現在網路對資料的需求比以往都還要強烈,到了 2025 年, 已經成為想要高效、聰明抓資料的團隊首選。不管你是做銷售、電商,還是像我一樣熱愛數據,應該都發現,網頁爬蟲早就不只是「抓資料」這麼簡單——速度、規模,還有怎麼閃過 IP 被封鎖,才是現在的重點。隨著網頁爬蟲市場預計從 2025 年的 74.8 億美元一路成長到 2034 年將近 384 億美元 (),競爭和挑戰只會越來越硬。
但現實是,現在的網站充滿動態內容、反爬蟲機制,還有一直在變的版型。我看過太多爬蟲因為沒注意細節或低估網站防禦而失敗。接下來就讓我們用實戰經驗、幽默感和實用建議,深入聊聊 Node.js 網頁爬蟲的高效技巧。
為什麼 Node.js 這麼適合做網頁爬蟲?
如果你有同時抓過幾百、幾千個網頁,就知道速度和同時處理能力有多重要。這正是 Node.js 的強項。它的 非同步、非阻塞 I/O 架構,天生就適合大量同時發送網路請求——根本就是網路世界的多工王 ()。其他語言可能還在等回應,Node.js 已經在事件迴圈裡繼續跑新任務,效率超高。
尤其是遇到需要即時更新或大規模資料擷取,還有目標網站大量用 JavaScript 的時候,Node.js 表現常常比 Python、Java 更亮眼。事實上, 現在都用 Node.js 處理後端和自動化任務,已經是全球最受歡迎的網頁技術之一。
Node.js 跟其他網頁爬蟲框架的比較
來點技術比較,看看 Node.js 跟其他主流框架有什麼不同:
| 框架 | 優勢 | 劣勢 | 最佳應用情境 |
|---|---|---|---|
| Node.js | 非同步高並發、npm 生態系龐大、原生 JS 適合動態網頁 | 記憶體消耗較高、callback hell(若未用 async/await) | 即時爬取、JS 動態網頁、可擴展微服務 |
| Python | 豐富的爬蟲套件(BeautifulSoup、Scrapy)、語法簡單 | 大量並發較慢、處理 JS 動態網頁較弱 | 靜態 HTML、研究、原型開發 |
| Java | 強型別、企業級穩定性 | 語法冗長、靈活度較低 | 大型、企業級爬蟲專案 |
| Go | 執行快、並發效率高 | 生態系較小、學習曲線較陡 | 高效能、低延遲爬蟲 |
對多數商業用戶來說,Node.js 兼具速度、彈性和對現代 JS 網站的適應力,是理想選擇 ()。
打造穩定的 Node.js 網頁爬蟲環境
一個厲害的爬蟲,從好的架構開始。我的建議如下:
- 專案結構: 模組化設計,建議用
/src、/libs、/config等資料夾。敏感資訊(API 金鑰、代理)用dotenv存在環境變數 ()。 - HTTP 請求: 推薦 、 或 。
- HTML 解析: 靜態頁面用 ,動態內容則用 或 Playwright。
- 輔助工具: 處理資料, 或 驗證資料。
- 測試與檢查: 用 Mocha 寫測試,ESLint 維護程式品質 ()。
必備 Node.js 網頁爬蟲套件
- axios/got/node-fetch: 處理 HTTP 請求。Axios 支援 Promise 和 JSON 處理,是我的最愛。
- Cheerio: 快速、類 jQuery 的 HTML 解析器,適合靜態頁面,解析速度大約 0.5 秒 ()。
- Puppeteer/Playwright: 無頭瀏覽器自動化,專門對付動態 JS 網站。速度較慢(每頁約 4 秒),但處理動態內容不可或缺 ()。
- dotenv: 管理環境變數。
- csv-writer/jsonfile: 輸出資料。
避開 Node.js 網頁爬蟲常見地雷
我看過太多爬蟲被封鎖、當掉或產生一堆亂資料。以下是常見錯誤和解法:
- 忽略 robots.txt 和服務條款: 開始爬之前一定要檢查,違規可能會被封 IP 甚至觸法 ()。
- 過度請求伺服器: 請求間隨機延遲(1–3 秒)、控制同時請求數,別像機器人一樣狂轟 ()。
- 沒處理好錯誤: 請求一定要用 try/catch 包起來,處理 HTTP 錯誤並記錄失敗。遇到暫時性錯誤時,建議用指數退避重試 ()。
- 忘記設置請求標頭: 用真實的 User-Agent 並定期更換,加上 Accept-Language、Referer 等標頭模擬真實瀏覽器 ()。
怎麼閃過反爬蟲機制
現在網站的反爬蟲技術越來越多,以下是我的應對招式:
- 代理與 IP 輪換: 用代理池並定期換 IP,降低被封風險 ()。
- 隨機化標頭: 每次請求隨機 User-Agent、Accept-Language 等標頭。
- 無頭瀏覽器隱身插件: 用像
puppeteer-extra-plugin-stealth這類插件,隱藏自動化痕跡。 - 模擬人類行為: 加入隨機延遲、滑鼠移動、滾動和打字錯誤 ()。
在 Node.js 爬蟲裡模擬人類行為
這招又有趣又實用。建議讓爬蟲:
- 動作間隨機等待(
await page.waitForTimeout(randomDelay)) - 滑鼠移動時有微小抖動(
page.mouse.move(x, y)) - 打字時隨機延遲還會偶爾打錯(
page.type(selector, text, {delay: random(100,200)})) - 滾動時不規則,不要一口氣到底
這些技巧能大幅提升在防護嚴密網站上的成功率 ()。
用 Thunderbit 讓資料擷取變簡單
說到重點:網頁爬蟲其實很難,但不一定要這麼難。這也是我們打造 的原因。
Thunderbit 是一款 人工智慧網頁爬蟲 Chrome 擴充功能,讓你用自然語言就能從任何網站擷取資料。只要點「AI 建議欄位」,AI 會自動辨識頁面內容,然後一鍵「抓取」。就像請了一個永遠不喊累、也不會跟你討加薪的助理工程師。
更棒的是,Thunderbit 還有 API,可以直接整合進你的 Node.js 流程。你不用再寫一堆爬蟲程式,Thunderbit 幫你搞定動態內容、子頁、分頁等麻煩細節。你只要拉取結構化資料(CSV、JSON,或直接匯入 Google Sheets、Airtable、Notion),任務就能輕鬆完成 ()。
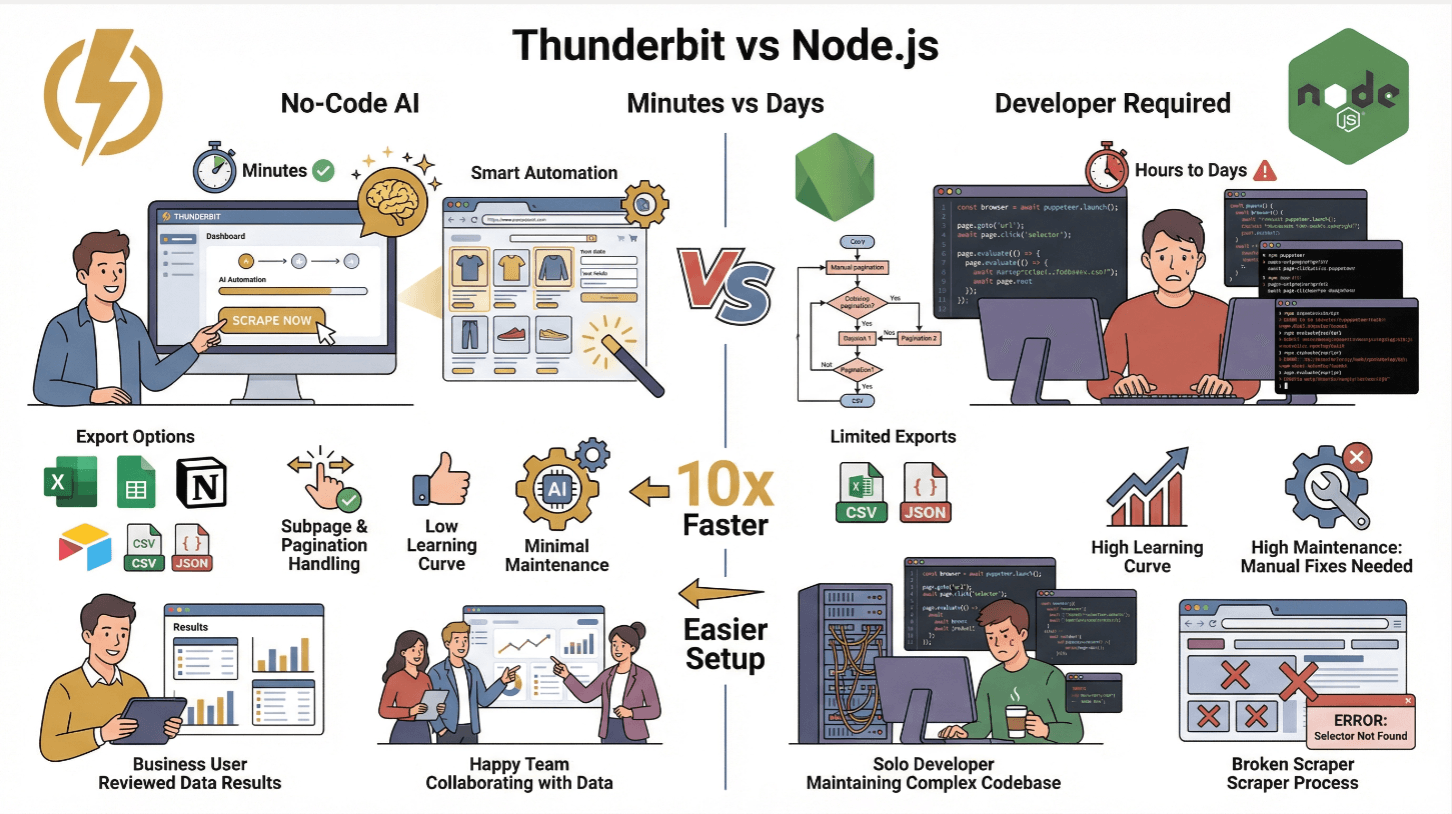
Thunderbit 跟傳統 Node.js 爬蟲的比較
| 功能 | Thunderbit | 傳統 Node.js 爬蟲 |
|---|---|---|
| 設定時間 | 幾分鐘(免寫程式) | 幾小時到幾天(需寫程式與測試) |
| 動態內容處理 | 支援(AI + 瀏覽器) | 支援(需用 Puppeteer/Playwright) |
| 子頁與分頁 | 一鍵完成 | 需手動撰寫程式 |
| 資料匯出 | Excel、Sheets、Notion、Airtable、CSV、JSON | CSV/JSON(需自訂程式) |
| 學習門檻 | 低(商業用戶友善) | 高(需開發經驗) |
| 維護成本 | 低(AI 自動適應) | 高(網站變動需手動修正) |
Thunderbit 超適合非技術團隊,或想省下寫程式時間、專心做數據分析的人。進階用戶也能透過 Thunderbit API 做大規模自動化 ()。
Cheerio + Puppeteer 動態內容混合用法
這是我最愛的 Node.js 爬蟲組合。步驟如下:
- 用 Puppeteer 載入網頁並執行 JavaScript(建議等到
networkidle,確保內容都載入)。 - 取得 HTML,用
await page.content()抓下完整頁面。 - 交給 Cheerio 解析:把 HTML 丟給 Cheerio,享受 jQuery 風格的快速資料擷取。
這種混合方式結合了 Puppeteer 處理動態內容的能力和 Cheerio 解析速度的優勢 ()。
效能小撇步: 只選你要的元素。Cheerio 會把整個 DOM 載入記憶體,避免用太廣的選擇器,重複抓同頁面可以考慮快取結果 ()。
HTML 解析與資料擷取優化建議
- 精準選擇器: 避免
$('body *'),只抓你要的內容。 - 大型頁面分流: HTML 太大可以分段處理或用串流。
- 快取渲染結果: 如果常常抓同一網址,建議快取 HTML。
- 資料驗證與清理: 用驗證套件確保資料品質,避免髒資料進資料庫 ()。
雲端大規模部署 Node.js 網頁爬蟲
想大規模抓資料?雲端化是必經之路。
- Docker 化爬蟲: 寫
Dockerfile,複製程式碼、安裝依賴、設定啟動點。 - 雲端部署: 小型任務可用 AWS EC2、Google Cloud Compute、Azure VM。大規模建議用 Kubernetes 或 AWS ECS/EKS、Google Cloud Run、Azure Kubernetes Service ()。
- Kubernetes 編排: 多 pod 並行,自動擴展,負載平衡分配網址。
- 排程任務: 用雲端排程器(CloudWatch Events、Cloud Scheduler)或 cron job 定時觸發。
實際案例裡,Kubernetes pod 從 5 擴展到 10,400 頁資料抓取時間從幾分鐘縮短到不到 1 分鐘 ()。
監控與自動擴展爬蟲基礎設施
- 日誌管理: 把日誌串流到 CloudWatch、Stackdriver 或 Datadog,設警報監控錯誤和延遲。
- 健康檢查: 用 Prometheus、Grafana 監控每分鐘抓取頁數、錯誤率和 pod 狀態。
- 自動擴展: 設定 Kubernetes HPA(水平自動擴展),根據 CPU 或請求數自動調整 pod 數量。
建議所有請求都實作指數退避重試,應對網路波動或暫時性封鎖。
資料儲存與後處理最佳做法
資料抓下來後,還要好好儲存和清理:
- 小型任務: 匯出 CSV、JSON,或直接推到 Google Sheets、Airtable、Notion(Thunderbit 內建支援)。
- 大型任務: 結構化資料用 SQL(MySQL/PostgreSQL),半結構化或彈性資料用 NoSQL(MongoDB、DynamoDB) ()。
- 雲端儲存: S3 或 Google Cloud Storage 存原始檔和備份。
- 資料清理: 驗證欄位、格式標準化(日期、數字)、去除重複。用 schema 驗證器確保資料品質 ()。
建議同時保留原始和清理後資料,方便日後重處理或除錯。
結論:Node.js 網頁爬蟲高效實戰重點
重點整理如下:
- 善用 Node.js 非同步優勢,大規模並發抓取,特別適合 JS 動態網頁。
- 工具組合靈活運用: 請求用 axios/got,靜態 HTML 用 Cheerio,動態內容用 Puppeteer,混合應用效率更高。
- 避開反爬陷阱: 輪換代理和標頭,模擬人類行為,遵守 robots.txt。
- 用 Thunderbit 簡化流程: 商業用戶或快速原型可用 ,AI 協助複雜資料擷取,API 可整合 Node.js。
- 大規模部署: Docker 化、Kubernetes 編排、全程監控確保穩定。
- 資料儲存與清理: 選對儲存方式,使用前一定要驗證資料。
網路世界只會越來越複雜,但只要掌握這些實戰技巧,你的 Node.js 網頁爬蟲就能一直高效又穩定,領先反爬技術一大步。如果你不想再半夜 debug selector,記得 Thunderbit 的 AI 隨時 standby。
想繼續學習?歡迎來 深入探索,或直接試用 ,體驗輕鬆抓資料的快感。
常見問題
1. 為什麼 Node.js 特別適合 2025 年的網頁爬蟲?
Node.js 的非同步事件驅動架構,能同時處理上千個請求,非常適合大規模或即時資料抓取。龐大的 npm 生態系和原生 JavaScript 支援,對現代 JS 網站尤其友善 ()。
2. 用 Node.js 爬蟲怎麼避免被封鎖?
建議用代理輪換、隨機化請求標頭、請求間隨機延遲,還有用 Puppeteer 模擬人類行為(滑鼠、滾動、打字)。一定要遵守 robots.txt 和網站規範 ()。
3. Node.js 爬蟲什麼時候該用 Cheerio,什麼時候該用 Puppeteer?
靜態 HTML(資料直接在原始碼裡)用 Cheerio 解析最快。遇到需要 JavaScript 動態載入的網站,就用 Puppeteer。最好的做法是先用 Puppeteer 渲染,再交給 Cheerio 解析 ()。
4. Thunderbit 怎麼簡化 Node.js 網頁爬蟲?
Thunderbit 讓你用 AI 和自然語言提示,完全不用寫程式就能抓結構化資料。自動處理動態內容、子頁、分頁,還有 API 方便 Node.js 整合。資料可直接匯出到 Excel、Google Sheets、Airtable 或 Notion ()。
5. 如何在雲端擴展和監控 Node.js 爬蟲?
把爬蟲 Docker 化,部署到 Kubernetes 或雲端服務,利用自動擴展應對流量高峰。用 CloudWatch、Prometheus 等工具監控日誌和指標,設警報監控錯誤和延遲 ()。
想讓你的網頁爬蟲更強大?不妨試試 Thunderbit,讓你的爬蟲又快又穩,永遠領先一步。
延伸閱讀