到了 2025 年,網路數據早就不是「有也好、沒有也沒差」的資源,而是企業決策的核心命脈。無論是電商大廠即時盯緊競爭對手價格,還是業務團隊自動蒐集潛在客戶名單,大家都把公開網路數據當成數位時代的石油。數據也很誠實地反映這趨勢:現在有 ,超過 。雖然 Python 常常被拿來討論,但,尤其在重視穩定性和系統整合的企業級應用裡。

我這幾年在 SaaS 和自動化領域打滾,親眼看到 Java 網頁爬蟲怎麼徹底翻轉企業營運。不過,也常遇到團隊卡在底層程式細節,或被動態網站、反爬蟲機制搞到頭大。這也是我想寫這份 2025 Java 網頁爬蟲實戰指南的原因,特別強調怎麼把程式和現代 AI 工具(像 )結合。無論你是開發者、營運主管,還是只想輕鬆拿到數據的商業用戶,這份指南都能幫你少走冤枉路。
什麼是 Java 網頁爬蟲?一分鐘快速上手
簡單說,Java 網頁爬蟲就是用 Java 程式自動從網站抓資料。你可以把它想像成一個超快的虛擬助理,能一口氣讀成千上萬個網頁,把你要的資訊整理好丟進表格裡——而且永遠不會喊累、不會出包,速度只看網路多快。
它的運作流程超直觀:
- 發送請求到網站(就像你用瀏覽器開網頁一樣)。
- 下載 HTML 原始碼(也就是網頁的底層結構)。
- 解析 HTML,轉成程式能懂的結構。
- 擷取你要的資料(像商品名稱、價格、email 等)。
- 把結果存起來,格式可以是 CSV、Excel、資料庫,甚至 Google Sheets。
其實不用是資深工程師也能懂這些基本概念。只要選對工具、照步驟來,商業用戶也能輕鬆自動化數據蒐集,把雜亂的網頁變成有價值的洞察。
為什麼 2025 年企業更需要 Java 網頁爬蟲?
網頁爬蟲早就不是技術宅的玩具,而是企業競爭力的關鍵武器。來看看企業怎麼用 Java 網頁爬蟲搶先機,以及它帶來的實際效益:
| 網頁爬蟲應用場景 | 商業效益(ROI) | 典型產業 |
|---|---|---|
| 競價監控 | 即時掌握市場價格,快速調整帶動銷售成長 20%+ | 電商、零售 |
| 潛在客戶開發與銷售情報 | 自動產生最新名單,人工搜尋時間減少 70% | B2B 銷售、行銷、獵才 |
| 市場調查與趨勢分析 | 及早發現市場趨勢,營收提升 5–15%,行銷投報率提高 10–20% | 消費品、行銷顧問 |
| 金融與投資數據 | 提供交易決策的另類數據,網頁爬蟲「另類數據」市場規模超過 50 億美元 | 金融、對沖基金、金融科技 |
| 流程自動化與監控 | 例行數據自動收集,節省 73% 成本,部署速度提升 85% | 房地產、供應鏈、政府 |
()
為什麼選 Java?因為它天生適合大規模、穩定又好整合。很多企業的數據流程本來就架在 Java 上,直接串接網頁爬蟲最順手。而且 Java 的多執行緒和錯誤處理能力,讓你能輕鬆應付每天成千上萬頁的龐大任務。
Java 網頁爬蟲的運作原理與獨家優勢
來拆解一下典型 Java 網頁爬蟲的核心流程:
- HTTP 請求: 用 JSoup 或 Apache HttpClient 這類函式庫抓網頁內容。你可以自訂標頭、用代理伺服器,甚至模擬真實瀏覽器來閃避封鎖。
- HTML 解析: JSoup 這類工具會把 HTML 轉成「DOM 樹」,讓你用 CSS 選擇器輕鬆定位資料。
- 資料擷取: 你可以自訂規則(像「抓所有
<span class='price'>」)來拿到你要的資訊。 - 資料儲存: 結果可以存成 CSV、Excel、JSON 或直接寫進資料庫。
Java 在網頁爬蟲領域的獨特優勢
- 多執行緒處理: Java 能同時抓和處理多個網頁,效率大提升。Python 的 GIL 會卡住,但 Java 的執行緒是真正並行。
- 高效能: Java 是編譯型語言,處理大型或高記憶體需求的任務超給力。
- 企業級整合: Java 爬蟲能無縫串接現有系統(像 CRM、ERP、資料庫),不用多繞一圈。
- 嚴謹錯誤處理: Java 的型別和例外處理機制,讓長期維運的爬蟲更穩、更好顧。
如果你要穩定又能擴展的數據流程,Java 絕對是首選。
Java 網頁爬蟲必備函式庫與框架:怎麼選?
市面上 Java 網頁爬蟲函式庫不少,但最常用的有三個:JSoup、HtmlUnit、Selenium。各有各的強項:
| 函式庫 | 支援 JavaScript? | 易用性 | 效能 | 最適合用途 |
|---|---|---|---|---|
| JSoup | ❌(不支援 JS) | 非常簡單 | 高效 | 靜態網頁、快速任務、輕量級爬蟲 |
| HtmlUnit | ⚠️ 部分支援 | 中等 | 普通 | 簡單 JS、表單提交、無頭爬蟲 |
| Selenium | ✅ 完全支援 | 中等/較難 | 單頁效能較低 | JS 重度、互動式或動態網頁 |
()
JSoup:靜態 HTML 解析首選
幾乎是我處理大多數爬蟲任務的第一選擇。它輕巧、好上手,特別適合資料直接寫在 HTML 裡的靜態網頁。
範例:
1Document doc = Jsoup.connect("https://www.scrapingcourse.com/ecommerce/").get();
2String bannerTitle = doc.select("div.site-title").text();
3System.out.println("Banner: " + bannerTitle);就是這麼簡單。如果你要抓部落格、商品列表或目錄型網站,JSoup 超好用。
HtmlUnit:模擬瀏覽器,處理進階互動
是用 Java 寫的無頭瀏覽器。它能處理部分 JavaScript、填表單、點按鈕,卻不用真的開瀏覽器視窗。
適用時機: 需要登入、處理簡單動態內容,但又不想用 Selenium 那麼重時。
範例:
1WebClient webClient = new WebClient();
2HtmlPage page = webClient.getPage("https://example.com/login");
3// ... 填寫表單並送出 ...Selenium:對付 JS 重度與互動式網頁
是重量級選手。它能控制真實瀏覽器(像 Chrome、Firefox),所以人類能看的網站它都能搞定,包括全 JS 架構的網站。
適用時機: 需要抓現代 Web App、無限滾動頁面,或必須模擬點擊、等待等互動行為時。
範例:
1WebDriver driver = new ChromeDriver();
2driver.get("https://www.scrapingcourse.com/ecommerce/");
3List<WebElement> products = driver.findElements(By.cssSelector("li.product"));
4// ... 擷取資料 ...
5driver.quit();Thunderbit 加持:AI 視覺化自動化,讓 Java 爬蟲更強大
這裡特別推薦給不想天天寫程式的商業用戶和團隊: 是一款結合 AI 的無程式碼網頁爬蟲,讓你直接在瀏覽器裡視覺化設定爬蟲任務,資料一鍵匯出到 Excel、Google Sheets、Airtable 或 Notion。
為什麼要把 Thunderbit 跟 Java 結合?
- AI 智能欄位建議: Thunderbit 的「AI 建議欄位」會自動分析網頁,推薦你該抓哪些資料,完全不用自己找 HTML 或寫選擇器。
- 子頁面自動爬取: 需要更細的資料?Thunderbit 可自動點每個子頁(像商品詳情頁),幫你補齊數據。
- 即用範本: 熱門網站(Amazon、Zillow、LinkedIn)有一鍵範本,完全免設定。
- 快速匯出: 資料抓好後,幾秒內就能匯出,Java 程式可直接後續處理、分析或整合。
Thunderbit 對原型開發、處理複雜網站,或讓非工程師也能拿到數據特別有幫助。對開發者來說,也能把重複、容易壞的部分交給 Thunderbit,自己專心寫商業邏輯。
Thunderbit + Java 複合式工作流
我最常用的流程如下:
- 用 Thunderbit 快速原型: 透過 Chrome 擴充套件視覺化設定爬蟲,讓 AI 幫你選欄位、處理分頁,資料匯出到 Google Sheets 或 CSV。
- Java 處理後續: 用 Java 讀匯出的資料(Sheets、CSV、Airtable),進一步分析、整合或自動化。
- 自動化排程: Thunderbit 內建排程功能,讓資料自動更新,Java 流程則自動接收最新數據。
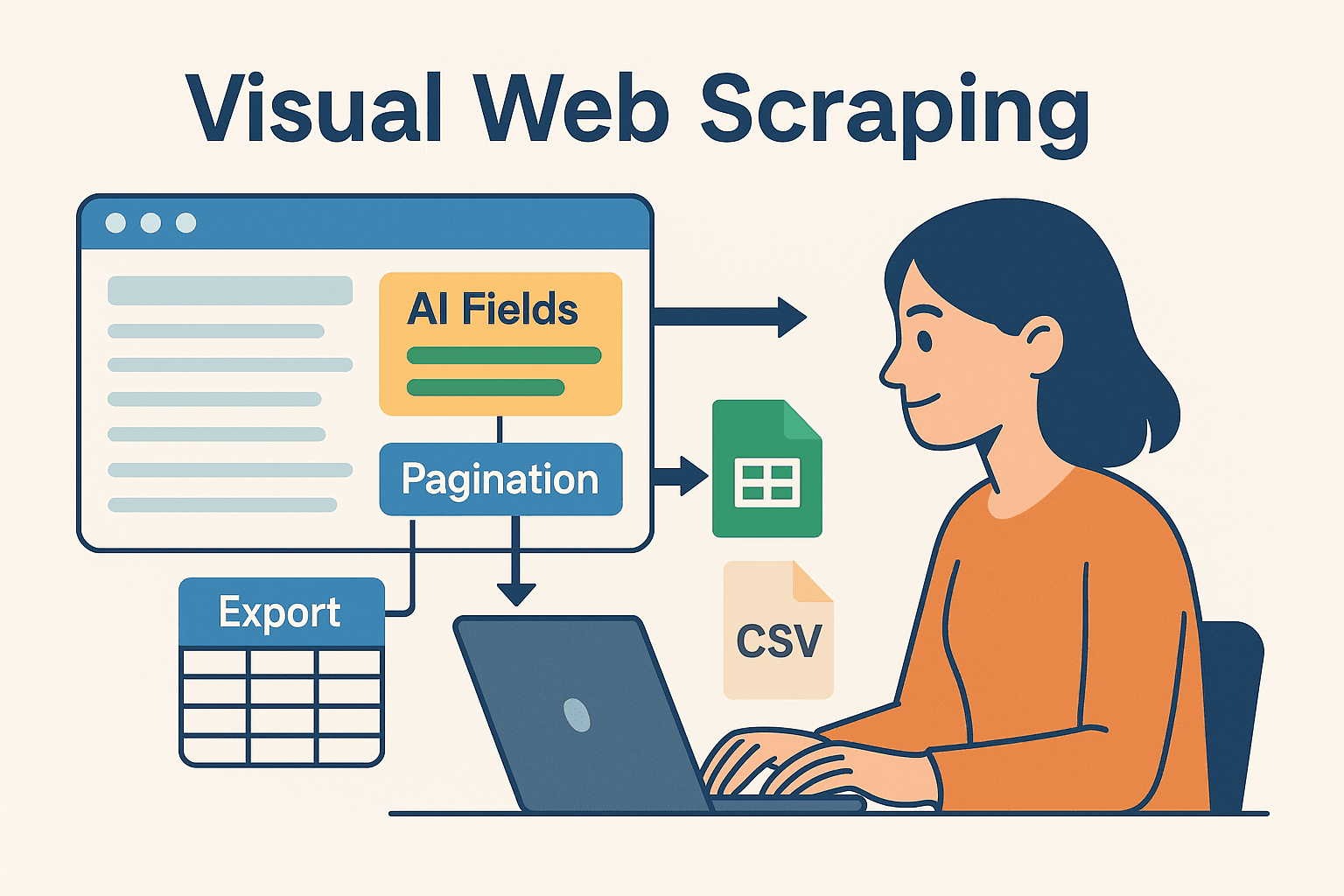
這種混合做法,讓你同時享有 AI 無程式碼的彈性與速度,以及 Java 強大的後端處理力。
實戰教學:打造你的第一個 Java 網頁爬蟲
來動手做做看,以下是從零開始寫一個簡單 Java 網頁爬蟲的步驟:
Java 環境準備
- 安裝 Java(JDK): 建議用 Java 17 或 21。
- 設定 Maven: 幫你自動管理函式庫。
- 選擇 IDE: IntelliJ IDEA、Eclipse、VSCode 都很適合。
- 在
pom.xml加入 JSoup:1<dependency> 2 <groupId>org.jsoup</groupId> 3 <artifactId>jsoup</artifactId> 4 <version>1.16.1</version> 5</dependency>
撰寫與執行爬蟲
以下範例會從電商示範網站抓商品名稱和價格:
1import org.jsoup.Jsoup;
2import org.jsoup.nodes.Document;
3import org.jsoup.select.Elements;
4import org.jsoup.nodes.Element;
5public class ProductScraper {
6 public static void main(String[] args) {
7 String url = "https://www.scrapingcourse.com/ecommerce/";
8 try {
9 Document doc = Jsoup.connect(url)
10 .userAgent("Mozilla/5.0")
11 .get();
12 Elements productElements = doc.select("li.product");
13 for (Element productEl : productElements) {
14 String name = productEl.selectFirst("h2").text();
15 String price = productEl.selectFirst("span.price").text();
16 System.out.println(name + " -> " + price);
17 }
18 } catch (Exception e) {
19 e.printStackTrace();
20 }
21 }
22}小技巧: 記得設定 user-agent 模擬真實瀏覽器,不然有些網站會擋掉預設的 Java user-agent。
資料匯出與應用
- 匯出 CSV: 用
FileWriter或 OpenCSV 寫檔。 - 匯出 Excel: 用 Apache POI 處理 .xls/.xlsx。
- 資料庫整合: 用 JDBC 直接寫進資料庫。
- Google Sheets: 先用 Thunderbit 匯出,再用 Java 的 Google Sheets API 讀取。
Java 網頁爬蟲常見挑戰與解法
網頁爬蟲不是一路順風,這裡整理最常見的難題和對策:
- IP 封鎖與速率限制: 降低請求速度(
Thread.sleep())、輪換代理、隨機延遲。大量任務建議用代理服務。 - 驗證碼與反爬蟲: 用 Selenium 模擬真實用戶,或外包給反機器人 API。有時用 Thunderbit 雲端爬蟲也能繞過。
- 動態內容抓不到: 如果 JSoup 抓不到資料,通常是 JS 動態載入。改用 Selenium、HtmlUnit,或找出網站的 API。
- 網站結構變動: 寫彈性選擇器,並定期監控爬蟲狀態,隨時更新。Thunderbit 的 AI 可快速適應版面變動,只要重新執行「AI 建議欄位」即可。
- 登入與 Session 處理: 需登入時要妥善管理 Cookie 和 Session。Selenium 和 Thunderbit(登入 Chrome 後)都能處理。
進階技巧:提升 Java 網頁爬蟲效率
想再進階一點?這些招式可以試試看:
- 多執行緒: 用 Java 的
ExecutorService同時抓多頁,但別太激進以免被封鎖! - 自動排程: Java 可用 Quartz Scheduler,或直接用 Thunderbit 雲端自然語言排程(像「每週一上午 9 點」)。
- 雲端擴展: 大型任務可在雲端跑無頭瀏覽器,或分散到多台機器。
- 混合式流程: 難搞的網站交給 Thunderbit,其他用 Java 程式,最後在資料倉庫整合。
- 監控與日誌: 用 Java 日誌框架追蹤爬蟲健康狀態,及早發現錯誤並自動警示。
結語與重點整理
網路數據就是新時代的黃金,而 Java 依然是企業級數據擷取的最佳利器,特別適合追求穩定、規模化和系統整合的團隊。核心流程很簡單:抓取、解析、擷取、輸出。有了 JSoup、HtmlUnit、Selenium 這些工具,從靜態目錄到複雜 JS 網站都能輕鬆搞定。
但你不必什麼都自己來。像 這種 AI 工具,讓你能用視覺化方式快速原型、調整和擴展爬蟲專案。我的建議是:勇敢結合程式和無程式碼工具。用 Thunderbit 快速設定和維護,Java 則負責後端重任。
想體驗 Thunderbit 怎麼提升你的工作效率?,幾分鐘內就能開始抓第一個網站。想學更多,歡迎逛逛 ,深入了解各種教學和自動化新知。
祝你爬蟲順利,數據永遠新鮮、結構化、隨時可用!
常見問答
1. 2025 年 Java 還適合做網頁爬蟲嗎?
當然適合。雖然 Python 適合寫小腳本,但 Java 依然是企業級、大型、長時間運行爬蟲的首選,尤其需要多執行緒和系統整合時。
2. 什麼時候該用 JSoup、HtmlUnit 或 Selenium?
靜態網頁用 JSoup,簡單動態內容或表單提交用 HtmlUnit,JS 重度或互動式網站就選 Selenium。依網站複雜度選對工具最重要。
3. 如何避免爬蟲被封鎖?
降低請求頻率、用代理、設定真實 user-agent、模擬人類行為。遇到難搞網站可以考慮 Thunderbit 雲端爬蟲或反機器人 API。
4. Thunderbit 可以和 Java 結合嗎?
絕對可以。用 Thunderbit 視覺化定義和排程爬蟲,匯出資料後再用 Java 處理或整合,對商業用戶和開發者都是超強組合。
5. Java 網頁爬蟲最快的入門方式?
安裝 Java 和 Maven,加上 JSoup,先試著抓一個簡單網站。複雜任務或快速原型可以裝 ,讓 AI 幫你搞定,再把結果串進 Java 流程。
想看更多技巧、程式範例或自動化密技?歡迎逛逛 或訂閱 ,獲得第一手教學和最新爬蟲技術。
延伸閱讀