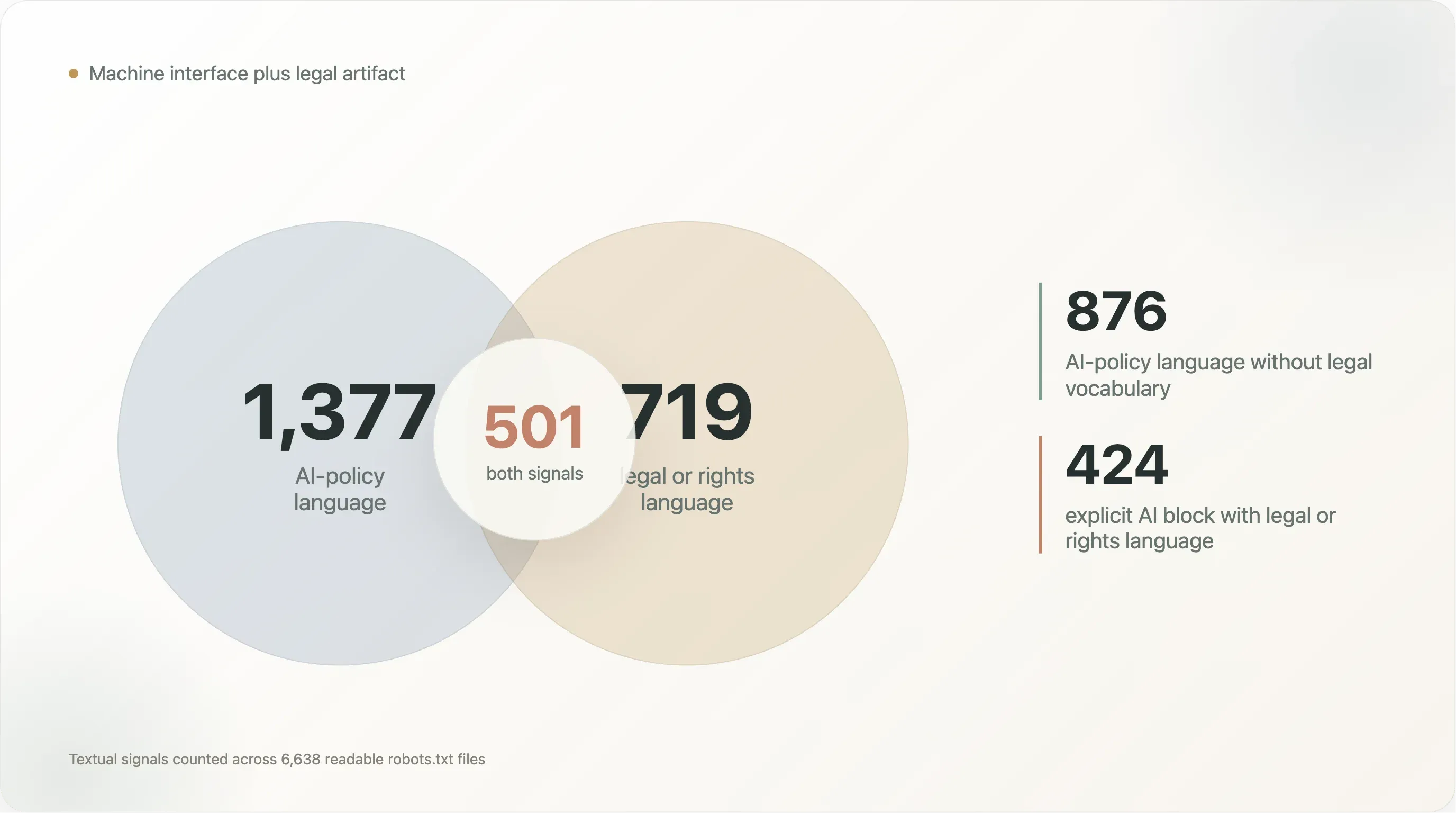
| 文字模式 | 檔案數 |
|---|---|
| AI 政策語言與法律/權利語言並存 | 501 |
| 只有 AI 政策語言,沒有法律/權利語言 | 876 |
| 只有法律/權利語言,沒有 AI 政策語言 | 218 |
Content-Signal 且含法律/權利語言 | 242 |
| 明確 AI 封鎖且含法律/權利語言 | 424 |
這是一種新的檔案。
傳統的 robots.txt 是寫給爬蟲看的;而帶有法律前言的 robots.txt 同時是寫給至少四種受眾看的:
- 需要機器可讀指令的爬蟲營運者;
- 需要政策訊號的搜尋與 AI 供應商;
- 想明確保留權利的律師;
- 未來可能把註解當成意圖證據閱讀的稽核者、法院或記者。
這種多受眾設計解釋了為什麼有些檔案現在讀起來像政策文件。但它也削弱了「爬蟲能解析什麼」與「人類法務想宣告什麼」之間的清楚分離。
那 876 份只有 AI 政策語言、卻沒有法律詞彙的檔案,大多是機器政策檔:機器人名稱、Disallow 區塊與樣板語言。501 份同時有 AI 與法律語言的檔案則不同,它們試圖同時扮演爬蟲指令與權利保留。218 份只有法律語言、沒有 AI 詞彙的檔案則顯示,這種做法並不是從 LLM 才開始;robots.txt 早就被拿來表述條款、許可邊界與權利主張。
例如,某段註解可能說明禁止機器學習,但實際指令區塊只封鎖了少數已知 user agent。某個網站可能在全站宣告權利,但實際只列出少數幾個爬蟲。某個 CDN 樣板可能把 AI 相關詞彙注入一份其實從未由網站營運者手動撰寫法律語言的檔案。某個網站也可能寫出廣泛的 User-agent: * 規則,卻在不知不覺間把未來的新爬蟲也封鎖了。
從治理角度來看,robots.txt 之所以變得吸引人,正是因為它公開且可機器讀取。但它承載的政策越多,它的限制也就越明顯:
- 沒有認證層可證明某個特定政策是由權利人審閱,而非沿襲自基礎設施;
- 沒有原生版本歷史;
- 沒有針對預期用途的結構化欄位,例如訓練、擷取、搜尋索引、摘要、快取或模型評估;
- 沒有 AI 爬蟲身分的通用登錄表;
- 沒有執行機制。
這不代表檔案沒用,而是代表它很脆弱。
更好的理解方式,是把 robots.txt 視為一層通知:一份公開、可檢視的偏好與意圖宣告。它本身不是完整的權利管理系統。
發現四:在 AI 到來之前,搜尋本來就不平等
原始報告最強烈的發現之一,是許多出版者會區分 AI 訓練爬蟲與搜尋爬蟲:他們會封鎖 CCBot、GPTBot 或 Google-Extended,同時保留 Google 搜尋可見性。
這份延伸報告補上一個不同的觀點:傳統搜尋爬蟲之間也不是平等對待。
我們檢查了六個搜尋爬蟲:
- Googlebot;
- Bingbot;
- DuckDuckBot;
- Slurp;
- Baiduspider;
- YandexBot。
在 7,248 個可分析網站中:
| 搜尋爬蟲處理方式 | 網站數 |
|---|---|
| 至少封鎖一個搜尋爬蟲 | 562 |
| 允許 Googlebot 但封鎖至少一個其他搜尋爬蟲 | 404 |
| 封鎖六個受檢查的搜尋爬蟲全部 | 152 |
被封鎖的機器人分布並不平均:
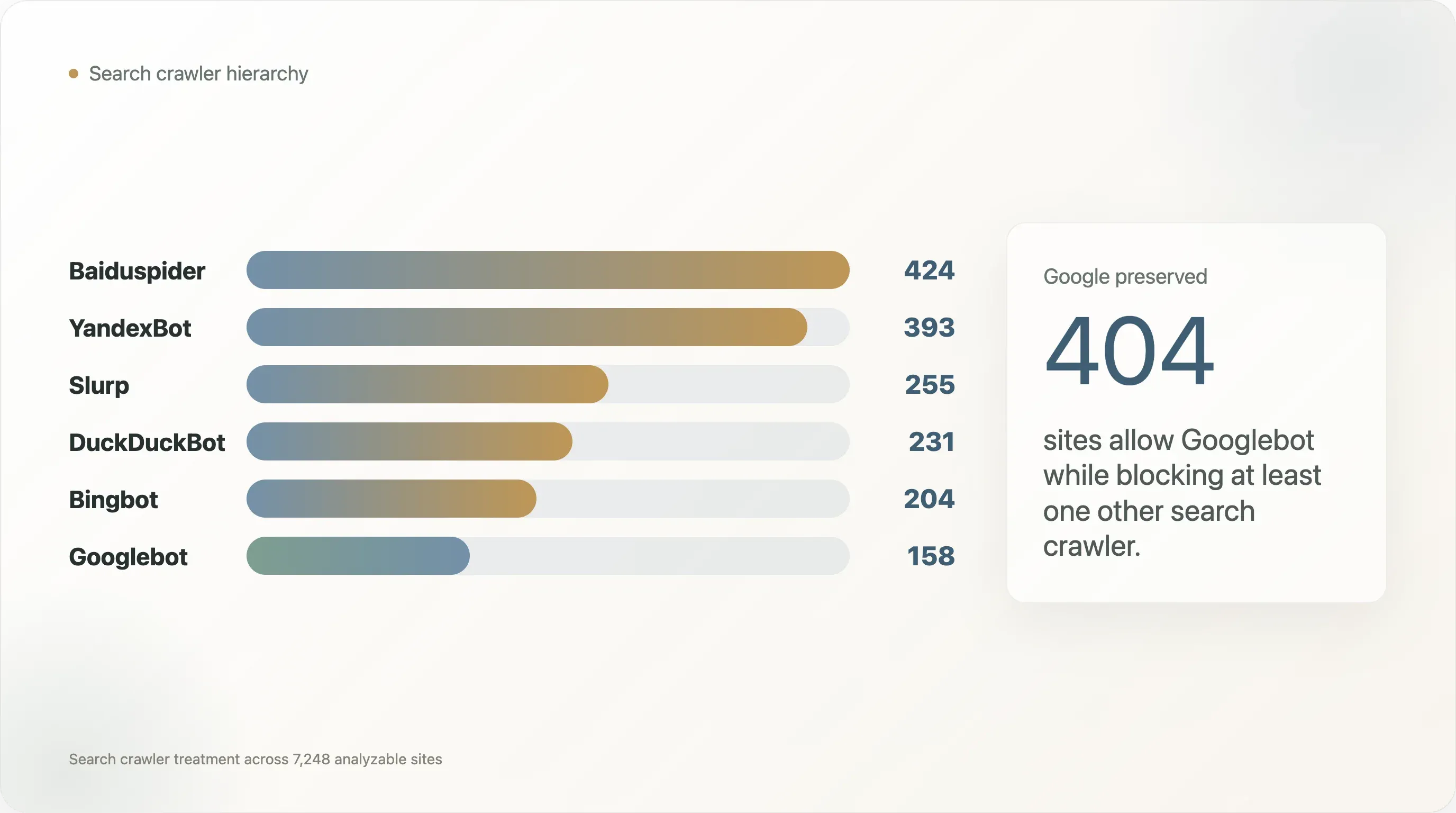
| 搜尋爬蟲 | 封鎖它的網站數 |
|---|---|
| Baiduspider | 424 |
| YandexBot | 393 |
| Slurp | 255 |
| DuckDuckBot | 231 |
| Bingbot | 204 |
| Googlebot | 158 |
在這組樣本裡,Googlebot 是最少被封鎖的爬蟲。Baiduspider 與 YandexBot 更常被封鎖,而在多數這類案例中,Googlebot 仍被允許。在那 404 個允許 Googlebot、卻封鎖其他搜尋爬蟲的網站中,有 269 個封鎖 Baiduspider,240 個封鎖 YandexBot。
這些例子都很高知名度:
| 網域 | 在允許 Googlebot 時封鎖的搜尋爬蟲 |
|---|---|
facebook.com | Baiduspider、YandexBot |
apple.com | Baiduspider |
twitter.com | DuckDuckBot、Slurp、Baiduspider、YandexBot |
netflix.com | DuckDuckBot、Slurp |
x.com | DuckDuckBot、Slurp、Baiduspider、YandexBot |
tiktok.com | Baiduspider |
baidu.com | Bingbot、DuckDuckBot、Slurp、YandexBot |
washingtonpost.com | YandexBot |
wsj.com | YandexBot |
bilibili.com | DuckDuckBot、Slurp、YandexBot |
temu.com | Slurp |
t-mobile.com | Baiduspider、YandexBot |
這對 AI 辯論很重要,因為它顯示即使在 LLM 爬蟲出現之前,robots.txt 也從來不是一個中立、普遍可存取的協定。公開網路早就有一套層級:
- Googlebot 通常會被保留,因為失去 Google 搜尋流量代價太高;
- 區域型或競爭對手爬蟲比較容易被封鎖;
- 有些網站會把搜尋爬蟲存取視為按市場或按供應商的決策。
AI 爬蟲進入的是一個早就習慣差異化存取的生態。
這讓政策轉換更容易理解。一個寫下「封鎖 Google-Extended、允許 Googlebot」的出版者,並不是在發明一種新歧視,而是在把舊模式套用到新型爬蟲:保留分發,限制擷取。
尚未解決的問題是,這種舊模式是否能持續擴張。搜尋時代,經濟上重要的爬蟲只有少數幾個;但到了 AI 時代,爬蟲身分被切分成模型供應商、檢索機器人、資料中介、學術爬蟲、合成瀏覽器代理與基礎設施層擷取器。除非生態系統收斂到更少、且以用途為核心的訊號,命名 user agent 的數量只會持續增加。
這就是組態債如何複利擴大。
發現五:不同產業的複雜度不同,但和 AI 封鎖率不是同一種分布
原始報告顯示 AI 封鎖在產業之間差異很大:新聞封鎖率高;電信、政府與 SaaS 則較低。
但組態複雜度切分網路的方式不同。
在一些可讀 robots.txt 數量足夠、足以比較的類別中:
| 類別 | n | 中位數位元組數 | P90 位元組數 | 中位數 Disallow | P90 Disallow | 中位數 User-agent | P90 User-agent |
|---|---|---|---|---|---|---|---|
| ecommerce | 215 | 1,738 | 10,388 | 37 | 164 | 3 | 49 |
| travel | 63 | 2,074 | 27,368 | 41 | 779 | 5 | 34 |
| news | 647 | 1,534 | 7,039 | 19 | 114 | 6 | 68 |
| finance | 121 | 1,002 | 8,337 | 17 | 132 | 2 | 23 |
| academia | 253 | 839 | 3,959 | 14 | 75 | 1 | 11 |
| government | 151 | 1,227 | 3,263 | 13 | 46 | 1 | 4 |
| SaaS | 368 | 485 | 12,606 | 4 | 56 | 1 | 10 |
| dev tools | 119 | 273 | 9,255 | 3 | 58 | 1 | 10 |
P90 Disallow by category chart here<<<<<<<<<<<<<<<<<<<<<<<<<
新聞之所以政治上複雜,是因為它寫明 AI 規則與法律文字;但電商與旅遊在營運上複雜,則是因為它們有大量商品目錄、分面導覽、搜尋結果頁、篩選器、會員路徑與帶參數的 URL。
這個區別很重要。
旅遊是最明顯的例子。這個類別切片中只有 63 份可讀檔案,但其 P90 robots.txt 達 27.4 KB,P90 Disallow 數量高達 779,遠高於新聞。這並不代表旅遊網站有更成熟的 AI 政策,而是代表旅遊網站有更多爬蟲營運者容易浪費預算的表面:日期搜尋、可用性頁面、評論分頁、預訂流程、篩選組合與在地化庫存路徑。
SaaS 則是另一種意外。它的中位數檔案只有 485 位元組,但 P90 卻跳到 12.6 KB。多數 SaaS 網站都開放而精簡;少數網站則有很長的路徑控制檔,通常是因為文件、登入頁面、應用程式路由與行銷頁面共用同一個網域。
新聞在營運上處於中間,但在政治上接近前列。它的 P90 User-agent 數量是 68,高於這個表中的電商、旅遊、金融、學術、政府、SaaS 與開發工具。這顯示的是針對特定機器人的政策,而不只是路徑整理。
出版者的 robots.txt 可能因權利政策而複雜;市集的檔案可能因爬取預算管理而複雜;大學的檔案可能因多年舊路徑累積在同一網域下而複雜;社群平台的檔案可能因為必須在大規模下曝露某些表面、隱藏另一些表面而複雜。
AI 政策只是疊在這一切之上,並沒有取代原本讓檔案變複雜的原因。
這也說明為什麼 AI 時代的 robots.txt 治理,無法靠一份通用封鎖清單解決。底層檔案各有不同工作:
- 電商網站管理重複路徑與商品頁面;
- 旅遊網站管理列表、行事曆、評論與動態搜尋頁;
- 新聞網站管理版權、封存與授權立場;
- SaaS 與開發工具網站通常希望 AI 可見;
- 政府網站通常需要公開存取,但仍可能有敏感系統需要排除;
- 社群平台則要管理使用者生成內容、個人檔案頁與反濫用疑慮。
同一條 AI 爬蟲規則,在每種環境中的意義都不同。
發現六:組態債指數找的是審查風險,不是道德失敗
這次分析建立了一個簡單的組態債分數,用來找出那些可能難以審查的 robots.txt 檔案。
這個分數加權以下因素:
- 檔案大小;
User-agent指令數量;Disallow指令數量;Allow指令數量;- 非核心指令數量;
- 是否包含 AI 政策語言;
- 是否同時包含明確 AI 封鎖與法律或版權語言。
這不是正確性分數。高複雜度檔案完全可能是刻意如此;低複雜度檔案也仍可能出錯。重點在於初步篩選:如果一份檔案又大、又充滿政策、又針對特定機器人、還有大量例外,那它就值得更嚴格的審查規範。
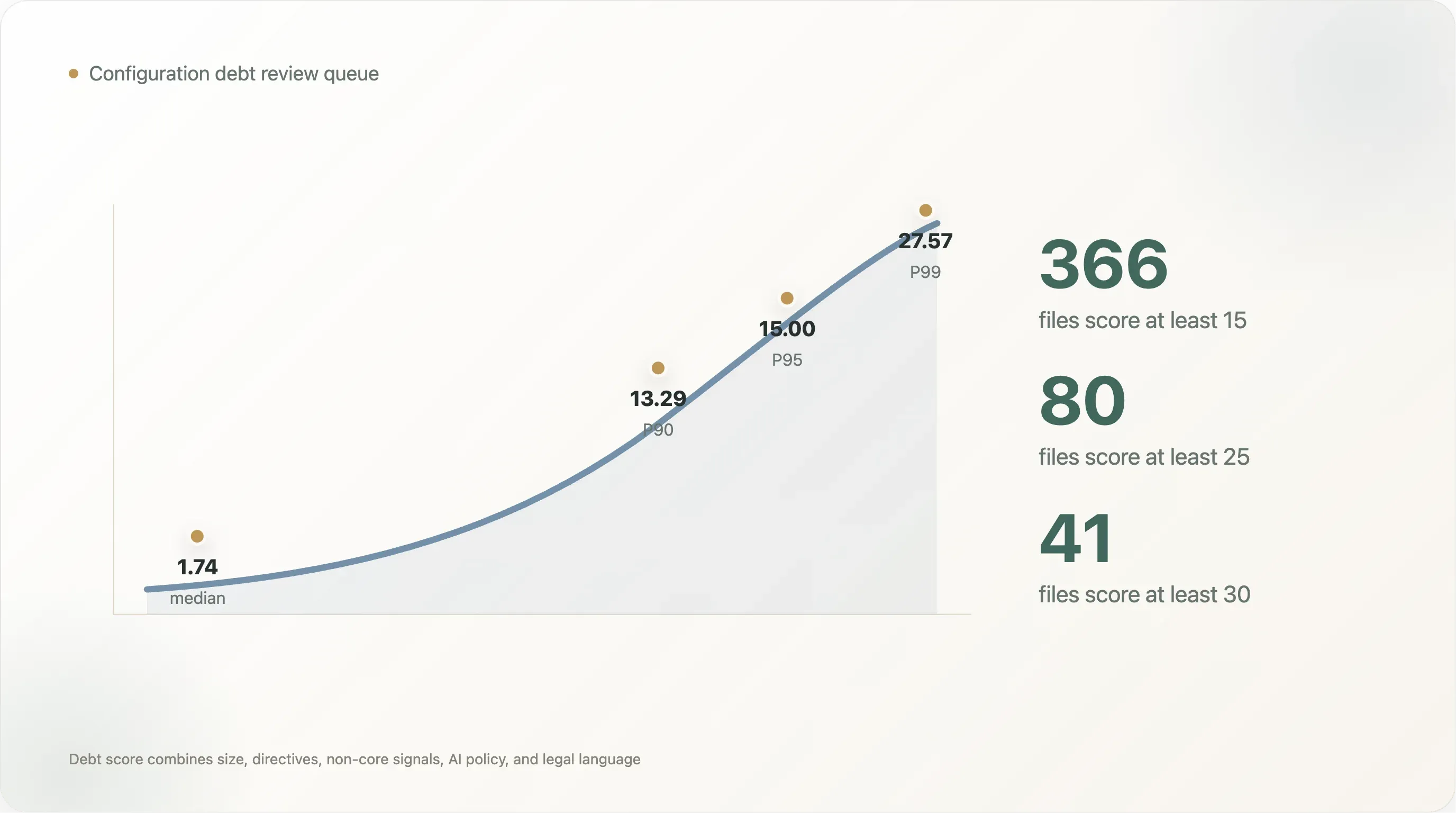
分數分布非常陡峭。中位數可讀檔案的分數是 1.74,P90 是 13.29,P95 是 15.00,P99 是 27.57。只有 366 份檔案分數至少 15,80 份至少 25,41 份至少 30。這就是實務上的審查隊列:不是每個網站都需要一個治理專案,但尾端上方那一群確實需要。
類別視角也顯示,單一句「AI 封鎖者」標籤太過扁平:
| 類別 | 中位數分數 | P90 分數 |
|---|---|---|
| travel | 4.92 | 28.94 |
| search | 2.97 | 24.23 |
| social | 2.25 | 15.00 |
| news | 4.91 | 14.92 |
| finance | 1.67 | 12.61 |
| SaaS | 0.98 | 11.85 |
| ecommerce | 3.88 | 10.87 |
| government | 1.57 | 6.38 |
旅遊與搜尋的 P90 分數最高,因為少數檔案變得非常大、規則也非常多。新聞的中位數分數偏高,則是因為整個類別普遍更常出現政策語言與針對機器人的處理方式。電商的中位數 Disallow 數量很高,但其 P90 債務分數低於旅遊,因為它的複雜度更集中在路徑規則,而不是混合式政策/法律訊號。
這份資料集中分數最高的檔案包括:
| 網域 | 高分原因 |
|---|---|
linkedin.com | 檔案極大、數千條路徑規則、很多命名 user agent、明確 AI 政策語言 |
lnkd.in | 與 LinkedIn 短連結基礎設施相同的政策表面 |
fragrantica.com | 數百個命名 user-agent 區塊,外加 AI 政策語言 |
sovcombank.ru | 數百個 user-agent 區塊與法律/政策語言 |
academia.edu | 大型 allow/disallow 矩陣與明確 AI 封鎖政策 |
opentable.com | 大型路徑規則集、許多網站地圖指令、AI 相關政策表面 |
etsy.com | 大型電商路徑控制檔,超過 1,600 條 Disallow 規則 |
runescape.com | 幾乎 5,000 條 Disallow 指令,全都在同一個 user-agent 群組下 |
這些檔案不該因為複雜而被嘲笑。複雜性往往反映真實商業需求。但它們也證明,robots.txt 政策應該像其他正式營運組態一樣接受工程紀律:
- 所有權應該明確;
- 變更應該經過審查;
- 生成區段應標示出來;
- 盡可能將法律註解與機器指令分離;
- 應為關鍵爬蟲建立測試案例,驗證預期的機器人存取;
- 應保留版本歷史;
- 舊機器人名稱應退場或文件化;
- AI 訓練、AI 擷取、搜尋索引與封存,應視為不同用途。
最後一點最重要。當前語法是以 user-agent 為中心:它要求網站營運者列出機器人名稱。AI 時代真正需要的是以用途為中心:它要求網站營運者說明哪些用途被允許。
這兩者並不相同。
這種不匹配,正是為什麼更長的封鎖清單不會長久。出版者今天可以新增 GPTBot、ClaudeBot、CCBot、Google-Extended、Bytespider、Applebot-Extended 與 PerplexityBot,但明天就可能出現新的爬蟲名稱、檢索代理或資料中介。一套以用途為基礎的政策,會讓網站能說「搜尋索引可以,AI 訓練不行,使用者觸發的檢索也許可以」,而不是把 robots.txt 變成機器人通訊錄。
這對 AI 治理意味著什麼
公開辯論常把 robots.txt 描述成「有意義」或「過時」。資料顯示的答案更務實:
robots.txt 很有意義,但它已經負荷過重。
它之所以有意義,是因為大型網站真的在使用它,爬蟲也能解析它,而政策選擇對研究者、記者、供應商與法院都是可見的。原始報告發現,在可分析的頂級網站中,有 17.0% 明確寫了 AI 專屬規則。這不是象徵性雜訊。
它之所以負荷過重,是因為這份檔案現在必須表達的不只是機器人存取:
- 「不要拿這些內容訓練。」
- 「你可以把這些內容用於搜尋索引。」
- 「你可以把這些內容用於即時檢索。」
- 「你不可以建立快取資料集。」
- 「這項法律保留適用於歐盟文字與資料探勘法。」
- 「這個由 CDN 管理的網站送出
Content-Signal: ai-train=no。」 - 「這個網站希望 Googlebot 存取,但不希望 YandexBot 存取。」
- 「這個網站有 1,000 條舊 URL 路徑不應被爬取。」
當前語法根本不是為這麼多工作設計的。
若要降低這筆債務,有三項改變會有幫助:
-
爬蟲身分需要登錄制度。 網站營運者不應該被迫維護一份不斷增長的清單,列出
GPTBot、ClaudeBot、anthropic-ai、CCBot、Google-Extended、Applebot-Extended、Bytespider、OAI-SearchBot、ChatGPT-User等等。沒有登錄制度,政策永遠會落後於爬蟲行為。 -
AI 使用需要結構化詞彙。 訓練、檢索、索引、摘要、資料集轉售、模型評估與使用者觸發瀏覽是不同用途。用供應商專屬 user-agent 名稱來表達這些用途,太脆弱了。
-
政策需要可稽核性。 網路需要一種方法,能區分人手撰寫的權利保留、沿襲自 CDN 預設值、CMS 自動產生樣板、過時舊規則,以及不小心寫出的全面封鎖。這種區分對信任與訴訟都很重要。
這並不代表要一夜之間取代 robots.txt。更好的方向是分層:保留 robots.txt 作為探索與相容性介面,但針對 AI 專屬用途,標準化鄰接的機器可讀政策。
llms.txt 是其中一種嘗試,但在這份資料集中採用率仍然很低:只有 83 份可讀檔案提到它。Content-Signal 較為顯眼,是因為 Cloudflare 可以透過基礎設施分發,而且我們掃描到的 271 份 Content-Signal 檔案也都匹配到了 AI 政策語言。不過,廣泛分發並不等於形成共識。真正可持久的解法,可能還是得靠標準化那套看似枯燥但必要的機制:清楚欄位、清楚語義、爬蟲承諾與公開測試套件。
結論
AI 爬蟲之戰把 robots.txt 變成了一種治理文件。這既有用,也有風險。
有用,是因為檔案是公開的。研究者能稽核,出版者能修改,爬蟲能遵守,法院能閱讀,基礎設施供應商也能大規模部署。
有風險,是因為它承擔得太多了。
Tranco Top 10K 中位數的 robots.txt 檔案仍然小到可以理解;但高流量網路的長尾,充滿了大型、舊式、層層堆疊、供應商專用且帶有法律壓力的檔案。如今已有數百個網站維護的 robots.txt 組態,比起簡單的爬蟲提示,更應被理解為正式營運政策系統。
核心教訓不是 robots.txt 失敗了,而是網路把它升級了,卻沒有重新設計它。
如果 AI 存取政策要依賴機器可讀的公開宣告,那下一步就不是再做一份更長的封鎖清單,而是更好的政策基礎設施:以用途為基礎的權限、穩定的爬蟲身分、可審查的樣板與稽核軌跡。
在此之前,公開網路的 AI 治理層,仍會繼續建立在一個從未打算承載這麼多重量的文字檔上。
可重現性說明
交付資料夾包含:
source_data/analysis.json— 原始彙總指標。source_data/site_meta.csv— 原始逐站分析表。source_data/bot_status.csv— 原始網域對機器人政策表。source_data/fetch_meta.csv— 原始擷取中繼資料。source_data/sites.csv— 原始網域/類別/狀態表。derived_data/robots_complexity_by_site.csv— 生成本報告所需的逐站複雜度指標。derived_data/search_bot_treatment.csv— 搜尋爬蟲處理矩陣。derived_data/category_complexity_summary.csv— 類別層級複雜度摘要。derived_data/top_config_debt_sites.csv— 依前述初步篩選分數排序的高分網站。derived_data/summary_metrics.json— 本報告引用的所有重點指標。
歡迎將方法論更正、資料集問題與後續分析寄至 support@thunderbit.com。本報告的發布不受 Thunderbit 持有的任何商業立場影響;我們打造的是 AI 驅動的網頁爬蟲,而我們在結構上確實希望 robots.txt 能持續成為公開網路上有意義、可機器讀取的契約。本報告中的資料本身自成一體。—— Thunderbit 研究團隊,2026 年 5 月。