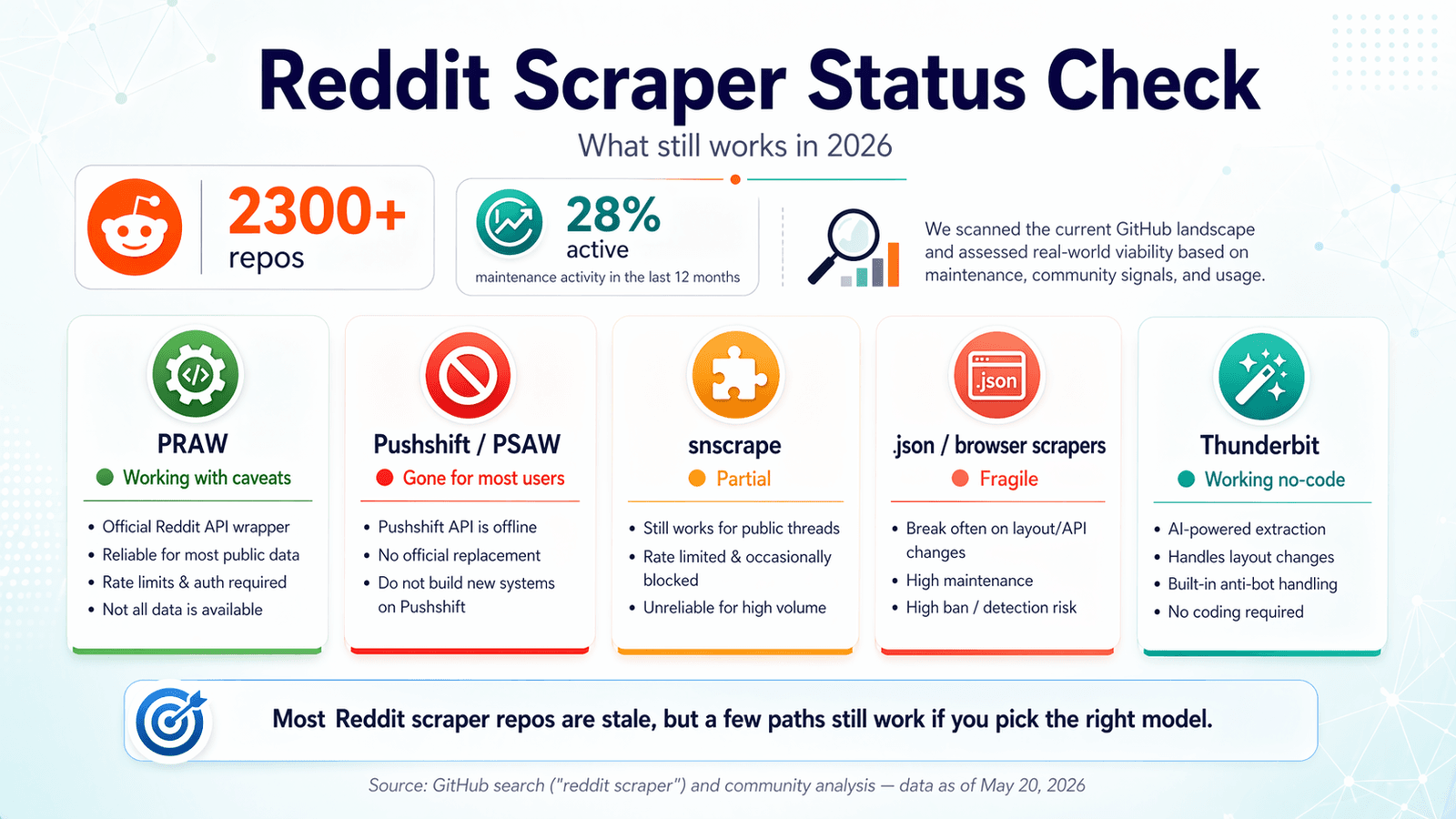
GitHub 現在顯示超過 。看起來像自助餐,但問題是:近十二個月內真正有維護跡象的,大約只有 28%。過去幾週,我一直在翻這些 repo、測試端點、閱讀 issue 佇列,並對照 Reddit 自己的政策更新。目標很簡單:別讓你辛苦 clone 一個 repo、跟 OAuth 奮戰,然後在半夜才發現它早在 2024 年就悄悄壞掉了。到了 2026 年,Reddit scraper GitHub 的版圖像是一座理想與現實並存的墓園:少數工具真的有用,大多數則不是壞了就是過時了。這篇指南會告訴你哪些還能用、哪些已失效、什麼時候該完全跳過程式碼,以及如何站在 Reddit 越來越嚴格的執法規範那一邊。如果你想直接走捷徑,Thunderbit 是我們為這類問題打造的免程式方案——但我也會老實說,哪些情況下用程式碼仍然更合理。
什麼是 Reddit Scraper GitHub Repo?為什麼這麼多都壞了?
所謂的「reddit scraper github」repo,通常是用 Python(有時是 JavaScript)寫的開源專案,用來自動抓取 Reddit 上的貼文、留言、使用者資料或媒體。大致可分成四類:
- API 包裝器(像 PRAW):使用 Reddit 官方 API,需要 OAuth,並遵守 Reddit 的規則。
- Pushshift / PSAW 類工具:過去用來透過 Pushshift 的大型 Reddit 歷史資料庫抓歷史資料。
- 公開
.json端點爬蟲:在 Reddit URL 後面加.json,或直接打公開端點,不必驗證。 - 瀏覽器型爬蟲:使用 Playwright、Selenium 或瀏覽器擴充功能載入 Reddit 頁面,擷取已渲染內容。
為什麼這麼多會壞?主要有三個原因。
- Reddit 在 2023 年中大幅調整 API 收費。 免費 API 限制降到 。更高的商業用量現在每 1,000 次 API 呼叫要收 0.24 美元。很多 repo 都是為了那個幾乎沒有上限的年代而寫的——那個年代已經結束了。
- Pushshift 的公開存取被撤銷。 Pushshift 曾是 Reddit 歷史研究的核心。一旦 Reddit 限制它,很多「歷史爬蟲」repo 失去了主要資料來源。雖然有些 README 看起來還活著,但底層依賴對一般使用者來說已經沒了。
- Reddit 同時收緊政策與執法。 2024 年的 robots.txt 更新、2025 年的 ,以及 2026 年 3 月的 ,都明確顯示 Reddit 不再把大量爬取當成無害的背景噪音。他們甚至已經 。
結論很直接:你只要搜尋「reddit scraper github」,會看到幾百個結果;但最後一次提交時間和 open issue 數量,會告訴你完全不同的故事。
2026 年 Reddit Scraper GitHub 狀態檢查:哪些還能用?
大多數競品文章都寫於 2023 或 2024 年,而且從沒更新。論壇使用者仍在追著一年前還能跑的 repo 出錯——有位使用者的求助「一直碰到 Reddit API 限制錯誤:有什麼方法能繞過嗎?」幾乎就是 2026 年 Reddit scraper 使用體驗的縮影。
我做了一次新鮮度檢查,確認時間截至 2026 年 4 月。結果如下。
PRAW:官方 Python 包裝器
狀態:✅ 仍可使用,但有前提。
(Python Reddit API Wrapper)仍然是 Reddit scraping 最穩定的開源基礎。它維護得很積極——4,099 顆星、最後推送時間為 2026 年 4 月 20 日、只有 6 個 open issue,而且 (2024 年 10 月發佈)。
優點: 官方、文件完整、能抽象掉大部分 Reddit API 的複雜性。
2026 年限制:
- OAuth 要求更嚴格。你需要註冊 Reddit app,並填寫獲批的使用情境說明。
- 自 2024 年起速率限制更低(有 OAuth 時每分鐘 100 次查詢、沒有時 10 次)。
- 約 1,000 篇貼文的清單上限仍然存在。r/redditdev 和 Stack Overflow 的社群討論都證實:每個 listing endpoint 。
如果你願意待在 API 的框架裡,PRAW 仍然是最安全的選擇。
只是它已經不再是那種可以自由大量抓資料的工具了。
如果你想看官方 API 路線的實作流程,這段教學很適合搭配這一節:
Pushshift / PSAW:曾經很強、如今關門的資料庫
狀態:❌ 公開存取已消失。
曾經是 Pushshift 最常用的 Python 包裝器,而 Pushshift 原本也是取得 Reddit 歷史資料最容易的方式。到了 2026 年,這個 repo 已歸檔,README 甚至直接寫著「THIS REPOSITORY IS STALE」,而近期的 open issue 包括像「Pushshift.io UNABLE to connect」和「The code not working. Possibly due to pushshift api.」這類例子。
學術用途或許仍能透過特定管道取得存取權,但如果你今天在搜尋「reddit scraper github」,Pushshift / PSAW 已經不是可行選項。若你需要深度歷史資料,就得改找核准的學術資料存取或授權路徑。
snscrape(Reddit 模組):部分可用,但不可靠
狀態:⚠️ 部分可用——偶爾失效,而且大致沒在維護。
有 5,337 顆星,但最後一次推送是 2023 年 11 月 15 日。README 仍寫著 Reddit scraping 可「via Pushshift」支援。與 Reddit 有關的 open issue 包含「Error reddit scraping」與「Reddit scraper returns no submissions before 2022-11-03」,而且最近沒有明顯的修復活動。
它在某些環境下,適合做少量、一次性的抓取,但不適合生產環境或定期任務。把它當成舊世代工具比較合理。
Playwright 與 .json 端點爬蟲:有效,但脆弱的替代方案
狀態:✅ 可用,但很脆弱。
這個思路很直接:用 headless browser(Playwright、Puppeteer)載入 Reddit 頁面,抓取渲染後內容;或者直接在 Reddit URL 後加 .json,不走官方 API 也能拿到結構化資料。
優點: 不需要 API key,可繞過 1k 貼文上限,也能取得已渲染內容。
缺點: Reddit 一旦改版前端版面或 JSON 結構就可能壞掉,也可能觸發反機器人機制,而且技術設定更繁瑣。我這個月實測時,直接對 Reddit 公開 .json 端點發出請求,回傳的是 403。這不代表所有環境都會被擋,但至少表示 .json 這條捷徑,已經不能再假設「一定能直接用」。
像 這類 repo 反而很誠實:README 直接提醒使用者「請搭配輪換代理使用,不然 Reddit 可能送你一個 IP ban。」這句話幾乎就是 2026 年 4 月的真實寫照。
如果你在評估瀏覽器自動化這條路,這支 Playwright 教學很適合接在下面這一節閱讀:
Thunderbit:AI 驅動的瀏覽器爬取(免程式、免 API Key)
狀態:✅ 可用——會自動適應頁面變動。
Thunderbit 採取的是完全不同的方法。它是一個 ,用 AI 讀取 Reddit 頁面、建議資料欄位(貼文標題、作者、讚數、時間戳、URL 等),並在兩次點擊內匯出結構化資料。沒有 OAuth 設定、沒有 API key 註冊、沒有 Python 環境、也不用處理依賴套件。AI 每次都會重新讀頁面,所以當 Reddit 改版時,Thunderbit 會自動調整,而不是悄悄壞掉。
可免費匯出到 CSV、Google Sheets、Airtable 或 Notion。支援分頁與子頁面爬取(例如先抓 subreddit 列表,再逐篇進入貼文抓留言)。對於想要 Reddit 資料、但不想維護 GitHub repo 的使用者來說,這是阻力最小的路徑。
(先說清楚:Thunderbit 是我們做的,所以我確實有立場——但本文後面也會清楚說明哪些情境下程式碼方案仍然更合理。)
並排狀態摘要表
| 工具 / 類別 | 到 2026 年 4 月仍可用? | 需要 API Key? | 備註 |
|---|---|---|---|
| PRAW | ✅ 是,但有前提 | 是(OAuth) | 維護最好的開源基礎。受速率限制與 1k 貼文上限限制。 |
| Pushshift / PSAW | ❌ 否(對大多數使用者而言) | 不適用 | 公開存取已消失。Repo 已歸檔。 |
| snscrape(Reddit 模組) | ⚠️ 部分可用 / 不可靠 | 否 | 仍寫著 Reddit「via Pushshift」;自 2023 年起維護停滯。 |
| .json / 公開端點爬蟲 | ⚠️ 部分可用 | 否 | 能用,但直接請求越來越常被阻擋;依賴代理。 |
| Playwright / 瀏覽器爬蟲 | ✅ 是,但很脆弱 | 通常否 | 最實際的免 API 自行實作方案。頁面改動與反機器人檢查仍是關鍵。 |
| Thunderbit | ✅ 是 | 否 | AI / 瀏覽器工作流;不需 OAuth,也不需選擇器。最適合非開發者。 |
速率限制、1k 貼文上限,以及真正有幫助的是什麼
這是任何使用 reddit scraper github 專案的人最常遇到的第 1 號痛點。論壇討論串裡充滿挫折感:「跑到一半因為 rate limit 掛掉,真的受夠了」、「為什麼我只拿到大約 1,000 筆資料?」核心限制就是 Reddit 的 API 速率限制(每分鐘請求數)與約 1,000 貼文的清單上限(API 每個 listing endpoint 只會回傳最近約 1,000 篇貼文)。
速率限制管理的最佳做法
Reddit 目前公開基準是:。實務上可以這樣處理:
- 指數退避。 如果遇到 rate-limit 回應,先等待,再把重試間隔逐步拉長(1 秒、2 秒、4 秒、8 秒……)。不要一直猛打同一個端點。
- 讀取
X-Ratelimit-Remaining標頭。 Reddit API 回應會包含標頭,告訴你還剩多少請求、以及什麼時候重置。請依這些數值節奏化請求,而不是憑感覺亂猜。 - 輪換 user-agent。 有些 repo 會建議這麼做以避免被偵測。這可能有幫助,但請以合乎倫理的方式使用——不要拿來逃避你自己被記錄的封鎖。
- 全部記錄下來。 為 API 回應、rate-limit 標頭與錯誤加上 logging。當你的爬蟲在凌晨 2 點掛掉時,log 就是你最好的朋友。
突破 1,000 貼文上限
對付 API 約 1,000 筆清單上限,最可信的 workaround 是 時間區段切分:
- 用
before與aftertimestamp 參數查詢一個時間切片。 - 把時間窗往前或往後移。
- 重複執行。
- 以貼文 ID 去重。
這不是很優雅,但比起假裝只靠一個請求迴圈就能從 listing endpoint 任意抓歷史資料,誠實得多。若你真的需要歷史資料,就得找核准的學術存取或授權路徑——Pushshift 已不再是預設答案。
瀏覽器型爬取(Playwright 或 Thunderbit)則能完全繞過這個上限,因為它抓的是頁面渲染後的內容,而不是 API 回傳值。Thunderbit 的分頁功能可以讓你一路點下去,把多頁資料都收集起來。
去重與錯誤復原
多數 reddit scraper github repo 預設都沒有處理去重或錯誤復原。使用者會直接抱怨:「沒有一個有 dedup、沒有錯誤後的 rate limit 避讓、也沒檢查檔案是否已下載。」你可以這樣做:
- 去重: 對每篇貼文的 ID(或 ID + 內容)做雜湊。把看過的 hash 存在簡單的 SQLite 資料庫,甚至純文字檔也可以。每次插入前先檢查 hash 是否已存在。這在分段時間窗或重跑失敗任務時特別重要。
- 錯誤復原: 每抓 N 筆資料就把進度寫到 checkpoint 檔。若執行中失敗,下次從最後一個 checkpoint 繼續,而不是全部重來。這能把一個跑到第 2 小時才掛掉的 3 小時工作,變成只需續跑 1 小時。
不同方法如何處理這些限制

| 方法 | 速率限制處理 | 可抓 >1k 貼文? | 自動去重? | 錯誤復原? |
|---|---|---|---|---|
| PRAW(原生) | 手動(sleep/retry) | ❌(API 上限) | ❌ | ❌ |
| PRAW + 時間窗切分 | 手動 | ✅(workaround) | ❌ | ❌(除非自行加上) |
| Playwright .json 抓取 | 不適用(無 API) | ✅ | ❌ | ❌ |
| Thunderbit(瀏覽器爬取) | 內建(AI 節奏控制) | ✅(分頁) | 不適用(視覺化檢查) | 內建 |
什麼時候 Reddit Scraper GitHub Repo 不是答案:免程式路線
大多數 reddit scraper github 文章都假設你會 Python。但很多在找 Reddit scraping 解法的人,其實是行銷、業務、研究人員或獨立創業者,並不會每天寫 Python。對這群人來說,GitHub repo 會帶來一些隱形成本:
- 建立 OAuth 憑證與 Reddit 開發者 app
- 管理 Python virtual environment 與依賴衝突
- 當 PRAW 內部改動時,處理難懂的錯誤訊息
- 如果 Reddit 判定你的使用情境未獲核准,還得面對 API key 被撤銷
- Reddit 每次改動都要跟著維護腳本
這些都不是假設情境。 有 2,563 顆星與 107 個 open issue;最近的回報包括「Struggling to install」、「PRAW module error」與「Exception not allowing to even authenticate.」
如果符合以下情況,就用 GitHub Repo...
- 你需要客製化爬取邏輯(例如特定的留言樹遍歷、整合自訂 NLP 流程)。
- 你想整合到既有的 Python 資料管線中。
- 你需要以很高的規模抓取,並搭配自訂儲存(資料庫、data warehouse)。
- 你能舒適地維護程式碼並處理破壞性變更。
如果符合以下情況,就用免程式工具...
- 你需要快速拿到 Reddit 資料——是幾分鐘,不是花好幾小時設定。
- 你不想管理 API key、OAuth app 或 Python 環境。
- 你想直接匯出到試算表、Notion 或 Airtable,立即使用。
- 你希望 Reddit 版面改變時,工具能自動適應。
Thunderbit 正好站在免程式這一邊。使用者可以透過 AI 建議欄位,在 2 次點擊內 ,免費匯出到 CSV/Google Sheets/Airtable/Notion,並處理分頁,不用寫任何程式。它的瀏覽器型爬取代表不需要 OAuth 設定,也不需要 API key 註冊。
快速教學:用 Thunderbit 抓 Reddit(一步一步)
- 安裝 。
- 前往你要抓取的 Reddit 頁面(subreddit、搜尋結果、使用者檔案)。
- 點擊「AI 建議欄位」。 Thunderbit 會讀取頁面並建議欄位——貼文標題、作者、讚數、時間戳、URL 等。
- 需要的話調整欄位,然後點擊「抓取」。
- 檢視資料表。 你也可以點擊「抓取子頁面」,逐篇進入貼文抓留言或其他細節。
- 匯出 到你偏好的目的地:Google Sheets、Excel、Airtable、Notion、CSV 或 JSON。
兩分鐘。零程式碼。如果你想看實際操作,可以看看 。
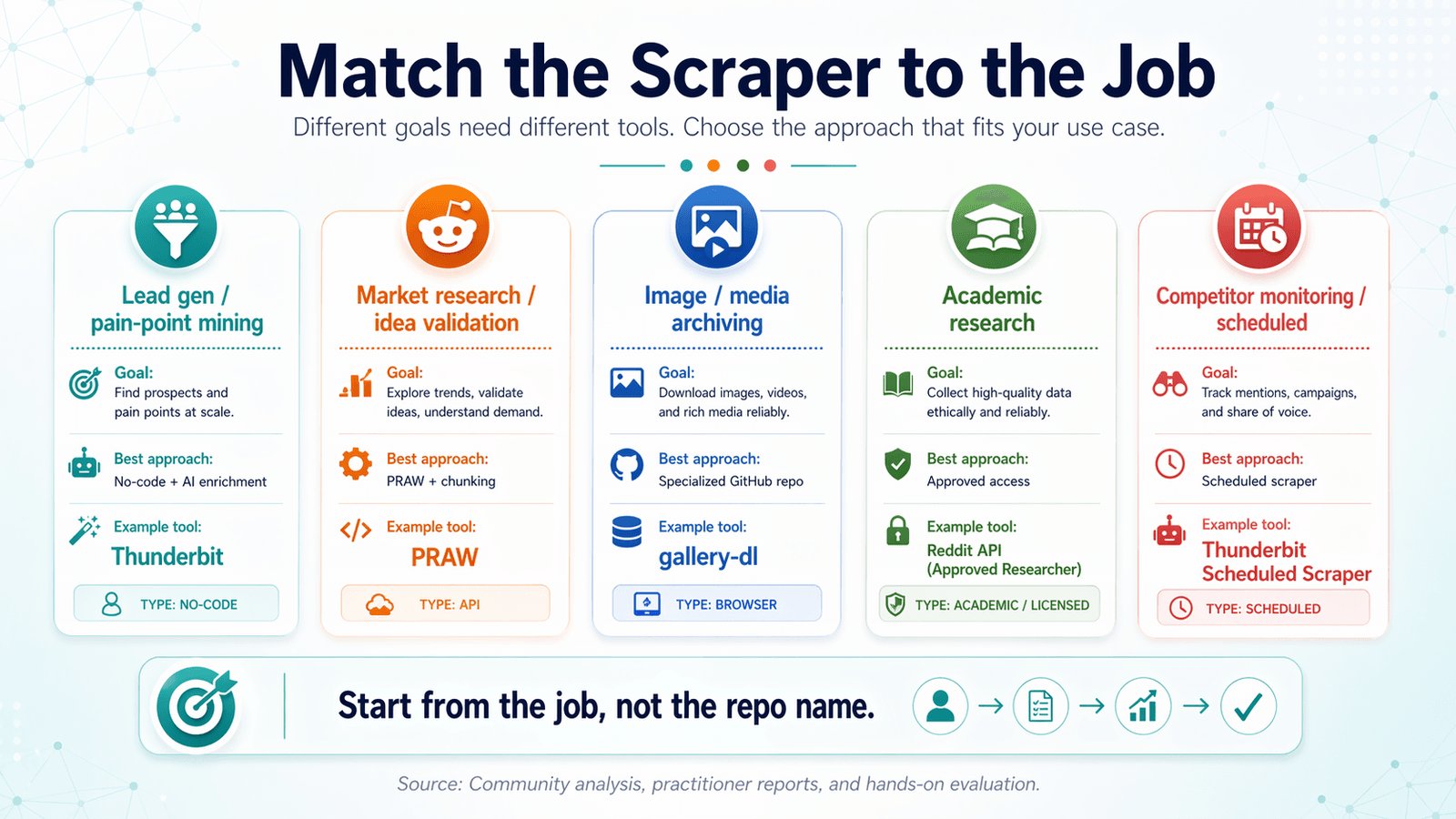
對準任務選對 Reddit Scraper:使用情境決策矩陣
大多數 reddit scraper github 文章都按工具分類,這其實本末倒置。
你應該先從目標出發,再往回推最適合的工具。
名單開發與痛點挖掘
你需要的是: 具關鍵字過濾的貼文 + 留言、AI 標記/分類,以及可匯出到 CRM 就緒格式。
最佳方法: 免程式爬蟲 + AI 增強。
推薦工具: (AI 標記 + 匯出到 Google Sheets/Airtable,方便匯入 CRM)。
範例流程: 抓取某個 subreddit 裡提到特定痛點的貼文。用 Thunderbit 的 Field AI Prompt 把情緒分類或主題標籤化。然後匯出到銷售團隊的 Airtable 或 Google Sheet。
市場研究與點子驗證
你需要的是: 大量貼文標題 + 分數、subreddit 層級趨勢資料。
最佳方法: 用 PRAW 搭配時間窗切分處理大量資料,或用 Thunderbit 做快速擷取。
範例: 抓取 r/SaaS 或 r/startups 在過去 90 天的熱門主題與 upvote 模式。
圖片與媒體歸檔
你需要的是: 媒體 URL、去重、定時執行。
最佳方法: 專門的 GitHub repo(例如 )加上 cron job。
注意: 這裡去重非常重要——同一張圖片在不同 subreddit 重複發佈很常見。
學術研究與歷史資料
你需要的是: 歷史資料、完整留言樹、大型資料集。
最佳方法: 核准的學術存取或授權資料路徑。Pushshift 已不再是通用解答。
現實檢查: 由於 Pushshift 的限制與 Reddit 收緊資料政策,這是 2026 年最難處理的使用情境。
競品監測與排程爬取
你需要的是: 固定間隔的重複抓取、變更偵測。
最佳方法: Thunderbit 的 (用自然語言描述時間間隔、輸入 URL、按下 Schedule)或,若是程式碼使用者,則用 cron + script。
使用情境決策矩陣表
| 使用情境 | 你需要什麼 | 最佳方法 | 範例工具 |
|---|---|---|---|
| 名單開發 / 痛點挖掘 | 貼文 + 留言、關鍵字過濾、AI 標記 | 免程式爬蟲 + AI 增強 | Thunderbit |
| 市場研究 / 點子驗證 | 大量貼文標題 + 分數、subreddit 層級資料 | PRAW + 時間窗切分,或 Thunderbit | PRAW 或 Thunderbit |
| 圖片 / 媒體歸檔 | 媒體 URL、去重、排程執行 | 專門 GitHub repo + cron | bulk-downloader-for-reddit |
| 學術研究 | 歷史資料、完整留言樹 | 核准的學術存取或 Playwright | Pushshift academic API(若可存取) |
| 競品監測 / 排程 | 重複抓取、變更偵測 | 排程爬蟲 | Thunderbit Scheduled Scraper 或 cron + script |
在你開始前,先評估任何 Reddit Scraper GitHub Repo
在你 clone 一個 repo 並開始除錯之前,先做這個 5 分鐘健康檢查,能省下你很多時間。
5 分鐘 Repo 健康檢查
- 最後提交日期。 如果超過 6 個月,請謹慎。Reddit 的 API 變動很頻繁。
- open issue 與 closed issue 比例。 未解 issue 很多是紅旗。檢查最近 issue 是否提到驗證失敗、403 或 Pushshift 中斷。
- LICENSE 檔案。 先看有沒有。沒有授權檔 = 法律狀態不明(下面會再談)。
- 依賴套件。 需要的函式庫是否已更新?是否用了已淘汰的套件?
requirements.txt裡全是 2022 年鎖版套件,是警訊。 - README 品質。 是否清楚說明安裝與設定?有沒有使用範例?文件差 = 你得花更多時間除錯。
- Stars、forks 與最近活動。 星星很多但近期活動很少,通常代表這專案曾經熱門、現在已被放生。把 stars 和
pushed_at日期一起看。
舉個例子: 有 364 顆星,乍看之下很可信。但這個 repo 已歸檔,而且 README 明確寫著「THIS REPOSITORY IS STALE。」
單看星星數,說明不了全貌。
讓你的 Reddit Scraper GitHub 設定發揮最大效益的技巧
如果你最後還是決定走程式碼路線,下面這些做法可以幫你少掉很多麻煩。
一定要使用虛擬環境
虛擬環境能把爬蟲的依賴隔離起來,避免跟其他 Python 專案互相衝突。只要一個指令:python -m venv venv,然後在安裝任何東西之前先啟用它。這是基本衛生,但我看過太多標題叫「module not found」的 GitHub issue,知道這件事值得再提醒一次。
安全儲存憑證
絕對不要把 Reddit API 的 client ID 或 secret 直接硬寫進腳本。請使用環境變數或 .env 檔,並把 .env 加進 .gitignore。如果你不小心把憑證推到 GitHub,請立刻更換——機器人會掃描外洩的 API key。
把一切都記錄下來
替 API 回應、rate-limit 標頭與錯誤加上 logging。當某件事壞掉時,log 就是「我完全知道發生了什麼」與「我完全不知道為什麼停了」之間的差別。
有計畫地排程與自動化
如果要定期抓取,請用 cron(Linux/Mac)或 Task Scheduler(Windows)——但要監控失敗情況。連續兩週默默失敗的 cron job,比完全不自動化還糟。
替代方案:Thunderbit 的 讓你用自然語言描述間隔,不需要寫 cron 語法。
Reddit Scraping 的法律與倫理最佳實踐
這不是可有可無的免責聲明。自 2023 年 API 變動以來,Reddit 就積極執行條款;而抓取個資也有真實的法律風險。
以下才是真正重要的部分。
Reddit 的服務條款:實際上寫了什麼?
Reddit 的 (修訂至 2026 年 3 月 31 日)明確禁止以自動化方式存取、搜尋或收集服務資料,除非條款或另行協議允許。 與 則補充更多細節:Reddit 可以監控與稽核開發者使用情形、變更或中止存取,並因過度或濫用而永久封鎖存取。商業用途通常需要明確核准。
2026 年 3 月的 又更進一步:透過 API 存取 Reddit 資料前必須先獲核准,未經核准的商業化與 AI / 資料探勘用途皆被禁止,而執法措施可包括撤銷 token、停用 app 或帳號,以及停用相關 bot 或網域。
robots.txt 合規性
Reddit 目前的 非常嚴格:
1User-agent: *
2Disallow: /這代表對所有自動化 user-agent 一律禁止。它也連結了 。這比一些開發者仍從舊式網頁爬取慣例裡假設的寬鬆 robots.txt 模式,嚴格得多。
最佳做法:即使你的工具沒有自動檢查,也要在爬取前先看 robots.txt。
個人資料與隱私(GDPR / CCPA)
如果你在抓取使用者名稱、貼文歷史或任何可識別個人身分的資訊,(歐盟)與 CCPA(加州)可能適用。最佳做法:在儲存前先把個資匿名化或彙總。不要在沒有合法依據的情況下,建立個別使用者的檔案。
GitHub Repo 授權:建構前先確認
許多 reddit scraper github repo 使用 MIT 或 Apache 授權(較寬鬆),但也有不少根本沒有 LICENSE 檔——法律上就等於「保留所有權利」。在 fork、修改或基於某個 repo 開發之前,一定先看 LICENSE 檔。沒有授權 = 法律狀態不明,不管它有多少星星都一樣。
2025–2026 年的執法是真實存在的
Reddit 的執法故事並沒有停在 2023 年。Reddit 在 2025 年對 Anthropic 提起訴訟,指控其未經授權抓取/使用 Reddit 內容,並在 2025 年底進一步處理 Reddit v. SerpApi。這些都顯示 Reddit 願意走法律執法,而不只是技術封鎖。
2026 年如何選對 Reddit Scraper GitHub 方法
自 2023 年以來,reddit scraper github 的生態已經大幅改變。大多數 repo 都過時了。速率限制與 1k 貼文上限是真限制。Pushshift 對一般使用者來說已經沒了。而 Reddit 的政策體系也比以往更明確、執行更嚴格。
簡短版本如下:
- PRAW 仍然是最可靠的開源基礎,前提是你能接受 Reddit API 限制,並想自行開發客製邏輯。
- Pushshift / PSAW 不再是通用解答。
- snscrape 的 Reddit 模組 已屬舊世代,而且不可靠。
- .json 與公開端點爬蟲 很脆弱,而且在 2026 年經常被封。
- 瀏覽器型工具——無論是 Playwright repo,或像 這類免程式方案——對很多使用者,尤其是非開發者,都是最實際的路線。
先從你的使用情境出發,而不是先看工具。在決定採用任何 GitHub 專案之前,先跑一次 5 分鐘 repo 健康檢查。
如果你寧可跳過設定,直接在幾分鐘內開始抓 Reddit,。
常見問題
2026 年 GitHub 上最好的開源 Reddit scraper 是哪些?
仍然是最可靠的 API 包裝器,維護活躍且文件完善。 則是建立在 PRAW 上、仍有維護的 CLI 工具,可信度也不錯。Playwright 型爬蟲適合非 API 抓取,而 snscrape 的 Reddit 模組則只有部分功能可用,且大多未維護。使用任何 repo 之前,都要先看最後提交日期與 open issue——GitHub 上 裡,大多都已經過時。
抓取 Reddit 合法嗎?
抓取公開可見資料處於法律灰色地帶,但 Reddit 自己的條款相當嚴格。、、、 和 都傾向反對未經授權的大量抓取。商業再散佈抓來的資料,可能需要 Reddit 明確授權。如果你在抓個資,GDPR 與 CCPA 也可能適用。
我怎麼突破 Reddit 的 API 速率限制?
請用指數退避、監看 X-Ratelimit-Remaining 標頭,並考慮用時間窗切分在限制內運作。瀏覽器型爬取(Playwright 或 )因為抓的是已渲染頁面,所以可繞過 API 速率限制,但也有自己的代價(頁面載入速度、反機器人措施)。沒有什麼魔法能完全移除速率限制——它們是伺服器端執行的。
我可以不用 API key 就抓 Reddit 嗎?
可以。Playwright 型爬蟲和 .json URL 技巧都不需要 API key。 也不需要 API key,因為它是透過瀏覽器抓取。代價是:.json 端點在許多環境中已越來越常被封鎖(截至 2026 年 4 月,很多環境會回傳 403),而且瀏覽器型抓取比 API 呼叫更慢、資源消耗更高。
Reddit 抓取的 Pushshift 發生了什麼事?
自 2023 年 Reddit 的資料授權變動開始後,Pushshift 的公開 API 存取就被移除了。 包裝器已經歸檔且過時。雖然可能仍有有限的學術存取管道,但對今天搜尋「reddit scraper github」的大多數使用者來說,Pushshift 已經不是可行方案。如果你需要深度歷史 Reddit 資料,請研究 Reddit 核准的學術或授權資料路徑。
延伸閱讀