

有些人收集郵票,有些人收集球鞋。但如果您在 2026 年從事銷售、行銷、電商或營運,很可能在收集一些更……數位化的東西:網頁資料。而且不只是小量而已——企業現在平均每年在網頁資料蒐集上的支出高達 500 萬美元,而網頁爬蟲也已經成為各部門的標準工具,從策略到客服都在用(來源)。
隨著需求爆炸式成長,兩個名字在每一篇 Python 爬蟲教學和商業資料專案裡都反覆出現:Playwright 和 Selenium。這兩者一開始都是拿來做瀏覽器自動化測試的工具,但現在已經成為任何想把網頁轉成結構化、可執行資料的人首選的框架。不過,關鍵在於:在它們之間做選擇,並不只是技術決策而已——而是要替您的實際爬取需求挑對工具。如果您不是開發者,或只是想快速拿到結果,其實還有一條更簡單的路(提示:完全不用寫任何一行 Python)。一起來看看。
從測試工具到網頁爬取利器:認識 Playwright 和 Selenium
先從背景說起。Selenium 自 2004 年就已經存在,是瀏覽器自動化界的老牌可靠選擇。它原本是為 QA 測試人員打造的,可以控制 Chrome、Firefox,甚至 Internet Explorer(如果您喜歡挑戰極限的話)。Playwright 則是在 2020 年橫空出世,背後有 Microsoft 支持,以更現代的方式做瀏覽器自動化——您可以把它想成 Selenium 的年輕、速度更快的兄弟。
這兩個工具都能讓您寫腳本(通常是 Python),開啟瀏覽器、前往網站、點擊按鈕、填寫表單,最重要的是——擷取資料。雖然它們的出身都來自自動化測試,但現在已經成為各種網頁爬取任務的基礎,從價格監控到名單開發都少不了它們(來源)。而且不只是開發者在關注:越來越多商業用戶也開始動手打造自己的爬蟲,或者至少嘗試這麼做。
但問題在於:當您真的開始爬資料時,優先順序就變了。您更在意的不是測試覆蓋率,而是穩定拿到資料、避免被封鎖,以及不要把整個週末都花在除錯 Python 錯誤上。這才是 Playwright 和 Selenium 真正拉開差距的地方。
核心差異:Playwright 與 Selenium 的網頁爬取比較

直接切入重點:Playwright 和 Selenium 都能爬網站,但它們各自擅長的場景不同。
- Selenium 是老將。它幾乎支援所有瀏覽器與語言,社群龐大,非常適合爬取結構固定、內容較靜態的舊網站。
- Playwright 則是帶著現代功能的新秀。它為今天這種動態、JavaScript 密集的網站而設計,內建處理登入、彈出視窗、無限捲動等功能。它也通常更快、設定更簡單,尤其對 Python 使用者來說更友善。
不過別只聽我說,接下來我們就逐項拆解。
功能比較表:Playwright vs. Selenium
| 功能 | Selenium | Playwright |
|---|---|---|
| 語言支援 | Python、Java、C#、JS、Ruby 等 | Python、JS/TS、Java、C# |
| 瀏覽器支援 | Chrome、Firefox、Edge、Safari、IE、Opera | Chromium(Chrome/Edge)、Firefox、WebKit |
| 設定複雜度 | 需要瀏覽器驅動程式、手動設定 | 一個指令就能安裝全部 |
| 速度/效能 | 較慢、資源消耗較高 | 在 JS 密集頁面通常更快;原生支援非同步/並行 |
| 動態內容處理 | 需手動等待,程式碼較多 | 自動等待,輕鬆處理 JS 密集網站 |
| 反機器人偵測規避 | 較容易被偵測,需要額外外掛 | 內建隱匿機制,更像真實使用者 |
| 除錯工具 | 基本功能(Selenium IDE、截圖) | Inspector、錄影、codegen |
| 社群支援 | 龐大、成熟、教學很多 | 成長快速、文件現代、開發者活躍 |
| Python 爬蟲流程 | 設定較多、樣板程式較多 | 更順手、程式碼更少、對初學者更友善 |
如何選對工具:什麼時候該用 Playwright,什麼時候該用 Selenium
那麼,下一個爬取專案該選哪一個?根據我多年打造自動化工具、幫團隊從網路世界挖出資料的經驗,我的看法如下。
- 如果符合以下情況,Selenium 比較適合您:
- 您要爬的網站很「老派」——例如靜態 HTML、JavaScript 很少,沒有花俏的彈出視窗。
- 您需要支援奇怪的瀏覽器(沒錯,像 Internet Explorer 這種)或整合舊系統。
- 您想要龐大社群帶來的安全感,以及搜尋 StackOverflow 時滿滿的解答。
- 您本來就因為測試專案而熟悉 Selenium。
- 如果符合以下情況,Playwright 比較適合您:
- 網站是現代、動態、JavaScript 很多的類型(像電商、社群媒體,或任何會讓筆電風扇狂轉的網站)。
- 您需要登入、點分頁、處理無限捲動,或應付彈出視窗。
- 您想快速上手,設定更少、程式碼更少。
- 您已經厭倦到處寫
time.sleep(5),希望工具幫您處理時機控制。
有個簡單的經驗法則:如果您第一次用 Selenium 爬某個網站,結果整個過程充滿「怎麼還沒載入?」的時刻,那大概就是該試試 Playwright 的時候了。
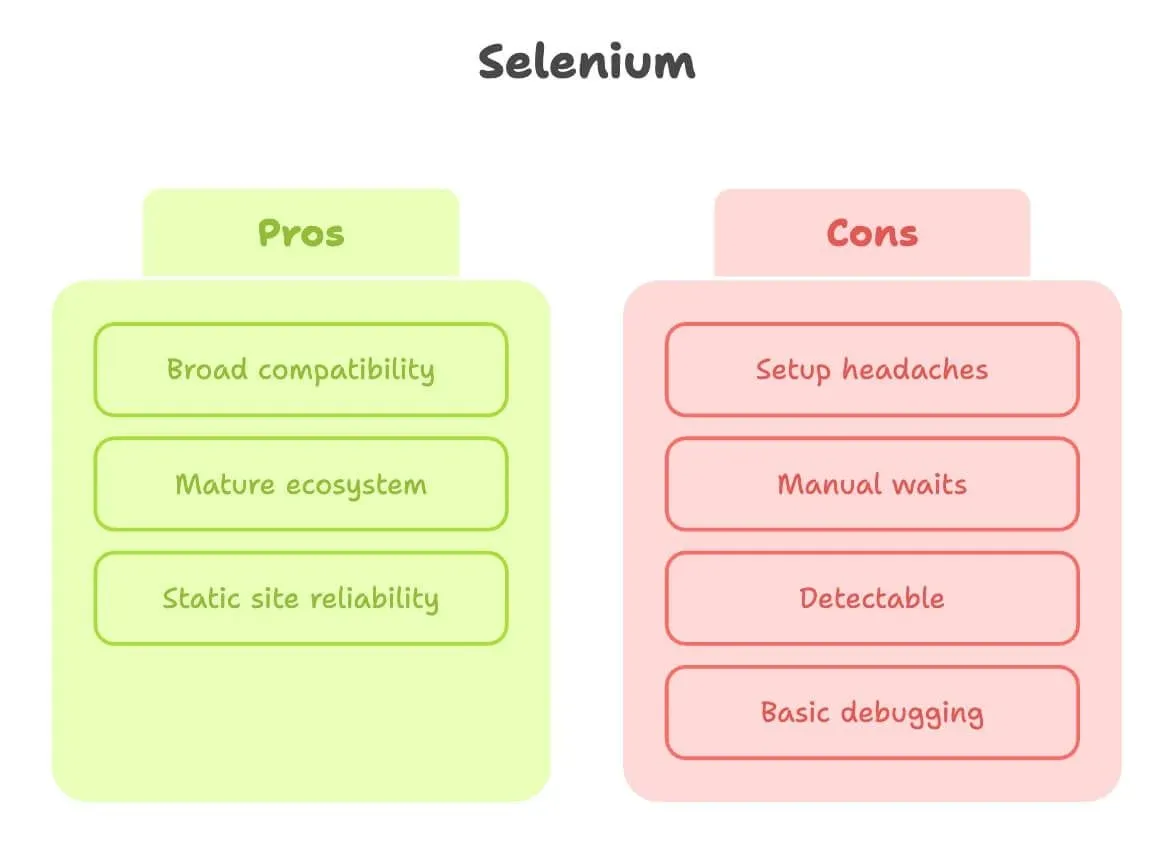
Selenium 網頁爬取:優勢與限制
我們也要替 Selenium 平反一下。它是瀏覽器自動化界的老前輩,而對很多爬取工作來說,它確實就是能用。
優勢:
- 相容性廣: 幾乎支援所有瀏覽器與語言。
- 生態成熟: 教學、問答、外掛都非常多。
- 適合靜態網站: 如果頁面變化不大,Selenium 很穩。
限制:
- 設定麻煩: 您得下載並設定瀏覽器驅動程式(像 ChromeDriver),還要保持版本更新。初學者常常卡在這一步(來源)。
- 手動等待: 動態內容?您大概得寫很多明確等待,甚至是隨便塞
sleep。 - 較容易被偵測: 很多網站能看出 Selenium 驅動的瀏覽器,尤其您如果是在雲端伺服器上跑,更容易被擋。
- 除錯能力基本: 沒有內建錄影或互動式 Inspector。
簡單說,Selenium 非常適合簡單、穩定的網站,但在現代互動式頁面上,常常會讓人有種在推大石頭上坡的感覺。
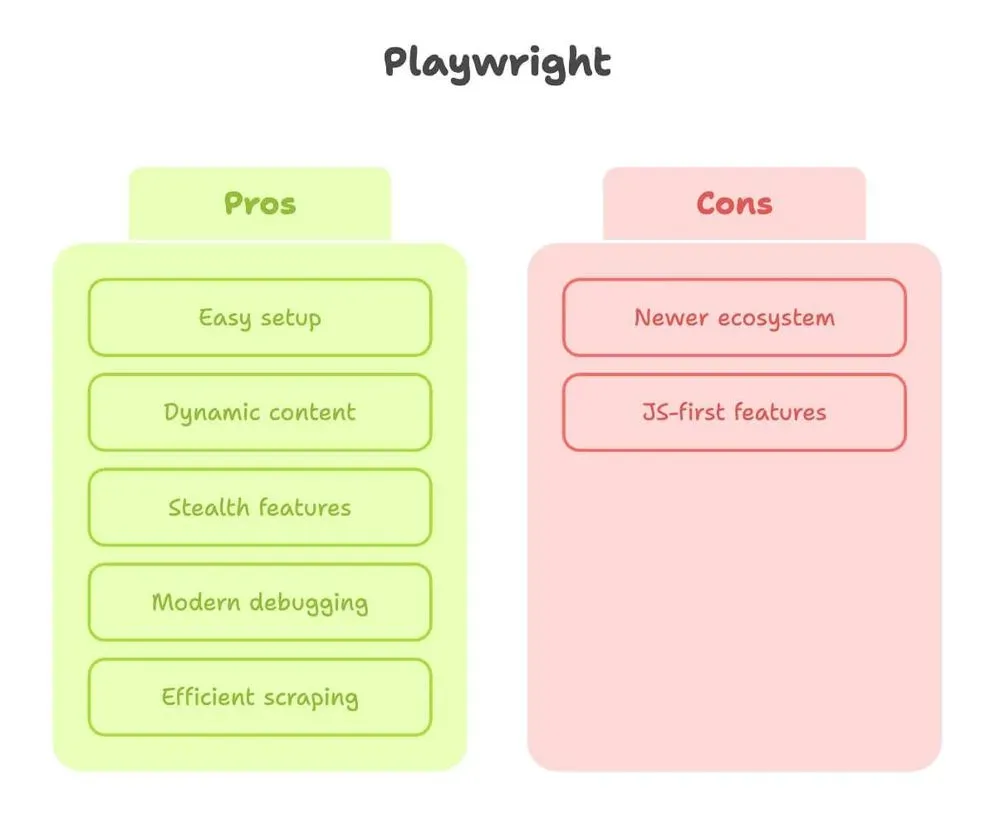
Playwright 網頁爬取:優勢與限制
現在來談 Playwright。身為一個花很多時間同時使用這兩個工具的人,我可以很肯定地說,Playwright 的設計者顯然真的懂網頁爬取有多折磨人。
優勢:
- 設定簡單: 一次 pip install,一個指令,就能開始。沒有驅動程式的煩惱。
- 擅長處理動態內容: 會自動等待元素載入,您不用猜頁面什麼時候準備好了(來源)。
- 隱匿功能: 更像真實使用者,內建隱身模式與多個 context 支援(很適合同時以多個「使用者」身分爬取)。
- 現代化除錯: Inspector、錄影,甚至可以從您手動點擊直接產生程式碼。
- 速度快、效率高: 特別適合大量頁面爬取或平行執行。
限制:
- 生態較新: 教學稍微少一些,不過差距正在快速縮小。
- 有些功能偏 JavaScript 優先: 大多數功能在 Python 都能用,但偶爾會遇到某些功能在 JS 文件裡寫得更完整。
總結來說:只要網站有一點點動態性,或我想在不跟設定打架的情況下快速拿到結果,Playwright 就是我的首選。
反機器人偵測:哪個 Python 爬蟲更能應付現代網站?
我們來談談大家最在意的事:被封鎖。在網頁爬取裡,最難的不是寫程式,而是確保網站不會直接把門關上。
- Selenium:開箱即用的情況下比較容易被偵測。網站可以看出
webdriver標記、headless 使用者代理字串,以及其他明顯特徵。雖然有一些繞法(像 undetected-chromedriver),但它們需要額外設定,而且永遠都在追著反機器人技術跑(來源)。 - Playwright:內建一些隱匿能力,例如自動隱藏自動化指紋、支援多個瀏覽器 context,以及等待更像真人的互動。它不是魔法,但至少第一次嘗試就被封鎖的機率比較低。
但真相是: 這兩個工具都無法完全免疫反機器人措施。若是高風險爬取(像球鞋限量發售或售票網站),您還是需要代理伺服器、輪換 IP,甚至處理 CAPTCHA。Playwright 只是讓這一切沒那麼痛苦。
開發者體驗:設定、學習曲線與除錯
來談談實際上手的感受——尤其如果您是初學者,或只是想完成工作,不想先拿個 Python 博士學位。
- Selenium:
- 設定: 安裝 Python、安裝 Selenium、下載對應的瀏覽器驅動程式,把它放進 PATH,然後祈禱版本沒配錯。(我看過卡在驅動程式這一步的人,比卡在實際爬取的人還多。)
- 學習曲線: 資源很多,但也有大量舊程式碼和過時教學。
- 除錯: 多半靠 print 陳述式和截圖。Selenium IDE 雖然存在,但功能很基本。
- Playwright:
- 設定:
pip install playwright,接著playwright install。完成。 - 學習曲線: 文件現代、範例很多,而且 API 感覺更「人性化」——您可以用文字、角色,甚至 placeholder 來選取元素。
- 除錯: Inspector 讓您可以逐步執行腳本、觀察瀏覽器,甚至錄下爬取過程的影片(來源)。
- 設定:
如果您想要快速看到成果,並把時間花在更少的設定與排錯上,Playwright 很明顯是贏家。如果您已經習慣 Selenium 的各種小毛病,或是需要它廣泛的相容性,那 Selenium 也很不錯。
逐步教學:用 Playwright 或 Selenium 建立您的第一個 Python 網頁爬蟲
我們來看看用兩個工具各自建立爬蟲時,實際流程長什麼樣子——不寫程式,只看步驟。
Playwright(Python):
- 安裝 Playwright 與瀏覽器:
pip install playwright+playwright install - 啟動瀏覽器: 開啟 Chromium、Firefox 或 WebKit 瀏覽器(無頭或可視皆可)。
- 前往頁面: 使用
page.goto("<https://example.com>") - 等待內容: Playwright 會自動等待元素載入。
- 擷取資料: 使用更直覺的選擇器(例如
get_by_text、locator("span.price"))。 - 處理分頁或子頁面: 逐頁迴圈或點擊連結——Playwright 很容易平行處理多個頁面。
- 匯出資料: 存成 CSV、Excel 或資料庫。
- 除錯: 如果出狀況,用 Inspector 或錄影查看問題。
Selenium(Python):
- 安裝 Selenium:
pip install selenium - 下載瀏覽器驅動程式:(例如 Chrome 的 ChromeDriver)並放進 PATH。
- 啟動瀏覽器: 開啟 Chrome、Firefox 或其他瀏覽器。
- 前往頁面:
driver.get("<https://example.com>") - 等待內容: 手動加入明確等待(
WebDriverWait),或如果您很有把握,就用time.sleep。 - 擷取資料: 使用
find_element或find_elements(CSS/XPath 選擇器)。 - 處理分頁或子頁面: 透過 URL 迴圈或點擊按鈕,但您得自己管理時機與導航。
- 匯出資料: 存成 CSV、Excel 或資料庫。
- 除錯: 多半是手動處理——看瀏覽器、印出 HTML,或截圖。
看出差別了嗎?Playwright 對現代網站來說,就是更接近「即裝即用」。
不只寫程式:用 Thunderbit AI Web Scraper 進行無程式碼網頁爬取
使用 AI 從任何網站擷取資料 Get Started Free
說真的,不是每個人都想為了抓一張商品價格表或名單,就變成 Python 大師。也許您在銷售、行銷、不動產或營運部門,您只是想現在就拿到資料。這就是 Thunderbit 登場的時候。
身為 Thunderbit 的共同創辦人,我親眼看過太多商業用戶只想跳過寫程式,直接拿到成果。所以我們打造了一個AI 驅動的 Chrome 擴充功能,讓您只要兩個點擊就能爬取任何網站——不用 Python、不用驅動程式、也不用除錯。
Thunderbit 的運作方式
- 前往您想爬取的網站。
- 點擊「AI 建議欄位」。 Thunderbit 的 AI 會掃描頁面,並推薦資料欄位(例如商品名稱、價格、圖片、評分)。
- 點擊「爬取」。 您會立刻得到一個結構化的資料表。
- 匯出到 Excel、Google 試算表、Airtable、Notion、CSV 或 JSON。 完成。
不用調整選擇器、不用反覆試錯、也不用寫程式。這就像叫外送一樣簡單(老實說,可能還比等餐點送到更快)。
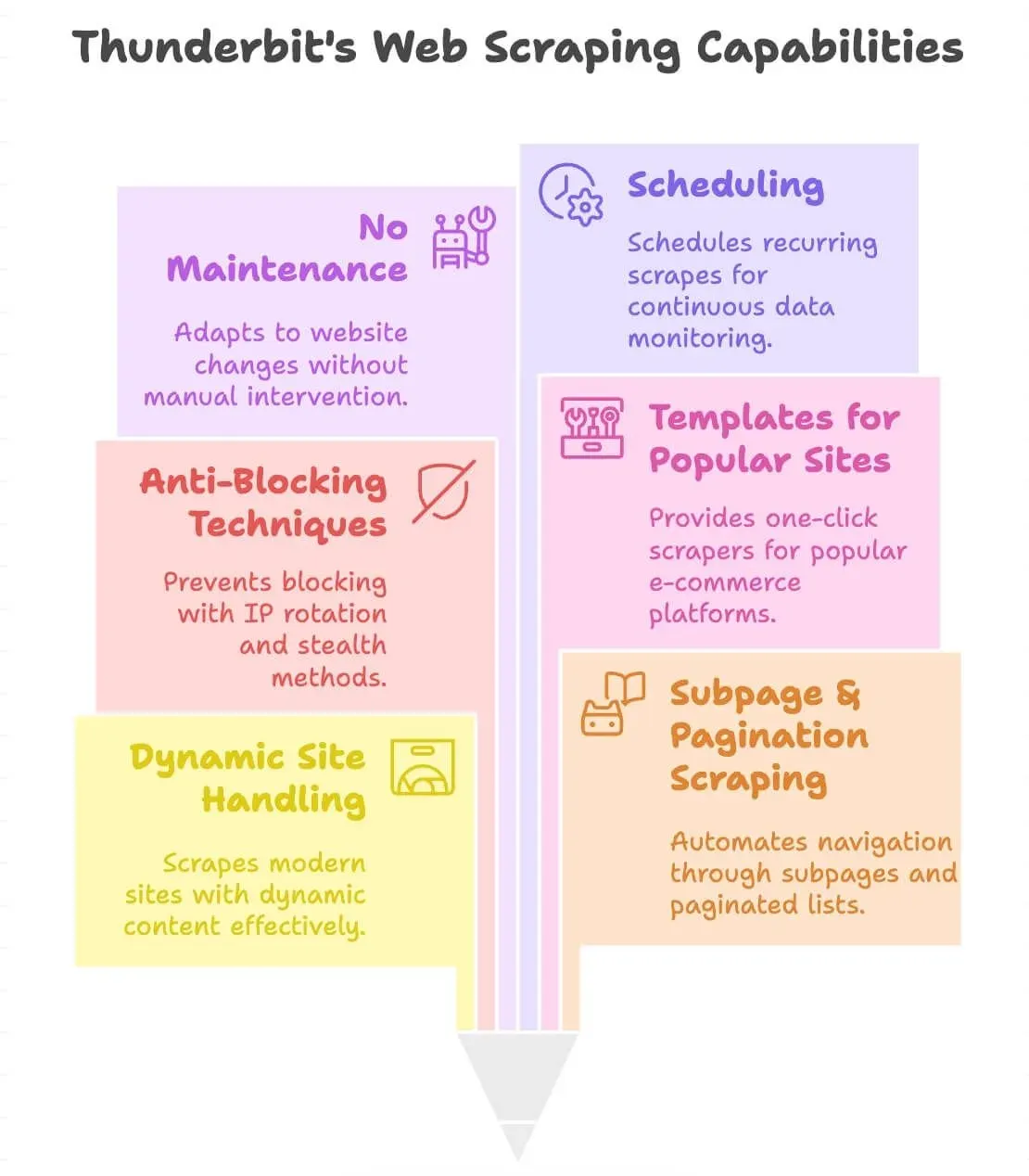
Thunderbit 有什麼不同?
- 可處理動態網站: 可爬取現代電商、名錄網站,甚至有無限捲動或彈出視窗的頁面。
- 支援子頁面與分頁爬取: 會自動點進商品頁或分頁清單,把您需要的資料全部抓回來。
- 內建防封鎖: 使用後端 IP 輪換與隱匿技術,降低被封鎖的機率。
- 熱門網站範本: 提供 Amazon、eBay、Shopify、Zillow 等網站的一鍵爬蟲(詳見我們的部落格)。
- 維護成本更低: 當網站版面變動時,「AI 建議欄位」通常能重新偵測欄位,因此您多半只要重新執行建議步驟,不必從頭重建選擇器腳本。
- 排程: 可設定定期爬取,進行持續監控(例如每日價格檢查)。
- 支援 55 種語言: 幾乎可從任何地方擷取與翻譯資料。
最棒的是?您完全不需要懂 HTML、CSS 或 Python。 只要會用瀏覽器,就能用 Thunderbit。
哪一種網頁爬取方案最適合您?
最後用一個快速決策指南來收尾:
| 您的情況 | 最佳工具 |
|---|---|
| 爬取靜態、簡單的網站;不介意設定 | Selenium |
| 爬取現代、動態的網站;想快速拿到結果 | Playwright |
| 需要支援舊瀏覽器或舊語言 | Selenium |
| 想要簡單設定、現代除錯、較少程式碼 | Playwright |
| 不是開發者;現在就要資料,且不想寫程式、不想設定 | Thunderbit |
| 需要爬取多個頁面、子頁面或排程工作 | Thunderbit |
| 想直接匯出到 Excel、Sheets、Notion、Airtable | Thunderbit |
| 受不了 Python 錯誤除錯 | Thunderbit |
如果您是開發者,或者很享受玩程式碼,Playwright 和 Selenium 都是很強的選擇。但如果您的目標是盡快把資料放進試算表,Thunderbit 可以幫您省下好幾個小時,甚至好幾天的工作量。
結論:用您想要的方式,快速又可靠地爬取網頁資料
網頁爬取已經成為主流,而且很有道理:企業需要資料來競爭,而且現在就需要。Playwright 和 Selenium 都已經從簡單的測試工具,進化成不可或缺的爬取框架,各自有自己的優勢。Selenium 是靜態網站與舊系統的老牌可靠選擇;Playwright 則是現代、快速、適合動態互動頁面的方案。
但老實說,經過多年 SaaS、自動化與 AI 的經驗後,我的建議是:如果您不是為了寫程式而來,別把時間浪費在驅動程式、選擇器和反機器人技巧上。 使用 Thunderbit 的 AI Web Scraper,您可以在幾分鐘內從「我需要這些資料」變成「這是我的 Excel 檔案」——不是幾天。
所以,不管您是 Python 高手,還是只想拿到結果的商業用戶,都有適合您的爬取方案,也有適合您的耐心程度。試試看,找出最適合您工作流程的工具,並記住:最好的爬蟲,就是那個能用最少麻煩把您需要的資料拿到手的工具。
如果您有一天凌晨兩點還在除錯 Selenium 驅動程式錯誤,至少要知道——Thunderbit 會一直在這裡,準備好只靠兩次點擊就完成爬取。祝您爬取順利。
想進一步了解無程式碼爬取、AI 驅動的資料擷取,以及 Thunderbit 如何幫助您的團隊?歡迎查看我們的 部落格,或立即開始使用 Thunderbit Chrome 擴充功能。
P.S. 如果您還是不確定該用哪個工具,或者想看看 Thunderbit 實際運作的樣子,歡迎到我們的 YouTube 頻道 看示範、技巧,以及偶爾出現的網頁爬取笑話。(沒錯,我們真的有。)
延伸閱讀:
試用 AI 網頁爬蟲 Get Started Free




