

網路上到處都是要填的表單、要盯的儀表板,還有一堆等著整理的數據。如果你跟我一樣,肯定也曾經心裡嘀咕:「難道每次都要這樣一頁頁慢慢點嗎?」放心,你絕對不是唯一這樣想的人。2024 年,Python 正式超車 JavaScript,成為 GitHub 上最夯的語言,將近四分之一的 Python 開發者都在用它搞自動化和網頁爬蟲(GitHub Octoverse、JetBrains Survey)。為什麼會這樣?因為 Python 讓網站自動化不只是做得到,還超級實用,甚至連不是工程師的人也能輕鬆上手。
這篇教學會帶你一步步學會 python 自動化網站操作的精髓。我會說明為什麼 Python 是首選、怎麼打造你的自動化工具箱、用 Selenium 自動填表和瀏覽網站的實戰技巧,還有像 Thunderbit 這種 AI 工具怎麼讓自動化變得更強大。不管你是對重複工作感到厭煩的上班族,還是想優化流程的開發者,都能在這裡找到實用步驟、程式碼範例,還有我自己踩過的坑。
為什麼用 Python 來自動化網站操作?
使用 AI 從任何網站抓取數據 Get Started Free
先來說重點:為什麼大家都愛用 Python?以我和多數開發者的經驗來說,Python 就像自動化界的瑞士刀,萬用又好上手,原因如下:
- 語法超直白: Python 的語法很親民,初學者也能看懂、改腳本,不用像在解密古文一樣(Monterail)。
- 生態系超豐富: Python 有一堆自動化相關的函式庫,最常用的三大法寶:
- Selenium: 模擬真實用戶在瀏覽器裡的所有操作,像點擊、輸入、瀏覽等(BlazeMeter)。
- Requests: 直接發 HTTP 請求,無需開瀏覽器就能拿到網頁或 API 資料(Requests Docs)。
- BeautifulSoup: 解析 HTML 或 XML,快速抓出你要的資料(BeautifulSoup Docs)。
- 社群活躍、資源多到爆: 遇到問題,Stack Overflow 或各大部落格幾乎都能找到解法。
- 跨平台沒煩惱: Python 腳本在 Windows、macOS、Linux 都能跑,幾乎不用改。
跟 Java、C# 這些語言比起來,Python 用更少的程式碼就能搞定更多事,也更容易維護。雖然 JavaScript 也能自動化瀏覽器,但 Python 的函式庫和文件對商務自動化來說更友善(ActiveBatch)。
打造你的 Python 自動化工具箱
在開始自動化之前,先把環境準備好。無論你用 Windows、macOS 還是 Linux,以下是我推薦的安裝步驟:
1. 安裝 Python 和 Pip
- Windows: 到 python.org 下載 Python 3,安裝時記得勾選「Add Python to PATH」。
- macOS: 可以用官方安裝程式,或用 Homebrew 執行
brew install python3。 - Linux: 多數發行版預設就有 Python,沒有的話用
sudo apt-get install python3 python3-pip。
確認安裝:
python3 --version
pip --version
如果找不到 pip,請另外安裝(Ubuntu 可用 sudo apt-get install python3-pip)。
2. 安裝 Selenium 及其他套件
Python 和 pip 準備好後,安裝常用函式庫:
pip install selenium requests beautifulsoup4
- Selenium:瀏覽器自動化
- Requests:HTTP 請求
- BeautifulSoup:HTML 解析
3. 下載 WebDriver(Selenium 專用)
Selenium 需要驅動程式來控制瀏覽器。Chrome 請下載 ChromeDriver,Firefox 請用 geckodriver。
- 把驅動程式放到系統 PATH,或在腳本裡指定路徑:
from selenium import webdriver
driver = webdriver.Chrome(executable_path="/path/to/chromedriver")
新版 Selenium 如果驅動已在 PATH,通常會自動偵測。
4. 建立虛擬環境
用虛擬環境(像 venv 或 virtualenv)可以讓每個專案的依賴都獨立,避免版本打架(Real Python)。
建立並啟用虛擬環境:
python3 -m venv myenv
source myenv/bin/activate # Windows 用 myenv\Scripts\activate
之後的 pip install 只會影響這個專案。
5. 各作業系統小技巧與排錯
- Windows: 如果
python或pip不能用,檢查 PATH 或用py啟動。 - macOS: 請用
python3取代python,避免跟系統預設版本混淆。 - Linux: 如果在無頭伺服器跑 Selenium,請用 headless 模式或安裝 Xvfb。
遇到驅動或套件版本問題,記得確認相容性並適時更新。
用 Selenium 自動化網站表單與瀏覽
接下來進入重頭戲:讓瀏覽器自動幫你操作。Selenium 是這方面的主力,無論是自動登入還是多步驟流程都難不倒它。
開啟瀏覽器並載入網頁
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://example.com/login")
這樣就能開啟 Chrome 並進入登入頁。
定位與操作網頁元素
Selenium 支援用 ID、name、CSS selector、XPath 等多種方式找元素:
username_box = driver.find_element(By.ID, "username")
password_box = driver.find_element(By.NAME, "pwd")
login_button = driver.find_element(By.XPATH, "//button[@type='submit']")
- 填寫文字欄位:
username_box.send_keys("alice") - 點擊按鈕:
login_button.click() - 下拉選單選擇:
from selenium.webdriver.support.ui import Select
select_elem = Select(driver.find_element(By.ID, "country"))
select_elem.select_by_visible_text("Canada")
- 跳轉頁面:
driver.get("https://example.com/profile")
元素選取最佳實踐
- 優先用 ID 或獨特屬性,最穩定。
- CSS selector 精簡又好維護。
- 避免用絕對 XPath,頁面一改就容易失效(Medium)。
處理動態內容與等待
現代網站常常動態載入內容,腳本太快點擊會出錯。建議用 顯式等待:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.ID, "loginBtn")))
這會等最多 10 秒直到按鈕可點擊。顯式等待比 time.sleep() 靈活又可靠(BrowserStack)。
範例:自動化多步驟網頁表單
以下示範自動填寫兩步驟註冊流程(以公開測試網站為例):
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get("https://practicetestautomation.com/Practice-Signup")
# 步驟 1:填寫第一個表單
driver.find_element(By.ID, "name").send_keys("Alice")
driver.find_element(By.ID, "email").send_keys("alice@example.com")
driver.find_element(By.ID, "password").send_keys("SuperSecret123")
driver.find_element(By.ID, "nextBtn").click()
# 步驟 2:等待並填寫第二個表單
WebDriverWait(driver, 10).until(EC.visibility_of_element_located((By.ID, "address")))
driver.find_element(By.ID, "address").send_keys("123 Maple St")
driver.find_element(By.ID, "phone").send_keys("5551234567")
driver.find_element(By.ID, "submitBtn").click()
# 步驟 3:確認註冊成功
WebDriverWait(driver, 5).until(EC.text_to_be_present_in_element((By.TAG_NAME, "h1"), "Welcome"))
print("註冊成功!")
driver.quit()
這個腳本會自動填寫兩個表單、等待每個步驟載入,並檢查是否註冊成功。這種模式在自動化各種網站流程時都超實用。
Thunderbit:AI 驅動的複雜網站自動化
試用 Thunderbit Chrome 擴充功能 只需幾下點擊,AI 幫你自動抓取網頁數據與流程。 Get Started Free
如果你遇到的是結構亂七八糟的網站、需要從 PDF 或圖片中擷取資料,或根本不想寫程式怎麼辦?這時候 Thunderbit 就超好用。
Thunderbit 是一款 AI 網頁爬蟲 Chrome 擴充功能,讓你只要幾下點擊就能自動抓取數據、操作網站,完全不用寫程式。它對商務用戶來說特別有感,原因如下:
- 自然語言指令: 只要描述你要什麼(像「產品名稱、價格、評分」),Thunderbit 的 AI 就會自動判斷怎麼抓(Futurepedia)。
- 子頁面抓取: 需要每個商品的詳細頁資料?Thunderbit 會自動點進子頁並把資料加到表格。
- 一鍵範本: Amazon、Zillow 等熱門網站有現成範本,直接套用馬上有結果。
- 支援 PDF 與圖片: 能直接擷取 PDF(含掃描檔)和圖片裡的文字,這在 Python 需額外安裝套件。
- 排程抓取: 用自然語言設定定時任務(像「每週一上午九點」)。
- 免費匯出資料: 可匯出到 Excel、Google Sheets、Airtable、Notion、CSV 或 JSON,完全免費。
Thunderbit 特別適合把雜亂的網頁內容轉成結構化資料,或讓非技術同事也能自動化自己的工作流程。就像有個 AI 助理,永遠不會抱怨重複工作。
什麼時候該用 Thunderbit,什麼時候該用 Python?
-
用 Python(Selenium/Requests/BeautifulSoup):
- 需要自訂邏輯、整合其他系統或細緻控制時。
- 流程不只抓資料,還要做分析、API 呼叫或複雜條件判斷。
- 你熟悉寫程式,想用版本控制管理專案。
-
用 Thunderbit:
- 想快速、無程式碼抓資料或自動化常規操作。
- 面對結構混亂、PDF、圖片等難搞的網站。
- 讓非工程師同事也能自動化,或處理臨時、頻繁的抓取需求。
我自己常常兩者搭配用:Thunderbit 快速原型或給業務、營運團隊用,Python 則負責深度整合與自訂流程。
讓 Python 自動化腳本更穩定可靠的訣竅
自動化的價值在於穩定。以下是我讓腳本長期運作順暢的幾個做法:
錯誤處理與重試
把容易出錯的操作包在 try/except 裡:
try:
element = driver.find_element(By.ID, "price")
except Exception as e:
print("找不到價格元素:", e)
driver.save_screenshot("screenshot_error.png")
# 可以選擇重試或跳過
遇到網路不穩或元素偶爾失敗時,加上簡單重試機制:
import time
max_retries = 3
for attempt in range(max_retries):
try:
driver.get(url)
break
except Exception as e:
print(f"第 {attempt+1} 次失敗,重試中...")
time.sleep(5)
處處用顯式等待
不要假設元素馬上就緒,每次互動前都用顯式等待:
WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.CLASS_NAME, "result"))).click()
日誌與監控
長時間運作的腳本建議用 Python 的 logging 模組記錄進度與錯誤。遇到重大錯誤可自動發郵件或 Slack 通知。失敗時記得截圖,方便除錯。
資源管理
腳本結束時務必呼叫 driver.quit(),避免瀏覽器殘留佔用資源。
節流與禮貌
大量抓取時,請隨機延遲(像 time.sleep(random.uniform(1,3))),避免被封鎖。遵守 robots.txt,不要對伺服器造成負擔。
因應網站變動
網站常常改版,ID 會變、版面會調整、彈窗會冒出。我的做法:
- 用彈性選取器: 優先用穩定屬性或
data-*屬性,少用脆弱的 XPath。 - 集中管理選取器: 把所有選取器集中在腳本最上方,方便日後維護。
- 定期測試: 定期執行腳本,及早發現問題。
- 版本控制: 用 Git 管理腳本,方便回溯。
如果是內部系統,建議請網頁團隊加上穩定的 data-automation-id 供自動化用。
Python 自動化工具比較:Selenium、Requests、BeautifulSoup、Thunderbit
以下快速比較,幫你選對工具:
| 工具 | 優勢與適用情境 | 限制與注意事項 |
|---|---|---|
| Selenium (WebDriver) | 完整瀏覽器自動化,支援動態 JS,模擬真實用戶操作,適合多步驟流程 | 速度較慢、資源消耗高、需安裝驅動,選取器不穩定時易失效 |
| Requests + BeautifulSoup | 靜態頁面/API 抓取快速輕量,HTML 解析簡單,適合大量資料擷取且無 JS 動態需求 | 無法處理動態 JS,不能模擬用戶互動,需自行寫解析邏輯 |
| Thunderbit | 無程式碼、AI 驅動,能處理雜亂網站、PDF、圖片、子頁抓取、即時範本、免費匯出,適合非工程師 | 自訂邏輯彈性較低,依賴外部服務,AI 建議初期可能需微調 |
實戰教學:用 Python 自動化網站操作的 7 步驟
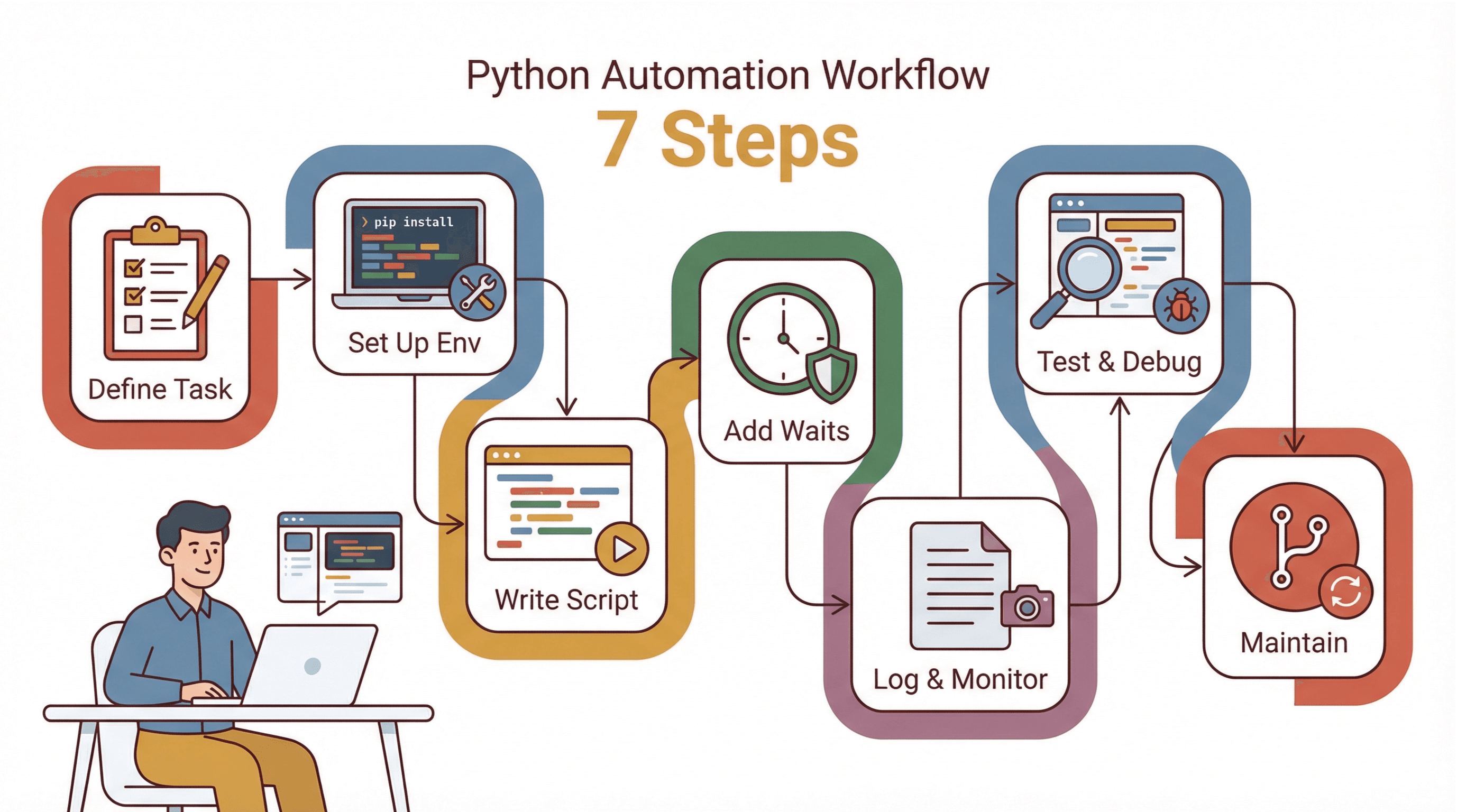 這是我自動化任何網站任務的標準流程:
這是我自動化任何網站任務的標準流程:
- 明確定義任務: 先寫下你手動會做的每一步,標出難點(像登入、彈窗、動態內容)。
- 建置環境: 安裝 Python、pip、虛擬環境、Selenium 與對應 WebDriver。
- 逐步撰寫腳本: 先寫基本瀏覽,再逐步加入互動,每加一段就測試。
- 加上等待與錯誤處理: 用顯式等待,脆弱步驟包 try/except。
- 加日誌監控: 記錄進度與錯誤,失敗時自動截圖。
- 測試與除錯: 用瀏覽器開發者工具檢查選取器,建議先用可見模式觀察彈窗或跳轉。
- 維護與更新: 選取器集中管理,用版本控制,定期檢查腳本。
新手建議從小任務開始,例如自動登入測試網站或填寫簡單表單,每完成一個小目標都能累積信心與技巧。
結語與重點整理
用 python 自動化網站操作,絕對是讓你省時又省力的神隊友。Python 語法簡單、函式庫強大,無論是簡單填表還是複雜多步驟流程都能搞定。龐大的社群和豐富資源,讓你遇到問題也不怕。每天省下 15 分鐘,一年下來就多出近 90 小時(LinkedIn)。
但別忘了,有時最快的解法是用 AI 工具如 Thunderbit。遇到結構混亂的網站,或想讓非技術同事也能自動化,Thunderbit 幾下點擊就能搞定。
我的建議?從你最常覺得煩的網頁任務開始,試著用 python 自動化網站操作或 Thunderbit 來解決。你會驚訝自己能多快從「又要重複做」變成「幾秒就搞定」。
想深入學習網頁爬蟲,歡迎參考 Thunderbit Blog 的更多教學與技巧。
常見問題
1. 為什麼 Python 這麼適合自動化網站操作?
Python 語法易讀、函式庫齊全(像 Selenium、Requests、BeautifulSoup),加上龐大社群支援,是網頁自動化與腳本首選(GitHub Octoverse)。
2. Selenium、Requests、BeautifulSoup 有什麼差別?
Selenium 可以自動操作瀏覽器,適合動態網站與用戶互動。Requests 用於無需瀏覽器的網頁或 API 抓取(適合靜態內容)。BeautifulSoup 解析 HTML,通常搭配 Requests 使用。
3. 什麼情況下該用 Thunderbit 而不是 Python?
當你想用無程式碼、AI 驅動的方式抓取結構混亂的網站、PDF、圖片,或讓非技術同事也能自動化時,選 Thunderbit。需要自訂邏輯、整合或複雜流程時,則用 Python。
4. 如何讓 Python 自動化腳本更穩定?
多用顯式等待、try/except 錯誤處理、網路重試與日誌監控。選取器集中管理,網站變動時及時更新。
5. 可以把 Thunderbit 和 Python 結合嗎?
當然可以!用 Thunderbit 快速抓資料,再用 Python 處理或分析。或用 Python 實現複雜邏輯,Thunderbit 負責快速、無程式碼抓取。
想開始用 python 自動化網站操作?不妨試試 Thunderbit 免費 Chrome 擴充功能,或動手寫 Python 腳本,讓你工作效率大提升。
試用人工智慧網頁爬蟲 Get Started Free
延伸閱讀




