

我到現在還記得,第一次嘗試用網站抓取銷售名單時的情景。我當時心想:「嘿,我會 JavaScript,這能有多難?」幾個小時後,我已經深陷在一團亂麻般的選擇器、一直消失的動態內容,以及對反爬機制的深刻敬意之中。後來才發現,這並不是只有我遇到的問題——90% 的企業 現在都表示,資料對業務的重要性正在不斷提升,而網頁爬蟲正是這股趨勢的核心。但當網站越做越複雜時,使用 JavaScript 來抓取資料,既像超能力,也像解謎遊戲。
使用 AI 從任何網站抓取資料 Get Started Free
在這篇指南裡,我會分享我一路以來學到的 JavaScript 網頁爬蟲經驗——從入門基礎到那些最棘手的細節,以及像 Thunderbit 這類現代 AI 工具,如何幫你擺脫被選擇器折磨到頭痛的困境。不論你是在幫電商團隊整理商品列表,還是在為銷售團隊建立潛在客戶名單,讓我們一起深入了解如何用 JavaScript(再加上一點 AI)拆解網頁資料抓取這件事。
用 JavaScript 進行網頁爬蟲:基礎與限制
先從最基本的概念說起:使用 JavaScript 進行網頁爬蟲,指的是透過程式化方式從網站擷取資料,做法可以是在瀏覽器中執行腳本,也可以在後端使用 Node.js。JavaScript 本來就是網頁的語言,因此拿來做爬蟲顯得很自然——特別是它擁有像 Cheerio(適合靜態 HTML 解析)以及 Puppeteer、Playwright(適合無頭瀏覽器自動化)這類豐富的函式庫生態。
為什麼 JavaScript 這麼受歡迎?
- 可直接操作 DOM: 在瀏覽器裡,你可以像真人一樣直接查看與操作 DOM。
- 生態完整: Node.js 讓你能使用強大的 HTTP 請求、解析與自動化函式庫。
- 彈性高: 登入、自動點擊、捲動頁面——Chrome 裡能做的事,你幾乎都能用程式自動化。
但問題來了:現代網站變化很快。它們會用 JavaScript 動態載入內容、調整 DOM 節點順序,還會部署反機器人防護機制。這代表你的爬蟲腳本今天能跑,不代表明天還能正常工作。你會不斷更新選擇器、處理彈窗,還要追著非同步載入的資料跑。這有點像打地鼠,只不過加了更多大括號。
為什麼複雜網頁會讓 JavaScript 爬蟲變得棘手
以前抓資料很單純,只要把 HTML 抓下來,解析出你要的內容就好。但現在的網路世界已經不是那麼回事了。像 Facebook Marketplace、Amazon,甚至你本地的房地產刊登頁,很多都靠 JavaScript 框架即時渲染內容,把資料藏在無限捲動裡,還把資訊塞進錯綜複雜的 DOM 結構中。
單靠傳統 HTML 解析,現在已經不太夠用了。比方說,要擷取商品評論或巢狀留言,不只是找到正確的 <div> 就好,而是要理解元素之間的關係、每個欄位的上下文,有時甚至要掌握資料背後的語意。
這時候,更聰明的前置處理就很重要了。你不能只是把原始 HTML 抓下來然後祈禱一切順利,而是需要一種方式,去語意理解頁面內容:哪個是商品名稱?哪個是價格?哪個是使用者評論?對一般 JavaScript 來說,這要求不低;但這也正是 AI 工具最能發揮價值的地方。
傳統的 JavaScript 網頁爬蟲方案
來談談工具。傳統的 JavaScript 爬蟲技術組合通常包含以下其中一種或多種:
- Cheerio: 很適合解析靜態 HTML。你可以把它想像成伺服器端的 jQuery。
- Puppeteer / Playwright: 無頭瀏覽器自動化工具。它們會啟動真實瀏覽器、執行 JavaScript,並讓你像真人一樣與頁面互動(或像一個喝了太多咖啡的機器人)。
一般的流程大致如下:
- 請求頁面(可使用無頭瀏覽器或直接請求)。
- 等待內容載入(有時會搭配
waitForSelector或類似方法)。 - 解析 DOM 取得想要的資料。
- 擷取並整理 結果格式。
聽起來很簡單,對吧?但麻煩就在這裡:網站只要一改版,你的選擇器就可能失效;網站多了一個彈窗,腳本就卡住;欄位順序一調整,資料就亂掉。維護工作會變成沒完沒了的例行公事。
常見 JavaScript 爬蟲函式庫比較
| 功能 | Cheerio | Puppeteer | Playwright |
|---|---|---|---|
| 最適合 | 靜態 HTML | 動態頁面 | 動態頁面 |
| 瀏覽器自動化 | 否 | 是 | 是 |
| 支援 JS 內容 | 否 | 是 | 是 |
| 速度 | 快 | 較慢 | 較慢 |
| API 易用性 | 簡單 | 中等 | 中等 |
| 反爬閃避能力 | 有限 | 中等 | 中等 |
| 跨瀏覽器支援 | 否 | 僅 Chrome | Chrome、Firefox、WebKit |
| 使用情境 | 簡單網站、API | 互動式網站 | 互動式網站 |
Cheerio(目前版本線為 1.1.x)對靜態頁面或回傳 HTML 的 API 來說非常快,但它無法執行 JavaScript。Puppeteer(24.x)與 Playwright(1.60.x)則是處理動態內容的首選,但它們較重,也需要更多設定。兩者都能自動化登入、點擊與捲動,不過你仍然得為網站的各種變化編寫對應邏輯。如果你需要 Chromium 以外的瀏覽器支援,Playwright 仍然更有優勢;而 Puppeteer 則更偏向 Chrome 優先的精簡方案。
介紹 Thunderbit:為 JavaScript 工作流程打造的 AI 網頁爬蟲
接下來就是有趣的地方了。在 Thunderbit,我們意識到,爬蟲不只是把 HTML 抓回來而已,而是要像人一樣理解頁面。因此我們打造了 Thunderbit,一款 AI 網頁爬蟲 Chrome 擴充功能,把語意理解帶進網頁資料擷取流程。
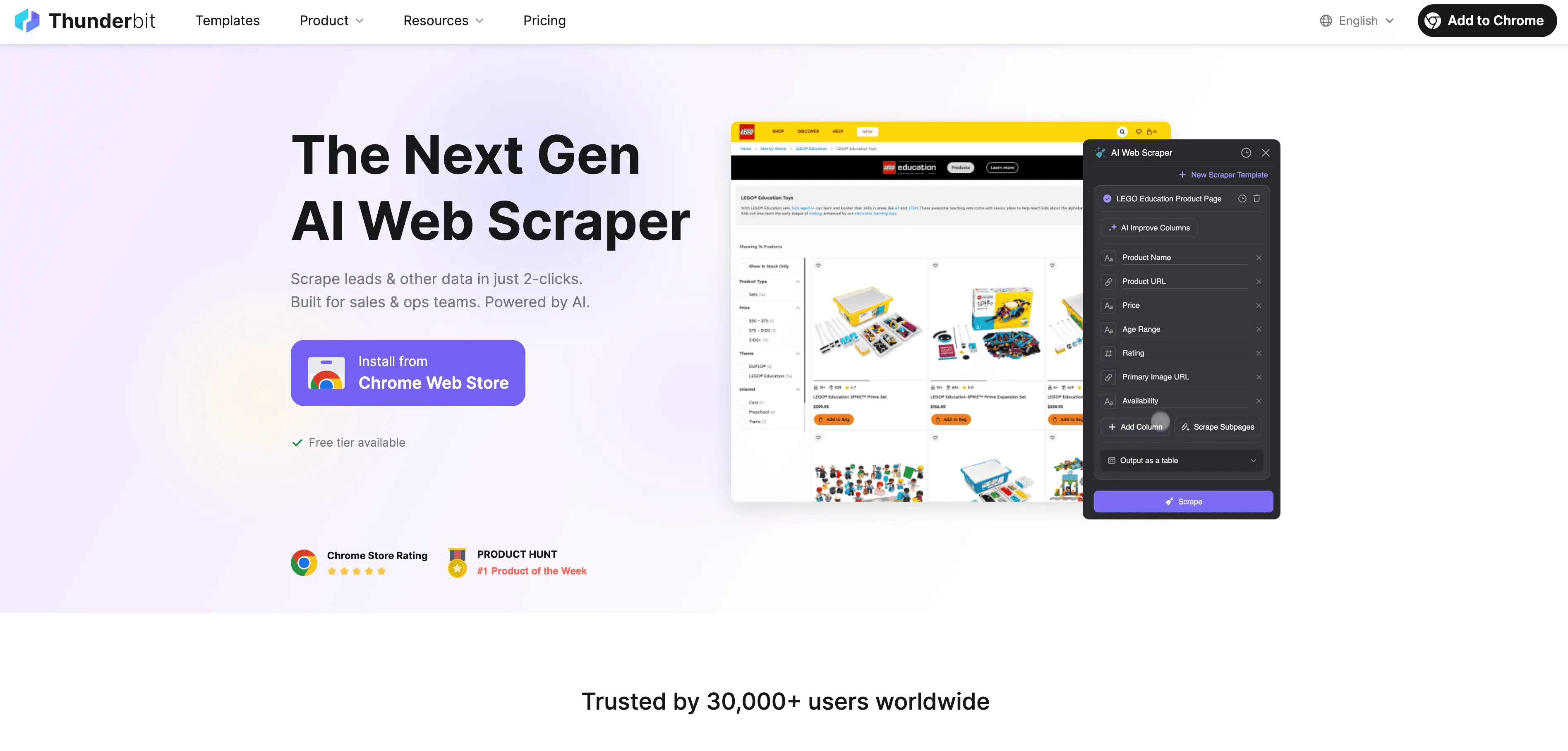
它怎麼運作?
- Thunderbit 會先把網頁轉換成 Markdown 表示——你可以把它想成更乾淨、結構更清楚的頁面版本。
- 接著,我們的 AI 會分析這份 Markdown,找出欄位、關聯與上下文——也就是能分辨哪個是價格、哪個是評論,哪個只是裝飾用表情符號。
- 最後得到的是結構化、帶標籤的資料,而且即使版面改動、內容動態更新,甚至 DOM 階層發生變化,也依然相當穩定。
對商業使用者來說,這代表更少手動整理資料、更少壞掉的腳本,以及更多時間投入真正的洞察分析。對開發者來說,則代表你可以專注在瀏覽自動化(登入、點擊、捲動)上,讓 Thunderbit 負責那些又髒又雜的資料擷取工作。
分步教學:使用 JavaScript 進行網頁爬蟲(傳統方法與 Thunderbit 版)
來動手實作吧。我會用一個真實案例帶你走一遍:從一個示範電商網站抓取商品列表。先用 Puppeteer 示範傳統作法,再展示如何把繁重的擷取工作交給 Thunderbit,讓流程更有效率。
第 1 步:建立 JavaScript 爬蟲環境
先確認你已經安裝好 Node.js——目前 Node 24 是 Active LTS 版本(Node 22 處於維護期;如果你想追最新進度,Node 26 是最新 Current 版本)。準備好之後,我們來安裝 Puppeteer:
npm install puppeteer
如果你比較喜歡 Playwright(支援更多瀏覽器),可以使用:
npm install playwright
如果你不是技術背景,也不用擔心:你不需要成為 JavaScript 高手。直接複製貼上程式碼,我會逐步解釋每一段在做什麼。
第 2 步:導覽並操作動態頁面
現代網站很喜歡把資料藏在登入頁、彈窗與無限捲動裡。以下示範如何用 Puppeteer 自動完成這些操作:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
// 前往登入頁
await page.goto('https://example.com/login');
await page.type('#username', 'your_username');
await page.type('#password', 'your_password');
await page.click('#login-button');
await page.waitForNavigation();
// 前往商品列表頁
await page.goto('https://example.com/products');
// 捲動頁面以載入更多項目
await page.evaluate(async () => {
for (let i = 0; i < 5; i++) {
window.scrollBy(0, window.innerHeight);
await new Promise(resolve => setTimeout(resolve, 1000));
}
});
// 等待商品載入完成
await page.waitForSelector('.product-card');
// ...(下一步會進行資料擷取)
})();
這段腳本會先登入、跳到商品頁,再透過捲動載入更多內容。關鍵在於要等待元素出現,不然你最後抓到的只會是一片空白。
第 3 步:使用 JavaScript 擷取資料
接下來我們來抓資料。假設每個商品都包在一個 .product-card 的 div 裡:
const products = await page.$$eval('.product-card', cards =>
cards.map(card => ({
name: card.querySelector('.product-title').innerText,
price: card.querySelector('.product-price').innerText,
link: card.querySelector('a').href,
}))
);
console.log(products);
常見陷阱包括:
- 選擇器很容易失效。 如果網站把
.product-title改成.title,你的腳本就會報錯。 - 隱藏資料。 有些價格或評論會在頁面載入後,透過 AJAX 才出現。
- 反爬措施。 請求太多,可能會被封鎖。
第 4 步:用 Thunderbit AI 強化擷取流程
這時 Thunderbit 就派上用場了。與其跟選擇器與脆弱邏輯纏鬥,不如把渲染後的 HTML(甚至截圖)交給 Thunderbit,讓 AI 幫你完成擷取。
實務上怎麼做?
- 先用 Puppeteer 或 Playwright 自動完成瀏覽、登入與導覽。
- 到達你要擷取的頁面後,抓出 HTML:
const pageContent = await page.content();
- 透過 Thunderbit Chrome 擴充功能 把這份 HTML 送去做 AI 擷取。
Thunderbit 會:
- 將頁面轉成 Markdown,方便進行語意解析。
- 用 AI 辨識欄位、關聯與上下文。
- 輸出你可以匯出到 Excel、Google Sheets、Airtable 或 Notion 的結構化資料。
不用再追著變動的選擇器跑,也不用費心整理一團亂的資料了。
處理動態內容與非同步載入
動態內容幾乎是每個爬蟲最頭痛的問題。網站很愛在初次渲染後才載入資料,例如無限捲動、「載入更多」按鈕,或是 AJAX 載入的評論。
傳統做法:
- 使用
waitForSelector等元素出現。 - 等待「網路閒置」(沒有新請求)後再抓資料。
- 手動觸發捲動或點擊,以載入更多內容。
但這些方法都很脆弱。只要網站改變載入邏輯,你的腳本就可能失效。
Thunderbit 的做法: 透過把頁面轉成 Markdown 並交由 AI 分析結構,Thunderbit 對特定 DOM 階層或 ID 的依賴更低。即使網站改了版,只要內容還在,Thunderbit 的 AI 通常就能找到並擷取它。這代表更少維護成本,以及更穩定可靠的資料結果。
建立可長期運作的資料流程:從腳本到商業洞察
爬蟲不只是一次性的任務,它其實是一條資料管線的起點。我通常會這樣規劃:
- 使用 JavaScript(Puppeteer / Playwright)自動化瀏覽與資料擷取。
- 再交給 Thunderbit 進行 AI 結構化與標註。
- 將結果匯出到你常用的工具:Excel、Google Sheets、Airtable、Notion。
- 使用 Thunderbit 的 Scheduled Scraper 排程重複任務——只要描述頻率(例如「每週一早上 9 點」)、輸入網址,剩下交給 Thunderbit 處理。
- 把結構化資料接回你的業務流程中,不論是銷售開發、價格監控,還是市場研究。
這個組合——用 JavaScript 做自動化、用 Thunderbit 做 AI 擷取——可以讓你打造可重複、低維護成本的資料流程,持續為業務提供新鮮且準確的資料。
結論:如何根據需求選擇合適的網頁爬蟲方式
那麼,用 JavaScript 抓網頁資料,最好的方式是什麼?我的看法如下:
- 傳統 JavaScript 爬蟲(Cheerio、Puppeteer、Playwright)很適合簡單、靜態的網站,或是你需要完全掌控瀏覽器自動化流程的情境。但它的維護成本較高:選擇器會壞、版面會變,反爬機制也一天比一天更嚴格。
- Thunderbit 的 AI 擷取 則多了一層語意理解能力。它對版面變動更有韌性,減少人工資料清理的需求,也能讓你把注意力放在洞察上,而不是除錯腳本。
什麼情況該用哪一種?
- 如果只是快速、一次性抓取簡單頁面,用 Cheerio 或 Puppeteer 就夠了。
- 如果面對的是複雜、動態的網站,或你想讓工作流程更具未來性,就把 JavaScript 腳本與 Thunderbit 的 AI 擷取結合起來。
- 如果你是想完全跳過程式碼的商業使用者,Thunderbit Chrome 擴充功能是最簡單的選擇,只要兩下就能把網頁變成試算表。
想看更多範例嗎?歡迎到 Thunderbit 部落格 了解更深入的教學,例如 如何抓取 Amazon 商品、將資料匯入 Excel 等等。
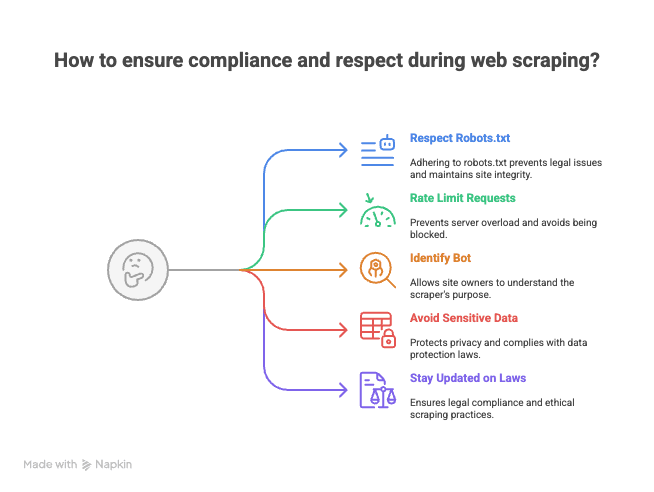
加碼:爬蟲時如何保持合規與尊重網站規範
在你把爬蟲腳本丟到網路世界之前,先提醒一句(這是來自曾經收到過幾封網站管理員「友善」來信的過來人經驗):
- 尊重 robots.txt 與服務條款。 不是每個網站都歡迎被抓取。
- 限制請求頻率。 不要一直猛打伺服器,請適度分散請求,避免被封鎖(甚至列入黑名單)。
- 清楚標示你的機器人身分。 使用自訂 User-Agent 字串,讓網站擁有者知道是誰在存取。
- 避免抓取敏感或個人資料。 只處理公開資訊,並尊重隱私。
- 持續留意法規與最佳實務。 網頁爬蟲在某些司法管轄區仍處於法律灰色地帶,而近期的案例(像 hiQ v. LinkedIn、Bright Data v. Meta)也持續影響哪些做法被允許——在基於抓取資料建立公開產品之前,務必先確認最新判決。
請記住:能力越大,責任越大(有時還會收到一封措辭嚴厲的停止侵權通知)。
使用 JavaScript 進行網頁爬蟲,既是一門藝術,也是一門科學。只要有合適的工具,再加上一點 AI 的幫助,你就能把網路變成自己的結構化資料樂園。如果你真的卡住了,也知道去哪裡找我——我大概會一邊喝咖啡,一邊開著 Thunderbit 分頁除錯選擇器。
祝你抓取順利!
常見問題
1. 什麼是使用 JavaScript 進行網頁爬蟲?為什麼它這麼受歡迎?
使用 JavaScript 進行網頁爬蟲,是指透過在瀏覽器執行腳本或使用 Node.js 後端程式,從網站中程式化擷取資料。它之所以受歡迎,是因為 JavaScript 可以直接操作 DOM,擁有豐富的 HTTP 請求與自動化函式庫生態,也能靈活自動化登入、點擊、捲動等互動流程。
2. 抓取現代動態網站的主要挑戰是什麼?
現代網站常使用 JavaScript 框架動態載入內容,並把資料藏在無限捲動、彈窗之後,還會經常改版。這讓傳統爬蟲方法非常脆弱,因為只要選擇器一變,或資料是非同步載入,腳本就很容易失效。
3. Cheerio、Puppeteer 和 Playwright 這些傳統 JavaScript 爬蟲工具有什麼差異?
- Cheerio 最適合靜態 HTML,速度快,但無法處理 JavaScript 渲染的內容,也不能做瀏覽器自動化。
- Puppeteer 和 Playwright 則是為動態頁面設計,支援瀏覽器自動化,也能處理 JavaScript 內容,但速度較慢,設定也比較多。Playwright 還支援多種瀏覽器,而 Puppeteer 主要以 Chrome 為主。
4. Thunderbit 相較於傳統爬蟲方式,有哪些優勢?
Thunderbit 會先把網頁轉換成結構化 Markdown,再用 AI 語意理解頁面內容並擷取帶標籤的資料欄位。這種方式對版面變動更有韌性,也能減少人工清理資料的需求,相較於傳統依賴選擇器的爬蟲方式,維護成本更低。
5. 網頁爬蟲時,有哪些合規且尊重網站的最佳做法?
- 務必檢查並遵守網站的 robots.txt 與服務條款。
- 控制請求頻率,避免對伺服器造成壓力。
- 用自訂 User-Agent 清楚標示你的機器人。
- 避免抓取敏感或個人資料,僅使用公開資訊。
- 留意你所在地區的法律規範與最佳實務。
了解更多:
- 用 AI 進行即時網頁爬取:快速指南
- 如何用 AI 抓取任何網站
- 使用 JavaScript 與 Node.js 進行網頁爬蟲——新手教學
- 使用 JavaScript 與 Node.js 進行網頁爬蟲
立即試用 Thunderbit AI 網頁爬蟲 Get Started Free




