一項以爬取為基礎的研究,探討高流量網站如何為大型語言模型發布可機器讀取的指引、早期實作長什麼樣子,以及為什麼衡量採用情況不能只看 HTTP 200 回應數量。
- 資料集:
data/llms_probe_results_top_10000.csv - Tranco 清單下載時間:2026 年 5 月 6 日
- 範圍:根目錄的
/llms.txt與/llms-full.txt
關鍵指標
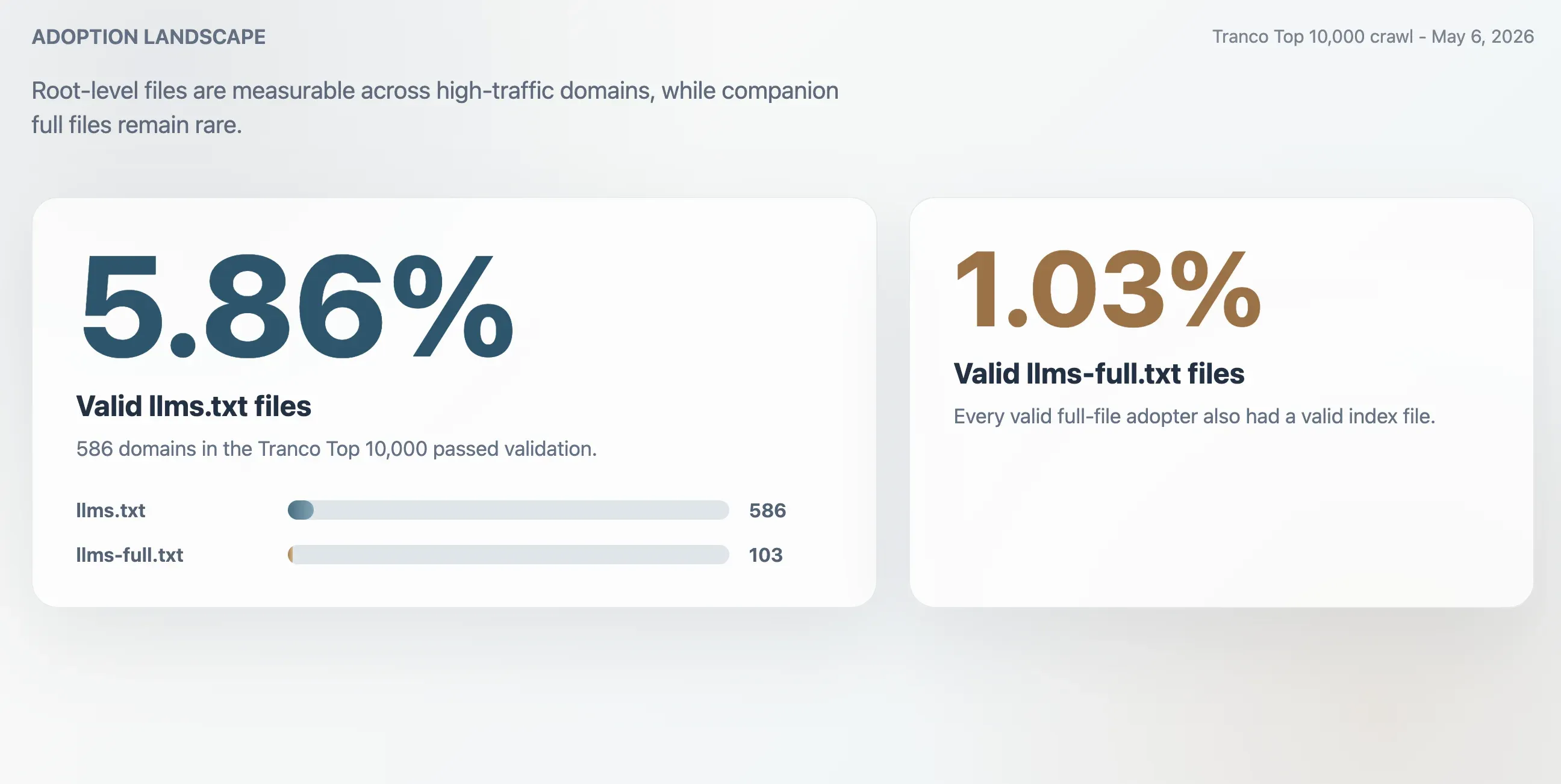
- 5.86%:Tranco Top 10,000 中有效
llms.txt的採用率,對應 586 個網域。 - 1.03%:有效
llms-full.txt的採用率,對應 103 個網域。所有有效 full-file 採用者也都有有效的 index 檔。 - 63.51%:
/llms.txt的 HTTP 200 回應中,未通過驗證的占比。 - 2.74 倍:若只用原始 HTTP 200 回應來衡量採用率,估計會高估的倍數。
執行摘要
llms.txt 仍然是一種早期的網路慣例,但它已不再只是邊緣實驗。這項研究在 2026 年 5 月 6 日爬取 Tranco Top 10,000 網域時,找到了 586 個有效的 llms.txt 檔案,觀察到的採用率為 5.86%。搭配的 llms-full.txt 檔案則少得多:只有 103 個網域有有效的 full file,採用率為 1.03%。
最重要的方法論發現是:狀態碼並不是衡量採用的好代理。爬蟲對 /llms.txt 觀察到 1,606 次 HTTP 200 回應,但只有 586 次通過驗證。其餘 1,020 次多半是跳轉到非目標頁面、一般 HTML 頁面、空白內容,或其他無效回應。若天真的爬蟲把每個 200 回應都算作採用,會把有效採用率高估約 2.74 倍。
在有效採用者之中,實作品質比單純的佔位符敘事更高。有效檔案的中位大小約為 7.1 KB,61.77% 的有效檔案大於 5 KB,70.82% 含有六個以上的 Markdown 區段,77.47% 含有 11 個以上的 Markdown 連結。早期採用者包括 Cloudflare、Azure、GitHub、DigiCert、WordPress.org、Adobe、Dropbox、PayPal、Stripe、Salesforce、Slack、Zendesk、Okta、Datadog 與 Cloudinary。
llms.txt最適合被理解為一種提供給 AI 系統的說明與導覽訊號,而不是robots.txt的替代品。它的價值不只是檔案存在,而是這份檔案能否幫助機器找到權威、精簡且最新的資訊。
背景:網路正在加入面向 AI 的訊號
網站長期以來會使用 robots.txt 來表達爬蟲偏好、用 sitemap.xml 來改善網址發現,並透過結構化資料幫助搜尋與平台系統理解頁面。生成式 AI 帶來了不同的問題。內容可能被用於訓練、檢索、摘要、代理式瀏覽、程式碼輔助、客服與答案生成。這就同時產生兩種需求:出版者希望對自動化使用有更多控制,但也希望 AI 系統在互動時能找到正確的權威資訊。
,由 Jeremy Howard 於 2024 年提出,將此檔案定位為放在網站根目錄的 Markdown 文件,用來在推論時提供適合 LLM 的資訊。這個提案主張,HTML 頁面往往包含導覽、廣告、腳本與其他雜訊,讓語言模型更難處理。精簡的 Markdown 檔可以把模型導向最重要的頁面、文件、API、範例、政策與產品資訊。
外部網路研究提供了更大的背景。 描述 robots.txt 與服務條款中的 AI 相關限制迅速增加,並指出現有的網路同意機制並不是為大規模 AI 資料重用而設計。 也讓 AI 爬蟲與 robots.txt 的模式在 Top 10,000 網域層級變得可見。在這樣的環境下,llms.txt 位在 AI 訊號的建設性一側:不是「不要爬這裡」,而是「如果你要理解這個網站,請從這裡開始」。
外部證據與採用爭論
關於 llms.txt 的公開爭論主要分成兩種說法。樂觀派認為,這個檔案能為 AI 系統提供更乾淨、更有效率的權威內容路徑。懷疑派則認為,沒有任何主要 LLM 供應商公開承諾會把它當成排名、爬取或引用訊號,因此出版者不應只因為有這個檔案就期待流量提升。這次更新所檢視的三份外部參考,支持一個更細緻的結論:llms.txt 是有用的基礎設施,但它對直接流量的影響證據仍然有限,且高度依賴情境。
外部採用基準正在快速變化
回報,截至 2025 年 6 月 22 日,前 1,000 個網站的採用率為 0.3%,也就是 1,000 個網站中有 3 個。其方式是每月自動掃描 domain.com/llms.txt,並透過驗證排除重新導向與 HTML 回應。這種方法在方向上與本研究較保守的驗證流程相似。
結果差距很大:本研究在 2026 年 5 月 6 日對 Tranco Top 1,000 找到 75 個有效 llms.txt 檔案,採用率為 7.50%。這兩個數字不應被視為嚴格的時間序列,因為排名來源、實作細節、驗證邏輯與爬取時間都可能不同。不過,這個對比仍顯示:從 2025 年中到 2026 年 5 月,採用情況出現了明顯變化,特別是在開發者、SaaS、雲端、安全與文件密集型網站中。
| 來源 | 快照時間 | 樣本 | 報告的有效採用率 | 解讀 |
|---|---|---|---|---|
| Rankability | 2025 年 6 月 22 日 | 前 1,000 個網站 | 0.3% | 2025 年中期顯示採用率仍非常低的早期公開基準。 |
| 本研究 | 2026 年 5 月 6 日 | Tranco Top 1,000 | 7.50% | 後期爬取顯示高流量網站已出現可見採用。 |
| 本研究 | 2026 年 5 月 6 日 | Tranco Top 10,000 | 5.86% | 更廣樣本顯示採用可被量化,但尚未成為主流。 |
流量實驗仍然結論不一
於 2026 年 1 月發布一項 10 個網站的分析,追蹤每個網站在導入前後各 90 天的表現。文章指出,兩個網站的 AI 流量分別成長 12.5% 與 25%,八個沒有可測量的改善,另有一個下降 19.7%。其核心解讀是因果上需要謹慎:那兩個看似成功的案例,同時也推出了新版型、重建資源中心、加入可抽取的比較表、獲得媒體報導、修正技術問題,或發布新的 FAQ 式內容。以這個框架來看,llms.txt 比較像是在記錄更強的內容與技術工作;它本身似乎不是成長的單一原因。
則從較小規模的站點觀察得出較正面的結論。他在加入 llms.txt 與 llms-full.txt 後,比較 Yandex.Metrica 中兩段各四個月的期間。LLM 轉介工作階段從 75 增加到 92,成長 23%;使用者數從 51 增加到 64。Perplexity 的工作階段從 29 增加到 55,而 ChatGPT 的工作階段則從 31 降到 26。同一篇文章也指出,總轉介流量成長更快,從 160 增加到 290 次工作階段,因此 LLM 工作階段占比從 47% 降到 32%。
| 證據類型 | 觀察結果 | 主要注意事項 | 對本報告的影響 |
|---|---|---|---|
| Search Engine Land 的 10 站點前後比較研究 | 兩個網站上升、八個無明顯變化、一個下降。 | 正面案例同時發生了內容、公關與技術變更。 | 支持把 llms.txt 視為基礎設施,而不是單獨的成長槓桿。 |
| Alimbekov 個人部落格前後觀察 | LLM 轉介工作階段在後期期間增加 23%。 | 沒有控制組;總轉介流量增加 81%,而 LLM 占比下降。 | 暗示對技術型部落格可能有上行空間,尤其來自 Perplexity,但因果尚未隔離。 |
| 本次以爬取為基礎的採用研究 | 586 個有效檔案與大量結構化實作。 | 衡量的是存在與結構,不是下游流量影響。 | 顯示採用與實作成熟度,但本身不能代表 ROI。 |
這場爭論真正釐清了什麼
外部證據讓這份資料集的解讀更清楚。結構良好的 llms.txt 可以降低機器解析的摩擦,特別適合開發者文件、API 參考與知識庫內容。但最強的流量案例,似乎仍然取決於那些本來就有用、可抽取、具權威性且容易被發現的內容。因此,實際問題不應只是單獨問「llms.txt 重要嗎?」而是這份檔案是否屬於更大的 AI 可讀內容系統的一部分。
更新後的解讀:
llms.txt應被視為低成本的 AI 面向基礎設施來實作,而不應被定位為更好的文件、結構化內容、技術可近性、引用、連結或品牌權威的替代品。
方法論
本研究以 Tranco Top 10,000 網域作為樣本。Tranco 是一個以研究為導向的熱門網站排名系統,設計上比許多傳統 Top 清單更穩定,也更能抵抗操縱。Tranco 來源檔於 2026 年 5 月 6 日下載,來源的 Last-Modified 時間戳為 2026 年 5 月 5 日 22:17:59 GMT。
爬蟲針對每個網域測試兩個根目錄路徑:
https://example.com/llms.txt,必要時使用 HTTP 備援。https://example.com/llms-full.txt,必要時使用 HTTP 備援。
對於每次探測,爬蟲都會記錄狀態碼、最終 URL、抓取方式、回應位元組數、內容類型、錯誤訊息、耗時與驗證結果。成功的回應本文會儲存在 raw_llms_txt/,供檢視與進一步分析。
驗證規則
只有在回傳成功本文、且看起來不像一般網站備援頁面的情況下,才會被計為有效檔案。最終 URL 路徑必須維持在 /llms.txt 或 /llms-full.txt。空白內容會被拒絕。明顯的 HTML 文件與應用程式外殼會被拒絕。內容類型僅作為輔助證據,而不是唯一規則,因為少數有效的類文字檔案是以非典型內容類型提供的。
採用概況
爬取結果在 Tranco Top 10,000 中找到 586 個有效的 llms.txt 檔案。有效採用率為 5.86%。較小的 llms-full.txt 搭配檔則在 103 個網域上存在且有效,占樣本的 1.03%。
| 指標 | 數量 | 占 Top 10,000 比例 |
|---|---|---|
| 已爬取網域 | 10,000 | 100.00% |
| 有效 llms.txt 檔案 | 586 | 5.86% |
| 有效 llms-full.txt 檔案 | 103 | 1.03% |
| /llms.txt 的 HTTP 200 回應 | 1,606 | 16.06% |
| 被判定為無效的 HTTP 200 回應 | 1,020 | 10.20% |
採用並不只集中在最頂端
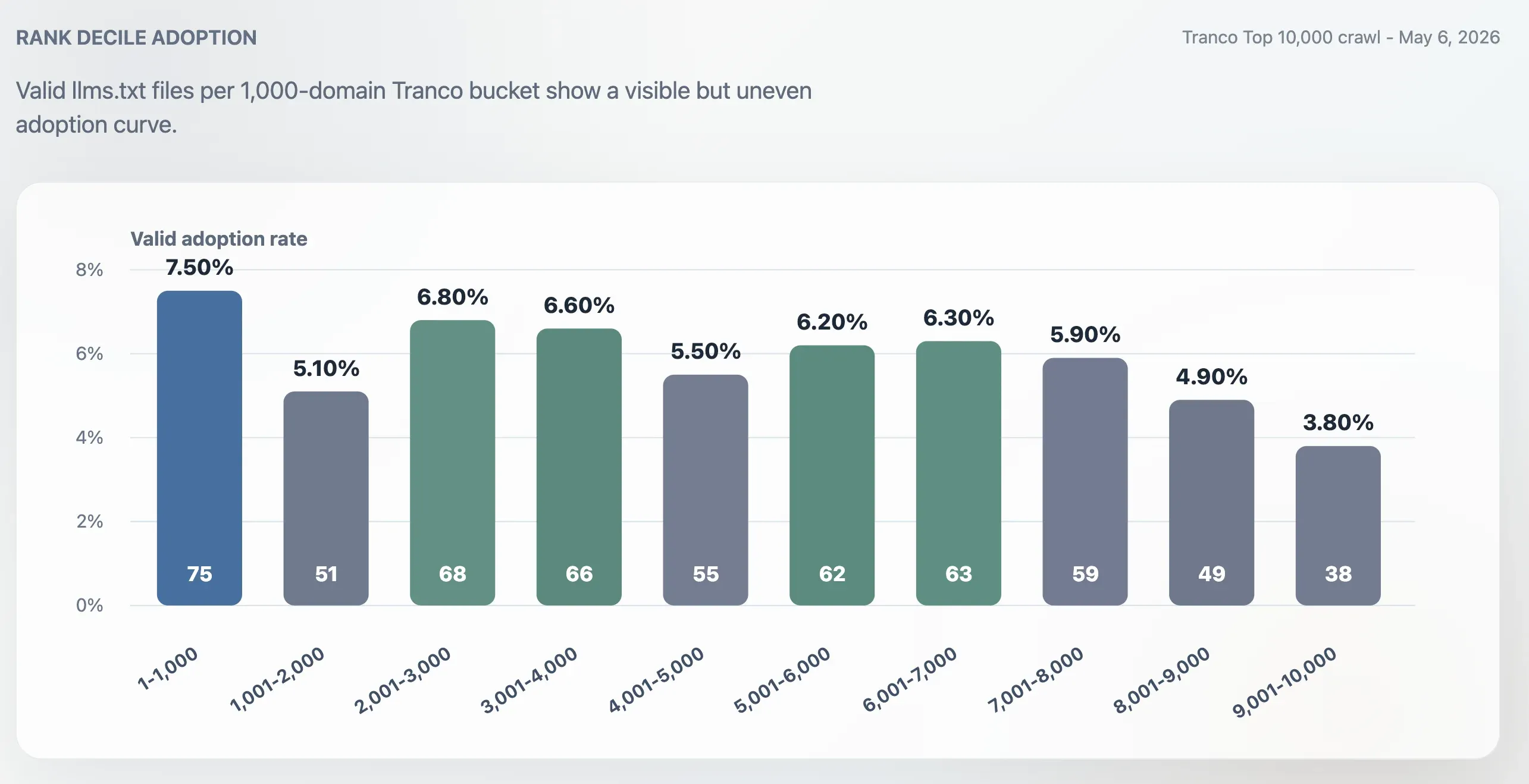
在前 1,000 名中的採用率高於完整 Top 10,000,但並不只集中在最頂尖的大型網站。前 1,000 名的採用率為 7.50%。最後一個 1,000 網域區間,也就是第 9,001–10,000 名,則降到 3.80%。排名中段仍然活躍:第 2,001–3,000、3,001–4,000、5,001–6,000,以及 6,001–7,000 區間都落在約 6% 左右。
早期採用者
排名最高的有效採用者是 Tranco 排名第 4 的 Cloudflare。其他高排名採用者包括 Azure、GitHub、DigiCert、WordPress.org、Adobe、Sentry、Dropbox、PayPal、Shopify、Taboola、Avast、Weather.com、Oxylabs、SourceForge、Cisco、Stripe、Slack、Dell、NVIDIA、Indeed、Zendesk、Calendly、Palo Alto Networks、Okta、Braze、Klaviyo、Intercom、Datadog、Cloudinary、ClassLink 與 OneSignal。
這些採用者並非隨機出現。它們通常具有龐大的文件表面、需要說明的產品線、API 或開發者生態系、支援內容、定價頁、安全與隱私材料,以及足以在意 AI 系統如何解讀其網站的品牌權威。
| 排名 | 網域 | 檔案大小 | 觀察到的模式 |
|---|---|---|---|
| 4 | cloudflare.com | 4,225 B | 精簡的產品、開發者、公司與定價索引。 |
| 26 | azure.com | 47,037 B | 開發者工具、AI、運算、儲存、安全、監控與選用資源。 |
| 28 | github.com | 27,108 B | 程式化存取、Copilot、MCP、REST API、Actions、儲存庫與 CLI 連結。 |
| 248 | stripe.com | 64,229 B | Payments、Connect、Checkout、Billing、Tax、Atlas、Radar 與開發者文件。 |
| 265 | salesforce.com | 1.02 MB | 大型產品與 Agentforce 連結目錄,且沒有 Markdown 區段標題。 |
前 1,000 名採用者的類別
本研究根據網域背景、第一層標題、原始檔案結構與內容關鍵詞,將 Tranco Top 1,000 中 75 個有效採用者進行分類。最大類別是行銷、媒體與 adtech,占 22.67%。雲端、開發者與基礎設施網站占 20.00%。SaaS、生產力與客戶營運網站占 17.33%。安全、身分與隱私網站占 12.00%。
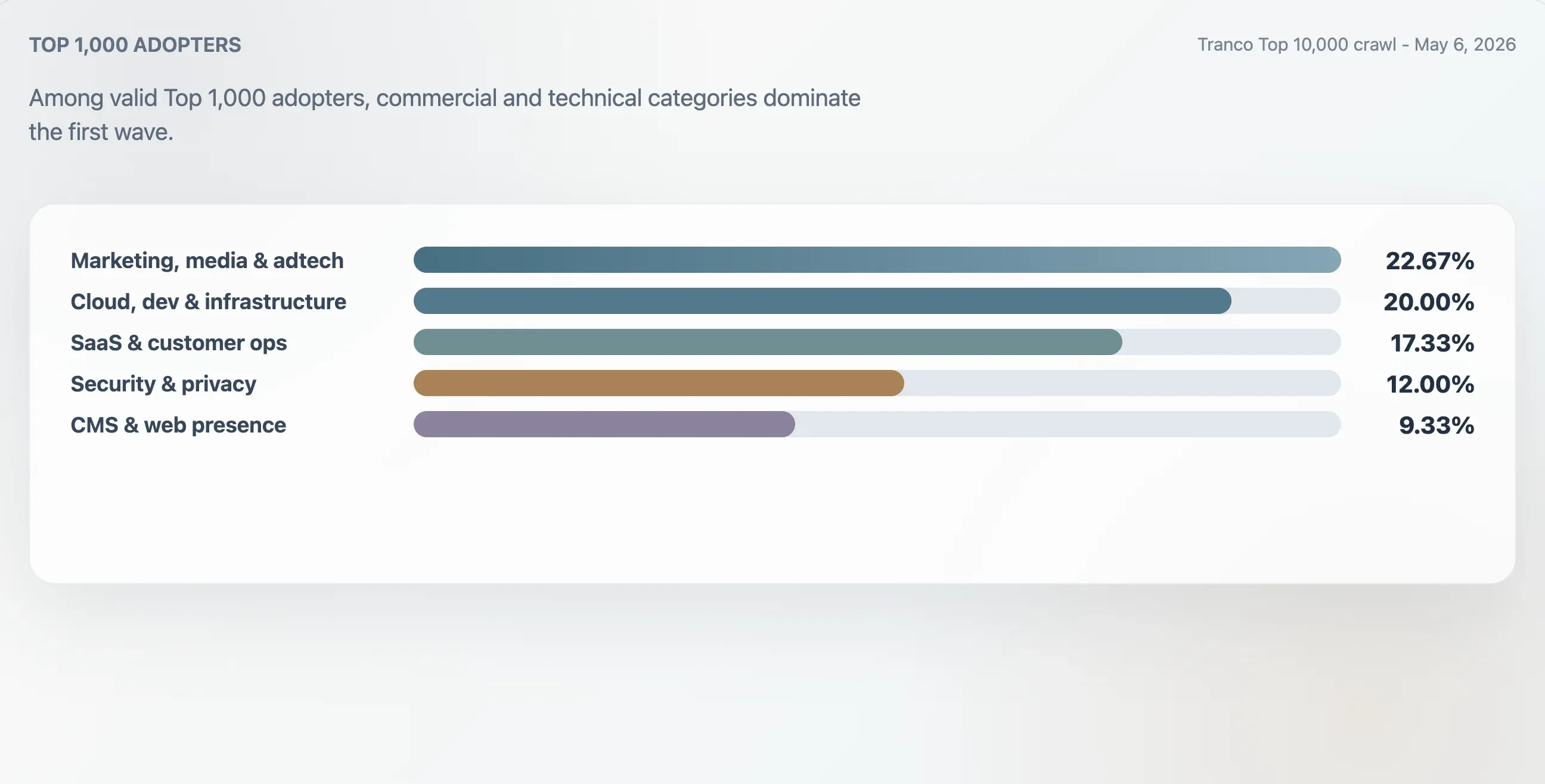
| 類別 | 網域數 | 占前 1,000 採用者比例 | 中位品質分數 | 中位連結數 |
|---|---|---|---|---|
| 行銷、媒體與 adtech | 17 | 22.67% | 94 | 25 |
| 雲端、開發者與基礎設施 | 15 | 20.00% | 94 | 62 |
| SaaS、生產力與客戶營運 | 13 | 17.33% | 94 | 46 |
| 安全、身分與隱私 | 9 | 12.00% | 98 | 78 |
| CMS、託管與網站存在 | 7 | 9.33% | 100 | 24 |
TLD 模式
頂級網域不等於產業標籤,但它們是有用的方向性訊號。在樣本中至少有 50 個網域的 TLD 裡,.io 的有效採用率最高,達 14.44%。.com 以 8.19% 緊隨其後。.gov、.edu 與 .net 的採用率較低,顯示早期採用者基礎更偏向商業與技術,而非機構型網站。
實作品質
有效採用不代表實作品質一致。有些檔案是精簡、分區清楚的索引。有些幾乎是純敘述。有些是原始連結目錄。有些則是接近空白的佔位符。有些是多 MB 的內容傾倒,可能完整,但抓取與解析成本很高。
在有效的 llms.txt 檔案中,362 份大於 5 KB,占有效採用者的 61.77%。檔案大小中位數約為 7.1 KB。P90 檔案大小為 156 KB,P95 為 356 KB,P99 為 2.54 MB,觀察到的最大檔案為 7.97 MB。
常見內容訊號
對有效檔案做關鍵詞層級掃描後發現,許多網站不只是發佈一份宣告,而是在把模型導向具有實際用途的材料。支援或說明類詞彙出現在 70.31% 的有效檔案中。部落格、指南或教學類詞彙出現在 67.92%。安全、隱私、合規或條款類詞彙出現在 61.43%。定價出現在 53.92%,文件出現在 52.22%,API 類詞彙出現在 33.96%,而變更紀錄或發佈訊號出現在 27.30%。
品質評分與原型
為了從「是否存在」進一步看向「是否成熟」,本研究建立了一個輕量級的實作分數。這個分數會考量內容類型、檔案大小、Markdown 結構、連結數、主題涵蓋度,以及缺少標題、沒有 Markdown 連結、非典型內容類型、過小檔案、過大檔案與連結堆砌等警示訊號。這不是正式標準,而是用來比較觀察到的實作情況之研究評分模型。
使用這個模型,416 份有效檔案被歸類為強結構化索引,107 份為可用索引,24 份為薄弱或不規則,39 份為象徵性或低實用性。另一項原型分析則找出 296 份結構化索引、113 份分段文字檔、63 份連結目錄、52 份薄索引、50 份象徵性或佔位符檔案,以及 12 份大型內容傾倒。
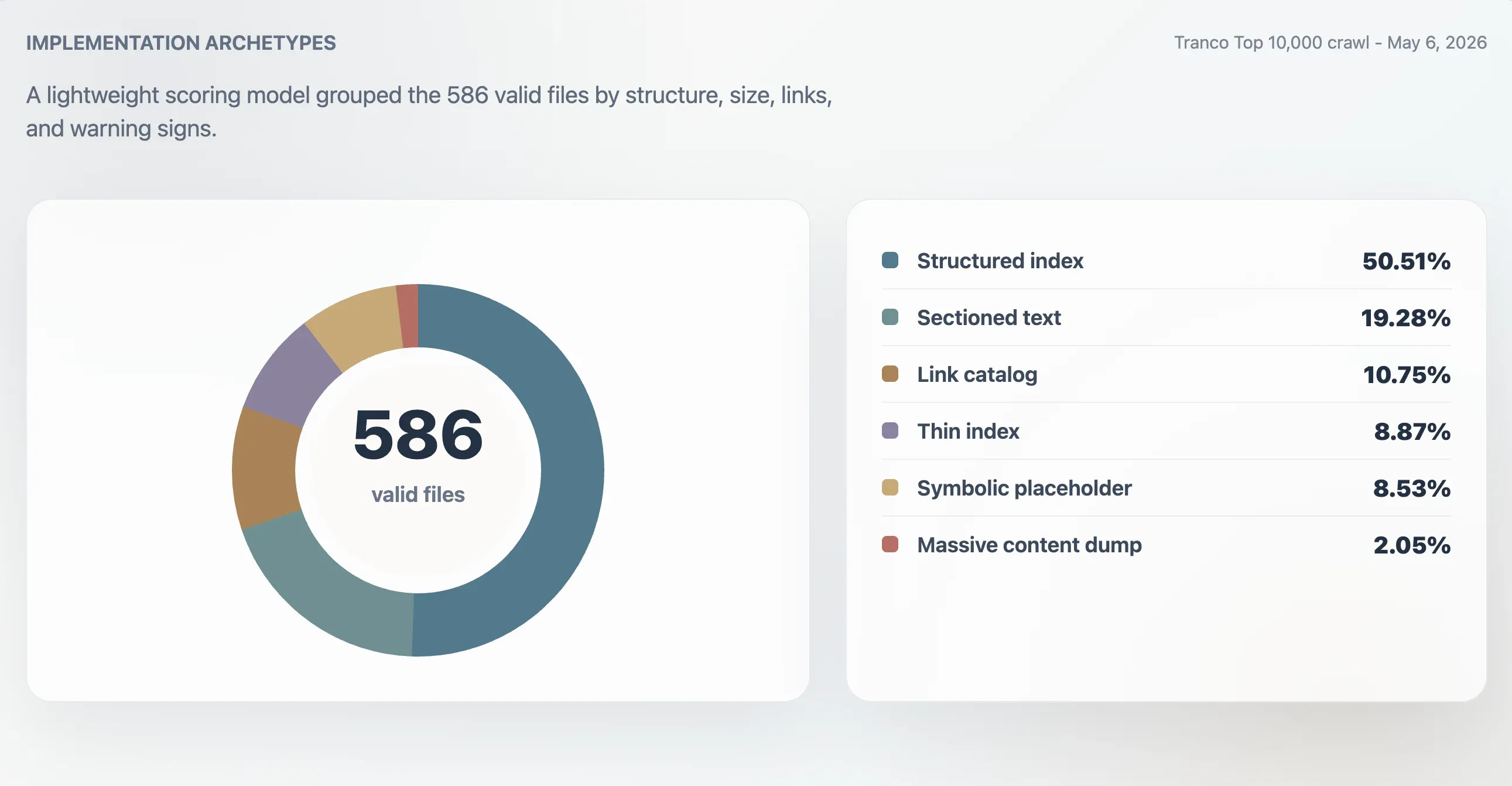
| 原型 | 網域數 | 占有效檔案比例 | 中位分數 | 中位檔案大小 | 中位連結數 |
|---|---|---|---|---|---|
| 結構化索引 | 296 | 50.51% | 98 | 11,241 B | 61.5 |
| 分段文字 | 113 | 19.28% | 78 | 4,718 B | 0 |
| 連結目錄 | 63 | 10.75% | 86 | 4,160 B | 23 |
| 薄索引 | 52 | 8.87% | 66 | 2,814 B | 0 |
| 象徵性或佔位符 | 50 | 8.53% | 27 | 15 B | 0 |
| 大型內容傾倒 | 12 | 2.05% | 74 | 2.84 MB | 7,259.5 |
頂尖採用者的實作更密集
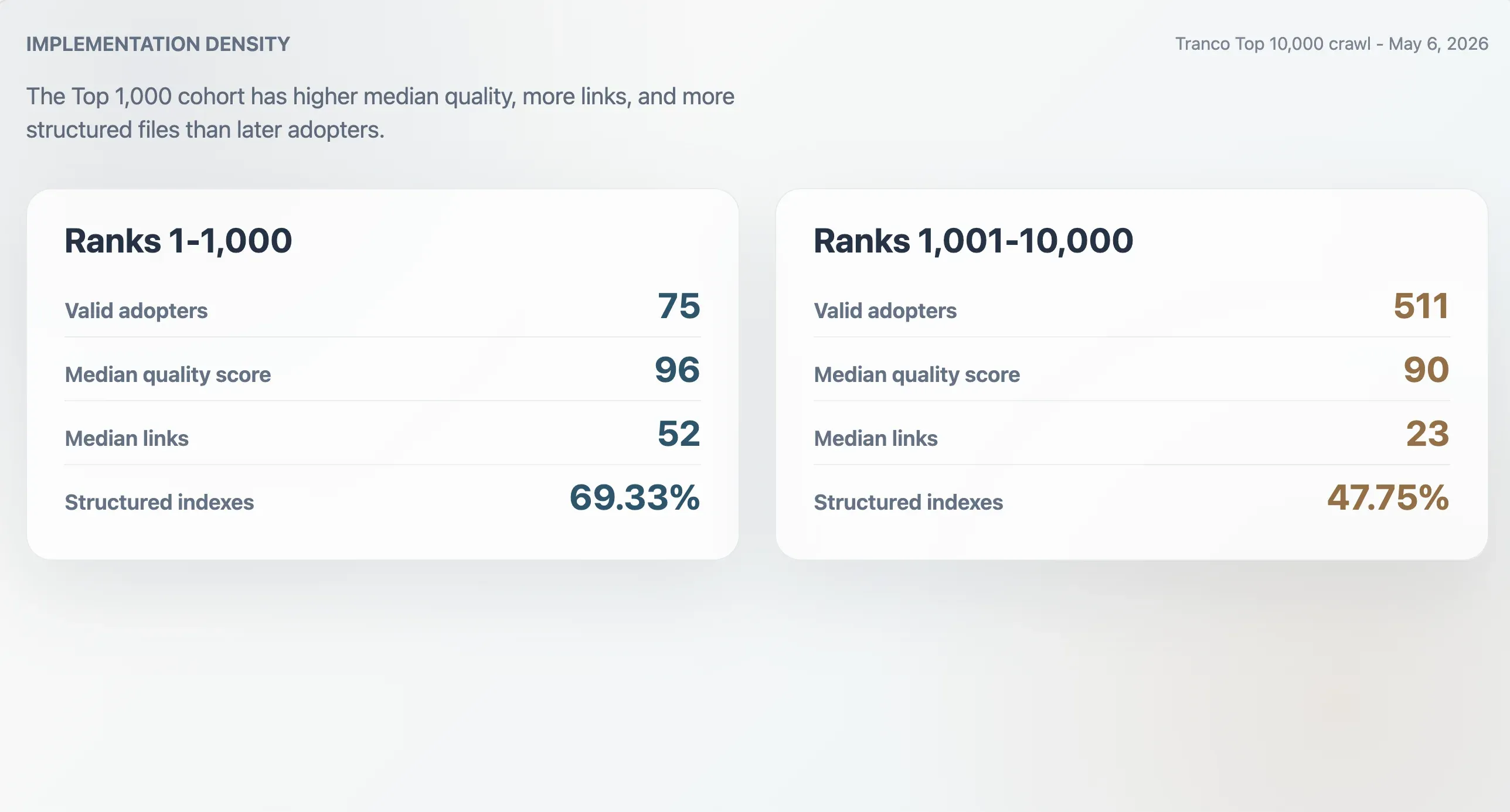
Tranco Top 1,000 中的 75 個有效採用者,其品質分數中位數為 96,檔案大小中位數為 9,068 bytes,Markdown 連結數中位數為 52,區段數中位數為 11。排名 1,001–10,000 的 511 個採用者則較低:分數 90、檔案大小 6,506 bytes、Markdown 連結 23、區段 9。Top 1,000 採用者也更可能是結構化索引:69.33%,相較於後段群組的 47.75%。
假陽性問題

最大的測量風險是假陽性。在回傳 /llms.txt HTTP 200 的 1,606 個網域中,有 1,020 個未通過驗證。最常見的無效原因是跳轉到非目標頁面,共 618 件。另有 367 個回應是一般 HTML 文件。29 個回傳空白內容,6 個則是其他或未分類的無效回應。
這很重要,因為許多大型網站會把未知路徑導向登入頁、首頁、應用程式外殼、區域頁、同意彈窗或行銷備援頁。對只看狀態碼的爬蟲來說,這些回應看起來正常,但其實不包含有效的 llms.txt 訊號。
llms-full.txt:更稀少,也更不均衡
搭配的 llms-full.txt 檔案遠比 llms.txt 少。爬取結果找到 103 個有效 full file,占有效 llms.txt 採用者的 17.58%,以及完整 Top 10,000 樣本的 1.03%。
full-file 的實作很不均衡。在 103 個雙檔採用者中,57 個的 llms-full.txt 比 index 檔還大,但另外 46 個要嘛 full file 不比 index 檔大,要嘛 full file 小於 100 bytes。full-to-index 的大小比例中位數為 1.43,但極端案例高得多。Supabase 的 full file 大約是其 index 檔的 7,139 倍。Made-in-China.com 的 full file 則達 89.89 MB。
| 網域 | llms.txt | llms-full.txt | 比例 |
|---|---|---|---|
| made-in-china.com | 4.49 MB | 89.89 MB | 20.0x |
| sendbird.com | 281.86 KB | 11.99 MB | 42.5x |
| taboola.com | 286.78 KB | 11.73 MB | 40.9x |
| supabase.co | 1.26 KB | 8.98 MB | 7,139.3x |
| neon.tech | 27.44 KB | 5.01 MB | 182.7x |
建議: 只有在網站已經具備穩定的文件產線、版本控管紀律,以及把大量內容暴露為單一可機器讀取檔案的明確理由時,才發布
llms-full.txt。
llms.txt、robots.txt 與 sitemap.xml
llms.txt 不應被當成新的 robots.txt。兩者都是位於根目錄的可機器讀取檔案,但它們傳達的是不同訊息。robots.txt 是爬蟲偏好與存取控制訊號。sitemap.xml 是網址發現訊號。llms.txt 則是說明與導覽訊號。
| 訊號 | 主要角色 | 典型讀者 | 本研究中的解讀 |
|---|---|---|---|
robots.txt | 宣告爬蟲偏好與路徑層級限制。 | 搜尋爬蟲、AI 爬蟲、典藏爬蟲、通用機器人。 | 治理與存取訊號。 |
sitemap.xml | 列出可被發現的網址,供索引系統使用。 | 搜尋引擎與索引管線。 | 發現訊號。 |
llms.txt | 提供精簡的網站脈絡、重要連結、文件、API、範例與政策參考。 | LLM 應用、AI 代理、開發者工具、檢索系統。 | 說明與導覽訊號。 |
建議
對考慮導入 llms.txt 的網站而言,從本資料集與外部流量證據來看,最強的實作模式相當務實:
- 在根目錄發布
/llms.txt,並確保無須登入、無須執行 JavaScript、無同意牆,也沒有離題跳轉就能存取。 - 盡可能以
text/plain或text/markdown提供。 - 先用簡短描述介紹網站,再依產品、文件、API、定價、變更紀錄、範例、支援、政策與公司資源分組連結。
- 優先使用權威連結,而不是把所有 URL 都列上。
- 避免空洞的象徵性檔案;它們最多只算弱訊號。
- 除非有強烈的機器消費使用情境與可靠的產生流程,否則避免大量不加區分的傾倒內容。
- 發布後驗證最終 URL、回應本文、內容類型、Markdown 結構、連結數與檔案大小。
團隊也應該謹慎設定預期。目前可取得的公開實驗並未證明 llms.txt 會獨立提升 AI 轉介流量。若團隊想測試商業影響,應該同時追蹤 LLM 轉介、被引用頁面、機器人請求、索引新鮮度與內容變更。一個有用的實驗會比較配對頁面群組、在可行時保持內容更新不變,並把 Perplexity、ChatGPT、Gemini、Claude 與 Bing/Copilot 等平台特定流量分開分析。
限制
這是一份以爬取為基礎的快照,不是永久的事實真相。網站可隨時新增、移除或修改 llms.txt 檔案。某些網域可能會封鎖自動化請求,或因地理位置、TLS 設定、跳轉邏輯、User-Agent 或機器人防護而表現不同。本研究只測試根目錄檔案,並未搜尋子網域或非標準路徑。
品質分數與原型分類是研究工具,不是正式合規標籤。主題分析是以關鍵詞為基礎,應視為方向性參考。本研究並未證明任何特定 AI 平台目前在正式環境中會讀取、遵守或使用 llms.txt。
本版本所檢視的外部流量證據也有其限制。Search Engine Land 的分析更適合作為多站點觀察的謹慎提醒,而不是隨機實驗。Alimbekov 的結果可作為透明的站點層級案例研究,但它沒有控制組,且包含總轉介流量大幅成長的期間。這些參考有助於框定爭論,但不會把這次爬取變成因果性的流量研究。
檔案與可重現性
| 檔案 | 用途 |
|---|---|
crawl_llms_txt.py | 用於 /llms.txt 與 /llms-full.txt 的爬蟲。 |
analyze_llms_txt.py | 主要採用分析與圖表生成。 |
deep_analyze_llms_txt.py | 用於排名十分位、TLD、主題訊號、品質分數、原型與雙檔行為的次級分析。 |
deep_dive_early_quality.py | 早期採用者分類與實作品質深度分析。 |
data/llms_probe_results_top_10000.csv | 主要爬取結果資料集。 |
data/deep_analysis_top_10000.json | 次級分析摘要。 |
data/deep_early_quality_analysis.json | 早期採用者類別、品質群組比較、原型細節與案例研究。 |
來源
- ,Jeremy Howard,2024 年。
- 。
- 。
- 。
- ,Data Provenance Initiative。
- 。
- ,Search Engine Land,2026 年 1 月。
- ,Rankability,2025 年 6 月。
- ,Renat Alimbekov。
若有方法論修正、資料集問題或後續分析,歡迎寄至 support@thunderbit.com。本報告獨立於 Thunderbit 持有的任何商業立場而發布。本報告中的資料本身即具獨立性。— Thunderbit 研究團隊,2026 年 5 月。