

2025 年的網路世界可說是風起雲湧——您看到的流量,有一半甚至不是人類。沒錯:機器人和爬蟲如今已佔據超過 50% 的網際網路活動(Thales Group),而其中只有一小部分是您真正想要的「好機器人」:搜尋引擎、社群媒體預覽器,以及分析輔助工具。那其他的呢?只能說,它們不一定是來幫忙的。身為多年在 Thunderbit 打造自動化與 AI 工具的人,我親眼見過合適或不合適的爬蟲如何左右 SEO、扭曲分析數據、耗盡頻寬,甚至引發嚴重的資安事件。
如果您正在經營企業、管理網站,或只是想把數位資產打理好,了解誰正在敲您伺服器的大門,比以往任何時候都更重要。這也是我整理這份 2025 爬蟲指南的原因——帶您認識最重要的爬蟲、它們的用途、如何辨識它們,以及如何讓網站對好機器人保持開放,同時把壞機器人擋在門外。
什麼才算是「已知」爬蟲?User-Agent、IP 與驗證
先從基本概念說起:到底什麼是「已知」爬蟲?簡單來說,就是會用一致的 user-agent 字串自我識別的機器人(例如 Googlebot/2.1 或 bingbot/2.0),而且理想上會從可公開查驗的 IP 範圍或 ASN 區塊來抓取資料,這些都能被您驗證(Googlebot 驗證)。大廠——Google、Microsoft、Baidu、Yandex、DuckDuckGo——都會公開說明自家機器人的資訊,很多情況下也會提供工具或 JSON 檔,列出官方 IP(Googlebot IP 清單,Bingbot IP 清單,DuckDuckBot IP)。
但關鍵問題在這裡:只靠 user-agent 其實很危險。偽裝非常普遍——惡意機器人經常假扮成 Googlebot 或 Bingbot,只為了繞過您的防線(SecurityWeek)。所以黃金標準是雙重驗證:同時檢查 user-agent 和 IP 位址(或 ASN),並透過反向 DNS 查詢或官方清單交叉比對。如果您正在使用像 Thunderbit 這樣的工具,就能把這個流程自動化——抓取日誌、比對 user-agent,再交叉參照 IP,建立一份即時、可信的網站爬蟲清單。
如何使用這份爬蟲清單
那您到底要怎麼利用這份已知爬蟲清單?以下是我建議的做法:
- 允許清單: 確保您想要的機器人(搜尋引擎、社群媒體預覽器)不會被防火牆、CDN 或 WAF 意外封鎖。使用官方 IP 與 user-agent 做精準允許。
- 分析過濾: 將機器人流量從分析工具中過濾掉,讓數據反映真實的人類訪客,而不只是 Googlebot 和 AhrefsBot 在您網站上繞圈(SecurityWeek)。
- 機器人管理: 對過於積極的 SEO 工具設定 crawl-delay 或限速規則,並封鎖或挑戰未知或惡意機器人。
- 自動化日誌分析: 使用 AI 工具(像 Thunderbit)擷取、分類並標記日誌中的爬蟲活動,讓您能看出趨勢、識別冒名者,並隨時更新政策。
維護爬蟲清單不是一次設定就能放著不管的工作。新機器人不斷冒出來,舊機器人的行為也會改變,攻擊者的手法也一年比一年更狡猾。透過 Thunderbit 抓取官方文件或 GitHub 倉庫來自動更新,可以替您省下大量時間與麻煩。
1. Thunderbit:AI 驅動的爬蟲識別與資料管理
使用 Thunderbit 進行 AI 驅動的爬蟲管理 Get Started Free
Thunderbit 不只是人工智慧網頁爬蟲,更是一個幫團隊理解與管理爬蟲流量的資料助理。Thunderbit 的特點如下:
- 語意前處理: 在擷取資料之前,Thunderbit 會先將網頁與日誌轉換成 Markdown 風格的結構化內容。這種「語意層級」前處理,讓 AI 真正理解它所讀取內容的上下文、欄位與邏輯。對於複雜、動態,或 JavaScript 很重的頁面尤其有用(像 Facebook Marketplace 或長串留言串),傳統基於 DOM 的爬蟲往往在這些地方失手。
- 雙重驗證: Thunderbit 可以快速蒐集官方爬蟲 IP 文件與 ASN 清單,再拿去和您的伺服器日誌比對。結果就是一份您真的能信賴的「可信爬蟲允許清單」——不必再人工逐一交叉核對。
- 自動化日誌擷取: 把原始日誌交給 Thunderbit,它就會把內容轉成結構化表格(Excel、Sheets、Airtable),並標記高頻訪客、可疑路徑與已知機器人。接著您可以把結果送進 WAF 或 CDN,自動進行封鎖、限速或 CAPTCHA 挑戰。
- 合規與稽核: Thunderbit 的語意擷取會保留清楚的稽核軌跡——誰在什麼時候存取了什麼,以及您如何處理。對 GDPR、CCPA 與其他合規需求來說,幫助非常大。
我看過團隊用 Thunderbit 把爬蟲管理工作量減少 80%——也終於能掌握哪些機器人在幫忙、哪些在搗亂、哪些根本只是在假裝。
2. Googlebot:搜尋引擎標準答案
Googlebot 是網頁爬蟲的黃金標準。它負責將您的網站收錄到 Google 搜尋中——如果把它封鎖,就等於在數位店面門口掛上「暫停營業」的牌子。
- User-Agent:
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) - 驗證方式: 使用 Google 的反向 DNS 方法 或 官方 IP 清單。
- 管理建議: 一律允許 Googlebot。使用 robots.txt 引導它抓取,而不是封鎖;如有需要,可在 Google Search Console 中調整 crawl rate。
3. Bingbot:Microsoft 的網路探索者
Bingbot 為 Bing 與 Yahoo 的搜尋結果提供動力。對多數網站來說,它是第二重要的爬蟲。
- User-Agent:
Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) - 驗證方式: 使用 Microsoft 的驗證工具 與 官方 IP 清單。
- 管理建議: 允許 Bingbot,並在 Bing Webmaster Tools 中管理 crawl rate;robots.txt 可用於進一步微調。
4. Baiduspider:中國領先的搜尋爬蟲
Baiduspider 是通往中文搜尋流量的大門。
- User-Agent:
Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html) - 驗證方式: 沒有官方 IP 清單;可在反向 DNS 中查看是否出現
.baidu.com,但要留意其限制。 - 管理建議: 如果您想要中文流量,就允許它。可用 robots.txt 設定規則,但要注意 Baiduspider 有時不會遵守。若不需要中文 SEO,可考慮限速或封鎖以節省頻寬。
5. YandexBot:俄羅斯的搜尋引擎爬蟲
YandexBot 對俄語與 CIS 市場至關重要。
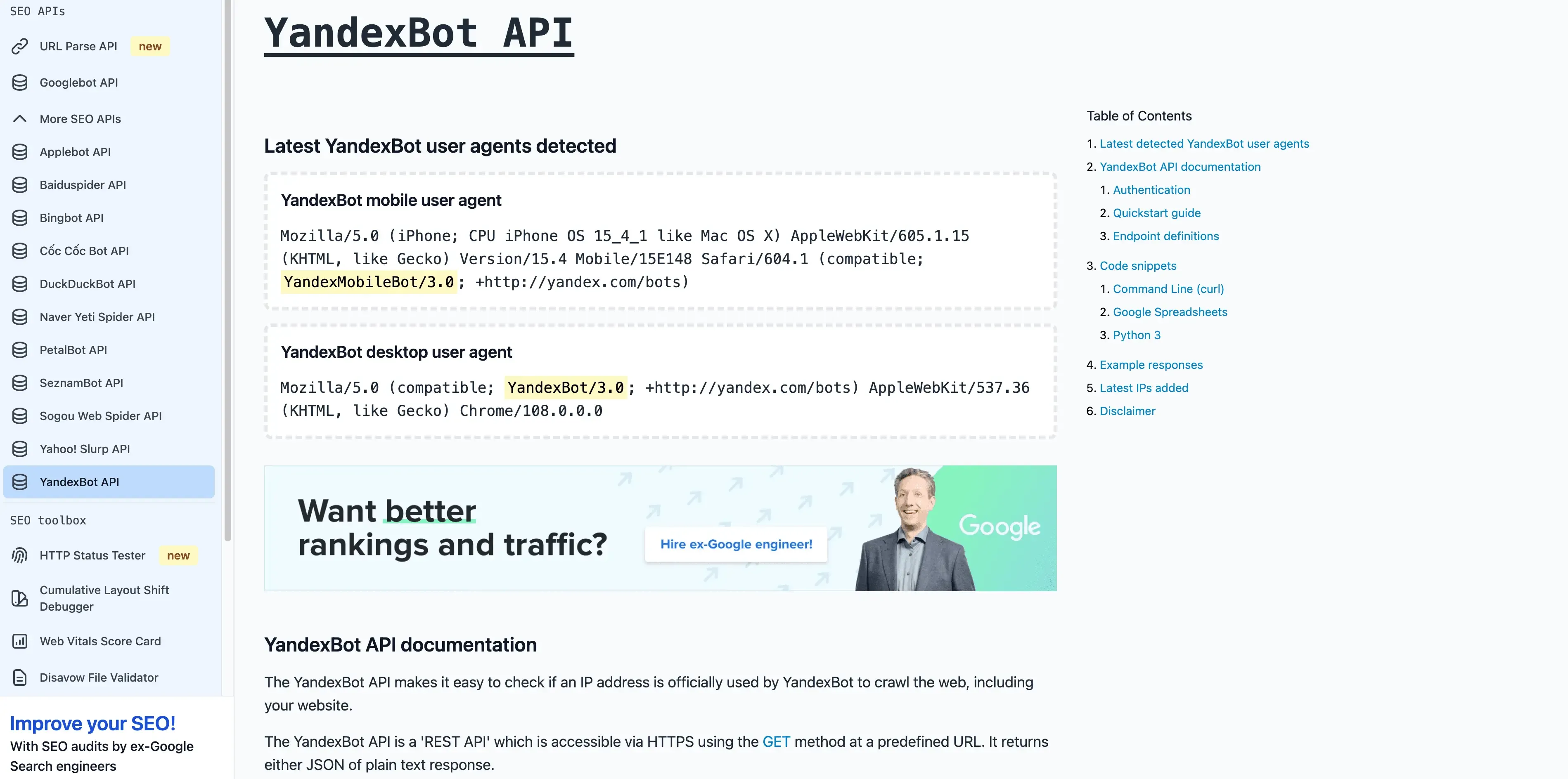
- User-Agent:
Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots) - 驗證方式: 反向 DNS 應以
.yandex.ru、.yandex.net或.yandex.com結尾。 - 管理建議: 如果您的目標受眾是俄語使用者,就允許它。可使用 Yandex Webmaster 進行抓取控制。
6. DuckDuckBot:重視隱私的搜尋爬蟲
DuckDuckBot 為 DuckDuckGo 以隱私為核心的搜尋服務提供支援。
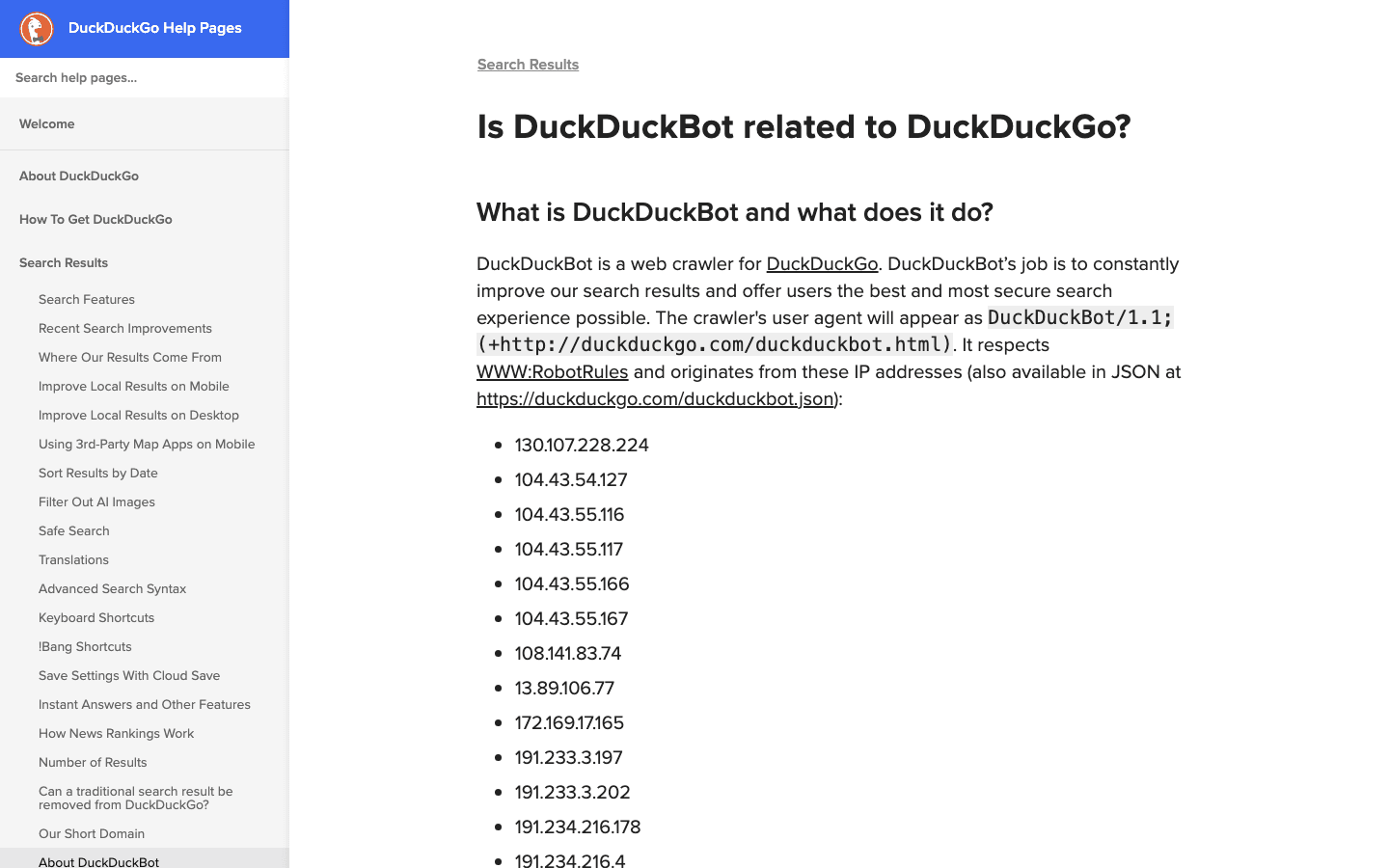
- User-Agent:
DuckDuckBot/1.1; (+http://duckduckgo.com/duckduckbot.html) - 驗證方式: 官方 IP 清單(JSON)。
- 管理建議: 除非您完全不在意重視隱私的使用者,否則就允許它。抓取負載低,管理也容易。
7. AhrefsBot:SEO 與外部連結分析
AhrefsBot 是頂級的 SEO 工具爬蟲——很適合做外部連結分析,但也可能很耗頻寬。
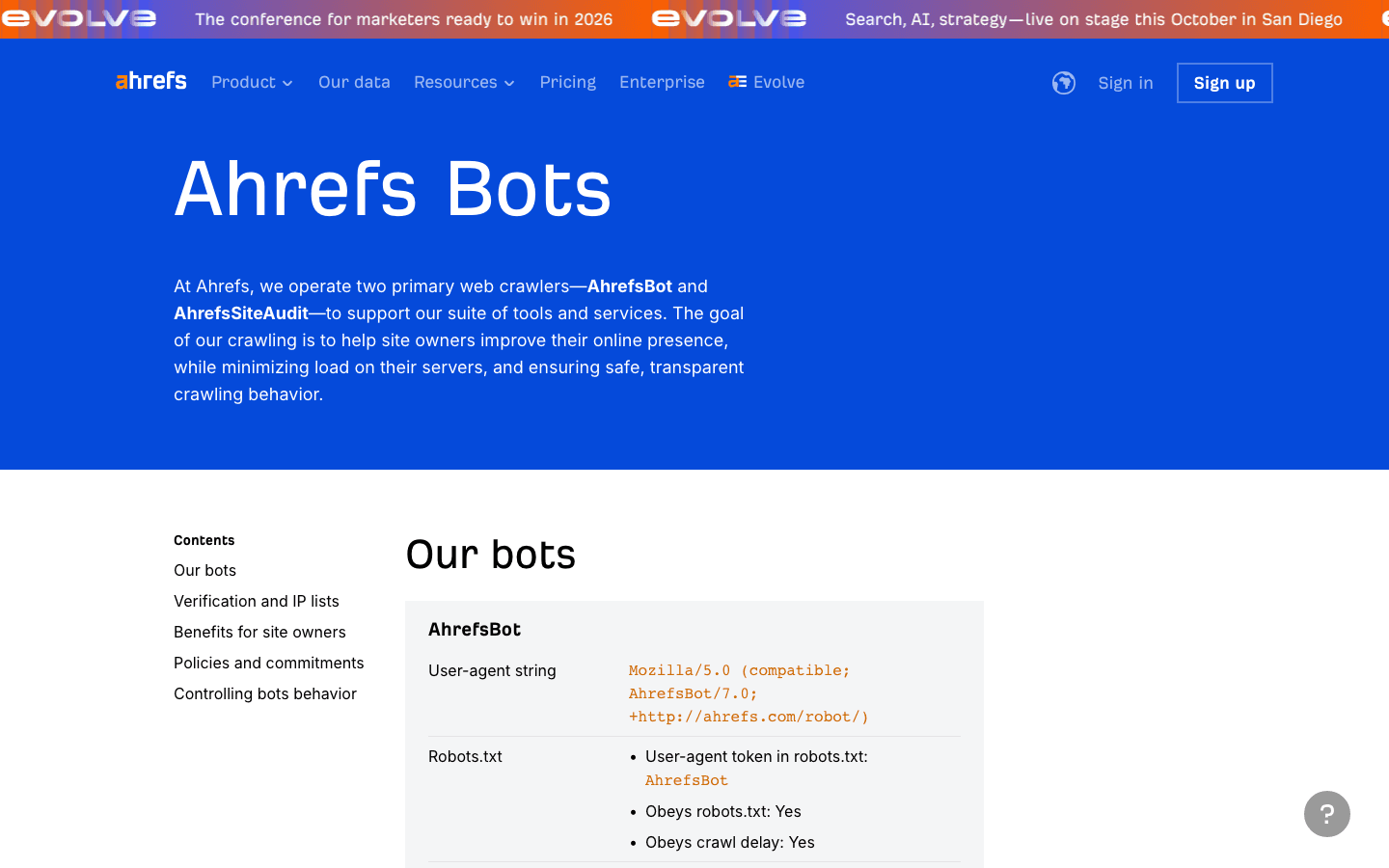
- User-Agent:
Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/) - 驗證方式: 沒有公開 IP 清單;請透過 UA 與反向 DNS 驗證。
- 管理建議: 如果您有使用 Ahrefs,就允許它。可用 robots.txt 設定 crawl-delay 或封鎖。您也可以透過 電子郵件選擇退出 。
8. SemrushBot:競品 SEO 洞察
SemrushBot 也是另一個主要的 SEO 爬蟲。
- User-Agent:
Mozilla/5.0 (compatible; SemrushBot/1.0; +http://www.semrush.com/bot.html)(另有SemrushBot-BA、SemrushBot-SI等變體) - 驗證方式: 透過 user-agent;沒有公開 IP 清單。
- 管理建議: 如果您有使用 Semrush,就允許它;否則可用 robots.txt 或伺服器規則限速或封鎖。
9. FacebookExternalHit:社群媒體預覽機器人
FacebookExternalHit 會抓取 Facebook 與 Instagram 連結預覽所需的 Open Graph 資料。
- User-Agent:
facebookexternalhit/1.1 (+http://www.facebook.com/externalhit_uatext.php) - 驗證方式: 透過 user-agent;IP 屬於 Facebook 的 ASN。
- 管理建議: 允許它,才能有豐富的社群預覽。若封鎖,Facebook/Instagram 上就不會顯示縮圖或摘要。
10. Twitterbot:X(Twitter)連結預覽爬蟲
Twitterbot 會為 X(Twitter)抓取 Twitter Card 資料。
- User-Agent:
Twitterbot/1.0 - 驗證方式: 透過 user-agent;Twitter ASN(AS13414)。
- 管理建議: 允許它以產生 Twitter 預覽。使用 Twitter Card meta 標籤可獲得最佳效果。
比較表:爬蟲清單一覽
| 爬蟲 | 用途 | User-Agent 範例 | 驗證方式 | 商業影響 | 管理建議 |
|---|---|---|---|---|---|
| Thunderbit | AI 日誌/爬蟲分析 | N/A(工具,不是機器人) | N/A | 資料管理、機器人分類 | 用於日誌擷取、建立允許清單 |
| Googlebot | Google 搜尋索引 | Googlebot/2.1 | DNS 與 IP 清單 | 對 SEO 至關重要 | 一律允許,透過 Search Console 管理 |
| Bingbot | Bing/Yahoo 搜尋 | bingbot/2.0 | DNS 與 IP 清單 | 對 Bing/Yahoo SEO 很重要 | 允許,透過 Bing Webmaster Tools 管理 |
| Baiduspider | Baidu 搜尋(中國) | Baiduspider/2.0 | 反向 DNS、UA 字串 | 對中國 SEO 很關鍵 | 若目標市場是中國就允許,並監控頻寬 |
| YandexBot | Yandex 搜尋(俄羅斯) | YandexBot/3.0 | 反向 DNS 至 .yandex.ru | 對俄羅斯/東歐很重要 | 若目標市場是 RU/CIS 就允許,使用 Yandex 工具 |
| DuckDuckBot | DuckDuckGo 搜尋 | DuckDuckBot/1.1 | 官方 IP 清單 | 重視隱私的受眾 | 允許,影響低 |
| AhrefsBot | SEO/外部連結分析 | AhrefsBot/7.0 | UA 字串、反向 DNS | SEO 工具,可能很耗頻寬 | 透過 robots.txt 允許/限速/封鎖 |
| SemrushBot | SEO/競爭分析 | SemrushBot/1.0(另有變體) | UA 字串 | SEO 工具,可能較激進 | 透過 robots.txt 允許/限速/封鎖 |
| FacebookExternalHit | 社群連結預覽 | facebookexternalhit/1.1 | UA 字串、Facebook ASN | 社群互動 | 允許以顯示預覽,使用 OG 標籤 |
| Twitterbot | Twitter 連結預覽 | Twitterbot/1.0 | UA 字串、Twitter ASN | Twitter 互動 | 允許以顯示預覽,使用 Twitter Card 標籤 |
管理您的爬蟲清單:2025 最佳實務
進一步了解如何運用 AI 進行清單爬取 Get Started Free
- 定期更新: 爬蟲版圖變化很快。建議每季檢視一次,並使用像 Thunderbit 這樣的工具抓取與比對官方清單(Human Security)。
- 驗證,不要只相信: 務必同時檢查 user-agent 與 IP/ASN。別讓冒名者偷偷混進來,扭曲您的分析數據或抓走您的資料(FriendlyCaptcha)。
- 將好機器人加入允許清單: 確保搜尋與社群爬蟲不會被反機器人規則或防火牆誤擋。
- 對激進機器人限速或封鎖: 對抓取過於頻繁的 SEO 工具,可用 robots.txt、crawl-delay 或伺服器規則處理。
- 自動化日誌分析: 使用 AI 驅動工具(像 Thunderbit)擷取、分類並標記爬蟲活動——幫您省時,也能發現您可能錯過的趨勢。
- 平衡 SEO、分析與資安: 不要擋掉真正推動業務的機器人,但也別讓壞機器人為所欲為。
結論:讓您的爬蟲清單保持最新、可執行
在 2025 年,管理爬蟲清單不只是 IT 雜務——它關乎 SEO、分析、安全與合規,是直接影響業務的關鍵工作。既然機器人現在已佔據大部分網路流量,您就必須知道誰在造訪、為什麼來,以及該如何應對。保持清單最新、盡可能自動化,並善用像 Thunderbit 這樣的工具,才能走在趨勢前面。網路只會越來越忙碌,而在這個由機器人驅動的世界裡,聰明且可執行的爬蟲策略,就是您最好的防禦與進攻。
常見問題
1. 為什麼維護最新的爬蟲清單很重要?
因為現在機器人已佔據超過一半的網路流量,而且其中只有一小部分是有益的。維持清單更新,能確保您放行對 SEO 與社群預覽有幫助的好機器人,並封鎖或限速壞機器人,保護您的分析數據、頻寬與資料安全。
2. 我怎麼判斷一個爬蟲是真實的還是偽裝的?
不要只相信 user-agent——一定要透過官方清單或反向 DNS 查詢來驗證 IP 位址或 ASN。像 Thunderbit 這類工具可以自動把日誌與已公開的機器人 IP 和 user-agent 做比對,簡化整個流程。
3. 如果有未知機器人在爬我的網站,我該怎麼辦?
先調查它的 user-agent 與 IP。如果它不在允許清單中,而且也不符合已知機器人的特徵,就可以考慮限速、挑戰驗證或直接封鎖。也可以利用 AI 工具在新爬蟲出現時進行分類與監控。
4. Thunderbit 如何幫助管理爬蟲?
Thunderbit 會用 AI 從日誌中擷取、結構化並分類爬蟲活動,讓您更容易建立允許清單、識別冒名者,並自動執行政策。它的語意前處理特別適合複雜或動態網站。
5. 封鎖像 Googlebot 或 Bingbot 這類大型爬蟲有什麼風險?
封鎖搜尋引擎爬蟲可能會讓您的網站從搜尋結果中消失,進而扼殺自然流量。請務必仔細檢查防火牆、robots.txt 與反機器人規則,確保您沒有誤擋最重要的爬蟲。
延伸閱讀:
試用 Thunderbit 進行 AI 驅動的爬蟲管理 Get Started Free




