

週二中午前,我的 OpenRouter 儀表板就顯示已經花了 47 美元。我大概只跑了十幾個程式任務——沒做什麼誇張的事,只有一些重構和幾個 bug 修正。就在那時我才發現,OpenClaw 的預設設定竟然默默把每一次互動都導向 Claude Opus,每個背景心跳 ping 也不例外,而且是按每百萬 tokens 15 美元以上在計費。
如果你也遇過類似狀況——而根據論壇上的討論,這種情況其實非常常見(「我已經花了 40 塊,但根本沒怎麼用」,有位使用者這麼寫)——那這篇指南會帶你完整走過我實際採用的「盤點+優化」方法,最終把每月支出大約砍掉 90%。這不只是「換成便宜模型」而已,而是系統性地拆解 token 到底花去哪裡、怎麼監控、哪些平價模型真的能扛住真實的 agent 工作,以及三組你今天就能直接複製使用的設定。整個流程只花了我一個下午。
什麼是 OpenClaw Token 使用量(為什麼預設值這麼高)?
Token 是 OpenClaw 中所有 AI 互動的計費單位。你可以把它想成一小段文字,大約每 4 個英文字符算 1 個 token。你送出的每則訊息、收到的每個回覆、每個背景程序的觸發,都會以 token 計費。
問題在於,OpenClaw 的預設值是為了最大能力設計,不是為了最低成本。開箱即用時,主模型就設成 anthropic/claude-opus-4-5——也就是可用選項裡最貴的那一個。心跳 ping 也用 Opus?子代理處理旁支任務時也用 Opus?拿 Opus 來做心跳 ping,就像請神經外科醫師來貼 OK 繃。技術上完全沒問題,但價格高得離譜。
多數使用者根本沒意識到,自己其實是在用高級費率處理最簡單的背景工作。這種預設配置,基本上假設你想讓最好的模型永遠處理所有事情,費用自然也照最高標準來算。
為什麼降低 OpenClaw Token 使用量,不只是省錢而已
最直接的好處當然是省錢,但還有一些會隨時間疊加的附加收益。
便宜的模型通常也更快。Gemini 2.5 Flash-Lite 的速度大約是 每秒 214 個 tokens,而 Opus 大約只有 51——也就是每次互動大約快 4 倍。GPT-OSS-120B 在 Cerebras 上可達 每秒 1,917 個 tokens,大約比 Opus 快 35 倍。對於有 50 次以上工具呼叫的 agent 迴圈來說,這種速度差意味著幾分鐘就能完成,而不是每一輪都等 Opus 那令人痛苦的 13.6 秒首 token 時間。
你還會得到更大的緩衝空間,不容易碰到 rate limit、被限流的 session 也更少,想擴大量使用時也不用跟帳單一起焦慮。
不同使用情境下的預估節省如下:
| 使用者類型 | 預估每月支出(預設) | 完整優化後 | 每月節省 |
|---|---|---|---|
| 輕度(約每天 10 次查詢) | 約 $100 | 約 $12 | 約 88% |
| 中度(約每天 50 次查詢) | 約 $500 | 約 $90 | 約 82% |
| 重度(每天 200+ 次查詢) | 約 $1,750 | 約 $220 | 約 87% |
這些不是假設值。曾有開發者記錄自己從 每月 600–750 美元降到每天 3–4 美元——也就是實打實砍掉 90%——關鍵就是把模型路由與本文後面會提到的隱藏耗損修正疊加起來。
OpenClaw Token 使用量解剖:每個 Token 到底花去哪裡
這一段是多數優化指南會跳過、但其實最重要的部分。你看不見問題,就沒辦法修。
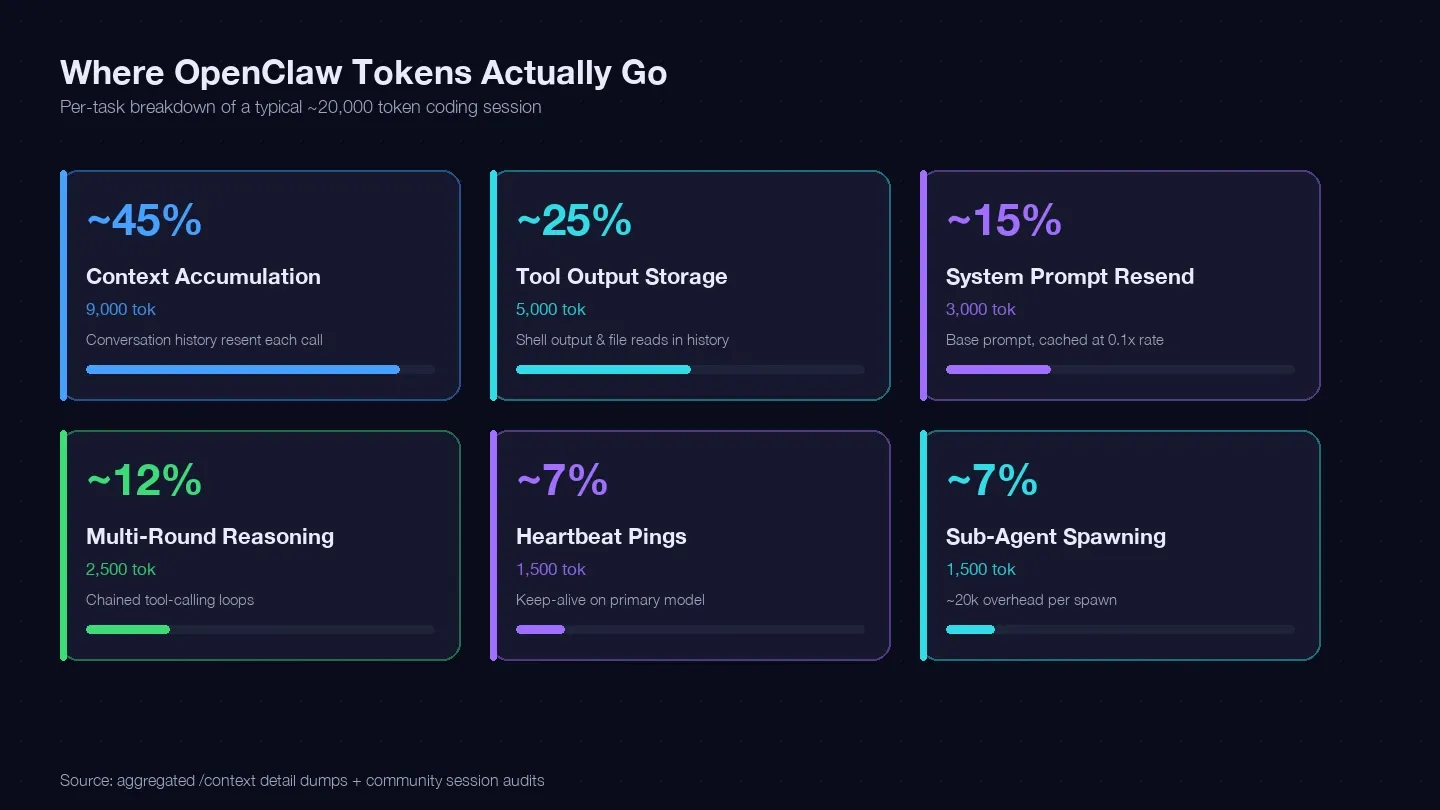
我實際稽核了幾個 session,並交叉比對 LaoZhang 的成本優化指南 和社群的 /context dump,整理出一份典型單一程式任務的 token 帳本。大約 20,000 個 tokens 大致花在這些地方:
| Token 類別 | 通常占比 | 範例(1 個程式任務) | 能否控制? |
|---|---|---|---|
| 上下文累積(每次呼叫都重送對話歷史) | 約 40–50% | 約 9,000 tokens | 可以 — /clear、/compact、縮短 session |
| 工具輸出存放(shell 輸出、檔案讀取結果保留在歷史中) | 約 20–30% | 約 5,000 tokens | 可以 — 減少讀取、縮小工具範圍 |
| 系統提示重送(約 15K 基礎長度) | 約 10–15% | 約 3,000 tokens | 部分可控 — 讀取快取按 0.1 倍費率 |
| 多輪推理(串接式工具呼叫迴圈) | 約 10–15% | 約 2,500 tokens | 依模型選擇與提示詞品質而定 |
| 心跳/保活 ping | 約 5–10% | 約 1,500 tokens | 可以 — 改設定 |
| 子代理呼叫 | 約 5–10% | 約 1,500 tokens | 可以 — 改模型路由 |
最大的一桶——上下文累積——其實就是你的對話歷史在每次 API 呼叫時都被重新送出。某個 真實 session dump 顯示,單是 Messages 區塊就已經有 185,400 個 tokens,而模型甚至還沒開始回應。系統提示和工具又額外增加了約 35,800 個固定開銷。
重點是:如果你沒有在不相關的任務之間清空 session,你就等於在每一輪都把整段對話歷史重新傳一遍,也重新收費一次。
如何監控 OpenClaw Token 使用量(看不到,就無法降低)
在改任何設定之前,先搞清楚你的 tokens 都跑去哪裡。直接跳到「換便宜模型」卻不先監控,就像想減肥卻從來不上體重計。
查看 OpenRouter 儀表板
如果你是透過 OpenRouter 轉送請求,最方便的免設定方式就是 Activity 頁面。你可以依 model、provider、API key 和時間區間篩選。Usage Accounting 檢視會把每次請求的 prompt、completion、reasoning 和 cached tokens 拆開。它也提供匯出按鈕(CSV 或 PDF),方便做長期分析。
要看什麼:哪個模型吃掉最多 tokens,以及 heartbeat 或 sub-agent 請求是否出現了異常大的項目。
稽核本機 API 紀錄
OpenClaw 會把 session 資料儲存在 ~/.openclaw/agents.main/sessions/sessions.json,裡面包含每個 session 的 totalTokens。你也可以執行 openclaw logs --follow --json,即時查看每次請求的紀錄。
有個值得知道的限制是:sessions.json 的 totalTokens 在 compaction 後不會更新,因此儀表板可能會顯示壓縮前的舊數字。實際上應該以 /status 和 /context detail 為準,而不是檔案裡存的總數。
使用第三方追蹤工具(適合中高頻使用者)
LiteLLM proxy 可在 100+ 供應商前方提供一個相容 OpenAI 的端點,並且能 自動記錄每個虛擬金鑰、模型、使用者與團隊的支出。它最強的功能是:可針對每個 key 設硬性預算,而且即使你執行 /clear 也不會失效——就算子代理失控,也不可能突破你設定的上限。
Helicone 更簡單——只要 把 base URL 換成一行,就能得到一個 Sessions 檢視,把相關請求分組。像「幫我修這個 bug」這種提示詞,若展開成 8 次以上子代理呼叫,會被整合成一筆 session,直接看到真實總成本。免費方案:每月 10,000 次請求。
在 OpenClaw 裡快速抽查
日常監控時,這四個 session 內指令就夠用了:
/status— 顯示上下文使用量、最近輸入/輸出 tokens、預估成本/usage full— 每次回應底部的使用量摘要/context detail— 逐檔案、逐技能、逐工具的 token 拆解/compact [guidance]— 強制壓縮,並可附帶焦點提示字串
在修改設定前後都跑一次 /context detail。這就是判斷你的優化到底有沒有效的方式。
OpenClaw 最便宜模型大比拚:哪些平價 LLM 真能扛住 agent 工作
多數指南都會在這裡犯錯。它們只列價格表,然後直接指向最便宜那一列就結束。但基準測試不一定能預測真實的 agent 表現——社群對這件事已經反覆提醒很多次了。正如某位使用者所說:「benchmarks 根本無法真正說明哪個最適合 agentic AI。」
關鍵洞察是:最便宜的模型,不一定會帶來最低總成本。 一個會失敗、還要重試四次的模型,最後可能比一個 第一次就成功 的中階模型更貴。在實際生產環境裡,請預留 5–10% 的重試率——而且如果五個 LLM 呼叫是串接起來的,只要第 4 步失敗,單純重試就會把前面五步全部再跑一次。
以下是我整理的能力矩陣,採用的是基於真實使用回饋的「Real Agentic Score」,不是人工合成的 benchmark:
| 模型 | 輸入 $/1M | 輸出 $/1M | 工具呼叫可靠性 | 多步推理能力 | 真實 Agent 評分(1–5) | 最適合 |
|---|---|---|---|---|---|---|
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | 中等 — 偶爾會迴圈 | 基礎 | ⭐2.5 | 心跳、簡單查詢 |
| GPT-OSS-120B | $0.04 | $0.19 | 尚可 | 尚可 | ⭐3.0 | 平價試驗、重視速度的任務 |
| DeepSeek V3.2 | $0.26 | $0.38 | 不穩定(6 個公開 issue) | 不錯 | ⭐3.0 | 重推理、少量工具呼叫 |
| Kimi K2.5 | $0.38 | $1.72 | 不錯(透過 :exacto) | 尚可 | ⭐3.5 | 簡單到中等程度的程式工作 |
| MiniMax M2.5 / M2.7 | $0.28 | $1.10 | 不錯 | 不錯 | ⭐4.0 | 日常通用程式主力模型 |
| Claude Haiku 4.5 | $1.00 | $5.00 | 很好 | 不錯 | ⭐4.5 | 可靠的中階備援 |
| Claude Sonnet 4.6 | $3.00 | $15.00 | 很好 | 很好 | ⭐5.0 | 複雜多步任務 |
| Claude Opus 4.5/4.6 | $5.00 | $15.00 | 很好 | 很好 | ⭐5.0 | 只保留給最難的問題 |
關於 DeepSeek 和 Gemini Flash 用於工具呼叫的警告
DeepSeek V3.2 表面上看起來很漂亮——在 SWE-Bench 上有 72–74%,價格又比 Sonnet 便宜 11–36 倍。但實際上,跨 Cline、Roo Code、Continue 和 NVIDIA NIM 的 六個獨立 GitHub issue 都記錄了它的工具呼叫行為有問題。Composio 的對決結論是:「DeepSeek V3.2 做出了一部分 app,但在執行、速度和可靠性上都卡住了。」Zvi Mowshowitz 更是一句話總結:「還行又便宜,但……。」
Gemini 2.5 Flash 也有類似落差。一篇 Google AI Developers Forum 的討論串標題叫「Very frustrating experience with Gemini 2.5 function calling performance」,開頭就寫著:「Gemini 模型的 function calling 行為已經變得完全不可靠、不可預測.」
OpenRouter 也特別提醒一個關鍵細節:「同樣權重的模型,在不同 host 上的工具呼叫傾向與準確度可能差異極大.」如果你透過 OpenRouter 轉送便宜模型,請留意 :exacto 標籤——供應商悄悄切換,可能一夜之間就把原本可靠的便宜模型變成昂貴的重試迴圈。
各模型適用時機
- Gemini Flash-Lite: 心跳、保活 ping、簡單問答。絕對不要拿來做多步工具呼叫。
- MiniMax M2.5/M2.7: 日常通用程式工作主力。SWE-Pro 56.22、Terminal-Bench 2 57.0%,價格只有 Sonnet 的一小部分。
- Claude Haiku 4.5: 當便宜模型在工具呼叫上卡住時,用它當可靠備援。工具呼叫可靠性極佳,價格約比 Sonnet 便宜 3 倍。
- Claude Sonnet 4.6: 複雜的多步 agent 工作。這是你真正花錢有感的地方。
- Claude Opus: 只留給最難的問題,其他都不要用它。
(模型價格變動很快,實際套用設定前,請先到 OpenRouter 或各供應商頁面確認最新費率。)
多數指南都會漏掉的隱藏 token 耗損
論壇使用者回報,關閉某些功能可以大幅降成本,但我看過的指南沒有一份把所有隱藏耗損和實際 token 影響整理成一份統一清單。以下是完整拆解:
| 隱藏耗損 | 每次發生的 token 成本 | 修正方式 | 設定鍵 |
|---|---|---|---|
| 預設用 Opus 跑心跳 | 未隔離時每次約 100,000 tokens | 改用 Haiku + isolatedSession | heartbeat.model、heartbeat.isolatedSession: true |
| 子代理自動生成 | 每次啟動前約 20,000 tokens | 子代理改路由到 Haiku | subagents.model |
| 載入整個 codebase 上下文 | 每次自動探索約 3,000–15,000 tokens | 用 .clawignore 排除 node_modules、dist、lockfiles | .clawrules + .clawignore |
| 記憶自動摘要 | 每個 session 約 500–2,000 tokens | 關閉或降低頻率 | memory: false 或 memory.max_context_tokens |
| 對話歷史累積 | 每輪累積 500+ tokens | 不相關任務之間開新 session | 執行 /clear 的紀律 |
| MCP server 工具額外開銷 | 4 個 server 約 7,000 tokens;5 個以上可到 50,000+ | 保持 MCP 簡化 | 移除未使用的 MCP |
| 技能/外掛初始化 | 每載入一個技能 200–1,000 tokens | 關閉未使用技能 | skills.entries.<name>.enabled: false |
| Agent Teams(plan 模式) | 約為一般 session 的 7 倍成本 | 只在真的需要平行工作時使用 | 盡量採順序執行 |
心跳耗損尤其值得單獨點出。預設情況下,心跳每 30 分鐘就會在主模型(Opus)上觸發一次。把 isolatedSession: true 打開後,這一項可以從每次約 100,000 tokens 降到 2,000–5,000 tokens——單這一項就能少掉 95–98%。
兩分鐘內最值得做的三個快速省 token 動作
這三個都沒風險,而且不到兩分鐘就能完成:
-
不同任務之間執行
/clear(5 秒)。 這是單次最有效的 token 節省方式。論壇普遍認為,只要在開始新工作前清空 session 歷史,就能 減少 50–70%。還記得前面 /context dump 裡那個 18.5 萬 token 的 Messages 區塊嗎?/clear會把它清掉。 -
把瑣碎工作切到
/model haiku-4.5(10 秒)。 有策略地切換模型,在日常任務上可帶來 60–80% 的成本降低。Haiku 處理大多數直線型程式工作、檔案查找、commit 訊息都綽綽有餘。 -
把
.clawrules縮到 200 行以下,再加上.clawignore(90 秒)。 你的規則檔每次訊息都會載入。200 行大約就是每輪 1,500–2,000 tokens;1,000 行則會永久讓每次請求多背負 8,000–10,000 tokens。再搭配.clawignore排除node_modules/、dist/、lockfiles 和產生的程式碼,有開發者聲稱只靠這個習慣就 減少 92% token 用量。
一步一步來:三組可直接複製的設定,快速壓低 OpenClaw Token 用量

下面提供三份完整且有註解的 openclaw.json 設定,從「先開始省錢」到「完整優化堆疊」都有。每份都附內嵌註解與每月成本估算。
開始前須知:
- 難度: 初階(Config A)→ 中階(Config B)→ 進階(Config C)
- 所需時間: Config A 約 5 分鐘,Config C 約 15 分鐘
- 你需要: 已安裝 OpenClaw、文字編輯器、可存取
~/.openclaw/openclaw.json
Config A:初階 — 先把錢省下來
五行。零複雜度。把預設模型從 Opus 換成 Sonnet,關閉 memory 開銷,並把心跳隔離到 Haiku。
// ~/.openclaw/openclaw.json
{
"agents": {
"defaults": {
"model": { "primary": "anthropic/claude-sonnet-4-6" }, // 原本是 Opus — 立刻省下 3–5 倍
"heartbeat": {
"every": "55m", // 對齊 1 小時快取 TTL,提升快取命中率
"model": "anthropic/claude-haiku-4-5", // ping 用 Haiku,不要用 Opus
"isolatedSession": true // 約 10 萬 → 2–5 千 tokens / 次
}
}
},
"memory": { "enabled": false } // 每個 session 省約 500–2,000 tokens
}
套用後你應該看到的變化: 先後各跑一次 /status。你每次請求的成本應該會明顯下降,而 OpenRouter Activity 頁面裡的 heartbeat 記錄也應該顯示 Haiku,而不是 Opus。
| 使用等級 | 預設(Opus) | Config A(Sonnet + Haiku 心跳) | 節省 |
|---|---|---|---|
| 輕度(約每天 10 次查詢) | 約 $100 | 約 $35 | 65% |
| 中度(約每天 50 次查詢) | 約 $500 | 約 $250 | 50% |
| 重度(約每天 200 次查詢) | 約 $1,750 | 約 $900 | 49% |
Config B:中階 — 聰明的三層路由
主模型用 Sonnet 處理真正工作。子代理和 compaction 用 Haiku。Claude 被限流時,Gemini Flash-Lite 當便宜備援。fallback 鏈會自動處理供應商故障。
{
"agents": {
"defaults": {
"model": {
"primary": "anthropic/claude-sonnet-4-6",
"fallbacks": [
"anthropic/claude-haiku-4-5", // Sonnet 被限流時使用
"google/gemini-2.5-flash-lite" // 超便宜的最後備援
]
},
"models": {
"anthropic/claude-sonnet-4-6": {
"params": { "cacheControlTtl": "1h", "maxTokens": 8192 }
}
},
"heartbeat": {
"every": "55m", // 55 分鐘 < 1 小時 cache TTL = 可命中快取
"model": "google/gemini-2.5-flash-lite", // 每次 ping 幾毛錢
"isolatedSession": true,
"lightContext": true // 心跳只帶最少上下文
},
"subagents": {
"maxConcurrent": 4, // 從預設 8 降下來
"model": "anthropic/claude-haiku-4-5" // 子代理不需要 Sonnet
},
"compaction": {
"mode": "safeguard",
"model": "anthropic/claude-haiku-4-5", // compaction 摘要交給 Haiku
"memoryFlush": { "enabled": true }
}
}
}
}
預期結果: 你的 logs 裡,子代理項目應該會改成 Haiku 計費。心跳成本幾乎可忽略不計。fallback 鏈也代表即使 Claude 暫時不可用,你的 session 也不會卡死,而是平順降級到 Gemini。
| 使用等級 | 預設 | Config B | 節省 |
|---|---|---|---|
| 輕度 | 約 $100 | 約 $20 | 80% |
| 中度 | 約 $500 | 約 $150 | 70% |
| 重度 | 約 $1,750 | 約 $500 | 71% |
Config C:進階玩家 — 完整優化堆疊
每個子代理分別指定模型、把上下文壓縮固定交給 Haiku、視覺任務走 Gemini Flash、.clawrules 和 .clawignore 都縮緊、停用沒用到的技能。這就是把節省率推進到 85–90% 的設定。
{
"agents": {
"defaults": {
"workspace": "~/clawd",
"model": {
"primary": "anthropic/claude-sonnet-4-6",
"fallbacks": [
"openrouter/anthropic/claude-sonnet-4-6", // 不同供應商作為備援
"minimax/minimax-m2-7", // 便宜的日常主力備援
"anthropic/claude-haiku-4-5" // 最後一層備援
]
},
"models": {
"anthropic/claude-sonnet-4-6": {
"params": { "cacheControlTtl": "1h", "maxTokens": 8192 }
},
"minimax/minimax-m2-7": {
"params": { "maxTokens": 8192 }
}
},
"heartbeat": {
"every": "55m",
"model": "google/gemini-2.5-flash-lite",
"isolatedSession": true,
"lightContext": true,
"activeHours": "09:00-19:00" // 夜間不發心跳
},
"subagents": {
"maxConcurrent": 4,
"model": "anthropic/claude-haiku-4-5"
},
"contextPruning": { "mode": "cache-ttl", "ttl": "1h" },
"compaction": {
"mode": "safeguard",
"model": "anthropic/claude-haiku-4-5",
"identifierPolicy": "strict",
"memoryFlush": { "enabled": true }
},
"bootstrapMaxChars": 12000, // 從預設 20000 降下來
"imageModel": "google/gemini-3-flash" // 視覺任務改走便宜模型
}
},
"memory": { "enabled": true, "max_context_tokens": 800 }, // 最小化記憶
"skills": {
"entries": {
"web-search": { "enabled": false },
"image-generation": { "enabled": false },
"audio-transcribe": { "enabled": false }
}
}
}
每個子代理覆寫範例 —— 貼到 ~/.openclaw/agents/lint-runner/SOUL.md:
---
name: lint-runner
description: 執行 lint/format 檢查並套用簡單修正
tools: [Bash, Read, Edit]
model: anthropic/claude-haiku-4-5
---
最低可用 .clawignore —— 光是這份就能把一般 bootstrap 從 150k 字元壓到約 30–50k:
node_modules/
dist/
build/
.next/
coverage/
.venv/
vendor/
*.lock
package-lock.json
yarn.lock
pnpm-lock.yaml
*.min.js
*.min.css
**/__snapshots__/
**/*.snap
| 使用等級 | 預設 | Config C | 節省 |
|---|---|---|---|
| 輕度 | 約 $100 | 約 $12 | 88% |
| 中度 | 約 $500 | 約 $90 | 82% |
| 重度 | 約 $1,750 | 約 $220 | 87% |
這些數字與兩份獨立的真實使用者回報相符:Praney Behl 記錄的 每月 600–750 美元 → 每天 3–4 美元(省下 90%),以及 LaoZhang 的案例研究顯示在部分優化後從 943 → 347 美元(63%)、1,750 → 1,000 美元(64%)、200 → 70 美元(65%)。
用 /model 指令即時控制 OpenClaw Token 使用量
/model 指令會在保留完整對話上下文的前提下,切換下一輪要使用的模型——不會重設,也不會丟失歷史。這是長期累積省錢效果的日常習慣。
實際工作流:
- 在處理棘手的多檔案重構?繼續用 Sonnet。
- 只是想快速問「這個 regex 是在做什麼?」→
/model haiku,問完再/model sonnet切回去。 - 寫 commit message 或潤飾文件?
/model flash-lite,搞定。
你也可以在 openclaw.json 的 commands.aliases 裡設定別名,把短名稱(haiku、sonnet、opus、flash)對應到完整 provider 字串。每次切換都能少打幾個字。
算一下就知道:每天 50 次查詢都用 Sonnet,大約是每天 3 美元;同樣 50 次查詢若按 70/20/10 分配到 Haiku/Sonnet/Opus,大約是每天 1.10 美元。換算成一個月,就是從 90 美元降到 33 美元——便宜 63%,而且不用換工具,只要改習慣。
加碼:用 Thunderbit 追蹤不同供應商的 OpenClaw 模型價格
用 AI 追蹤不同供應商的模型價格 Get Started Free
在 OpenRouter、Anthropic 直連 API、Google AI Studio、DeepSeek、MiniMax 這麼多模型與供應商之間,價格經常變動。Anthropic 曾一夜之間把 Opus 的輸出價格砍了約 67%。Google 也在 2025 年 12 月把 Gemini 免費方案限制下調了 50–80%。如果要手動維護一份靜態價格試算表,幾乎注定會跟不上變化。
Thunderbit 不需要任何爬蟲程式碼,就能解決這件事。它是一個專為這類結構化資料擷取打造的 Chrome 擴充功能,屬於 AI 網頁爬蟲。
我實際使用的流程是:
- 打開 OpenRouter 的模型頁面,在 Chrome 點 Thunderbit 的「AI Suggest Fields」。它會讀取頁面並建議欄位——模型名稱、輸入價格、輸出價格、context window、provider。
- 按下 Scrape,然後直接匯出到 Google Sheets。
- 用自然語言設定排程抓取——例如「每週一上午 9 點重新抓一次 OpenRouter 模型清單」——之後它就會自動在雲端執行。
從那之後,你的個人價格追蹤表就會自動更新。任何突然便宜 30% 的模型,或任何被標上 Exacto 的 provider,都會在週一早上的試算表裡自動出現,不需要你手動做任何事。我們也在部落格上寫過更多關於 商業用途的 AI 資料擷取 的案例。
如果你是要比對各家供應商頁面(Anthropic、Google、DeepSeek)的價格,Thunderbit 的子頁面抓取會一路跟進每個模型連結,讀取其詳細頁並抓出各供應商費率——當你想知道把 Kimi K2.5 經由 OpenRouter 路由,是否比直接走 NVIDIA Build 更便宜時,這功能特別有用。請查看 Thunderbit pricing 了解免費方案與方案細節。
降低 OpenClaw Token 使用量的重點總結
核心框架:理解 → 監控 → 路由 → 優化。
按影響力排序,最值得先做的是:
- 不要把 Opus 當預設。 把主模型改成 Sonnet 或 MiniMax M2.7,光這一項就能省下 3–5 倍成本。
- 隔離心跳。 設
isolatedSession: true,並把心跳改走 Gemini Flash-Lite。這能把約 10 萬 token 的耗損壓到約 2–5 千。 - 把子代理路由到 Haiku。 每次啟動前就會先載入約 2 萬 tokens 的上下文,別讓這件事發生在 Opus 上。
- 養成
/clear的習慣。 免費、只要 5 秒,而且社群共識認為它比任何單一操作都更能省 token。 - 加入
.clawignore。 排除node_modules、lockfiles 和 build 產物,可以大幅減少 bootstrap 上下文。 - 在變更前後用
/context detail監測。 如果不能測量,就無法改善。
最便宜的模型要看任務而定。心跳用 Gemini Flash-Lite。日常程式碼用 MiniMax M2.7。需要穩定工具呼叫時用 Haiku。複雜多步工作交給 Sonnet。只有在真正最難的問題上才用 Opus,除此之外別碰它。
多數讀者只要用 Config A 或 B,就能在一個下午內看到 50–70% 的節省。要達到完整 85–90%,則需要把模型路由、隱藏耗損修正、.clawignore、session 紀律全部疊起來——但這是做得到的,而且效果很穩定。
常見問題
1. OpenClaw 每個月大概要多少錢?
完全取決於你的設定、使用量和模型選擇。輕度使用者(約每天 10 次查詢)在優化後通常每月花 5–30 美元;若用預設值,則可能超過 100 美元。中度使用者(約每天 50 次查詢)大約落在每月 90–400 美元。重度使用者在預設下可能達到 每月 600–2,000+ 美元——曾有記錄最極端的案例是單月 5,623 美元。Anthropic 內部遙測顯示,中位數大約是 每位開發者每日 13 美元。
2. 目前最便宜、又還適合寫程式的 OpenClaw 模型是哪個?
MiniMax M2.5/M2.7 是最適合一般日常使用的主力模型——工具呼叫表現不錯,SWE-Pro 56.22,價格約每百萬 tokens 0.28 / 1.10 美元。若只是心跳和簡單查詢,Gemini 2.5 Flash-Lite 以 0.10 / 0.40 美元很難被打敗。若你需要很好的工具呼叫能力、但又不想付 Sonnet 的價格,Claude Haiku 4.5 以 1 / 5 美元是非常可靠的中階備援。
3. 我可以在 OpenClaw 裡用免費方案模型嗎?
技術上可以。GPT-OSS-120B 在 OpenRouter 的 :free 標籤和 NVIDIA Build 上都是免費的。Gemini Flash-Lite 也有免費方案(每分鐘 15 次、每天 1,000 次)。DeepSeek 也提供 註冊送 500 萬 free tokens。但免費方案通常限制很嚴、速度較慢,而且可用性不穩。日常使用來說,每百萬 tokens 只要幾毛錢的便宜付費模型,反而可靠得多。
4. 在對話中途用 /model 切換模型,會把上下文弄丟嗎?
不會。/model 會保留整個 session 的上下文——下一輪只是改由新模型處理,完整歷史都還在。這在 OpenClaw 的概念文件裡有確認,在 Claude Code 裡也一樣。你可以自由在 Haiku 和 Sonnet 之間切換,不會失去任何內容。
5. 今天要最快降低 OpenClaw 帳單,最有效的一招是什麼?
在不相關任務之間輸入 /clear。這是免費的、只要五秒,而且會清掉每次 API 呼叫都會重新送出的對話歷史。某個真實 session 顯示累積了 185,000 tokens 的訊息歷史——這些內容每一輪都被重新傳送、重新計費。開始新工作前先清空,是你能建立的最高投資報酬習慣。
試試 Thunderbit 的 AI 網頁爬蟲 Get Started Free




