

網路上的資料量爆炸成長,大家想把這些資料抓下來的需求也跟著快速升高。不過如果您真的去查某個單一的市場規模數字,會發現不同分析師的估算差很多,差距甚至可能到一個數量級,差別往往取決於他們算的是軟體、服務、代理伺服器,還是三者全包。比較誠實的說法是,網頁爬取已經成了資料工作流程裡那個不花俏、卻少不了的一塊。
不管您是商業分析師、行銷人員,還是單純好奇的初學者,能夠從網站擷取資料,正快速變成一項必備技能。如果您跟我一樣,大概也想跳過沒完沒了的複製貼上,直接進入重點:可行的洞察、乾淨的試算表,甚至一點自動化的小魔法。
這就是 Python 派上用場的地方。它就像資料世界的瑞士刀——對初學者來說夠簡單,對於從單一頁面爬取到數千頁抓取也同樣夠強大。在這篇實作教學中,我會帶您了解使用 Python 進行網頁爬取的基礎、示範如何處理動態網站,甚至介紹我們的 Thunderbit——一款由 AI 驅動、免程式碼的網頁爬蟲,讓資料擷取像叫外送一樣簡單。不論您是想學程式碼,還是只想找個捷徑,這篇都很適合您。
什麼是網頁爬取?為什麼要用 Python 從網站擷取資料?
使用 AI 從任何網站擷取資料 Get Started Free
網頁爬取是自動從網站擷取資訊,並將其轉換成結構化格式——像是試算表、CSV 或資料庫——以便進一步分析或商業使用 (PromptCloud)。它不再需要手動複製貼上,而是由爬蟲模擬人類操作,只是速度更快、規模更大。
為什麼這麼有價值?因為在今天的商業世界裡,資料驅動決策就是王道。規模越大,越需要用真實數字而不是感覺來支撐決策——而這些數字,很多一開始都來自別人的網頁。
想像一下,您可以每天監控競爭對手價格、彙整房地產清單,或建立客製化的潛在客戶名單,全都不用大費周章。
那麼,為什麼是 Python?以下就是它成為網頁爬取首選語言的原因:
- **可讀性與簡潔性:**Python 語法乾淨、對初學者友善,讓您很容易撰寫並理解爬取腳本 (PromptCloud)。
- 豐富的生態系:
requests、BeautifulSoup、Scrapy和Selenium等套件,讓爬取、解析與自動化瀏覽器操作都變得輕而易舉。 - **社群支援:**Python 長期穩居 全球最受歡迎的程式語言 之一,網路上有無數教學、論壇與程式碼範例可以參考。
- **可擴充性:**Python 從簡單的一次性腳本,到大規模爬蟲都能勝任。
簡單來說:不論您是完全新手,還是經驗老到的分析師,Python 都是您通往網頁資料世界的入場券。
入門:Python 網頁爬取教學基礎
在進入程式碼之前,先來拆解一下用 Python 從網站擷取資料的基本流程:
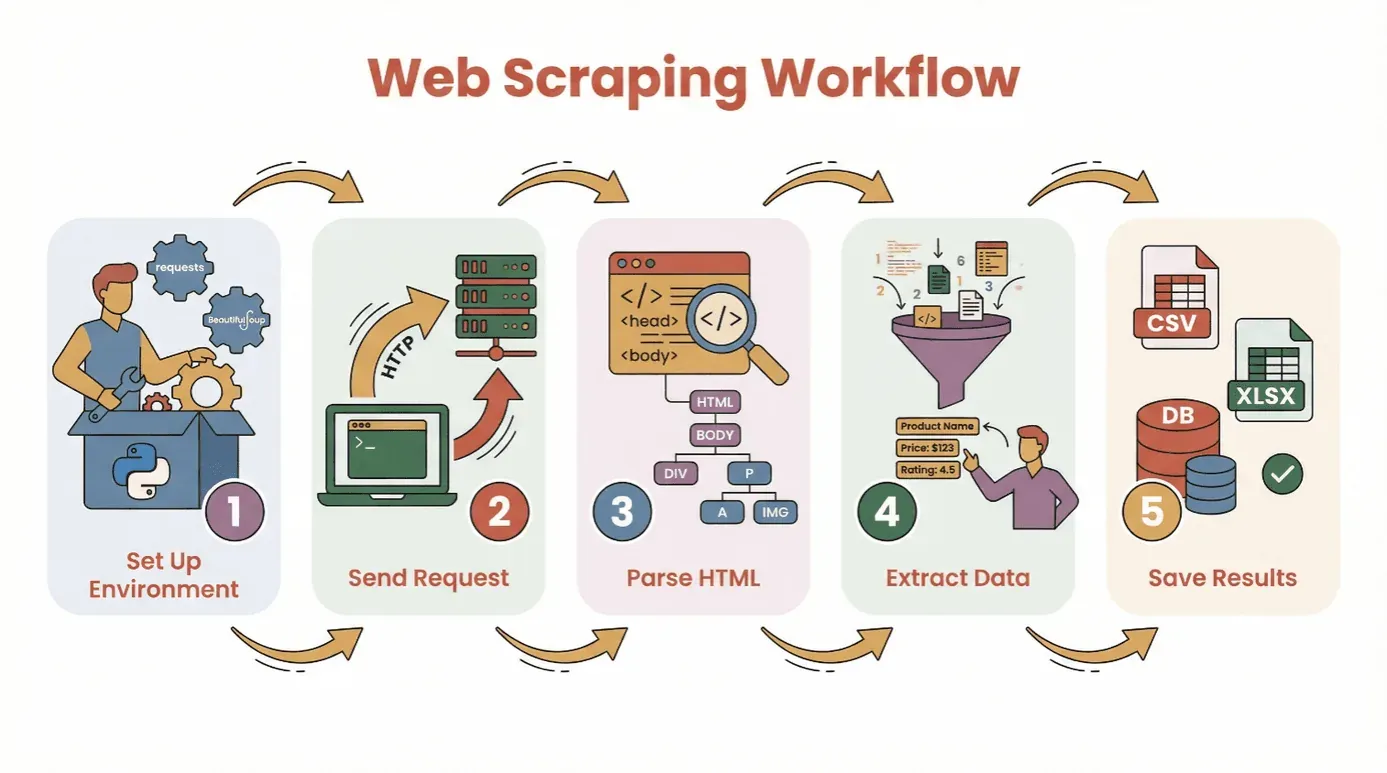
- **設定環境:**安裝 Python 與必要套件(
requests、BeautifulSoup等)。 - **送出請求:**使用 Python 抓取目標網頁的 HTML 內容。
- **解析 HTML:**用解析器瀏覽頁面結構。
- **擷取資料:**定位並抓出您需要的資訊。
- **儲存結果:**將資料存成 CSV、Excel 檔或資料庫,方便分析。
您不需要是程式高手才能開始。如果您知道怎麼安裝 Python 並執行腳本,其實已經成功一半了。對完全的新手來說,我建議使用 虛擬環境 或 Jupyter Notebook,但您也可以用任何基本的文字編輯器。
必備套件:
requests— 用來抓取網頁BeautifulSoup— 用來解析 HTMLpandas— 用來儲存與清理資料(可選,但非常推薦)
如何選擇合適的 Python 網頁爬取套件:BeautifulSoup、Scrapy,還是 Selenium?
不是每個 Python 爬取工具都一樣。以下是三個最受歡迎選項的快速比較:
| 工具 | 最適合 | 優點 | 缺點 |
|---|---|---|---|
| BeautifulSoup | 簡單、靜態頁面;初學者 | 好上手、設定簡單、文件完善 | 不太適合大規模抓取或動態內容 |
| Scrapy | 大規模、多頁面爬取 | 速度快、非同步、內建管線、能處理爬取與資料儲存 | 學習曲線較陡,對小型工作來說大材小用,也無法執行 JavaScript |
| Selenium | 動態/大量 JavaScript 的網站、自動化 | 可渲染 JS、模擬使用者操作、支援登入與點擊 | 較慢、耗資源、設定更複雜 |
BeautifulSoup:簡單 HTML 解析的首選
BeautifulSoup 非常適合初學者與小型專案。它只需要幾行程式碼,就能解析 HTML 並擷取元素。如果您的目標網站大多是靜態內容(沒有花俏的 JavaScript 載入),BeautifulSoup 加上 requests 就夠了。
範例:
import requests
from bs4 import BeautifulSoup
url = "https://example.com"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
titles = [h2.text for h2 in soup.find_all('h2', class_='product-title')]
print(titles)
適用情境:一次性爬取、簡單部落格、商品頁面或目錄網站。
Scrapy:適合大規模或結構化爬取
Scrapy 是一套完整框架,適合爬整個網站或處理成千上萬的頁面。它是非同步的(也就是速度快)、支援資料清理/儲存管線,還能自動追蹤連結。
範例:
import scrapy
class ProductSpider(scrapy.Spider):
name = "products"
start_urls = ["https://example.com/products"]
def parse(self, response):
for item in response.css('div.product'):
yield {
'name': item.css('h2::text').get(),
'price': item.css('span.price::text').get()
}
適用情境:大型專案、排程爬取,或需要速度與結構化處理時。
Selenium:處理動態與大量 JavaScript 的網站
Selenium 可以控制真正的瀏覽器(像 Chrome 或 Firefox),所以它能處理用 JavaScript 載入資料、需要登入,或必須點按按鈕的網站。
範例:
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://example.com/login")
driver.find_element(By.NAME, "username").send_keys("myuser")
driver.find_element(By.NAME, "password").send_keys("mypassword")
driver.find_element(By.XPATH, "//button[@type='submit']").click()
dashboard = driver.find_element(By.ID, "dashboard").text
print(dashboard)
driver.quit()
適用情境:社群媒體、股票網站、無限捲動頁面,或任何「檢視原始碼」看起來是空白的網站。
逐步教學:如何使用 Python 從網站擷取資料(新手教學)
讓我們用 requests 與 BeautifulSoup 走一個真實範例。我們會抓一個簡單的書籍列表網站,擷取標題、作者與價格。
步驟 1:設定 Python 環境
先安裝需要的套件:
pip install requests beautifulsoup4 pandas
接著,在程式中匯入它們:
import requests
from bs4 import BeautifulSoup
import pandas as pd
步驟 2:向網站發送請求
抓取 HTML 內容:
url = "http://books.toscrape.com/catalogue/page-1.html"
response = requests.get(url)
if response.status_code == 200:
html = response.text
else:
print(f"無法擷取頁面:{response.status_code}")
步驟 3:解析 HTML 內容
建立 BeautifulSoup 物件:
soup = BeautifulSoup(html, 'html.parser')
找出所有書籍容器:
books = soup.find_all('article', class_='product_pod')
print(f"這個頁面找到 {len(books)} 本書。")
步驟 4:擷取您需要的資料
逐一迴圈處理每本書並抓出細節:
data = []
for book in books:
title = book.h3.a['title']
price = book.find('p', class_='price_color').text
data.append({"Title": title, "Price": price})
步驟 5:儲存資料供分析使用
轉成 DataFrame 並儲存:
df = pd.DataFrame(data)
df.to_csv('books.csv', index=False)
現在您已經有一份可直接分析的乾淨 CSV 檔了!
疑難排解小技巧:
- 如果結果是空的,請確認資料是不是由 JavaScript 載入的(看下一節)。
- 一定要用瀏覽器的開發者工具檢查 HTML 結構。
- 遇到缺漏資料時,可用
get_text(strip=True)與條件判斷來處理。
解決動態內容:抓取由 JavaScript 渲染的網站資料
現代網站很愛用 JavaScript。有時您要的資料不在最初的 HTML 裡,而是在頁面顯示後才載入。如果您的爬蟲抓不到內容,很可能就是遇到動態內容了。
處理方式:
- **Selenium:**模擬真實瀏覽器,等待內容載入,還能點按按鈕或捲動頁面。
- **Playwright/Puppeteer:**更進階,但概念相近(無頭瀏覽器)。
Selenium 簡明指南:
- 安裝 Selenium 與瀏覽器驅動程式(例如 ChromeDriver)。
- 使用明確等待,讓內容有時間載入。
- 擷取渲染後的 HTML,必要時再用 BeautifulSoup 解析。
範例:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get("https://example.com/dynamic")
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CLASS_NAME, "dynamic-content"))
)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
# 如前面一樣擷取資料
driver.quit()
什麼時候需要 Selenium?
- 如果
requests.get()回傳的 HTML 沒有資料,但您在瀏覽器看得到。 - 如果網站有無限捲動、彈出視窗,或需要登入。
用 AI 簡化網頁爬取:使用 Thunderbit 從網站擷取資料
試試 Thunderbit AI 網頁爬蟲 只要 2 步就能從任何網站擷取資料,無需程式碼。 Get Started Free
老實說,有時您想要的只是資料,不是程式碼。這時 Thunderbit 就派上用場了。Thunderbit 是一款 AI 驅動的 Chrome 擴充功能,只要幾個點擊,就能從任何網站擷取資料,完全不需要 Python。
Thunderbit 的運作方式:
- 安裝 Thunderbit Chrome 擴充功能。
- 打開您的目標網站。
- **點擊 Thunderbit 圖示,按下「AI 建議欄位」。**Thunderbit 的 AI 會掃描頁面,建議要擷取哪些資料(例如商品名稱、價格、Email)。
- 視需要調整欄位,然後點擊「爬取」。
- 直接匯出資料到 Excel、Google Sheets、Notion 或 Airtable。
Thunderbit 的亮點:
- **無需寫程式。**連我媽媽都會用(雖然她還是常常打給我問 Wi‑Fi 問題)。
- **支援子頁面與分頁。**想從多個頁面爬商品詳細資料?Thunderbit 可以自動點頁並幫您合併資料。
- **自然語言指令。**只要告訴它您要什麼(例如「擷取所有商品標題與價格」),AI 就會自己處理。
- **熱門網站一鍵套用範本。**Amazon、Zillow、LinkedIn 等網站,都能一鍵完成。
- **免費匯出資料。**可下載 CSV、Excel,或直接推送到您常用的工具。
Thunderbit 目前已獲得全球超過 100,000 位使用者 信賴。它有免費方案可以先試用,不用先付費——目前的頁面額度請參考 定價頁面,因為限制曾經調整過幾次。對企業使用者來說,它能大幅省時;對 Python 使用者來說,它也是在決定要不要自己寫爬蟲前,先評估工作量的好工具。
爬取後處理:使用 Pandas 與 NumPy 清理和分析資料
擷取資料只是第一步。原始網頁資料通常很亂——重複、缺值、格式不一致。這時 Python 的 pandas 和 NumPy 套件就很有用。
常見清理工作:
- 移除重複:
df.drop_duplicates(inplace=True) - 處理缺失值:
df.fillna('Unknown')或df.dropna() - 轉換資料型態:
df['Price'] = df['Price'].str.replace('$','').astype(float) - 解析日期:
df['Date'] = pd.to_datetime(df['Date']) - 過濾離群值:
df = df[df['Price'] > 0]
基本分析:
- 摘要統計:
df.describe() - 按類別分組:
df.groupby('Category')['Price'].mean() - 快速繪圖:
df['Price'].hist()或df.groupby('Category')['Price'].mean().plot(kind='bar')
如果您需要更進階的數學運算或快速陣列操作,NumPy 會很有幫助。不過對大多數商業使用者來說,pandas 已經能涵蓋 95% 的需求。
**資源:**如果您剛接觸 pandas,可以參考 10 Minutes to pandas 指南。
成功進行 Python 網頁爬取的最佳實務與技巧
網頁爬取很強大,但也伴隨責任。以下是我在爬取時的檢查清單,幫您像專業人士一樣操作(而不是被封鎖或被告):
- **尊重 robots.txt 與服務條款。**一定要先確認網站是否允許爬取 (PromptCloud)。
- **不要對伺服器造成壓力。**請在請求之間加入延遲(
time.sleep(2)),並以接近人工的速度爬取。 - **使用合理的請求標頭。**設定 User-Agent,模擬瀏覽器。
- **妥善處理錯誤。**使用 try/except,並在失敗時重試。
- **必要時輪換代理伺服器。**若是大規模爬取,建議使用代理池以避免 IP 被封。
- **保持道德與合法。**未經許可,不要爬取登入後可見的內容或個人資料。
- **記錄流程。**把爬取了什麼、從哪裡抓、什麼時候抓的,都記下來。
- **有官方 API 就優先使用。**有時候比起抓 HTML,還有更好的方法。
想了解更多技巧,請參考 終極網頁爬取指南。
結論與重點整理
使用 Python 進行網頁爬取,是把網路上的混亂資訊轉化為結構化、可行資料的超能力。不論您是使用程式碼(requests、BeautifulSoup、Scrapy 或 Selenium),還是像 Thunderbit 這樣的免程式碼工具,您都能從網站擷取資料,發掘新的洞察。
請記住:
- 先從簡單開始——先爬單一頁面,再挑戰大型專案。
- 依需求選對工具(基礎用 BeautifulSoup、規模用 Scrapy、動態網站用 Selenium、免程式碼用 Thunderbit)。
- 用 pandas 和 NumPy 清理並分析資料。
- 永遠負責任且合乎倫理地爬取。
準備好自己動手試試了嗎?先從一個小專案開始——也許是抓今天的新聞標題,或一份商品清單——看看您能多快從原始網頁變成乾淨的試算表。如果您想跳過程式碼,請 下載 Thunderbit,讓 AI 幫您完成繁重工作。
想看更多教學、技巧與網頁爬取知識,歡迎前往 Thunderbit 部落格。
常見問題
1. 什麼是網頁爬取?為什麼 Python 這麼受歡迎?
網頁爬取是自動從網站擷取資料的過程。Python 之所以受歡迎,是因為語法易讀、套件強大(像 BeautifulSoup、Scrapy 和 Selenium),而且社群支援非常充足 (PromptCloud)。
2. 我應該用哪個 Python 套件來做網頁爬取?
簡單的靜態頁面用 BeautifulSoup;大規模或多頁面爬取用 Scrapy;動態或 JavaScript 很多的網站用 Selenium。每個工具都有各自的強項,取決於您的需求 (IPRoyal)。
3. 如果網站是用 JavaScript 載入資料,我該怎麼辦?
對於 JavaScript 渲染的內容,請用 Selenium(或 Playwright)模擬瀏覽器,並在擷取資料前等待內容載入。有時候,透過查看網路流量,也能找出底層 API 端點。
4. Thunderbit 是什麼?它如何簡化網頁爬取?
Thunderbit 是一款 AI 驅動的 Chrome 擴充功能,讓您無需寫程式就能從任何網站擷取資料。它會用 AI 建議欄位、處理子頁面與分頁,並可直接匯出到 Excel、Google Sheets、Notion 或 Airtable。
5. 我該如何在 Python 中清理和分析爬來的資料?
使用 pandas 來移除重複、處理缺失值、轉換資料型態並進行分析。NumPy 很適合數值運算。若要視覺化,pandas 也能搭配 Matplotlib 快速繪圖 (10 Minutes to pandas)。
祝您爬取順利——也願您的資料永遠乾淨、結構化,隨時可用。
試用 AI 網頁爬蟲 Get Started Free
了解更多




