在這個數據掛帥的時代,幾乎每間公司都在搶著把網路上的原始資料轉化成有用的商業洞察。我親身體會過,一位厲害的資料爬蟲專家,真的能徹底翻轉企業的決策流程、加速市場調查,甚至讓公司在競爭中搶得先機。但現實是:要找到對的人才,遠比你想像的複雜。現在資料爬蟲專家的需求正夯,選對人和選錯人,差別就在於你能不能拿到乾淨、合規又能用的商業數據,還是只得到一堆雜亂沒用的資訊。

如果你正準備招募資料爬蟲專家,放心,你絕對不是唯一一個。全球網頁爬蟲市場成長超快,現在各行各業都靠穩定的數據流來維持競爭力()。隨著工具越來越進化,像 這種 AI 平台崛起,加上法規越來越嚴格,選才時你要考慮的絕對不只技術力。以下是我在招募資料爬蟲人才時,自己踩過的坑和學到的經驗,分享給你,希望能幫你找到真正能帶動業務成長的專家。
招聘前,先搞清楚你的資料爬取需求
在寫職缺說明前,先問自己:我們到底要抓什麼資料?目的是什麼?我看過太多專案就是因為這題沒想清楚,最後整個方向都歪掉。你需要的是結構化資料(像整齊的商品價格表),還是要處理亂七八糟的非結構化資料(像評論、圖片或自由文字)?是一次性抓完就好,還是要定期自動更新?
需求定義清楚,才能讓商業目標跟技術需求對齊,也能讓招募流程更順。舉例來說,從電商網站抓結構化資料,跟從社群媒體抓情感分析、或從 PDF 挖法律資訊,所需技能完全不同。
厲害的公司通常會在招募前,先把爬取需求規劃得很細——像是目標網站、要抓的欄位、更新頻率、合規要求都列出來()。這種清楚度,才能吸引到真正適合專案的高手,而不是只會寫腳本的工程師。
結構化 vs. 非結構化資料:差在哪?
簡單說:
- 結構化資料:有明確架構、格式固定,像表格、試算表或資料庫。常見的有商品清單、股價、聯絡人名單。抓這類資料通常比較簡單,Thunderbit 這類工具可以直接把網頁表格轉成可用的試算表()。
- 非結構化資料:內容亂、格式不一,像部落格文章、圖片、PDF 或用戶評論。這類資料常常要靠 AI 解析、自然語言處理,甚至影像辨識等進階技術()。
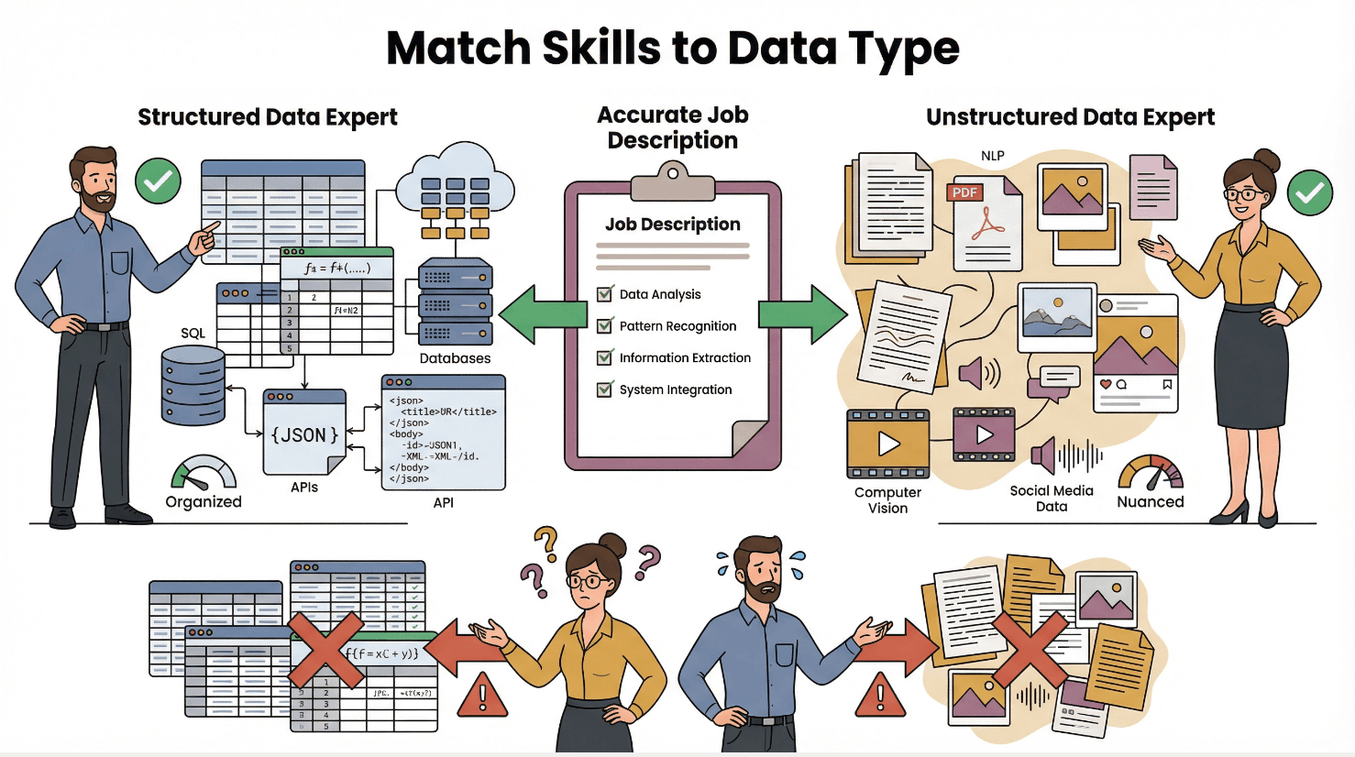
資料的複雜度,直接決定你要找什麼樣的專家。擅長結構化資料的人,不一定能搞定非結構化來源,反過來也一樣。記得讓職缺說明反映出專案的真實挑戰。
把候選人技能和專案需求精準對上
當你把資料需求想清楚,下一步就是把這些需求轉成具體的技能要求。我自己會特別注意:
- 技術力:熟悉各種爬蟲工具(不管是寫程式還是無程式碼)、懂 HTML/CSS/JavaScript、有反爬蟲經驗,還有資料清理能力()。
- 解決問題的能力:能不能處理網站突發變動、CAPTCHA 驗證或需求臨時改變?
- 細心程度:爬蟲不是只會抓資料,還要確保每次都能抓到正確、格式一致的資料。
- 軟實力:溝通、獨立作業、適應力。資料爬取常常要跟業務團隊協作、快速調整方向,還要有耐心。
最理想的候選人,就是有跟你專案挑戰高度吻合經驗的人。像是如果你的網站有很強的反爬蟲機制,就要找有代理伺服器、瀏覽器自動化或 AI 工具經驗的人。
評估現代工具(像 Thunderbit)操作經驗
AI 驅動、無程式碼工具像 的出現,已經徹底改變資料爬蟲專家的工作方式。現在,比起誰能寫出最漂亮的 Python 程式,更重要的是誰能快速、穩定、大規模交付成果。
Thunderbit 讓用戶只要用自然語言描述需求,點一下「AI 建議欄位」,剩下的交給 AI 處理。這對非技術團隊或多語言資料抓取特別有幫助()。我在面試時,會問候選人有沒有用過 Thunderbit 這類工具,以及他們怎麼用這些工具解決實際問題。
熟悉 AI 工具是大加分,代表他們能更快適應新網站、處理複雜或動態內容,也能減少後續維護()。同時也代表他們有跟上產業趨勢。
評估技術實力和實戰解題能力
技術力是基本門檻,但要怎麼評估?我建議用實作測驗和作品集審查。請候選人分享最近的專案:目標是什麼?遇到哪些挑戰?怎麼處理反爬蟲或資料清理?
也可以設計一個貼近實際需求的作業,比如「從這個電商網站抓商品名稱、價格和圖片,還要處理分頁和子頁面」。如果能用程式碼和 Thunderbit 這類無程式碼工具都完成,會更加分。
觀察他們能不能清楚說明思路、紀錄流程,遇到問題時能不能靈活調整。最優秀的專家,會把爬蟲當成持續優化的流程,而不是一次性任務()。
測試反爬蟲和深度爬取能力
現在網站的反爬蟲機制越來越聰明,你的專家也要跟得上。面試時可以問:
- 反爬蟲經驗:怎麼處理 CAPTCHA、IP 封鎖或 User-Agent 偵測?有沒有用過瀏覽器自動化或高級代理()?
- 深度爬取:能不能不只抓列表頁,還能深入子頁、PDF 或圖片?
- 應變能力:網站臨時改版時,會怎麼處理?
一個好的技術測驗,可以要求從有基本反爬蟲的網站抓資料,或要求候選人透過子頁面補充表格資料——Thunderbit 的子頁爬取功能就能做到這點。
重視 AI 和無程式碼爬蟲工具的實戰經驗
純手寫腳本的時代已經過去了。AI 和無程式碼工具讓更多人能參與資料爬取,懂得善用這些平台的專家,能更快、更穩定交付成果,維護成本也更低。
以 Thunderbit 為例,具備以下功能:
- AI 建議欄位:AI 自動掃描頁面,推薦可提取的欄位,完全不用手動設定。
- 子頁爬取:自動拜訪每個子頁,讓你的資料集更完整。
- 多語言支援:支援 34 種語言,國際專案也沒問題。
- 即時匯出:可以直接把結果匯出到 Excel、Google Sheets、Notion 或 Airtable。
招募時,記得找能熟練運用這些功能的候選人。可以請他們分享用 Thunderbit(或類似工具)解決複雜爬取問題的經驗,或在面試現場直接實作。
以 Thunderbit 為標竿:進階技能檢核
以下是能展現高階 Thunderbit 操作力的幾個指標:
- 自訂 AI 指令:能不能用 Field AI Prompts 精準提取和標註資料?
- 子頁和分頁爬取:有沒有用過 Thunderbit 處理多層級資料抓取?
- 資料匯出和整合:能不能熟練把資料匯出到各平台並進行清理?
- 持續學習:有沒有關注 Thunderbit 最新功能和更新?
面試問題舉例:
- 「請描述你用 Thunderbit 子頁爬取豐富資料集的經驗,遇到哪些挑戰?」
- 「你怎麼利用 AI 建議欄位加快工作流程?」
- 「有沒有自訂過 Field AI Prompts 來解決棘手的資料提取?」
確保合法與道德的資料收集
這點超級重要。網頁上看得到的資料,不代表你就能隨便抓()。招募資料爬蟲專家時,一定要確認他們懂相關法律和道德界線。
要注意的法規包括:
- GDPR(歐盟):保護個人資料和隱私()。
- CCPA(加州):規範加州居民個資收集()。
- 著作權和資料庫權利:即使資料公開,抓取受著作權保護或專有資料還是可能違法()。
- 網站服務條款:很多網站明文禁止爬蟲()。
近年法院多傾向允許抓取公開資料,但法規還在變動中()。厲害的專家會懂得怎麼合規、道德地設計爬蟲方案。
面試時檢測合規意識
可以問這些問題:
- 「你怎麼確保爬蟲專案符合 GDPR 或 CCPA?」
- 「你會怎麼避免抓取受著作權或敏感資料?」
- 「遇到網站明確禁止爬蟲時,你會怎麼處理?」
如果對方答得很模糊、不懂隱私法,或對合規態度很隨便,這就是警訊。你要找的是把合規當成核心職責的人。
建立持續學習和適應變化的團隊文化
網頁爬蟲領域變化超快。網站會改版,反爬蟲技術一直進化,新工具也不斷冒出來。最厲害的資料爬蟲專家,永遠保持學習熱忱。
招募時可以觀察:
- 有沒有在追產業部落格或參加爬蟲社群?
- 有沒有嘗試新工具或 Thunderbit 最新功能?
- 能不能說明怎麼因應法規或技術變動調整工作流程?
鼓勵團隊持續追蹤 Thunderbit 新功能、參加線上研討會,甚至參與開源專案。這種學習文化,能大幅提升效率、資料品質和合規性。
善用 Thunderbit 新功能,持續優化流程
Thunderbit 不斷推出新功能——像排程爬取、AI 欄位建議、多語言支援等。能跟上這些更新的專家,交付成果會更快、更好。
像是利用 Thunderbit 的排程爬取,專家能自動定時抓資料,確保數據即時更新。或是精通 Field AI Prompts,能用最少人工介入,精準提取和標註複雜資料。
主動學習、勇於嘗試新功能的人,是團隊的寶藏——不管網路怎麼變,都能讓你的資料流程順暢運作。
軟實力同樣重要:溝通、獨立和解決問題
技術力很重要,但軟實力才是讓資料爬蟲專家真正發揮價值的關鍵。我特別重視:
- 清楚溝通:能不能把技術概念講給非技術同事聽?
- 獨立作業:能不能自己完成任務並做決策?
- 堅持不懈:遇到困難時,會不會持續嘗試還是輕易放棄?
- 靈活應變:需求變動或網站改版時,能不能快速調整?
舉個例子:我合作過一位專家,不只交付乾淨數據,還會主動提醒潛在合規風險並提出流程優化建議。這種主動性,真的超有價值。
寫明確、精準的職缺說明,吸引頂尖人才
優秀人才從明確的職缺說明開始。請具體列出需求、技能和合規期望。建議包含:
- 職責說明:要抓哪些資料?會用哪些工具?
- 技能要求:列出技術(像 Thunderbit、Python、反爬蟲技巧)和軟實力(溝通、獨立作業)。
- 合規重點:強調合法、道德資料收集的重要性。
- 持續學習:表明公司重視持續訓練和工具精進。
用能吸引同時具備技術和商業思維人才的語言。提到 Thunderbit 或 AI 工具經驗,有助於吸引前瞻型專家。
職缺範本參考
以下是一份可自訂的範本:
| 職稱 | 資料爬蟲專家 |
|---|---|
| 關於我們 | 我們是一家以數據為導向的公司,誠徵資料爬蟲專家,協助我們高效擷取、清理並交付高品質網路資料,為業務決策提供洞察。你將運用 Thunderbit 等先進工具,自動化並優化資料收集流程。 |
| 工作內容 | - 規劃並執行資料爬取專案(結構化與非結構化資料) - 運用 AI 工具(如 Thunderbit)高效提取資料 - 處理反爬蟲、分頁與子頁爬取 - 確保合規(GDPR、CCPA、著作權、T&Cs) - 清理、結構化並匯出資料至 Excel、Google Sheets、Notion 或 Airtable - 與業務團隊溝通分析結果與建議 - 持續學習最新爬蟲工具與最佳實踐 |
| 條件要求 | - 有資料爬取經驗(需提供作品集或專案案例) - 熟悉 AI/無程式碼工具如 Thunderbit - 具備解決問題與溝通能力 - 了解資料隱私法規與合規 - 樂於持續學習與自我提升 |
| 加分條件 | - 有多語言爬取專案經驗 - 熟悉 Field AI Prompts 與自訂資料標註 - 參與過爬蟲社群或開源專案 |
面試與評估的最佳做法
面試資料爬蟲專家既是科學也是藝術。我建議:
- 技術測驗:給實際爬取任務,最好同時用程式碼和 Thunderbit 等無程式碼工具完成。
- 作品集審查:要求過往專案、程式碼或案例分享。
- 行為面試:深入了解溝通、獨立作業和適應力。
- 合規檢測:用情境題測試其法律和道德意識。
- 遠端評估:可以用螢幕分享即時展示,或設計明確的居家作業。
技術、實作和軟實力並重,才能找到不只是「爬蟲手」,而是真正的數據夥伴。
結語:打造成功的資料爬蟲團隊
招募資料爬蟲專家,絕對不只是看技術力,更要把業務需求、技能組合和合規意識緊密結合。請先明確定義需求,找能處理結構化和非結構化資料、熟悉現代 AI 平台(像 Thunderbit)的人才。別忘了檢查合規意識和持續學習的態度——因為在這個領域,停下來就等於落後。
這樣做的回報?你會拿到乾淨、可用的數據,推動更聰明的決策、更快的執行力,真正建立競爭優勢。準備好了嗎?歡迎安裝 或瀏覽 獲取更多團隊建設秘訣。
常見問題
1. 網頁爬蟲中的結構化和非結構化資料有什麼差別?
結構化資料有明確架構(像表格、資料庫),容易擷取和分析。非結構化資料則比較亂(像文字、圖片、PDF),需要進階技術處理()。
2. 為什麼招募資料爬蟲專家時,要重視 Thunderbit 等工具經驗?
AI 工具像 Thunderbit 能大幅提升資料擷取效率和穩定性,特別適合非技術用戶或多語言專案。熟悉這些工具的專家,能用更少設定和維護,快速交付成果()。
3. 如何評估候選人的資料爬取技術力?
可以用實作測驗、作品集審查和情境題面試。請候選人完成實際爬取任務、處理反爬蟲,或用子頁爬取豐富資料集。
4. 招募資料爬蟲專家時,應注意哪些法律和道德議題?
要確認候選人懂 GDPR、CCPA、著作權和網站服務條款。負責任的爬取,必須尊重隱私、智慧財產和合規要求()。
5. 如何鼓勵資料爬蟲團隊持續學習?
建立持續學習文化——鼓勵團隊追蹤產業部落格、嘗試新工具像 Thunderbit,並參與爬蟲社群。持續學習能提升資料品質和長期競爭力。
想打造理想的數據團隊?從明確需求開始,兼顧技能和心態,讓數據(還有 Thunderbit)成為你的最佳助力。
延伸閱讀