
上週我花了整個下午,想讓一個 AI agent 在一個需要登入的入口網站上填寫供應商表單。到了第三個小時,我正盯著「Connection Refused」錯誤訊息,我的 VPS 也已經沒記憶體了,老實說,我差點就想全部改成手動處理。
這幾乎就是 OpenClaw 瀏覽器自動化的入門體驗。這套工具可以瀏覽頁面、擷取資料、填寫表單,還能用自然語言指令串起複雜流程——真的很強。但從「聽起來很厲害」到「在我電腦上真的能跑」之間,正是大多數人卡住的地方。
我在這條路的兩端都待過很久:一邊是在 Thunderbit 打造自動化工具,一邊是測試開源生態能提供什麼。這篇指南就是我當初最希望有人給我的版本:完整的安裝流程、最容易踩雷的瀏覽器模式選擇、原生 Windows 路線(因為不該把 WSL 當成必要條件)、反機器人存活指南、實際輸出範例、常見錯誤與真實修法,以及誠實評估 OpenClaw 什麼時候適合用、什麼時候其實太大材小用了。
用 AI 從任何網站擷取資料 Get Started Free
什麼是 OpenClaw 瀏覽器自動化?
OpenClaw 是一個免費、開源、採用 MIT 授權的 AI agent 平台,可以代替你控制瀏覽器。你不用寫 Selenium 腳本或 Puppeteer 程式碼,只要用自然語言描述你要做什麼——例如「進到這個頁面,抓出所有商品名稱和價格」——AI 就會自己想辦法完成。它使用一套編號快照系統:agent 會辨識頁面元素、替每個元素編上參考號,然後一步一步互動。
它的架構分成三個部分,所以安裝不只是裝個擴充功能那麼簡單:
- Gateway(VPS/伺服器): 負責處理指令並連接 LLM 的「大腦」,預設跑在 18789 連接埠。
- Node Host(本機): 讓 Gateway 可以把瀏覽器指令傳到你本機 Chrome 的中繼層,通常透過像 Tailscale 這類安全通道連線。
- Chrome Extension(Browser Relay): 讓 agent 可以直接控制你實際瀏覽器中的分頁。
另外還有 Control Service(18791)、CDP Relay(18792),以及受管理瀏覽器 CDP(18800–18899,最多支援 100 個平行設定檔)。
沒錯,這些元件真的不少。但一旦搞懂每個部分的角色,整個流程就會合理很多。你可以把它想成遙控車:Gateway 是遙控器,Node Host 是無線訊號,而 Chrome Extension 就是那台車本身。

為什麼 OpenClaw 瀏覽器自動化對商務團隊很重要
知識工作者有高達 60% 的時間 花在例行行政工作上,而不是高價值任務上,其中每天光是搜尋和蒐集資訊就要花 1.8 小時。Smartsheet 也發現,超過 40% 的員工 每週至少有四分之一的工時耗在手動、重複性的工作上。單是人工輸入資料,每名員工每年就讓美國企業平均損失約 $8,500。
這正是 OpenClaw 瀏覽器自動化要解決的問題。實務上,它對應到幾種常見的商務流程:
| 使用情境 | OpenClaw 的工作內容 | 商業成果 |
|---|---|---|
| 潛在客戶開發 | 從目錄與公司頁面抓取聯絡資訊 | 更快填滿銷售名單 |
| 競品價格監控 | 每日瀏覽商品頁並擷取價格 | 即時掌握競爭情資 |
| 表單填寫/資料輸入 | 填寫重複性的網頁表單(CRM、入口網站、申請表) | 每週省下數小時 |
| 內容監控 | 檢查競品部落格、職缺頁、新聞稿 | 提早發現競爭訊號 |
| QA/測試 | 跑完整個網頁流程,確認功能是否正常 | 降低使用者體驗破損的情況 |
AI agent 市場在 2025 年已達 $73.8 億美元,相較 2023 年的 37 億美元幾乎翻倍,而 88% 的組織 至少已在一項業務中使用 AI 自動化。這早就不是小眾領域了。
Sandbox Chromium、Browser Relay、Chrome Remote Debugging:如何選對模式
以我的經驗來看,選錯瀏覽器模式,是新手用 OpenClaw 時最常見也最惱人的問題。很多人花好幾個小時排查連線錯誤,其實如果一開始選對模式,根本不會發生。OpenClaw 提供三種連線方式,各有明顯取捨:
- Sandbox Chromium(受管理設定檔): OpenClaw 在伺服器上自行啟動無頭瀏覽器。沒有登入狀態、速度快、設定簡單——但更容易被反機器人系統偵測。
- Browser Relay(既有登入階段): 在你的本機跑一個 node host,把 VPS 的指令中繼到你實際使用的 Chrome。支援登入狀態與 cookies,並沿用你真實的瀏覽器指紋。
- Chrome Remote Debugging(Remote CDP): 透過 WebSocket URL 連接遠端瀏覽器。可完整存取工作階段,設定最複雜,但可搭配 Browserless 或 Browserbase 等雲端服務。
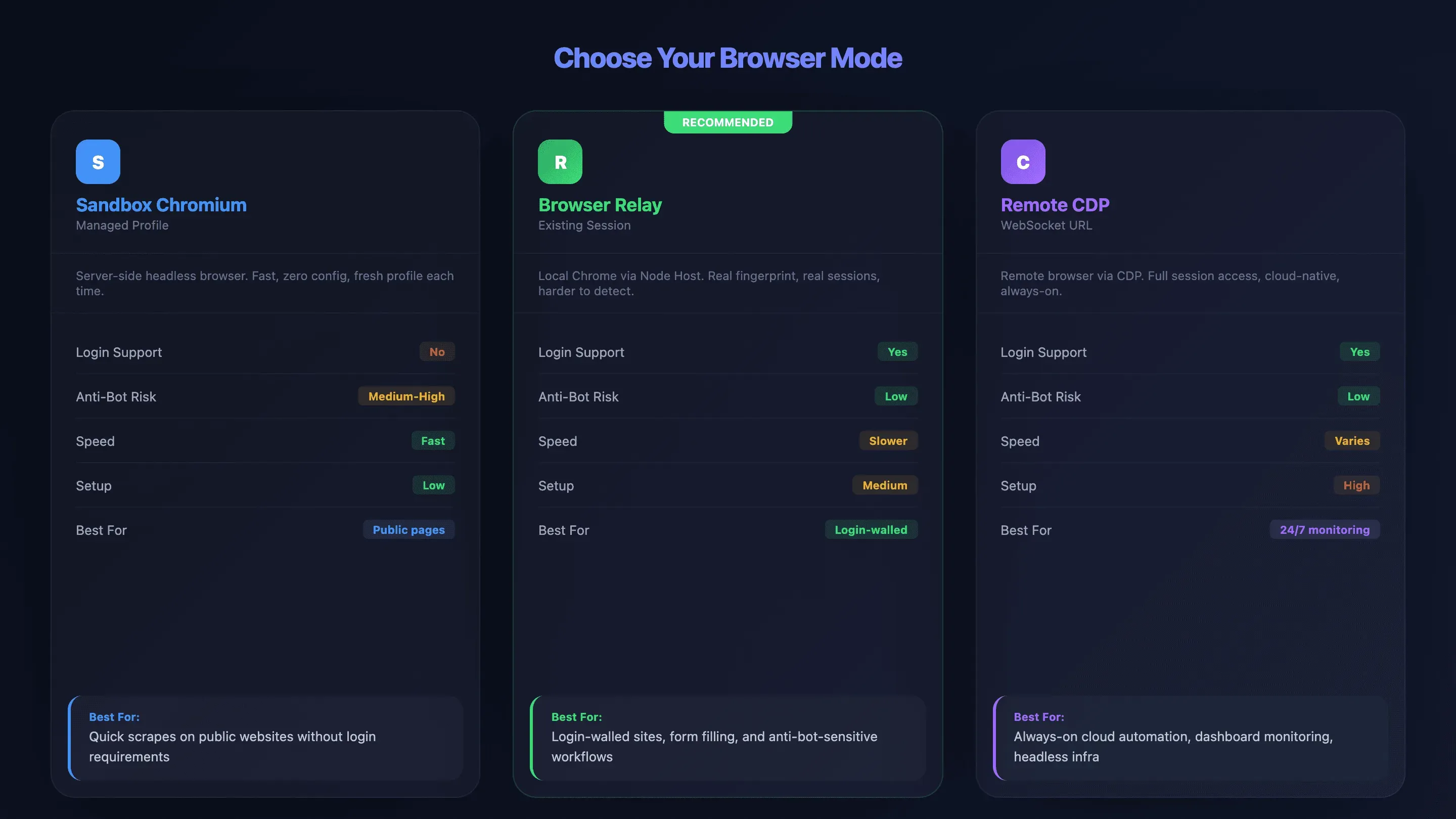
比較表:三種瀏覽器模式一次看懂
| 因素 | Sandbox Chromium | Browser Relay | Remote CDP |
|---|---|---|---|
| 登入支援 | ❌ 不支援(全新設定檔) | ✅ 支援(真實工作階段) | ✅ 支援(預先登入) |
| 反機器人風險 | ⚠️ 中高 | ✅ 低(真實指紋) | ✅ 低(由服務商管理) |
| 速度 | ✅ 快 | ⚠️ 較慢(經過網路中繼) | ⚠️ 視情況而定 |
| 設定難度 | 低 | 中 | 高 |
| 完整功能支援 | ✅ 是(全部功能) | ⚠️ 受限(不支援批次、下載攔截) | 取決於服務商 |
| 最適合 | 公開頁面、快速擷取 | 需要登入的網站、表單填寫 | 雲端基礎架構、全天候監控 |
決策流程圖:你該選哪一種模式?
照著這些問題依序判斷:
- 「你需要登入嗎?」——不需要 → Sandbox Chromium。需要 → 下一題。
- 「網站有很強的反機器人防護嗎?」——有 → Browser Relay(你的真實瀏覽器指紋比較不容易被偵測)。沒有 → Browser Relay 或 Remote CDP 都可以。
- 「你需要一個持續常駐的工作階段嗎?例如 24/7 監控儀表板?」——需要 → 搭配雲端服務使用 Remote CDP。不需要 → Browser Relay。
實際情境對照:
- 擷取公開的 Amazon 列表 → Sandbox Chromium
- 填寫登入後的 CRM 表單 → Browser Relay
- 全天候監控內部分析儀表板 → 搭配 Browserless/Browserbase 的 Remote CDP
這一步選對了,你真的可以省下好幾個小時的除錯時間。真的。
開始之前
- 難度: 中等(需要能接受 CLI)
- 所需時間: 完整安裝約 45–75 分鐘;每一步約 10–15 分鐘
- 你需要準備: 一台 VPS(至少 2GB RAM,建議 4GB)、Node.js v22.12.0+、Tailscale 帳號(免費即可)、Chrome 瀏覽器,以及耐心
步驟 1:在 VPS 上啟動 OpenClaw(或直接在本機跑)
VPS 是 OpenClaw「大腦」所在的位置。要讓它跑起來,有兩條路:
方案 A:一鍵式 VPS 主機方案
有些供應商提供預先設定好的 OpenClaw 映像:
| 供應商 | 起始價格 | 備註 |
|---|---|---|
| Hostinger | 每月 $6.99 起 | 預先設定映像 |
| Tencent Cloud Lighthouse | 約每年 ~$0.08 起(促銷) | 建議 2 核/4GB |
| Hetzner | 每月 $4.09 起(CX22) | 性價比高;需手動安裝 |
| DigitalOcean | 每月 $4 起 | 需手動安裝 |
| Vultr | 每月 $3.50 起 | 需手動安裝 |
方案 B:手動 CLI 安裝
# 透過 npm 安裝(需要 Node.js v22.12.0+)
npm install -g openclaw
# 執行導引精靈
openclaw onboard
# 產生 gateway token(請保存,node host 會用到)
openclaw doctor --generate-gateway-token
# 驗證設定
openclaw doctor --fix
最低規格: 2GB RAM(1GB 很容易當掉),建議 4GB。每個無頭瀏覽器實例閒置時會吃掉 400–800 MB。若你用 Docker,請設定 shm_size: '2gb'——這對穩定性非常重要。
完成這一步後,你應該已經讓 OpenClaw 跑起來,並且把 Gateway token 存在安全的地方。(我自己是放在密碼管理器裡。千萬別弄丟。)
步驟 2:設定 Tailscale 連接 VPS 與本機
Tailscale 會在你的 VPS 和本機裝置之間建立一條私有、加密的通道,讓瀏覽器指令不會直接暴露在公開網際網路上。考慮到 OpenClaw 在 2026 年初曾被 Kaspersky 標記出 512 個漏洞,跳過這一步不是好主意。
# 在 VPS 上
curl -fsSL https://tailscale.com/install.sh | sh
sudo tailscale up --ssh=true
# 記下 VPS 的 Tailscale IP(100.x.x.x)
# 設定 Gateway 監聽 Tailscale 網路
openclaw config set gateway.listen "100.x.x.x:18789"
在你的本機到 tailscale.com/download 安裝 Tailscale。兩台裝置必須使用同一個 Tailscale 帳號。
如果你不想用 Tailscale,也有替代方案:
| 因素 | Tailscale | Cloudflare Tunnel | WireGuard |
|---|---|---|---|
| 設定時間 | 5 分鐘 | 10–15 分鐘 | 20–30 分鐘 |
| 成本 | 免費(個人用途) | 免費 | 免費 |
| NAT 穿透 | 自動 | 自動 | 手動 |
這時你應該已經能從本機 ping 到 VPS 的 Tailscale IP。如果不行,請確認兩台裝置是否登入同一個 Tailscale 帳號。
步驟 3:在本機安裝 Node Host
Node Host 負責把 VPS Gateway 的瀏覽器指令轉送到你本機的 Chrome——它是伺服器與瀏覽器之間的翻譯層。
# 安裝 node host 套件
npm install -g @openclaw/node-host
# 設定步驟 1 取得的 gateway token
export OPENCLAW_GATEWAY_TOKEN="your-token-here"
# 啟動 node host,指向你的 VPS Tailscale IP
openclaw node install --host 100.x.x.x --port 18789
# 從 VPS 端核准連線
openclaw node approve <node-id>
你應該會看到 node 已成功連線並通過核准的提示。如果核准卡住,請重新啟動 VPS 上的 Gateway 程序。
步驟 4:安裝 OpenClaw Chrome 擴充功能
這個擴充功能讓 agent 可以直接控制瀏覽器分頁。你也可以在 Chrome Web Store 搜尋「OpenClaw Browser Relay」來安裝。
# 安裝擴充功能檔案
openclaw browser extension install
# 或手動安裝:
# 1. 開啟 chrome://extensions
# 2. 開啟「開發人員模式」(右上角切換)
# 3. 點選「載入未封裝項目」→ 選擇擴充功能資料夾
# 4. 釘選到工具列
# 5. 確認圖示狀態顯示「ON」
如果圖示顯示「ON」,就代表設定成功了。如果還是顯示「OFF」,請直接往下看疑難排解章節。
步驟 5:執行你的第一個 OpenClaw 瀏覽器自動化任務
先打開一個目標分頁,然後在 OpenClaw 聊天介面裡試一個簡單任務:
前往 https://books.toscrape.com,擷取此頁每一本書的標題與價格
預期流程: 指令送出 → agent 進行快照(以編號參考識別頁面元素)→ agent 擷取資料 → 回傳結構化輸出為 JSON 或 CSV。
根據我的經驗,先從超簡單的提示開始。把需求講得太細,反而可能讓 AI 混淆——只有在 agent 誤解你的第一個指令時,再慢慢補充細節。
如果第一頁有 20 本書,通常大約要 30–60 秒。只要有結構化資料回來,就代表你的 OpenClaw 瀏覽器自動化設定成功了。
Windows 上的 OpenClaw 瀏覽器自動化:原生安裝路線
大多數 OpenClaw 教學都預設你用的是 macOS 或 Linux。若你是 Windows 使用者,你應該已經感受到了差異。某位論壇使用者講得很到位:「很多方案概念上都很合理,但沒有一個是為原生 Windows 設計的。」
以下是實際可行的方法。
方案 A:Windows 上的 Chrome Remote Debugging(推薦的原生路線)
這是最可靠的 Windows 原生做法。打開 PowerShell,啟動 Chrome 並開啟遠端除錯:
& "C:\Program Files\Google\Chrome\Application\chrome.exe" --remote-debugging-port=9222
如果 Chrome 不在這個路徑,請試試:
# 檢查其他安裝位置
Get-ChildItem "C:\Program Files*\Google\Chrome\Application\chrome.exe" -Recurse
# 或檢查 AppData
& "$env:LOCALAPPDATA\Google\Chrome\Application\chrome.exe" --remote-debugging-port=9222
接著把 openclaw.json 裡的 cdpUrl 設成 ws://localhost:9222,讓 OpenClaw 透過 Remote CDP 連上去。
方案 B:Windows 上用 Docker Desktop 當備案
如果原生路線不穩,Windows 的 Docker Desktop 可以跑一個無頭 Chromium 容器:
docker run -d --name openclaw-browser -p 9222:9222 --shm-size=2g browserless/chrome
# 讓 OpenClaw 指向:cdpUrl: "ws://localhost:9222"
這會多一層複雜度,但對某些人來說更穩定。能用,只是不優雅。
Windows 專用錯誤清單
| 錯誤 | 原因 | 修正方法(PowerShell) |
|---|---|---|
| 9222 連接埠已被占用 | 其他 DevTools 工作階段正在使用 | `Get-Process -Id (Get-NetTCPConnection -LocalPort 9222).OwningProcess |
| 找不到 Chrome 執行檔 | 路徑不對 | Get-ChildItem "C:\Program Files*\Google\Chrome\Application\chrome.exe" -Recurse |
| Tailscale connection refused | Windows 防火牆擋住了 | New-NetFirewallRule -DisplayName "OpenClaw" -Direction Inbound -LocalPort 18789 -Protocol TCP -Action Allow |
| npm 權限錯誤 | 沒有用管理員權限執行 | 以 Administrator 身分開啟 PowerShell,或使用 nvm-windows |
上面的每個指令都是 PowerShell,不是 bash。可以直接複製貼上。
OpenClaw 瀏覽器自動化的反機器人求生指南
反機器人偵測,是 OpenClaw 使用者最常遇到的挫折。OpenClaw 預設的 Chromium 沒有內建隱匿機制——網站會透過 WebDriver 標記、螢幕尺寸、字型指紋與 IP 信譽來辨識它。我看過有些網站在幾秒內就把 agent 擋下來。
但處理方式有分層。先從最簡單的修法開始,真的不行再往上升級。
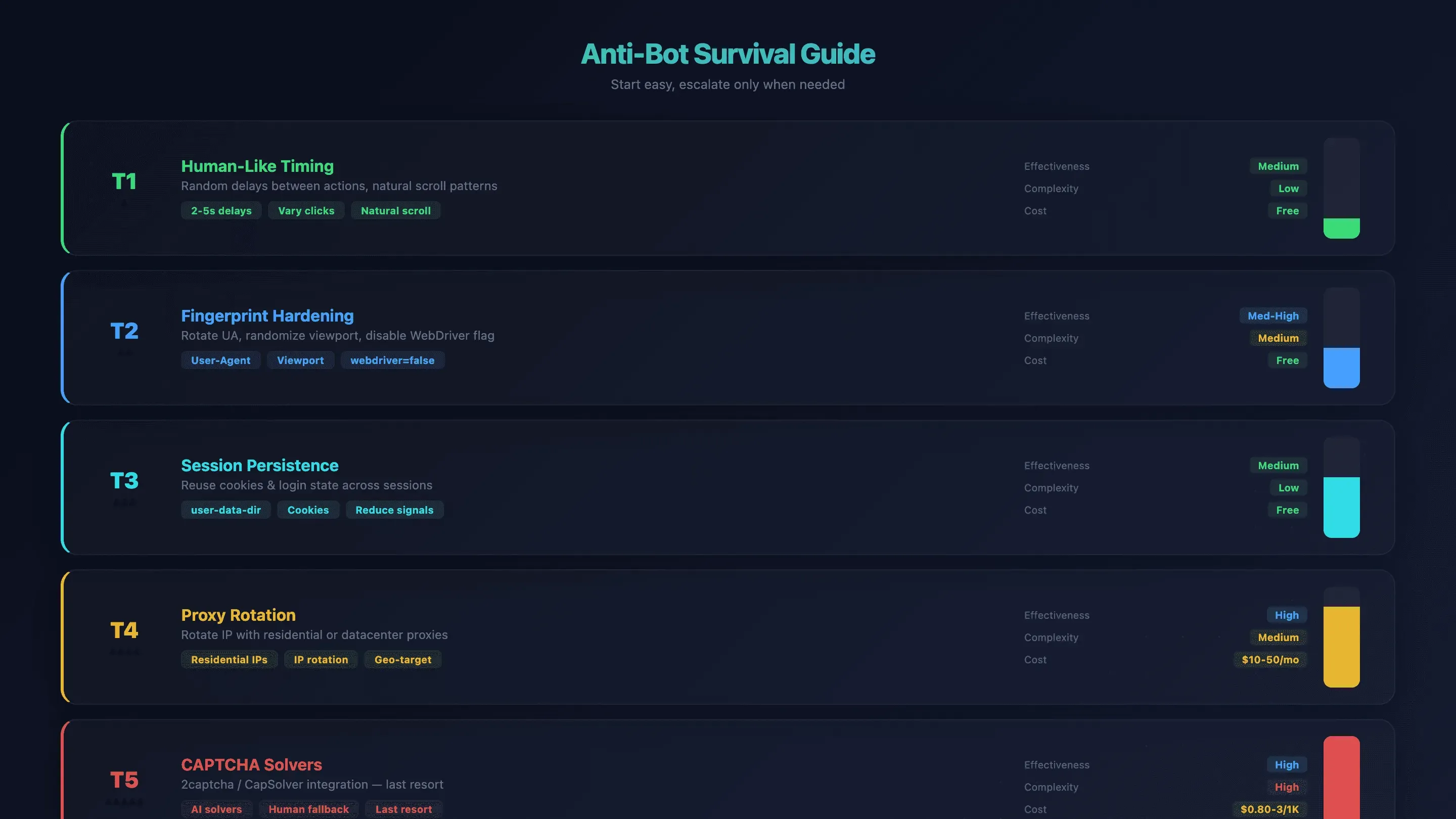
第 1 層:像人一樣的操作節奏
在提示詞中加入隨機延遲。不要讓 agent 像機器一樣狂點,請明確要求:「每次點擊之間等待 2–5 秒。」AI 本來就會有些微隨機性,但明確指示還是有幫助。
效果: 中等|複雜度: 低|成本: 免費
第 2 層:加強指紋保護
輪替 user-agent 字串、隨機化視窗大小,並讓 OpenClaw 自動關閉 navigator.webdriver 標記(透過 --disable-blink-features=AutomationControlled)。
# 設定自訂標頭
openclaw browser set headers --headers-json '{"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36"}'
# 隨機化視窗大小
openclaw browser set viewport 1366 768
# 設定時區與語系
openclaw browser set timezone America/New_York
openclaw browser set locale en-US
如果想要更進一步的反偵測方案,社群推薦 Camoufox(一款以 Firefox 為基礎的 anti-detect 瀏覽器,在 C++ 引擎層做指紋偽裝)。
效果: 中高|複雜度: 中|成本: 免費
第 3 層:保留登入工作階段
使用 user-data-dir 來保留 cookies 與登入狀態,避免每次都像新瀏覽器一樣,降低被反機器人系統盯上的機率。
openclaw config set browser.profiles.persistent.userDataDir "/path/to/chrome-profile"
openclaw config set browser.profiles.persistent.cdpPort 18802
效果: 中等|複雜度: 低|成本: 免費
第 4 層:輪換 Proxy
如果時間與指紋偽裝都不夠,就輪換 IP。住宅型 proxy 更難被偵測;資料中心型 proxy 速度更快、價格也更低。
export OPENCLAW_BROWSER_PROXY="http://user:pass@proxy.example.com:8080"
注意:瀏覽器層級的 proxy 設定目前仍屬於功能需求(GitHub Issue #8079)。目前必須在作業系統或環境變數層級設定 proxy。
| 供應商 | 住宅型 | 資料中心型 | 最適合 |
|---|---|---|---|
| Bright Data | $4–8.40/GB | $0.43–0.60/GB | 企業級、最高品質 |
| Oxylabs | $6–8/GB | $0.48–5/GB | 大規模擷取 |
| Decodo (Smartproxy) | $4–5.50/GB | $0.70–5/GB | 中階預算 |
| IPRoyal | $5–7/GB | -- | 省預算方案 |
| DataImpulse | $1/GB | -- | 最低成本 |
效果: 高|複雜度: 中|成本: 每月 $10–50
第 5 層:CAPTCHA 解題服務
最後手段。可整合 2captcha 或 CapSolver 這類服務。
| 服務 | reCAPTCHA v2 | Cloudflare Turnstile | 延遲 |
|---|---|---|---|
| 2Captcha | $2.99/1K | $2.99/1K | 15–45 秒(真人解題) |
| CapSolver | $0.80–1.50/1K | $0.80/1K | 0.5–10 秒(AI) |
| FlareSolverr(開源的 Cloudflare 繞過工具)在 2025–2026 年被記錄為不太可靠,因為 Cloudflare 的防護已經不斷升級。 |
效果: 高|複雜度: 高|成本: 每 1K 次解題 $0.80–3
反機器人總整理
| 技術 | 效果 | 複雜度 | 成本 |
|---|---|---|---|
| 像人一樣的節奏 | 中等 | 低 | 免費 |
| 指紋加固 | 中高 | 中 | 免費 |
| 保留工作階段 | 中等 | 低 | 免費 |
| Proxy 輪換 | 高 | 中 | 每月 $10–50 |
| CAPTCHA 解題服務 | 高 | 高 | 每 1K 次解題 $0.80–3 |
如果你一直撞上反機器人防線,只是單純想拿到資料:Thunderbit 的雲端擷取可以直接處理公開網站的反機器人機制——不用設定 proxy,也不用調整指紋。這是完全不同的做法(由託管雲端基礎架構,每次都重新讀取網站),能繞開標準資料擷取工作最常見的反機器人攻防戰。
實際輸出:OpenClaw 瀏覽器自動化到底會產生什麼
在投入 45–75 分鐘設定之前,你大概會想先看看最後會長什麼樣子。合理——下面我列三個工作流程範例,附上實際輸出。
範例 1:網頁爬取——擷取商品資料
提示詞:「前往 https://books.toscrape.com,擷取此頁每一本書的標題與價格」
輸出(前 5 筆):
| 標題 | 價格 |
|---|---|
| A Light in the Attic | £51.77 |
| Tipping the Velvet | £53.74 |
| Soumission | £50.10 |
| Sharp Objects | £47.82 |
| Sapiens: A Brief History of Humankind | £54.23 |
耗時: 第一頁 20 筆約 45 秒。若要分頁,需再補一句:「點 Next 按鈕,重複處理 5 頁。」總共約 100 筆,約 3 分鐘完成。
範例 2:表單自動化——填寫多欄位網頁表單
情境: 填寫一份供應商詢問表單,內容包含公司名稱、聯絡資訊與產品興趣。
agent 會先替表單建立快照,依參考號辨識每個欄位,再依序填入。前面是空白欄位,後面則全部填好,並出現確認訊息。任何下拉選單或核取方塊都會交由快照系統處理——agent 會「看見」選項並選對答案。
耗時: 6 個欄位約 30 秒。
範例 3:分頁處理——跨多頁擷取資料
初始結果: 第 1 頁得到 20 筆。當你下達「按 Next,處理所有頁面」後,在 books.toscrape.com 上總共擷取到 50 頁、1,000 筆資料。agent 會透過快照找到「Next」按鈕,然後在迴圈中連續點擊。
耗時: 完整 1,000 筆資料約 12 分鐘。
並排比較:同樣的擷取任務在 Thunderbit 中怎麼做
以同樣的 books.toscrape.com 範例來看,在 Thunderbit 的流程是這樣:
- 安裝 Thunderbit Chrome 擴充功能(約 30 秒)
- 開啟頁面
- 點選「AI Suggest Fields」→ AI 自動辨識 Title、Price、Availability、Rating
- 點選「Scrape」→ 擷取 20 筆資料
- 使用分頁控制 → 擷取所有頁面
- 匯出到 Google Sheets(免費)
總耗時:約 3 分鐘,從零開始到資料匯出完成,而且不需要 VPS、CLI 或任何設定。
重點不在於哪個工具絕對「比較好」,而是你真正想完成的是什麼。
什麼情況下 OpenClaw 瀏覽器自動化太大材小用了(以及替代方案)
OpenClaw 擅長的是複雜、多步驟、agent 式自動化——像是需要登入的工作流程、把瀏覽器操作和 shell 指令串在一起、在 VPS 上 24/7 執行。但如果你的目標只是「從列表頁擷取商品資料」或「從目錄抓出 email」,整套 VPS + Tailscale + node host 架構很可能太重了。
我看過有人為了一個 2 分鐘就能完成的任務,先花 60 多分鐘設定環境。這筆帳不太划算。
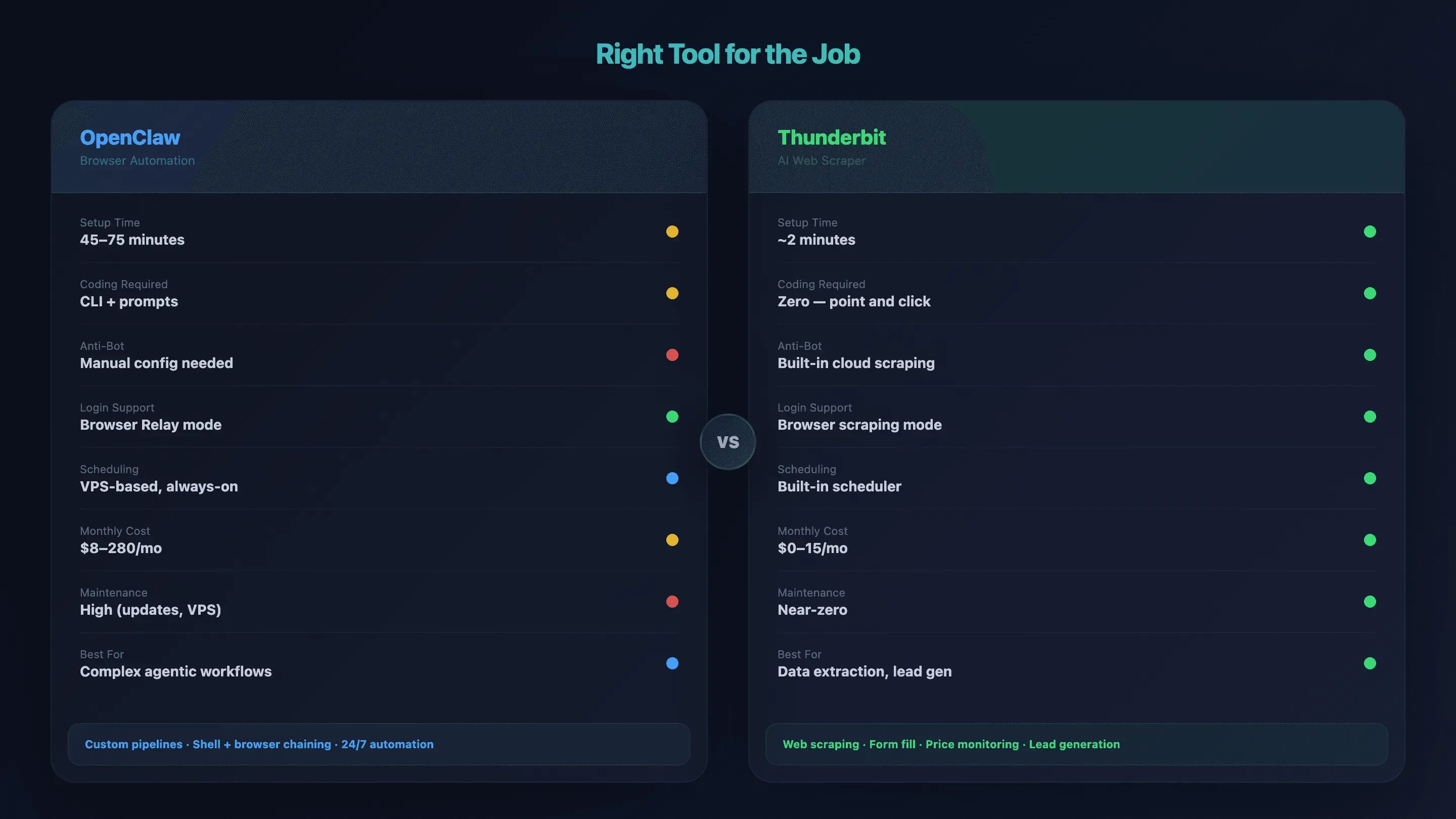
對症下藥:工具比較表
| 因素 | OpenClaw 瀏覽器自動化 | Thunderbit |
|---|---|---|
| 設定時間 | 45–75 分鐘(VPS + Tailscale + node host) | 約 2 分鐘(安裝 Chrome 擴充功能) |
| 是否需要寫程式 | CLI + 自然語言提示詞 | 完全不用——點「AI Suggest Fields」→「Scrape」即可 |
| 反機器人處理 | 手動(proxy、指紋設定) | 內建雲端擷取 |
| 需要登入的網站 | ✅ Browser Relay/遠端除錯 | ✅ 瀏覽器擷取模式 |
| 子頁面補強 | 每個流程都要自訂腳本 | 一鍵子頁面擷取 |
| 排程/24×7 執行 | 基於 VPS,常駐運作 | 內建排程爬蟲 |
| 每月成本 | $8–14(興趣用途)到 $110–280(高使用量) | $0(免費方案)到 $15/月 |
| 維護負擔 | 高(更新、VPS、除錯) | 幾乎為零——AI 會自動適應版面變動 |
| 最適合 | 複雜 agent 流程、自訂資料管線 | 資料擷取、表單填寫、名單開發、價格監控 |
使用情境導向
- 你需要多步驟的 agent 式工作流程,要把瀏覽器操作和 shell 指令、訊息工具、資料庫串起來 → OpenClaw 才是對的選擇。
- 你要從網站擷取資料、填表或監控價格,而且不想碰終端機 → Thunderbit 會更快幫你完成。 你也可以看看 Thunderbit YouTube 頻道 的快速示範。
- 你只需要一段針對單一 API 端點的輕量腳本 → 一個簡單的 Python requests 腳本可能就夠了。
這就是我在團隊裡有人問「這個任務該用什麼工具?」時,真的會採用的判斷框架。
OpenClaw 瀏覽器自動化常見錯誤與修復方式
請把這一段存起來。內容是按症狀整理的,方便你直接 Ctrl+F 找解法。
「Connection Refused」或 Node Host 無法連線
可能原因(請依序檢查):
- 兩台裝置都沒有啟動 Tailscale → 兩邊都執行
tailscale status - Gateway 還是只監聽 localhost,沒有改成 Tailscale 網路 →
openclaw config set gateway.listen "100.x.x.x:18789" - IP 位址錯了 → 用
tailscale ip -4再確認一次 - 防火牆擋住 18789 連接埠 →
sudo ufw allow 18789/tcp(Linux)或新增 Windows 防火牆規則
擴充功能圖示一直是「OFF」或分頁無法被偵測
- 擴充功能沒有用開發者模式載入 → 到
chrome://extensions啟用開發人員模式,然後重新載入 - Node Host 沒有執行 → 用
openclaw node start重新啟動 - Chrome 實例衝突 → 關掉所有 Chrome,重新啟動,再重載擴充功能
agent 回傳空白或錯誤資料
- 頁面還沒完全載入: 指示 agent「導航後先等待 3 秒再擷取」。很多 SPA 需要時間渲染。
- 被反機器人擋下: 檢查你看到的是 CAPTCHA 頁面還是真內容。把 Sandbox Chromium 換成 Browser Relay。
- 快照過期: 請 agent「重新建立快照」——導航後參考號會失效。
「Port 9222 Already in Use」
通常是 Chrome DevTools 或其他自動化工具已經在使用這個連接埠。
# macOS/Linux
lsof -i :9222 | grep LISTEN
kill -9 <PID>
# Windows PowerShell
Get-Process -Id (Get-NetTCPConnection -LocalPort 9222).OwningProcess | Stop-Process -Force
VPS 記憶體不足
每個無頭瀏覽器實例會使用 400–800 MB RAM。同時跑太多個,會讓小型 VPS 當掉。
修復方式:
- 停用圖片/CSS/字型載入:
openclaw browser network route --abort "**/*.{png,jpg,gif,css,woff2}" - 同時執行的實例數量限制在記憶體可承受範圍內
- Docker 設定中加入
shm_size: '2gb' - 啟用 session hibernation:
OPENCLAW_HIBERNATE_AFTER=300 - 如果真的需要更大餘裕,就升級到 4GB 以上 RAM 的 VPS
讓 OpenClaw 瀏覽器自動化穩定運作的小技巧
以下是我長期跑這些設定後整理出來的最佳做法:
- 在純資料擷取任務中關掉圖片、樣式表與字型。 這能大幅降低資源消耗,也會加快速度。
- 重複使用瀏覽器實例,不要每個任務都重新啟動。新的實例很吃 RAM,也更容易觸發反機器人訊號。
- 從簡單提示詞開始。 只有在 agent 誤解時再補充細節。講太多有時反而比幫助更大。
- 監控 VPS 資源用量(CPU、RAM),在碰到上限之前就先擴容。凌晨兩點遇到 VPS 當機,真的很難修。
- 保持 OpenClaw 和 Chrome 擴充功能更新——但先在測試環境驗證更新。OpenClaw 每月大約會發佈 13 個版本,而且不是每個版本都順順的。
- 對於持續、重複的任務(每天查價格、每週抓名單),Thunderbit 的排程爬蟲 可以讓你用自然語言設定間隔,之後就完全不用管 VPS 維護。
倫理與法律注意事項
簡短但重要。請尊重 robots.txt(已在 RFC 9309 中被 IETF 標準化)、控制請求頻率、檢查目標網站的服務條款,並依照 GDPR/隱私法規處理個人資料。hiQ v. LinkedIn 的判例(2022)確立了抓取公開可存取資料不違反 CFAA,但這不代表什麼都可以做。負責任地使用自動化,對你和你的公司都更有保障。想了解更多,可以參考我們的 網頁爬取法律影響 指南。
總結
OpenClaw 瀏覽器自動化是一個很強大的選擇,特別適合用自然語言控制的複雜、多步驟網頁流程。最重要的重點如下:
- 一開始就選對瀏覽器模式(Sandbox、Relay、Remote CDP)——這一個決定就能省下大量除錯時間。
- Windows 使用者有可行路線,但你需要照著 Windows 專用指令操作,並留意防火牆與路徑問題。
- 反機器人處理是真正的難題——先從最簡單的方法開始(節奏、指紋),需要再往上升級。
- 先看輸出,再決定要不要投入。 如果你只需要從列表頁拿到結構化資料,像 Thunderbit 這種無程式碼工具,幾分鐘就能上手,而且幾乎不用維護。
- 記得把維護成本算進去。 OpenClaw 每月大約會推出 13 個版本,VPS 成本也會累積,而除錯本來就是這套玩法的一部分。
如果你想先走簡單路線,Thunderbit 提供免費方案——先安裝擴充功能、擷取一個頁面,看看是否已經能滿足你的需求,再決定要不要投入完整的 VPS 架構。如果你最後還是選 OpenClaw,請把這篇指南存起來。你遲早會用到那份錯誤清單——也祝你的瀏覽器實例永遠有足夠的 RAM。
常見問題
OpenClaw Sandbox Chromium 和 Browser Relay 有什麼差別?
Sandbox Chromium 是在伺服器上跑無頭瀏覽器——速度快、設定簡單,但每次都會建立全新的設定檔(沒有登入狀態),而且更容易被反機器人系統偵測。Browser Relay 則是把指令轉送到你本機上的真實 Chrome,所以它支援登入、會沿用真實瀏覽器指紋,而且網站更難判斷它是自動化工具。代價是 Browser Relay 因為要透過網路中繼所以速度較慢,而且功能上有些限制(不支援批次動作、下載攔截)。
我可以在 Windows 上不靠 WSL 直接跑 OpenClaw 瀏覽器自動化嗎?
可以,但有一些限制。最穩定的原生 Windows 路線是透過 PowerShell 啟動 Chrome Remote Debugging(chrome.exe --remote-debugging-port=9222)。如果這個方案不穩,Docker Desktop 可以當備案。Windows 上完整的原生 Node Host 支援可能還有一些邊角問題——請以最新文件為準,並預期會遇到防火牆阻擋、執行檔路徑不同等 Windows 特有問題。本指南 Windows 章節中的所有指令都是 PowerShell,不是 bash。
在 OpenClaw 瀏覽器自動化中要怎麼處理 CAPTCHA?
先降低被偵測的機率:加入像人類一樣的操作節奏、加強瀏覽器指紋、並保留 session 以免每次都像新瀏覽器。如果 CAPTCHA 還是一直出現,就整合像 2captcha(每 1K 次解題 $2.99)或 CapSolver(每 1K 次 $0.80–1.50,AI 驅動)這類解題服務。若是公開網站而你只是單純要資料,Thunderbit 的雲端擷取可以自動處理反機器人問題,不需要任何 proxy 或 CAPTCHA 設定。
OpenClaw 瀏覽器自動化是免費的嗎?
OpenClaw 本身是開源的(MIT 授權),而且免費。不過執行它需要基礎設施——VPS 每月約 $4–15,加上可選的 proxy 輪換(每月 $10–50)或 CAPTCHA 解題服務(按次計費)。總月成本從興趣用途的 $8–14,到大量自動化工作負載的 $110–280 不等。相比之下,Thunderbit 的免費方案 可支援基本擷取,而且沒有基礎設施成本。
如果我的 OpenClaw agent 一直回傳空結果,該怎麼辦?
請依序檢查三件事:第一,頁面可能還沒載入完成——請指示 agent「導航後先等待 3 秒再擷取」。第二,你可能撞上反機器人牆——如果 agent 看到的是 CAPTCHA 頁而不是內容,請把 Sandbox Chromium 改成 Browser Relay。第三,快照參考號可能已過期——每次導航後都請 agent「重新建立快照」。如果以上都無效,請檢查 VPS 的記憶體使用量——瀏覽器實例如果已經崩潰,常常會默默回傳空結果。
試試 Thunderbit,更快完成網頁資料擷取 Get Started Free




