如果您曾嘗試從現代網站抓資料——像是房地產平台、電商網站,甚至是您最愛的社群動態牆——很可能都會碰到瓶頸。您打開頁面、檢視 HTML,然後……什麼也沒有。您真正想要的關鍵資訊(價格、清單、評論)根本不在那裡。原因在於,今天的網路早已不只是 HTML 而已——它是由 JavaScript 驅動的,而且現在幾乎99% 的網站都使用前端腳本來渲染內容()。傳統爬蟲就像只看劇本來理解一部電影——完全錯過了現場正在發生的精彩內容。
我在 SaaS 和自動化領域待了多年,親眼看過這場轉變如何讓商務使用者、業務團隊和研究人員傷透腦筋。但好消息是:掌握 JavaScript 爬取,已經不再只是開發者的專利。只要方法對了,再加上一點 AI 工具的幫助(例如 ),任何人都能從最動態、最互動的網站中擷取資料。接下來,我們就來拆解什麼是 JavaScript 爬取、它為什麼重要,以及您該如何開始——完全不用寫程式。
什麼是 JavaScript 爬取?為什麼它對現代網頁資料擷取很重要?
先從基礎開始。JavaScript 爬取指的是使用能夠載入網頁、執行其中所有 JavaScript,並擷取腳本執行後才出現內容的工具或機器人。這和傳統 HTML 抓取有很大差別;後者只會抓取伺服器送來的原始程式碼。對今天的網站來說,那份原始 HTML 往往只是個骨架——真正的內容(產品清單、評論、價格)通常是由 JavaScript 補上去的,有時甚至要等您捲動、點擊或互動後才會出現。
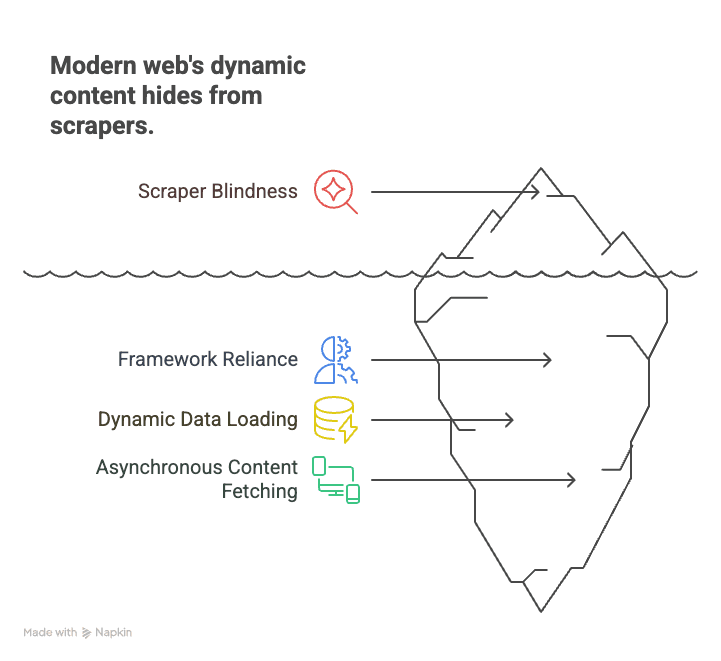
這為什麼重要? 因為現代網站多半建立在 React、Angular 和 Vue 這類框架上。這些單頁應用程式(SPA)會即時載入資料,讓靜態爬蟲對大多數內容都「看不見」。例如:
- 電商網站: 商品價格和庫存數量可能要在您捲動或套用篩選後才會載入。
- 房地產網站: 房源清單會隨著您往下滑而出現,細節則是動態載入。
- 社群媒體: 貼文、留言和按讚數都是非同步抓取,初始 HTML 裡根本看不到。
傳統爬蟲只會抓頁面,看到一個空殼,重要內容全都漏掉。相對地,JavaScript 爬取就像把頁面打開在 Chrome 裡,讓所有腳本跑完,再把您看到的內容抓下來——就跟人類操作一樣。
簡單來說: 如果您想在 2025 年抓取幾乎任何現代網站的資料,就得掌握 JavaScript 爬取。否則,您會錯過大部分重點內容()。
JavaScript 爬取的主要挑戰(以及如何克服)
JavaScript 爬取不只是「抓取,但步驟更多」而已。它有自己的一套難題。以下是您會遇到的挑戰,以及如何逐一破解。
動態內容渲染
挑戰: 大多數內容根本不在 HTML 裡。它是在頁面開啟後才透過 JavaScript 載入——有時要等捲動、點擊或網路請求之後才會出現。如果您只抓 HTML,就只會拿到佔位符或空容器。
解法: 使用 無頭瀏覽器——這種工具能模擬真實瀏覽器、執行所有腳本,並等待內容出現。像 和 就是這方面的業界標準。它們能讓您:
- 開啟頁面並讓 JavaScript 跑完。
- 等待特定元素載入(例如「.product-list」)。
- 從 DOM 中擷取完整渲染後的內容。
這種做法現在已經是抓取動態網站的黃金標準()。
反機器人與自動化防護
挑戰: 網站現在越來越會阻擋機器人。您可能會遇到:
- CAPTCHA 驗證
- IP 封鎖或流量限制
- 瀏覽器指紋辨識(檢查您是不是真人)
- 誘捕陷阱(用假連結抓機器人)
解法: 謹慎爬取,並模擬真人行為:
- 遵守 robots.txt 和服務條款。
- 控制請求頻率——加入隨機延遲,不要狂打伺服器。
- 輪換 IP,如果您要大規模抓取(但請以合乎倫理的方式操作)。
- 使用真實的瀏覽器標頭,避免明顯的機器人特徵。
- 不要在未經允許下抓取登入後內容或繞過 CAPTCHA。
例如,Thunderbit 鼓勵使用者只抓取公開可存取的資料,並內建合規最佳實務()。
無限捲動與使用者觸發事件
挑戰: 很多網站使用無限捲動,或必須點擊才能載入更多資料。如果您的爬蟲只抓取初始可見內容,就會漏掉大部分資訊。
解法: 使用瀏覽器自動化來:
- 模擬捲動(像使用者一樣載入更多結果)。
- 點擊「載入更多」按鈕或分頁標籤。
- 等待新內容出現後再進行擷取。
Thunderbit 的 AI 能自動辨識這些模式,並替您處理捲動或分頁,您不必自己寫客製化腳本()。
維持效能與規模化
挑戰: 每個頁面都跑一次無頭瀏覽器,資源消耗很高。抓取數百或數千個頁面,速度會很慢,也很吃電腦效能。
解法: 使用並行爬取——同時執行多個瀏覽器或分頁。或者更好的是,把工作交給雲端。Thunderbit 的雲端抓取加速器(又稱 Lightning Network)一次最多可抓取 50 個頁面,大幅加快大型任務的處理速度()。
Thunderbit:讓 JavaScript 爬取變得簡單又強大
老實說:大多數商務使用者都不想寫程式、除錯選擇器,或盯著腳本跑。這就是我們打造 的原因——一款由 AI 驅動的網頁爬蟲,專為需要從動態、JavaScript 密集型網站取得資料的非開發者設計。
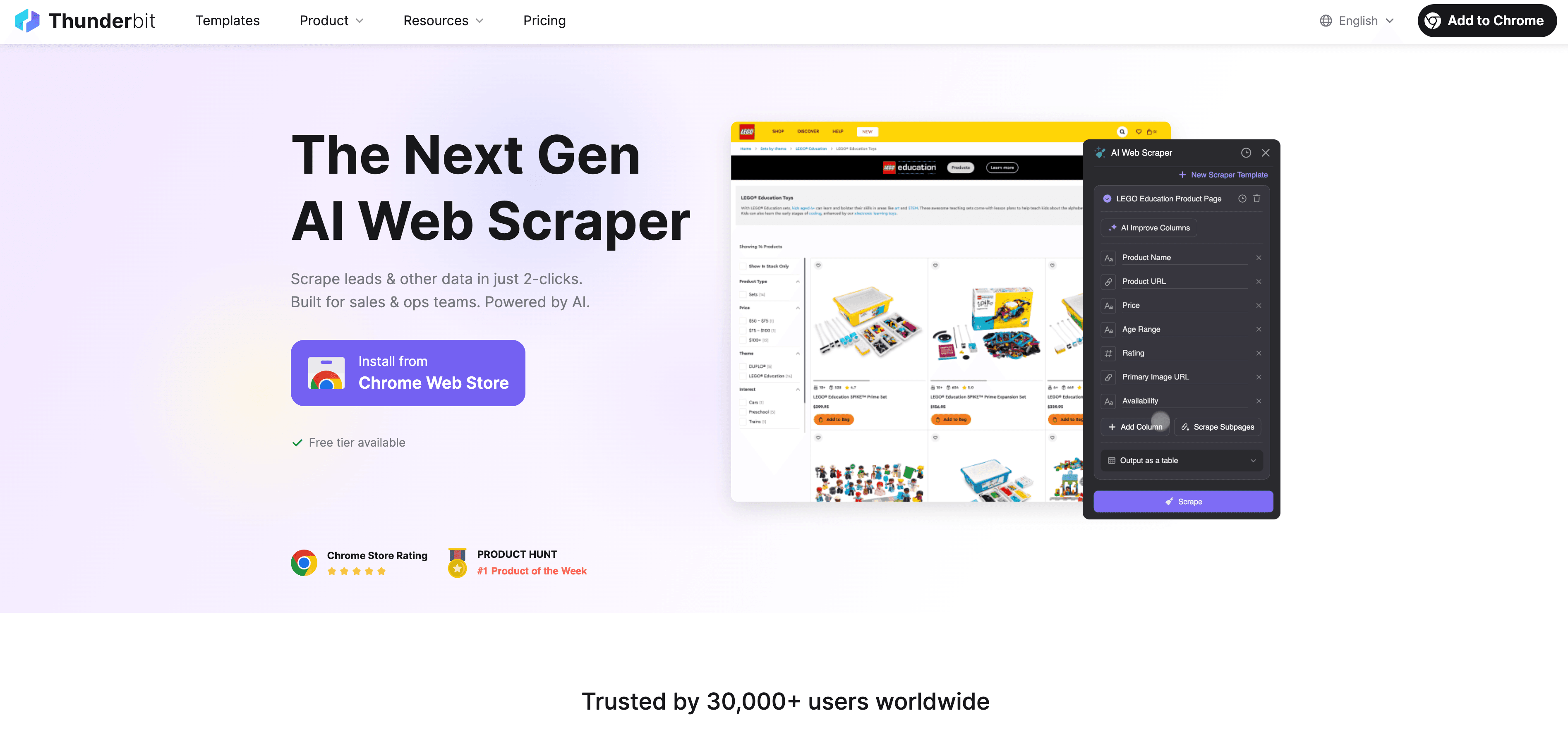
以下是 Thunderbit 如何幫您省下 JavaScript 爬取的麻煩:
- AI 建議欄位: 只要點一下「AI 建議欄位」,Thunderbit 的 AI 就會掃描頁面、推薦最適合擷取的欄位,並設定正確的資料類型。再也不用猜來猜去或反覆試錯。
- 自然語言擷取: 用簡單英文描述您要什麼(例如「抓取產品名稱、價格和評分」),Thunderbit 就會幫您想辦法取得。
- 處理動態內容: Thunderbit 會在真實瀏覽器中執行(您的 Chrome 或雲端),因此它會執行所有 JavaScript,並等待內容載入——就像真人一樣。
- 支援子頁面與分頁: 需要抓多頁資料,或追蹤到子頁面(例如商品詳情)嗎?Thunderbit 會自動處理,並把所有資料整合成一個表格。
- 雲端加速: 大型任務時,Thunderbit 的 Lightning Network 可在雲端一次抓取最多 50 個頁面,讓您的電腦完全不費力。
- 免程式碼、介面友善: 如果您會用 Excel,就會用 Thunderbit。點選操作即可,無需任何技術設定。
- 免費匯出資料: 可將資料匯出到 Excel、Google Sheets、Airtable、Notion 或 JSON——不收額外費用。
Thunderbit 已獲全球超過 30,000 位使用者信賴,從業務團隊到電商營運人員,再到房地產專業人士都在使用()。
AI 建議欄位與自然語言擷取
這正是 Thunderbit 最亮眼的地方。您不需要在 HTML 裡東找西找,也不必寫 XPath 選擇器;只要按個按鈕,Thunderbit 的 AI 就會幫您做重活。它會讀取頁面、理解結構,並準確建議該擷取哪些內容。如果您有特定需求,只要用簡單英文打出來——Thunderbit 的 AI 會把您的要求對應到正確元素。
這對初學者來說是革命性的改變。您不需要懂 HTML、CSS 或 JavaScript。只要說出您要什麼,其餘交給 AI 處理即可()。
分頁與子頁面爬取
Thunderbit 不只是只能抓單頁。它可以:
- 辨識並處理分頁(點擊「下一頁」或透過捲動載入更多內容)。
- 抓取子頁面(例如商品詳情、作者個人頁或評論),並把資料合併到主表格中。
- 處理無限捲動,模擬使用者操作,讓您拿到全部資料,而不只是初始畫面上看得到的部分。
例如,要抓取一個有 20 頁商品的電商分類頁?Thunderbit 會自動逐頁點過去,並把結果整合起來。需要每個商品頁的詳細資料?使用子頁面爬取,Thunderbit 就會逐一造訪每個連結、擷取額外資訊,並豐富您的資料集()。
Lightning Network 與雲端加速:擴大 JavaScript 爬取規模
當您需要抓取數百或數千個頁面時,一頁一頁慢慢來並不實際。這就是 Thunderbit 的 Lightning Network 派上用場的地方。
- 雲端抓取: 將繁重工作交給 Thunderbit 的雲端伺服器(位於美國、歐洲和亞洲)。雲端一次可抓取最多 50 個頁面,大幅提升大型任務速度。
- 並行爬取: Thunderbit 的雲端會把工作切分給多個 worker,而不是等每個頁面在您的瀏覽器裡慢慢載入。抓 1,000 個商品頁?雲端幾分鐘就能完成,不是幾小時。
- 排程爬取: 需要每天監控價格或列表嗎?只要用自然語言設定排程(例如「每天下午 9 點」),Thunderbit 就會自動執行任務,並把資料匯出到您的 Google Sheet 或資料庫()。
對需要即時資料的大型銷售、電商和營運團隊來說,這真的是救星——而且不必雇用開發者或架設伺服器。
多頁與大量資料擷取
Thunderbit 讓您很容易:
- 抓取整個目錄或型錄(例如某分類下的全部商品、某區域的全部房源)。
- 一鍵匯出結果到 Excel、Google Sheets、Airtable 或 Notion。
- 省下數小時甚至數天的手動工作——有使用者在不到 10 分鐘內,就抓到了數百筆房地產清單,還包含經紀人資訊。
逐步指南:如何用 Thunderbit 開始 JavaScript 爬取
準備試試看了嗎?以下是使用 Thunderbit 的入門方式——即使您以前從沒抓過網站也沒問題。
設定您的第一個爬取任務
- 安裝 Thunderbit: 下載 。註冊免費帳號。
- 選擇目標網站: 前往您想抓取的網站。如果需要登入,請先登入(Thunderbit 會在您的瀏覽器環境中運作)。
- 開啟 Thunderbit: 點擊 Chrome 工具列上的 Thunderbit 圖示。選擇您的資料來源(目前頁面、URL 清單,或檔案上傳)。
- 選擇執行模式: 小型任務或需要登入的網站,請使用 瀏覽器模式。大型任務則切換到 雲端模式 進行並行爬取。
- AI 建議欄位: 點擊「AI 建議欄位」。Thunderbit 的 AI 會掃描頁面並建議要擷取的欄位(例如「產品名稱」、「價格」、「圖片網址」)。
- 調整欄位: 視需要重新命名、新增或移除欄位。如果您想格式化或分類資料,也可以加入自訂 AI 指令。
- 設定分頁/捲動: 如果網站使用分頁或無限捲動,請在 Thunderbit 的設定中開啟對應選項。
- 點擊「抓取」: Thunderbit 會載入頁面、執行所有 JavaScript,並把資料擷取到表格中。
擷取與匯出資料
- 預覽結果: Thunderbit 會在表格中顯示您的資料。請抽查完整性與準確性。
- 匯出: 點擊「匯出」,可下載為 Excel、CSV、JSON,或直接傳送到 Google Sheets、Airtable 或 Notion。
- 驗證: 把幾筆資料和實際網站對照,確認內容完全一致。
- 疑難排解: 如果資料少抓了,試著先捲動頁面、調整 AI 指令,或切換到雲端模式以提升效能。
若想看更詳細的操作流程,請參考 或 。
安全且合規的 JavaScript 爬取最佳實務
能力越大,責任越大。以下是如何確保您的做法符合法律與倫理:
- 尊重 robots.txt 與服務條款: 務必確認網站是否允許抓取。如果明文寫著「禁止機器人」,就不要硬闖()。
- 避免抓取個人資料: GDPR 和 CCPA 會把姓名、電子郵件和個人檔案視為受保護資訊——即使它們是公開的也一樣。只有在您有正當理由且取得同意時,才應抓取個資。
- 不要繞過登入或 CAPTCHA: 這屬於法律灰色地帶,甚至更糟。請只處理公開資料。
- 控制請求頻率: 不要讓伺服器超載。Thunderbit 的雲端模式會分散請求並輪換 IP,以降低被封鎖的風險。
- 以道德方式使用資料: 不要重新發布受著作權保護的內容,也不要濫用抓取來的資訊。
- 收到刪除請求就刪除: 如果有人要求您移除其資料,請照做。
Thunderbit 的設計本身就鼓勵合規——只抓公開資料、不做駭入,並提供清楚的匯出選項,方便您負責任地使用。
避免法律風險
- 只抓取公開、非個人資料。
- 不要抓明確禁止抓取的網站。
- 如果不確定,就先詢問許可或使用網站的官方 API。
- 保留您抓了什麼、何時抓的紀錄。
- 一旦收到停止與終止要求,請立即配合。
若想深入了解,請參考 。
JavaScript 爬取方案比較:Thunderbit vs. 傳統工具
| 面向 | Puppeteer/Playwright(程式碼) | Sitebulb(SEO 爬蟲) | Thunderbit(AI 無程式碼) |
|---|---|---|---|
| 設定時間 | 數小時(需要寫程式) | 中等(需要設定) | 數分鐘(點選即可) |
| 所需技能 | 高(僅限開發者) | 中等 | 低(任何人都能用) |
| 支援 JS 內容 | 可以(需手動撰寫腳本) | 可以(用於 SEO) | 可以(AI 自動處理) |
| 分頁/子頁面 | 手動撰寫腳本 | 有限 | 自動(AI 辨識) |
| 維護成本 | 高(頁面變動就容易壞) | 中等 | 低(AI 可適應) |
| 擴充性 | 手動(自己寫程式) | 有限 | 內建雲端(50 倍) |
| 匯出選項 | 手動(自己寫程式) | CSV/Excel | Excel、Sheets、Notion |
| 最適合 | 開發者、自訂流程 | SEO 稽核 | 商務使用者、分析師 |
對想快速拿到結果、又不想碰技術麻煩的商務使用者來說,Thunderbit 無疑是更清楚的贏家()。
結論與重點整理
JavaScript 爬取已不再是小眾技能——對任何需要 2025 年網頁資料的人來說,它都是必備能力。現在幾乎99% 的網站都在使用前端腳本,傳統抓取方式早就不夠用了()。好消息是:您不必是開發者,也能精通它。
請記住以下幾點:
- 動態內容無所不在: 如果您想抓現代網站,就需要能執行 JavaScript 的工具。
- 挑戰真實存在,但可被解決: 無頭瀏覽器、智慧等待與雲端加速,讓最棘手的資料也能被擷取。
- Thunderbit 讓一切更簡單: 透過 AI 欄位建議、自然語言擷取、子頁面與分頁支援,以及雲端加速,Thunderbit 把強大的 JavaScript 爬取能力帶到每個人手上。
- 保持合規: 永遠尊重網站規則、隱私法規與道德準則。
- 今天就開始: 安裝 Thunderbit、選一個網站,看看只要幾次點擊,您能解鎖多少資料。
想再深入一點?歡迎查看 的更多指南,或觀看我們的 逐步示範。
祝您爬取順利——也願您的資料永遠動態、完整,隨時可用。
常見問題
1. 什麼是 JavaScript 爬取?它和傳統抓取有什麼不同?
JavaScript 爬取是使用能載入網頁、執行其中所有 JavaScript,並擷取腳本執行後才出現內容的工具。傳統抓取只會擷取原始 HTML,因此會漏掉現代網站上的大多數內容。
2. 為什麼我需要 JavaScript 爬取來擷取商務資料?
因為幾乎所有現代網站都使用 JavaScript 動態載入內容。如果沒有 JavaScript 爬取,您就會錯過產品清單、評論、價格以及其他關鍵資料。
3. Thunderbit 如何幫初學者簡化 JavaScript 爬取?
Thunderbit 使用 AI 來建議欄位、處理動態內容,並自動化分頁與子頁面爬取。您只要用簡單英文描述想要的內容,不需要寫程式。
4. JavaScript 爬取合法嗎?我該注意什麼?
只要負責任地操作,JavaScript 爬取就是合法的——只抓公開資料、尊重 robots.txt 和服務條款,且未經同意不要抓取個人資訊。Thunderbit 鼓勵合規與負責任的使用。
5. 如果我要處理大量任務,如何擴大 JavaScript 爬取規模?
Thunderbit 的 Lightning Network(雲端抓取)讓您一次最多抓取 50 個頁面,能輕鬆處理像價格監控或名單開發這類跨數千頁的大型任務。
了解更多: