

到了 2026 年,網路世界比以往更狂野——如今全球一半的網際網路流量都來自機器人,而開源網頁爬蟲正是背後默默無名的功臣,從價格監控到 AI 訓練,樣樣都少不了它們。我在 SaaS 與自動化領域待了很多年,而我學到最重要的一件事就是:選對自架式爬蟲,能替團隊省下好幾個月的麻煩,甚至少掉幾次熬夜除錯。無論你是要抓取少量商品頁面,還是要為研究而爬取數百萬個 URL,這份清單中的開源 Firecrawl 替代方案都能滿足你——不管你的規模、技術棧或對複雜度的接受度如何。
但關鍵在於:沒有一套方案能通吃所有情境。有些團隊需要 Scrapy 的原始火力,或 Heritrix 的典藏級能力;也有人會覺得開源函式庫的維護成本太高。所以,接下來我們就來拆解 2026 年最值得關注的 9 個開源 Firecrawl 替代方案,看看各自的強項,並幫你把工具對準真正的業務需求——省去反覆試錯的痛苦。
如何為你的業務挑選最適合的開源 Firecrawl 替代方案
在深入清單之前,先談談策略。開源網頁爬取的選擇比以往更豐富,而你的決策應該取決於幾個關鍵因素:
- 易用性: 你想要的是點選式介面,還是能接受自己寫 Python、Go 或 JavaScript?
- 擴展性: 你只是要抓一個網站,還是得跨數百個網域爬取數百萬頁面?
- 內容類型: 目標網站是靜態 HTML,還是高度依賴 JavaScript 與動態載入?
- 整合需求: 你打算怎麼用這些資料——匯出到 Excel、送進資料庫,還是接到分析流程?
- 維護成本: 你有沒有資源維護自訂程式碼,還是想要能自動適應網站變動的工具?
下面這張速查表可以幫你快速判斷:
| 情境 | 最佳工具 |
|---|---|
| 無程式碼、離線瀏覽 | HTTrack |
| 大規模、多網域爬取 | Scrapy、Apache Nutch、StormCrawler |
| 動態/JavaScript 很重的網站 | Puppeteer |
| 需要表單自動化/登入 | MechanicalSoup |
| 靜態網站下載/封存 | Wget、HTTrack、Heritrix |
| Go 開發者、高效能需求 | Colly |
現在,讓我們一起看看 2026 年最值得關注的 9 個開源 Firecrawl 替代方案。
1. Scrapy:最適合大規模 Python 爬取

Scrapy 是開源網頁爬取領域的重量級冠軍。它以 Python 打造,是需要大規模爬取的開發者首選框架——像是數百萬頁面、頻繁更新、以及複雜的網站邏輯。
為什麼選 Scrapy?
- 超大規模: Scrapy 每秒可處理數千個請求,並被用於每月抓取數十億頁面的公司採用(Zyte)。
- 可擴充且模組化: 你可以撰寫自訂 spider、透過 middleware 接入代理、處理登入,並輸出成 JSON、CSV 或資料庫。
- 社群活躍: 有大量外掛、文件與 Stack Overflow 解答。
- 實戰驗證: 全球電商、新聞與研究團隊都在正式環境中使用它。
限制: 對非開發者來說學習曲線較陡,而且網站一變動,你就得維護自己的 spider。不過如果你追求的是完全控制與可擴展性,Scrapy 幾乎很難被超越。
2. Apache Nutch:最適合企業搜尋引擎
Apache Nutch 是開源爬蟲界的老前輩,專為企業級、網際網路規模的爬取而設計。如果你想打造自己的搜尋引擎,或要爬取數百萬個網域,Nutch 就是你的好夥伴。
為什麼選 Apache Nutch?
- Hadoop 驅動的大規模能力: 建構在 Hadoop 之上,Nutch 能在伺服器叢集間爬取數十億頁面(Common Crawl 就用它來爬取公開網路)。
- 批次爬取: 只要提供 seed URL 清單就能執行,非常適合排程型的大規模任務。
- 整合性: 可與 Solr、Elasticsearch 與大數據流程搭配使用。
限制: 設定複雜(像是 Hadoop 叢集、Java 設定檔),而且它更偏向原始爬取而不是結構化資料擷取。小型專案用它太重,但在網路規模爬取上幾乎無可匹敵。
3. Heritrix:最適合網頁封存與合規需求
Heritrix 是 Internet Archive 自家的爬蟲,專為網頁封存與數位保存而生。
為什麼選 Heritrix?
- 典藏級完整性: 可擷取每個頁面、資產與連結——非常適合法規遵循或歷史快照。
- WARC 輸出: 以標準化的 Web ARChive 檔案儲存所有內容,方便重播或分析。
- 網頁式管理介面: 可透過瀏覽器 UI 設定與監控爬取任務。
限制: 體積龐大(需要大量磁碟與記憶體)、不執行 JavaScript,而且輸出的是原始封存檔,而不是結構化資料表。最適合圖書館、檔案館或受監管產業。
4. Colly:最適合高效能 Go 開發者
Colly 是 Go 開發者的最愛——速度快、輕量,而且高度並行的網頁爬蟲。
為什麼選 Colly?
- 飛快的速度: Go 的並行能力讓 Colly 能以極低的 CPU/RAM 成本爬取數千頁面(Oxylabs)。
- 簡潔 API: 你可以為 HTML 元素定義回呼,自動處理 cookies 與 robots.txt。
- 很適合靜態網站: 非常適合伺服器端渲染頁面、API,或想把爬取功能整合進 Go 後端時使用。
限制: 沒有內建 JavaScript 渲染(處理動態網站時,你需要搭配像 Chromedp 這類工具),而且你得會 Go。
5. MechanicalSoup:最適合簡單表單自動化

MechanicalSoup 是一個 Python 函式庫,介於簡單 HTTP 請求與完整瀏覽器自動化之間。
為什麼選 MechanicalSoup?
- 表單自動化: 很容易登入、填寫表單與維持 session——非常適合抓取需要驗證登入的內容。
- 輕量: 底層使用 Requests 與 BeautifulSoup,因此速度快、部署也簡單。
- 互動型網站的好選擇: 如果你要提交搜尋表單,或登入後再抓資料,MechanicalSoup 是很好的選擇(Apify Blog)。
限制: 不支援 JavaScript 執行,所以無法處理 JavaScript 很重的網站。最適合靜態或伺服器端渲染、互動簡單的頁面。
6. Puppeteer:最適合動態與 JavaScript 很重的網站
Puppeteer 是現代 JavaScript 密集網站的瑞士刀。它是 Node.js 函式庫,讓你能完整控制無頭 Chrome 瀏覽器。
為什麼選 Puppeteer?
- 能處理動態內容: 可抓取 SPA、無限捲動,以及透過 AJAX 載入資料的頁面(Browserless Guide)。
- 模擬使用者行為: 點擊按鈕、填表、截圖,甚至還能透過外掛解 CAPTCHA。
- 強大的自動化能力: 很適合測試、監控,以及抓取真實使用者看得到的一切。
限制: 資源消耗高(需執行完整 Chrome 執行個體)、比純 HTTP 爬蟲慢,而且擴展時需要穩定的硬體或雲端編排能力。
7. Wget:最適合快速命令列下載

Wget 是下載靜態網站與檔案的經典命令列工具。
為什麼選 Wget?
- 簡單: 一個指令就能下載整個網站或資料夾——不需要寫程式。
- 速度快: 以 C 語言撰寫,因此快速又高效。
- 很適合靜態內容: 非常適合文件網站、部落格或大量檔案下載(HuggingFace Guide)。
限制: 不會執行 JavaScript,也不處理表單,而且下載的是原始頁面,不是結構化資料。你可以把它想成靜態網站的數位吸塵器。
8. HTTrack:最適合離線瀏覽(無程式碼)
HTTrack 就像 Wget 的親切版本,提供圖形介面來鏡像網站。
為什麼選 HTTrack?
- GUI 直覺: 逐步式精靈讓非技術使用者也能輕鬆上手。
- 離線瀏覽: 會自動調整連結,讓你可以在本機瀏覽鏡像網站。
- 很適合封存: 對研究人員、行銷人員,或任何想在不寫程式的情況下保存網站快照的人來說都很實用(Reddit DataHoarder)。
限制: 不支援動態內容、大型網站時可能較慢,而且不是為結構化資料擷取而設計的。
9. StormCrawler:最適合即時分散式爬取

StormCrawler 是現代化的分散式爬蟲,適合需要大規模即時、持續取得網路資料的團隊。
為什麼選 StormCrawler?
- 即時爬取: 建構於 Apache Storm 之上,能以串流方式處理資料——非常適合新聞監控或搜尋引擎(Wikipedia)。
- 模組化且可擴展: 可依需求加入解析、索引與自訂處理 bolts。
- 被 Common Crawl 使用: 為全球最大開放網頁封存之一的新聞資料集提供動力。
限制: 需要 Java 開發與 Storm 叢集,因此最適合有分散式系統經驗的團隊。對小型專案來說太重。
比較開源 Firecrawl 替代方案:哪個免費競品最適合你?
以下是這 9 個工具的並列比較:
| 工具 | 最佳使用情境 | 主要優勢 | 缺點 | 語言/設定 |
|---|---|---|---|---|
| Scrapy | 大規模、高頻爬取 | 強大、可擴展、社群龐大 | 學習曲線陡峭,需要 Python | Python 框架 |
| Apache Nutch | 企業級、網路規模爬取 | Hadoop 驅動、經過大規模驗證 | 設定複雜、偏向批次處理 | Java/Hadoop |
| Heritrix | 封存、合規爬取 | 可完整擷取網站、WARC 輸出 | 體積龐大、無 JS、原始封存檔 | Java 應用程式、網頁 UI |
| Colly | Go 開發者、高效能爬取 | 快速、API 簡潔、並行能力強 | 無 JS、需要 Go | Go 函式庫 |
| MechanicalSoup | 表單自動化、登入後爬取 | 輕量、可處理 session | 無 JS、規模有限 | Python 函式庫 |
| Puppeteer | 動態/JavaScript 很重的網站 | 完整瀏覽器控制、自動化能力強 | 資源消耗高、需要 Node.js | Node.js 函式庫 |
| Wget | 靜態網站下載、離線存取 | 簡單、快速、CLI | 無 JS、原始頁面 | 命令列工具 |
| HTTrack | 非技術使用者、網站封存 | GUI、離線瀏覽容易 | 無 JS、大型網站較慢 | 桌面應用程式(GUI) |
| StormCrawler | 即時、分散式爬取 | 可擴展、模組化、即時 | 需要 Java/Storm 經驗 | Java/Storm 叢集 |
你應該自己打造,還是使用現成的開源 Firecrawl 替代方案?
說實話:自己打造爬蟲聽起來很有趣——直到你真正陷入維護、代理與反爬機制的泥沼。上面這些開源工具都凝聚了多年實戰經驗與社群智慧。根據產業報告,使用現成方案是最快、最可靠的做法,也能避免重造輪子(IveerData)。
- 適合採用開源的情況: 你的需求與現有工具相符、你想縮短開發時間、而且很重視社群支援。
- 適合自己打造的情況: 你有真正獨特的需求、深厚的內部專業能力,而且爬取本身就是你業務的核心。
不過,當你把工程時間、伺服器維護,以及為對抗反爬措施而不斷更新的成本算進去時,開源其實並不真的「免費」。如果你想在不寫程式的情況下享受強大爬蟲的好處,還有另一個選擇。
加碼:如果開源太複雜,不妨試試 Thunderbit
雖然上面列出的工具對開發者來說都很驚人,但它們也有共同限制:需要程式知識、難以應對動態的 AI 反爬機制,而且必須持續維護。
Thunderbit 是我最推薦給想繞過這些限制的人的工具。它把強大的爬取能力與易用性之間的落差補了起來。
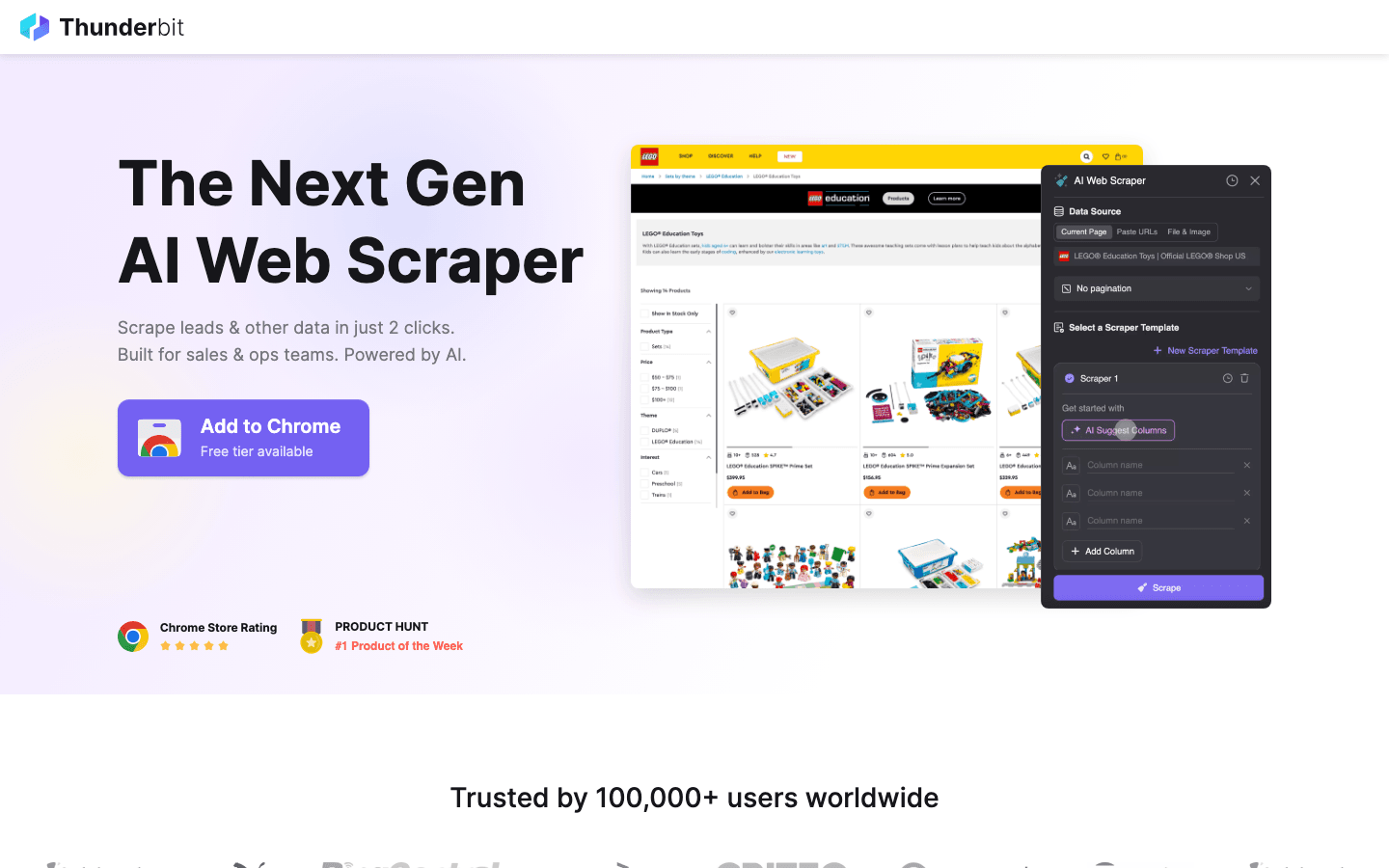
為什麼要考慮 Thunderbit,而不是開源方案?
- 完全不需要寫程式: 和 Scrapy 或 Puppeteer 不同,Thunderbit 是 AI 驅動的 Chrome 擴充功能。你只要點一下「AI 建議欄位」,它就會替你建立爬蟲。
- 處理麻煩內容: 動態內容、無限捲動與分頁都能由 AI 自動處理,幫你省下大量自訂腳本的時間。
- 立即匯出: 兩次點擊,就能從網站直接匯出到 Excel、Google Sheets 或 Notion。
- 免維護: 網站版面改了,你不用自己更新程式碼——Thunderbit 的 AI 會自動幫你適應。
如果你是銷售、行銷或研究人員,想要的是「現在就有」的資料,而不是去學 Python 或 Go,那麼 Thunderbit 就是這份開源工具清單的最佳補充。
想看看實際運作嗎?下載 Chrome 擴充功能 親自試試看。
結論:為 2026 年找到合適的自架式網頁爬蟲
閱讀更多網頁爬取指南 Get Started Free
開源 Firecrawl 替代方案的世界,比以往更豐富。無論你需要的是 Scrapy 或 Nutch 的原始規模,還是 Heritrix 的典藏準確性,都能找到對應的解法。重點是讓工具符合需求——如果只是快速抓資料,就別過度工程化;如果你是在網際網路規模爬取,就別捨不得投入。
也別忘了,如果開源路線實在太技術性、太耗時間,像 Thunderbit 這樣的 AI 工具隨時可以補上缺口。
準備好了嗎?可以先用 Scrapy 啟動你的下一個大型資料專案,或是試試 Thunderbit 來體驗簡單、AI 驅動的爬取。如果你想看更多網頁爬取技巧,歡迎到 Thunderbit Blog 看深度解析與教學。
常見問題
1. 使用開源 Firecrawl 替代方案的主要優勢是什麼?
開源替代方案提供彈性、成本節省,以及自架與自訂爬蟲的能力。你可以避免被供應商綁定,同時享有活躍的社群支援與更新。
2. 哪個工具最適合非技術使用者、又想快速看到結果?
HTTrack 是離線瀏覽很穩定的開源選擇。不過,如果你需要的是結構化資料擷取(例如 Excel 表格),我們會因為 AI 能力而推薦加碼工具 Thunderbit。
3. 我要怎麼處理動態、JavaScript 很重的網站?
Puppeteer 是最佳選擇——它能控制真實瀏覽器,因此可以抓取使用者看得到的任何內容,包括 SPA 與 AJAX 載入的資料。
4. 什麼時候該使用像 Apache Nutch 或 StormCrawler 這種重量級爬蟲?
如果你需要跨多個網域爬取數百萬頁面,或需要即時、分散式爬取(像搜尋引擎或新聞監控),這些工具就是為規模與可靠性而生。
5. 我應該自己打造爬蟲,還是使用現成的開源方案?
對大多數團隊來說,使用並客製化現成的開源工具更快、更便宜,也更可靠。只有在你有高度專門化需求、而且具備長期維護資源時,才值得自己打造。
祝你爬取順利——也願你的資料永遠新鮮、結構化,隨時可用。
免費試用 Thunderbit AI 網頁爬蟲 Get Started Free
了解更多




