
網路發展的速度真的超乎想像。到了 2024 年,全球網站數量已經突破 11 億個,而網路上的資料量更是高達 149 ZB(Zettabytes),預計明年還會衝破 181 ZB。這些內容可不只是披薩菜單這麼簡單。但重點來了:其實只有大約 4% 的網路內容被搜尋引擎索引。剩下的內容都屬於「深網」,一般搜尋根本找不到。那搜尋引擎和企業到底怎麼在這片數位叢林裡找到有用的資訊?這就要靠網頁爬蟲出馬了。
這篇指南會帶你認識什麼是網頁爬蟲、它的運作方式,以及為什麼不只是工程師,任何想善用網路資料的人都該懂。還會幫你釐清「網頁爬蟲」和「網頁爬蟲」的差別(真的不一樣!),介紹實際應用場景,並帶你看看程式碼與免寫程式的解決方案(我最推薦 Thunderbit)。不管你是剛入門的新手,還是想提升效率的商務用戶,都能在這裡找到答案。
什麼是網頁爬蟲?網頁爬蟲的基礎概念
先從最簡單的說起。網頁爬蟲(有時也叫 spider、bot 或網站爬蟲)是一種自動化程式,會有系統地瀏覽網頁、抓取頁面內容,並沿著連結發現更多新內容。你可以把它想像成一個機器圖書館員,手上有一份書單(URL),每本書都會讀一遍,然後根據書裡的參考資料再去找更多書。爬蟲的運作方式就是這樣——只是它讀的是網頁,圖書館則是整個網際網路。
核心流程如下:
- 從一組網址(種子)開始
- 逐一拜訪每個頁面,下載內容(HTML、圖片等)
- 尋找頁面上的超連結,把新連結加入待抓取清單
- 重複以上步驟——不斷發現新頁面,擴大地圖
網頁爬蟲的主要任務是發現並整理網頁。對搜尋引擎來說,爬蟲會複製頁面內容,送回去做索引和分析。某些專用爬蟲則會針對特定資料做擷取(這時就會用到網頁爬蟲,稍後會詳細說明)。
重點整理:
網頁爬蟲的本質是探索與繪製網路地圖,而不只是單純抓資料。這也是 Google、Bing 等搜尋引擎能掌握網路全貌的基礎。
搜尋引擎怎麼運作?爬蟲的角色
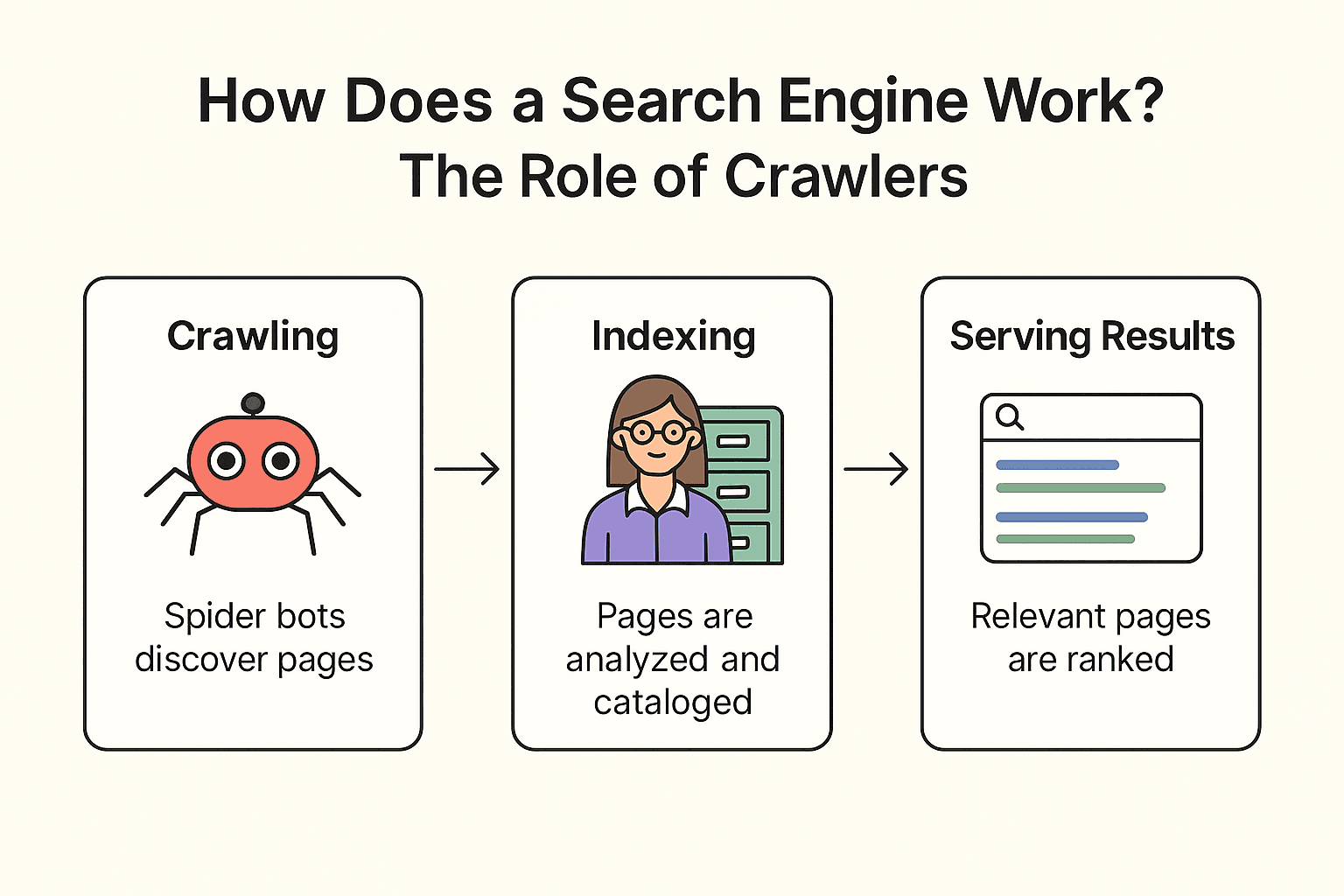
那 Google(或 Bing、DuckDuckGo)到底是怎麼運作的?其實分三個步驟:爬取、索引、呈現搜尋結果(可以參考 Google 官方說明)。
我們用圖書館來比喻(畢竟大家都愛這個例子):
-
爬取(Crawling):
搜尋引擎會派出「蜘蛛機器人」(像 Googlebot)在網路上探索。它們從已知的頁面出發,抓取內容,並沿著連結發現新頁面——就像圖書館員檢查每個書架,根據書裡的參考資料找到更多書。
-
索引(Indexing):
找到新頁面後,搜尋引擎會分析內容、判斷主題,並把重要資訊存進龐大的數位卡片櫃(索引庫)。不是每個頁面都會被收錄——有些被封鎖、品質太差或重複內容會被跳過。
-
呈現搜尋結果(Serving Results):
當你搜尋「附近最好吃的披薩」,搜尋引擎會從索引庫找出相關頁面,根據數百個因素(關鍵字、人氣、新鮮度等)排序,最後呈現一份有條理的網頁清單給你。
小知識:
搜尋引擎不會抓取所有網頁。像是需要登入的頁面、被 robots.txt 擋住的內容,或是沒有其他網站連結的頁面,可能永遠不會被發現。所以有些企業會主動提交網址或 sitemap 給 Google。
網頁爬蟲 vs. 網頁爬蟲:有什麼不同?
這裡常常讓人搞混。很多人把「網頁爬蟲」和「網頁爬蟲」當成同一回事,但其實差異很大。
| 面向 | 網頁爬蟲(Spidering) | 網頁爬蟲 |
|---|---|---|
| 目標 | 發現並索引盡可能多的頁面 | 從一個或多個網頁擷取特定資料 |
| 比喻 | 圖書館員為每本書建目錄 | 學生從幾本重點書抄筆記 |
| 產出 | 網址清單或頁面內容(用於索引) | 結構化資料集(CSV、Excel、JSON)含目標資訊 |
| 使用者 | 搜尋引擎、SEO 工具、網頁存檔 | 銷售、行銷、研究等商業團隊 |
| 規模 | 超大(數百萬/數十億頁面) | 精準(數十、數百或數千頁面) |
簡單說:
- 網頁爬蟲重點在於發現頁面(建立網路地圖)
- 網頁爬蟲則是擷取你想要的資料(把資訊整理成表格)
多數商業用戶(尤其是銷售、電商、行銷)其實更需要爬蟲——也就是取得結構化資料來分析,而不是爬遍整個網路。爬蟲是搜尋引擎和大規模探索的基礎,爬蟲則專注於目標資料的擷取。
為什麼要用網頁爬蟲?企業的實際應用
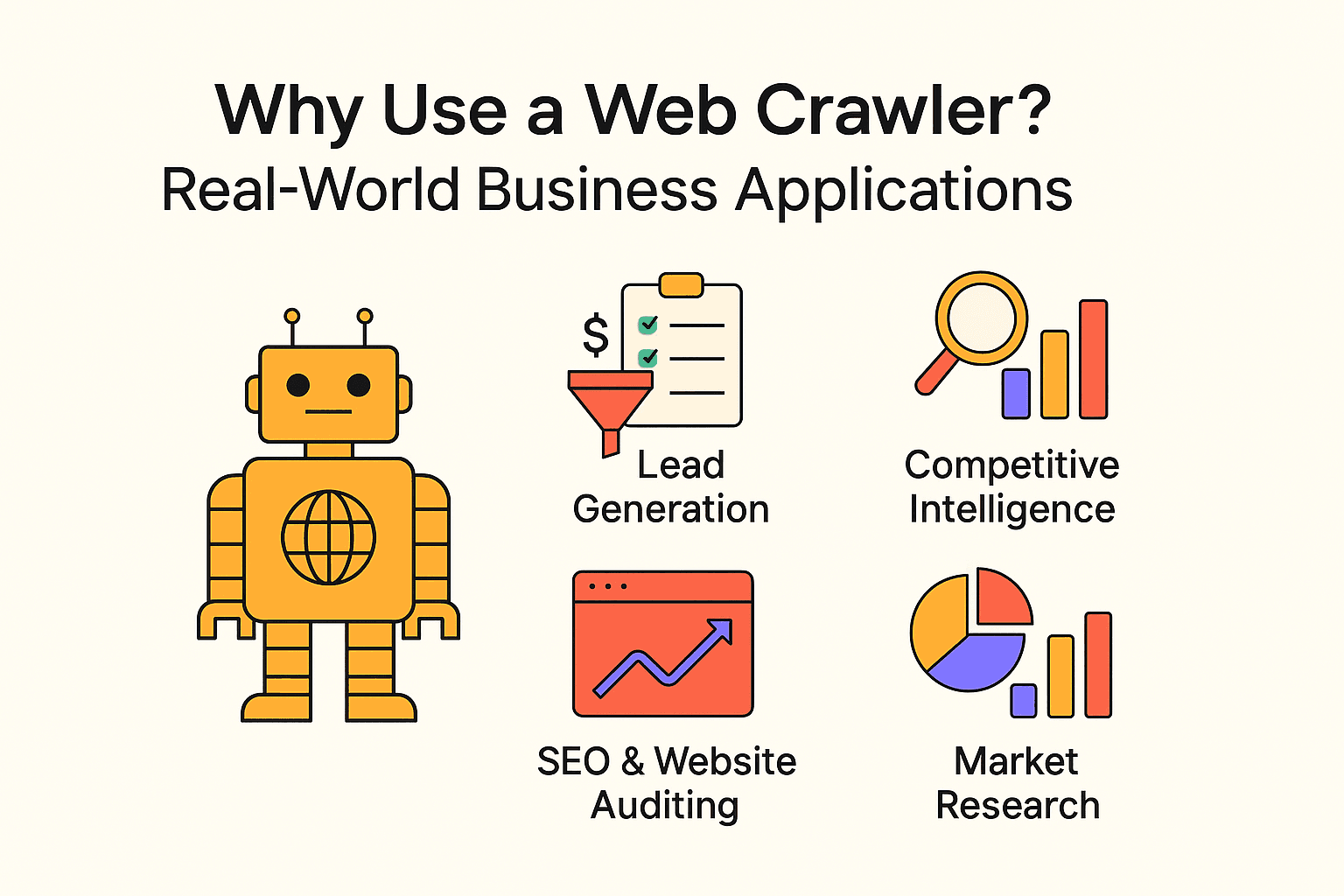
網頁爬蟲不只是搜尋引擎的專利。各種規模的企業都會用爬蟲和爬蟲來挖掘洞見、減少重複勞動。以下是常見的應用場景:
| 應用情境 | 目標用戶 | 預期效益 |
|---|---|---|
| 名單開發 | 銷售團隊 | 自動化開發潛在客戶,快速填充 CRM |
| 競爭情報 | 零售、電商 | 監控競爭對手價格、庫存、產品變化 |
| SEO 與網站健檢 | 行銷、SEO 團隊 | 找出壞連結、優化網站結構 |
| 內容彙整 | 媒體、研究、HR | 收集新聞、職缺或公開資料集 |
| 市場調查 | 分析師、產品團隊 | 大規模分析評論、趨勢或情緒 |
- Groupon 透過自動化名單開發讓潛在客戶數量翻倍。
- 82% 電商企業與 71% 金融服務公司都仰賴網頁爬蟲做決策。
- 網頁爬蟲能節省 90% 基礎設施成本,減少 60% 人力時間,遠勝人工收集。
總結:如果你還沒善用網路資料,你的競爭對手很可能早就開始了。
用 Python 寫網頁爬蟲:你需要知道什麼?
如果你會寫程式,Python 絕對是打造自訂網頁爬蟲的首選語言。基本流程如下:
- 用 requests 取得網頁內容
- 用 BeautifulSoup 解析 HTML、擷取連結或資料
- 寫迴圈(或遞迴)自動跟隨連結,持續爬取新頁面
優點:
- 彈性高、完全自訂
- 能處理複雜邏輯、串接資料庫等
缺點:
- 需要程式能力
- 網站結構一變,維護很麻煩
- 反爬蟲、延遲、錯誤處理都要自己搞定
新手範例:
這是一個簡單的 Python 程式,會從 quotes.toscrape.com 抓取名言和作者:
import requests
from bs4 import BeautifulSoup
url = "<http://quotes.toscrape.com/page/1/>"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
for quote in soup.find_all('div', class_='quote'):
text = quote.find('span', class_='text').get_text()
author = quote.find('small', class_='author').get_text()
print(f"{text} --- {author}")
如果要爬多頁,只要加上尋找「下一頁」的邏輯,重複執行即可。
常見陷阱:
- 忽略 robots.txt 或爬取間隔(千萬別當壞榜樣)
- 被網站反爬蟲機制擋下
- 不小心陷入無限迴圈(像是日曆頁面永遠翻不完)
實作教學:用 Python 打造簡易網頁爬蟲
想自己動手寫程式?這裡有一個簡單的步驟說明。
步驟 1:安裝 Python 環境
先確認你有安裝 Python,然後安裝需要的函式庫:
pip install requests beautifulsoup4
如果遇到問題,檢查 Python 版本(python --version)和 pip 是否正常。
步驟 2:撰寫爬蟲核心邏輯
基本架構如下:
import requests
from bs4 import BeautifulSoup
def crawl(url, depth=1, max_depth=2, visited=None):
if visited is None:
visited = set()
if url in visited or depth > max_depth:
return
visited.add(url)
print(f"Crawling: {url}")
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# 擷取連結
for link in soup.find_all('a', href=True):
next_url = link['href']
if next_url.startswith('http'):
crawl(next_url, depth + 1, max_depth, visited)
start_url = "<http://quotes.toscrape.com/>"
crawl(start_url)
小技巧:
- 限制爬取深度,避免無限循環
- 記錄已拜訪網址,避免重複
- 尊重 robots.txt,每次請求間加上延遲(time.sleep(1))
步驟 3:資料擷取與儲存
要儲存資料,可以寫入 CSV 或 JSON 檔:
import csv
with open('quotes.csv', 'w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(['Quote', 'Author'])
# 在爬蟲迴圈內寫入:
writer.writerow([text, author])
也可以用 Python 的 json 模組輸出 JSON 格式。
網頁爬蟲的注意事項與最佳實踐
網頁爬蟲很強大,但「能力越大,責任越重」(還有被封鎖的風險)。以下是安全又合規的建議:
- 遵守 robots.txt: 一定要檢查並遵守網站的 robots.txt 規範,哪些頁面不能抓都寫在裡面。
- 溫和爬取: 每次請求間隔幾秒,別讓伺服器過載。
- 控制範圍: 只抓你需要的內容,設定深度與網域限制。
- 標明身份: User-Agent 請寫明用途。
- 合法合規: 不要抓取私人或敏感資料,只取公開資訊。
- 道德使用: 不要整站複製,也別用資料做垃圾郵件。
- 小規模測試: 先小量測試,確認沒問題再擴大規模。
更多細節可參考這份最佳實踐指南。
什麼時候該選擇網頁爬蟲?Thunderbit 為商務用戶而生
使用 AI 從任何網站抓取資料 Get Started Free
老實說:除非你要打造自己的搜尋引擎或需要完整網站地圖,大多數商業用戶直接用網頁爬蟲工具會更有效率。
這就是 Thunderbit 的用武之地。身為共同創辦人兼執行長,我或許有點偏心,但我真心認為 Thunderbit 是非技術用戶最簡單的網頁資料擷取工具。
為什麼選 Thunderbit?
- 兩步完成: 點「AI 建議欄位」再點「開始抓取」,就這麼簡單。
- AI 智能判讀: Thunderbit 會自動分析頁面,推薦最適合擷取的欄位(商品名稱、價格、圖片等)。
- 支援批次與 PDF: 不只可抓當前頁面,也能批量處理多個網址,甚至 PDF 文件。
- 多元匯出: 可下載成 CSV/JSON,或直接傳送到 Google Sheets、Airtable、Notion。
- 完全免寫程式: 只要會用瀏覽器,就能上手。
- 子頁面擷取: 需要更細的資料?Thunderbit 會自動拜訪子頁面,幫你補齊資訊。
- 排程自動化: 用自然語言設定定期抓取(例如「每週一上午 9 點」)。
什麼情況下該用爬蟲?
如果你的目標是建立整個網站的地圖(像是搜尋引擎索引或 sitemap),那就需要用爬蟲。但如果你只想從特定頁面(如商品列表、評論、聯絡資訊)擷取結構化資料,爬蟲工具會更快、更簡單、更實用。
總結與重點回顧
重點整理:
- 網頁爬蟲是搜尋引擎和大數據專案探索網路的基礎,重點在「廣度」——盡可能發現更多頁面。
- 網頁爬蟲則專注於「深度」——從這些頁面擷取你需要的資料。大多數商業用戶其實只需要爬蟲。
- 你可以自己寫爬蟲(Python 很適合),但需要時間、技術與維護。
- 免寫程式、AI 驅動的工具(如 Thunderbit)讓人人都能輕鬆抓取網頁資料。
- 最佳實踐很重要: 請負責任地爬取與擷取,遵守網站規範,合法合規使用資料。
剛開始時,建議從簡單的專案下手——例如抓取商品價格、收集名單等。想快速上手可以試試 Thunderbit,想學技術細節也能用 Python 練習。
網路是資訊寶庫,只要方法正確,你就能挖掘出有價值的洞見,提升決策效率,讓你的事業領先一步。
常見問題
- 網頁爬蟲和網頁爬蟲有什麼不同?
爬蟲是發現與繪製網頁地圖,爬蟲則是從中擷取特定資料。爬蟲=探索,爬蟲=提取。
- 網頁爬蟲是否合法?
抓取公開資料通常沒問題,只要遵守 robots.txt 和網站使用條款。請避免抓取私人或有版權的內容。
- 抓取網站一定要會寫程式嗎?
不用。像 Thunderbit 這類工具,點幾下、靠 AI 就能完成,完全免寫程式。
- 為什麼 Google 沒有索引全部網頁?
因為大部分內容都在登入、付費牆後面,或被封鎖。實際上只有約 4% 被索引。
延伸閱讀
- FreeCodeCamp – 用 Python 和 BeautifulSoup 做網頁爬蟲教學
- Scrapy 官方教學
- Real Python – 用 Selenium 和 Python 做網頁自動化與爬蟲
- Apify Academy:網頁爬蟲與自動化課程
體驗人工智慧網頁爬蟲 Get Started Free




