
網路世界就像一座視覺叢林,每天都有數以億計的圖片被上傳,不管是電商商品照還是爆紅梗圖,圖片早已成為網路不可或缺的一部分。如果你做過銷售、行銷或研究,肯定體會過一張張手動下載圖片的痛苦。我以前也常常陷入「右鍵另存新檔」的無限輪迴,心裡想著:一定有更聰明的辦法吧?答案當然有!Python 圖片爬蟲還有像 這種無程式碼工具,已經徹底改變了大規模下載網站圖片的方式。
這篇文章會帶你一步步了解怎麼用 Python 抓網頁圖片、怎麼解決動態網站的難題,以及為什麼 Python 搭配 Thunderbit 可以讓你效率大爆發。不管你是要建立產品目錄、做競品分析,還是單純受夠了複製貼上的苦差事,這裡都有實用步驟、範例程式碼,還有一些輕鬆小撇步。
什麼是 Python 圖片爬蟲?
Python 圖片爬蟲就是一種自動化腳本或工具,能自動瀏覽網站、找到圖片檔案(像 <img> 標籤裡的圖片),然後批次下載到你的電腦。你不用再一張張慢慢存,Python 會自動幫你抓網頁、解析 HTML、批量存下所有圖片()。
誰會用 Python 圖片爬蟲?只要你需要大量圖片又想省時省力,這就是你的好幫手:
- 電商團隊:從供應商網站批次下載商品圖片,快速建立商品目錄。
- 行銷人員:蒐集社群媒體圖片,做活動或趨勢分析。
- 研究人員:建立 AI/機器學習訓練集或學術研究資料集。
- 房仲業者:彙整房產照片,方便刊登或市場分析。
你可以把 Python 圖片爬蟲想像成你的數位小幫手——不會喊累,也不會被貓咪梗圖分心。
為什麼用 Python 來抓取網頁圖片?
 Python 在網頁爬蟲界就像瑞士刀,圖片抓取當然也難不倒它,原因如下:
Python 在網頁爬蟲界就像瑞士刀,圖片抓取當然也難不倒它,原因如下:
- 函式庫超多:Requests、BeautifulSoup、Selenium 等工具,從靜態 HTML 到複雜的 JavaScript 網站都能搞定()。
- 新手也能上手:語法簡單,教學和社群資源超多。
- 彈性高又能擴充:可以抓單一頁面,也能自動爬數千頁,還能自動處理下載後的圖片。
- 省時又省錢:實測用 Python 抓 100 張圖片只要 12 分鐘,手動卻要 2 小時()。
常見商業應用場景如下:
| 應用場景 | 手動痛點 | Python 爬蟲優勢 |
|---|---|---|
| 商品目錄建立 | 複製貼上超花時間 | 幾分鐘內下載上千張圖片 |
| 競品分析 | 細節容易漏掉、效率低 | 批量比對圖片,快速掌握差異 |
| 趨勢研究 | 資料集不完整 | 快速蒐集大量多元圖片樣本 |
| AI/ML 訓練集建立 | 標註很麻煩 | 自動蒐集、準備訓練資料 |
| 房地產刊登 | 資料分散、更新慢 | 圖片集中管理,隨時更新 |
Python 圖片爬蟲必備工具
來看看 Python 圖片爬蟲常用的工具組合:
| 函式庫 | 功能說明 | 適用情境 | 優點 | 缺點 |
|---|---|---|---|---|
| Requests | 透過 HTTP 抓取網頁與圖片 | 靜態網站 | 簡單快速 | 無法解析 HTML、無 JS 支援 |
| BeautifulSoup | 解析 HTML,尋找 <img> 標籤 | 擷取圖片網址 | 易用、容錯高 | 不支援 JS |
| Scrapy | 全方位爬蟲/爬網框架 | 大型專案 | 非同步、內建匯出 | 學習曲線較高 |
| Selenium | 自動化瀏覽器(支援 JS、滾動等互動) | 動態/JS 網站 | 可渲染 JS、模擬用戶操作 | 速度較慢、需額外設定 |
| Pillow (PIL) | 處理下載後的圖片 | 圖片驗證/編輯 | 可調整大小、格式轉換、檢查圖片 | 本身不負責爬取 |
什麼時候該用哪個?
- 靜態網站:
requests + BeautifulSoup是基本組合。 - 動態網站(無限滾動、JS 圖片庫):
Selenium最好用。 - 大型、重複性高的專案:
Scrapy結構化又高效。 - 圖片後處理:
Pillow幫你整理下載好的圖片。
實作教學:用 Python 批量下載網站圖片
來實際操作看看,以下是用 Python 從靜態網站下載圖片的步驟:
建立 Python 執行環境
先確認你有安裝 Python 3。建議用虛擬環境:
1python3 -m venv venv
2source venv/bin/activate # Windows 用 venv\Scripts\activate安裝需要的函式庫:
1pip install requests beautifulsoup4擷取圖片網址
在瀏覽器打開目標網站,右鍵「檢查」找到 <img> 標籤。
以下是擷取圖片網址的範例程式:
1import requests
2from bs4 import BeautifulSoup
3from urllib.parse import urljoin
4import os
5url = "https://example.com"
6response = requests.get(url)
7soup = BeautifulSoup(response.text, "html.parser")
8img_tags = soup.find_all("img")
9img_urls = [urljoin(url, img.get("src")) for img in img_tags if img.get("src")]小提醒: 有些網站會用 data-src 或 srcset 來做延遲加載,記得也要檢查。
下載並儲存圖片
把圖片存到資料夾:
1os.makedirs("images", exist_ok=True)
2for i, img_url in enumerate(img_urls):
3 try:
4 img_resp = requests.get(img_url, headers={"User-Agent": "Mozilla/5.0"})
5 if img_resp.status_code == 200:
6 file_ext = img_url.split('.')[-1].split('?')[0]
7 file_name = f"images/img_{i}.{file_ext}"
8 with open(file_name, "wb") as f:
9 f.write(img_resp.content)
10 print(f"Downloaded {file_name}")
11 except Exception as e:
12 print(f"Failed to download {img_url}: {e}")整理建議:
- 檔名可以用產品編號或頁面標題。
- 不同類別或來源可以用子資料夾分類。
- 儲存前記得檢查重複(比對網址或用 hash)。
常見錯誤與排解
- 圖片沒抓到? 可能是 JS 動態載入,請看下一節。
- 被擋下請求? 設定 User-Agent,下載時加上
time.sleep()。 - 重複下載? 用 set 記錄已下載網址或檔名。
- 權限錯誤? 確認腳本有寫入資料夾的權限。
抓取動態或 JavaScript 網頁的圖片
有些網站會用 JS、無限滾動或「載入更多」按鈕來隱藏圖片,這時就要用 Selenium。
用 Selenium 處理動態內容
先安裝 Selenium 和瀏覽器驅動(像 ChromeDriver):
1pip install selenium下載 ,並加入 PATH。
Selenium 基本範例:
1from selenium import webdriver
2from selenium.webdriver.common.by import By
3import time
4import os
5driver = webdriver.Chrome()
6driver.get("https://example.com/gallery")
7# 滾動到底部載入更多圖片
8last_height = driver.execute_script("return document.body.scrollHeight")
9while True:
10 driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
11 time.sleep(2) # 等待圖片載入
12 new_height = driver.execute_script("return document.body.scrollHeight")
13 if new_height == last_height:
14 break
15 last_height = new_height
16img_elements = driver.find_elements(By.TAG_NAME, "img")
17img_urls = [img.get_attribute("src") for img in img_elements if img.get_attribute("src")]
18os.makedirs("dynamic_images", exist_ok=True)
19for i, img_url in enumerate(img_urls):
20 # (下載邏輯同前)
21 pass
22driver.quit()進階技巧:
- 用
WebDriverWait等待圖片出現。 - 需要點擊才能顯示圖片時,用
element.click()。
其他選擇: Playwright(Python 版)對複雜網站更快更穩定()。
無程式碼方案:用 Thunderbit 抓取網站圖片
不是每個人都想寫程式或安裝驅動,這時 就超好用——這款無程式碼、AI 驅動的網頁爬蟲 Chrome 擴充功能,讓圖片擷取就像點外送一樣簡單。
Thunderbit 圖片擷取步驟
- 安裝 Thunderbit:下載 。
- 打開目標網站:進入你想抓取圖片的頁面。
- 啟動 Thunderbit:點擊擴充功能圖示,開啟側邊欄。
- AI 智能欄位建議:點選「AI Suggest Fields」,Thunderbit 會自動偵測頁面圖片,幫你建立「圖片」欄位()。
- 開始爬取:按下「Scrape」,Thunderbit 會自動收集所有圖片,連子頁面和無限滾動都能搞定。
- 匯出:可將圖片網址或檔案直接匯出到 Excel、Google Sheets、Notion、Airtable 或 CSV——即使免費方案也沒限制。
加碼功能: Thunderbit 免費圖片提取器,一鍵就能抓取頁面上所有圖片網址()。
Thunderbit 優勢:
- 完全不需要寫程式或懂 HTML。
- 自動處理動態內容、子頁面、分頁。
- 匯出即時又無限制(免費方案也適用)。
- AI 會自動適應網站變動,免維護煩惱。
Python + Thunderbit:雙劍合璧的最佳解
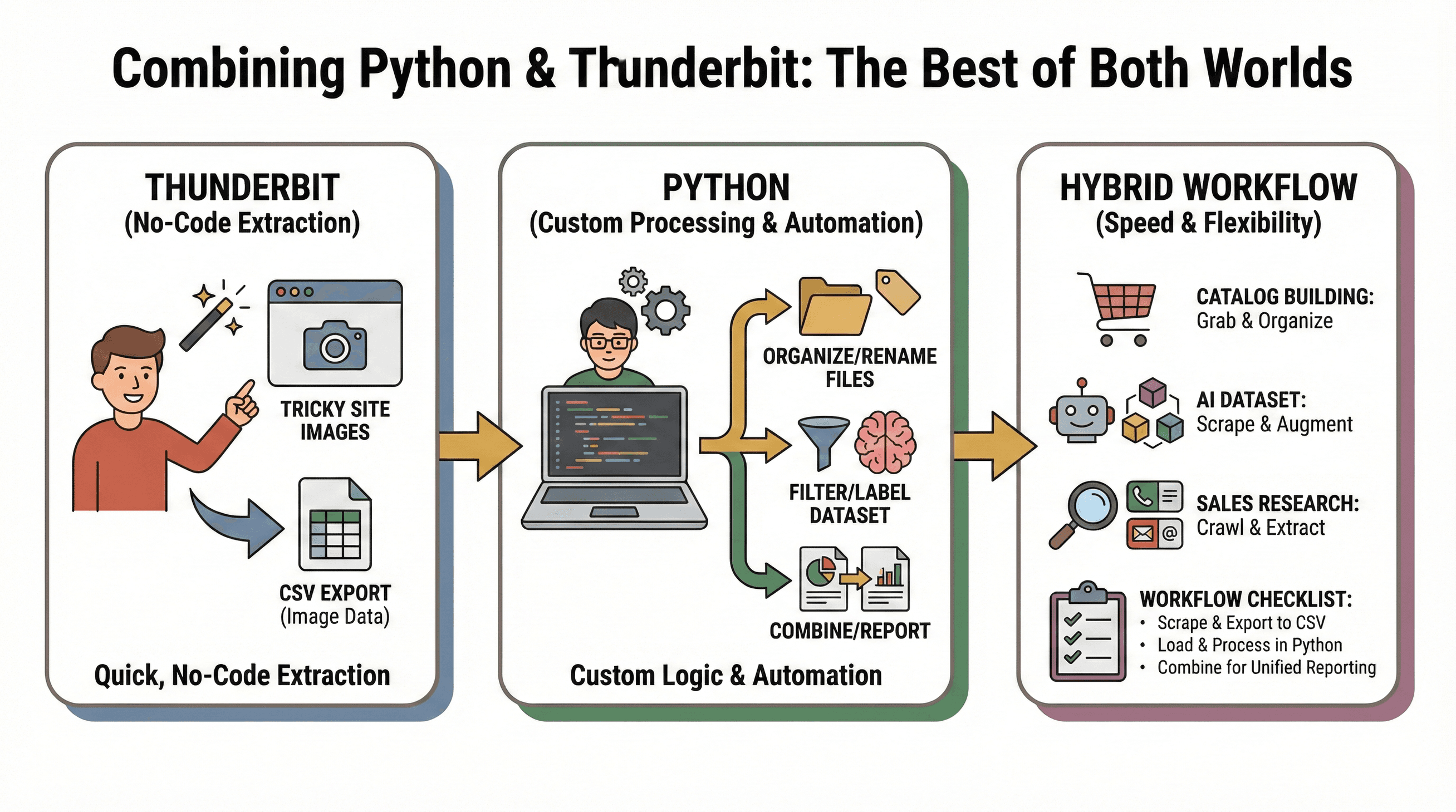 我最愛的工作流程:用 Thunderbit 快速無程式碼擷取圖片,再用 Python 進行自訂處理或自動化。
我最愛的工作流程:用 Thunderbit 快速無程式碼擷取圖片,再用 Python 進行自訂處理或自動化。
應用範例:
- 商品目錄建立:Thunderbit 先抓下難搞網站的圖片,Python 再分類、重新命名或批次處理。
- AI 訓練集建立:Thunderbit 從多個來源抓圖,Python 腳本再篩選、標註或增強資料集。
- 銷售研究:Python 爬取公司網址清單,Thunderbit 擷取每個網站的圖片、信箱或電話。
混合流程檢查表:
- 用 Thunderbit 擷取圖片並匯出 CSV。
- 在 Python 中載入 CSV,進行進一步分析或自動化。
- 整合多來源資料,產出統一報表。
這種混合方式又快又彈性,幾乎能解決所有網頁圖片抓取需求。
Python 圖片爬蟲常見問題與最佳實踐
常見問題:
- 被擋下請求:加上 User-Agent 標頭、適當延遲,並遵守
robots.txt。 - 圖片沒抓到:遇到 JS 載入內容時,改用 Selenium 或 Thunderbit。
- 重複下載:追蹤已下載網址或用檔案 hash。
- 檔案損壞:下載後用 Pillow 驗證圖片。
最佳實踐:
- 依網站、類別或日期建立清楚的資料夾結構。
- 檔名盡量具描述性(如產品編號、頁面標題)。
- 過濾不相關圖片(如廣告、icon),可用檔案大小或尺寸判斷。
- 抓取前務必檢查版權與網站服務條款()。
Python 圖片爬蟲方案比較:寫程式 vs. 無程式碼
來看看各種方案的優缺點對比:
| 比較項目 | Python (Requests/BS) | Selenium (Python) | Thunderbit (無程式碼) |
|---|---|---|---|
| 易用性 | 中等(需寫程式) | 較難(程式+瀏覽器自動化) | 非常簡單(點選、AI 自動) |
| 動態內容支援 | 不支援 | 支援 | 支援 |
| 設定時間 | 較長(安裝、寫程式) | 長(驅動、寫程式) | 極短(安裝擴充功能) |
| 擴展性 | 手動(可多執行緒) | 慢(瀏覽器負擔大) | 高(雲端爬取、一次 50 頁) |
| 維護成本 | 高(網站變動易壞) | 高 | 低(AI 自動適應) |
| 匯出選項 | 自訂(CSV、資料庫) | 自訂 | 一鍵匯出 Excel、Sheets、Notion 等 |
| 成本 | 免費(開源) | 免費 | 免費方案,量大需付費 |
總結: 喜歡寫程式、追求高度自訂就選 Python;想要快速、簡單、支援動態網站,Thunderbit 是救星。多數團隊結合兩者效果最佳。
結論與重點整理
網路圖片爆炸成長,圖片資料越來越有價值,也越來越難整理。Python 圖片爬蟲讓你自動化下載、彈性處理,無程式碼工具如 Thunderbit 則讓圖片抓取人人都能上手。
重點整理:
- 靜態網站、客製流程:用 Python(Requests + BeautifulSoup)。
- 動態、JS 網站:用 Selenium。
- 快速、無程式碼擷取:Thunderbit 最方便,尤其適合匯出到 Excel、Google Sheets、Notion。
- 混合運用最強:Thunderbit 負責資料蒐集,Python 處理與自動化。
想提升圖片抓取效率?不妨寫個簡單 Python 腳本,或 試試,看看能省下多少時間。更多技巧與深入教學,歡迎參考 和 。
祝你爬圖順利,資料夾永遠井然有序!
常見問答
1. 什麼是 Python 圖片爬蟲?
Python 圖片爬蟲是一種自動化腳本或工具,能自動瀏覽網站、尋找圖片檔案(通常在 <img> 標籤),並下載到你的電腦,省去一張張手動存檔的麻煩。
2. 哪些 Python 函式庫最適合抓取網頁圖片?
最常用的有 Requests(抓取網頁)、BeautifulSoup(解析 HTML)、Selenium(處理動態內容)、Pillow(下載後圖片處理)。
3. 如何抓取 JavaScript 或無限滾動網站的圖片?
用 Selenium 自動操作瀏覽器,滾動頁面,等所有內容載入後再擷取圖片網址。Thunderbit 也能靠 AI 自動處理動態內容。
4. 有無程式碼方式抓取網站圖片嗎?
有!Thunderbit 是無程式碼 Chrome 擴充功能,利用 AI 自動偵測並擷取網站圖片,只要點選即可匯出到 Excel、Google Sheets、Notion 或 Airtable。
5. 可以結合 Python 和 Thunderbit 一起用嗎?
當然可以。Thunderbit 快速無程式碼擷取,Python 負責進階處理或自動化。從 Thunderbit 匯出資料後,用 Python 腳本進一步處理,兩者優勢兼得。
延伸閱讀