

網頁爬蟲早就不是工程師專屬的技能,如今對銷售、營運、市場研究人員來說,它幾乎成了一項人人該會的本事。網路上的資料量正在爆炸式膨脹——全球資料產量從 2019 到 2023 年間幾乎暴增了 193%——也難怪有 81% 的公司 現在都把資料當成決策的「核心」。但問題同樣明顯:有 95% 的組織 坦言,處理像雜亂 HTML 這種非結構化資料,是一大頭痛。我看過太多團隊困在一場又一場的複製貼上馬拉松裡,只為了把網站上的資訊搬進試算表——那畫面真的不太好看。
用 AI 從任何網站擷取資料 Get Started Free
這時候,Python 的 BeautifulSoup 就該登場了。這篇教學走的是實作路線,我會帶你一步步把 BeautifulSoup 用來做網頁爬蟲,並附上一個你可以直接搬去套用到自家業務的 Python Beautiful Soup 範例。而且我向來覺得與其埋頭硬做,不如把工具用巧,所以也會示範怎麼把 BeautifulSoup 和 Thunderbit——我們家的 AI 網頁爬蟲——搭在一起,讓你的流程更快、拿到的資料更乾淨、結構更整齊;不論你的程式底子如何,都能輕鬆跟上。
BeautifulSoup 是什麼?為什麼拿它做網頁爬蟲?
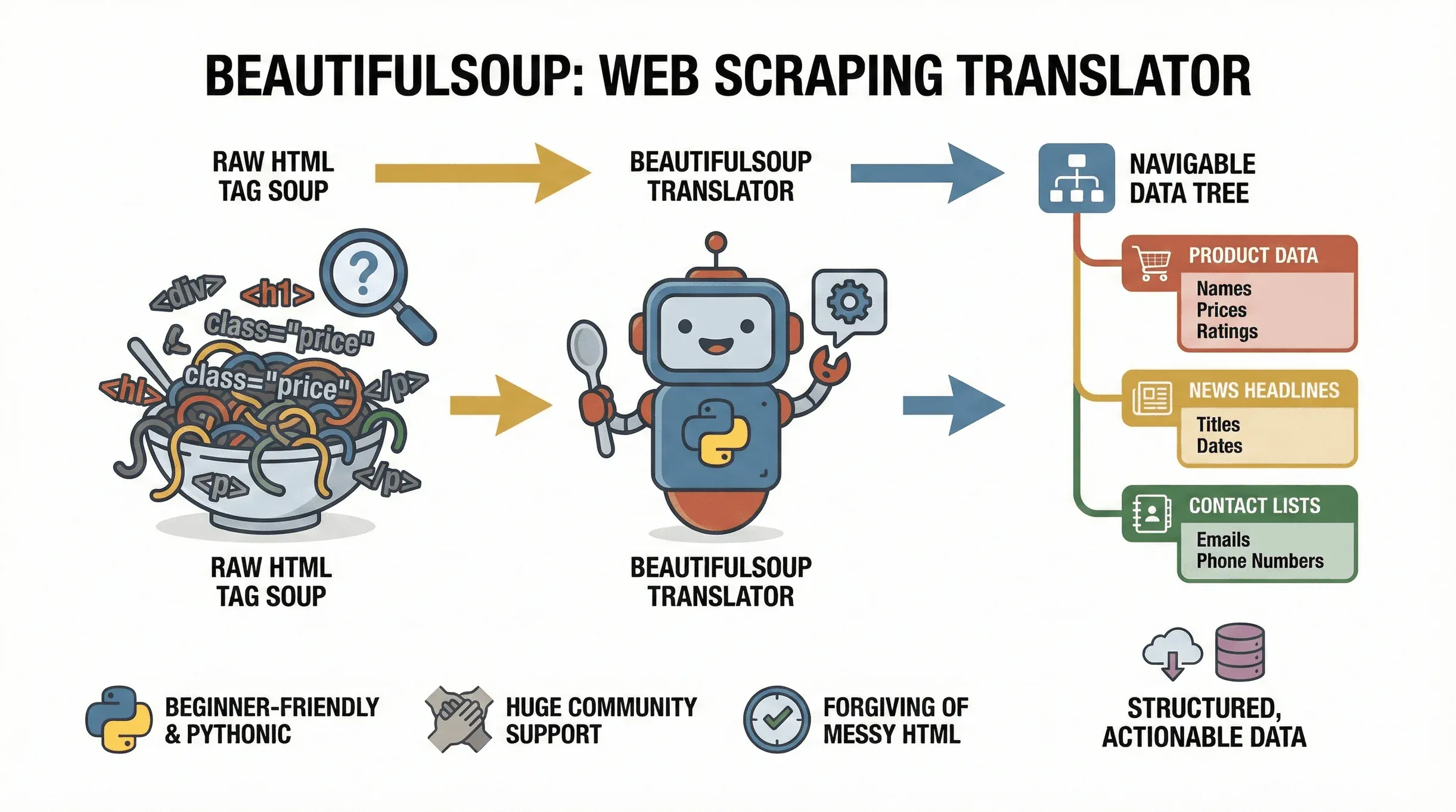 先從最基礎的講起。BeautifulSoup 是一個 Python 函式庫,專門讓你輕鬆解析 HTML 與 XML 文件。你可以把它當成一台翻譯機:它會把網頁上那一團「標籤大雜燴」整理成一棵可以走來走去的樹狀結構,讓你輕鬆找到、抓出並操作想要的資料。這個專案到現在都還在持續維護——
先從最基礎的講起。BeautifulSoup 是一個 Python 函式庫,專門讓你輕鬆解析 HTML 與 XML 文件。你可以把它當成一台翻譯機:它會把網頁上那一團「標籤大雜燴」整理成一棵可以走來走去的樹狀結構,讓你輕鬆找到、抓出並操作想要的資料。這個專案到現在都還在持續維護——beautifulsoup4 4.14.3 也已經在 2025 年底登上 PyPI——所以你在這裡學到的東西都相當新。不管你想抓電商網站的商品價格、蒐集新聞標題,還是從商業名錄網站擷取名單線索,BeautifulSoup 都是把網頁變成結構化、可執行資料的首選工具。
它為什麼這麼受歡迎?第一,對初學者非常友善。BeautifulSoup 對雜亂的 HTML 很包容(網路上這種東西多到數不清),再加上一套 Python 風格的語法,幾行程式就能從零開始做出一支爬蟲。它的支援度也很廣,下載量大、社群熱絡——所以一旦卡住,通常 Google 一下就能找到解法。
BeautifulSoup 常見的用途有:
- 從電商頁面抓商品名稱、價格與評分
- 從新聞網站抓標題、作者與發布日期
- 解析表格或名錄(例如公司或聯絡人清單)
- 從列表網站蒐集電子郵件或電話號碼
- 追蹤更新(例如價格變動、新職缺等)
只要你的資料藏在靜態 HTML 裡,BeautifulSoup 就是你做網頁爬蟲時最靠得住的搭檔。
BeautifulSoup 做網頁爬蟲的獨到之處
Python 的網頁爬蟲函式庫一大堆——那憑什麼挑 BeautifulSoup?跟其他工具比起來,它的優勢在這幾點:
- 簡單好學: BeautifulSoup 輕量、容易上手。你不必架一整套框架,也不用寫一堆樣板程式。它特別適合快速、一次性的爬取任務,或剛入門的初學者。
- 容錯性高: 就算碰到破損或格式亂七八糟的 HTML 它也能應付,而這種情況其實比你想的還常見。
- 彈性高: 你不會被綁進某種僵硬的爬取架構。把 HTML 餵給它,再撈出你要的資料,就這麼簡單。
- 整合性佳: BeautifulSoup 跟其他 Python 函式庫處得很好,像
requests(抓網頁)、csv(存資料)和pandas(分析資料)都能順順搭配。
那它跟其他工具放在一起,到底怎麼比?
| 工具 | 最適合 | 優點 | 缺點 |
|---|---|---|---|
| BeautifulSoup | 靜態 HTML 解析、初學者 | 簡單、設定快、容錯高、彈性好 | 不適合 JavaScript 很重的網站 |
| Scrapy | 大規模、非同步任務 | 功能強大、可擴充、內建爬取架構 | 學習曲線較陡、設定較多 |
| Selenium | JavaScript/動態內容 | 可與 JS 互動、填表、點按鈕 | 較慢、較重、資源耗用較高 |
如果你才剛起步,或只是要快速解析靜態頁面,BeautifulSoup 簡單又百搭,幾乎什麼場面都應付得來 (medium.com)。碰到更複雜或動態的網站,可以再把它跟 Selenium 或 Scrapy 配著用——但要先把基本功練好,BeautifulSoup 絕對是最好的起點。
幫 BeautifulSoup 把 Python 環境準備好
環境設定的步驟如下:
-
安裝 Python: 到 python.org 下載最新版。
-
建立虛擬環境(可選,但建議做):
python -m venv venv source venv/bin/activate # Windows 上:venv\Scripts\activate -
安裝 BeautifulSoup 與相依套件:
pip install beautifulsoup4 requests lxml html5libbeautifulsoup4:主要函式庫requests:用來抓取網頁lxml或html5lib:更快/更可靠的 HTML 解析器
-
除錯小技巧:
- 如果跳出「找不到 pip」的錯誤,試試
pip3或py -m pip。 - 在 Mac/Linux 上,你可能需要
sudo權限。 - 如果你用的是 Windows,記得確認 Python 已經加進你的 PATH。
- 如果跳出「找不到 pip」的錯誤,試試
想確認設定有沒有弄好,跑這段快速測試就知道:
from bs4 import BeautifulSoup
import requests
html = requests.get("http://example.com").text
soup = BeautifulSoup(html, "html.parser")
print(soup.title)
只要你看到 <title>Example Domain</title>,就代表一切就緒 (Thunderbit Blog)。
Python Beautiful Soup 範例:一步一步帶你做
下面示範一個貼近真實情境的 python beautiful soup 範例。假設你想從公開新聞網站抓出最新標題,做法是這樣:
1. 取得網頁
import requests
from bs4 import BeautifulSoup
url = "https://www.bbc.com/news"
response = requests.get(url)
html = response.text
2. 解析 HTML
soup = BeautifulSoup(html, "html.parser")
3. 檢視 HTML 結構
打開瀏覽器的開發者工具(按右鍵 → 檢視),找出包著標題的標籤。很多新聞網站會把標題放在帶有特定 class 的 <h3> 標籤裡。
舉例來說,你可能會看到:
<h3 class="gs-c-promo-heading__title">Headline Title</h3>
4. 擷取資料
headlines = soup.find_all("h3", class_="gs-c-promo-heading__title")
for h in headlines:
print(h.get_text(strip=True))
這會把頁面上所有的新聞標題印出來。
5. 把資料存成 CSV
接著把這些標題存下來,方便日後分析:
import csv
with open("headlines.csv", "w", newline='', encoding="utf-8") as file:
writer = csv.writer(file)
writer.writerow(["headline"])
for h in headlines:
writer.writerow([h.get_text(strip=True)])
這樣你就拿到一份可以直接丟進 Excel 或 Google Sheets 的 CSV 檔。
讀懂 HTML 結構,擷取才會準
在動手寫程式之前,先把頁面的 HTML 看清楚。方法如下:
- 打開開發者工具: 在頁面上按右鍵,選「檢視」。
- 找出你要的資料: 把滑鼠移到元素上,看看哪個標籤包著你要的資訊(例如標題、價格、作者)。
- 記下標籤與 class: 留意像
class="product-title"或id="main-content"這類有辨識度的識別碼。 - 測試你的選擇器: 用 BeautifulSoup 的
.find()、.find_all()或.select()方法鎖定那些元素。
小撇步:可以用 soup.prettify() 在 Python 主控台印出比較好讀的 HTML 版本。
用 BeautifulSoup 擷取並整理資料
假設你想從部落格頁面抓出標題與作者:
articles = soup.find_all("article")
data = []
for article in articles:
title = article.find("h2").get_text(strip=True)
author = article.find("span", class_="author").get_text(strip=True)
data.append({"title": title, "author": author})
現在你手上就有一份字典清單——拿去匯出成 CSV 或進一步分析都很合適。
連結、圖片或任何屬性也能照樣抓,像這樣:
for link in soup.find_all("a"):
print(link.get("href"))
圖片同理:
for img in soup.find_all("img"):
print(img.get("src"))
把擷取到的資料存起來:從 Python 到 Excel 或 CSV
資料整理好之後,輸出其實很輕鬆。下面示範怎麼用 csv 模組搞定:
import csv
with open("articles.csv", "w", newline='', encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=["title", "author"])
writer.writeheader()
for row in data:
writer.writerow(row)
如果你比較習慣 pandas,也可以這樣做:
import pandas as pd
df = pd.DataFrame(data)
df.to_csv("articles.csv", index=False)
df.to_excel("articles.xlsx", index=False)
記得一律用 UTF-8 編碼,免得跑出奇怪的亂碼,處理跨國資料時尤其要注意。
實戰案例:用 BeautifulSoup 爬新聞網站
我們來實際走一遍 python beautiful soup 範例:從新聞網站抓出文章標題、作者與發布日期。
假設你想從 CNN 抓文章資料:
import requests
from bs4 import BeautifulSoup
import csv
url = "https://edition.cnn.com/world"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
articles = soup.find_all("article")
data = []
for article in articles:
title_tag = article.find("h3")
date_tag = article.find("span", class_="date")
author_tag = article.find("span", class_="author")
title = title_tag.get_text(strip=True) if title_tag else ""
date = date_tag.get_text(strip=True) if date_tag else ""
author = author_tag.get_text(strip=True) if author_tag else ""
data.append({"title": title, "date": date, "author": author})
with open("cnn_articles.csv", "w", newline='', encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=["title", "date", "author"])
writer.writeheader()
for row in data:
writer.writerow(row)
這段程式會抓出最新文章,撈出標題、日期和作者,再存成 CSV——前提是 CNN 現在的標記結構還跟上面一樣。大型新聞網站常常換 class 名稱跟 DOM 結構,所以正式跑資料前,記得先回頭把頁面重新檢查一次。真正穩定的是結構模式(例如用 <article> 當容器,再對子標籤呼叫 find);至於 "date"、"author" 這些 class 名稱只是示意,實際還是要照當下頁面的內容去調整。
進階工作流程:BeautifulSoup 加上 Thunderbit
接著談談怎麼讓你的爬蟲流程更順。Thunderbit 是一款 AI 驅動的網頁爬蟲 Chrome 擴充功能,能幫你把擷取資料時的猜測通通省掉。用 Thunderbit,你可以:
- 使用「AI 建議欄位」: Thunderbit 會讀過頁面,自動建議該擷取哪些欄位——不必再翻 HTML 或調選擇器。
- 爬取子頁面: Thunderbit 能順著連結進到子頁(例如單一商品頁或文章頁),補上更多細節,讓資料集更完整。
- 立即匯出: 一鍵把資料直接送進 Excel、Google Sheets、Airtable 或 Notion。
- 處理分頁: Thunderbit 能跨多個頁面爬資料,連無限捲動也能應付。
- 排程爬取: 設定定期任務,讓資料隨時保持最新。
這是我很喜歡的一種混合工作流程:
- 先用 Thunderbit: 打開目標網站,點一下 Thunderbit 圖示,讓「AI 建議欄位」幫你認出正確的欄位(例如標題、作者、日期)。
- 匯出資料: 下載成 CSV,或直接送進 Google Sheets。
- 再用 BeautifulSoup 做客製處理: 如果你需要更深入的分析(例如清理文字、去重,或跟其他資料來源合併),就把匯出的 CSV 載進 Python,用 BeautifulSoup 或 pandas 做後處理。
這個組合讓你兩邊的好處都拿到:Thunderbit 的速度與 AI 欄位偵測,再加上 BeautifulSoup 處理客製邏輯的彈性。
速度與資料品質:為什麼 Thunderbit 要搭 BeautifulSoup?
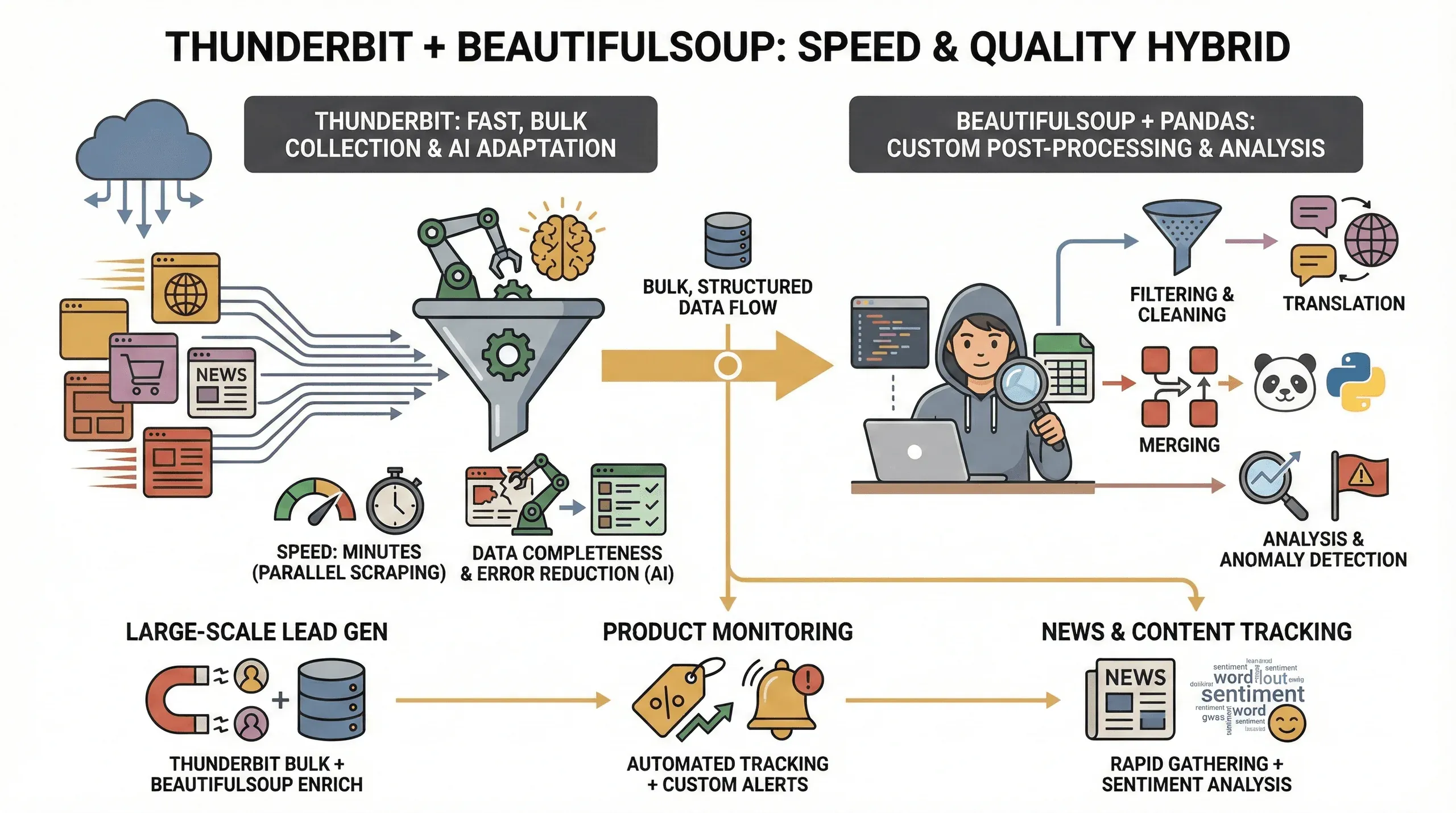 為什麼要兩個工具一起上?這是我的觀察:
為什麼要兩個工具一起上?這是我的觀察:
- 速度: Thunderbit 能平行爬取數十個頁面(雲端模式下最多同時 50 個),讓你幾分鐘就拿到資料,而不是耗上好幾個小時。
- 資料完整性: Thunderbit 的 AI 能跟著版面變動調整,連難搞的網站也能撈出結構化資料,大幅降低欄位漏掉的機率。
- 減少錯誤: class 名稱一改就掛掉的腳本,不再是你的煩惱——Thunderbit 的 AI 每次都會重新評估頁面。
- 客製後處理: 如果你有進階需求(例如篩選、翻譯,或合併資料集),BeautifulSoup 和 pandas 能讓你完全掌控整個流程。
這種混合做法特別適合:
- 大規模名單開發: 先用 Thunderbit 抓回大量資料,再用 BeautifulSoup 清理、補強。
- 商品監控: 重複性的爬取交給 Thunderbit,BeautifulSoup 則負責分析趨勢或標出異常。
- 新聞與內容追蹤: 先用 Thunderbit 快速蒐集文章,再用 Python 做情緒分析或關鍵字擷取。
BeautifulSoup 網頁爬蟲常見問題排除
試用 Thunderbit Chrome 擴充功能 用 AI 在 2 次點擊內爬取任何網站。 Get Started Free
網頁爬蟲不見得一路順遂——以下是幾個常踩的坑,以及對應的解法:
- 動態內容: 如果網站是靠 JavaScript 載入資料(無限捲動、AJAX),BeautifulSoup 單槍匹馬是看不到的。這種情況請改用 Selenium 或 Thunderbit 的瀏覽器模式。
- 反機器人機制: 有些網站會擋掉自動請求。你可以試著設定自訂的 User-Agent 標頭、在請求之間加上延遲,或用 Thunderbit 的雲端爬取繞過簡單的封鎖。
- HTML 結構變更: 如果你的程式突然掛了,很可能是網站的 HTML 改了。請重新檢查頁面、更新選擇器。Thunderbit 的 AI 在這方面也能即時幫你跟上。
- 資料缺失: 呼叫
.get_text()之前,先確認元素存不存在。取屬性值盡量用.get()取代[],避免 KeyError。 - 編碼問題: 存檔時用 UTF-8 編碼,特殊字元才不會出包。
另外,請務必尊重 robots.txt 和網站的服務條款,爬取時守規矩、留餘地,才不會造成對方網站的困擾。
結論與重點整理
在什麼都講資料的年代,學會用 BeautifulSoup 做網頁爬蟲是一項很划算的投資。這篇 beautifulsoup 網頁爬蟲教學的重點整理如下:
- BeautifulSoup 是解析靜態 HTML、再用 Python 擷取結構化資料的理想起點。
- 環境設定 很簡單——裝好 Python、pip 和幾個函式庫就行。
- 檢視 HTML 是鎖定正確資料的關鍵。
- 匯出成 CSV/Excel,資料立刻就能用於商業分析。
- 搭配 Thunderbit 能帶來 AI 欄位偵測、更快的爬取速度與更省事的匯出——非常適合商務使用者與非程式人員。
- 混合工作流程(Thunderbit 負責大量擷取,BeautifulSoup 負責客製處理)能同時兼顧速度、資料品質與彈性。
想把網頁爬蟲功力再往上推一層,建議兩個工具都試試:先用簡單的 BeautifulSoup 腳本練手,再看看 Thunderbit 的 AI 網頁爬蟲 能讓你快上多少。想看更多實作指南,也可以到 Thunderbit Blog 逛逛。
把這些方法用熟,乾淨、結構清楚、隨時能用的資料就會變成日常。
試用 Thunderbit AI 網頁爬蟲 Get Started Free
常見問題
1. 什麼是 BeautifulSoup?它用來做什麼?
BeautifulSoup 是一個用來解析 HTML 與 XML 文件的 Python 函式庫。它能幫你從網頁中抓出資料,整理成清單或表格這類結構化格式,非常適合用在網頁爬蟲專案上。
2. BeautifulSoup 跟 Selenium、Scrapy 有什麼差別?
BeautifulSoup 輕量、好上手,適合處理靜態 HTML 頁面。Selenium 比較適合爬取動態、JavaScript 很多的網站,Scrapy 則是功能完整的框架,適合大規模、非同步的爬取。對初學者與快速任務而言,BeautifulSoup 是最好的選擇。
3. 可以把 BeautifulSoup 和 Thunderbit 一起用嗎?
當然可以。Thunderbit 能用 AI 快速認出並擷取網頁欄位,你再用 BeautifulSoup 對匯出的資料做客製後處理或更深入的分析。
4. 用 BeautifulSoup 做網頁爬蟲時,常會遇到哪些挑戰?
常見的有處理動態內容、應付反機器人機制,還有跟上 HTML 結構的變動。善用 Thunderbit 的 AI 功能或瀏覽器模式,能幫你解掉不少這類麻煩。
5. 怎麼把 BeautifulSoup 抓到的資料匯出成 Excel 或 CSV?
你可以用 Python 內建的 csv 模組,或 pandas 函式庫,把抓到的資料寫進 CSV 或 Excel 檔。記得一律用 UTF-8 編碼,才能正確處理特殊字元,也才跟試算表工具相容。
想自己動手試試嗎?下載 Thunderbit 的 Chrome 擴充功能,今天就開始更聰明地爬資料。想看更多教學與技巧,歡迎逛逛 Thunderbit Blog。
延伸閱讀




