老實說,如果每次有人丟給我一份塞滿「重要資料」的 PDF,還期待我能神奇地把它變成試算表,我大概早就買得起一輩子都喝不完的咖啡了(也許還能多買幾個 Chrome 擴充功能)。PDF 到處都是——銷售合約、產品型錄、研究論文、發票,樣樣都有。但真要把這些檔案裡的資料拿來用呢?嗯,真正的挑戰(翻譯:頭痛)就開始了。
我自己也經歷過不少次——複製、貼上、重新排版,有時候格式一亂、圖片和連結瞬間消失,我甚至只能直接放棄。不過好消息是:PDF 抓取的世界已經大幅改變,尤其是 AI 驅動工具興起之後。如果你已經厭倦花好幾個小時重新輸入數字,或為了壞掉的表格抓狂,那你來對地方了。一起來看看 PDF 抓取是什麼、為什麼重要,以及像 這類工具如何把它變得(終於)不再痛苦。
什麼是 PDF 抓取?先理解 PDF 資料擷取的基礎概念
先從最簡單的說起:PDF 抓取,其實就是「自動從 PDF 檔案中取出結構化資料」。PDF 爬蟲則是用來把你在意的內容——文字、表格、圖片、連結,等等——擷取出來,並整理成你真正能使用的格式,例如 Excel、Google Sheets,或資料庫。
但問題來了:PDF 不像網頁或 Excel 檔。它更像數位列印稿,重點是到哪裡看起來都一樣,而不是方便電腦拆解。有些 PDF 可以選取文字,有些其實只是掃描圖片(這就需要 OCR,也就是光學字元辨識),而格式還可能亂七八糟。所以,PDF 抓取不只是複製文字而已,而是在解讀一整個由版面、字型,甚至隱藏中繼資料組成的拼圖。
你可以從 PDF 擷取哪些內容?
- 純文字(段落、標題等)
- 表格(例如:財務資料、產品規格、調查數據)
- 圖片與圖形(圖表、Logo、掃描簽名)
- 超連結與引用(內嵌網址、引文)
- 表單資料(可填寫表單中的欄位)
- 中繼資料(作者、標題、建立日期、標籤)
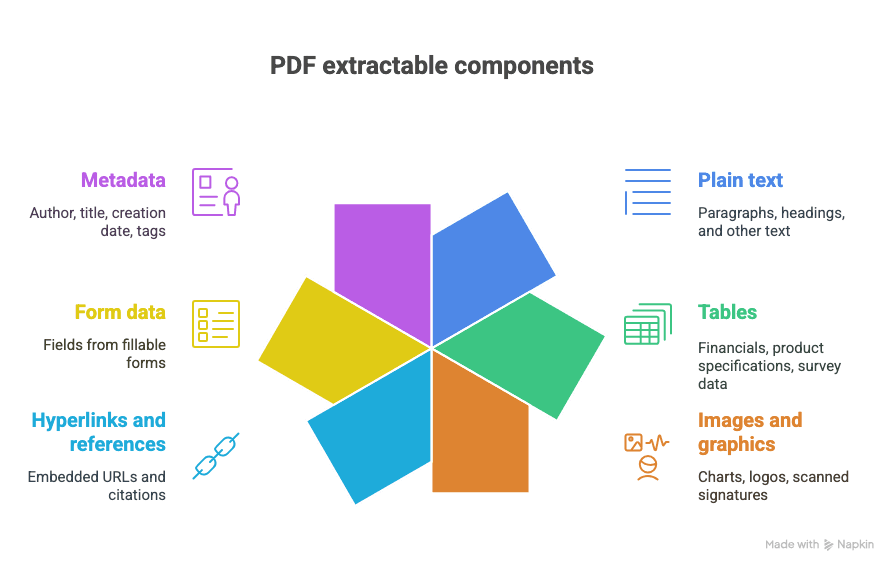
而且沒錯,這些內容有時還會全部混在同一份華麗又混亂的文件裡。
為什麼 PDF 抓取很重要:實際應用場景與商業效益
那為什麼要費心抓取 PDF?因為每個人都在用 PDF,而裡面的資料往往對企業至關重要。這就是 PDF 抓取大顯身手的地方:
| 應用場景 | 人工處理成本 | 使用 PDF 爬蟲 | 節省時間與錯誤 |
|---|---|---|---|
| 銷售名單擷取 | 從提案或活動 PDF 裡手動複製聯絡人,還可能漏掉潛在客戶 | 立即把所有名單拉進試算表 | 速度快 80–90%,錯誤更少 |
| 電商產品資料 | 從供應商 PDF 輸入產品規格要花好幾天,格式還常常亂掉 | 批次擷取成 CSV 或 Sheets | 節省 95%+ 時間,資料一致 |
| 研究資料分析 | 把學術論文裡的表格逐一誊寫,打錯字風險很高 | 擷取表格、參考資料,甚至掃描文字 | 節省 80% 時間,準確度更高 |
再來看幾個數字:
- 每年產生約 。
- 都把 PDF 當作資訊分享的主要格式。
- 像 PDF 資料輸入這類人工數位行政工作,會吃掉 。
- 自動化工具可把錯誤率從 。
如果你在銷售、電商或研究領域,PDF 資料擷取自動化不只是加分項,而是競爭優勢。
傳統 PDF 抓取方法:挑戰與限制
老實說,把 PDF 裡的資料弄出來,舊方法……真的不太行。以下是多數人都試過的幾種方式(以及它們為什麼那麼惱人):

1. 手動複製貼上
- 痛點: 格式會被弄亂,表格變成一團糟,圖片和連結消失,最後只剩下頭痛。
- 人力成本: 很高。如果你有 5,000 份 PDF,就算每份只花 1 分鐘,也代表你有 80 多個小時再也回不來了。
- 錯誤率: 5–10%。打錯字、漏列、誤刪——我都經歷過。
2. 先轉成 Word/Excel,再整理
- 痛點: 簡單文件有時勉強可行,但複雜版面或表格很容易亂掉,最後還是得手動整理。
- 圖片/連結: 通常會在轉換過程中消失。
- 精準擷取: 別想了——你拿到的是整份文件,不是你真正需要的部分。
3. 自訂程式(Python 等)
- 痛點: 你得會寫程式(或至少身邊有個隨叫隨到的工程師)。每遇到一種新 PDF 格式,都得調整腳本。掃描版 PDF?那就祝你好運。
- 維護成本: 很高。供應商只要一改發票範本,你的腳本就可能壞掉。
- 可擴充性: 對不熟技術的人來說,幾乎不友善。
4. 線上轉檔工具
- 痛點: 一次性工作很方便,但你得把敏感文件上傳到第三方伺服器(合規問題立刻浮現)。而且可控制的擷取範圍很有限。
- 格式: 看運氣。你可能花在清理格式上的時間,比省下來的還多。
一句話總結: 傳統方法慢、容易出錯,而且無法規模化。這也是為什麼很多團隊最後只能「將就用」,但代價是巨大的生產力損失。
現代 PDF 抓取解決方案:從程式到免寫碼工具
好在我們早就不必困在黑暗年代了。現在的 PDF 抓取工具越來越聰明、快速,也更容易上手。
1. 程式庫(給開發者)
- 範例: 、、。
- 優點: 彈性超高,可自動化處理大量批次,而且免費(開源)。
- 缺點: 設定時間長,需要程式能力,容易壞(遇到新格式就出問題),OCR/圖片支援也有限。
2. 線上 PDF 轉換器
- 範例: 、、。
- 優點: 幾乎不用設定,對非技術人員也很友善,小量工作很快。
- 缺點: 客製化有限、隱私疑慮、格式錯誤、檔案大小/頁數限制。
3. AI 驅動的 PDF 爬蟲
- 範例: 、Nanonets、Docparser。
- 優點: 不需要寫程式,可處理文字/表格/圖片/連結,AI 還會建議該擷取什麼,支援批次作業,也能整合 Sheets/Notion/Airtable。
- 缺點: 有些工具有點數/頁數限制,可能需要網路連線,遇到複雜文件時也可能需要一點學習成本。
比較 PDF 抓取工具:哪種方式最適合你?
| 工具/方法 | 設定方式 | 最適合 | 可擷取內容 | 可客製化? | 費用 |
|---|---|---|---|---|---|
| Tabula(Tabula-py) | 中等(介面/程式) | PDF 表格 | 表格 | 部分可 | 免費 |
| PDFMiner | 需要寫程式 | 文字很多的 PDF | 文字 | 可以(透過程式) | 免費 |
| PyPDF2 | 需要寫程式 | 簡單文字/中繼資料 | 文字、中繼資料 | 可以(透過程式) | 免費 |
| Smallpdf/線上轉檔 | 無(網頁版) | 快速轉換 | 整份文件(Word/Excel) | 否 | 免費增值 |
| Thunderbit | 2 步安裝 | 商務使用者、團隊 | 文字、表格、圖片、連結 | 可以(AI 提示詞) | 免費增值(專業版每月 16.5 美元) |
認識 Thunderbit:AI PDF 爬蟲 Chrome 擴充功能
接下來要介紹的是一個讓我(以及很多商務使用者)生活輕鬆許多的工具:。
Thunderbit 有什麼不一樣?
- 2 步擷取: 在 Chrome 打開 PDF,點一下 Thunderbit 擴充功能,其餘交給 AI。
- AI 欄位建議: Thunderbit 的「AI 建議欄位」會讀取你的 PDF,並推薦你可能需要的欄位(例如「姓名」、「Email」、「價格」等)。
- 支援圖片、連結與表格: 不只是純文字——Thunderbit 也能擷取圖片、超連結,甚至對掃描文件進行 OCR。
- 自訂提示詞: 只需要電話號碼或產品規格?加上一段自訂指令,Thunderbit 就會專注擷取你要的內容。
- 到處都能匯出: 直接把資料送到 Excel、Google Sheets、Airtable 或 Notion,不用再玩 CSV 轉換遊戲。
- 批次與子頁面抓取: 手上有一串 PDF 或連結?Thunderbit 可以一次全部處理。
- 企業級穩定性: 以準確度、隱私與真實工作流程為設計核心。
簡單來說,它就像一個數位實習生,而且是真的喜歡做資料輸入(還永遠不會累)。
如何使用 Thunderbit 從 PDF 抓取資料:逐步教學
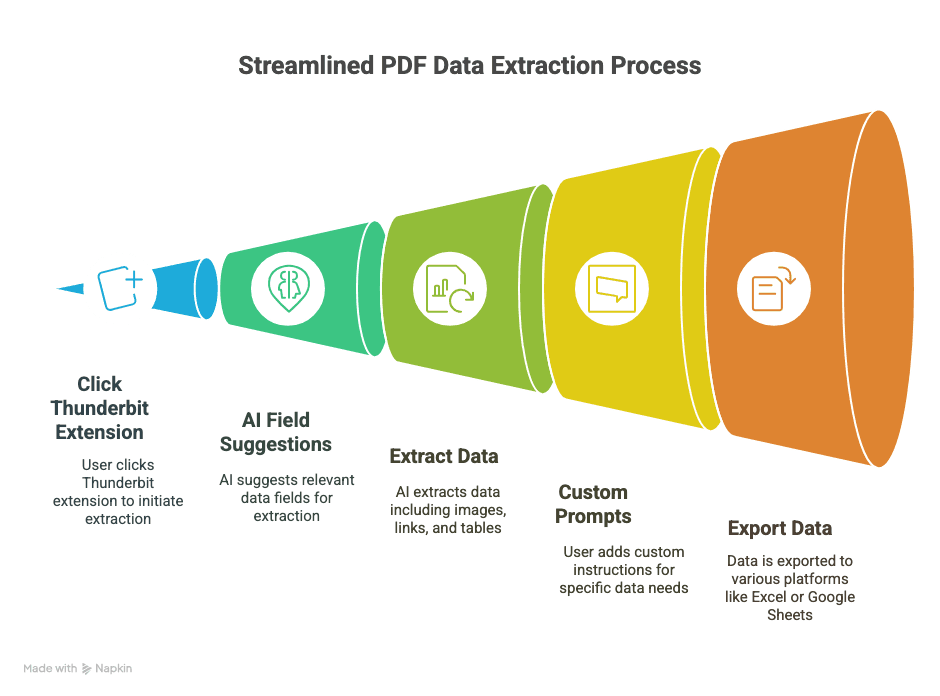
準備好看看它有多簡單了嗎?以下是我如何用 Thunderbit 把 PDF 變成結構化、可直接使用的資料:
1. 安裝 Thunderbit
- 取得 。
- 註冊帳號(Google 帳號或 Email 都可以,只要幾秒)。
2. 在 Chrome 中打開你的 PDF
- 可以直接打開網路上的 PDF 連結,也可以把本機 PDF 拖進 Chrome 分頁。
3. 在 PDF 上啟動 Thunderbit
- 點擊瀏覽器工具列上的 Thunderbit 圖示。
- 選擇「AI Web Scraper」——Thunderbit 會偵測到這份 PDF,並準備開始工作。
4. 讓 AI 建議欄位
- 點選「AI 建議欄位」。
- Thunderbit 的 AI 會掃描 PDF,並推薦欄位(例如「日期」、「金額」、「聯絡人姓名」等)。
- 你也可以直接在擴充功能內的表格預覽擷取結果。
5. 需要的話再自訂
- 重新命名欄位、刪掉多餘欄位,或自行新增欄位(例如「保固期限」或「產品網址」)。
- 如果資料比較難抓,可以直接在 PDF 中選取文字,教 AI 你要的是什麼。
6. 選擇匯出格式
- 可選 CSV、Google Sheets、Airtable 或 Notion。
- 授權 Thunderbit 連線(只需一次設定)。
7. 開始抓取並匯出
- 按下「抓取」或「匯出」。
- Thunderbit 會處理 PDF,並把資料送到你指定的位置——通常只要幾秒。
就這麼簡單。無需寫程式、無需複製貼上、無需崩潰。
使用 Thunderbit 提高 PDF 資料擷取準確度的小技巧
- 檢查 AI 建議欄位: AI 很聰明,但快速看一眼,能確保拿到的正是你需要的內容。
- 處理複雜表格: 如果是跨頁或版面怪異的表格,可以先用預覽找出問題,再視需要調整欄位。
- 擷取圖片/連結: 如果 PDF 有這些內容,記得把欄位包含進去——Thunderbit 也抓得到。
- 掃描版 PDF: Thunderbit 內建 OCR 表現不錯,但掃描越清楚,結果通常越好。
- 自訂提示詞: 只想抓 email 或電話?加上一句像「擷取所有電子郵件地址」的提示,Thunderbit 就會專注處理這些內容。
進階 PDF 抓取:擷取圖片、連結與自訂資料
Thunderbit 不只是處理純文字而已。以下是你可以從 PDF 挖出更多價值的方法:
- 圖片: 擷取 Logo、圖表或任何內嵌圖形。Thunderbit 甚至能對圖片中的文字做 OCR。
- 超連結: 抓出所有網址或引用來源——對研究論文或履歷都很有幫助。
- 自訂資料類型: 用 AI 提示詞只擷取你需要的內容(例如「找出所有產品 SKU 及其價格」)。
- 摘要與分類: 新增一欄,讓 Thunderbit 即時幫你摘要段落或分類資料。
為特定商業需求解析 PDF 資料
- 銷售: 從一批提案中只擷取聯絡資訊。
- 電商: 從供應商型錄中拉出產品規格、價格與圖片。
- 研究: 取得表格、參考資料,甚至直接從學術論文生成摘要。
而且一旦拿到資料,就可以把它整理成適合在 Excel、Google Sheets 或 Notion 裡分析的格式——Thunderbit 幫你完成重工,你只需要使用結果。
匯出並運用你的 PDF 資料:從擷取到行動
把資料抓出來只是第一步。接下來要讓它真正派上用場:
- 匯出選項: CSV、Excel、Google Sheets、Airtable、Notion——選你最順手的。
- 格式化技巧: 使用 Thunderbit 的欄位類型設定(數字、日期、文字),讓資料乾淨且可直接分析。
- 工作流程整合: 把匯出的資料連接到 CRM、庫存系統或分析儀表板。
- 協作: 與團隊共享 Google Sheets 或 Airtable 資料庫,大家都能使用同一份即時資料。
最棒的是?再也不用來回寄試算表,也不用擔心漏掉某一列。
PDF 抓取的常見陷阱,以及如何避免
即使工具再好,也還是可能遇到一些坑。以下是我學到的經驗(有時是付出代價後才學會的):
- OCR 錯誤: 模糊掃描或奇怪字型,連最好的 OCR 都可能被難倒。盡量使用最清楚的 PDF,並再次檢查關鍵欄位。
- 複雜版面: 多欄或巢狀表格可能需要一點人工引導——可使用 Thunderbit 的手動選取或提示詞。
- 資料類型: 逗號很多的數字,或格式怪異的日期?匯出前先設定欄位類型,或在 Excel/Sheets 裡清理。
- 檔案大小/頁數限制: 超大 PDF?可以切成較小的檔案,或在批次作業中使用 Thunderbit 的雲端模式。
- AI「幻覺」: 這很少見,但 AI 偶爾可能猜欄位名稱或補上缺失資料。務必抽查輸出結果,特別是重要數字。
- 人工複核: 對於關鍵業務資料,還是做一次快速驗證比較好——自動化工具很準,但多一雙人眼永遠不會錯。
如果你真的卡住了,Thunderbit 的支援與社群也都能幫上忙。
結論與重點整理:讓 PDF 抓取真正為你的業務服務
來做個總結吧。以前從 PDF 擷取資料簡直是場惡夢——慢、容易出錯,又超級枯燥。但有了像 這樣的現代工具,現在它變得快速、準確,甚至可以說幾乎還挺好玩。
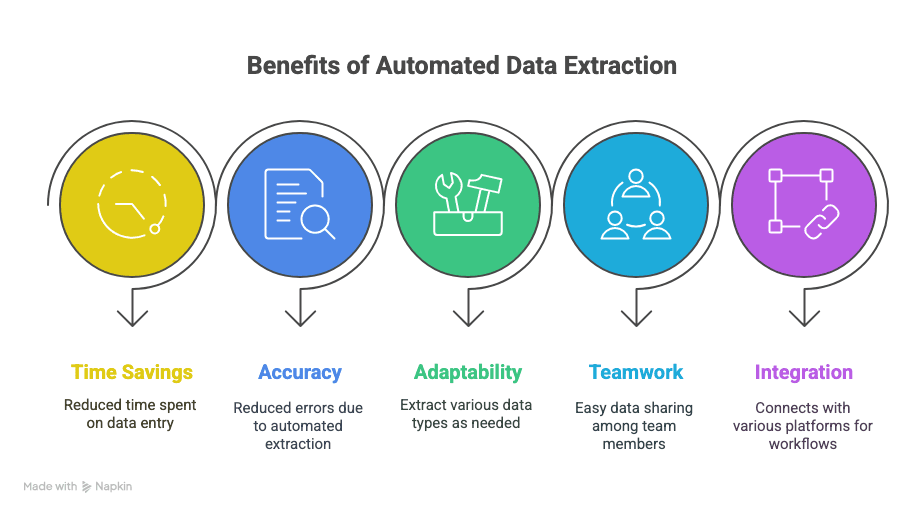
你會得到什麼?
- 省下時間: 節省數小時,甚至數週的人工資料輸入。
- 減少錯誤: 自動擷取能降低打錯字與漏列的情況。
- 更高彈性: 想抓什麼就抓什麼——文字、表格、圖片、連結,通通可以。
- 更好協作: 無論團隊成員在哪裡,都能即時共享資料。
- 更聰明的工作流程: 可與 Sheets、Notion、Airtable 等工具整合。
準備好試試看了嗎? 下載 ,拿下一份 PDF 來實測,看看生活可以輕鬆多少。未來的你(還有你的腕隧道)會感謝現在的決定。
想看更多技巧與指南,歡迎前往 ,或深入閱讀 。
讓我們把 PDF 帶來的頭痛,轉化為生產力的勝利——一次點擊,一次完成。
Shuai Guan,Thunderbit 共同創辦人暨執行長